Reducción de Dimensionalidad y Visualización de Datos Complejos
UMAP (Uniform Manifold Approximation and Projection) es una técnica moderna de reducción de dimensionalidad no lineal diseñada para representar conjuntos de datos de alta dimensionalidad en espacios de menor dimensión conservando, en la medida de lo posible, la estructura de los datos originales.
Desarrollada por Leland McInnes, John Healy y James Melville en 2018, UMAP se ha convertido en una de las alternativas más populares a t-SNE gracias a su capacidad para generar visualizaciones de alta calidad, su mayor velocidad de ejecución y su mejor escalabilidad en grandes volúmenes de datos.
Actualmente, UMAP es ampliamente utilizado en Data Science, Machine Learning, Deep Learning, bioinformática, procesamiento del lenguaje natural y visión por computadora para explorar datos complejos y extraer patrones ocultos.
¿Qué es UMAP?
UMAP es una técnica de reducción de dimensionalidad basada en principios de:
- Teoría de variedades (Manifold Learning).
- Topología algebraica.
- Geometría diferencial.
- Teoría de grafos.
Su objetivo consiste en proyectar datos de alta dimensionalidad a un espacio de menor dimensión manteniendo tanto las relaciones locales como parte de la estructura global del conjunto de datos. La idea fundamental es asumir que los datos se encuentran distribuidos sobre una variedad matemática de menor dimensión dentro del espacio original.
Por ejemplo:
- Imágenes representadas por miles de píxeles.
- Embeddings de texto con cientos de dimensiones.
- Datos genómicos con miles de variables.
Aunque aparentemente complejos, estos datos suelen contener estructuras internas que pueden representarse en menos dimensiones sin perder gran parte de la información relevante.
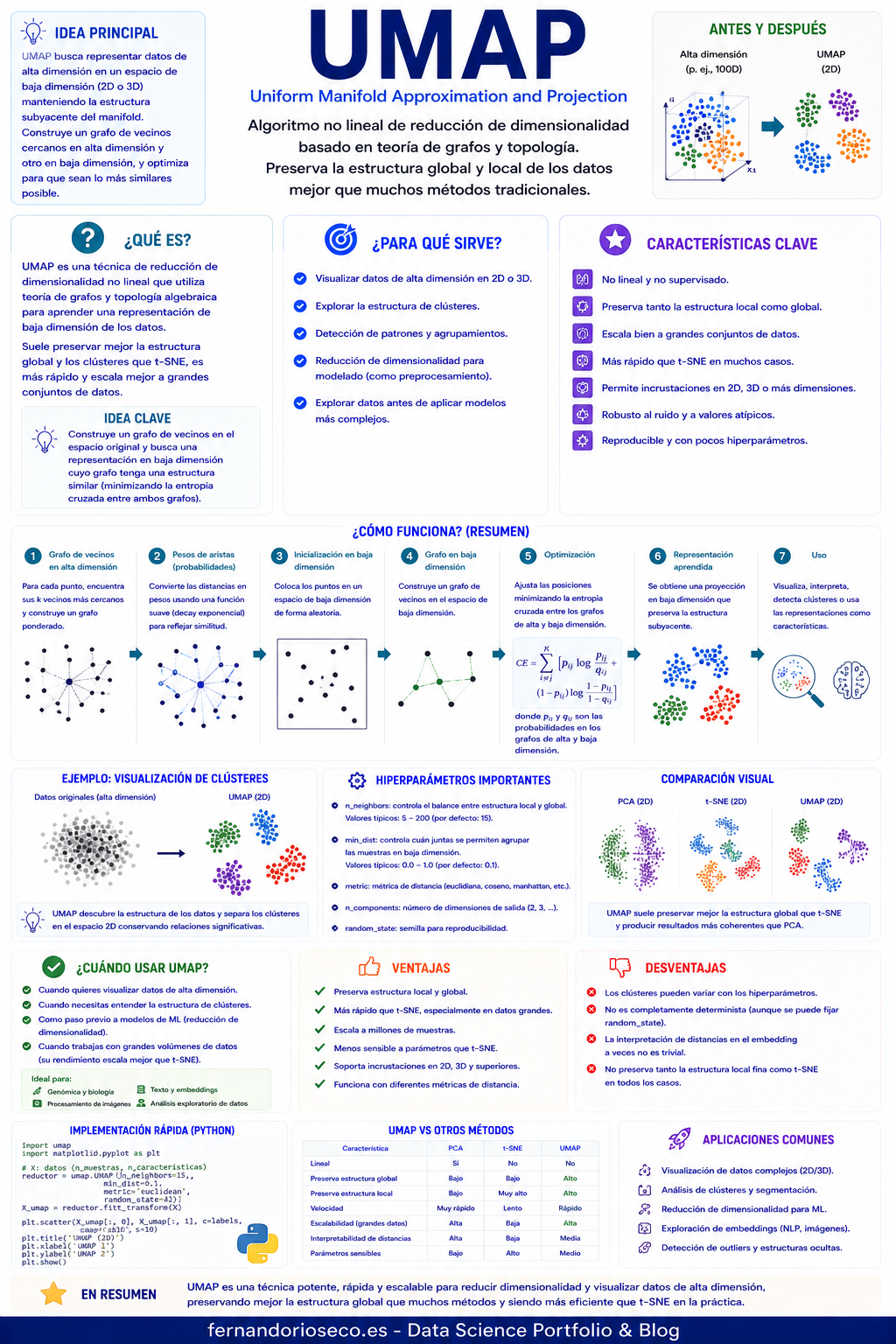
¿Cómo funciona UMAP?
