Visualización de Datos de Alta Dimensionalidad
La transformación t-SNE (t-Distributed Stochastic Neighbor Embedding) es una técnica de reducción de dimensionalidad no lineal diseñada principalmente para la visualización de datos complejos en espacios de dos o tres dimensiones. Su capacidad para revelar patrones, agrupaciones y estructuras ocultas la ha convertido en una de las herramientas más populares en Data Science, Machine Learning e Inteligencia Artificial.
A diferencia de técnicas tradicionales como PCA, que buscan conservar la máxima varianza de los datos, t-SNE se enfoca en preservar las relaciones de vecindad entre observaciones. Esto permite representar conjuntos de datos de alta dimensionalidad de forma intuitiva y visualmente interpretable.
La técnica es especialmente útil para explorar datos antes de construir modelos predictivos, ayudando a comprender la estructura interna de la información y detectar agrupaciones naturales.
¿Qué es t-SNE?
t-SNE es un algoritmo de reducción de dimensionalidad desarrollado por Laurens van der Maaten y Geoffrey Hinton en 2008. Su objetivo consiste en transformar datos de muchas dimensiones en un espacio de menor dimensión, generalmente dos o tres dimensiones. Durante esta transformación intenta conservar la proximidad relativa entre observaciones.
En términos sencillos:
- Los puntos cercanos en el espacio original permanecen cercanos en la representación reducida.
- Los puntos alejados tienden a mantenerse separados.
Esto permite visualizar conjuntos de datos complejos que serían imposibles de interpretar directamente.

¿Cómo funciona t-SNE?
El algoritmo transforma las relaciones entre observaciones en probabilidades. Primero calcula la similitud entre puntos en el espacio original. Si dos observaciones son muy parecidas, tendrán una probabilidad alta de ser consideradas vecinas. Esta probabilidad puede representarse mediante una distribución gaussiana:
$$p_{j|i}=\frac{\exp\left(-\frac{||x_i-x_j||^2}{2\sigma_i^2}\right)}{\sum_{k\neq i}\exp\left(-\frac{||x_i-x_k||^2}{2\sigma_i^2}\right)}$$
Posteriormente, t-SNE construye una representación en baja dimensión utilizando una distribución t de Student para medir similitudes:
$$q_{ij}=\frac{(1+||y_i-y_j||^2)^{-1}}{\sum_{k\neq l}(1+||y_k-y_l||^2)^{-1}}$$
Finalmente, el algoritmo intenta minimizar la diferencia entre ambas distribuciones utilizando la divergencia de Kullback-Leibler:
$$KL(P||Q)=\sum_{i}\sum_{j}p_{ij}\log\frac{p_{ij}}{q_{ij}}$$
El resultado es una representación bidimensional o tridimensional que preserva las relaciones locales entre observaciones.
Intuición detrás de t-SNE
La idea principal puede entenderse mediante un ejemplo sencillo. Supongamos un conjunto de imágenes de animales representadas por cientos de características numéricas. En el espacio original:
- Las imágenes de perros estarán cerca unas de otras.
- Las imágenes de gatos formarán otro grupo.
- Las imágenes de aves aparecerán en otra región distinta.
t-SNE intenta mantener esas vecindades cuando reduce las dimensiones. El resultado suele mostrar grupos claramente diferenciados que permiten identificar patrones visualmente.
Ejemplo conceptual
Imaginemos un conjunto de datos de clientes con 100 variables:
- Edad.
- Ingresos.
- Historial de compras.
- Frecuencia de visitas.
- Interacción con campañas.
- Comportamiento digital.
Visualizar directamente estas 100 dimensiones es imposible.
Aplicando t-SNE:
- Los clientes con comportamientos similares aparecerán agrupados.
- Los perfiles diferentes formarán grupos separados.
- Los posibles segmentos de mercado serán más fáciles de identificar.
Parámetros importantes de t-SNE
El comportamiento del algoritmo depende de varios hiperparámetros.
Perplexity
Controla el número efectivo de vecinos considerados.
- Valores comunes: entre 5 y 50, frecuentemente 30 como punto de partida.
- Valores pequeños: Capturan estructuras muy locales.
- Valores grandes: Capturan patrones más globales.
Learning Rate
Determina la velocidad de optimización. Valores habituales:
- Entre 100 y 1000.
Un valor inadecuado puede producir representaciones distorsionadas.
