¿Cómo aprenden las máquinas? Una Guía Introductoria al Machine Learning y Deep Learning
En la era digital, escuchamos los términos Inteligencia Artificial, Machine Learning y Deep Learning casi a diario. Sin embargo, ¿sabemos realmente qué significan y cómo se diferencian?
A menudo se piensa en la informática como un conjunto de reglas estrictas escritas por humanos. Pero existe una rama tecnológica que rompe con este esquema: las máquinas que aprenden a partir de la experiencia. A continuación, desglosaremos los conceptos fundamentales para entender esta revolución tecnológica, que muchos ya consideran “la nueva electricidad”.
¿Qué es el Machine Learning (Aprendizaje Automático)?
El Machine Learning (ML) es un subconjunto de la Inteligencia Artificial centrado en el estudio y la construcción de programas que no son programados explícitamente. En lugar de seguir instrucciones fijas, estos algoritmos descubren patrones ocultos a medida que se les expone a una mayor cantidad de datos a lo largo del tiempo.
La regla de oro del ML: A mayor volumen de datos de calidad, mejor será la capacidad del algoritmo para entender los patrones subyacentes.
Sin embargo, es importante destacar que el rendimiento de estos algoritmos tradicionales tiene un límite: llega un punto en el que el aprendizaje se estanca (efecto de rendimiento decreciente), independientemente de cuántos datos nuevos agreguemos.
Los Componentes del Aprendizaje: Características frente a Objetivo
Para entender cómo una máquina procesa la información, debemos desglosar un conjunto de datos en sus dos elementos fundamentales. Tomemos como ejemplo el famoso Iris Dataset, un conjunto de datos clásico en el mundo académico que registra las medidas de tres especies de flores (Virginica, Setosa y Versicolor):
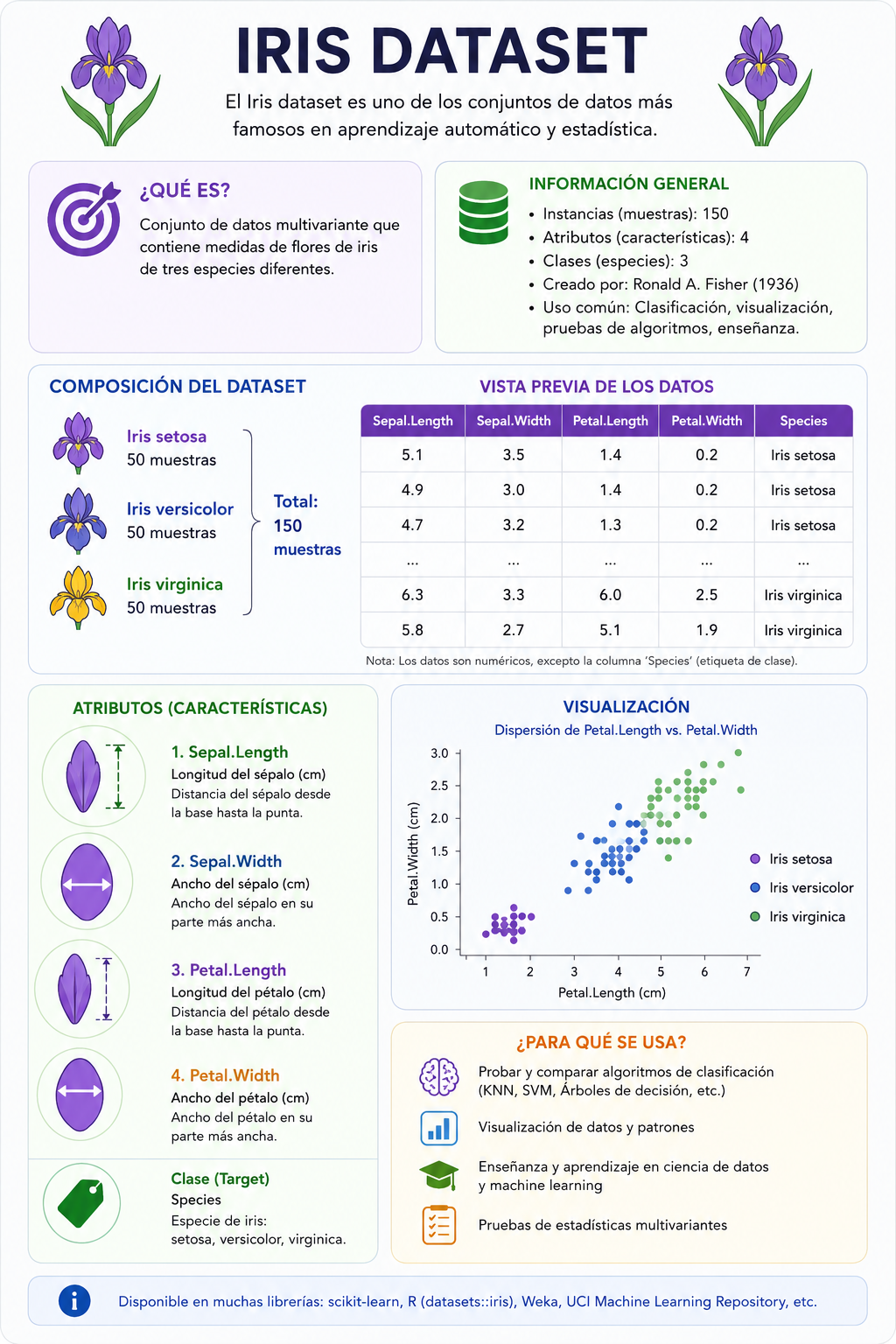
- Características (Features): Son las variables independientes, es decir, las propiedades observables que introducimos en el algoritmo. En el caso de las flores, las características son cuatro de sus medidas físicas: la longitud del sépalo, el ancho del sépalo, la longitud del pétalo y el ancho del pétalo.
- Variable Objetivo (Target): Es la columna o etiqueta final que el programa intenta predecir de forma automática. En este ejemplo, el objetivo es determinar con precisión la especie de la flor.
