El ajuste por mínimos cuadrados es uno de los pilares del análisis de datos.
Nos permite encontrar patrones y relaciones entre variables incluso cuando los datos no son perfectos. La idea esencial es siempre la misma:
Buscar los coeficientes que minimicen el error entre las observaciones reales y las predicciones del modelo.
A partir de aquí, la regresión lineal se convierte en la base de modelos más complejos de machine learning, donde la idea de “ajustar” parámetros para minimizar errores sigue siendo el núcleo de todo el proceso.
De los datos a la recta
Imaginemos que tenemos dos variables, x y y, y sospechamos que están relacionadas de forma lineal. Por ejemplo:
x = [1, 2, 3, 4, 5]
y = [7, 11, 15, 19, 23]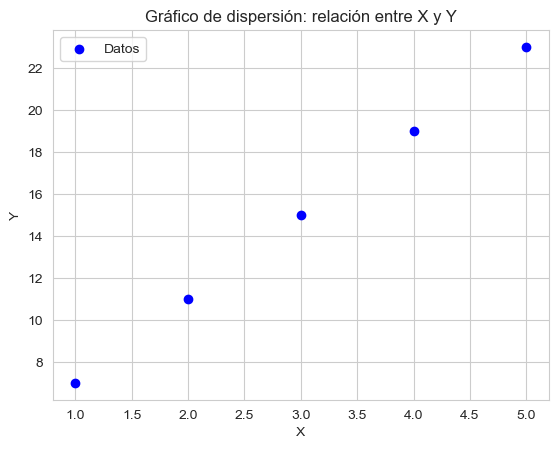
Código de la Grafica
Código en Matplotlib
import matplotlib.pyplot as plt
# Datos
x = [1, 2, 3, 4, 5]
y = [7, 11, 15, 19, 23]
# Crear gráfico de dispersión
plt.scatter(x, y, color='blue', marker='o', label='Datos')
# Etiquetas y título
plt.title('Gráfico de dispersión: relación entre X y Y')
plt.xlabel('X')
plt.ylabel('Y')
plt.grid(True)
plt.legend()
# Mostrar gráfico
plt.show()El modelo lineal
Si las variables son linealmente dependientes, podemos escribir:
$$y = \beta_0 + \beta_1 x$$
donde:
- β₀ (beta cero) es el intercepto, el valor de y cuando x = 0.
- β₁ (beta uno) es la pendiente, que indica cuánto cambia y por cada unidad de x.
Nuestro objetivo es determinar estos coeficientes (β₀ y β₁) de manera que la recta se ajuste lo mejor posible a los datos.
Representando el modelo como un sistema lineal
Podemos escribir la ecuación anterior en forma matricial.
Para cada observación de \(x\), formamos una fila en una matriz \(M \)que tiene dos columnas: una con los valores de \(x\) y otra con unos.
$$M =\begin{bmatrix}1 & 1 \\ 2 & 1 \\ 3 & 1 \\ 4 & 1 \\ 5 & 1 \end{bmatrix} ,\quad \beta = \begin{bmatrix} \beta_1 \\ \beta_0 \end{bmatrix}$$
Entonces el modelo se puede escribir como:
$$y = M \cdot \beta$$
donde y es el vector de observaciones reales.
Si tenemos más ecuaciones que incógnitas (más datos que parámetros), se trata de un sistema sobredeterminado, y no habrá una solución exacta. En esos casos, buscamos una solución aproximada, aquella que minimiza los errores o residuos.
Resolviendo con el método de los mínimos cuadrados
La solución óptima en el sentido de mínimos cuadrados se obtiene resolviendo la ecuación normal:
$$\hat{\beta} = (M^T M)^{-1} M^T y$$
Aquí:
- \( M^T \) es la traspuesta de \(M\).
- \( (M^T M)^{-1} \) es su inversa.
- \( \hat{\beta} \) son las estimaciones de los coeficientes.
En el ejemplo de datos anteriores, este procedimiento nos da:
$$\beta_0 = 3, \quad \beta_1 = 4$$
por lo que la ecuación ajustada es:
$$y = 3 + 4x$$
Si probamos estos valores, obtenemos una coincidencia exacta con los datos: la relación es perfectamente lineal.
