¿Qué es una Metodología en Ciencia de Datos?
Una metodología es un sistema de métodos y directrices que guía las decisiones del investigador a lo largo de todo el proceso científico. En nuestro campo, constituye un marco de trabajo estructurado que orienta a los científicos de datos y a los ingenieros de Machine Learning en la resolución de problemas complejos y en la toma de decisiones informadas.
Definición Clave: Una metodología robusta no se limita al modelado algorítmico. Abarca el diseño de formularios de recolección de datos, el establecimiento de estrategias de medición y la comparación crítica de métodos analíticos en función de los objetivos específicos del negocio y el contexto del proyecto.
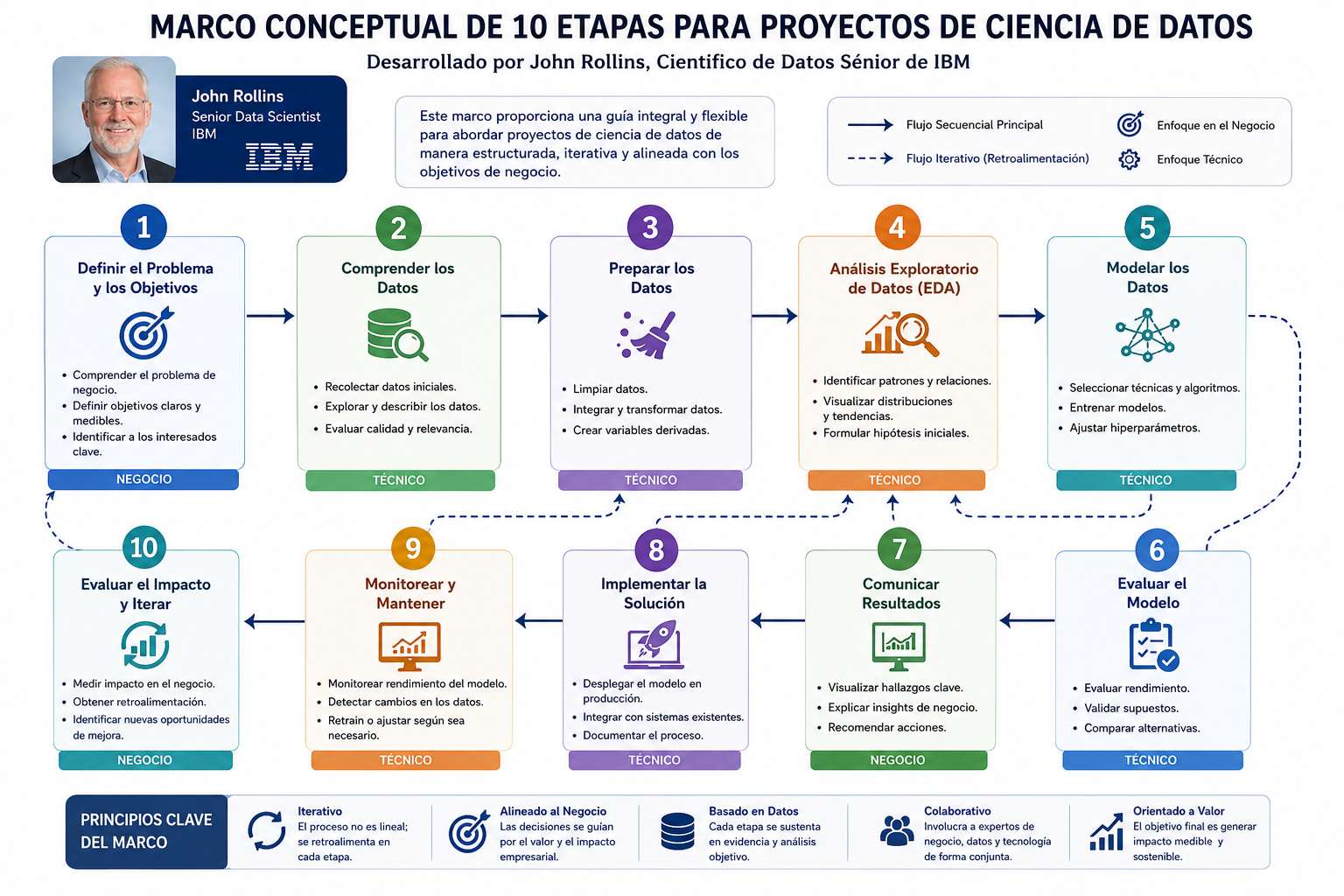
Las 10 Etapas de la Metodología de John Rollins
Un estándar ampliamente adoptado en la industria es el marco conceptual desarrollado por John Rollins, científico de datos sénior de IBM, cuya experiencia profesional consolidó una estructura de 10 etapas secuenciales e iterativas:
- Business Understanding (Comprensión del negocio)
- Analytic Approach (Enfoque analítico)
- Data Requirements (Requisitos de datos)
- Data Collection (Recolección de datos)
- Data Understanding (Comprensión de los datos)
- Data Preparation (Preparación de los datos)
- Modeling (Modelado)
- Evaluation (Evaluación)
- Deployment (Despliegue)
- Feedback (Retroalimentación)
El Poder de Hacer las Preguntas Correctas
Las preguntas son la piedra angular de cualquier proyecto de datos y el motor que impulsa cada una de las 10 etapas descritas. Para garantizar la viabilidad y el rigor de un diseño analítico, la metodología nos obliga a responder a diez preguntas esenciales, agrupadas en tres bloques críticos de ejecución:
| Bloque Temático | Etapa Metodológica | Pregunta Clave a Responder |
| Definición y Enfoque | 1. Business Understanding | ¿Cuál es el problema específico que se intenta resolver? |
| 2. Analytic Approach | ¿Cómo se pueden utilizar los datos para responder a dicha pregunta? | |
| Organización de Datos | 3. Data Requirements | ¿Qué datos se necesitan para responder a la pregunta? |
| 4. Data Collection | ¿De dónde provienen y cómo se recibirán las fuentes de datos? | |
| 5. Data Understanding | ¿Los datos recolectados representan fielmente el problema a resolver? | |
| 6. Data Preparation | ¿Qué manipulación y preprocesamiento adicional requieren los datos? | |
| Validación y Diseño Final | 7. Modeling | Al aplicar visualizaciones de datos, ¿se observan patrones que atiendan el problema? |
| 8. Evaluation | ¿El modelo responde a la pregunta de negocio original o se deben ajustar los datos? | |
| 9. Deployment | ¿Cómo se puede poner en práctica y producción el modelo desarrollado? | |
| 10. Feedback | ¿Cómo se obtendrá retroalimentación de los interesados y del modelo para mejorar el proceso? |
Al implementar de manera sistemática este checklist analítico, los equipos de Data Science no solo optimizan el tiempo de desarrollo y la eficiencia de la investigación científica, sino que aseguran una alineación perfecta entre el desarrollo técnico de Machine Learning y los objetivos estratégicos de la organización.
En el entorno corporativo e industrial, el éxito de un proyecto de Inteligencia Artificial o Ciencia de Datos no radica únicamente en la sofisticación de los algoritmos utilizados, sino en la rigurosidad del proceso metodológico seguido. Dos de las fases más críticas en metodologías estándar de la industria (como CRISP-DM) son el establecimiento de una sólida Comprensión del Negocio (Business Understanding) y la correcta selección del Enfoque Analítico (Analytic Approach).
1. Comprensión del Negocio (Business Understanding)
El punto de partida de cualquier metodología de ciencia de datos seria consiste en dedicar el tiempo necesario a buscar aclaraciones y alinear expectativas. Avanzar a ciegas bajo la presión de plazos ajustados sin definir el problema real suele derivar en soluciones técnicamente válidas pero comercialmente inútiles.