UMAP trabaja en dos etapas principales.
Construcción de una representación topológica
Primero identifica las relaciones de vecindad entre observaciones.
Para ello:
- Calcula los vecinos más cercanos de cada punto.
- Construye un grafo ponderado.
- Estima la estructura local de los datos.
El concepto básico puede representarse mediante la distancia entre observaciones:
$$d(x_i,x_j)=||x_i-x_j||$$
A partir de estas distancias se genera una representación probabilística de las relaciones entre los puntos.
Optimización en baja dimensión
Posteriormente, el algoritmo busca una representación reducida que conserve la estructura del grafo original. Para ello minimiza una función de coste que mide la diferencia entre:
- Las relaciones en el espacio original.
- Las relaciones en el espacio reducido.
El resultado es una proyección de dos o tres dimensiones donde los puntos similares permanecen cercanos.
Fundamentos intuitivos de UMAP
La intuición detrás de UMAP es sencilla. Supongamos un conjunto de fotografías de animales. Cada imagen contiene miles de características numéricas.
UMAP intenta:
- Identificar cuáles imágenes son similares.
- Construir una red de relaciones entre ellas.
- Proyectar esa red en un espacio de menor dimensión.
Como resultado:
- Las imágenes de perros aparecen agrupadas.
- Las imágenes de gatos forman otro grupo.
- Las aves aparecen en una región distinta.
Todo ello conservando gran parte de la estructura original de los datos.
Ejemplo conceptual
Imaginemos una empresa de comercio electrónico con información de clientes basada en:
- Historial de compras.
- Frecuencia de visitas.
- Categorías preferidas.
- Tiempo de permanencia.
- Dispositivos utilizados.
- Interacciones con campañas.
El conjunto podría contener cientos de variables.
Aplicando UMAP es posible:
- Reducir la complejidad de los datos.
- Visualizar segmentos de clientes.
- Detectar grupos de comportamiento similares.
- Identificar posibles anomalías.
Parámetros más importantes de UMAP
El comportamiento del algoritmo depende principalmente de dos hiperparámetros.
- n_neighbors : Controla el número de vecinos considerados para construir la estructura local.
- Valores pequeños conservan patrones muy locales y detectan grupos pequeños.
- Valores grandes capturan estructuras más globales y generan agrupaciones más suaves. Los valores más habituales se encuentran entre 5 y 50.
- min_dist: Controla la distancia mínima permitida entre puntos en la representación final.
- Valores pequeños: generan grupos compactos y destacan mejor los clústeres.
- Valores grandes: distribuyen más los datos y conservan mejor la estructura global. Generalmente oscila entre: 0.0 y 0.5.
Beneficios de UMAP
- Excelente capacidad de visualización.
- Conserva relaciones locales y parte de las globales.
- Escala mejor que t-SNE.
- Menor tiempo de ejecución.
- Admite conjuntos de datos muy grandes.
- Funciona con relaciones no lineales.
- Puede utilizarse como técnica de preprocesamiento.
- Compatible con aprendizaje supervisado y no supervisado.
Por estas razones se ha convertido en una herramienta estándar en numerosos proyectos modernos de Machine Learning.
¿Cuándo utilizar UMAP?
- Se trabaja con datos de alta dimensionalidad.
- Se desea visualizar información compleja.
- Existen relaciones no lineales entre variables.
- Se requiere una alternativa rápida a t-SNE.
- Se necesita preprocesamiento para modelos posteriores.
Casos frecuentes:
- Exploración de datos.
- Análisis de embeddings.
- Segmentación de clientes.
- Bioinformática.
- Visión artificial.
- Procesamiento del lenguaje natural.
Ventajas
- Mayor velocidad que t-SNE.
- Mejor escalabilidad.
- Conservación simultánea de estructuras locales y globales.
- Capacidad para trabajar con millones de observaciones.
- Flexibilidad en la elección de métricas de distancia.
- Excelente calidad visual.
- Posibilidad de reutilizar el modelo para nuevos datos.