El flujo de producción: El algoritmo se entrena cruzando las features con sus respectivos targets. Una vez que el modelo ha aprendido la relación matemática entre ambos componentes, se puede poner en producción. A partir de ese momento, si le entregamos únicamente las cuatro características de una nueva flor, la máquina será capaz de adivinar la especie correcta sin necesidad de que un humano la etiquete.
Los Dos Grandes Pilares: Aprendizaje Supervisado vs. No Supervisado
Dependiendo de los datos que tengamos y del objetivo que busquemos, el Machine Learning se divide principalmente en dos metodologías:
| Criterio | Aprendizaje Supervisado | Aprendizaje No Supervisado |
| ¿Tiene etiquetas / Target? | Sí. Los datos están preclasificados. | No. Solo se dispone de los datos brutos. |
| Meta principal | Predecir el objetivo o etiqueta para nuevos datos. | Encontrar una estructura o relación oculta en los datos. |
| Ejemplo práctico | Detección de fraude: Analizar si una transacción con tarjeta es “fraude” o “no fraude” basándose en el historial. | Segmentación de clientes: Agrupar usuarios de un e-commerce por comportamientos similares para campañas de marketing. |
| Evaluación | Existe una respuesta correcta o incorrecta bien definida. | No hay una respuesta “correcta” única; se deben evaluar diferentes modelos. |
El Desafío de los Datos Complejos y el Nacimiento del Deep Learning
El Machine Learning tradicional es extraordinario trabajando con datos estructurados (tablas, números, categorías). Por ejemplo, para predecir si un correo es spam, o si una transacción es fraudulenta, podemos definir características claras como la hora, el monto o la ubicación.
Sin embargo, ¿qué pasa cuando intentamos que una máquina identifique si una imagen contiene un gato o un perro?
Para una computadora, una imagen es una rejilla de miles de píxeles (una pequeña foto de 256 x 256 píxeles se traduce en más de 65.000 características). Si analizamos cada píxel de forma aislada, perdemos la relación espacial (cómo se conecta un píxel con el de al lado para formar un ojo o una nariz).
Para solucionar esta limitación del ML tradicional, nació el Deep Learning (Aprendizaje Profundo).
