Desarrollo de un Motor de Recomendación para Plataformas MOOC mediante Machine Learning
Este proyecto corresponde al Capstone Project del programa profesional IBM Machine Learning Professional Certificate, finalizado en 2025. Como trabajo final de la certificación, integra de forma práctica los conocimientos adquiridos a lo largo de todo el itinerario formativo, incluyendo análisis exploratorio de datos, ingeniería de características, aprendizaje supervisado y no supervisado, reducción de dimensionalidad, procesamiento de datos textuales y sistemas de recomendación.
El objetivo del proyecto es resolver un problema empresarial real mediante la aplicación de técnicas de Machine Learning, siguiendo una metodología similar a la empleada en entornos profesionales de ciencia de datos e inteligencia artificial.
Reestructuración del Proyecto y Gestión de Datos
Durante el análisis inicial de este proyecto se identificó que los notebooks originales funcionan de forma relativamente independiente y utilizan distintos conjuntos de datos previamente preparados. Lo que constituye una de las debilidades de muchos proyectos educativos: el pipeline real está oculto o simplificado para centrarse en la técnica que se quiere enseñar. Esto dificulta la comprensión del flujo completo de datos y la trazabilidad de las transformaciones realizadas a lo largo del proyecto.
Con el objetivo de construir una solución más cercana a un entorno profesional de Ciencia de Datos y Machine Learning, se ha decidido reorganizar el proyecto siguiendo una arquitectura basada en etapas claramente definidas. Para ello, se identificarán los conjuntos de datos originales proporcionados por IBM y se establecerá un flujo de procesamiento donde cada notebook consumirá los resultados generados por la fase anterior.
El proyecto partirá de tres fuentes de datos principales:
- course_genre.csv, que contiene la información categórica de los cursos.
- course_processed.csv, que contiene la información textual de los cursos utilizada para las tareas de procesamiento de lenguaje natural.
- ratings.csv, que almacena las interacciones entre usuarios y cursos.
La arquitectura final seguirá un enfoque tipo pipeline, donde los datos evolucionan progresivamente desde su estado original hasta convertirse en las características y estructuras necesarias para los diferentes sistemas de recomendación implementados. Este enfoque aporta varias ventajas:
De esta manera, el proyecto mantiene el mismo problema de negocio planteado en el Capstone de IBM, pero adopta una estructura de datos más sólida, transparente y alineada con las buenas prácticas de desarrollo de proyectos de Machine Learning en entornos reales.
Introducción
Los sistemas de recomendación se han convertido en una pieza fundamental dentro de las plataformas digitales modernas. Empresas como Netflix, Spotify, Amazon, YouTube o Coursera utilizan algoritmos de recomendación para personalizar la experiencia de sus usuarios, facilitar el descubrimiento de contenido relevante y aumentar los niveles de interacción dentro de sus ecosistemas.
En este proyecto se aborda el diseño y desarrollo de un sistema de recomendación aplicado al sector de la formación online. El escenario se sitúa en una plataforma MOOC (Massive Open Online Course) denominada AI Training Room, una empresa dedicada a la distribución de cursos relacionados con inteligencia artificial, machine learning, ciencia de datos, computación en la nube y desarrollo de software.
Debido al rápido crecimiento de la plataforma y al incremento constante del catálogo de cursos disponibles, surge la necesidad de ayudar a los estudiantes a identificar contenidos de interés de forma eficiente. Un sistema de recomendación permite resolver este problema mediante el análisis de los cursos existentes y del comportamiento de los usuarios, generando sugerencias personalizadas que facilitan la construcción de itinerarios formativos adaptados a cada alumno.
Desde una perspectiva empresarial, una recomendación más precisa no solo mejora la experiencia de aprendizaje, sino que también puede incrementar indicadores clave como la retención de usuarios, el número de inscripciones por estudiante y los ingresos de la organización.
El objetivo principal de este proyecto consiste en explorar, implementar y comparar diferentes enfoques de recomendación utilizando técnicas de aprendizaje automático tanto supervisadas como no supervisadas. Para ello se trabajará con información relativa a cursos, contenidos y registros de inscripción de estudiantes.
A lo largo del proyecto se desarrollará un flujo de trabajo completo de Machine Learning que incluye:
- Comprensión y exploración de los datos disponibles.
- Análisis exploratorio de datos (EDA).
- Extracción de características textuales mediante técnicas de Bag of Words (BoW).
- Construcción de sistemas de recomendación basados en contenido.
- Aplicación de algoritmos de aprendizaje no supervisado como métricas de similitud, K-Means y Análisis de Componentes Principales (PCA).
- Desarrollo de modelos de filtrado colaborativo utilizando algoritmos como K-Nearest Neighbors (KNN), Non-negative Matrix Factorization (NMF), Redes Neuronales Artificiales y modelos clásicos de Machine Learning.
- Comparación del rendimiento de los distintos enfoques mediante evaluaciones offline.
