En ciencia de datos y estadística, las decisiones que tomamos dependen directamente de cómo analizamos la información. A menudo confiamos en medidas estadísticas como medias, proporciones o correlaciones para sacar conclusiones. Sin embargo, a veces las tendencias cambian drásticamente cuando separamos los datos en grupos o los combinamos.
A este fenómeno se le conoce como Paradoja de Simpson. En pocas palabras, ocurre cuando una tendencia observada en varios grupos individuales desaparece o incluso se invierte al combinar los datos de todos esos grupos.
Ejemplo clásico: recomendaciones de consolas de videojuegos
Imaginemos una encuesta sobre qué consola recomiendan más los usuarios, PS4 o Xbox One, separando las respuestas por género:
Grupos
PS4
Xbox One
Masculino
50/150 = 33%
180/360 = 50%
Femenino
200/250 = 80%
36/40 = 90%
Combinado
250/400 = 62.5%
216/400 = 54%
A primera vista, tanto hombres como mujeres prefieren Xbox One dentro de sus respectivos grupos. Pero al combinar los datos, PS4 parece ser la consola más recomendada.
Esto parece contradictorio —y lo es. La paradoja surge porque las proporciones se interpretan sin tener en cuenta el tamaño de cada grupo.
En este caso:
Xbox One tiene muchas más respuestas de hombres (360) que de mujeres (40).
PS4 tiene el patrón opuesto: muchas más respuestas femeninas (250) que masculinas (150).
Cuando agregamos los datos, los tamaños de muestra desiguales alteran la tendencia global. Este es el corazón de la Paradoja de Simpson: una conclusión opuesta al combinar los datos frente a cuando se analizan por separado.
Cómo reproducir la paradoja en Python
Podemos ilustrar el efecto con un pequeño ejemplo:
import pandas as pd# Datos de ejemplodata = pd.DataFrame({'consola': ['PS4']*400 + ['Xbox One']*400,'genero': ['Hombre']*150 + ['Mujer']*250 + ['Hombre']*360 + ['Mujer']*40,'recomienda': ( [1]*50 + [0]*100 + # PS4 hombres [1]*200 + [0]*50 + # PS4 mujeres [1]*180 + [0]*180 + # Xbox hombres [1]*36 + [0]*4# Xbox mujeres )})# Tasas por grupoprint(data.groupby(['consola','genero'])['recomienda'].mean().unstack())# Tasa global combinadaprint('\nTasas globales:')print(data.groupby('consola')['recomienda'].mean())
Salida:
genero Hombre Mujerconsola PS4 0.33 0.80Xbox One 0.50 0.90Tasas globales:consolaPS4 0.625Xbox One 0.540
La paradoja aparece claramente: las preferencias se invierten al combinar los grupos.
Un ejemplo del mundo real: tratamientos de salud mental
La paradoja de Simpson no es solo una curiosidad estadística. En el mundo real se ha observado en áreas críticas como la medicina, educación, o economía.
Considera un estudio sobre la efectividad de dos terapias para la depresión:
Tipo de depresión
Terapia A
Terapia B
Ligera
81/87 = 93%
234/270 = 87%
Severa
192/263 = 73%
55/80 = 69%
Combinado
273/350 = 78%
289/350 = 83%
Aquí, la Terapia A funciona mejor tanto para casos leves como severos. Sin embargo, al combinar los datos, parece que la Terapia B es más efectiva.
¿Por qué? Porque el número de pacientes tratados con cada terapia y tipo de depresión no es el mismo. En los casos leves (que tienen tasas altas de éxito), la mayoría recibió la Terapia A, mientras que los casos severos (con tasas más bajas) se concentraron más en la Terapia B.
La gravedad de la depresión es una variable de confusión, es decir, un factor no considerado que afecta el resultado global.
Lecciones de la Paradoja de Simpson
El contexto importa. Los datos sin contexto pueden llevar a conclusiones erróneas. Siempre debemos preguntarnos qué factores ocultos pueden estar influyendo en las relaciones observadas.
Analiza por subgrupos antes de agregar. Las tendencias globales pueden esconder comportamientos opuestos en segmentos individuales.
El tamaño de muestra importa. No todos los grupos tienen el mismo peso; las proporciones deben interpretarse considerando cuántos datos hay en cada grupo.
Correlación no implica causalidad. Que dos variables se muevan juntas no significa que una cause a la otra. La paradoja de Simpson es una excelente demostración de esto.