Establecer Objetivos y Metas Claros
El proceso comienza por descifrar el propósito de quien formula la pregunta de negocio. Por ejemplo, ante una solicitud común como “¿Cómo podemos reducir los costos de una actividad?”, el científico de datos debe profundizar en si el fin último es mejorar la eficiencia operativa o potenciar la rentabilidad general de la empresa.
- Identificación de Requisitos: Consiste en desglosar las metas generales en objetivos específicos medibles.
- Priorización Estratégica: Organizar las discusiones estructuradas con los stakeholders clave permite identificar qué subproblemas abordar primero en función de su viabilidad e impacto.
Caso de Estudio: Reducción de Readmisiones Hospitalarias
Para ilustrar la importancia de esta fase, analicemos el caso de una aseguradora de salud que enfrentaba una reducción en el financiamiento público para readmisiones, lo que amenazaba con elevar las primas de sus clientes.
Antes de recolectar un solo dato, el equipo (en colaboración con autoridades sanitarias y científicos de datos) definió los objetivos del proyecto. Al analizar el contexto, identificaron que el 30% de los pacientes que terminaban rehabilitación volvían a ser ingresados en un año, y el 50% en un plazo de cinco años. Tras revisar los registros, se priorizó a los pacientes con Insuficiencia Cardíaca Congestiva (CHF), situados en la cima de la lista de readmisiones.
Formulación y Pertinencia de Preguntas
Una vez que se comprende el negocio, el científico de datos debe formular preguntas analíticas pertinentes. No todos los datos disponibles o preguntas que surgen en una organización aportan valor a la meta trazada.
Ejemplo en Estrategia de Precios de Comercio Electrónico
Si el objetivo principal de un e-commerce es optimizar su estrategia de precios para maximizar ingresos y rentabilidad, la clasificación de preguntas se divide de la siguiente manera:
| Preguntas Altamente Relevantes | Preguntas No Relevantes para el Objetivo |
| ¿Cómo varían los comportamientos de compra de los clientes durante períodos promocionales específicos? | ¿Cuántos empleados trabajan en el departamento de marketing? |
| ¿Cuáles son los márgenes de ganancia de los diferentes productos? | ¿Cuál es la estructura organizacional de la empresa? |
| ¿De qué manera influyen las opiniones y calificaciones de los productos en las decisiones de compra? | ¿Cuánto gasta la empresa en suministros de oficina? |
| ¿Cómo influyen los datos demográficos de los clientes en su sensibilidad al precio? | — |
2. El Enfoque Analítico (Analytic Approach)
Una vez consolidada la pregunta de investigación, se procede a seleccionar el Enfoque Analítico adecuado. Esto significa identificar qué tipo de patrones de datos se requieren extraer para responder a la interrogante de la manera más efectiva posible.
Tomando como base las necesidades de optimización de una empresa de transporte y logística, los enfoques se categorizan en cuatro grandes modelos de patrones de datos:
Modelo Predictivo (Predictive Model)
Se utiliza cuando la pregunta requiere determinar las probabilidades de una acción futura basándose en datos históricos.
- Preguntas tipo: ¿Cómo podemos pronosticar el número óptimo de vehículos de entrega necesarios para un día específico según el volumen de pedidos esperado? o ¿Cuál es el tiempo estimado de entrega considerando patrones de tráfico y condiciones climáticas?
Modelo Descriptivo (Descriptive Model)
Se aplica cuando el objetivo es mostrar relaciones, resumir comportamientos existentes o identificar tendencias históricas sin realizar predicciones directas.
- Preguntas tipo: ¿Cuáles son los costos promedio de envío para diferentes rutas y cómo varían según la hora del día? o ¿Cuáles son los intervalos de tiempo y los días de mayor actividad semanal basándose en pedidos pasados?
Modelo de Clasificación (Classification Model)
Adecuado para problemas que requieren categorizar elementos o donde la respuesta analítica es de naturaleza categórica (por ejemplo, respuestas de tipo Sí/No).
- Preguntas tipo: ¿Cómo podemos clasificar las rutas de entrega en diferentes categorías según el volumen de pedidos y la duración promedio? o ¿En qué franjas horarias específicas se deben segmentar los cronogramas para equilibrar la carga laboral?
Agrupamiento (Clustering / Grouping-based)
Un enfoque de Machine Learning no supervisado utilizado para descubrir la estructura intrínseca de los datos y conocer el comportamiento de entidades sin realizar predicciones explícitas de eventos pasados.
- Preguntas tipo: ¿Cómo podemos agrupar las regiones de entrega en función de la densidad de clientes y la frecuencia de pedidos para optimizar la planificación de rutas?
Aplicación Técnica del Enfoque: El Modelo de Árbol de Decisión
Retomando el caso de estudio de readmisiones por Insuficiencia Cardíaca Congestiva (CHF), los científicos de datos seleccionaron un Modelo de Clasificación basado en Árboles de Decisión. Esta elección técnica se fundamenta directamente en los requisitos de negocio previamente establecidos:
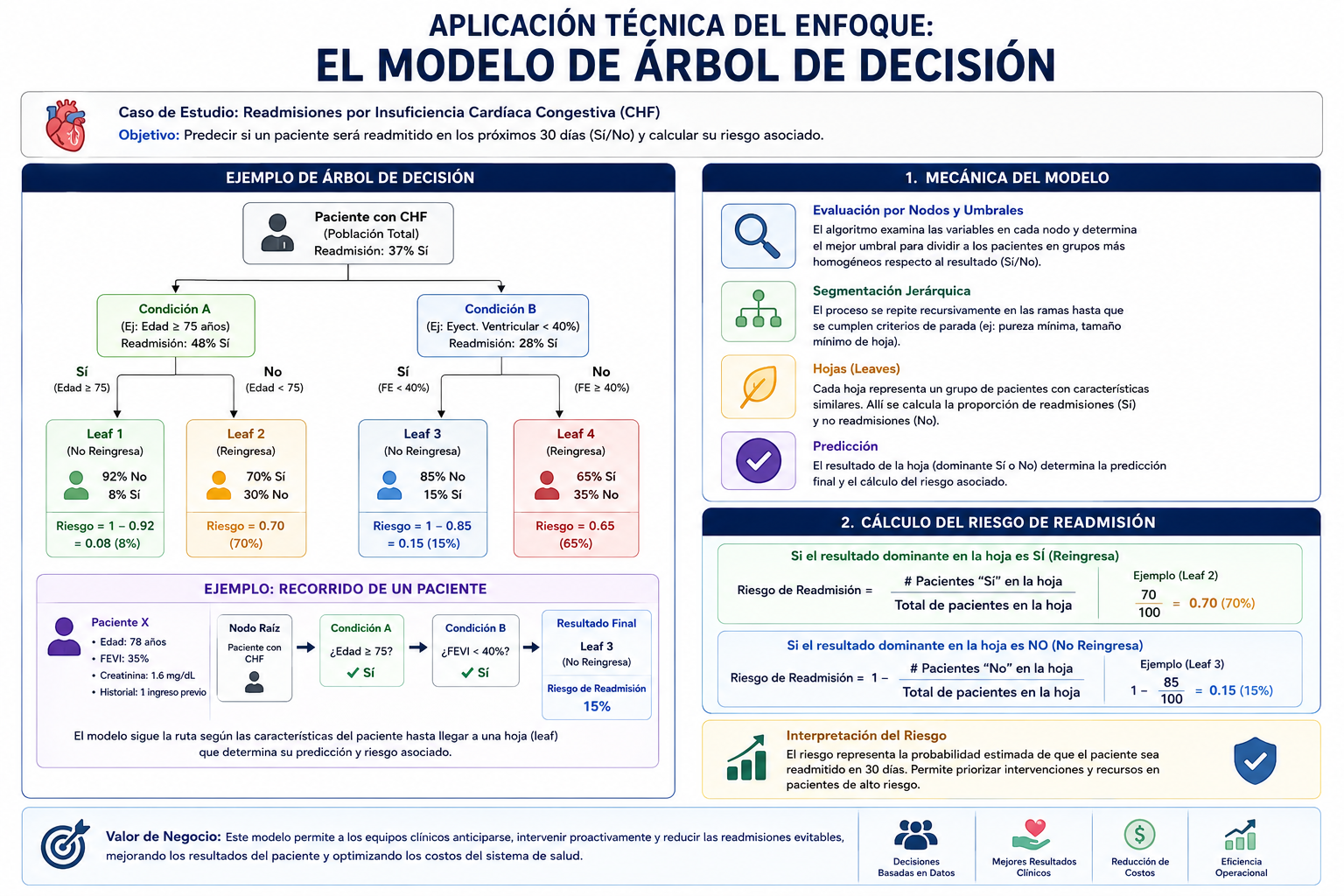
Mecánica del Modelo y Toma de Decisiones
- Evaluación por Nodos y Umbrales: El algoritmo examina las variables en cada uno de los nodos a lo largo de las rutas hasta llegar a una “hoja” (leaf), determinando valores umbral específicos para segmentar a los pacientes.
