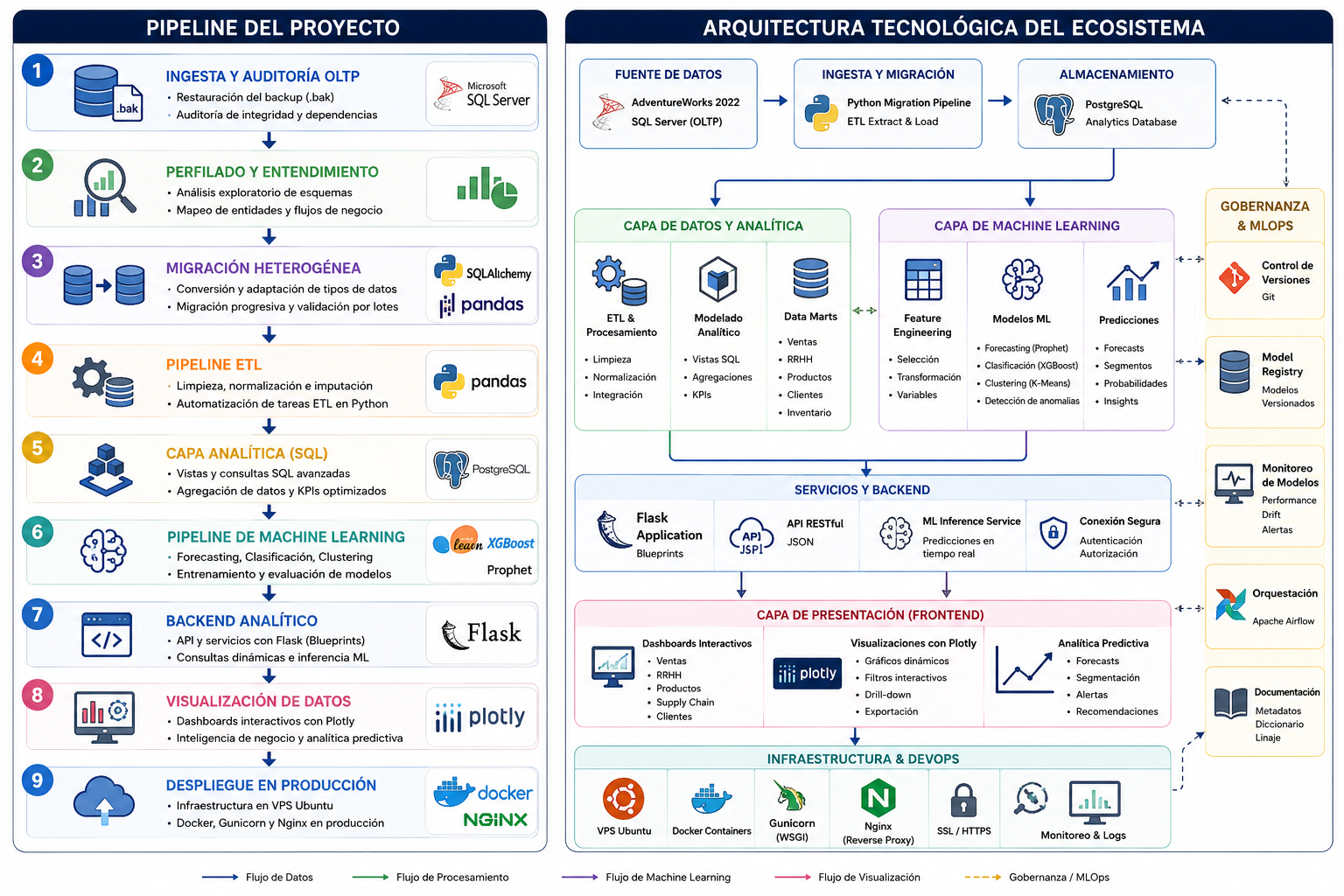
Este proyecto documenta el diseño e implementación de una plataforma de datos full-stack y de código abierto, desarrollada para reemplazar una infraestructura analítica comercial costosa y rígida. A través de la migración de la base de datos relacional de AdventureWorks desde SQL Server hacia PostgreSQL, el desarrollo de pipelines ETL modulares en Python y la integración de modelos predictivos de Machine Learning, se transformó un sistema de reportes tradicional en un motor independiente y escalable, centralizado en una aplicación web interactiva con Flask y Docker.

El Desafío del Negocio (The Problem Statement)
AdventureWorks Inc. gestionaba su inteligencia de negocio y reportería a través de una suite de analítica comercial propietaria y tradicional basada en licencias de software cerrado. Al escalar la organización, el equipo se enfrentó a tres bloqueos críticos:
- Escala Exponencial de Costos por Licenciamiento: El modelo de cobro por usuario o por núcleo se volvió financieramente insostenible ante la creciente demanda de acceso concurrente por parte de Ventas, RRHH, Producción y Compras.