En Resumen
La Paradoja de Simpson nos recuerda que los datos nunca cuentan toda la historia por sí solos.
Antes de tomar decisiones basadas en estadísticas agregadas, debemos explorar los subgrupos y buscar posibles variables de confusión que puedan estar distorsionando la interpretación.
En análisis de datos, la clave no es solo calcular, sino entender. Porque a veces, los promedios engañan más de lo que explican.
En este articulo veremos cómo estudiar la asociación entre dos variables categóricas.
Ejemplo: Inventario de Personalidad Narcisista (NPI-40)
El Inventario de Personalidad Narcisista (NPI-40) es un cuestionario que evalúa rasgos narcisistas a través de 40 ítems con opciones A o B. Las respuestas se puntúan para determinar el nivel de narcisismo, que puede variar de bajo a muy alto. Se aclara que este inventario no es un diagnóstico clínico, sino una herramienta para medir características de personalidad. Cada pregunta tiene dos posibles respuestas: “sí” o “no”.
Algunas de las preguntas incluidas en este ejemplo son:
influence:
yes → “Tengo un talento natural para influir en las personas.”
no → “No soy bueno para influir en las personas.”
blend_in:
yes → “Prefiero mezclarme con la multitud.”
no → “Me gusta ser el centro de atención.”
special:
yes → “Creo que soy una persona especial.”
no → “No soy mejor ni peor que la mayoría.”
leader:
yes → “Me veo como un buen líder.”
no → “No estoy seguro de ser un buen líder.”
authority:
yes → “Me gusta tener autoridad sobre otras personas.”
no → “No me importa seguir órdenes.”
Como puedes imaginar, las respuestas a algunas de estas preguntas están asociadas entre sí. Por ejemplo, alguien que se considera líder también podría tender a disfrutar de tener autoridad.
Tablas de Contingencia de Frecuencias
Una forma práctica de resumir la relación entre dos variables categóricas es mediante una tabla de contingencia (también conocida como tabla cruzada o de doble entrada). Podemos construirla fácilmente en pandas con crosstab().
Supongamos que queremos analizar la relación entre influence (creerse bueno para influir en los demás) y leader (verse como líder):
import pandas as pdinfluence_leader_freq = pd.crosstab(npi.influence, npi.leader)print(influence_leader_freq)
Resultado:
leader no yesinfluenceno 3015 1293yes 2360 4429
Esta tabla muestra cuántas personas dieron cada combinación de respuestas. Por ejemplo:
3015 personas respondieron “no” a ambas preguntas.
4429 personas respondieron “sí” tanto a influence como a leader.
Observación: si alguien se ve como líder, es más probable que también piense que tiene talento para influir en los demás. Esto ya sugiere una posible asociación entre ambas variables.
Tablas de Contingencia de Proporciones
Para comparar mejor, es útil expresar las frecuencias como proporciones del total. Podemos hacerlo dividiendo entre el número total de observaciones:
leader no yesinfluenceno 0.272 0.117yes 0.213 0.399
Estas proporciones nos muestran que las categorías “sí/sí” (0.399) y “no/no” (0.272) son las más frecuentes. En otras palabras, casi el 40% de los participantes se ven como líderes y dicen tener talento para influir.
Proporciones Marginales
Ahora bien, incluso si no existiera relación entre las variables, las proporciones no se distribuirían equitativamente (no serían todas 0.25). Por ejemplo, puede que más de la mitad de las personas se consideren influyentes, lo cual afectará las proporciones. Las proporciones marginales resumen la fracción total de personas en cada categoría individual (por filas y columnas).
leader_marginals = influence_leader_prop.sum(axis=0)influence_marginals = influence_leader_prop.sum(axis=1)print("Marginal por líder:\n", leader_marginals)print("\nMarginal por influencia:\n", influence_marginals)
Resultado:
Marginal por líder:no 0.484yes 0.516Marginal por influencia:no 0.388yes 0.612
Esto nos dice que:
El 51.6% de las personas se consideran líderes.
El 61.2% piensa que tiene talento para influir.
