¿Qué es la Validación de Datos?
La validación de datos (Data Validation) es el proceso de verificar que los datos cumplen una serie de reglas, restricciones y criterios de calidad antes de ser utilizados en análisis, informes, procesos de negocio o modelos de Machine Learning.
Su objetivo principal es garantizar que los datos sean correctos, completos, consistentes y adecuados para el propósito previsto.
La validación permite detectar errores, anomalías e inconsistencias antes de que afecten a la calidad de los análisis o al rendimiento de los modelos predictivos.
Por ejemplo, si una columna denominada “Edad” contiene valores negativos o superiores a 120 años, un proceso de validación debería identificar esos registros como inválidos.
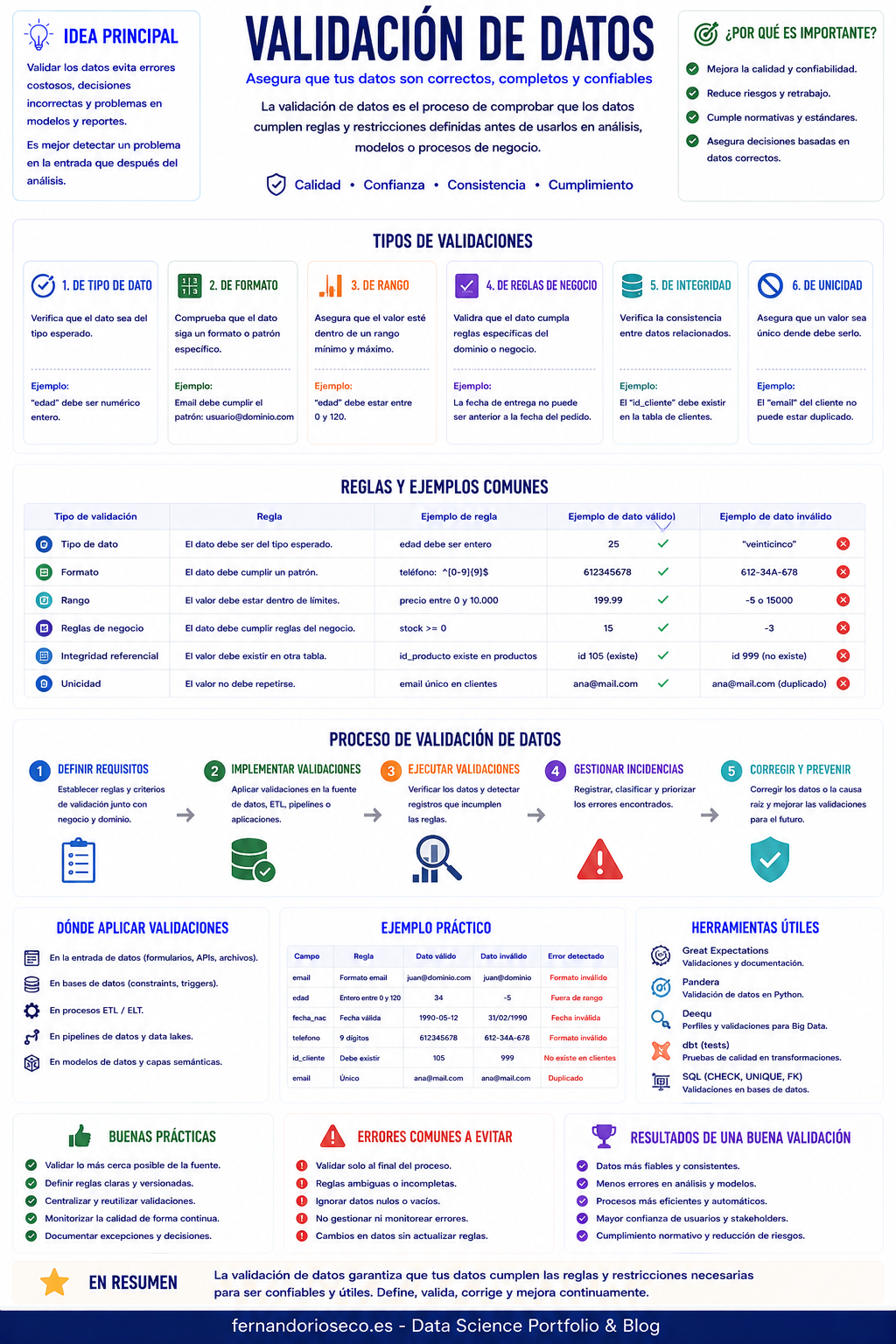
¿Por qué es importante la validación de datos?
Los datos pueden proceder de múltiples fuentes:
- Bases de datos.
- Formularios web.
- Sistemas ERP.
- CRM.
- APIs.
- Sensores IoT.
- Archivos CSV o Excel.
Durante su captura o integración pueden producirse errores que comprometan la calidad de la información.
Algunos ejemplos son:
- Campos obligatorios vacíos.
- Fechas incorrectas.
- Valores fuera de rango.
- Registros duplicados.
- Formatos inconsistentes.
- Relaciones inválidas entre tablas.
La validación ayuda a detectar estos problemas antes de que se propaguen a otras etapas del proyecto.
¿Cómo funciona la validación de datos?
El proceso consiste en definir reglas de calidad y comprobar si los datos las cumplen. Generalmente se siguen los siguientes pasos:
- Definir reglas de validación.
- Analizar los datos.
- Detectar incumplimientos.
- Generar alertas o informes.
- Corregir o rechazar registros inválidos.
- Volver a verificar los datos.
Las reglas pueden aplicarse a:
- Una columna individual.
- Varias columnas simultáneamente.
- Una tabla completa.
- Múltiples tablas relacionadas.
Tipos de validación de datos
- Validación de rango: Comprueba que un valor se encuentre dentro de límites permitidos.
- Validación de formato: Verifica que los datos sigan un formato determinado. Ejmp.: emails, teléfono, códigos postales, etc.
- Validación de obligatoriedad: Comprueba que determinados campos no estén vacíos.
- Validación de unicidad: Garantiza que ciertos valores no se repitan.
- Validación de consistencia: Verifica que diferentes campos sean coherentes entre sí. Ejmp: fecha inicio / fecha fin.
- Validación referencial: Comprueba relaciones entre tablas. Ejemplo: Cliente existente antes de crear un pedido, producto válido antes de registrar una venta.
Beneficios de la validación de datos
- Mejora la calidad de los datos.
- Reduce errores analíticos.
- Incrementa la fiabilidad de los modelos.
- Facilita el cumplimiento normativo.
- Evita problemas operativos.
- Incrementa la confianza en los resultados.
- Reduce costes derivados de datos incorrectos.
¿Cuándo utilizar la validación de datos?
- Durante la captura de datos.
- En procesos ETL.
- Antes del análisis exploratorio.
- Antes de entrenar modelos.
- Durante integraciones entre sistemas.
- En entornos productivos.
- Como parte de la monitorización continua.
La detección temprana de errores suele ser más eficiente que corregirlos posteriormente.
Ventajas
- Detecta errores rápidamente.
- Automatiza controles de calidad.
- Reduce problemas en etapas posteriores.
- Mejora la fiabilidad de los análisis.
- Facilita auditorías de datos.
- Puede integrarse en pipelines automatizados.
- Incrementa la confianza en los datos.
Desventajas
Aunque es una práctica fundamental, también presenta algunos inconvenientes:
- Requiere definir reglas adecuadas.
- Puede aumentar la complejidad de los procesos.
- Algunas validaciones son costosas computacionalmente.
- Puede generar falsos positivos.
- Necesita mantenimiento cuando cambian los requisitos del negocio.
Limitaciones
La validación de datos presenta ciertas limitaciones:
- No corrige automáticamente todos los errores.
- No detecta todos los problemas semánticos.
- Depende de las reglas definidas.
- Puede pasar por alto anomalías desconocidas.
- No garantiza datos perfectos.
Un dato puede cumplir todas las reglas técnicas y seguir siendo incorrecto desde el punto de vista del negocio.