- Cálculo del Riesgo de Readmisión: El modelo proporciona el resultado condicional (Sí/No reingresa) y la probabilidad del mismo basándose en la proporción del resultado dominante en cada grupo:
- Si el resultado dominante en la hoja es Sí, el riesgo equivale directamente a la proporción de pacientes “Sí” en esa hoja.
- Si el resultado dominante es No, el riesgo se calcula matemáticamente como $1 – \text{proporción de pacientes No en la hoja}$.
Ventajas de cara al Negocio y la Práctica Clínica
La elección de este enfoque analítico específico responde a una justificación metodológica clave: la interpretabilidad. Un modelo de árbol de clasificación es altamente intuitivo para profesionales que no pertenecen al ámbito de los datos (como los médicos y gestores clínicos). Los médicos pueden observar con precisión qué combinaciones de condiciones biológicas o de tratamiento provocan que un paciente sea catalogado como de “alto riesgo”.
3. La Fase de Requisitos (Data Requirements)
Una vez que se ha definido el problema de negocio y se ha seleccionado el enfoque analítico pertinente, el científico de datos entra en una de las fases más operativas e interconectadas del ciclo de vida del proyecto: la determinación de los requisitos de datos.
Para entender esta etapa, resulta útil recurrir a una analogía gastronómica : si el problema que queremos resolver equivale a la receta culinaria, los datos son los ingredientes indispensables para elaborarla. Si el objetivo es preparar una cena de espaguetis pero no se cuenta con los componentes adecuados, el éxito del plato se verá comprometido. Bajo este principio de “cocinar con datos”, el equipo técnico debe identificar con precisión qué ingredientes se necesitan, cómo recolectarlos, cómo interpretarlos y de qué manera prepararlos para alcanzar el resultado esperado.
Definición de Requisitos Analíticos
Antes de proceder a la recolección o manipulación directa de la información, es vital delimitar los requisitos analíticos específicos que exige la técnica de modelado elegida. Esto implica determinar de forma explícita:
- El contenido: Qué sustancia o variables debe albergar la información.
- El formato: La estructura técnica en la que deben presentarse los datos.
- Las fuentes: Los orígenes y sistemas de donde se extraerá la información inicial.
La Importancia de la Prospección: Un buen científico de datos debe pensar a futuro. Definir correctamente los requisitos en esta fase previene errores costosos y facilita las fases posteriores de preparación y modelado de datos.
Caso de Estudio: Clasificación con Árboles de Decisión en el Sector Salud
Para ilustrar cómo se aplican los requisitos de datos en un entorno real, analicemos el diseño metodológico implementado para un modelo de clasificación basado en árboles de decisión dentro del sector de los seguros médicos, cuyo objetivo era modelar y predecir la tasa de readmisión de pacientes.
Selección y Criterios de Inclusión de la Cohorte
El primer paso consistió en acotar el universo de datos seleccionando una cohorte de pacientes adecuada a partir de la base de miembros de la aseguradora. Para garantizar que se pudiera consolidar un historial clínico completo, se definieron tres criterios de inclusión estrictos:
- Área de Cobertura: El paciente debía haber sido ingresado como paciente interno dentro del área de servicio del proveedor para asegurar el acceso a toda la información médica relevante.
- Diagnóstico Principal: Se acotó la búsqueda exclusivamente a pacientes con un diagnóstico primario de insuficiencia cardíaca congestiva durante el periodo de un año completo.
- Permanencia Mínima: El paciente debía registrar una inscripción continua de al menos seis meses previa a su admisión hospitalaria por insuficiencia cardíaca, permitiendo así compilar un antecedente médico fidedigno.
Criterios de Exclusión Estratégica
Con el fin de no sesgar los resultados del modelo, se excluyó deliberadamente de la cohorte a aquellos pacientes con insuficiencia cardíaca que además presentaran otras condiciones médicas preexistentes de alta gravedad. Estas comorbilidades suelen provocar tasas de readmisión inusualmente elevadas que no se corresponden con el comportamiento estándar del problema principal, lo que alteraría el rendimiento del algoritmo.
Formato y Estructura Técnica del Modelo
El algoritmo de árboles de decisión impone restricciones muy claras en cuanto a la estructura de la matriz de entrada. Requiere estrictamente un único registro por paciente, donde las columnas representen de forma tabular las variables que evaluará el modelo.
Sin embargo, la realidad de los datos clínicos de un solo individuo es transaccional y masiva, abarcando:
- Historiales de admisiones y altas hospitalarias.
- Diagnósticos primarios, secundarios y terciarios.
- Procedimientos médicos realizados.
- Prescripciones farmacológicas y recetas emitidas.
- Servicios derivados de consultas externas e interconsultas.
Debido a esta naturaleza médica, un único paciente puede acumular miles de registros transaccionales en los sistemas de salud. Para transformar esta estructura masiva y profunda al formato plano exigido por el modelo (un registro por fila), los científicos de datos planificaron la agregación o “roll-up” de dichos datos transaccionales al nivel de paciente, lo que conlleva la creación de nuevas variables sintéticas que resuman el comportamiento histórico del individuo.
Aunque la ejecución de esta transformación corresponde propiamente a la fase de Preparación de Datos, anticipar y mapear esta necesidad desde la etapa de Requisitos de Datos es lo que garantiza la viabilidad técnica de todo el proyecto de Machine Learning.
4. La Fase de Recolección (Data Collection)
Tras definir las especificaciones técnicas en la etapa de requisitos, la metodología avanza hacia un paso intensamente práctico y operativo: la Recolección de Datos. Esta fase no se limita a un mero proceso de descarga o acumulación de archivos; representa un punto de control crítico donde el científico de datos evalúa de manera empírica la viabilidad técnica del diseño inicial.
Siguiendo con nuestra analogía culinaria, si en la etapa anterior elaboramos la lista de compras, en esta fase acudimos al mercado a buscar los ingredientes. Es común descubrir que algunos de ellos están fuera de temporada, son difíciles de conseguir o implican un coste computacional y operativo mayor de lo previsto. Ante esta realidad, el equipo se ve obligado a revisar los requisitos teóricos y tomar decisiones estratégicas sobre si es necesario recolectar un volumen mayor o menor de información.
Al finalizar la recolección, los “ingredientes” se encuentran listos sobre la mesa de trabajo. En este punto, el profesional obtiene una perspectiva clara del material real con el que construirá la solución.
Evaluación Inicial y Detección de Gaps
Una vez completada la carga inicial, el científico de datos debe aplicar técnicas analíticas preliminares para auditar el set de datos:
- Estadística Descriptiva: Permite evaluar el contenido general, las distribuciones de las variables y la calidad superficial de la información.
