Embedding models
Los embedding models son el componente que transforma el contenido obtenido de los document en representaciones vectoriales densas que capturan significado semántico. En sistemas modernos de RAG dentro de LangChain, los embeddings son la base sobre la que se construye todo el sistema de recuperación.
En términos operativos, un embedding model proyecta texto en un espacio vectorial donde la distancia entre vectores refleja similitud semántica. Esto permite ejecutar búsquedas por similitud (normalmente usando cosine similarity o dot product) en bases de datos vectoriales. La calidad de esta proyección determina directamente la capacidad del sistema para recuperar contexto relevante.
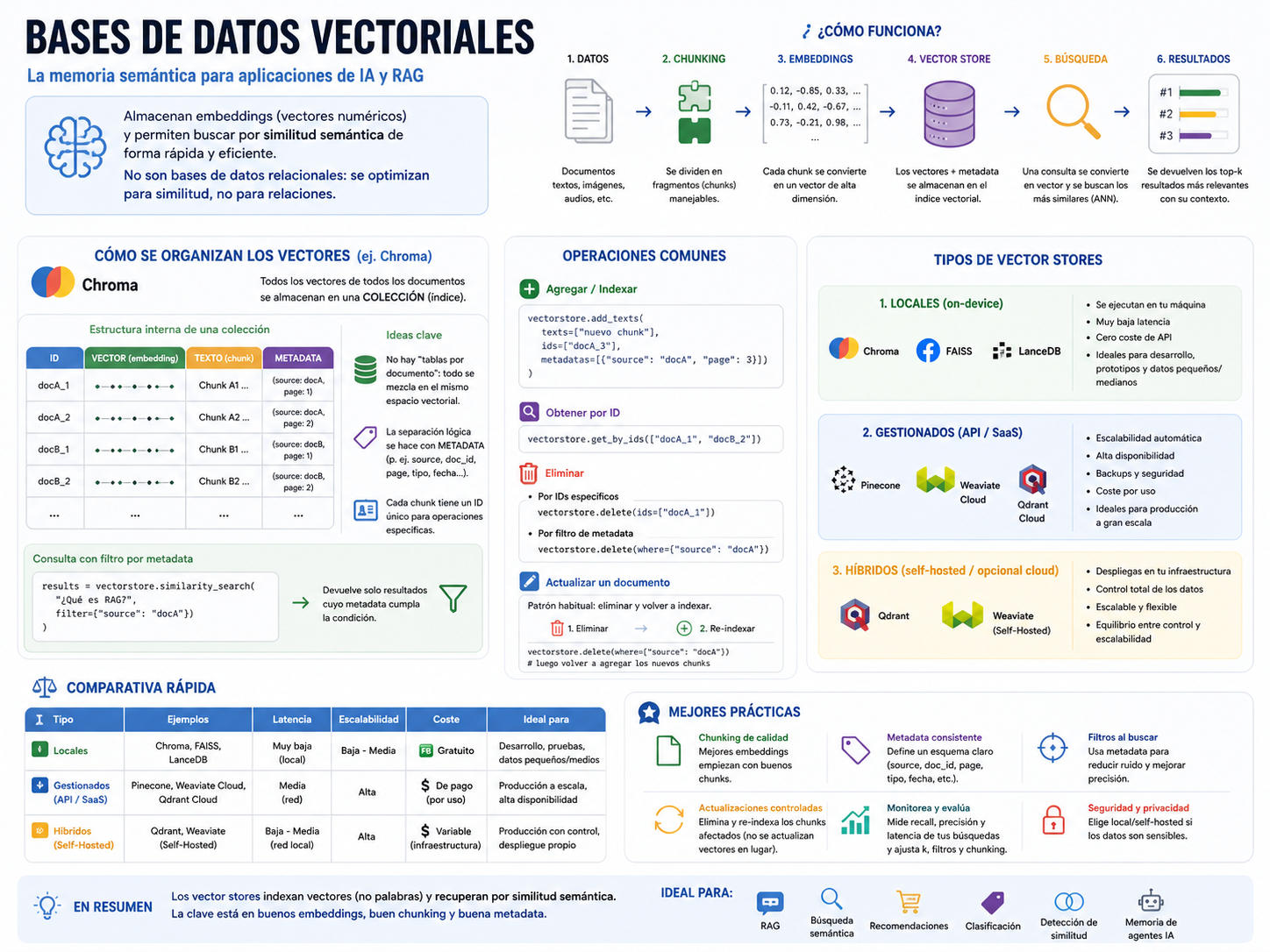
Relación entre embeddings y organización en el vector store
Un aspecto crítico que suele pasarse por alto es que los embeddings no se almacenan como “un vector por documento”, sino como un vector por fragmento (chunk). Esto significa que un mismo documento genera múltiples embeddings que se indexan de forma independiente en el vector store.