Comparación entre validación y limpieza de datos
| Aspecto | Validación de Datos | Limpieza de Datos |
|---|---|---|
| Objetivo | Detectar problemas | Corregir problemas |
| Define reglas | Sí | No necesariamente |
| Corrige errores | No siempre | Sí |
| Automatización | Alta | Media |
| Prevención | Sí | Parcialmente |
| Diagnóstico | Sí | Parcialmente |
La validación identifica incumplimientos mientras que la limpieza se centra en corregirlos.
Comparación entre validación y perfilado de datos
| Aspecto | Validación de Datos | Perfilado de Datos |
|---|---|---|
| Basado en reglas | Sí | No necesariamente |
| Detecta incumplimientos | Sí | Sí |
| Analiza estadísticas | Limitado | Sí |
| Genera métricas descriptivas | No principalmente | Sí |
| Control de calidad | Alto | Medio |
El perfilado ayuda a comprender los datos y la validación verifica si cumplen criterios específicos.
Aplicaciones en Data Science y Machine Learning
La validación de datos es fundamental en:
- Machine Learning supervisado.
- Machine Learning no supervisado.
- Business Intelligence.
- Ingeniería de datos.
- Sistemas de recomendación.
- Detección de fraude.
- Analítica financiera.
- Analítica de clientes.
- Procesamiento de lenguaje natural.
- Visión por computador.
Cualquier proyecto basado en datos requiere algún nivel de validación para garantizar la calidad de la información.
Impacto en los modelos de Machine Learning
Los modelos predictivos pueden verse afectados por:
- Valores fuera de rango.
- Etiquetas incorrectas.
- Registros incompletos.
- Variables inconsistentes.
- Errores de formato.
Una validación adecuada ayuda a:
- Reducir ruido.
- Mejorar la precisión.
- Disminuir sesgos.
- Aumentar la robustez del modelo.
En muchos casos, mejorar la calidad de los datos genera más beneficios que modificar el algoritmo utilizado.
Implementación en Python
Validar valores nulos
import pandas as pd
df = pd.read_csv("datos.csv")
nulos = df.isnull().sum()
print(nulos)
Validar rangos numéricos
edades_invalidas = df[
(df["edad"] < 0) |
(df["edad"] > 120)
]
print(edades_invalidas)
Validar unicidad
duplicados = df[
df["id_cliente"].duplicated()
]
print(duplicados)
Validar formato de correo electrónico
import re
patron = r"^[\w\.-]+@[\w\.-]+\.\w+$"
emails_invalidos = df[
~df["email"].str.match(
patron,
na=False
)
]
print(emails_invalidos)
Validar fechas
fechas_invalidas = df[
df["fecha_fin"] <
df["fecha_inicio"]
]
print(fechas_invalidas)
Validación automática con Pandera
Una de las bibliotecas más utilizadas para validar datos en Python es Pandera.
pip install panderaEjemplo básico
import pandera as pa
from pandera import Column, DataFrameSchema
schema = DataFrameSchema({
"edad": Column(
int,
checks=pa.Check.in_range(
min_value=0,
max_value=120
)
)
})
schema.validate(df)
En caso de incumplimiento, Pandera generará una excepción indicando los registros inválidos.
Buenas prácticas
Al implementar validaciones es recomendable:
- Definir reglas claras desde el inicio.
- Automatizar validaciones repetitivas.
- Documentar todas las reglas de negocio.
- Validar datos antes de transformarlos.
- Registrar incidencias detectadas.
- Revisar periódicamente las reglas.
- Integrar la validación dentro de pipelines ETL y ML.
Conclusión
La validación de datos es un proceso fundamental para garantizar que la información utilizada en análisis y modelos de Machine Learning cumpla criterios mínimos de calidad, consistencia y fiabilidad. Mediante la aplicación de reglas específicas, permite detectar errores antes de que afecten a los resultados o generen decisiones incorrectas.
Aunque no sustituye a la limpieza de datos ni al perfilado, constituye una pieza clave dentro de cualquier estrategia de calidad de datos. Una validación adecuada reduce riesgos, mejora la confianza en la información y contribuye a desarrollar modelos analíticos más precisos y robustos.