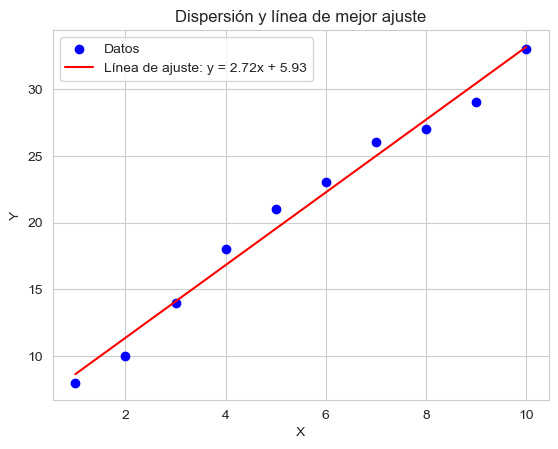
Cuando los datos no son perfectamente lineales
En la práctica, los datos reales rara vez se ajustan perfectamente a una línea.
Supongamos que ahora tenemos un conjunto diferente:
Código de la Grafica
Código en Matplotlib
import matplotlib.pyplot as plt
# Datos
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [8, 10, 14, 18, 21, 23, 26, 27, 29, 33]
# Crear gráfico de dispersión
plt.scatter(x, y, color='blue', marker='o', label='Datos')
# Etiquetas y título
plt.title('Gráfico de dispersión: relación entre X y Y')
plt.xlabel('X')
plt.ylabel('Y')
plt.grid(True)
plt.legend()
# Mostrar gráfico
plt.show()Vemos que no todos caen exactamente sobre una misma recta. Aun así, queremos una línea que represente la tendencia general: esa es la llamada línea de mejor ajuste (line of best fit).
La idea de los residuos
Cada punto tiene una pequeña distancia vertical hasta la recta estimada. Esa diferencia se llama residuo y se define como:
$$\text{residuo}_i = y_i – \hat{y}_i$$
donde \(\hat{y}_i\) es el valor predicho por el modelo. El método de mínimos cuadrados busca los parámetros β₀ y β₁ que minimicen la suma de los cuadrados de esos residuos:
$$\text{minimizar } \sum_{i=1}^{n} (y_i – \hat{y}_i)^2$$
En forma desarrollada o explícita:
$$\text{minimizar: } (y_1 – \hat{y}_1)^2 + (y_2 – \hat{y}_2)^2 + \cdots + (y_n – \hat{y}_n)^2$$
Al hacerlo, la recta resultante será aquella que “pasa más cerca” de todos los puntos en promedio.
Interpretación visual
- β₀ desplaza la recta hacia arriba o abajo.
- β₁ modifica su inclinación.
Podemos imaginar que “movemos” y “rotamos” la línea hasta que la suma de los residuos sea lo más pequeña posible. En ese punto, hemos encontrado la línea de mejor ajuste.
Extensión a modelos polinomiales
La misma lógica se puede aplicar cuando la relación no es lineal. Por ejemplo, si creemos que \(y \) depende de \(x²\), podemos ajustar un modelo cuadrático:
$$y = \beta_0 + \beta_1 x + \beta_2 x^2$$
En este caso, la matriz \(M \) tendrá tres columnas: una para \(x^2\), una para \(x\) y una para los unos.
$$M = \begin{bmatrix} x_1^2 & x_1 & 1 \\ x_2^2 & x_2 & 1 \\ \vdots & \vdots & \vdots \\ x_n^2 & x_n & 1 \end{bmatrix}$$
Y nuevamente, los coeficientes se obtienen con la misma fórmula general:
$$\hat{\beta} = (M^T M)^{-1} M^T y$$
Si aplicamos este método a un conjunto de datos donde la relación es cuadrática, obtendremos una curva que se adapta mucho mejor a los puntos observados que una simple línea.
Generalización
Esta metodología puede ampliarse para ajustar polinomios de grado superior o otros tipos de funciones (logarítmicas, exponenciales, etc.), siempre que podamos expresar el modelo en forma lineal respecto a los coeficientes β.
Por ejemplo, para un polinomio cúbico:
$$y = \beta_0 + \beta_1 x + \beta_2 x^2 + \beta_3 x^3$$
solo tendríamos que añadir una columna más a \(M\)con los valores de (x^3).