En sistemas como Chroma, todos estos vectores se almacenan dentro de una misma colección (índice), independientemente del documento de origen. No existen “tablas separadas por documento”; en su lugar, cada entrada del índice contiene:
- el embedding
- el contenido (
page_content) - la metadata asociada
- un identificador (ID)
De forma conceptual:
[vector, texto, metadata, id]Cuando se indexan múltiples documentos, todos sus chunks se mezclan dentro del mismo espacio vectorial:
ID | Texto | Metadata
-------------------------------------------
docA_1 | chunk A1 | {source: docA}
docA_2 | chunk A2 | {source: docA}
docB_1 | chunk B1 | {source: docB}
Esto implica que la “separación” entre documentos no es física, sino lógica, y se realiza mediante metadata.
Tipos de embedding models
En producción, no todos los embeddings son equivalentes; se diferencian por arquitectura, objetivo y rendimiento.
General-purpose embeddings: Modelos optimizados para tareas generales de similitud semántica como OpenAI embeddings (text-embedding models), se usan en RAG estándar y búsqueda semántica.
Instruction-tuned embeddings: Modelos ajustados con instrucciones para mejorar tareas específicas (query vs document alignment). Tiene la ventaja de hacer mejor matching entre pregunta y contexto
Domain-specific embeddings: Entrenados en dominios concretos: legal, médico, código. Esto hace que mejoren el recall en casos especializados
Multilingual embeddings: permiten búsqueda cruzada entre idiomas.
Parámetros clave
- Dimensionalidad: Más dimensiones → más capacidad semántica, pero mayor coste.
- Normalización: Muchos modelos requieren normalización del vector para usar cosine similarity correctamente.
- Tokenización: El embedding depende del tokenizer del modelo → afecta cómo se representa el texto.
Decisiones críticas en producción
- Query vs Document embeddings: En sistemas avanzados: embeddings distintos para queries y documentos
- Chunking alignment: El rendimiento depende directamente de cómo has hecho el text splitting un chunk mal definido lleva a un embedding pobre y la consecuencia es un retrieval malo
- Batch vs real-time:
- Indexing → los documentos se procesan en batch para generar embeddings de forma eficiente y reducir coste computacional.
- Queries → las consultas del usuario se embeben en tiempo real para realizar búsqueda semántica inmediata sobre la base vectorial.
Errores comunes
- Usar embeddings genéricos en dominios especializados → reduce la precisión semántica porque el modelo no captura bien el vocabulario ni las relaciones propias del dominio.
- No normalizar vectores → provoca que métricas como cosine similarity den resultados incorrectos o inconsistentes en la búsqueda. (
encode_kwargs={"normalize_embeddings": True}) - Usar chunks demasiado grandes o pequeños → los grandes introducen ruido y los pequeños pierden contexto, degradando el retrieval.
- No evaluar recall@k → impide medir si el sistema realmente recupera información relevante, ocultando fallos críticos en producción. Ver en retrievers.
Vector stores
Los vector stores son el componente encargado de almacenar y consultar embeddings de forma eficiente. En un sistema RAG dentro de LangChain, no basta con generar vectores; es necesario indexarlos en una estructura que permita búsquedas por similitud a gran escala con baja latencia.
En términos operativos, un vector store gestiona tres elementos: el vector (embedding), el contenido original (texto) y la metadata asociada. A partir de ahí, permite ejecutar consultas semánticas donde una query se transforma en embedding y se compara contra el índice para recuperar los elementos más cercanos.

Tipos, elección y uso en producción
La elección del vector store no es trivial; afecta a latencia, escalabilidad, coste y operativa. En la práctica, la decisión se reduce a dónde se ejecuta (local vs gestionado) y qué volumen/latencia necesitas.
Tipos de vector stores
Local (on-device): Se ejecutan en la propia máquina, sin dependencias externas. Ideales para prototipos, entornos offline o setups local-first.
- Ejemplos: Chroma, FAISS
- Ventajas: cero coste de API, baja latencia local, control total
- Limitaciones: escalabilidad y concurrencia limitadas
Gestionados (API / SaaS): Servicios externos optimizados para indexación y búsqueda vectorial a gran escala.