Deep Learning: Redes Neuronales y Autoaprendizaje
El Deep Learning (DL) es, a su vez, un subconjunto del Machine Learning que utiliza modelos matemáticos altamente complejos llamados redes neuronales profundas.
La diferencia radical entre ambos enfoques radica en el procesamiento de las características:
- En el Machine Learning clásico: Un ingeniero o científico de datos humano debe identificar y extraer manualmente las características relevantes antes de entrenar al modelo.
- En el Deep Learning: El proceso es directo. Se introducen los píxeles brutos de la imagen en la red neuronal, y es el propio modelo el que aprende a extraer y combinar las características en capas intermedias.
Aunque los pasos intermedios de una red neuronal profunda no siempre son fáciles de interpretar por los humanos, el modelo es capaz de detectar primero bordes, luego combinar esos bordes para formar figuras (ojos, labios, formas) y finalmente realizar predicciones asombrosamente precisas (como reconocer el rostro de una persona específica).

Las Dos Grandes Metodologías: Aprendizaje Supervisado y No Supervisado
No todos los problemas de datos se estructuran de la misma manera ni persiguen los mismos objetivos. Por ello, el Machine Learning se divide principalmente en dos ramas bien definidas:
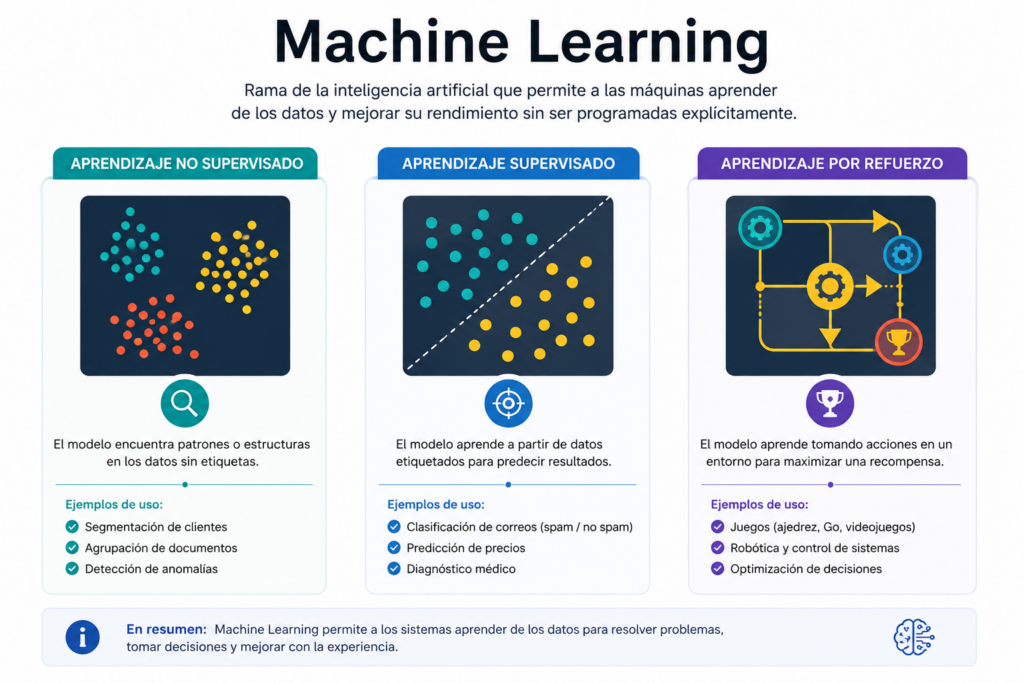
Aprendizaje Supervisado (Supervised Learning)
En esta modalidad, el algoritmo trabaja con un conjunto de datos completamente etiquetado. Esto significa que cada registro de entrenamiento incluye tanto las características como la respuesta correcta (el target).
- El Objetivo: Aprender a mapear las entradas con las salidas para predecir la etiqueta de datos futuros y desconocidos.
- Ejemplo 1 (Filtro de Spam): El sistema analiza miles de correos preclasificados por humanos como “Spam” o “No Spam”. Al procesar este histórico, el algoritmo detecta qué palabras o patrones se repiten en el correo basura y aprende a aislarlo en la bandeja de entrada real.