Tablas de Contingencia Esperadas
Si las variables no estuvieran asociadas, podríamos predecir las proporciones esperadas multiplicando las proporciones marginales de cada categoría:
Líder = no
Líder = sí
Influencia = no
0.484 × 0.388 = 0.188
0.516 × 0.388 = 0.200
Influencia = sí
0.484 × 0.612 = 0.296
0.516 × 0.612 = 0.315
Si el total de observaciones es 11 097, podemos calcular las frecuencias esperadas:
Líder = no
Líder = sí
Influencia = no
0.188 × 11097 = 2087
0.200 × 11097 = 2221
Influencia = sí
0.296 × 11097 = 3288
0.315 × 11097 = 3501
Podemos obtener esta tabla automáticamente con SciPy:
from scipy.stats import chi2_contingencyimport numpy as npchi2, pval, dof, expected = chi2_contingency(influence_leader_freq)print(np.round(expected))
Salida:
[[2087. 2221.] [3288. 3501.]]
Estas son las frecuencias esperadas si no hubiera asociación entre las variables.
Comparación Observada vs Esperada
Tabla observada:
leader no yesinfluenceno 3015 1293yes 2360 4429
Tabla esperada (sin asociación):
leader no yesinfluenceno 2087 2221yes 3288 3501
Vemos diferencias notables: por ejemplo, hay 3015 observaciones reales en la celda (no/no), cuando esperaríamos 2087. Esto sugiere que las variables están efectivamente asociadas.
La Estadística Chi-Cuadrado (χ²)
Para cuantificar la diferencia entre ambas tablas, utilizamos la prueba Chi-Cuadrado de independencia. La fórmula general es:
Cómo evaluar la asociación entre una variable cuantitativa (por ejemplo, una puntuación o precio) y una variable categórica (por ejemplo, tipo de escuela, zona, o profesión).
Ejemplo: Datos de Estudiantes
Supongamos que tenemos un conjunto de datos de estudiantes de dos escuelas portuguesas. Contiene la siguiente información:
school: escuela del alumno → Gabriel Pereira ('GP') o Mousinho da Silveira ('MS')
address: zona de residencia → 'U' urbana o 'R' rural
absences: número de ausencias durante el curso
Mjob: profesión de la madre
Fjob: profesión del padre
G3: puntuación final del alumno en matemáticas (0 a 20)
Queremos responder:
¿Las puntuaciones de matemáticas (G3) están asociadas con la escuela a la que asisten los estudiantes?
Si es así, conocer la escuela podría ayudarnos a predecir el rendimiento académico.
Diferencias de Medias y Medianas
Una forma inicial de explorar esta relación es comparar las medias y medianas de las puntuaciones en cada grupo.
import numpy as np# Dividir los puntajes según la escuelascores_GP = students.G3[students.school == 'GP']scores_MS = students.G3[students.school == 'MS']# Calcular mediasmean_GP = np.mean(scores_GP)mean_MS = np.mean(scores_MS)mean_diff = mean_GP - mean_MSprint(f"Media GP: {mean_GP:.2f}")print(f"Media MS: {mean_MS:.2f}")print(f"Diferencia de medias: {mean_diff:.2f}")
Resultado:
Media GP: 10.49 Media MS: 9.85 Diferencia de medias: 0.64
También podríamos usar la mediana en lugar de la media para reducir el efecto de valores extremos.
Median_GP: 12.00Median_MS: 11.00Diferencia de medianas: 1.00
Estas diferencias nos dan una idea inicial, pero no nos dicen si la diferencia es relevante o significativa. Para eso, es útil visualizar la dispersión de los datos.
Diagramas de Caja Comparativos
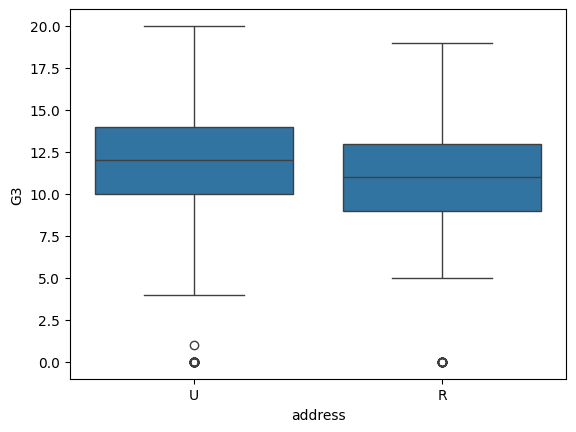
Los diagramas de caja (boxplots) permiten visualizar simultáneamente la distribución, mediana y variabilidad de una variable cuantitativa entre grupos. Esto puede ayudarnos a determinar si las diferencias de medias o medianas son “grandes” o “pequeñas”. Echemos un vistazo a los diagramas de caja de los puntajes de matemáticas en cada escuela:
import seaborn as snssns.boxplot(data = students, x = 'address', y = 'G3')plt.show()
Estos gráficos nos permiten ver si una escuela o zona tiene valores consistentemente más altos, o si las distribuciones se superponen mucho.