- Visualización de Datos: Ayuda a identificar anomalías visuales directas y a extraer los primeros insights o intuiciones sobre el comportamiento de las variables.
- Identificación de Brechas (Gaps): El objetivo principal de esta auditoría es descubrir vacíos en la información. Cuando se detectan datos faltantes, el equipo debe trazar planes específicos para rellenar esos vacíos o, en su defecto, buscar variables sustitutas adecuadas.
Caso de Estudio: Desafíos de Integración en el Sector Salud
Retomando el modelo de clasificación para predecir la readmisión de pacientes con insuficiencia cardíaca congestiva, la fase de recolección evidenció la complejidad de los entornos de datos corporativos.
Para nutrir el árbol de decisión, fue necesario localizar y extraer elementos provenientes de múltiples sistemas de información:
- Datos demográficos, clínicos y de cobertura de las pólizas de los pacientes.
- Información detallada de los proveedores de salud.
- Registros históricos de reclamaciones (claims) y facturación médica.
- Historiales farmacéuticos y diagnósticos asociados a la patología principal.
Gestión de Datos No Disponibles y Decisiones Diferidas
Durante el proceso surgió un obstáculo habitual: la información farmacéutica de ciertos medicamentos específicos no estaba integrada con el resto de las fuentes de datos de la organización.
Frente a un escenario de datos incompletos o de difícil acceso, la metodología de John Rollins aporta una directriz fundamental: es perfectamente válido posponer las decisiones sobre datos no disponibles y avanzar con lo que se tiene. No es estrictamente necesario detener el proyecto; se puede intentar adquirir esa información ausente en una etapa posterior, por ejemplo, tras evaluar los resultados intermedios del modelado predictivo.
Si las primeras métricas del modelo sugieren que la variable ausente (en este caso, el historial de medicamentos) es crítica para lograr la precisión deseada, se justifica invertir el tiempo y los recursos necesarios para extraerla. En este caso de estudio real, el equipo continuó el desarrollo y descubrió que era posible construir un modelo predictivo con un rendimiento óptimo prescindiendo de dicha información farmacéutica.
Colaboración de Ingeniería y Automatización de Procesos
La recolección de datos efectiva es una tarea multidisciplinar. Los administradores de bases de datos (DBAs) y los programadores trabajan en estrecha colaboración para diseñar las consultas de extracción y fusionar los flujos de datos procedentes de los distintos silos de la empresa. Esta consolidación técnica persigue dos grandes objetivos:
- Eliminar la redundancia: Limpiar registros duplicados o contradictorios antes de dar paso a la siguiente etapa de la metodología: la comprensión profunda de los datos (Data Understanding).
- Optimizar el ciclo de vida: Durante esta fase, el equipo analítico debate y define mejores prácticas de gobernanza e infraestructura, lo que incluye la automatización de procesos dentro de la propia base de datos. Automatizar la ingesta garantiza que las futuras recolecciones de datos sean operaciones más rápidas, eficientes y menos propensas a errores manuales.
5. Comprensión de los Datos (Data Understanding)
Una vez recolectados los primeros flujos de información, la metodología pasa de la mera acumulación a un proceso de auditoría y análisis crítico: la Comprensión de los Datos. Esta fase abarca todas las actividades analíticas orientadas a evaluar de forma rigurosa el set de datos que se acaba de construir.
En esencia, este bloque metodológico busca responder a una pregunta fundamental e imperativa para la viabilidad del proyecto: ¿Son los datos recolectados verdaderamente representativos del problema que se intenta resolver?
Herramientas de Auditoría Analítica y Calidad de Datos
Para alcanzar un entendimiento profundo y asegurar la calidad del set de datos, el equipo de Data Science debe someter a las columnas que se convertirán en las variables predictoras del modelo a tres tipos de análisis estadísticos:
- Estadísticas Univariadas Básicas: Consiste en calcular de forma individual para cada variable métricas clave como la media, mediana, valores mínimos, máximos y la desviación estándar.
- Correlaciones Cruzadas (Pairwise Correlations): Se utilizan para evaluar el grado de relación lineal entre pares de variables. Esto permite identificar variables altamente correlacionadas que resultarían redundantes para el algoritmo, facilitando la decisión de conservar únicamente una de ellas para el modelado.
- Análisis de Histogramas: Examinar la distribución visual de las variables ayuda a proyectar qué transformaciones o estrategias de preparación serán necesarias más adelante para optimizar el rendimiento del modelo.
Ejemplo de Consolidación: Si un histograma revela que una variable categórica posee demasiados valores distintos y dispersos como para ser informativa, la distribución visual servirá de guía para decidir cómo agrupar y consolidar metodológicamente dichas categorías.
Desentrañando el Significado de los Datos y Anomalías
El uso combinado de estadísticas univariadas e histogramas es la herramienta principal para diagnosticar problemas de calidad y tomar decisiones de recodificación o descarte. Un reto recurrente en esta fase es la interpretación semántica de las anomalías:
- El dilema de los valores faltantes (Missing Values): Cuando se detecta la ausencia de un dato, el científico de datos debe determinar si ese vacío encierra un significado latente. En ocasiones, un valor faltante equivale implícitamente a un “No” o a un “0”; en otras, representa simplemente un desconocimiento absoluto del dato.
- Valores engañosos o codificados: Es común encontrar variables numéricas con registros que alteran las métricas tradicionales si no se corrigen. Por ejemplo, una columna destinada a la “Edad” puede contener valores lógicos entre 0 y 100 años, pero incluir también registros con el número 999. En la gobernanza de ciertos sistemas tradicionales, ese “999” funciona como un código para denotar un dato faltante, pero un algoritmo lo procesará como una edad válida y real a menos que el equipo técnico lo identifique y lo corrija a tiempo.
La Naturaleza Iterativa de la Metodología
La fase de comprensión de datos suele desafiar las definiciones teóricas iniciales del proyecto. En el caso de estudio analizado, la métrica de éxito original para definir un ingreso por insuficiencia cardíaca congestiva se basó estrictamente en los pacientes que presentaban dicha condición como su diagnóstico principal.
Sin embargo, al ejecutar la auditoría de los datos, el equipo analítico constató que este criterio inicial no lograba capturar el volumen total de ingresos hospitalarios que la experiencia clínica y médica real estimaba.
Este hallazgo obligó a los científicos de datos a ejecutar un bucle de retroalimentación (loop) hacia la etapa anterior de Recolección de Datos con el fin de extraer también los registros de diagnósticos secundarios y terciarios, construyendo así una definición técnica mucho más robusta, fidedigna y exhaustiva de la patología.
Este comportamiento ejemplifica la esencia interactiva de la metodología de John Rollins: cuanto más se interactúa con el problema y los datos reales, más se aprende sobre el ecosistema del negocio. Este aprendizaje continuo permite refinar progresivamente el diseño del modelo, asegurando en última instancia una solución analítica de mayor calidad y precisión.
6. La Fase de Preparación (Data Preparation)
Tras completar la auditoría y validación de la información en la etapa de comprensión, la metodología avanza hacia la fase que mayor esfuerzo operativo demanda: la Preparación de los Datos. En el ciclo de vida de un proyecto analítico, esta etapa, junto con la recolección y la comprensión, representa la fase más costosa en términos de tiempo, llegando a absorber de manera habitual entre el 70% y el 90% del esfuerzo total del proyecto.
Para ilustrar este proceso, podemos recurrir nuevamente a una analogía culinaria : la preparación de los datos equivale a lavar y cortar vegetales recién cosechados. Al igual que eliminamos la tierra, las imperfecciones y las partes no comestibles antes de cocinar, el científico de datos debe purificar los sets de información eliminando duplicados, corrigiendo valores inválidos y dando el formato exacto requerido por el algoritmo.