- Limitaciones de Integración con Data Science y ML: El ecosistema cerrado dificultaba acoplar modelos avanzados de Machine Learning (como forecasting de series temporales con Prophet o clasificación con XGBoost) en los flujos de datos sin recurrir a costosos módulos de IA adicionales.
- Dependencia del Proveedor (Vendor Lock-in): La falta de control sobre el procesamiento impedía personalizar la interfaz a nivel corporativo y flexibilizar el despliegue en infraestructura propia.
Nuestra Solución:
Arquitectura Full-Stack Data de Código Abierto. Diseñamos y desarrollamos una plataforma web propietaria, independiente y end-to-end que migró la infraestructura y transformó los reportes rígidos del pasado en un motor analítico y predictivo centralizado:
Pipeline del proyecto
Fase 1: Ingesta, Auditoría y Exploración Profunda (OLTP)
Objetivo: Comprender las reglas y la estructura exacta del negocio para mitigar sesgos en las etapas de transformación y modelado.
- Aprovisionamiento: Extracción y restauración del backup relacional nativo (
.bak) de AdventureWorks 2022 en SQL Server. - Data Quality & Perfilado Inicial: Auditoría técnica mediante scripts SQL de exploración individual para cada una de las 18 tablas relevantes, documentando rangos de fechas, valores únicos y patrones de columnas clave.
- Garantía de Integridad: Identificación exhaustiva de claves primarias y foráneas reales, consolidando las dinámicas operacionales en un Diccionario de Datos maestro y un diagrama relacional completo.
Fase 2: Diseño del Modelo Analítico Relacional y Requerimientos
Objetivo: Traducir los objetivos corporativos en una arquitectura de datos técnica limpia y estructurada.
- Definición de Granularidad: Establecimiento preciso del nivel de detalle de las entidades operativas (ej. Ventas por línea de pedido, Inventarios por snapshots de producto/almacén y Finanzas por periodo contable).
- Mapeo de KPIs: Selección de indicadores estratégicos para una visión de 360° (Sales Amount, Total Product Cost, Profit, Margen %, Tendencias YoY/MoM, Ticket Promedio y Alertas de Stock).
- Gobernanza Técnica: Generación de un Documento de Requerimientos Funcionales como base para validar formalmente las necesidades lógicas con cada área antes de iniciar el código.
Fase 3: Extracción y Preparación mediante Vistas SQL
Objetivo: Proveer una capa de datos purificada, segura y optimizada desde la base de origen.
- Desacoplamiento Estructural: Creación de vistas en SQL Server diseñadas según los requerimientos funcionales para pre-estructurar el set de datos.
- Seguridad y Anonimización: Selección rigurosa de atributos descriptivos y demográficos para segmentación, aplicando políticas de privacidad al anonimizar o remover datos sensibles de clientes.
- Cómputo en Base de Datos: Implementación de transformaciones básicas directamente en el motor de origen (como cálculo dinámico de edad y unificación de jerarquías de productos) para aligerar las fases posteriores de procesamiento en Python.
Fase 4: Migración Heterogénea de Bases de Datos
Objetivo: Romper la dependencia con el proveedor tradicional migrando el núcleo de la compañía a un motor Open-Source (PostgreSQL) sin alterar su estructura relacional original.
- Schema Mapping: Traducción de tipos de datos, restricciones e incompatibilidades entre SQL Server y PostgreSQL mediante el uso de Python.
- Pipelines de Ingesta: Diseño de scripts de migración progresiva y por lotes para mover de manera controlada el modelo relacional puro, asegurando consistencia matemática absoluta entre ambos motores.
- Stack Principal: SQL Server, PostgreSQL, SQLAlchemy, PyODBC, Psycopg2 y Pandas.
Fase 5: Pipeline ETL y Automatización con Python
Objetivo: Construir un pipeline reproducible con un solo comando que extraiga, limpie y guarde datos curados listos para consumo concurrente.
- Pipeline Modular (Jupyter/Scripts): Desarrollo de notebooks de experimentación consolidados posteriormente en un script ejecutable (
etl_pipeline.py) alimentado por un archivo central de configuración (config.py). - Feature Engineering & Limpieza: Tratamiento automatizado de valores nulos mediante reglas específicas según la columna, conversión estructurada de tipos/fechas y eliminación de duplicados mediante funciones reutilizables (
CheckData). - Persistencia Eficiente (Formatos de Alto Rendimiento): Exportación de datasets limpios y validados a disco en formato Parquet (para optimizar espacio y velocidad de lectura).
- Trazabilidad y Auditoría: Integración de logs detallados de seguimiento en consola para registrar el éxito/fallo del pipeline y mantenimiento de un registro maestro de control (
datasets_control.xlsx) con métricas de filas y columnas procesadas.
Fase 6: Optimización de la Capa Analítica en PostgreSQL
Objetivo: Centralizar la lógica analítica pesada dentro de PostgreSQL para mitigar la carga computacional en el backend de la aplicación.
