La distribución binomial es una de las herramientas más importantes en estadística y ciencia de datos. Aparece siempre que repetimos un experimento con dos posibles resultados —éxito o fracaso, sí o no, 1 o 0 — y queremos conocer la probabilidad de obtener cierto número de éxitos en un conjunto de intentos.
En esta clase veremos qué es, cómo se construye y por qué es tan útil para problemas reales como comprobar si una moneda está trucada, evaluar la precisión de un modelo o estimar tasas de éxito en marketing, medicina o industria.
Del experimento Bernoulli a la distribución Binomial
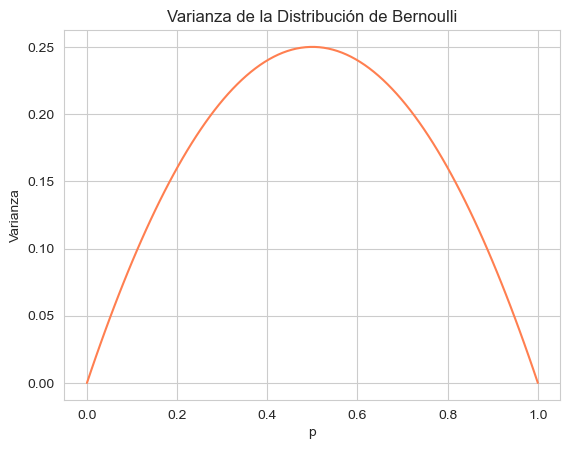
En el articulo anterior aborde la Distribución Bernoulli, que describe un experimento con dos resultados posibles:
- Éxito → se representa con 1
- Fracaso → se representa con 0
Si la probabilidad de éxito es p, entonces la probabilidad de fracaso es 1 – p.
La pregunta ahora es: ¿qué ocurre cuando repetimos este experimento varias veces?
Por ejemplo:
- Lanzar una moneda n veces
- Enviar n anuncios y medir si cada usuario hace clic
- Revisar n productos y ver si cada uno tiene defectos
La distribución que describe el número total de éxitos obtenidos en n intentos independientes es la Distribución Binomial.
Una aplicación real: ¿es justa una moneda? (Test de hipótesis)
Supón que quieres determinar si una moneda es justa.
Planteamos dos hipótesis:
- H₀ (Hipótesis nula): la moneda es justa → \( p = 0.5 \)
- H₁ (Hipótesis alternativa): la moneda no es justa → \( p \neq 0.5 \)
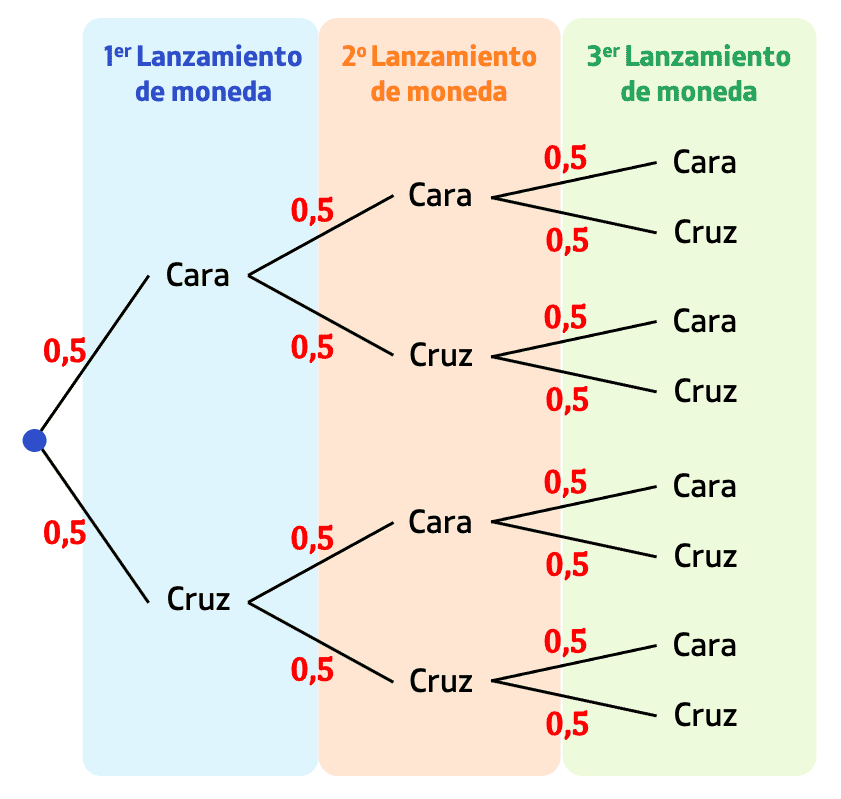
Lanzas la moneda n veces y defines:
$$X_i = \begin{cases}1, & \text{si sale cara} \\ 0, & \text{si sale cruz} \end{cases}$$
El número total de caras es:
$$S = X_1 + X_2 + \cdots + X_n$$
La pregunta clave es:
¿cuál es la probabilidad de que ocurra un determinado valor de S si la moneda es justa?