Continuando con la analogía, picar una cebolla finamente permite que sus sabores se distribuyan de forma homogénea por toda la salsa, algo que no ocurriría si se arrojara la pieza entera a la olla. Del mismo modo, transformar y moldear las variables facilita de manera drástica el trabajo del algoritmo de Machine Learning. Una vía altamente efectiva para mitigar la enorme carga operativa de esta fase es la automatización de los procesos de limpieza e ingesta directamente dentro de la base de datos, lo que puede reducir el tiempo dedicado a estas tareas hasta en un 50%, permitiendo a los equipos enfocarse en lo que realmente aporta valor: el diseño y optimización de los modelos predictivos.
Conceptos Clave en la Preparación de Datos
Para transformar con éxito el set de datos crudos en una matriz apta para el modelado, se deben dominar tres pilares procedimentales:
- Saneamiento del Set de Datos: Consiste en el tratamiento de valores faltantes o nulos, la detección y eliminación de registros duplicados y la corrección de anomalías técnicas identificadas previamente.
- Feature Engineering (Ingeniería de Características): Es el proceso de aplicar el conocimiento del dominio de negocio para estructurar y combinar datos crudos en nuevas variables explicativas (denominadas features o características). Estas variables sintéticas actúan como indicadores que simplifican la detección de patrones por parte de los algoritmos de Machine Learning.
- Análisis de Texto y Datos No Estructurados: Es una práctica fundamental para asegurar que las agrupaciones y categorizaciones lógicas de las variables de texto sean rigurosas, garantizando que el código de programación no pase por alto información relevante u oculta en los campos alfanuméricos.
Caso de Estudio: Preparación y Modelado para Insuficiencia Cardíaca
Retomando de forma práctica el modelo de clasificación basado en árboles de decisión para la aseguradora médica, la fase de preparación de datos ilustra a la perfección cómo se ejecutan estos conceptos teóricos en un entorno corporativo real:
Delimitación de Conceptos Clínicos y Criterios Médicos
El primer desafío metodológico consistió en definir con precisión matemática qué constituye una “insuficiencia cardíaca congestiva”. Aunque conceptualmente parece una tarea sencilla, desde la perspectiva de los datos no lo es: esta patología implica una acumulación específica de fluidos corporales y representa solo una variante dentro del amplio espectro de fallos cardíacos. Para asegurar la viabilidad del modelo, se requirió asesoramiento clínico experto con el fin de mapear y seleccionar con exactitud el conjunto de códigos de diagnóstico médico (Diagnosis-Related Group codes) correspondientes a esta condición específica.
Definición del Target y Temporalidad de Eventos
El siguiente paso fue estructurar la variable dependiente o target (el objetivo que el modelo debe predecir). Esto exigió analizar detalladamente la secuencia cronológica de los ingresos de cada paciente para diferenciar metodológicamente entre dos tipos de eventos:
- Index Admission (Admisión de Referencia): El reingreso inicial u hospitalización base por insuficiencia cardíaca.
- Readmission (Readmisión): Cualquier reingreso hospitalario subsiguiente relacionado con la misma patología.
Bajo la guía de expertos del sector salud, se fijó una ventana temporal estricta de 30 días tras el alta médica de la admisión de referencia para contabilizar un evento como una readmisión válida. La variable resultante fue un objetivo de clasificación binaria con dos únicos valores posibles: Sí o No.
Agregación Masiva de Datos Transaccionales (Roll-up)
El reto técnico más complejo de este caso radicaba en la discrepancia de formatos. El algoritmo de árboles de decisión exige estrictamente una estructura tabular de un único registro por paciente. Sin embargo, el historial médico real de los asegurados es de naturaleza transaccional : los sistemas acumulan cientos o miles de filas independientes por persona que detallan visitas al médico, análisis de laboratorio, reclamaciones de seguros (claims), servicios de urgencias, procedimientos quirúrgicos y recetas farmacéuticas.
Para resolver esta asimetría, los científicos de datos procedieron a agregar todo el historial transaccional al nivel de paciente, consolidando miles de filas en una sola línea maestra por individuo. Durante este proceso de agregación y a través de la ingeniería de características (feature engineering), se crearon decenas de variables sintéticas nuevas basadas en la frecuencia y la recencia, tales como:
- El número total de visitas realizadas a médicos y clínicas especialistas.
- La fecha de la hospitalización más reciente asociada a los diagnósticos analizados.
- Indicadores consolidados de la historia clínica general (edad, género, tipo de cobertura de seguro).
El resultado final de esta fase fue una tabla unificada y saneada donde cada fila recopilaba los atributos analíticos de la historia clínica de un paciente único, dejando el set de datos completamente listo para nutrir la fase de Modelado.
¿Procedemos a redactar la siguiente sección del artículo orientada a las fases de Modelado y Evaluación (Modeling & Evaluation), o prefieres profundizar en los criterios matemáticos utilizados para la selección de variables predictoras?
7. La Fase de Modelado (Modeling)
Tras completar la extensa y demandante fase de preparación de datos, la metodología alcanza su núcleo algorítmico: el Modelado. Si las etapas previas se encargaron de asegurar, limpiar y estructurar los ingredientes, esta fase representa el momento exacto en el que el científico de datos “prueba la salsa” para determinar si el sabor es el correcto o si el plato requiere más condimento.
El modelado no es un proceso estático ni de un solo paso; es un pilar intensamente iterativo donde el profesional técnico calibra las matemáticas subyacentes para alinearlas con los objetivos del negocio antes de pasar a cualquier etapa de evaluación formal o despliegue en producción.
Conceptos Fundamentales del Modelado de Datos
El propósito principal del modelado es desarrollar estructuras matemáticas capaces de identificar y aprender patrones complejos dentro de los conjuntos de datos que han sido previamente preparados. Dependiendo de la naturaleza de la pregunta de negocio y del enfoque analítico seleccionado al inicio del proyecto, los modelos se dividen de forma general en dos grandes categorías:
- Modelos Descriptivos: Se orientan a responder preguntas sobre relaciones existentes y dinámicas internas de los datos. Por ejemplo: “Si un cliente realiza determinada acción, ¿qué otros comportamientos asociados suele presentar?” o “¿Cómo se agrupan nuestros usuarios según sus hábitos de consumo?” (estructuras habituales en algoritmos de clustering o reglas de asociación).
- Modelos Predictivos: Tienen como finalidad anticipar resultados futuros o clasificar entidades basándose en variables históricas. Su objetivo es calcular la probabilidad de que ocurra un evento específico o asignar etiquetas automáticas a nuevas observaciones (como determinar si una transacción es fraudulenta o no).
El entrenamiento de estos modelos se ejecuta sobre un conjunto de datos específico (denominado training set o conjunto de entrenamiento), y su éxito radica en la capacidad del científico de datos para realizar un ajuste fino de sus parámetros internos.
Caso de Estudio: Calibración de Parámetros mediante Árboles de Decisión
Para entender cómo opera el modelado en la práctica, analicemos el desarrollo del modelo de clasificación diseñado para la aseguradora médica, cuyo objetivo era predecir si un paciente con insuficiencia cardíaca congestiva sería reingresado en un plazo de 30 días tras su alta (una variable objetivo binaria: Sí o No).
La construcción de este modelo demostró que el diseño algorítmico requiere un ejercicio constante de experimentación y equilibrio de fuerzas mediante la sintonización de parámetros (parameter tuning):
Intento 1: El Modelo Base (Parámetros por Defecto)
El primer árbol de decisión se construyó utilizando los parámetros estándar del software analítico. Al revisar el rendimiento de este modelo inicial, los científicos de datos identificaron una asimetría crítica y peligrosa:
- Precisión en la clasificación del “No” (No reingresa): 95%
- Precisión en la clasificación del “Sí” (Sí reingresa): 19%
Aunque un 95% de acierto en los pacientes estables parece sobresaliente a nivel global, el objetivo primordial del negocio era detectar a los pacientes en riesgo de reingreso (el “Sí”) para poder intervenir médicamente a tiempo. Un 19% de precisión hacía que el modelo fuera completamente inútil para los fines asistenciales de la organización.