- Ejemplos: Pinecone, Weaviate (cloud), Qdrant Cloud
- Ventajas: alta disponibilidad, escalado automático, operaciones gestionadas
- Limitaciones: coste y dependencia de red
Híbridos (self-hosted / cloud opcional): Permiten ejecutar localmente o desplegar en servidor propio con capacidades de escalado.
- Ejemplos: Qdrant, Weaviate (self-hosted)
- Ventajas: equilibrio entre control y escalabilidad
- Limitaciones: necesitas gestionar infraestructura
Comparativa rápida
| Tipo | Ejemplo | Latencia | Escalabilidad | Tipo | Uso recomendado |
|---|---|---|---|---|---|
| Local | Chroma, FAISS | Muy baja | Baja | gratis | desarrollo, local RAG |
| API | Pinecone, Weaviate Cloud | Media | Alta | pago | producción a escala |
| Híbrido | Qdrant, Weaviate | Baja–Media | Alta | variable | producción self-hosted |
Criterios de elección
- Usa local (Chroma / FAISS) si: trabajas en desarrollo o laboratorio, necesitas privacidad total y los dataset son pequeños/medio
- Usa API (Pinecone / Weaviate Cloud) si: necesitas alta disponibilidad, tienes mucho volumen de datos y múltiples usuarios concurrentes
- Usa híbrido (Qdrant / Weaviate self-hosted) si: quieres control + escalabilidad, despliegas en servidor propio y buscas evitar costes SaaS
Insight importante
El vector store no mejora embeddings ni corrige errores de chunking solo acelera la búsqueda; la calidad depende del pipeline previo.
Ingesta / Indexación (escritura en el vector store)
La fase de ingesta es donde se construye el índice vectorial a partir de los datos ya preprocesados (cleaning + splitting). En este punto, los textos o documentos se transforman en embeddings y se almacenan junto con su metadata en el vector store.
Esta operación suele ejecutarse en batch durante el indexing, no en tiempo real, y es crítica porque define la calidad y consistencia del sistema de retrieval: cualquier error aquí (mal chunking, embeddings inconsistentes, falta de metadata) se propagará al resto del pipeline.
Métodos de ingesta
| Método | Descripción |
|---|---|
add_texts | Convierte textos en embeddings y los añade al índice existente. |
aadd_texts | Versión asíncrona de add_texts. |
add_documents | Añade o actualiza documentos (incluyendo metadata) en el vector store. |
aadd_documents | Versión asíncrona de add_documents. |
from_texts | Crea un vector store directamente a partir de una lista de textos. |
afrom_texts | Versión asíncrona de from_texts. |
from_documents | Inicializa un vector store desde documentos estructurados. |
afrom_documents | Versión asíncrona de from_documents. |
Crear vector store desde loaders + splitters
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-en",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
vectorstore = Chroma.from_documents(
chunks,
embedding=embeddings
)
Insight operativo
En producción, estos métodos se utilizan en pipelines de indexing offline, donde grandes volúmenes de datos se procesan en batch para evitar latencia y optimizar costes.
docsearch = Chroma.from_documents(
chunks,
embedding=embedding_model,
persist_directory="./chroma_db"
)Eliminación y gestión de datos
La gestión de datos en un vector store es fundamental para mantener la coherencia del índice a lo largo del tiempo. A diferencia de bases de datos tradicionales, los embeddings no suelen actualizarse “en sitio”; en la práctica, cualquier cambio en el contenido implica eliminar los vectores antiguos y reindexar los nuevos. Por ello, las operaciones de eliminación no son solo tareas de limpieza, sino una parte crítica del ciclo de vida del dato en sistemas RAG.
| Método | Descripción |
|---|---|
delete | Elimina vectores del índice por ID o mediante condiciones sobre metadata. |
adelete | Versión asíncrona de delete. |
Uso típico: eliminar chunks específicos de un documento.
vectorstore.delete(ids=["docA_1", "docA_2"])Elimina todos los vectores asociados a un documento completo.
vectorstore.delete(where={"source": "docA"})Patrón de actualización (delete + reindex)
# eliminar versión antigua
vectorstore.delete(where={"source": "docA"})
# volver a indexar contenido actualizado
vectorstore.add_texts(
texts=["nuevo contenido actualizado"],
metadatas=[{"source": "docA"}]
)
Acceso directo por ID
El acceso por ID permite recuperar documentos de forma determinista sin pasar por el proceso de búsqueda semántica. En lugar de calcular similitudes vectoriales, se accede directamente a los elementos almacenados en el índice usando sus identificadores únicos. Esta operación es clave para tareas de trazabilidad y control, ya que permite verificar exactamente qué contenido fue indexado o recuperado en etapas anteriores del pipeline.
