Proyecto Capstone del Curso Data Science: Analytics Specialist, de Codecademy. Enl flujo de trabajo incluyó:
Transformacion y limpieza de datos – Geolocalizacion – Analisis extadistico – Vizualizacion de datos – Test de Hipotesis
Página del proyecto en GitHub:
https://github.com/fer78/Data-Analytics-Final-Portfolio-Project.git
Introducción
Tema de elección libre, este dataset es de datos reales sobre Real State en Kaggle: Spanish Housing Dataset. Originalmente, fue recopilado mediante web scraping del portal de Idealista S.A.U.
Este proyecto se centra en analizar el segmento de apartamentos dentro del mercado inmobiliario español. Los apartamentos son un tipo de vivienda especialmente relevante en áreas urbanas y suburbanas, donde la demanda de opciones accesibles y funcionales es elevada.
Este análisis tuvo como objetivo ofrecer una comprensión detallada de las características, tendencias y factores que influyen en el precio y la disponibilidad de apartamentos en distintas regiones. Mediante técnicas de análisis exploratorio de datos (EDA), se identificaron patrones clave y correlaciones importantes que aportaron información de valor para compradores, inversores y otros actores del sector inmobiliario.
Aunque el análisis principal se centra en el segmento de apartamentos, la fase de transformación de datos se realizará sobre el conjunto completo del dataset. Este enfoque permite construir un DataFrame limpio y preparado para futuros análisis que puedan involucrar otros tipos de propiedades y segmentos del mercado.
Objetivos
El objetivo principal de este proyecto fue realizar un análisis estadístico de apartamentos y viviendas unifamiliares en venta en diversas provincias españolas durante el año 2019. El análisis utilizará técnicas de geolocalización y herramientas de visualización como Tableau.
Dado que el público objetivo incluye inversores y compradores privados de Estados Unidos, la terminología se ha adaptado a su contexto.
Los objetivos específicos del estudio son:
- Limpiar y explorar los datos para garantizar precisión y fiabilidad.
- Utilizar técnicas de geolocalización para convertir las direcciones de las propiedades en coordenadas geográficas.
- Calcular y resumir medidas estadísticas clave relacionadas con los precios y características de las viviendas.
- Visualizar la distribución geográfica e identificar diferencias de precios entre regiones.
- Analizar la relación entre las características de la propiedad y su precio.
- Aplicar técnicas de clustering para identificar patrones y segmentar el mercado inmobiliario.
- Realizar pruebas de hipótesis para comparar precios entre regiones y analizar el impacto de características específicas.
- Diseñar y construir un dashboard interactivo en Tableau para una exploración dinámica de los datos.
- Presentar las conclusiones principales del análisis y ofrecer recomendaciones prácticas basadas en los resultados obtenidos en un documento o presentación.
Fuente y Estructura de los Datos
El dataset contiene los datos en bruto, cuenta con 100.000 registros en 41 variables extraídas de las paginas en que se describen los anuncios inmobiliarios de la web. Incluyen características de la vivienda como el precio, tamaño, estado, dirección, ciudad, aire acondicionado, jardín, piscina, etc. Los datos están estructurados con identificadores claros e incluyen variables categóricas y numéricas, lo que permite realizar un análisis sólido.
Una muestra del primer registro del dataframe crudo para poder examinar rápidamente la estructura de los datos:
print(raw_data.head(1).T) 0
ad_description Precio chalet individual en la localidad de Ab...
ad_last_update Anuncio actualizado el 27 de marzo
air_conditioner 0
balcony 0
bath_num 2
built_in_wardrobe 0
chimney 0
condition segunda mano/buen estado
construct_date NaN
energetic_certif NaN
floor 2 plantas
garage plaza de garaje incluida en el precio
garden 1
ground_size NaN
heating NaN
house_id 81717634
house_type Casa o chalet independiente
kitchen NaN
lift NaN
loc_city Urcabustaiz
loc_district La iglesia
loc_full La iglesia , Urcabustaiz , Zuya, Álava
loc_neigh NaN
loc_street NaN
loc_zone Zuya, Álava
m2_real 1000
m2_useful 172.0
obtention_date 2019-03-29
orientation norte, sur, este, oeste
price 310000
reduced_mobility 0
room_num 4
storage_room 0
swimming_pool 0
terrace 1
unfurnished NaN
number_of_companies_prov 19147
population_prov 328868
companies_prov_vs_national_% 0.57
population_prov_vs_national_% 0.70
renta_media_prov 19889.00
Transformación de datos
La transformación de datos en el trabajo se divide en 3 partes fundamentales.