Además, UMAP puede utilizarse no solo para visualización sino también como etapa de reducción dimensional antes del entrenamiento de modelos predictivos.
Desventajas
- Sensibilidad a los hiperparámetros.
- Resultados diferentes según la inicialización.
- Interpretación matemática compleja.
- Posibilidad de generar agrupaciones artificiales si los parámetros no se ajustan correctamente.
- Requiere cierto conocimiento para optimizar sus resultados.
Limitaciones de UMAP
Aunque es una técnica muy potente, presenta algunas limitaciones.
- No preserva todas las distancias originales: prioriza relaciones locales y estructura topológica. Por ello, las distancias exactas entre grupos no siempre conservan su significado original.
- Dependencia de los hiperparámetros: Cambios en
n_neighborsymin_distpueden generar representaciones considerablemente distintas. - Complejidad matemática: La base teórica de UMAP es más sofisticada que la de técnicas clásicas como PCA, lo que dificulta su interpretación profunda.
- Posible pérdida de información: Como cualquier técnica de reducción dimensional parte de la información original se pierde. La representación final es una aproximación.
Diferencias entre PCA, t-SNE y UMAP
| Característica | PCA | t-SNE | UMAP |
|---|---|---|---|
| Tipo | Lineal | No lineal | No lineal |
| Velocidad | Muy alta | Baja | Alta |
| Escalabilidad | Excelente | Limitada | Muy buena |
| Conserva estructura local | Parcialmente | Muy bien | Muy bien |
| Conserva estructura global | Moderadamente | Limitado | Mejor |
| Uso para visualización | Bueno | Excelente | Excelente |
| Uso como preprocesamiento | Sí | Poco frecuente | Sí |
En muchos proyectos modernos, UMAP ha reemplazado a t-SNE debido a su mejor equilibrio entre rendimiento y calidad visual.
Aplicaciones en Data Science y Machine Learning
UMAP posee aplicaciones en numerosas disciplinas.
Machine Learning
- Reducción de dimensionalidad.
- Ingeniería de características.
- Preprocesamiento de datos.
- Visualización de modelos.
Deep Learning
- Análisis de embeddings.
- Visualización de representaciones latentes.
- Interpretación de redes neuronales.
Procesamiento del Lenguaje Natural
- Visualización de Word Embeddings.
- Análisis semántico.
- Exploración de documentos.
Bioinformática
- Análisis de secuenciación genética.
- Clasificación celular.
- Estudios de expresión génica.
Visión Artificial
- Agrupación de imágenes.
- Reconocimiento de patrones.
- Exploración de datasets visuales.
Marketing y Negocio
- Segmentación de clientes.
- Detección de anomalías.
- Análisis de comportamiento.
Implementación en Python
UMAP se encuentra disponible mediante la librería umap-learn.
pip install umap-learnEjemplo básico con Iris
from sklearn.datasets import load_iris
import umap
iris = load_iris()
X = iris.data
y = iris.target
reducer = umap.UMAP(
n_neighbors=15,
min_dist=0.1,
n_components=2,
random_state=42
)
X_umap = reducer.fit_transform(X)
print(X.shape)
print(X_umap.shape)
(150, 4)
(150, 2)El conjunto de datos se transforma de cuatro variables originales a una representación bidimensional.
Visualización de resultados
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
plt.scatter(
X_umap[:,0],
X_umap[:,1],
c=y,
cmap="viridis"
)
plt.xlabel("UMAP 1")
plt.ylabel("UMAP 2")
plt.title("Visualización mediante UMAP")
plt.show()
La representación suele mostrar una separación clara entre las diferentes especies del conjunto Iris.
Uso como preprocesamiento para Machine Learning
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
import umap
pipeline = Pipeline([
("umap", umap.UMAP(
n_components=20,
random_state=42
)),
("classifier", RandomForestClassifier())
])
pipeline.fit(X_train, y_train)
predictions = pipeline.predict(X_test)
Este enfoque permite reducir dimensionalidad antes de entrenar el modelo, disminuyendo la complejidad computacional y potencialmente mejorando el rendimiento.
Conclusión
UMAP es una de las técnicas de reducción de dimensionalidad más avanzadas y utilizadas actualmente en Data Science y Machine Learning. Su capacidad para preservar relaciones locales, mantener parte de la estructura global de los datos y escalar eficientemente a grandes conjuntos de información lo convierten en una alternativa muy atractiva frente a métodos tradicionales como PCA y t-SNE.
Gracias a su versatilidad, rapidez y calidad visual, UMAP se ha consolidado como una herramienta fundamental para la exploración de datos, la visualización de embeddings, la reducción de dimensionalidad y el preprocesamiento de modelos predictivos. Todo profesional que trabaje con datos de alta dimensionalidad debería conocer esta técnica y comprender cuándo aprovechar sus ventajas para obtener representaciones más informativas y útiles de sus datos.