El proyecto no busca únicamente obtener un modelo funcional, sino analizar las ventajas, limitaciones y casos de uso de cada técnica de recomendación. De esta forma, se reproduce un escenario real de investigación y desarrollo dentro de una empresa tecnológica, donde la selección del modelo adecuado requiere equilibrar precisión, escalabilidad e interpretabilidad.
Finalmente, este trabajo constituye una demostración práctica de competencias en análisis de datos, procesamiento de lenguaje natural, aprendizaje supervisado, aprendizaje no supervisado y sistemas de recomendación, áreas que representan una parte esencial de las aplicaciones modernas de Inteligencia Artificial.
1. Exploratory Data Analysis (EDA)
Antes de desarrollar los modelos de recomendación, fue necesario comprender la estructura y las características de los datos disponibles. Esta fase de análisis exploratorio tuvo como objetivo identificar los principales temas presentes en el catálogo de cursos, analizar la distribución de las categorías y detectar patrones relevantes en las inscripciones de los estudiantes.
<class 'pandas.DataFrame'>
RangeIndex: 307 entries, 0 to 306
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 COURSE_ID 307 non-null str
1 TITLE 307 non-null str
2 Database 307 non-null int64
3 Python 307 non-null int64
4 CloudComputing 307 non-null int64
5 DataAnalysis 307 non-null int64
6 Containers 307 non-null int64
7 MachineLearning 307 non-null int64
8 ComputerVision 307 non-null int64
9 DataScience 307 non-null int64
10 BigData 307 non-null int64
11 Chatbot 307 non-null int64
12 R 307 non-null int64
13 BackendDev 307 non-null int64
14 FrontendDev 307 non-null int64
15 Blockchain 307 non-null int64
dtypes: int64(14), str(2)El conjunto de datos de cursos contiene 307 cursos online clasificados en 14 categorías tecnológicas diferentes, incluyendo Machine Learning, Data Science, Cloud Computing, Python, Big Data y Desarrollo Web. La ausencia de valores nulos y la representación binaria de las categorías proporcionan una base sólida para la construcción de sistemas de recomendación basados en contenido.
Para obtener una visión general del catálogo, se generó una nube de palabras a partir de los títulos de los cursos. El análisis reveló una fuerte presencia de tecnologías ampliamente demandadas en la industria, como Python, Machine Learning, Artificial Intelligence, Data Science, TensorFlow y Cloud Computing. Estos resultados confirman que la plataforma está orientada hacia competencias técnicas de alta relevancia en el mercado laboral actual.

Posteriormente, se analizó la distribución de las categorías para identificar las áreas temáticas más representadas. Este análisis permitió comprender el equilibrio del catálogo y detectar los dominios con mayor oferta formativa. Asimismo, se exploraron combinaciones de categorías, identificando cursos que integran áreas complementarias como Machine Learning y Big Data, una combinación especialmente relevante para el desarrollo de soluciones escalables basadas en datos.
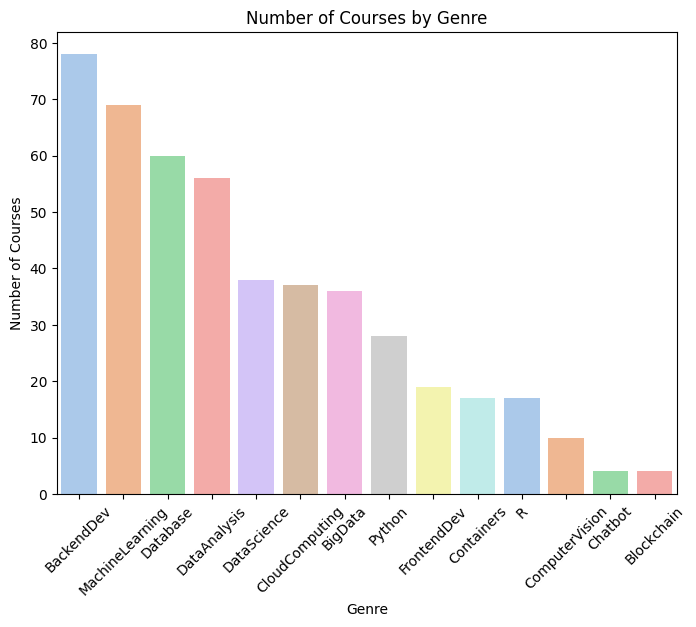
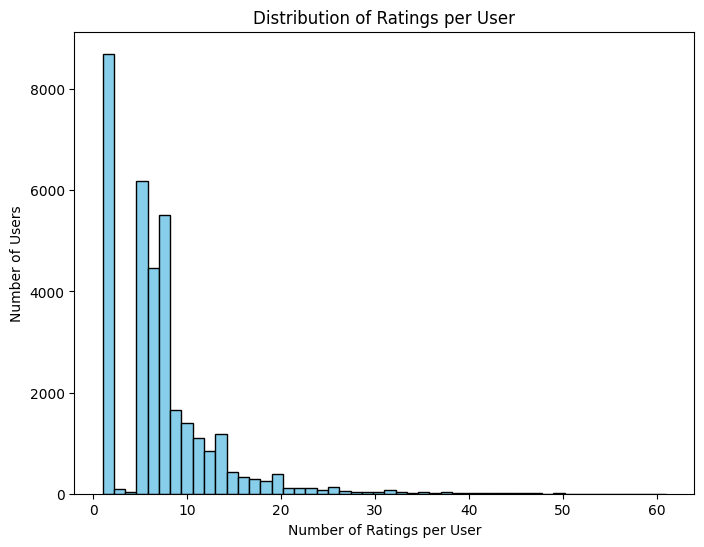
Finalmente, se examinó el conjunto de datos de inscripciones con el objetivo de identificar los cursos más populares y los patrones generales de participación de los estudiantes. Estos hallazgos proporcionaron información valiosa tanto para comprender el comportamiento de los usuarios como para fundamentar el diseño posterior de los modelos de recomendación.