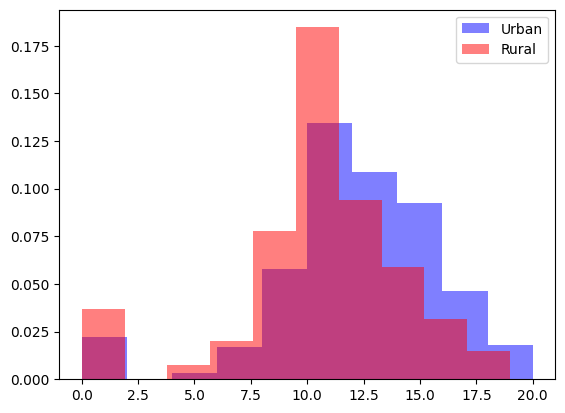
Histogramas Superpuestos
Otra opción es comparar las distribuciones con histogramas superpuestos. Aquí usamos alpha=0.5 para hacerlos semitransparentes, y density=True para que representen proporciones, no frecuencias absolutas (lo cual es importante si los grupos tienen tamaños distintos).
Si las curvas están muy superpuestas → la asociación es débil.
Si una está claramente desplazada a la derecha → hay una diferencia consistente entre grupos.
Las colas o picos distintos pueden revelar variabilidad o subgrupos (por ejemplo, alumnos destacados).
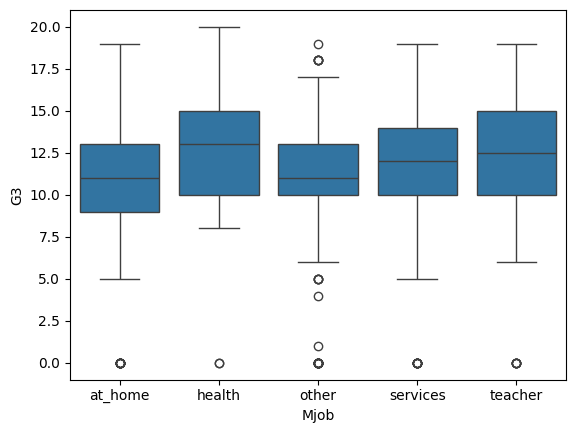
Variables Categóricas No Binarias
Hasta ahora, hemos trabajado con variables categóricas binarias (dos grupos). Pero ¿Qué ocurre si la categoría tiene más de dos valores?
Por ejemplo, la profesión de la madre (Mjob) puede tener cinco categorías:
at_home
health
services
teacher
other
Podemos visualizar la relación con un boxplot múltiple:
sns.boxplot(data = students, x = 'Mjob', y = 'G3')plt.show()
Aquí evaluamos todas las comparaciones por pares. Si al menos un grupo tiene una distribución diferente (por ejemplo, “health” con valores más altos), podemos decir que existe asociación entre las variables.
En este articulo se explora la correlación entre diferentes factores y se estima hasta qué punto son confiables sus relaciones. Además, aborda sobre los diferentes tipos de análisis que podemos realizar para descubrir la relación entre los datos: análisis univariado, bivariado y multivariado.
Cualquier conjunto de datos que queramos analizar tendrá diferentes campos (columnas) con múltiples observaciones (filas). Estas variables suelen estar relacionadas entre sí, ya que se recopilan del mismo fenómeno. Un campo puede influir o no sobre otro; para entenderlo, necesitamos detectar las dependencias existentes entre variables.
La fuerza de la relación entre dos campos de un conjunto de datos se llama correlación, y se representa con un número entre -1 y 1.
En otras palabras, la correlación es una técnica estadística que mide y describe cómo se relacionan y varían juntas dos variables. Nos permite responder preguntas como:
¿Cómo cambia una variable con respecto a otra?
Si cambia, ¿en qué grado o fuerza?
¿Podemos predecir una a partir de la otra?
Por ejemplo: la altura y el peso suelen estar relacionados. Las personas más altas tienden a pesar más que las más bajas. Si encontramos una persona más alta que el promedio, es razonable esperar que también pese más que el promedio.