Intento 2: Ajuste Extremo del Coste de Clasificación Errónea
Para corregir el déficit del primer intento, el equipo modificó un parámetro clave: el coste relativo de clasificación errónea. Se penalizó severamente al algoritmo cada vez que fallara en predecir un “Sí”, estableciendo una relación de coste extrema de 10 a 1 (asumiendo que predecir erróneamente un “No” cuando era un “Sí” era diez veces peor).
- Resultado: La precisión del “Sí” aumentó drásticamente al 85%, pero la precisión del “No” se desplomó al 45%.
Este escenario planteó un problema operativo grave. Clasificar erróneamente a tantos pacientes estables como “casos de riesgo” desencadenaría una ola de intervenciones médicas innecesarias, saturando los servicios de salud y generando costes logísticos inviables para la empresa. El algoritmo se había vuelto demasiado sensible.
Intento 3: El Balance Óptimo
Mediante experimentación continua, los científicos de datos recalibraron el parámetro a una relación de coste más moderada y realista de 4 a 1. Este ajuste técnico en el algoritmo permitió alcanzar el mejor equilibrio posible para las dimensiones del training set:
| Métrica Estadística | Parámetro Evaluado | Resultado Obtenido |
| Sensibilidad (Sensitivity) | Precisión exclusiva del “Sí” (Reingresa) | 68% |
| Especificidad (Specificity) | Precisión exclusiva del “No” (Estable) | 85% |
| Precisión Global (Overall Accuracy) | Rendimiento total del modelo | 81% |
Este tercer modelo proporcionó la estabilidad técnica y la viabilidad comercial exigidas por la organización. Este caso real demuestra que el modelado en Machine Learning no consiste en ejecutar un algoritmo una sola vez esperando un resultado perfecto; es un proceso riguroso de prueba, análisis de métricas y sintonización de parámetros hasta encontrar el punto exacto de equilibrio que responda a la necesidad original del negocio.
8. La Fase de Evaluación (Evaluation)
Una vez que el modelo analítico ha sido calibrado y sintonizado mediante el ajuste de sus parámetros, la metodología avanza hacia un punto de control riguroso: la Evaluación. Esta fase se ejecuta de forma simultánea e iterativa con la construcción del modelo durante la etapa de desarrollo y siempre tiene lugar antes de planificar cualquier despliegue (deployment) en los sistemas de producción.
Si en el modelado el científico de datos “prueba la salsa” para ajustar su sazón, en la evaluación se somete el plato a un panel de críticos para responder a una pregunta imperativa y pragmática: ¿El modelo desarrollado realmente responde a la pregunta inicial o es necesario realizar ajustes adicionales?
Los Dos Pilares de la Evaluación Analítica
Para evaluar la calidad y la viabilidad de una solución de Machine Learning, el equipo técnico debe abordar el diagnóstico desde dos perspectivas complementarias:
- Garantía de Rendimiento Técnico: Consiste en aplicar métricas estadísticas rigurosas para certificar que el modelo posee un poder predictivo real y que es capaz de generalizar sus conclusiones al enfrentarse a datos nuevos que no vio durante la fase de entrenamiento.
- Validación del Enfoque de Negocio: Un modelo puede ser una obra maestra matemática, pero si no responde a la necesidad u objetivos de la organización, o si sus resultados no son accionables para los interesados (stakeholders), carece de valor práctico. Esta faceta evalúa la relevancia de los insights generados en el contexto del problema real.
Herramientas de Diagnóstico: La Curva ROC
En el diseño de modelos de clasificación binaria —como el desarrollado para clasificar si un paciente reingresará o no—, una de las herramientas estadísticas más potentes para evaluar el rendimiento es la curva ROC (Receiver Operating Characteristic).
La curva ROC es una gráfica diagnóstica que cuantifica el desempeño de un modelo de clasificación al contrastar de forma directa dos métricas fundamentales a medida que varía el umbral de discriminación del algoritmo:
- Tasa de Verdaderos Positivos (Sensibilidad): El porcentaje de casos positivos correctamente identificados.
- Tasa de Falsos Positivos: El porcentaje de casos negativos que el modelo clasifica erróneamente como positivos.
El área bajo esta curva (conocida como AUC – Area Under the Curve) sirve como un indicador unificado para comparar la calidad de diferentes modelos de un vistazo.
Raíces Históricas de la Curva ROC: Como dato de gran interés educativo para la ciencia de datos, los orígenes de la curva ROC no se encuentran en la informática, sino en el ámbito militar durante la Segunda Guerra Mundial. Fue desarrollada por ingenieros aliados para optimizar la detección de aeronaves enemigas a través de las señales de radar tras el ataque a Pearl Harbor. Su propósito original era encontrar el equilibrio perfecto para configurar los radares: debían ser lo suficientemente sensibles para alertar de un ataque real (Verdadero Positivo), pero no tanto como para confundir una bandada de pájaros con bombardeos enemigos (Falso Positivo). En la actualidad, esta misma lógica matemática se aplica en el Machine Learning y la minería de datos moderna.
Caso de Estudio: Evaluación Comparativa para la Toma de Decisiones
Retomando de forma práctica el proyecto de la aseguradora médica para la insuficiencia cardíaca congestiva, la fase de evaluación consistió en someter los diferentes intentos de modelado a un análisis comparativo utilizando curvas ROC. El objetivo era medir gráficamente la efectividad de cada configuración en la discriminación de los pacientes en riesgo:
- Evaluación del Modelo 1 (Parámetros por defecto): La curva ROC reflejó visualmente las deficiencias de este enfoque. Al poseer una precisión del “Sí” de apenas el 19%, la gráfica evidenció un modelo plano e incapaz de resolver el problema de negocio principal.
- Evaluación del Modelo 2 (Relación de coste 10 a 1): Aunque este modelo incrementó la sensibilidad, la curva expuso un aumento inaceptable en la tasa de falsos positivos (desplomando la especificidad al 45%), lo que visualmente se tradujo en un rendimiento deficiente para las operaciones de la empresa.
- Evaluación del Modelo 3 (Relación de coste 4 a 1): Al trazar la curva ROC de esta versión, el equipo validó matemáticamente que este modelo lograba la mayor distancia óptima frente a la línea de asignación aleatoria. Consiguió un balance ideal con un 68% de sensibilidad y un 85% de especificidad, consolidando una precisión global del 81%.
A través de este diagnóstico visual y estadístico, los científicos de datos demostraron con certeza que el Modelo 3 era la solución más robusta y equilibrada de las opciones desarrolladas. Esta validación técnica cerró con éxito el bloque de diseño, otorgando la confianza necesaria para avanzar hacia la puesta en marcha de la estrategia analítica.
¿Procedemos a redactar las dos fases finales de la metodología, correspondientes al Despliegue (Deployment) y la Retroalimentación (Feedback), o prefieres profundizar en la interpretación matemática del Área Bajo la Curva (AUC)?
9. Fase de Implementación: El Despliegue (Deployment)
Una vez que el modelo ha sido validado estadísticamente y se ha certificado que responde con rigor a la pregunta de negocio original, la metodología avanza hacia la fase que materializa todo el valor del proyecto: el Despliegue.
Desarrollar un modelo de Machine Learning preciso no es el objetivo final de una iniciativa corporativa. El verdadero valor se genera cuando esa solución matemática se pone en práctica, se integra en los sistemas de la organización y se convierte en una herramienta accionable para los usuarios finales.
La Colaboración Multidisciplinar en la Puesta en Producción
El despliegue no es una tarea exclusiva del científico de datos; por el contrario, exige la articulación de un equipo multidisciplinar. En un escenario empresarial, el éxito de esta fase requiere la estrecha colaboración de diversos perfiles especializados:
- El Propietario de la Solución (Solution Owner): Garantiza que la implementación cumpla con las expectativas estratégicas y operativas del negocio.