Métodos de acceso
| Método | Descripción |
|---|---|
get_by_ids | Recupera documentos directamente por sus IDs. |
aget_by_ids | Versión asíncrona de get_by_ids. |
Recuperar documentos por ID
docs = vectorstore.get_by_ids(["docA_1", "docB_2"])
for doc in docs:
print(doc.page_content, doc.metadata)Uso en debugging: Permite verificar el origen del documento, metadatos asociados y contenido extacto indexado.
doc = vectorstore.get_by_ids(["docA_1"])[0]
print(doc.metadata)Reconstrucción de contexto: reconstruir un documento original a partir de chunks, auditar resultados del retrieval.
ids = ["docA_1", "docA_2"]
chunks = vectorstore.get_by_ids(ids)
full_text = " ".join([c.page_content for c in chunks])
Búsqueda semántica (core del RAG)
La búsqueda semántica es el núcleo de cualquier sistema RAG: es el mecanismo que permite recuperar información relevante a partir de una consulta, no por coincidencia exacta de palabras, sino por similitud en el espacio vectorial. En esta fase, la query se transforma en embedding y se compara contra el índice para encontrar los fragmentos más cercanos. Este proceso implementa, en la práctica, algoritmos de k-nearest neighbors (k-NN) o sus variantes aproximadas (ANN) para escalar a grandes volúmenes de datos.
Búsqueda básica
La forma más directa de retrieval es recuperar los documentos más similares a una query.
| Método | Descripción |
|---|---|
similarity_search | Devuelve los documentos más similares a una query. |
asimilarity_search | Versión asíncrona de similarity_search. |
similarity_search_by_vector | Realiza la búsqueda usando un embedding ya calculado. |
asimilarity_search_by_vector | Versión asíncrona de búsqueda por vector. |
results = vectorstore.similarity_search(
"What is a text splitter?",
k=3
)
# k muy bajo → pierdes información relevante
# k muy alto → el LLM recibe ruido
for doc in results:
print(doc.page_content)
| k | Uso |
|---|---|
| 1 | muy preciso, poco contexto |
| 3 | estándar |
| 5–10 | más contexto, más ruido |
Usar by_vector cuando ya tienes el embedding calculado y quieres optimizar rendimiento.
query_vector = embeddings.embed_query("What is LCEL?")
results = vectorstore.similarity_search_by_vector(query_vector)
Búsqueda con scoring
Estas variantes añaden información cuantitativa sobre la similitud, lo que permite evaluar y depurar el comportamiento del retrieval.
| Método | Descripción |
|---|---|
similarity_search_with_score | Devuelve documentos junto con su distancia o score técnico. |
asimilarity_search_with_score | Versión asíncrona. |
similarity_search_with_relevance_scores | Devuelve scores normalizados entre 0 y 1. |
asimilarity_search_with_relevance_scores | Versión asíncrona. |
Se usa para evaluación de calidad (recall, ranking), análisis de relevancia y tuning del sistema
results = vectorstore.similarity_search_with_relevance_scores(
"What are embeddings?",
k=3
)
for doc, score in results:
print(score, doc.page_content)MMR (Max Marginal Relevance)
MMR introduce un criterio adicional: no solo busca relevancia respecto a la query, sino también diversidad entre los resultados.
| Método | Descripción |
|---|---|
max_marginal_relevance_search | Selecciona documentos optimizando relevancia y diversidad. |
amax_marginal_relevance_search | Versión asíncrona. |
max_marginal_relevance_search_by_vector | MMR usando embeddings en lugar de texto. |
amax_marginal_relevance_search_by_vector | Versión asíncrona. |
Ejemplo con: max_marginal_relevance_search. Evita resultados redundantes, mejora la cobertura del contexto y es útil cuando los documentos son similares entre sí.
results = vectorstore.max_marginal_relevance_search(
"Explain embeddings",
k=3
)Método genérico
El método search permite unificar distintas estrategias bajo una sola interfaz.
| Método | Descripción |
|---|---|
search | Permite elegir el tipo de búsqueda (similarity, MMR, etc.). |
asearch | Versión asíncrona. |
search() permite seleccionar dinámicamente entre similarity, MMR, scoring.
results = vectorstore.search(
"What is RAG?",
search_type="mmr"
)Filtering (restricción por metadata)
El filtering permite restringir el espacio de búsqueda en el vector store utilizando metadata asociada a cada chunk. A diferencia de la búsqueda semántica, que opera sobre embeddings, los filtros actúan como una condición lógica que limita qué subconjunto de datos se considera antes (o durante) el cálculo de similitud.