- Modelado Lógico: Configuración de Vistas (Views) enriquecidas y almacenamiento indexado en PostgreSQL directamente sobre las tablas migradas.
- Agregación Avanzada: Construcción de consultas complejas diseñadas para unificar la información dispersa de las áreas de Sales, HR, Product Performance, Supply Chain y Customer Analytics en estructuras consolidadas.
Fase 7: Backend Analítico y Arquitectura de Software
Objetivo: Construir la capa lógica del servidor encargada de procesar peticiones y unificar los datos analíticos de la empresa.
- Backend Engineering: Desarrollo de una aplicación web robusta en Python utilizando Flask, estructurada de forma modular mediante Blueprints para segmentar los servicios de cada departamento de la compañía.
- Persistencia Dinámica y APIs: Conexión interactiva a PostgreSQL para leer de forma nativa los archivos estructurados y las vistas optimizadas, garantizando tiempos mínimos de respuesta del servidor (latencia en milisegundos).
Fase 8: Pipeline de Machine Learning y Analítica Predictiva
Objetivo: Escalar la plataforma hacia la analítica predictiva, dotando al sistema de la capacidad de anticipar eventos críticos de negocio.
- Modelado de Inteligencia Artificial: Diseño e implementación de modelos supervisados y de análisis temporal utilizando Scikit-Learn, XGBoost y Prophet.
- Casos de Uso Operacionales:
- Forecasting de Ventas: Modelos de series de tiempo para proyectar la demanda mensual e ingresos.
- Clasificación de Churn: Modelos predictivos para calcular la probabilidad de abandono de clientes recurrentes.
- Optimización de Cadena de Suministro: Predicción de quiebres de stock basándose en flujos históricos de inventario.
- Inferencia en Producción: Creación de un script automatizado para la extracción de features, reentrenamiento de modelos y serialización de artefactos (
.pkl/ ONNX), consumidos directamente por la API de Flask para generar predicciones en tiempo real. [1]
Fase 9: Visualización de Datos e Interfaces de Usuario (Frontend)
Objetivo: Democratizar los insights corporativos permitiendo a la mesa directiva evaluar el rendimiento histórico y forecast predictivos en una sola pantalla unificada.
- Frontend Interactivo: Creación de una interfaz web multipágina y responsive codificada con Plotly y Flask, reemplazando por completo los visualizadores de la suite comercial rígida.
- Dashboards Ejecutivos Diseñados: Executive Overview, Sales Intelligence, HR Analytics, Product Performance y Geographic Insights.
- Capa Semántica Unificada: Ocultamiento de columnas técnicas y exposición directa al usuario de medidas avanzadas de KPIs históricos calculados en base de datos junto a las proyecciones dinámicas estimadas por los modelos de Machine Learning.
Fase 10: Despliegue en Producción y DevOps (MLOps)
Objetivo: Publicar el sistema bajo una infraestructura escalable, segura y con costos de mantenimiento fijos, logrando la independencia total del negocio.
- Infraestructura Cloud: Aprovisionamiento, hardening y configuración de políticas de seguridad en un Servidor Virtual Privado (VPS) con Ubuntu Server.
- Contenerización Completa: Aislamiento de entornos y servicios (PostgreSQL, la aplicación Flask con sus pipelines de ML, las dependencias de Python y los servidores web) mediante Docker y Docker Compose.
- Arquitectura de Producción: Implementación del servidor WSGI Gunicorn acoplado a Nginx como proxy inverso, garantizando la gestión eficiente de peticiones, compresión de assets, balanceo de carga básico y cifrado SSL.
Ecosistema Tecnológico (Tech Stack)
| Categoría | Tecnologías Clave | Propósito en el Proyecto |
| Lenguajes | Python (v3.11+), SQL (T-SQL / PL-pgSQL), HTML5/CSS3 | Procesamiento central, consultas optimizadas e interfaz nativa. |
| Bases de Datos | SQL Server , PostgreSQL | Migración heterogénea desde el motor origen tradicional al destino Open-Source. |
| Data Engineering & ETL | Pandas, SQLAlchemy, PyODBC, Psycopg2, Parquet | Scripting modular, mapeo de esquemas y persistencia de alto rendimiento. |
| Data Science & ML | XGBoost, Prophet (Meta), Scikit-Learn, ONNX / Pickle | Modelos predictivos de series temporales, clasificación de churn e inferencia. |
| Backend & APIs | Flask, Flask Blueprints, Gunicorn | Arquitectura de software modular para servir datos y predicciones en tiempo real. |
| Frontend & UX | Plotly, Dash / Custom Components | Visualizaciones interactivas multipágina y dashboards corporativos 360°. |
| DevOps & MLOps | Docker, Docker Compose, Nginx, Ubuntu Server (VPS), SSL | Contenerización multi-servicio, proxy inverso, seguridad y despliegue en la nube. |
Infografía de pipeline y arquitectura tecnológica