En el análisis y la ciencia de datos, entender la forma de la distribución de los datos es tan importante como los valores en sí. Muchos modelos estadísticos y de machine learning funcionan mejor —o incluso lo asumen— cuando los datos siguen una distribución normal (gaussiana).
Sin embargo, los datos reales rara vez son perfectos: suelen estar sesgados, contener valores atípicos o tener una dispersión desigual. En este artículo aprenderás:
- Qué significa que los datos estén sesgados.
- Qué es la transformación logarítmica y por qué es útil.
- Cómo implementarla en Python.
- Qué otras transformaciones avanzadas pueden aplicarse según la situación.
¿Qué son los datos sesgados?
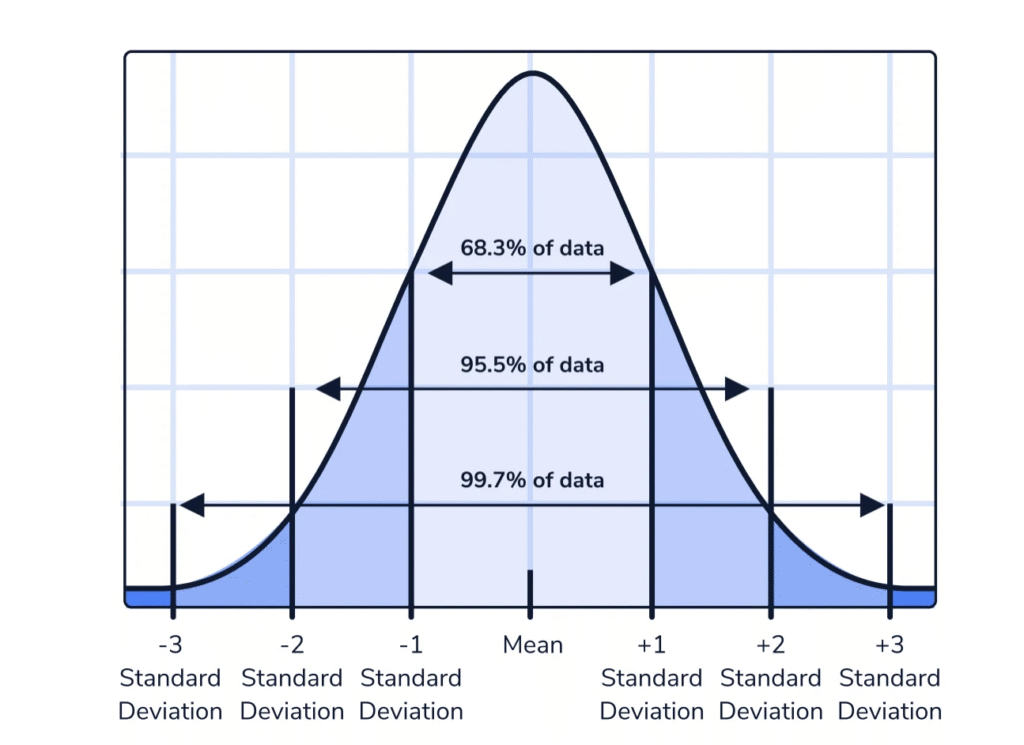
En una distribución normal, la media, la mediana y la moda coinciden, y la curva tiene forma de campana. Matemáticamente, se puede representar como:
$$f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x – \mu)^2}{2\sigma^2}}$$
donde:
- \( \mu \) es la media
- \( \sigma \) la desviación estándar.
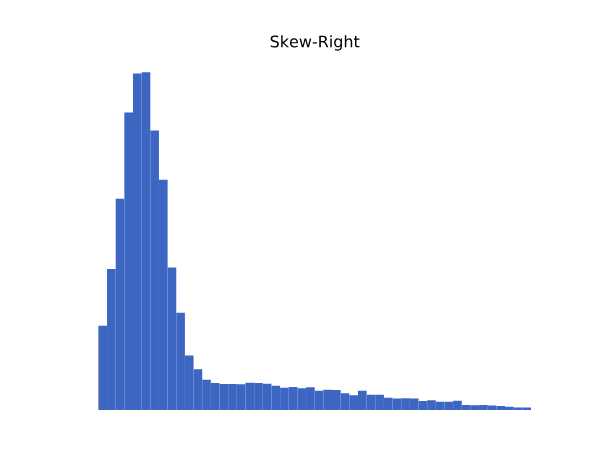
Sin embargo, muchos conjuntos de datos reales, como ingresos, precios o número de visitas, presentan sesgo (skewness): una asimetría en la distribución.
- Si la cola se extiende hacia la derecha, decimos que está sesgada positivamente.
- Si se extiende hacia la izquierda, está sesgada negativamente.
Por ejemplo, los ingresos de una población suelen estar sesgados a la derecha, porque hay muchas personas con ingresos bajos y pocas con ingresos muy altos.
¿Por qué importa el sesgo?
El sesgo afecta al análisis porque muchos métodos estadísticos y modelos predictivos suponen que los datos son normales.
Por ejemplo:
- En regresión lineal, el error residual se asume normal.