Qué es el Coeficiente de Correlación
La correlación nos indica cómo cambian las variables juntas, ya sea en la misma dirección o en direcciones opuestas, y la fuerza de esa relación. El coeficiente de correlación de Pearson \(ρ\) o \(r\) mide esta relación y se calcula como:
\( \text{cov}(x, y)\) es la covarianza entre las variables,
\( \sigma_x \) y \( \sigma_y \) son sus desviaciones estándar.
El valor de ( r ) varía entre -1 y +1:
Valor de r
Tipo de correlación
Interpretación
+1
Perfecta positiva
Ambas variables crecen juntas
0
Nula
No hay relación lineal
-1
Perfecta negativa
Una crece mientras la otra disminuye
Valores cercanos a |1| indican una relación fuerte, mientras que los cercanos a 0 indican una relación débil o inexistente.
Visualización: Diagramas de Dispersión
Los diagramas de dispersión son herramientas visuales clave para observar la correlación entre dos variables.
A continuación, veremos ejemplos con Python.
import matplotlib.pyplot as pltimport numpy as np# Generar datos simuladosx = np.linspace(1, 10, 10)y_pos = 2.5 * x + np.random.normal(0, 1, 10) # correlación positivay_neg = -2.5 * x + np.random.normal(0, 1, 10) # correlación negativay_none = np.random.normal(5, 5, 10) # sin correlación# Crear figurasfig, axs = plt.subplots(1, 3, figsize=(12, 4))axs[0].scatter(x, y_pos, color='green')axs[0].set_title('Correlación Positiva')axs[1].scatter(x, y_neg, color='red')axs[1].set_title('Correlación Negativa')axs[2].scatter(x, y_none, color='gray')axs[2].set_title('Sin Correlación')for ax in axs: ax.set_xlabel('Variable X') ax.set_ylabel('Variable Y') ax.grid(True)plt.tight_layout()plt.show()
Cuanto más se acerquen los puntos a una línea recta, mayor será la correlación. Si los puntos están dispersos sin formar ningún patrón, la correlación es baja o inexistente.
Correlación No Implica Causalidad
Una frase muy importante en estadística es:
“La correlación no implica causalidad.”
Esto significa que dos cosas pueden estar relacionadas sin que una cause la otra. Por ejemplo:
En invierno la gente compra más sopa caliente. Pero el frío no causa que la gente gaste más dinero; ambos fenómenos están relacionados por un tercer factor (la estación del año).
Las ventas de helado y los homicidios aumentan simultáneamente durante el verano. No significa que comer helado cause homicidios; ambos están correlacionados por la temperatura, que influye en ambos comportamientos.
Por tanto, una correlación fuerte no garantiza una relación de causa-efecto. Antes de sacar conclusiones, es crucial analizar los factores subyacentes.
Análisis Bivariado
El análisis bivariado estudia la relación entre dos variables. Se usa para determinar si existe una relación y qué tipo de relación hay (positiva, negativa o nula). Por ejemplo, analicemos la relación entre el dinero invertido en publicidad y las ventas obtenidas:
Usando Numpy y Scipy:
import numpy as npfrom scipy import statsimport matplotlib.pyplot as plt# Datos ficticiospublicidad = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])ventas = np.array([10, 13, 19, 23, 26, 33, 38, 41, 47])# Calcular coeficiente de correlación con Numpycorrelacion = np.corrcoef(publicidad, ventas)[0, 1]print(f"Coeficiente de correlación de Pearson: {correlacion:.3f}")# Calcular coeficiente de correlación con Scipycorr = stats.pearsonr(publicidad, ventas)print("Correlación:", corr[0])# Graficarplt.scatter(publicidad, ventas, color='blue', label='Datos')m, b = np.polyfit(publicidad, ventas, 1)plt.plot(publicidad, m*publicidad + b, color='red', label='Línea de mejor ajuste')plt.xlabel("Dólares en publicidad")plt.ylabel("Ventas")plt.title("Análisis Bivariado: Publicidad vs Ventas")plt.legend()plt.grid(True)plt.show()
Salida:
Coeficiente de correlación de Pearson: 0.997Correlación: 0.9973743231694302
Interpretación: Si el coeficiente de correlación \( r \) es cercano a 1, existe una relación positiva fuerte, lo que sugiere que al aumentar la inversión publicitaria, las ventas también aumentan.