- Ejemplo 2 (Detección de Fraude Financiero): Una entidad bancaria recopila un gran volumen de transacciones financieras etiquetadas previamente como “legítimas” o “fraudulentas”. El modelo estudia las variables asociadas a cada caso y automatiza las alertas en tiempo real.
Aprendizaje No Supervisado (Unsupervised Learning)
A diferencia del anterior, aquí nos enfrentamos a bases de datos que no contienen etiquetas ni una variable objetivo. La máquina se encuentra completamente sola ante los datos brutos.
- El objetivo: encontrar una estructura interna, relaciones ocultas o agrupaciones naturales dentro del conjunto de información.
- Ejemplo (Segmentación de Clientes): En una plataforma de comercio electrónico (e-commerce), se introducen los datos de comportamiento de compra de los usuarios. Sin decirle al programa qué buscar, el algoritmo encuentra patrones comunes y los divide en grupos con perfiles similares (por ejemplo: “compradores impulsivos de fin de semana” o “buscadores de ofertas tecnológicas”). Esto permite al equipo de marketing diseñar campañas personalizadas para cada segmento.
Nota metodológica: En el Aprendizaje No Supervisado no existe una respuesta correcta o incorrecta predefinida por un humano. El científico de datos debe probar diferentes modelos matemáticos y evaluar qué agrupaciones tienen más coherencia y valor estratégico para el problema de negocio.
Datos Estructurados: El Terreno Ideal del Machine Learning Tradicional
Para cerrar esta introducción, es vital comprender qué tipo de problemas se resuelven mejor con estas técnicas clásicas. Pensemos nuevamente en el caso de la detección de fraudes con tarjetas de crédito.
Si queremos identificar una transacción sospechosa, las características idóneas a combinar son muy claras y específicas:
- La hora exacta de la transacción.
- El monto económico cobrado.
- La ubicación geográfica del comercio.
- La categoría de la compra (tecnología, alimentación, viajes, etc.).
Toda esta información se organiza de forma perfecta en tablas de filas y columnas. Este tipo de datos estructurados con características altamente intuitivas representa el escenario ideal donde los algoritmos tradicionales de Machine Learning ofrecen un rendimiento excepcional, rápido y sumamente preciso.
Aquí tienes la continuación y el cierre de esta sección del artículo, totalmente integrada y redactada con un estilo educativo y profesional:
El Límite de los Datos Estructurados: El Desafío de las Imágenes
Como hemos visto, el Machine Learning tradicional brilla cuando trabaja con datos tabulares organizados. Sin embargo, el panorama cambia drásticamente cuando intentamos resolver problemas con datos no estructurados, como las imágenes.
Imaginemos que queremos entrenar un modelo tradicional para determinar si una imagen muestra un gato o un perro. ¿Qué características (features) deberíamos extraer de forma manual?
Para una computadora, una imagen no es más que una matriz de datos numéricos que representan el color de cada píxel individual. Si intentamos usar cada píxel como una característica aislada, nos topamos inmediatamente con dos grandes obstáculos teóricos y prácticos:
- La explosión de dimensiones: Incluso una imagen digital pequeña, de apenas $256 \times 256$ píxeles, se traduce en más de 65,000 píxeles. Esto significa obligar al algoritmo tradicional a trabajar con más de 65,000 características simultáneamente, un volumen masivo y poco eficiente para sus ecuaciones matemáticas.
- La pérdida de la relación espacial: Si analizamos cada píxel como una variable independiente, el sistema pierde por completo el contexto de lo que hay a su alrededor. La información de un píxel solo cobra verdadero sentido en relación con sus píxeles vecinos. Son las agrupaciones de píxeles contiguos las que forman de manera conjunta una estructura reconocible, como la nariz, los ojos o la silueta de un animal.
Este callejón sin salida técnico marcó durante años las limitaciones del Machine Learning clásico, abriendo paso a una de las mayores revoluciones de la informática moderna: el Deep Learning.