Cómo funciona: Cada chunk indexado incluye metadata:
Document(
page_content="...",
metadata={"source": "docA", "section": "intro"}
)El filtro se aplica en la búsqueda: solo se evalúan los vectores que cumplen esa condición.
results = vectorstore.similarity_search(
"text splitting",
k=3,
filter={"source": "docA"}
)Uso con retriever
retriever = vectorstore.as_retriever(
search_kwargs={
"k": 3,
"filter": {"source": "docA"}
}
)
docs = retriever.invoke("What is a text splitter?")
Casos de uso
- separación entre documentos
- sistemas multi-usuario (multi-tenant)
- filtrado por secciones (capítulos, páginas)
- control de contexto en RAG
Consideraciones
- Los filtros dependen de la metadata → si no la defines bien, no funcionan
- No sustituyen la similitud → la complementan
- Su implementación puede variar según el vector store
Insight clave
- embeddings → determinan relevancia
- filtering → determina contexto
Ambos son necesarios para un retrieval correcto.
Atributos
Los vector stores no solo almacenan datos, sino que también mantienen información sobre los componentes con los que fueron construidos. El atributo más relevante es embeddings, que hace referencia al modelo de embeddings asociado al índice.
Este atributo permite garantizar que las operaciones de retrieval se realicen con el mismo espacio vectorial con el que se indexaron los datos, evitando inconsistencias difíciles de detectar.
| Atributo | Descripción |
|---|---|
embeddings | Modelo de embeddings asociado al vector store. |
print(vectorstore.embeddings)Para qué se utiliza
- Consistencia → asegura que las queries se embeben con el mismo modelo usado en la indexación
- Debugging → permite verificar qué modelo está realmente en uso
- Auditoría → ayuda a rastrear configuraciones en sistemas complejos
Caso práctico
query_vector = vectorstore.embeddings.embed_query("What is RAG?")Error común
Cambiar el modelo de embeddings sin reindexar da como resultado búsquedas incorrectas o incoherentes.
index → creado con modelo A
query → generada con modelo B Retriever
El método as_retriever transforma el vector store en un componente de alto nivel que encapsula la lógica de búsqueda y lo hace directamente integrable en pipelines de RAG. En lugar de llamar manualmente a métodos como similarity_search, el retriever actúa como una interfaz estándar que recibe una query y devuelve los documentos relevantes, desacoplando la capa de almacenamiento de la lógica del sistema.
Este patrón es clave en LangChain, ya que permite componer fácilmente pipelines donde el retrieval se integra como una pieza más dentro del flujo de datos hacia el LLM.
| Método | Descripción |
|---|---|
as_retriever | Convierte el vector store en un retriever configurable para pipelines RAG. |
Ejemplo básico
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 3}
)
docs = retriever.invoke("What is a text splitter?")
Qué está haciendo internamente el retriever: (Es un wrapper sobre similarity_search.)
- Recibe la query
- La convierte en embedding
- Ejecuta búsqueda en el vector store
- Devuelve los documentos más relevantes
Insight estructural
Aunque la interfaz de VectorStore en LangChain puede parecer extensa, en la práctica se reduce a tres operaciones fundamentales que reflejan el ciclo de vida del dato en un sistema RAG.
Write (indexing)
Corresponde a la fase de ingesta, donde los datos se transforman en embeddings y se insertan en el índice vectorial. Se ejecuta normalmente en batch durante el indexing offline.
add_*→ inserción incrementalfrom_*→ construcción inicial del índice
Read (retrieval)
Es la fase de consulta, donde se recupera información relevante a partir de una query. Es el núcleo del sistema RAG.
similarity_*→ búsqueda por similitudmmr_*→ búsqueda con diversidadsearch→ interfaz general
Manage (mantenimiento)
Permite modificar o inspeccionar el índice. Es clave para actualización, limpieza y debugging.
delete→ eliminación de vectoresget_by_ids→ acceso directo por ID