- Ingenieros y Desarrolladores de Aplicaciones: Se encargan de encapsular el modelo y conectarlo mediante tuberías de datos o APIs con las interfaces de usuario.
- Administradores de TI y DevOps: Aseguran la escalabilidad, seguridad e infraestructura de servidores necesaria para que el modelo funcione de manera óptima en tiempo real o en lotes.
- Equipos de Negocio y Marketing: Diseñan las estrategias de comunicación y adopción del nuevo sistema.
El Factor Clave de Adopción: Un modelo puede proporcionar predicciones perfectas, pero si los interesados (stakeholders) no están familiarizados con la herramienta, desconocen cómo interpretar sus salidas o no confían en el sistema, la solución analítica quedará obsoleta. Familiarizar e integrar a los usuarios en el uso de la solución es un requisito indispensable en esta etapa.
Flexibilidad en el Ámbito de Aplicación
Los requisitos de despliegue varían de forma drástica según el canal y el contexto del problema. La metodología de John Rollins contempla que el despliegue puede ser tan directo o complejo como la solución lo requiera:
- Despliegue de Alcance Limitado: En escenarios donde los insights van dirigidos exclusivamente a la toma de decisiones ejecutivas, el despliegue puede consistir simplemente en la puesta en marcha del modelo ante un grupo reducido de usuarios clave o la publicación de los resultados en un cuadro de mando corporativo.
- Despliegue a Gran Escala: Si el modelo está diseñado para automatizar operaciones de cara al cliente (como un motor de recomendación en un e-commerce o un sistema de detección de fraudes bancarios), la solución requerirá integrarse en canales de producción masivos con alta disponibilidad y procesamiento en tiempo real.
Caso de Estudio: Aplicaciones Interactivas en el Sector Salud
Para ilustrar un despliegue de alta relevancia operativa, analicemos un caso de estudio paralelo aplicado al modelado del riesgo de hospitalización para pacientes con diabetes juvenil. Al igual que el modelo de insuficiencia cardíaca congestiva, este proyecto utilizó un algoritmo de clasificación basado en árboles de decisión como motor predictivo subyacente.
En este escenario, el despliegue definitivo se realizó a través de una aplicación analítica avanzada (desarrollada sobre entornos como IBM Cognos), transformando las salidas matemáticas del árbol de decisión en un entorno visual e interactivo para el personal médico:
- Mapas de Riesgo Geográfico: La aplicación integró una interfaz cartográfica que proporcionaba una visión general del riesgo de hospitalización a nivel nacional. Esto permitía a los administradores de salud identificar de un vistazo las regiones o zonas geográficas con mayor vulnerabilidad.
- Reportes de Nodos Clínicos: La solución desplegada incluyó un sistema de reportes interactivos estructurado según los nodos específicos derivados del árbol de decisión. De este modo, los médicos y clínicos podían explorar visualmente las combinaciones exactas de condiciones médicas, variables demográficas e historiales clínicos que ponían a un grupo determinado de pacientes en una situación de alto riesgo.
Al estructurar el despliegue mediante dashboards interactivos, el conocimiento derivado de las matemáticas complejas del Machine Learning se transformó en una herramienta intuitiva de soporte a la toma de decisiones médicas, permitiendo diseñar intervenciones preventivas personalizadas y optimizar los recursos hospitalarios.
¿Procedemos a redactar la última sección de la metodología, correspondiente a la fase de Retroalimentación (Feedback), o prefieres detallar las estrategias de integración tecnológica (como APIs y arquitecturas de microservicios) para modelos predictivos?
10. La Retroalimentación (Feedback)
El despliegue de un modelo predictivo en producción no representa, bajo ningún concepto, el desenlace de un proyecto de ciencia de datos. Al contrario, marca el inicio de una fase operativa crucial y continua: la Retroalimentación.
Una vez que la solución analítica se encuentra activa y operando en el mundo real, los flujos de datos generados por la experiencia de los usuarios finales y el rendimiento del propio algoritmo se convierten en el activo más valioso para su evolución. El valor sostenido de cualquier modelo de Machine Learning en el tiempo depende por completo de la capacidad del equipo para recolectar de forma sistemática este feedback y realizar los ajustes técnicos necesarios durante todo el ciclo de vida de la solución.
La Naturaleza Cíclica de la Metodología
La metodología de John Rollins no es un camino lineal de un solo sentido, sino un proceso intrínsecamente cíclico e iterativo. Cada una de las diez etapas estudiadas actúa como el pilar fundamental que define y prepara el escenario para la fase subsiguiente.
Este diseño modular garantiza que el refinamiento sea una constante en el juego analítico. El proceso de retroalimentación se fundamenta en una premisa científica ineludible: cuanto más se conoce sobre el comportamiento real de un fenómeno, más capacidad se tiene para refinar la solución analítica. A medida que el modelo se enfrenta a nuevas condiciones y recopila métricas de uso real, el equipo de ciencia de datos profundiza en el entendimiento del problema de negocio, lo que permite reiniciar el ciclo metodológico con un grado de precisión significativamente mayor.
Caso de Estudio: Refinamiento Evolutivo en Programas de Intervención Médica
Para comprender el impacto del feedback en la práctica, observemos el comportamiento posdespliegue del programa de gestión de salud diseñado para mitigar los reingresos y hospitalizaciones. La puesta en marcha de la aplicación interactiva abrió un canal de retroalimentación que redefinió por completo la estrategia técnica de los científicos de datos, impulsando dos mejoras de gran calado:
1. Incorporación de Datos de Participación Operativa
El uso de la herramienta por parte del personal de salud permitió identificar que los pacientes asignados a grupos de alto riesgo reaccionaban de forma diversa según su nivel de involucramiento en las actividades preventivas. La retroalimentación de los médicos clínicos sugirió que no bastaba con conocer el perfil histórico del paciente; era indispensable registrar si el individuo participaba activamente en el programa de intervención diseñado. Esta nueva variable operativa se integró de inmediato al modelo para afinar su capacidad de discriminación.
2. Reactivación y Absorción de Datos Diferidos (Farmacéuticos)
Si recordamos las etapas iniciales de la metodología (Específicamente en Data Collection), el equipo analítico había tomado la decisión de posponer e interrumpir temporalmente la recolección de los datos farmacéuticos detallados debido a que los sistemas de información de las recetas no estaban integrados y su extracción exigía un coste de desarrollo prohibitivo. El modelo inicial demostró ser lo suficientemente robusto para operar sin ellos.
Sin embargo, tras la fase de despliegue y tras evaluar los resultados prácticos del modelo en producción, el proceso de retroalimentación evidenció que para romper el techo de precisión alcanzado y optimizar las intervenciones clínicas más complejas, valía totalmente la pena realizar la inversión de tiempo, código y esfuerzo tecnológico necesaria para extraer e incorporar ese historial farmacéutico detallado que se había descartado al principio.
El Proceso de Revisión de Intervenciones y Prácticas Clave
El proceso de retroalimentación obliga a los científicos de datos y a los líderes de la organización a implementar una rutina de gobernanza analítica basada en tres mejores prácticas indispensables:
- Monitoreo de Métricas en Producción: Definir paneles de control para supervisar el comportamiento del modelo, midiendo si las tasas de falsos positivos y verdaderos positivos se mantienen estables o si sufren degradación (data drift o model degradation) ante los cambios del entorno real.
- Evaluación del Impacto de las Acciones: Analizar si las decisiones operativas basadas en las predicciones del modelo (por ejemplo, priorizar la atención de ciertos pacientes) están modificando positivamente los indicadores clave de rendimiento (KPIs) del negocio.
- Revisión de Procesos en Base de Datos: Colaborar con ingenieros de datos para asegurar que los nuevos elementos detectados en la fase de retroalimentación se automaticen e integren de forma eficiente en los almacenes de datos (Data Warehouses), cerrando el flujo metodológico con un sistema escalable, dinámico y en constante aprendizaje.
Más Allá de los Algoritmos: El Rol del Storytelling en Ciencia de Datos
Existe una última habilidad, frecuentemente subestimada en las formaciones puramente técnicas, que marca la diferencia entre un modelo archivado en un repositorio y una solución que transforma una organización: el storytelling con datos.
El rol de la narrativa en la vida de un científico de datos o analista no puede exagerarse. Dominar la construcción de historias no es un complemento cosmético; es una competencia crítica para cualquier profesional que necesite convertir métricas abstractas en decisiones estratégicas.
La Psicología Detrás de las Historias y los Datos
La razón por la que el storytelling es tan potente radica en la propia naturaleza humana. Los seres humanos entendemos, procesamos y recordamos el mundo de forma innata a través de historias.
Cuando un equipo técnico presenta un proyecto limitándose a proyectar números y KPIs aislados, es muy probable que la audiencia desconecte. Cualquiera puede mostrar datos en una pantalla, pero si esos datos no están respaldados por una narrativa estructurada y un argumento sólido que justifique la acción, la propuesta difícilmente resonará en la organización.
El Experimento de Stanford: Un estudio emblemático realizado en la Universidad de Stanford analizó el impacto de la comunicación cuantitativa. En el experimento, varios participantes debían realizar presentaciones de negocios (pitches). Algunos basaron sus discursos exclusivamente en estadísticas, gráficos rígidos y KPIs. Otros, en cambio, entrelazaron esos mismos datos numéricos dentro de una historia. Al evaluar el impacto a largo plazo, los resultados fueron contundentes: la audiencia recordaba de forma nítida los datos de aquellos ponentes que habían estructurado su presentación mediante un relato, mientras que los datos aislados de las presentaciones puramente estadísticas se olvidaron casi por completo.
El “Puente” entre el Equipo Técnico y el Negocio
En el ecosistema corporativo actual, el científico de datos actúa como un traductor. Su trabajo consiste en sumergirse en bases de datos relacionales complejas, entrenar algoritmos de Machine Learning y, posteriormente, emerger de ese entorno técnico para explicarle a un comité ejecutivo —que no tiene por qué entender de matemáticas avanzadas o de hiperparámetros— qué significan esos hallazgos.
El storytelling es el vehículo que permite cruzar ese puente. No se trata de simplificar el trabajo u ocultar el rigor estadístico, sino de contextualizar el dato. Una buena narrativa responde de forma clara a tres preguntas clave para los interesados (stakeholders):
- ¿Qué está pasando? (El hecho respaldado por el dato crudo).
- ¿Por qué importa? (El impacto financiero, operativo o asistencial de ese hecho).
- ¿Qué debemos hacer ahora? (La llamada a la acción o decisión estratégica).
Al dominar esta técnica, el profesional de la ciencia de datos no solo demuestra su competencia técnica, sino que dota a la organización de una razón convincente para actuar, garantizando que el ciclo metodológico culmine en un verdadero impacto transformador.
Marcos de Trabajo Alternativos: Introducción a CRISP-DM
Para concluir este recorrido por las metodologías analíticas, es fundamental estudiar el marco de trabajo que sentó los precedentes de la industria y que sigue siendo el estándar más utilizado en el ecosistema corporativo global: CRISP-DM (Cross-Industry Standard Process for Data Mining o Proceso Estándar de la Industria Cruzada para la Minería de Datos).
Si la metodología de John Rollins destaca por su desglose minucioso en 10 etapas secuenciales e iterativas, CRISP-DM ofrece un modelo robusto, probado por la industria, que proporciona un enfoque estructurado y flexible para guiar cualquier esfuerzo de minería de datos y Machine Learning. Comprender la relación y las equivalencias entre ambos marcos teóricos permite a los equipos de ciencia de datos adaptar sus procesos con la máxima agilidad según el alcance del proyecto.
Las 6 Etapas del Modelo CRISP-DM
A diferencia de la estructura de Rollins, el ciclo de vida de un proyecto bajo el estándar CRISP-DM se condensa en seis etapas principales interconectadas. El proceso es marcadamente iterativo, lo que significa que el avance a una fase frecuentemente depende de los hallazgos y validaciones de la etapa anterior:
- Business Understanding (Comprensión del negocio): Al igual que en el modelo de Rollins, esta fase inicial se enfoca en entender detalladamente los objetivos, requisitos y restricciones del proyecto desde una perspectiva empresarial, traduciendo dicha necesidad en la definición de un problema técnico de minería de datos.
- Data Understanding (Comprensión de los datos): Implica la recolección inicial de los datos, la familiarización con ellos, la identificación de problemas de calidad y la extracción de los primeros insights o subconjuntos ocultos mediante estadísticas descriptivas.
- Data Preparation (Preparación de los datos): Comprende todas las tareas necesarias para construir el set de datos final (la matriz de modelado) a partir de los datos en bruto. Incluye la selección de tablas, filas y atributos, la limpieza de registros y la transformación de variables.
- Modeling (Modelado): En esta fase se seleccionan y aplican diversas técnicas y algoritmos analíticos (como árboles de decisión, redes neuronales o regresiones) y se calibran sus hiperparámetros para optimizar su rendimiento.
- Evaluation (Evaluación): Antes de proceder al despliegue final, se evalúa rigurosamente el modelo construido para asegurar que alcanza los objetivos de negocio preestablecidos. Aquí se determina si existe alguna razón importante por la cual la solución no deba ponerse en marcha.
- Deployment (Despliegue): La fase final donde los conocimientos y modelos se integran en la operación diaria de la empresa. Puede ser tan simple como la generación de un reporte o tan compleja como la implementación de un proceso de Machine Learning automatizado en tiempo real.
Puntos de Encuentro y Divergencias Técnicas
Al contrastar la metodología clásica de John Rollins con el estándar CRISP-DM, se hacen evidentes sus paralelismos teóricos, pero también sus sutiles diferencias conceptuales. El análisis comparativo revela cómo ambos modelos distribuyen la carga de trabajo analítico:
- Fusión de Etapas de Datos: Lo que en CRISP-DM se denomina simplemente Data Understanding, en la metodología de Rollins se desglosa formalmente en tres pasos independientes y explícitos: Data Requirements (Requisitos), Data Collection (Recolección) y Data Understanding (Comprensión). Esta ramificación de Rollins aporta una guía más granular para las fases tempranas de ingeniería de datos.
- El Cierre del Ciclo: La Reunión de Feedback: Una de las diferencias más notables ocurre tras completar la fase de evaluación y puesta en marcha. En la práctica real de CRISP-DM, al finalizar las seis etapas, los científicos de datos convocan una nueva reunión de comprensión del negocio con los interesados (stakeholders) para discutir formalmente los resultados y decidir los siguientes pasos.
Aunque conceptualmente representa lo mismo, en el estándar CRISP-DM esta etapa final de revisión no cuenta con un nombre explícito dentro del diagrama oficial. Por el contrario, el modelo de John Rollins subsana este vacío metodológico nombrando y estructurando de forma directa y rigurosa la fase número diez como la Etapa de Retroalimentación (Feedback Stage).
Independientemente de si un equipo elige la granularidad de las 10 etapas de Rollins o la estructura consolidada de las 6 fases de CRISP-DM, el factor crítico de éxito radica en respetar la naturaleza cíclica del proceso. Las etapas continúan repitiéndose de forma sistemática hasta que la gerencia, los especialistas del dominio y los científicos de datos acuerden unánimemente que los modelos proporcionan las respuestas precisas para resolver los problemas de la organización y alcanzar sus metas estratégicas.