Responder a eso es exactamente el papel de la distribución binomial.
Construyendo la distribución binomial paso a paso
Caso S = 0 (todas cruces)
Para obtener 0 caras en n lanzamientos, todas deben ser cruces:
$$P(S=0) = (1 – p)^n$$
Solo existe una secuencia posible: TTTTT…T (n veces).
Caso S = 1 (una sola cara)
La probabilidad de que una secuencia concreta sea “una cara + n-1 cruces” es:
$$p(1-p)^{n-1}$$
Pero hay n posiciones posibles para esa única cara:
- Cara en el lanzamiento 1
- Cara en el lanzamiento 2
- …
- Cara en el lanzamiento n
Así que:
$$P(S=1) = n \cdot p(1-p)^{n-1}$$
Caso general: S = s
Para obtener exactamente s caras en n lanzamientos:
La probabilidad de una secuencia concreta es:
$$p^{s}(1-p)^{n-s}$$
El número de secuencias distintas que contienen exactamente s caras y n-s cruces es:
$$\begin{pmatrix} n \\ s \end{pmatrix}$$
que se lee “n elige s”.
Entonces, la probabilidad total es:
$$P(S=s) = \begin{pmatrix} n \\ s \end{pmatrix} p^{s}(1-p)^{n-s}$$
Esta es la fórmula de la distribución binomial.
¿Qué es el “n elige s”? La intuición del coeficiente binomial
El operador combinatorio:
$$ \begin{pmatrix} n \\ s \end{pmatrix} = \frac{n!}{s!(n-s)!}$$
cuenta cuántas formas hay de elegir s elementos dentro de un conjunto de n elementos, sin importar el orden.
Ejemplo clásico:
El número de manos posibles de 5 cartas tomadas de una baraja de 52 cartas es:
$$\begin{pmatrix}52 \\ 5 \end{pmatrix}$$
En nuestro contexto, representa cuántas secuencias distintas tienen s caras y n-s cruces.
¿Qué forma tiene la distribución binomial?
La distribución depende de dos parámetros:
- n → número de ensayos
- p → probabilidad de éxito en cada ensayo
Si aumentamos n (más repeticiones)
- El número máximo posible de éxitos crece
- La distribución se vuelve más “ancha” cuando se mira en términos de conteos
Pero si en vez de mirar S, miramos la fracción de éxitos:
$$\frac{S}{n}$$
lo que ocurre es que la distribución se estrecha alrededor de p. Esto conecta con la Ley de los Grandes Números.
Si cambiamos p (probabilidad de éxito)
- Si p aumenta → el histograma se desplaza hacia la derecha
- Si p disminuye → se desplaza hacia la izquierda
Cuando p = 0.5, la distribución es simétrica (si n es grande).
Propiedades importantes de la distribución binomial
Valor esperado (media)
$$E[S] = np$$
Varianza
$$Var(S) = np(1-p)$$
Aproximación normal (cuando n es grande)
Si (n) es suficientemente grande, la distribución binomial se aproxima a una normal:
$$S \approx \mathcal{N}(np, np(1-p))$$
Esto es extremadamente útil en estadística inferencial.
¿Para qué sirve la distribución binomial en ciencia de datos?
- Test A/B y marketing digital: Medir clics, conversiones o aperturas de email.
- Calidad industrial: Detectar la tasa de defectos.
- Modelos de clasificación: Analizar el número de aciertos vs. errores.
- Inferencia estadística: Construir intervalos de confianza para una proporción.
- Simulaciones y análisis de riesgo: Modelar escenarios de éxito/fracaso repetidos.
En Resumen
La distribución binomial:
- Surge al repetir un experimento Bernoulli n veces
- Modela el número de éxitos S en esas repeticiones
- Su fórmula combina:
- Probabilidad de una secuencia → \( p^s (1-p)^{n-s} \)
- Número de secuencias posibles → \( \begin{pmatrix} n \\ s \end{pmatrix} \)
- Tiene una estructura simple pero extremadamente poderosa
- Es fundamental en estadística, machine learning y análisis de datos aplicado