- En modelos de clasificación, los algoritmos que usan distancias (como k-NN) pueden verse afectados si las variables no están en escalas comparables o están muy sesgadas.
Reducir el sesgo mejora:
- La precisión del modelo.
- La interpretabilidad de los resultados.
- La estabilidad numérica en el entrenamiento.
Transformación Logarítmica
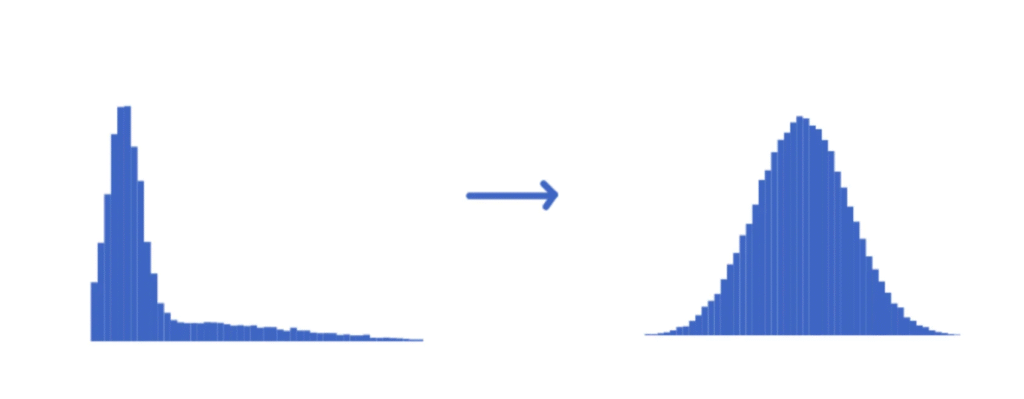
La transformación logarítmica es una de las herramientas más utilizadas para corregir el sesgo positivo. Consiste en reemplazar cada valor \(x\) por su logaritmo:
$$x’ = \log(x)$$
¿Qué hace exactamente?
- Comprime los valores grandes, reduciendo el impacto de los outliers.
- Expande los valores pequeños, acercando la distribución a una forma más simétrica.
Importante: solo puede aplicarse a valores positivos. Si existen ceros o negativos, hay que desplazarlos previamente (por ejemplo, usando (\log(x + 1))).
Ejemplo en Python
Veamos cómo aplicar esta técnica a un conjunto de datos de precios de viviendas.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Cargar datos de ejemplo (Kaggle o dataset propio)
home_data = pd.read_csv('home_data.csv')
home_prices = home_data['SalePrice']
# Visualizar la distribución original
sns.histplot(home_prices, kde=True, color="skyblue")
plt.title("Distribución original de precios de viviendas")
plt.show()
# Medir asimetría
print("Asimetría original:", home_prices.skew())
# Aplicar transformación logarítmica
log_home_prices = np.log(home_prices)
# Visualizar la distribución transformada
sns.histplot(log_home_prices, kde=True, color="lightgreen")
plt.title("Distribución tras transformación logarítmica")
plt.show()
# Medir asimetría posterior
print("Asimetría después de log-transform:", log_home_prices.skew())🔹 Salida esperada:
Asimetría original: 1.88
Asimetría después de log-transform: 0.12El cambio es notable: los datos ahora están mucho más cerca de una distribución normal.
Transformación con Scikit-Learn
Otra forma más flexible es usar la clase PowerTransformer de scikit-learn, que aplica una transformación de potencia (Box-Cox o Yeo-Johnson). Esta última admite valores negativos, lo que la hace ideal en contextos más generales.
from sklearn.preprocessing import PowerTransformer
import numpy as np
data = np.array([[1.0], [2.0], [3.0], [10.0], [50.0]])
pt = PowerTransformer(method='yeo-johnson')
transformed = pt.fit_transform(data)
print("Datos transformados:\n", transformed[:5])
Otras transformaciones avanzadas
Dependiendo del tipo y del sesgo de los datos, se pueden usar diferentes transformaciones:
| Tipo de Sesgo | Transformación recomendada | Fórmula | Notas |
|---|---|---|---|
| Sesgo positivo (cola a la derecha) | Logarítmica | \( x’ = \log(x) \) | Solo ( x > 0 ) |
| Sesgo positivo (con ceros o negativos) | Yeo-Johnson | — | Admite todo el rango de valores |
| Sesgo positivo leve | Raíz cuadrada | \(x’ = \sqrt{x}\) | Suaviza sin comprimir demasiado |
| Sesgo negativo (cola a la izquierda) | Cuadrática | \(x’ = x^2\) | Amplifica valores grandes |
| Valores con ceros y negativos | Raíz cúbica | \(x’ = x^{1/3} \) | Funciona con ( x < 0 ) |
Buenas prácticas
- Visualiza siempre tus datos antes y después de transformar.
- Mide la asimetría \( (\text{skewness})\) antes y después.
- No transformes por costumbre: hazlo solo si hay una razón estadística o del modelo.
- Guarda los parámetros de transformación si vas a aplicarlos en datos futuros (por ejemplo, en deploy de modelos).
- Considera también el escalado posterior (normalización o estandarización).