Deep Learning y Redes Neuronales Profundas
El Deep Learning (Aprendizaje Profundo) es un subcampo especializado dentro del Machine Learning que aborda la complejidad mediante el uso de modelos matemáticos avanzados conocidos como redes neuronales profundas.

Su gran ventaja competitiva radica en que los ingenieros ya no necesitan definir e identificar las características de forma manual. En su lugar, el propio modelo recibe los píxeles brutos de la imagen y posee la capacidad única de aprender, extraer y combinar esas características de forma completamente autónoma, estructurando internamente las relaciones espaciales de los datos.
¿Cómo se diferencian en la práctica? Un caso de estudio
Para entender la diferencia radical en el flujo de trabajo, analicemos cómo identificarían ambos enfoques el rostro de una persona específica (por ejemplo, “Arjun”):
- En el Machine Learning Clásico: El científico de datos debe definir a priori las características matemáticas que componen un rostro (la distancia entre los ojos, la forma de la nariz, el contorno de los labios). Si el profesional tiene éxito en su estimación manual, introduce estas propiedades seleccionadas en el algoritmo para que intente predecir la identidad. Diseñar buenas características mediante este método es una tarea titánica y sumamente compleja de realizar con precisión.
- En el Deep Learning: El proceso se unifica en un único flujo de trabajo. La red neuronal recibe directamente los píxeles brutos de la fotografía. A través de sus múltiples capas intermedias (u ocultas), el modelo realiza una ingeniería de características automatizada. En las primeras capas suele identificar elementos simples como bordes y líneas; posteriormente, las capas más profundas combinan esos bordes para reconocer formas complejas (ojos, labios, orejas) hasta procesar el rostro completo y predecir de forma exacta que se trata de Arjun.
Aunque el procesamiento matemático en estas capas intermedias a menudo resulta difícil de interpretar por los seres humanos (un fenómeno conocido como “caja negra”), su utilidad práctica para resolver tareas complejas de visión artificial y clasificación de imágenes ha superado con creces cualquier tecnología previa.
Criterios de Elección: ¿Cuándo usar cada tecnología?
A pesar del enorme impacto del Deep Learning en la investigación científica de vanguardia, es fundamental desmitificar la idea de que siempre es la mejor opción. La elección de la herramienta depende estrictamente de la naturaleza del problema y de los recursos disponibles:
- El poder del Machine Learning tradicional: Sigue siendo el rey indiscutible cuando se trabaja con conjuntos de datos pequeños o cuando la información cambia y se actualiza de manera constante en el tiempo sin un patrón fijo. En estos escenarios, los algoritmos tradicionales ofrecen un rendimiento significativamente superior, son más rápidos de entrenar y requieren una fracción del coste computacional.
- El momento del Deep Learning: Se vuelve indispensable cuando nos enfrentamos a grandes volúmenes de datos masivos (Big Data) y a formatos no estructurados (imágenes, audio, vídeo o texto libre), donde el rendimiento del Machine Learning tradicional tiende a estancarse.
Comprender esta frontera técnica nos permite apreciar cómo la Inteligencia Artificial ha evolucionado desde sus fundamentos teóricos primitivos hasta convertirse en lo que muchos expertos ya catalogan como “la nueva electricidad” de nuestra sociedad.
Aquí tienes la continuación del artículo, correspondiente a la sección final del módulo donde se introducen los fundamentos técnicos, las herramientas y el ciclo de trabajo que preparan al lector para la fase práctica de la ciencia de datos.
Fundamentos del Aprendizaje Automático: Vocabulario, Herramientas y Ciclo de Trabajo
Para cerrar esta introducción general y prepararnos con éxito de cara a las fases de Análisis Exploratorio de Datos (EDA), limpieza de información e inferencia estadística, es fundamental asentar las bases metodológicas. Todo profesional del Machine Learning debe dominar un conjunto de herramientas técnicas, un flujo de trabajo ordenado y un vocabulario preciso que evite interpretaciones erróneas de los modelos en producción.
Requisitos Técnicos y de Criterio Científico
Antes de pulsar la primera línea de código, el desarrollo de modelos requiere dos pilares conceptuales que no se pueden ignorar:
- Bases Matemáticas Fuertes: Es un error muy común saltarse los fundamentos de la estadística básica (probabilidad, cálculo de momentos, regla de Bayes) y del álgebra lineal. Sin esta base, se corre el riesgo de configurar mal los parámetros y malinterpretar por completo las métricas de rendimiento de los algoritmos.
- El Ecosistema Python: En la práctica, el entorno estándar de trabajo se compone de Jupyter Notebooks (o entornos iPython) respaldados por librerías maduras y especializadas:
| Librería | Propósito Principal en el Flujo de Trabajo |
| NumPy | Operaciones matemáticas complejas y análisis numérico de matrices. |
| Pandas | Manipulación de datos mediante estructuras llamadas DataFrames (tablas). |
| Matplotlib / Seaborn | Creación de gráficos y visualización de distribuciones de datos. |
| Scikit-Learn | Implementación de algoritmos tradicionales de Machine Learning. |
| TensorFlow / Keras | Construcción y entrenamiento de Redes Neuronales Profundas (Deep Learning). |
El Flujo de Trabajo Típico en Machine Learning (Workflow)
Construir un modelo predictivo no consiste simplemente en alimentar un algoritmo con datos aleatorios. Se trata de un proceso estructurado en 6 etapas secuenciales:
- Definición del Problema (Problem Statement): Determinar con exactitud qué meta se quiere alcanzar. Por ejemplo: “Queremos un sistema capaz de clasificar diferentes razas de perros a partir de fotografías”.
- Recolección de Datos (Data Collection): Reunir la información necesaria. Siguiendo el ejemplo anterior, no bastará con una sola imagen por raza; se requerirán miles de fotografías etiquetadas, tomadas desde diferentes ángulos y bajo distintas condiciones de luz.
- Exploración y Preprocesamiento (Exploratory Data Analysis & Preprocessing): Limpiar los datos para que el modelo pueda interpretarlos de forma óptima. Aquí se analizan mapas de calor de densidad de píxeles, se evalúa la distribución de las muestras y se transforman las variables en arrays multidimensionales normalizados.
- Modelado (Modeling): Entrenar los algoritmos. Normalmente se empieza construyendo un modelo base muy sencillo (baseline) para establecer un estándar mínimo de comparación antes de probar arquitecturas más complejas.
- Validación (Validation): Evaluar si el modelo realmente resuelve el problema. Para ello se utiliza un conjunto de datos de prueba retenido o apartado (holdout set). Se trata de datos e imágenes que el modelo nunca vio durante el entrenamiento, lo que permite verificar su porcentaje real de precisión en el mundo real.
- Toma de Decisiones y Despliegue (Deployment): Una vez que el modelo alcanza los rangos de precisión exigidos por el negocio, se comunican los resultados a las partes interesadas (stakeholders) y se traslada el código a un entorno de producción para que empiece a operar en tiempo real.
Diccionario Esencial para Científicos de Datos
Para comprender la estructura de cualquier conjunto de datos, resulta muy útil imaginar la información en el formato visual de una hoja de cálculo. Tomando de nuevo como referencia el histórico de las especies de flores Iris, definimos los cuatro términos clave:
- Variable Objetivo (Target Variable): Es la columna o propiedad específica que deseamos predecir de cara al futuro. En nuestra hoja de cálculo, la columna objetivo es
Species. - Características (Features / Explanatory Variables): Son el resto de las columnas de la tabla. Representan las variables independientes que el algoritmo analiza para buscar patrones y deducir el objetivo. En este conjunto de datos contamos con 4 características:
sepal length,sepal width,petal lengthypetal width. Cuando el modelo trabaje en producción con datos nuevos, solo dispondrá de estas columnas. - Observación o Ejemplo (Observation / Example): Se refiere a una fila completa dentro de la base de datos. Cada fila representa un caso de estudio individual con todas sus características y su correspondiente resolución, y sirve para que el modelo ajuste matemáticamente sus parámetros de aprendizaje.
- Etiqueta (Label): Es el valor concreto que toma la variable objetivo dentro de una observación específica. Mientras que la columna completa es el target, el dato puntual de una sola fila (por ejemplo, el valor escrito de
versicolorosetosa) es la etiqueta.