Análisis Multivariado
El análisis multivariado examina tres o más variables al mismo tiempo, buscando relaciones más complejas. Se utiliza cuando queremos entender cómo varias variables interactúan entre sí para predecir un resultado.
Ejemplo: predecir el precio de una casa según tamaño, ubicación y número de habitaciones.
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionimport numpy as npdata = pd.DataFrame({'tamaño_m2': [45, 55, 65, 75, 85, 95, 105, 115],'habitaciones': [1, 2, 2, 3, 3, 3, 4, 4],'ubicacion': [5, 4, 3, 2, 4, 3, 2, 1], # zonas más caras no siempre coinciden con mayor tamaño'precio': [160000, 170000, 185000, 190000, 210000, 220000, 240000, 230000]})# Variables independientes y dependienteX = data[['tamaño_m2', 'habitaciones', 'ubicacion']]y = data['precio']# Crear y entrenar el modelomodelo = LinearRegression()modelo.fit(X, y)# Mostrar resultadosprint("Coeficientes:", modelo.coef_)print("Intercepto:", modelo.intercept_)# --- Gráfico de correlaciones ---plt.figure(figsize=(8, 6))sns.heatmap(data.corr(), annot=True, cmap='coolwarm', fmt=".2f", linewidths=0.5)plt.title("Mapa de calor de correlaciones", fontsize=14)plt.show()
Coeficiente de tamaño_m2: 1800 ➜ Por cada metro cuadrado adicional, el precio sube 1,800 €, manteniendo las demás variables constantes.
Coeficiente de habitaciones: 22000 ➜ Añadir una habitación aumenta el precio promedio en 22,000 €, suponiendo mismo tamaño y ubicación.
Coeficiente de ubicacion: -9000 ➜ En este ejemplo, los valores de ubicación están codificados de forma que un número menor representa una zona mejor. Por eso el coeficiente es negativo: al bajar el número (mejor ubicación), aumenta el precio.
Intercepto: 11,000 ➜ Es el valor base del modelo cuando todas las variables valen 0 (solo tiene sentido teórico, no real).
El análisis multivariado permite estimar el efecto combinado de múltiples variables y mejorar la precisión de las predicciones.
Limitaciones de la Correlación
La correlación solo mide relaciones lineales. Puede ser engañosa cuando la relación es curvilínea o no lineal. Por ejemplo, los siguientes diagramas de dispersión muestran pares de variables con correlaciones cercanas a cero:
En uno de ellos, la relación es perfectamente horizontal (pendiente = 0).
En los demás, las relaciones son no lineales (curvas, cuadráticas, circulares, etc.).
En estos casos, la correlación no detecta la relación real, porque una línea recta no puede describir la forma del patrón.
Explorando la covarianza
Más allá de visualizar relaciones, también podemos utilizar estadísticas resumidas para cuantificar la fuerza de ciertas asociaciones. La covarianza es una estadística resumida que describe la fuerza de una relación lineal.
La covarianza puede variar desde infinito negativo hasta infinito positivo. Una covarianza positiva indica que un valor mayor de una variable está asociado con un valor mayor de la otra. Una covarianza negativa indica que un valor mayor de una variable está asociado con un valor menor de la otra. Una covarianza de 0 indica que no hay relación lineal. Aquí hay unos ejemplos:
Para calcular la covarianza, podemos usar la función cov() de NumPy, que produce una matriz de covarianza para dos o más variables . Una matriz de covarianza para dos variables se parece a esto:
Variable 1
Variable 2
Variable 1
varianza (Variable 1)
covarianza
Variable 2
covarianza
varianza (Variable 2)
En Python, podemos calcular esta matriz de la siguiente manera:
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as plt# Datos simulados de viviendasdata = pd.DataFrame({'tamaño_m2': [45, 55, 65, 75, 85, 95, 105, 115],'habitaciones': [1, 2, 2, 3, 3, 3, 4, 4],'ubicacion': [5, 4, 3, 2, 4, 3, 2, 1], # zonas más caras no siempre coinciden con mayor tamaño'precio': [160000, 170000, 185000, 190000, 210000, 220000, 240000, 230000]})# --- 1️⃣ Cálculo manual y con NumPy ---cov_matrix = np.cov(data['tamaño_m2'], data['precio'])cov_tamaño_precio = cov_matrix[0, 1]print("Matriz de Covarianza:\n", cov_matrix)print("\nCovarianza entre tamaño_m2 y precio:", round(cov_tamaño_precio, 2))
Salida:
Matriz de Covarianza:[[ 616.07142857 5687.5 ] [5687.5 53839285.71428572]]Covarianza entre tamaño_m2 y precio: 5687.5
Interpretación
El valor 5 687.5 es positivo, lo que significa que cuando el tamaño aumenta, el precio también tiende a aumentar.