Los 20 cursos con más estudiantes enrolados:
TITLE Enrolls
0 python for data science 14936
1 introduction to data science 14477
2 big data 101 13291
3 hadoop 101 10599
4 data analysis with python 8303
5 data science methodology 7719
6 machine learning with python 7644
7 spark fundamentals i 7551
8 data science hands on with open source tools 7199
9 blockchain essentials 6719
10 data visualization with python 6709
11 deep learning 101 6323
12 build your own chatbot 5512
13 r for data science 5237
14 statistics 101 5015
15 introduction to cloud 4983
16 docker essentials a developer introduction 4480
17 sql and relational databases 101 3697
18 mapreduce and yarn 3670
19 data privacy fundamentals 3624En conjunto, esta fase permitió obtener una comprensión profunda de los datos disponibles y sentó las bases para las etapas posteriores del proyecto, donde se aplicaron técnicas de recomendación basadas en similitud, clustering y filtrado colaborativo.
2. Ingeniería de Características: Representación Bag of Words (BoW)
Uno de los principales desafíos en la construcción de un sistema de recomendación basado en contenido es que los algoritmos de machine learning no pueden procesar directamente información textual. Aunque los títulos y descripciones de los cursos contienen información valiosa sobre las tecnologías, habilidades y temáticas abordadas, es necesario transformar ese contenido en una representación numérica antes de poder utilizarlo en modelos analíticos y algoritmos de recomendación.
Para resolver este problema, se implementó una estrategia de Bag of Words (BoW), una de las técnicas fundamentales del Procesamiento del Lenguaje Natural (NLP). El proceso comenzó con la preparación y limpieza del texto de los cursos mediante técnicas de tokenización, eliminación de palabras vacías (stopwords) y normalización del contenido textual. Este paso permitió reducir el ruido de los datos y conservar únicamente los términos más representativos de cada curso.
Una vez procesado el texto, se construyó un vocabulario global a partir de todos los términos presentes en el catálogo de cursos. Posteriormente, cada curso fue transformado en un vector numérico donde cada dimensión representa una palabra del vocabulario y su valor indica la frecuencia de aparición de dicho término en el curso correspondiente. De esta manera, el contenido textual quedó convertido en una estructura matemática apta para ser utilizada por algoritmos de machine learning.
El resultado de este proceso fue una matriz Bag of Words que captura la composición temática de cada curso y permite cuantificar el nivel de similitud entre ellos. Los cursos que comparten conceptos, tecnologías o áreas de conocimiento generan vectores similares, facilitando la identificación automática de contenidos relacionados incluso en ausencia de información histórica de los usuarios.
Esta fase constituye uno de los pilares del sistema de recomendación, ya que transforma datos no estructurados en características cuantificables sobre las que posteriormente se aplicarán métricas de similitud, algoritmos de clustering y modelos de recomendación basados en contenido.
Objetivos de la fase
- Transformar información textual en variables numéricas procesables por algoritmos de machine learning.
- Aplicar técnicas básicas de Procesamiento del Lenguaje Natural (NLP) para limpiar y estructurar el contenido de los cursos.
- Construir un vocabulario representativo de las tecnologías y habilidades presentes en el catálogo.
- Generar una matriz Bag of Words que describa matemáticamente cada curso.
- Preparar la base de características que servirá como entrada para los modelos de recomendación desarrollados en las siguientes etapas del proyecto.
Tecnologías utilizadas
- Python
- Pandas
- NLTK
- Bag of Words (BoW)
- Procesamiento del Lenguaje Natural (NLP)
- Ingeniería de Características (Feature Engineering)
Resultado obtenido
Se generó una representación vectorial de los cursos basada en su contenido textual, permitiendo convertir descripciones y títulos en información cuantificable. Esta transformación constituye la base sobre la que se calcularán similitudes entre cursos y se construirán los modelos de recomendación personalizados del proyecto.
Imagen recomendada para esta sección: diagrama del pipeline Texto → Tokenización → Limpieza → Vocabulario → Matriz Bag of Words → Vector de Características.