Número de Iteraciones
Controla el proceso de optimización. Generalmente:
- 1000 iteraciones o más.
- Más iteraciones suelen generar resultados más estables.
Beneficios de t-SNE
- Excelente capacidad de visualización.
- Descubre estructuras complejas no lineales.
- Detecta agrupaciones ocultas.
- Facilita el análisis exploratorio.
- Funciona bien con datos de alta dimensionalidad.
- Revela relaciones difíciles de detectar con métodos lineales.
- Produce representaciones visualmente intuitivas.
Por estas razones es una de las herramientas favoritas para análisis exploratorio de datos.
¿Cuándo utilizar t-SNE?
- Se desea visualizar datos de alta dimensionalidad.
- Se busca detectar agrupaciones naturales.
- Se necesita explorar datos antes de modelarlos.
- Se quiere analizar embeddings generados por redes neuronales.
- Se pretende comprender mejor la estructura de un conjunto de datos complejo.
Escenarios comunes:
- Computer Vision.
- Procesamiento del lenguaje natural.
- Bioinformática.
- Sistemas de recomendación.
- Análisis de clientes.
- Detección de anomalías.
Ventajas
- Captura relaciones no lineales.
- Conserva vecindades locales de forma efectiva.
- Produce visualizaciones muy informativas.
- Permite descubrir patrones ocultos.
- Funciona bien con datos complejos.
- Es ampliamente utilizada en investigación y análisis avanzados.
En muchos casos genera representaciones mucho más interpretables que PCA.
Desventajas
- Alto coste computacional.
- Resultados sensibles a los hiperparámetros.
- No es fácilmente interpretable matemáticamente.
- Los resultados pueden variar entre ejecuciones.
- No escala bien a conjuntos extremadamente grandes.
Además, la distancia entre grupos en el gráfico no siempre tiene un significado real en el espacio original.
Limitaciones de t-SNE
Existen varios aspectos que deben considerarse al utilizar esta técnica.
No preserva estructuras globales
t-SNE prioriza relaciones locales.
Como consecuencia:
- Las distancias entre grupos pueden ser engañosas.
- La separación visual no siempre refleja separación real.
Sensibilidad a hiperparámetros
Pequeños cambios en:
- Perplexity.
- Learning rate.
- Número de iteraciones.
Pueden producir visualizaciones muy diferentes.
No es una técnica predictiva
t-SNE está diseñada para:
- Exploración.
- Visualización.
No suele emplearse directamente como entrada para modelos predictivos.
Coste computacional
La complejidad aumenta significativamente conforme crece el número de observaciones. Para millones de registros pueden requerirse alternativas más eficientes.
Aplicaciones en Data Science y Machine Learning
t-SNE tiene una amplia presencia en proyectos analíticos modernos.
Visualización de datasets complejos
- Exploración de datos.
- Identificación de clusters.
- Detección de anomalías.
Computer Vision
- Visualización de embeddings de imágenes.
- Evaluación de modelos de clasificación.
- Análisis de características extraídas por CNN.
Procesamiento del Lenguaje Natural
- Visualización de Word Embeddings.
- Análisis de documentos.
- Exploración semántica.
Bioinformática
- Análisis genómico.
- Clasificación celular.
- Estudios de expresión genética.
Deep Learning
- Inspección de representaciones internas.
- Evaluación de capas ocultas.
- Interpretación de embeddings.
Comparación entre PCA, ICA y t-SNE
| Característica | PCA | ICA | t-SNE |
|---|---|---|---|
| Supervisado | No | No | No |
| Lineal | Sí | Sí | No |
| Preserva varianza | Sí | No | No |
| Busca independencia | No | Sí | No |
| Preserva vecindades | Parcialmente | Parcialmente | Sí |
| Visualización | Buena | Moderada | Excelente |
| Escalabilidad | Alta | Media | Baja |
En general:
- PCA se utiliza para compresión y reducción rápida.
- ICA para separación de fuentes independientes.
- t-SNE para visualización avanzada.
Implementación en Python
Scikit-Learn proporciona una implementación sencilla mediante la clase TSNE.
Ejemplo con el dataset Iris
from sklearn.datasets import load_iris
from sklearn.manifold import TSNE
iris = load_iris()
X = iris.data
y = iris.target
tsne = TSNE(
n_components=2,
perplexity=30,
random_state=42
)
X_tsne = tsne.fit_transform(X)
print(X.shape)
print(X_tsne.shape)
(150, 4)
(150, 2)Los datos originales de cuatro dimensiones se transforman en una representación bidimensional.
Visualización de los resultados
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
plt.scatter(
X_tsne[:,0],
X_tsne[:,1],
c=y,
cmap="viridis"
)
plt.xlabel("t-SNE 1")
plt.ylabel("t-SNE 2")
plt.title("Visualización mediante t-SNE")
plt.show()
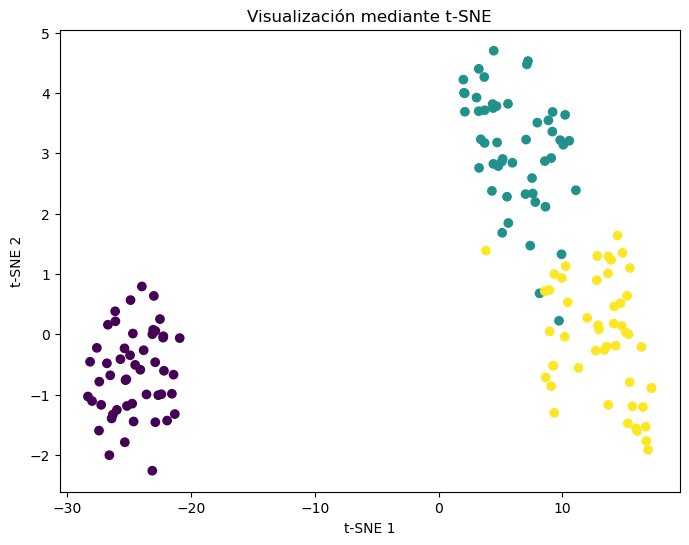
Ejemplo con Digits Dataset
from sklearn.datasets import load_digits
from sklearn.manifold import TSNE
digits = load_digits()
X = digits.data
y = digits.target
tsne = TSNE(
n_components=2,
perplexity=30,
random_state=42
)
X_tsne = tsne.fit_transform(X)
(1797, 64)
(1797, 2)import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
plt.scatter(
X_tsne[:,0],
X_tsne[:,1],
c=y,
cmap="viridis"
)
plt.xlabel("t-SNE 1")
plt.ylabel("t-SNE 2")
plt.title("Visualización mediante t-SNE")
plt.show()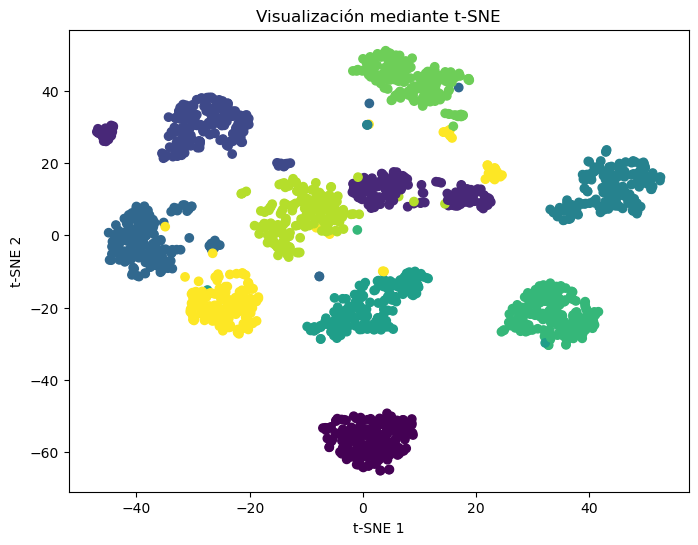
Conclusión
t-SNE es una de las técnicas más potentes para visualizar datos de alta dimensionalidad. Su capacidad para preservar relaciones locales y descubrir estructuras no lineales la convierte en una herramienta fundamental para el análisis exploratorio de datos, la interpretación de modelos y la investigación en Machine Learning.
Aunque no está diseñada para sustituir métodos de reducción dimensional tradicionales ni para servir como técnica predictiva, su utilidad para comprender la estructura interna de conjuntos de datos complejos es extraordinaria. Utilizada correctamente, t-SNE permite transformar grandes volúmenes de información multidimensional en representaciones visuales intuitivas que facilitan la identificación de patrones, agrupaciones y anomalías ocultas.