Si fuera negativo, indicaría que los valores mayores de una variable se asocian con valores menores de la otra.
Si fuera cercano a 0, implicaría que no hay una relación lineal clara entre tamaño y precio.
La magnitud (qué tan grande es el número) depende de las unidades de medida. Por eso, la covarianza no es directamente comparable entre conjuntos de datos distintos. Para una medida normalizada e interpretable, se usa la correlación de Pearson, que va de -1 a +1.
¿Qué cubre el análisis de datos exploratorios avanzados?
Calcular la varianza de una variable.
Evaluar la distribución de los datos.
Informar sobre cuartiles, cuantiles y rango intercuartil.
Explorar datos categóricos.
Transformar los datos para satisfacer tus necesidades.
Varianza
Calcular la media, mediana y moda es un buen comienzo para comprender la forma general de un conjunto de datos. Pero esas tres estadísticas solo cuentan parte de la historia.
Ambos tienen la misma media y mediana (0), pero claramente no representan la misma dispersión. Ahí entra en juego la varianza, que describe qué tan dispersos están los datos.
Distancia desde la media
Intuitivamente, queremos que la varianza sea mayor cuando los datos están más dispersos y menor cuando están más concentrados. Una primera idea sería usar el rango, pero solo considera los extremos.
En cambio, podemos medir cuánto se aleja cada punto de la media:
$$\text{diferencia} = X – \mu$$
Donde \( X \) es un punto de datos y \( \mu \) la media.
Promedio de las distancias
Podemos combinar las diferencias en una sola medida tomando su promedio. Sin embargo, si los valores por encima y por debajo de la media se cancelan (por ejemplo, [-5, 5]), el promedio sería 0, aunque los datos estén claramente dispersos.
Cuadrar las diferencias
Para evitar la cancelación, elevamos al cuadrado las diferencias:
$$\text{diferencia} = (X – \mu)^2$$
De este modo, los valores negativos desaparecen y las grandes desviaciones pesan más.
La varianza \( \sigma^2 \) se define entonces como:
La varianza no se interpreta directamente, sin tener en cuenta la escala de los datos. Esta crece con la magnitud de los valores porque está en unidades al cuadrado. Por eso, comparar una varianza de 328.56 en dos contextos distintos (media = 13 o media = 1200) no tiene sentido absoluto. En el primer caso, las desviaciones son grandes respecto a la media y en el segundo, son minúsculas.
Entonces:
La varianza no es una medida relativa, y solo tiene valor comparativo si las variables están en la misma escala.
Desviación estándar
La varianza tiene un inconveniente: sus unidades están al cuadrado como ya vimos anteriormente. Por eso usamos la desviación estándar, que devuelve las unidades originales:
La desviación estándar permite interpretar cuán inusual es un valor. Al encontrar el número de desviaciones estándar que un punto de datos está alejado de la media, podemos comenzar a investigar qué tan inusual es realmente ese punto de datos.
~68% de los datos están dentro de 1σ de la media.
~95% dentro de 2σ.
~99.7% dentro de 3σ.
Si un punto se encuentra a más de tres desviaciones estándar, es un valor atípico.
Describiendo un histograma
Media y Mediana
Ambas indican el centro de los datos. En distribuciones simétricas, suelen coincidir.
Dispersión (Spread)
Se describe con los valores mínimo y máximo, tomados con la media y la mediana, comienzan a indicar la forma del conjunto de datos subyacente.
Sesgo (Skewness)
Simétrico: la media ≈ mediana.
Sesgo a la derecha: cola larga hacia la derecha, media > mediana.
Sesgo a la izquierda: cola larga hacia la izquierda, media < mediana.
Modalidad
La modalidad describe el número de picos en un conjunto de datos.
Unimodal: un solo pico.
Bimodal o multimodal: varios picos.
Uniforme: sin agrupaciones claras.
Valores atípicos (Outliers)
Son puntos lejanos al resto del conjunto de datos. Conviene investigarlos: pueden ser errores o indicios interesantes.