1. Transformación inicial
En esta primera fase de transformación y depuración del conjunto de datos el objetivo es eliminar registros y variables que no aportan valor y asegurar que los datos estén en un formato adecuado para la geolocalización. Se aplican las siguientes operaciones:
- Data Filtering. Eliminar variables que no se van a utilizar en el análisis: Se eliminan 16 variables.
- Data Deduplication. Eliminar los datos duplicados: 6071 registros duplicados
- Handling Missing Data.
missing_values = raw_data.isnull().sum().sort_values(ascending=False)
print(missing_values[missing_values > 0])ground_size 93928
kitchen 91902
loc_street 80147
heating 69857
construct_date 63150
orientation 56789
garage 56130
loc_neigh 52086
m2_useful 44501
lift 38965
condition 13295
dtype: int64Es posible que algunas variables binarias tengan valores faltantes de tipo estructurales y deban reemplazarse por 0, como garage. Otras 9 variables con una gran cantidad de valores ausentes (más del 60% de los registros) se eliminan del conjunto de datos.
- Análisis individual por variables: esto incluye:
- Estandarización de categorías (conversión a la jerga del mercado americano)
- Corrección de valores inconsistentes
- Asignar tipos de datos correctos
Preparación para la geolocalización
- Data derivation:
- para estandarizar la variable de direcciones y poder utilizarla para la geolocalización se eliminan palabras como «Calle» y otras que no se utilizan.
- Se crea una variable nueva
city_provuniendoloc_cityyloc_zoney se utilizará como ubicación secundaria en caso de fallo de la dirección.
Finalmente, se guarda el dataset resultante con un nuevo nombre.
2. Geolocalización
Para obtener la latitud y longitud basada en la dirección utilizamos la librería geopy utilizando el geocodificador Nominatim. Un geolocalizador de código abierto que utiliza OpenStreetMap.
Dado el tamaño del dataset, geolocalizar todas las entradas de una sola vez sería ineficiente y podría provocar problemas de memoria y tiempos de procesamiento muy elevados. Para evitar esto, el archivo se divide en bloques de 10.000 filas.
El flujo de funciones utilizado para la geolocalización es el siguiente:
- create_chunks divide el DataFrame, guardar cada sección en disco.
- geolocate retorna un dataframe con la latitud, longitud y dirección completa obtenida por la geolocalización.
- split_address extrae de la dirección completa obtenida anteriormente el código postal, municipio y región.
- process_chunk procesa cada bloque ejecutando las funciones geolocate y split_address fila por fila e integra las nuevas variables, al final guarda el dataset procesado y libera la memoria.
- Se unen nuevamente los chunks procesados en un dataset que se guarda con un nuevo nombre.
Dispersión de coordenadas (Jitttering)
Una vez obtenemos las nuevas variables, preparamos el dataset para la fase de análisis. Una cuestión que se observó al realizar la geolocalización y representar las viviendas en mapa es que hay muchos casos en que es exactamente la misma. Esto ocurre por varias posibles razones:
- Ser parte de viviendas de un mismo edificio.
- Que la dirección no estaba en el formato correcto, por lo que la función de geolocalización utilizó la variable
city_provy solo geolocalizó la ciudad, en un punto central. - La existencia de propiedades en venta que no muestran su dirección exacta y comparten una ubicación genérica. Esto ocurre debido a una estrategia comercial utilizada por agentes inmobiliarios llamada blind listing. Con este método, la dirección real no se publica para proteger la información del vendedor y evitar que otros agentes o potenciales compradores contacten directamente con el propietario sin pasar por el agente encargado de la venta.
En este caso se utiliza una técnica para dispersar ligeramente puntos que tienen coordenadas idénticas o muy similares denominada jittering, facilitando la visualización y el análisis de datos. Para aplicar el jittering, se añade una pequeña cantidad de ruido aleatorio a las coordenadas de cada punto, permitiendo separarlos entre sí.
La función move_coordinates desplaza las coordenadas mediante un ángulo y distancia aleatorios proporcionados por la función disperse_coordinates. Este ángulo y distancia se convierten en grados de latitud y longitud y se suman a las coordenadas originales.
Así, múltiples propiedades con las mismas coordenadas se separan en diferentes posiciones alrededor del punto original. Una desventaja de esta técnica es que, si la ubicación está cerca de la costa, algunos puntos pueden terminar apareciendo sobre el mar.
La función disperse_coordinates primero agrupa todas las coordenadas duplicadas y luego aplica la función move_coordinates a cada registro, utilizando valores diferentes de ángulo y distancia dentro de los rangos definidos en los parámetros como distancia mínima y máxima desde el punto de coordenadas original.
Ejemplo de dispersión de coordenadas.
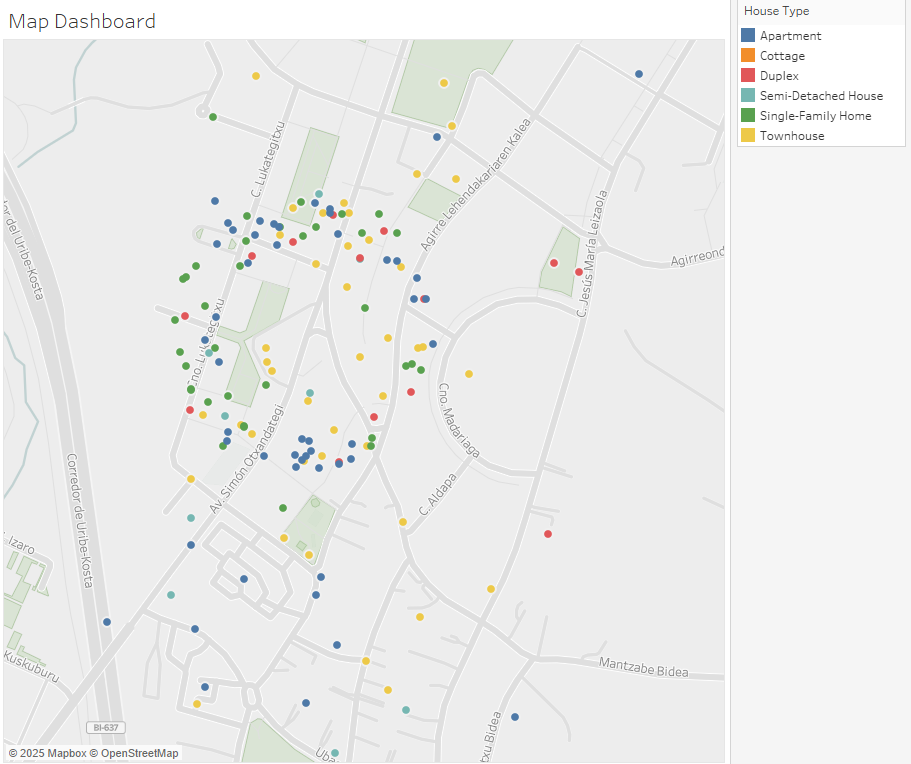
Una vez aplicada la dispersión se guarda el dataframe con un nuevo nombre.
3. Limpieza de datos para el análisis
Llegado a este punto, el dataframe tiene, 89948 registros y 19 columnas de las cuales 6 son creadas en el proceso de geolocalización.
processed_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 89948 entries, 0 to 89947
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 air_conditioner 89948 non-null int64
1 bath_num 89948 non-null int64
2 chimney 89948 non-null int64
3 condition 89948 non-null object
4 garage 89948 non-null object
5 garden 89948 non-null int64
6 house_type 89948 non-null object
7 m2_real 89948 non-null int64
8 price 89948 non-null float64
9 room_num 89948 non-null int64
10 storage_room 89948 non-null int64
11 swimming_pool 89948 non-null int64
12 terrace 89948 non-null int64
13 latitude 89948 non-null float64
14 longitude 89948 non-null float64
15 address 89948 non-null object
16 p_code 89948 non-null int64
17 region 89948 non-null object
18 municipality 89948 non-null object
dtypes: float64(3), int64(10), object(6)
memory usage: 13.0+ MBComenzamos el proceso de limpieza validando las coordenadas, los rangos para España son:
- Latitud: Entre 27.6°N (Islas Canarias) y 43.8°N (norte de España).
- Longitud: Entre -18.2°W (Islas Canarias) y 4.3°E (este de las Islas Baleares).
Representando las coordenadas obtenemos estos boxplots:
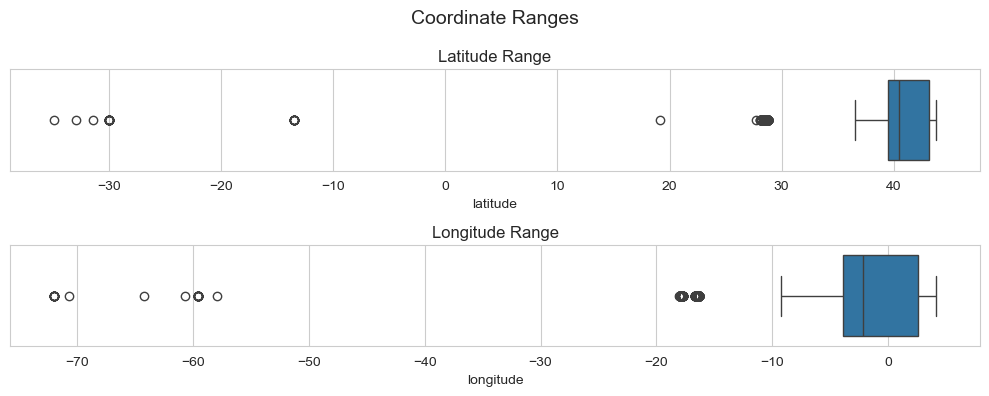
Código de la gráfica
fig, ax = plt.subplots(2,1, figsize=(10, 4))
sns.boxplot(x=processed_data['latitude'], ax=ax[0])
ax[0].set_title('Latitude Range')
sns.boxplot(x=processed_data['longitude'], ax=ax[1])
ax[1].set_title('Longitude Range')
fig.suptitle('Coordinate Ranges', fontsize=14)
plt.tight_layout()
plt.show()Tras contar los outliers de mas de 27.6 en la latitud y de más de -18.2 en la longitud, encontramos 37 registros fuera de rango que fueron eliminados.
Otros procesos de limpieza de datos que se realizaron fueron:
- Eliminar regiones con poca cantidad de registros.
- Eliminar tipos de viviendas que tienen pocos registros como: ranchos, mansiones, casas rurales, casas de campo, casas torres, palacios y castillos.
- Crear una nueva variable
price_segmentque agrupaba las viviendas en tres segmentos:- Affordable: hasta, €300,000.
- Mid-Range: desde, €300,000 a €700,000.
- Luxury: para más de €700,000.
- Tratamos los outliers en las variables que representaban el número de habitaciones, de baños, metros cuadrados, etc. Eliminamos los registros con datos inconsistentes como viviendas con valores 0 en baños o habitaciones.
- Al examinar la distribución de la variable
price, se observó una dispersión significativa entre los valores extremos y los cuartiles y se estableciendo un umbral mínimo de 10.000 y un máximo de 2 millones para los precios de las propiedades. El resto se eliminó del dataset. - Se creó una nueva variable
size_categoryque divide las viviendas en tres categorías:- Small: hasta 93 m².
- Medium: entre 94 m² y 232 m².
- Large: más de 232 m².
Procesar los valores atípicos
Finalmente, se realiza un proceso de eliminación de los outliers de forma segmentada:
- La función remove_outliers elimina valores atípicos usando el método del IQR (Rango Intercuartílico).
- La función clean_outliers_by_segment aplica la funcion anterior a segmentos del dataset para que cada grupo sea comparable consigo mismo.
- Primero por segmento de precio
- Dentro de cada segmento de precio, por tipo de vivienda
- Dentro de cada tipo de vivienda, por región
- Dentro de cada segmento de precio, por tipo de vivienda
- Primero por segmento de precio
De esta forma se procesan los valores atípicos de forma justa, respetando cada grupo.
Guardar el dataset
Al final de esta sección el dataframe está listo para el análisis estadístico y espacial, ha quedado con 77677 registros y 21 columnas. Un vistazo a un registro seria:
print(spain_housing.head(1).T)air_conditioner 0
bath_num 2
chimney 0
condition Resale
garage Not Included
garden 1
house_type Single-Family Home
m2_real 275
price 242000.00
room_num 3
storage_room 1
swimming_pool 1
terrace 1
latitude 38.59
longitude -0.14
address Urbanizatzación Convent de les Monges / Urbani...
p_code 3530
region Comunidad Valenciana
municipality Alicante
price_segment Affordable
size_category Large
Análisis de los datos
Los datos son analizados por segmento de precio con visualizaciones que muestran las relaciones y correlaciones entre las variables.
Para hacer más eficiente la ejecución de las visualizaciones se crea un fichero de python con funciones que muestran las visualizaciones para cada caso. El fichero se importa para utilizar las funciones.
Descripción de las funciones:
filterdf(df, col1, val1, col2, val2): Genera un dataframe filtrado por dos variables.binary_categorical_view(dataframe): Visualiza variables categóricas binarias:air_conditioner,chimney,garden,storage_room,swimming_pool,terrace.categorical_features_view(dataframe): Visualiza variables categóricas:room_num,bath_num,condition.boxplot_view(dataframe, column): Visualiza la distribución de una columna específica.boxplot_view_wo(dataframe, column): Visualiza la distribución de una columna específica sin mostrar valores atípicos.distribution_views(dataframe): Visualiza histogramas para las variables:m2_real,price.bivariate_distribution(dataframe, group_col, target_col, show_outliers, figsize): Muestra diagramas de caja de una variable agrupada por los valores de otra y muestra una tabla con el resumen estadístico.plot_histogram(df, column, bins=20, kde=True, figsize=(10, 6), xlim=None): Muestra un histograma de una variable, con opción de segmentar.plot_rooms_bathrooms_distribution(df): Muestra la distribución de baños y habitaciones de un segmento.plot_category_histograms(df, numeric_col, category_col): muestra el histograma de valores categóricos.- plot_histogram(df, column): Muestra un histograma.
- plot_binary_categorical_relationships(dataframe, target_variable): muestra la relación entre una variable numérica y las variables binarias del dataset y muestra una tabla resumen.
correlation_heatmap_by_size_category(df): Muestra un mapa de correlación por las categorías de tamaño.plot_distribution_by_price_segment(df): Agrupa datos por segmento de precio y tipo de propiedad, generando un mapa de calor.
Ejemplo de una función de vizualización del proyecto del fichero funtions.py :
def bivariate_distribution(dataframe, group_col, target_col, show_outliers=True, figsize=(10, 6)):
"""
Displays a boxplot and a summary table of a variable grouped by another variable's values.
"""
df_copy = dataframe.copy()
# Boxplot
plt.figure(figsize=figsize)
ax = sns.boxplot(data=df_copy, x=group_col, y=target_col, showfliers=show_outliers, palette="pastel")
plt.title(f'Boxplot of {target_col} by {group_col} with Mean Values')
plt.xlabel(group_col)
plt.ylabel(target_col)
plt.xticks(rotation=45)
plt.show()
# Summary Statistics table
summary_stats = df_copy.groupby(group_col)[target_col].agg(
mean=lambda x: round(x.mean(), 2),
Q1=lambda x: x.quantile(0.25),
Q3=lambda x: x.quantile(0.75),
std_dev=lambda x: round(x.std(), 2)
).reset_index()
summary_stats = summary_stats.sort_values(by='mean', ascending=False).reset_index(drop=True)
print(f"Summary Table of {target_col} by {group_col} sorted by Mean:")
print(summary_stats)bivariate_distribution(affordable_apartments, 'region', 'price', show_outliers=False)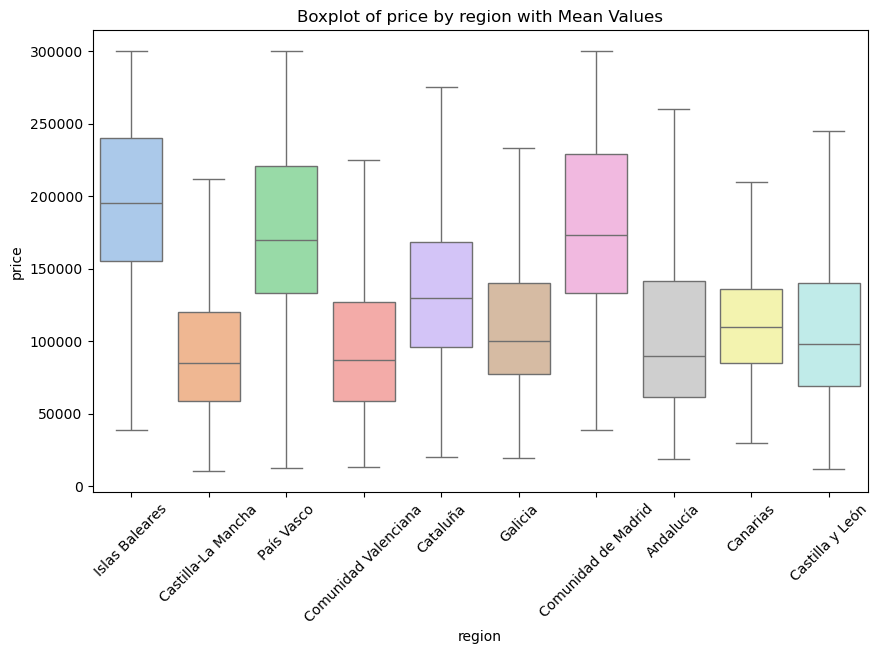
Summary Table of price by region sorted by Mean:
region mean Q1 Q3 std_dev
0 Islas Baleares 197767.25 155000.00 240000.00 56301.50
1 Comunidad de Madrid 180755.40 133350.00 229000.00 59592.77
2 País Vasco 176976.07 133000.00 220794.00 60137.55
3 Cataluña 133926.13 96000.00 168000.00 50869.32
4 Galicia 116780.80 77000.00 140000.00 55973.88
5 Canarias 114996.06 85000.00 136000.00 41459.24
6 Castilla y León 108825.89 69000.00 140000.00 53845.32
7 Andalucía 104710.97 61650.00 141650.00 54689.41
8 Comunidad Valenciana 100787.91 59000.00 126800.00 58180.42
9 Castilla-La Mancha 94720.85 58555.00 120000.00 50163.13En cada sección del análisis de datos se exponen los allazgos encontrados y resumenes de los datos explorados. Puedes ver el informe del proyecto de datos que se encuentra en el sitio del proyecto en GitHub.
Pruebas de Hipótesis y Análisis Predictivo
En esta fase del proyecto se aplicaron metodologías estadísticas avanzadas para validar con rigor los patrones observados durante el análisis exploratorio (EDA) y para profundizar en el comportamiento del mercado inmobiliario a partir de modelos predictivos. El objetivo fue responder a una pregunta clave: ¿Qué factores influyen de manera real y demostrable en el precio de los apartamentos en España?
El enfoque se dividió en dos áreas:
- Pruebas de hipótesis, orientadas a determinar si las relaciones observadas en el EDA eran estadísticamente significativas.
- Modelos predictivos, diseñados para medir el impacto cuantitativo de variables geográficas en el precio final de los inmuebles.
Las validaciones fueron las siguientes:
1.Comparación de precios entre segmentos de tamaño: se realizó un ANOVA de una vía, con las siguientes hipótesis:
- H₀: No existen diferencias significativas entre los precios medios de los tres segmentos.
- H₁: Existe al menos una diferencia significativa entre ellos.
2. Impacto de la condición del inmueble en el precio: Otra tendencia observada en el EDA era que las viviendas nuevas tendían a ser más caras, mientras que las viviendas a reformar mostraban precios más ajustados. Para comprobarlo, se volvió a aplicar un ANOVA, esta vez comparando los precios según la condición del inmueble:
- Nueva
- Reventa
- Necesita reforma
3. Relación entre número de baños y precio: Esta prueba buscó determinar si el número de baños ejercía un impacto real sobre el precio final. Se aplicó una correlación de Pearson, con las hipótesis:
- H₀: No existe relación significativa entre el número de baños y el precio.
- H₁: Existe una relación significativa entre ambos.
4. Modelo predictivo: el impacto de la ubicación
Además de validar hipótesis, se construyó un modelo de regresión lineal para evaluar hasta qué punto las variables geográficas (latitud, longitud y región) explicaban la variabilidad del precio.
Este enfoque combinando exploración visual, pruebas de hipótesis y modelado matemático permitió transformar el análisis en un marco sólido para la toma de decisiones de negocio informadas, especialmente útil para:
- agentes inmobiliarios,
- compradores e inversores,
- analistas urbanos,
- desarrolladores y arquitectos,
- ayuntamientos y oficinas de desarrollo económico.
Gracias a ello, el proyecto avanza desde la descripción hacia la modelización predictiva, permitiendo no solo entender el mercado, sino también empezar a anticipar comportamientos futuros con mayor precisión.
Sitio del proyecto:
https://github.com/fer78/Data-Analytics-Final-Portfolio-Project.git