Los diagramas de caja son una de las formas más comunes de visualizar un conjunto de datos. Al igual que los histogramas , los diagramas de caja dan una idea de la tendencia central y la dispersión de los datos.
En el análisis de datos, especialmente cuando trabajamos con conjuntos de datos tabulares, es común que lo primero que queramos hacer sea “entender el terreno”: obtener una visión rápida de los patrones, la distribución y las características principales de las variables. A este proceso lo llamamos estadísticas resumidas (summary statistics), y constituye uno de los pilares del análisis exploratorio de datos (EDA, Exploratory Data Analysis).
Estas estadísticas nos permiten responder preguntas básicas como:
¿Qué tan centrados o dispersos están los datos?
¿Existen valores extremos o atípicos?
¿Cómo se distribuyen los valores?
¿Qué categorías son más frecuentes?
Estas herramientas —medias, dispersiones, cuartiles, gráficos y agrupaciones— nos permiten:
Preparar los datos para análisis más complejos.
Detectar errores o valores extremos.
Comprender patrones iniciales.
Análisis Univariado: Explorando una Variable a la Vez
El análisis univariado se enfoca en describir y entender una sola variable por vez. Es la forma más directa de comenzar el EDA y nos permite observar tendencias, detectar anomalías y entender el comportamiento general de los datos.
Podemos dividirlo en dos grandes tipos:
Variables cuantitativas (numéricas)
Variables categóricas (de tipo texto o etiquetas)
Veamos cómo se resumen y visualizan cada una.
Variables Cuantitativas
Medidas de Tendencia Central
Las medidas de tendencia central buscan representar el valor “típico” o central de un conjunto de datos.
Media (promedio): la suma de todos los valores dividida por el número de observaciones. Es útil, pero sensible a valores atípicos.
Mediana: el valor que divide al conjunto en dos partes iguales. Menos afectada por outliers, representa mejor distribuciones sesgadas.
Moda: el valor más frecuente. Muy útil en datos categóricos o multimodales.
Media recortada: elimina un porcentaje de los valores más altos y bajos antes de calcular la media.
Los percentiles indican el porcentaje de observaciones por debajo de un valor dado. Por ejemplo, el percentil 80 = 130 significa que el 80% de los valores son menores que 130.
np.percentile(df['column'], 80)
Los cuartiles dividen los datos en cuatro partes iguales:
Q1 (25%), Q2 (50% = mediana), Q3 (75%)
El rango intercuartílico (IQR) se calcula como:
IQR = Q3 - Q1
y representa la dispersión central, resistente a outliers.
Visualización: Histogramas y Boxplots
Visualizar los datos es esencial para complementar las estadísticas numéricas.
Histograma: muestra la frecuencia de valores en intervalos (bins).
sns.histplot(df['column'])
Boxplot (diagrama de caja): representa la mediana, los cuartiles y los valores atípicos.
sns.boxplot(df['column'])
Estos gráficos ayudan a detectar sesgos, simetrías y valores extremos de un vistazo.
Variables Categóricas
Cuando analizamos variables no numéricas (como “país”, “color” o “tipo de producto”), las estadísticas cambian.
Frecuencias y Proporciones
La herramienta básica es el conteo de valores:
df['column'].value_counts()
Y para ver proporciones:
df['column'].value_counts(normalize=True)
Estas proporciones nos ayudan a entender la distribución de categorías, especialmente cuando hay clases dominantes o poco representadas.
Visualización
Gráficos de barras: ideales para mostrar frecuencias.
sns.countplot(x='column', data=df)
Gráficos circulares (pie charts): útiles para proporciones, aunque menos precisos.
Agrupación y Agregación de Datos
En análisis exploratorios más profundos, necesitamos obtener estadísticas por grupo. Por ejemplo: ¿Cuál es el precio promedio por tipo de carrocería?
La función groupby() de pandas permite dividir, aplicar y combinar fácilmente:
df.groupby('body-style')['price'].mean()
También podemos aplicar múltiples funciones de agregación:
Este enfoque es esencial para crear tablas resumen, indicadores por categoría y comparativas entre grupos.
Variables Categóricas Ordinales
Algunas categorías tienen un orden lógico (por ejemplo: “bajo”, “medio”, “alto”). En estos casos, podemos convertirlas en variables de tipo category ordenadas para analizarlas numéricamente: