[h5p id=»2″]
[h5p id=»3″]
[h5p id=»2″]
[h5p id=»3″]
Microsoft Power BI Data Analyst (PL-300) – Proyecto Final «Tonificado».
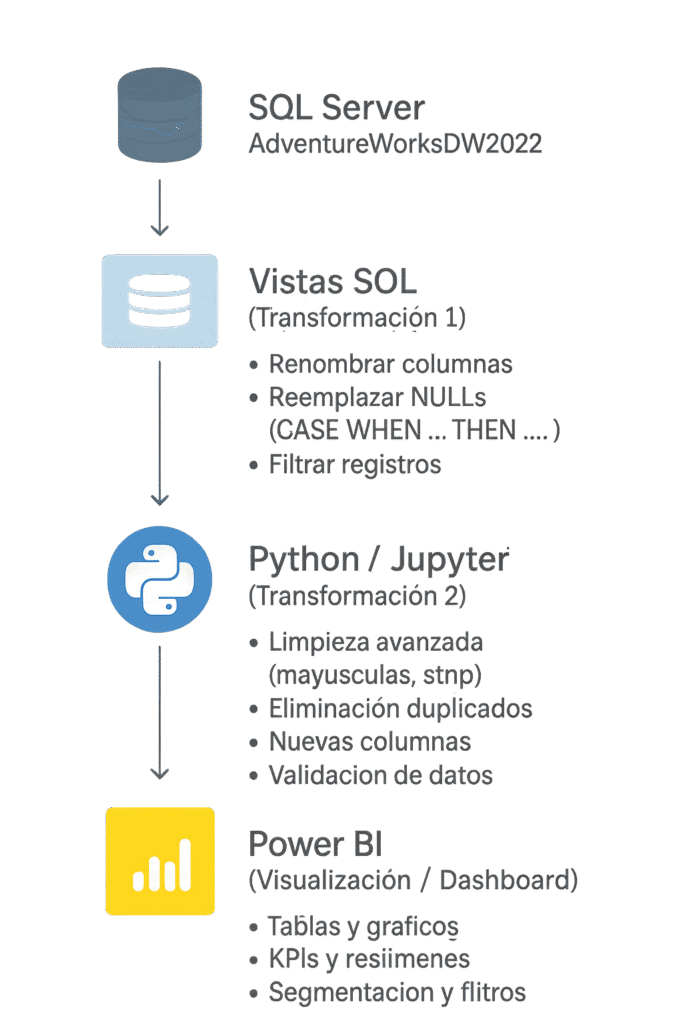
Proyecto de Dashboard 360° para AdventureWorks 2022. Se extrajeron y exploraron los datos con SQL, se limpiaron y transformaron usando Python y Pandas, y finalmente se visualizaron en Power BI. El proyecto abarca todo el proceso ETL: consultas y modelado de datos en SQL, manipulación y preparación de datos en Python, y construcción de visualizaciones interactivas en Power BI para análisis integral de finanzas, ventas, clientes y productos.
El proyecto de curso original solo incluía elaborar un dashboard con datos provenientes de tablas de Excel aportadas por el curso.
Tecnologías utilizadas
Lo primero y más importante: nunca empieces a extraer datos sin entenderlos al 100 %.
Acciones realizadas:
Como resultado se creó un Diccionario de Datos completo en Excel y un diagrama relacional.
Definición de un modelo dimensional robusto, siguiendo las mejores prácticas de arquitectura BI. Para garantizar un rendimiento óptimo en Power BI y un análisis consistente, se diseñó un modelo en estrella (Star Schema), manteniendo únicamente algunas jerarquías naturales con forma de snowflake cuando aportaban claridad sin afectar el rendimiento.
Establecer la granularidad exacta de cada tabla de hechos:
Se seleccionaron los indicadores esenciales para la visión 360°:
Durante esta fase se produjeron los documentos técnicos clave del proyecto:
Se crearon vistas en SQL Server, segun el documento de Requerimientos, que estructuran y preparan los datos para su posterior procesamiento en Python y análisis en Power BI.
Las vistas incluyen:
Además, se aplicaron transformaciones básicas dentro de las vistas, como el cálculo de edad a partir de la fecha de nacimiento y la unificación de jerarquías de productos, simplificando la carga y limpieza de datos en Python.
Resultado: Una capa de datos limpia, consistente y segura, lista para análisis avanzado en Python y visualización interactiva en Power BI, cumpliendo los objetivos del dashboard ejecutivo.
En esta fase se consolidan los datos de SQL Server y se preparan para su análisis en Power BI, asegurando datasets limpios, consistentes y listos para modelado.
Se crearon cuadernos de Jupyter para extraer vistas SQL a CSV:
/data/raw, eliminando prefijos vw_ en los nombres.Los CSV se cargaron en DataFrames de Pandas para exploración:
CheckData) para revisión rápida de los datasets.Se aplicaron transformaciones consistentes por tabla de hechos:
Se desarrollaron scripts para consolidar el flujo:
config.py: define rutas de trabajo y conexión a SQL Server con SQLAlchemy.etl_pipeline.py: ejecuta automáticamente:
/data/processed.Este enfoque permite reproducir todo el proceso con un solo comando, manteniendo la trazabilidad y calidad de los datos para análisis en Power BI.
Tras la limpieza y transformación, los datasets se preparan para su consumo en Power BI:
dimCliente.parquet, factVentas.parquet, etc.datasets_control.xlsx) que documenta: nombre del archivo, número de filas y columnas, fecha de exportación./data/final/, listos para el análisis.Este procedimiento asegura que los datos sean consistentes, auditables y fácilmente reutilizables por cualquier miembro del equipo BI.
La fase final consiste en construir el modelo semántico para análisis y reporting:
El resultado es un archivo Proyecto_Ventas.pbix completamente funcional y un documento de Modelo de Datos (Modelo de Datos en Power BI.pdf) con capturas de relaciones, medidas y estructura general, que permite navegar, analizar y tomar decisiones basadas en datos de manera rápida y confiable.
Las variables aleatorias son uno de los pilares fundamentales de la probabilidad y la estadística, y entenderlas es clave para trabajar con datos, modelos matemáticos, inferencia estadística o machine learning. En este artículo veremos de forma clara qué son, cómo se clasifican, cómo funcionan sus funciones asociadas (PMF y CDF), y cómo se calculan y visualizan con Python.
Una variable aleatoria es una función que asigna valores numéricos a los resultados de un experimento aleatorio.
Las variables aleatorias discretas son aquellas que toman un número finito o contablemente infinito de valores distintos. Cada uno de estos valores tiene una probabilidad asociada, y la suma de todas estas probabilidades debe ser igual a uno. Pueden adoptar valores que se pueden contar, como 0, 1, 2, …, n, o una lista de valores específicos como {-3, -1, 0, 1, 5}.
Ejemplos comunes:
Una variable aleatoria de Bernoulli es un tipo específico de variable aleatoria discreta que sólo toma dos posibles valores, típicamente 0 y 1, para representar los resultados de un único ensayo de Bernoulli.
Una variable de Bernoulli X se define de la siguiente manera:
Vamos a construir una función en Python que simule un experimento de Bernoulli, el cual podría representar, por ejemplo, el lanzamiento de una moneda:
import numpy as np
def bernoulli_trial(p=0.5):
"""Simula un experimento de Bernoulli.
Args:
p (float): Probabilidad de éxito (por defecto 0.5).
Returns:
int: 1 si el experimento resulta en éxito, 0 en caso contrario.
"""
return 1 if np.random.rand() <= p else 0
En esta función, np.random.rand() genera un número aleatorio entre 0 y 1, y compara este número con la probabilidad de éxito p. Si el número generado es menor o igual a p, el resultado es un éxito (1); de lo contrario, es un fracaso (0).
Podemos usar esta función para realizar múltiples ensayos y observar la frecuencia de éxitos, lo que nos permite estimar la probabilidad de éxito de la moneda:
def simulate_bernoulli_trials(n, p=0.5):
"""Simula n ensayos de Bernoulli y reporta la frecuencia de éxitos.
Args:
n (int): Número de ensayos.
p (float): Probabilidad de éxito.
Returns:
float: Frecuencia de éxitos.
"""
results = [bernoulli_trial(p) for _ in range(n)]
return sum(results) / n
# Simular 1000 lanzamientos de una moneda con p = 0.7
n_trials = 1000
success_prob = 0.612199
frequency_of_success = simulate_bernoulli_trials(n_trials, success_prob)
print(f"La frecuencia de éxito estimada es {frequency_of_success:.2f}")
Output:
La frecuencia de éxito estimada es 0.71
Este código simula 1000 lanzamientos de una moneda donde la probabilidad de obtener cara (éxito) es del 70%. La función simulate_bernoulli_trials devuelve la frecuencia de éxitos, que debería acercarse a 0.7 a medida que el número de ensayos aumenta.
Para visualizar cómo la frecuencia de éxitos converge a la probabilidad real, podríamos realizar múltiples simulaciones aumentando progresivamente el número de ensayos y graficar los resultados:
import matplotlib.pyplot as plt
trial_counts = [10, 50, 100, 500, 1000, 5000, 10000]
frequencies = [simulate_bernoulli_trials(count, success_prob) for count in trial_counts]
plt.figure(figsize=(10, 5))
plt.plot(trial_counts, frequencies, marker='o', linestyle='-')
plt.axhline(y=success_prob, color='r', linestyle='--')
plt.title('Convergencia de la Frecuencia de Éxitos a la Probabilidad Real')
plt.xlabel('Número de Ensayos')
plt.ylabel('Frecuencia de Éxitos')
plt.xscale('log')
plt.show()
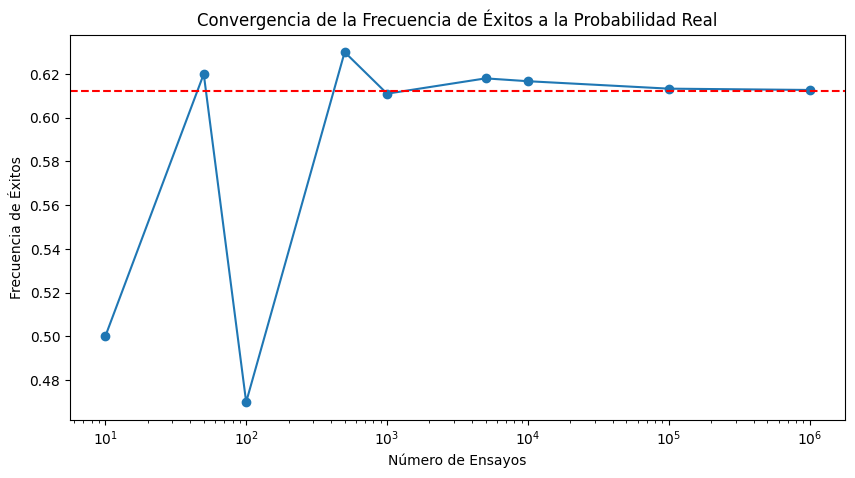
Este gráfico mostrará cómo la frecuencia de éxitos se estabiliza y converge hacia la probabilidad real de éxito (0.612199 en este caso) a medida que aumenta el número de ensayos, ilustrando la ley de los grandes números.
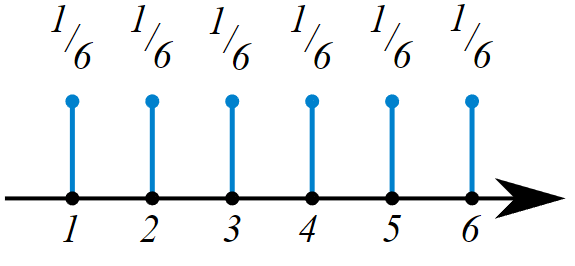
La Función de Masa de Probabilidad (PMF) es una función que describe la probabilidad de que una variable aleatoria discreta tome un valor específico. Es una función que devuelve la probabilidad de que una variable aleatoria discreta sea exactamente igual a algún valor. Es una función que asocia a cada punto de su espacio muestral X la probabilidad de que esta lo asuma. La función de probabilidad suele ser el medio principal para definir una distribución de probabilidad discreta, y tales funciones existen para variables aleatorias escalares o multivariantes, cuyo dominio es discreto.
La función de masa de probabilidad de un dado. Todos los números tienen la misma probabilidad de aparecer cuando este es tirado.
Por ejemplo, supongamos que lanzamos una moneda justa varias veces y contamos el número de caras. La función de masa de probabilidad que describe la probabilidad de cada resultado posible (p. ej., 0 caras, 1 cara, 2 caras, etc.) se denomina distribución binomial. Los parámetros para la distribución binomial son:
n para el número de intentos (por ejemplo, n=10 si lanzamos una moneda 10 veces)p para la probabilidad de éxito en cada prueba (probabilidad de observar un resultado particular en cada prueba. En este ejemplo, p= 0,5 porque la probabilidad de observar caras en un lanzamiento de moneda justo es 0,5)Si lanzamos una moneda normal 10 veces, decimos que el número de caras observadas sigue una distribución Binomial(n=10, p=0.5). El siguiente gráfico muestra la función de masa de probabilidad para este experimento. Las alturas de las barras representan la probabilidad de observar cada resultado posible calculado por el PMF.
Veamos cómo cambia la forma de la distribución binomial a medida que cambia el tamaño de la muestra.
Utilice el control deslizante para cambiar el valor de x lanzamientos de moneda justos, entre uno y diez. Las alturas de las barras resultantes representan la probabilidad de observar diferentes valores de caras en x número de lanzamientos de moneda justos. Puede pasar el cursor sobre cada barra y ver el valor numérico real de la altura de la barra. Las barras más altas representan resultados más probables.
Observe que a medida que x aumenta, las barras se hacen más pequeñas. Esto se debe a que la suma de las alturas de todas las barras siempre será igual a 1. Entonces, cuando x es mayor, el número de caras que podemos observar aumenta y la probabilidad debe dividirse entre más valores.
Binomial Distribution: Calculating Probability of a Given Number of Heads
El método binom.pmf() de la biblioteca scipy.stats se puede utilizar para calcular el PMF de la distribución binomial en cualquier valor. Este método toma 3 valores:
x: el valor del interésn: el número de ensayosp: la probabilidad de éxitoPor ejemplo, supongamos que lanzamos una moneda normal 10 veces y contamos el número de caras. Podemos usar la función binom.pmf() para calcular la probabilidad de observar 6 cabezas de la siguiente manera:
# import necessary library
import scipy.stats as stats
# st.binom.pmf(x, n, p)
print(stats.binom.pmf(6, 10, 0.5))
Output
0.205078
Observe que dos de los tres valores que entran en el método stats.binomial.pmf() son los parámetros que definen la distribución binomial: n representa el número de intentos y p representa la probabilidad de éxito.
Hemos visto que podemos calcular la probabilidad de observar un valor específico usando una función de masa de probabilidad. ¿Qué pasa si queremos encontrar la probabilidad de observar un rango de valores para una variable aleatoria discreta? Una forma de hacer esto es sumando la probabilidad de cada valor.
Por ejemplo, digamos que lanzamos una moneda justa 5 veces y queremos saber la probabilidad de obtener entre 1 y 3 caras. Podemos visualizar este escenario con la función de masa de probabilidad:
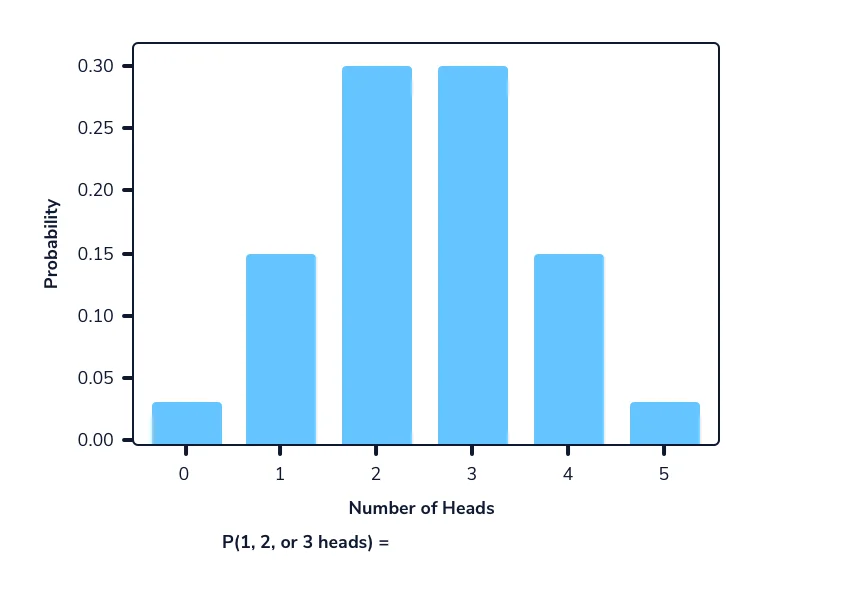
Podemos calcular esto usando la siguiente ecuación donde P(x) es la probabilidad de observar el número x de éxitos (cara en este caso):
P(1 to 3 heads) = P(1<= X <=3)
P(1 to 3 heads) = P(X=1) + P(X=2) + P(X=3)
P(1 to 3 heads) = 0.1562 + 0.3125 + 0.3125
P(1 to 3 heads) = 0.7812
Visualicemos lo que significa tomar la probabilidad de un rango. Utilice los controles deslizantes para seleccionar un rango de valores que representen el número de caras que podríamos observar en 10 lanzamientos de moneda justos.
Pruebe diferentes rangos para ver cómo cambian las probabilidades para diferentes valores. Pase el cursor sobre una barra individual para ver la altura de la barra (que corresponde a la probabilidad de que ocurra el valor).
Binomial Distribution: Calculating Probability of a Range
Podemos utilizar el mismo método binom.pmf() de la biblioteca scipy.stats para calcular la probabilidad de observar un rango de valores. Como se mencionó en un ejercicio anterior, el método binom.pmf toma 3 valores:
x: el valor del interésn: el número de ensayosp: la probabilidad de éxitoPor ejemplo, podemos calcular la probabilidad de observar entre 2 y 4 caras en 10 lanzamientos de moneda de la siguiente manera:
import scipy.stats as stats
# calculating P(2-4 heads) = P(2 heads) + P(3 heads) + P(4 heads) for flipping a coin 10 times
print(stats.binom.pmf(2, n=10, p=.5)
+ stats.binom.pmf(3, n=10, p=.5)
+ stats.binom.pmf(4, n=10, p=.5))
Output:
0.366211
También podemos calcular la probabilidad de observar menos de un cierto valor, digamos 3 caras, sumando las probabilidades de los valores debajo de él:
import scipy.stats as stats
# calculating P(less than 3 heads) = P(0 heads) + P(1 head) + P(2 heads) for flipping a coin 10 times
print(stats.binom.pmf(0, n=10, p=.5)
+ stats.binom.pmf(1, n=10, p=.5)
+ stats.binom.pmf(2, n=10, p=.5))
Output
0.0546875
Tenga en cuenta que debido a que nuestro rango deseado es inferior a 3 cabezas, no incluimos ese valor en la suma.
Cuando hay muchos valores de interés posibles, esta tarea de sumar probabilidades puede resultar difícil. Si queremos saber la probabilidad de observar 8 o menos caras en 10 lanzamientos de moneda, debemos sumar los valores del 0 al 8:
import scipy.stats as stats
var = stats.binom.pmf(0, n = 10, p = 0.5)
+ stats.binom.pmf(1, n = 10, p = 0.5)
+ stats.binom.pmf(2, n = 10, p = 0.5)
+ stats.binom.pmf(3, n = 10, p = 0.5)
+ stats.binom.pmf(4, n = 10, p = 0.5)
+ stats.binom.pmf(5, n = 10, p = 0.5)
+ stats.binom.pmf(6, n = 10, p = 0.5)
+ stats.binom.pmf(7, n = 10, p = 0.5)
+ stats.binom.pmf(8, n = 10, p = 0.5)
Output
0.98926
Esto implica una gran cantidad de código repetitivo. En su lugar, también podemos utilizar el hecho de que la suma de las probabilidades de todos los valores posibles es igual a 1:
P(0to8heads) + P(9to10heads) = P(0to10heads) = 1
P(0to8heads) = 1 − P(9to10heads)
Ahora, en lugar de sumar 9 valores para las probabilidades entre 0 y 8 caras, podemos hacer 1 menos la suma de dos valores y obtener el mismo resultado:
import scipy.stats as stats
# less than or equal to 8
1 - (stats.binom.pmf(9, n=10, p=.5) + stats.binom.pmf(10, n=10, p=.5))
Output
0.98926
La función de distribución acumulativa para una variable aleatoria discreta se puede derivar de la función de masa de probabilidad. Sin embargo, en lugar de la probabilidad de observar un valor específico, la función de distribución acumulativa proporciona la probabilidad de observar un valor específico O MENOS.
Como se analizó anteriormente, las probabilidades de todos los valores posibles en una distribución de probabilidad dada suman 1. El valor de una función de distribución acumulativa en un valor dado es igual a la suma de las probabilidades menores que él, con un valor de 1 para la mayor número posible.
Mostramos cómo se puede utilizar la función de masa de probabilidad para calcular la probabilidad de observar menos de 3 caras en 10 lanzamientos de moneda sumando las probabilidades de observar 0, 1 y 2 caras. La función de distribución acumulativa produce la misma respuesta al evaluar la función en CDF(X=2). En este caso, utilizar el CDF es más sencillo que el PMF porque requiere un cálculo en lugar de tres.
La animación del enlace muestra la relación entre la función de masa de probabilidad y la función de distribución acumulativa. El gráfico superior es el PMF, mientras que el gráfico inferior es el CDF correspondiente. Al observar la gráfica de una CDF, cada valor del eje y es la suma de las probabilidades menores o iguales que él en la PMF.
Podemos usar una función de distribución acumulativa para calcular la probabilidad de un rango específico tomando la diferencia entre dos valores de la función de distribución acumulativa. Por ejemplo, para encontrar la probabilidad de observar entre 3 y 6 caras, podemos tomar la probabilidad de observar 6 o menos cabezas y restar la probabilidad de observar 2 o menos caras. Esto deja un remanente de entre 3 y 6 cabezas.
La imagen de la derecha demuestra cómo funciona esto. Es importante tener en cuenta que para incluir el límite inferior en el rango, el valor que se resta debe ser uno menos que el límite inferior. En este ejemplo, queríamos saber la probabilidad de 3 a 6, que incluye 3.
Podemos utilizar el método binom.cdf() de la biblioteca scipy.stats para calcular la función de distribución acumulativa. Este método toma 3 valores:
x: el valor de interés, buscando la probabilidad de este valor o menosn: el tamaño de la muestrap: la probabilidad de éxitoCalcular matemáticamente la probabilidad de observar 6 o menos caras en 10 lanzamientos de moneda justos (0 a 6 caras) se parece a lo siguiente:
P(6 or fewer heads) = P(0 to 6 heads)
El codigo en Python es:
import scipy.stats as stats
print(stats.binom.cdf(6, 10, 0.5))
Output
0.828125
Se puede pensar que calcular la probabilidad de observar entre 4 y 8 caras en 10 lanzamientos de moneda justos es tomar la diferencia del valor de la función de distribución acumulativa en 8 de la función de distribución acumulativa en 3:
P(4 to 8 Heads) = P(0 to 8 Heads) − P(0 to 3 Heads)
En Python utilizamos el codigo:
import scipy.stats as stats
print(stats.binom.cdf(8, 10, 0.5) - stats.binom.cdf(3, 10, 0.5))
Output
0.81738
Para calcular la probabilidad de observar más de 6 caras en 10 lanzamientos de moneda justos, restamos el valor de la función de distribución acumulativa en 6 de 1. Matemáticamente, esto se parece a lo siguiente:
P(more than 6 Heads) = 1 - P(6 or fewer Heads)
Tenga en cuenta que “más de 6 cabezas” no incluye 6. En Python, calcularíamos esta probabilidad usando el siguiente código:
import scipy.stats as stats
print(1 - stats.binom.cdf(6, 10, 0.5))
Output
0.171875
Los tipos de variables aleatorias discretas se clasifican comúnmente según las distribuciones de probabilidad que describen cómo se comportan los datos asociados a estas variables. Aquí describo algunas de las distribuciones más comunes y utilizadas para variables aleatorias discretas. En Python, la librería scipy.stats proporciona implementaciones de las PMFs para muchas distribuciones discretas comunes, lo que facilita su cálculo en la práctica. Estas funciones son extremadamente útiles para simulaciones, modelado estadístico y análisis probabilístico en una amplia gama de aplicaciones.
from scipy.stats import binom import numpy # Parámetros n = 10 # número de ensayos p = 0.5 # probabilidad de éxito size = 100 # muestras a generar # Generar Variables numpy.random.binomial(n, p, size) # Calcular PMF para un valor específico k = 5 # número de éxitos prob = binom.pmf(k, n, p) print(f"Probabilidad de {k} éxitos en {n} ensayos: {prob:.4f}") from scipy.stats import poisson import numpy lambda_ = 3 # tasa media de eventos por intervalo zize = 10 # número de muestras a generar. # Generar variables numpy.random.poisson(lambda_, size) # Calcular PMF k = 4 # número de eventos prob = poisson.pmf(k, lambda_) print(f"Probabilidad de {k} eventos: {prob:.4f}") from scipy.stats import geom import numpy p = 0.2 # probabilidad de éxito en cada ensayo zize = 10 # número de muestras a generar. # generar variable numpy.random.geometric(p, size) # Calcular PMF k = 5 # ensayo en el que ocurre el primer éxito prob = geom.pmf(k, p) print(f"Probabilidad de primer éxito en el intento {k}: {prob:.4f}") from scipy.stats import nbinom import numpy r = 5 # número de éxitos deseados p = 0.5 # probabilidad de éxito en cada ensayo zize = 10 # número de muestras a generar. # generar variable numpy.random.negative_binomial(n, p, size) # Calcular PMF k = 10 # total de ensayos prob = nbinom.pmf(k-r, r, p) print(f"Probabilidad de alcanzar {r} éxitos en {k} ensayos: {prob:.4f}") from scipy.stats import hypergeom import numpy M = 20 # tamaño total de la población n = 7 # número de éxitos en la población N = 12 # tamaño de la muestra # Calcular PMF k = 3 # número de éxitos observados en la muestra prob = hypergeom.pmf(k, M, n, N) print(f"Probabilidad de {k} éxitos en una muestra de {N}: {prob:.4f}") # generar variable ngood # número de elementos "buenos" en la población. nbad # número de elementos "malos" en la población. nsample # número de elementos a muestrear (sin reemplazo). size # número de muestras a generar. numpy.random.hypergeometric(ngood, nbad, nsample, size=None)Estas distribuciones permiten modelar una gran variedad de procesos y fenómenos en diversos campos como la biología, ingeniería, economía, ciencias sociales, y más. Cada tipo de distribución proporciona un modelo estadístico que se adapta a las características específicas de los datos y la naturaleza del experimento o la observación realizada.
Las variables aleatorias continuas son aquellas que pueden tomar cualquier valor numérico dentro de un intervalo o conjunto de intervalos, a diferencia de las variables aleatorias discretas que tienen valores contables y separados. Este tipo de variables es fundamental en estadística y probabilidad para modelar fenómenos que requieren una escala de medida infinita y continua.
De manera similar a cómo las variables aleatorias discretas se relacionan con las funciones de masa de probabilidad, las variables aleatorias continuas se relacionan con las funciones de densidad de probabilidad. Definen las distribuciones de probabilidad de variables aleatorias continuas y abarcan todos los valores posibles que puede adoptar la variable aleatoria dada.
Cuando se representa gráficamente, una función de densidad de probabilidad es una curva que atraviesa todos los valores posibles que puede tomar la variable aleatoria, y el área total bajo esta curva suma 1.
La siguiente imagen muestra una función de densidad de probabilidad. El área resaltada representa la probabilidad de observar un valor dentro del rango resaltado.
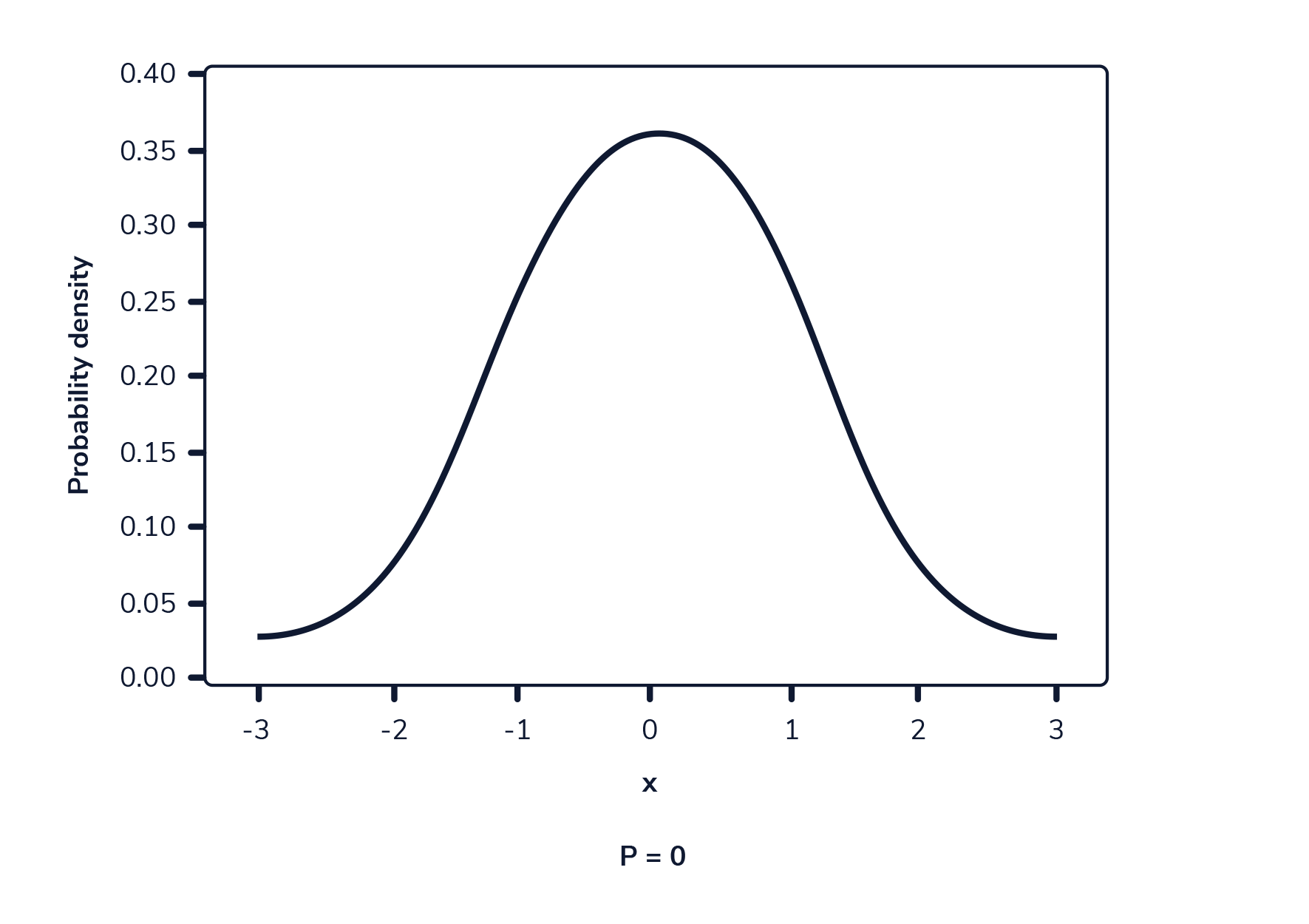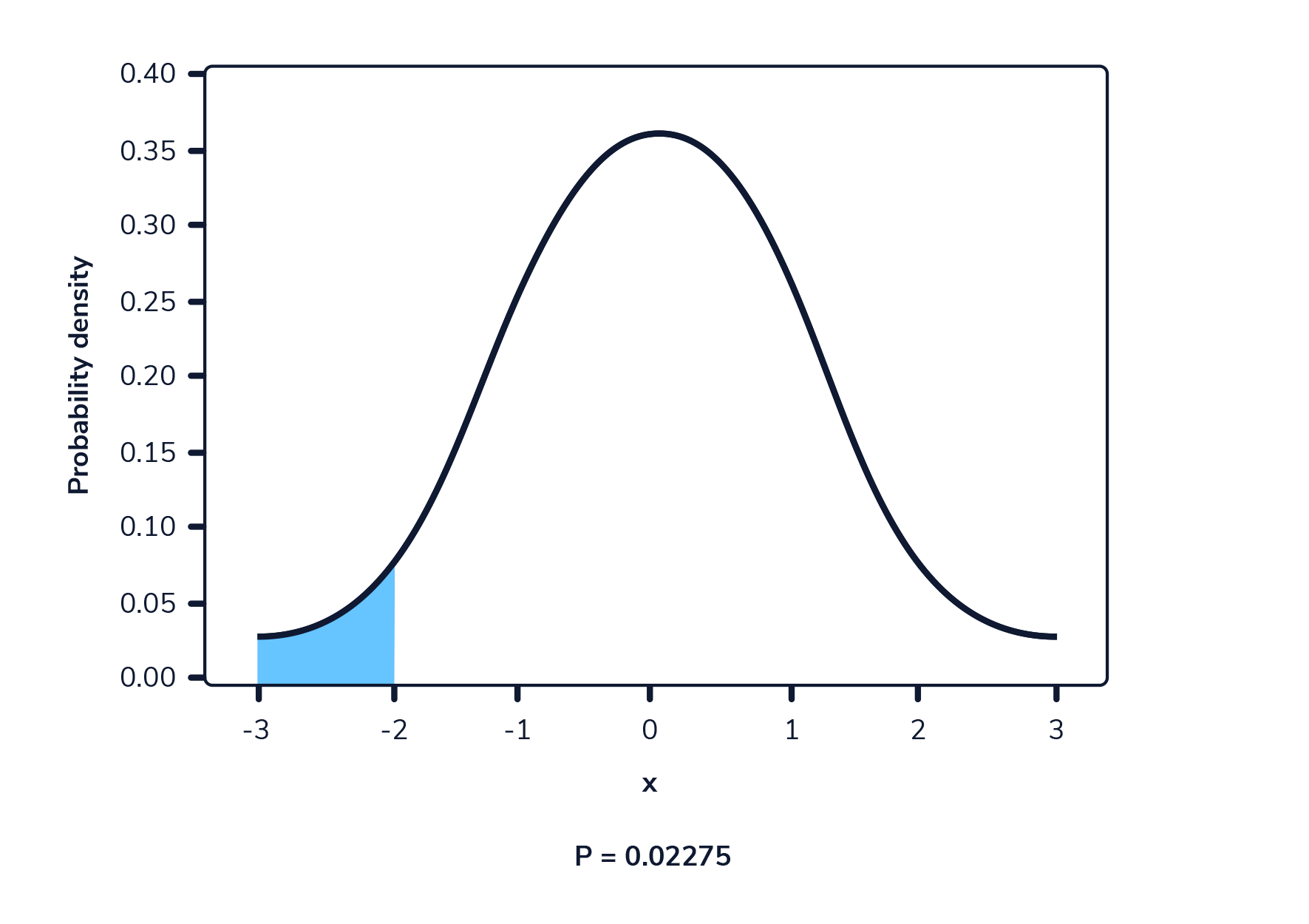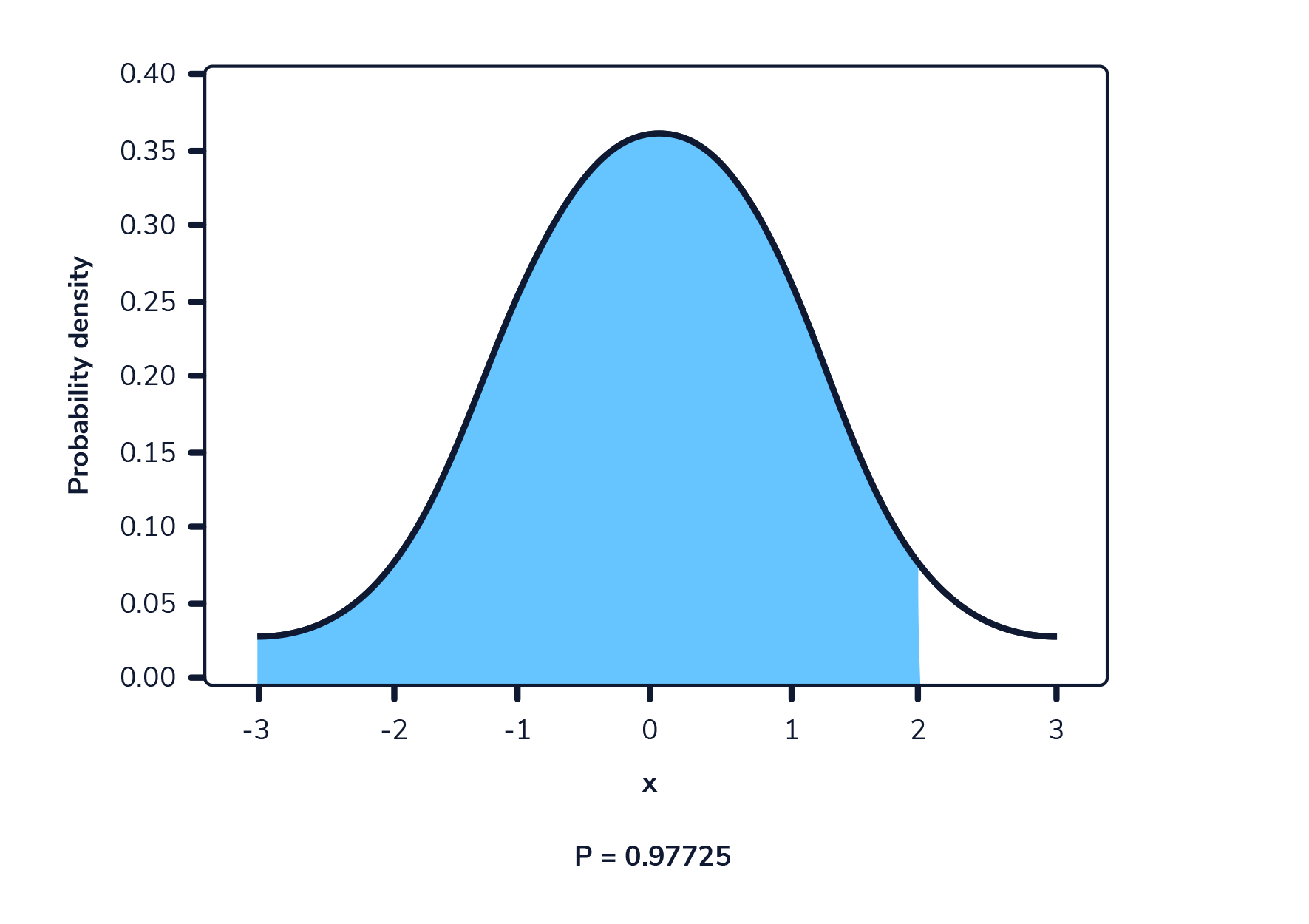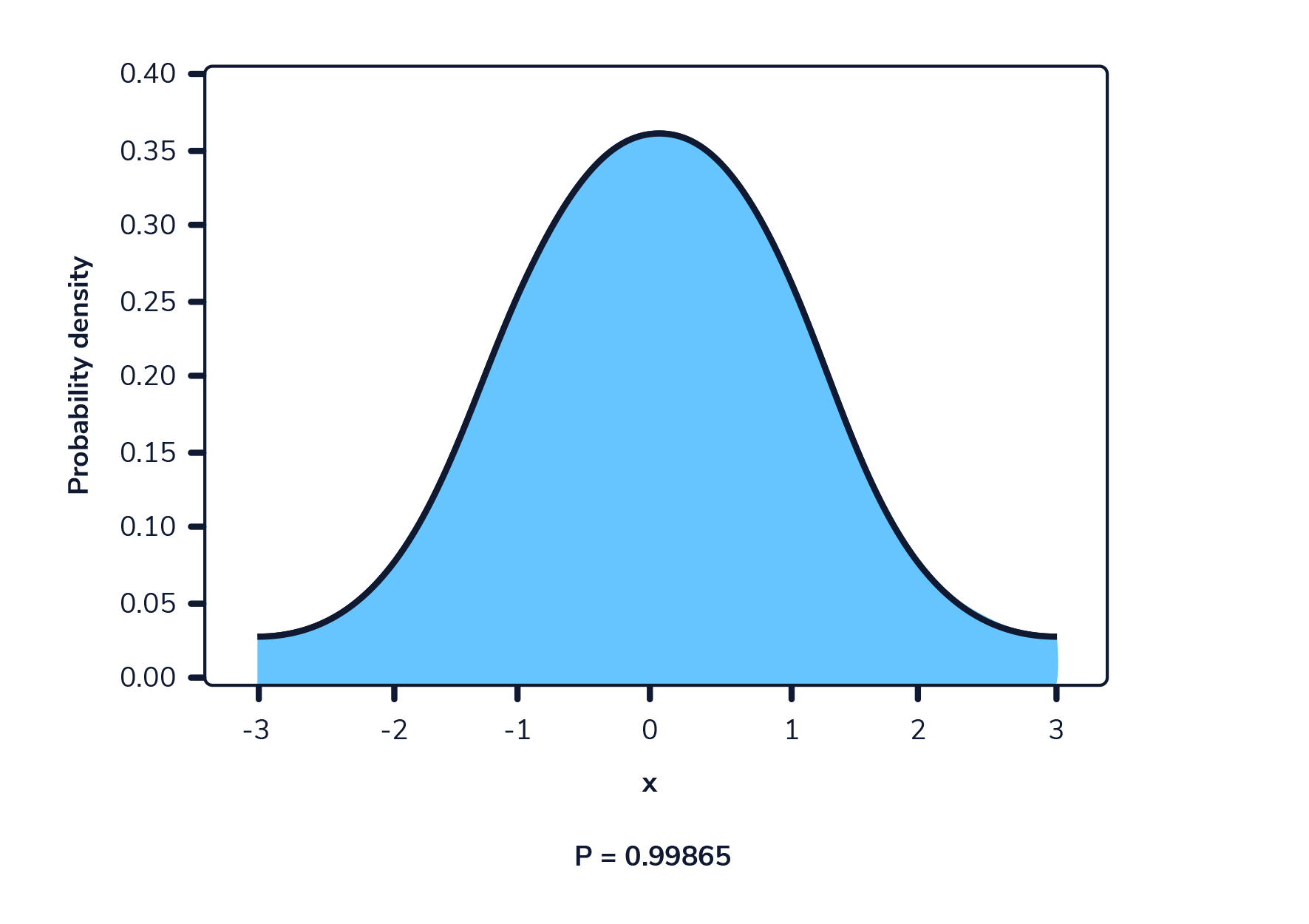
En una función de densidad de probabilidad, no podemos calcular la probabilidad en un solo punto. Esto se debe a que el área de la curva debajo de un único punto es siempre cero. El siguiente gif muestra esto.
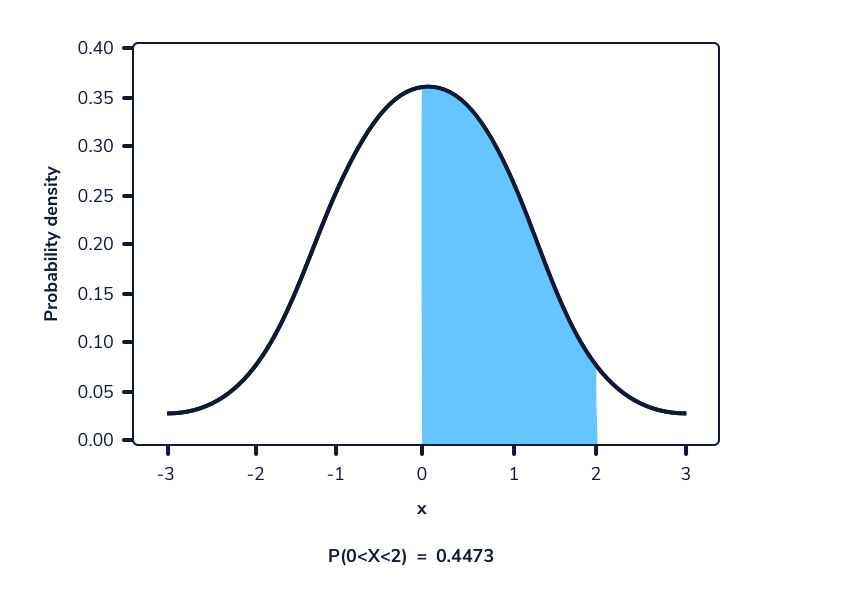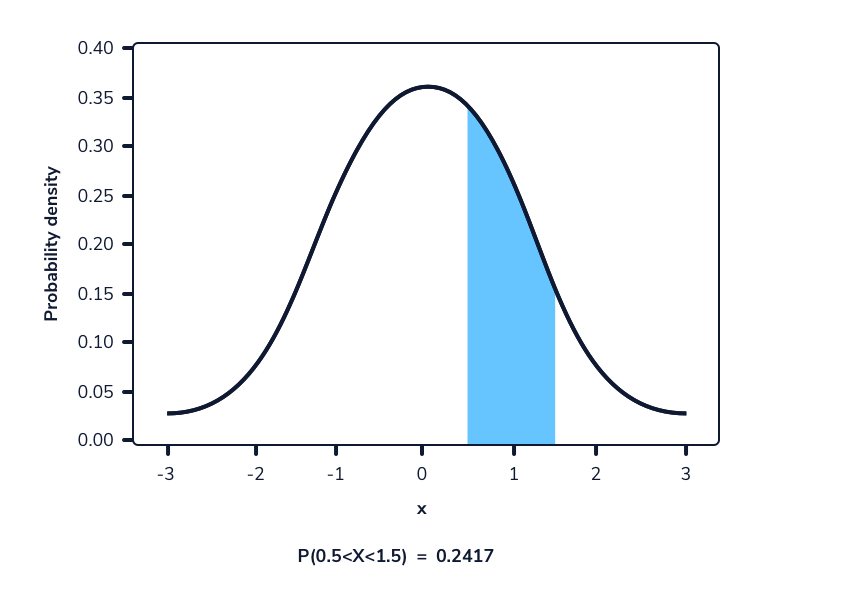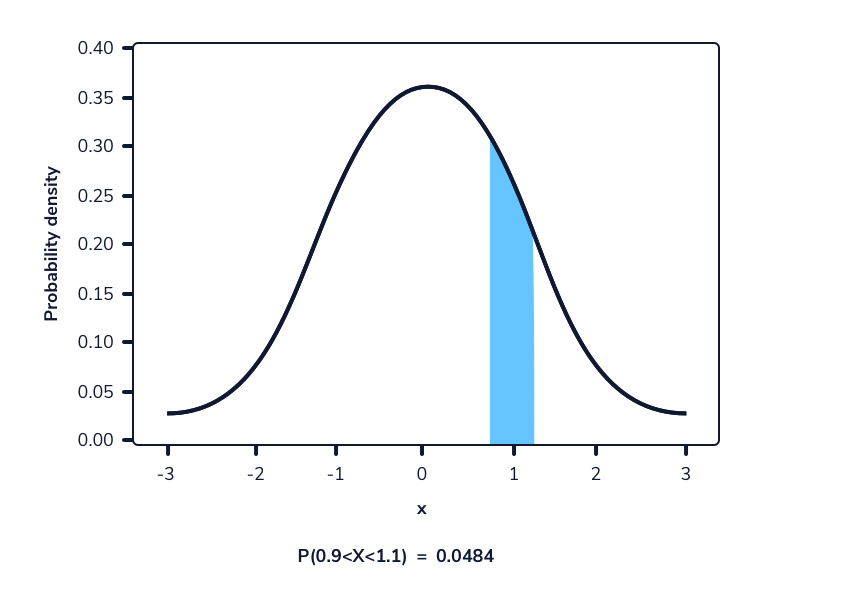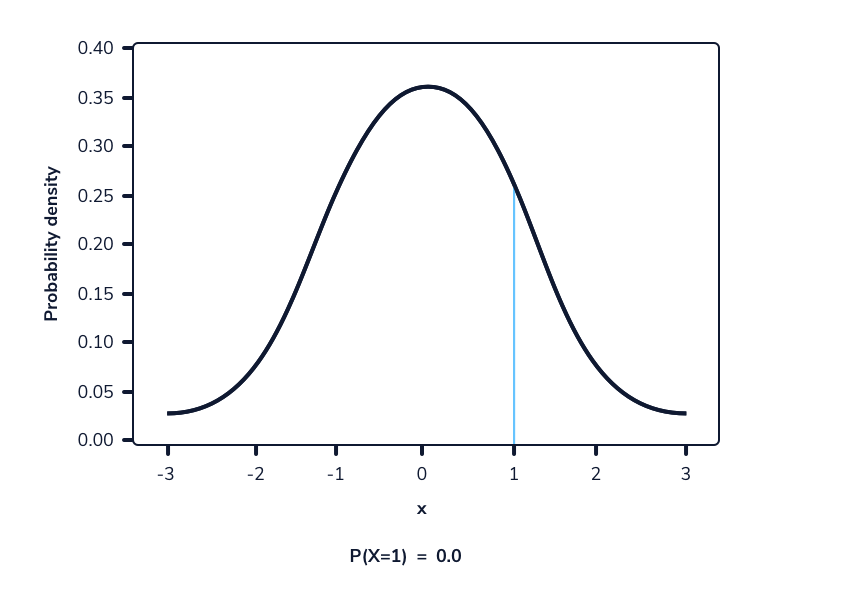
Como podemos ver en la imagen anterior, a medida que el intervalo se hace más pequeño, el ancho del área bajo la curva también se hace más pequeño. Al intentar evaluar el área bajo la curva en un punto específico, el ancho de esa área se vuelve 0 y, por lo tanto, la probabilidad es igual a 0.
Podemos calcular el área bajo la curva usando la función de distribución acumulativa para la distribución de probabilidad dada.
Por ejemplo, las alturas caen bajo un tipo de distribución de probabilidad llamada distribución normal. Los parámetros de la distribución normal son la media y la desviación estándar, y utilizamos la forma Normal(media, desviación estándar) como abreviatura.
Sabemos que la altura de las mujeres tiene una media de 167,64 cm con una desviación estándar de 8 cm, lo que las sitúa bajo la distribución Normal(167,64,8).
Digamos que queremos saber la probabilidad de que una mujer elegida al azar mida menos de 158 cm. Podemos usar la función de distribución acumulativa para calcular el área bajo la curva de la función de densidad de probabilidad de 0 a 158 para encontrar esa probabilidad.

Podemos calcular el área de la región azul en Python usando el método norm.cdf() de la biblioteca scipy.stats. Este método toma 3 valores:
x: el valor del interésloc: la media de la distribución de probabilidadscale: la desviación estándar de la distribución de probabilidadimport scipy.stats as stats
# stats.norm.cdf(x, loc, scale)
print(stats.norm.cdf(158, 167.64, 8))
Output
0.1141
Podemos tomar la diferencia entre dos rangos superpuestos para calcular la probabilidad de que una selección aleatoria esté dentro de un rango de valores para distribuciones continuas. Este es esencialmente el mismo proceso que calcular la probabilidad de un rango de valores para distribuciones discretas.
Digamos que queremos calcular la probabilidad de observar aleatoriamente a una mujer de entre 165 cm y 175 cm, suponiendo que las alturas todavía siguen la distribución Normal (167,74, 8). Podemos calcular la probabilidad de observar estos valores o menos. La diferencia entre estas dos probabilidades será la probabilidad de observar aleatoriamente a una mujer en este rango dado. Esto se puede hacer en Python usando el método norm.cdf() de la biblioteca scipy.stats. Como se mencionó anteriormente, este método adopta 3 valores:
import scipy.stats as stats
# P(165 < X < 175) = P(X < 175) - P(X < 165)
# stats.norm.cdf(x, loc, scale) - stats.norm.cdf(x, loc, scale)
print(stats.norm.cdf(175, 167.74, 8) - stats.norm.cdf(165, 167.74, 8))
Output
0.45194
También podemos calcular la probabilidad de observar aleatoriamente un valor o mayor restando de 1 la probabilidad de observar menos que el valor dado. Esto es posible porque sabemos que el área total bajo la curva es 1, por lo que la probabilidad de observar algo mayor que un valor es 1 menos la probabilidad de observar algo menor que el valor dado.
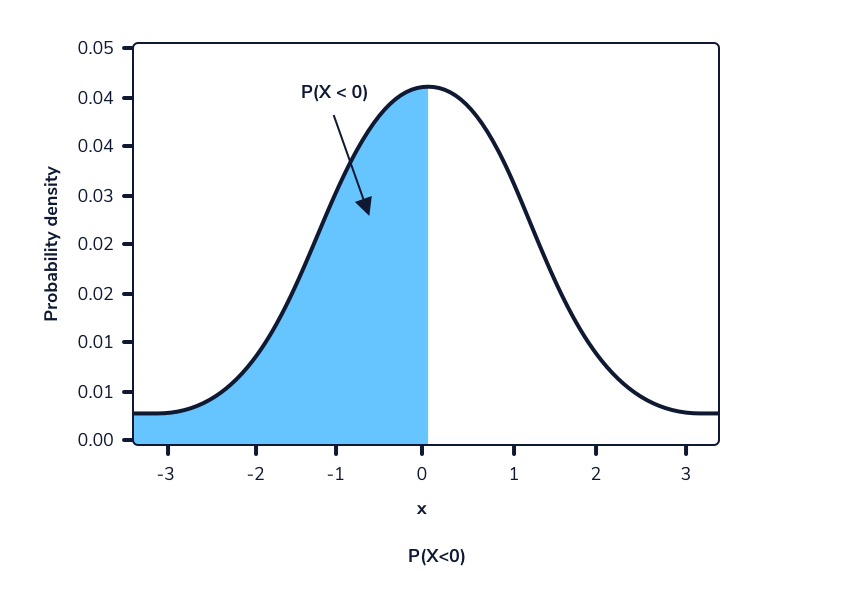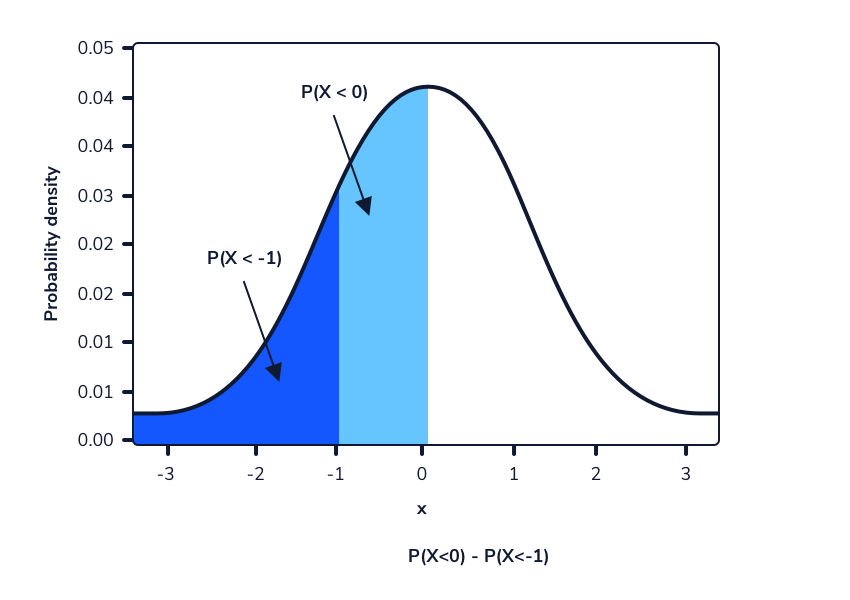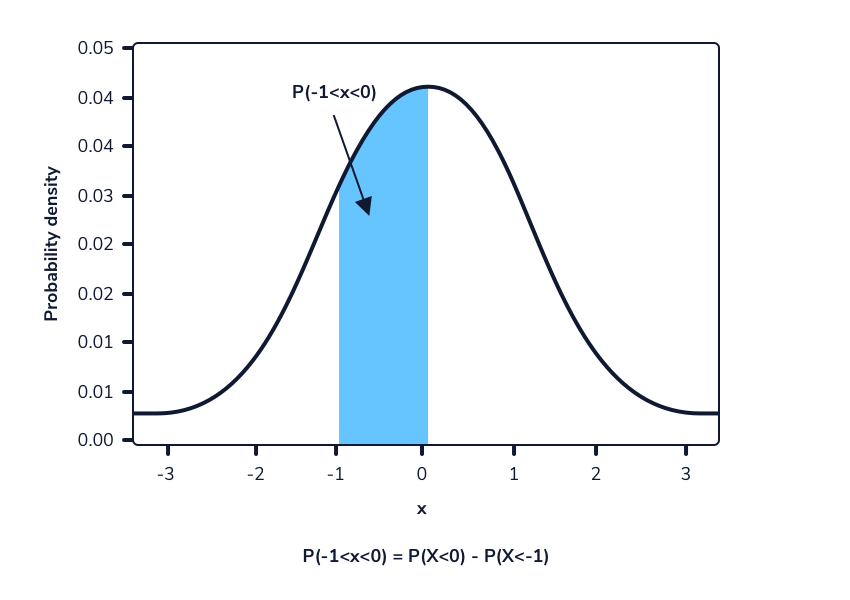
Digamos que queremos calcular la probabilidad de observar a una mujer que mide más de 172 centímetros, suponiendo que las alturas todavía siguen la distribución Normal (167,74, 8). Podemos pensar en esto como lo opuesto a observar a una mujer que mide menos de 172 centímetros. Podemos visualizarlo de esta manera:

Podemos usar el siguiente código para calcular el área azul tomando 1 menos el área roja:
import scipy.stats as stats
# P(X > 172) = 1 - P(X < 172)
# 1 - stats.norm.cdf(x, loc, scale)
print(1 - stats.norm.cdf(172, 167.74, 8))
Output
0.45194
loc: media de la distribución (mu).scale: desviación estándar de la distribución (sigma).size: número de muestras a generar.numpy.random.normal(loc=0.0, scale=1.0, size=None) Genera números a partir de una distribución normal con media loc y desviación estándar scale.scale: inverso de la tasa (lambda), a veces llamado parámetro de escala.size: número de muestras a generar.numpy.random.exponential(scale=1.0, size=None) Genera números a partir de una distribución exponencial con un parámetro de escala.low: límite inferior del rango de los valores.high: límite superior del rango de los valores.size: número de muestras a generar.numpy.random.uniform(low=0.0, high=1.0, size=None) Genera números a partir de una distribución uniforme entre low y high.a: parámetro de forma alpha.b: parámetro de forma beta.size: número de muestras a generar.numpy.random.beta(a, b, size=None) Genera números a partir de una distribución beta con parámetros a y b.shape: parámetro de forma (k).scale: parámetro de escala (theta).size: número de muestras a generar.numpy.random.gamma(shape, scale=1.0, size=None) Genera números a partir de una distribución gamma con un parámetro de forma y escala.Estos métodos permiten simular datos que siguen estas distribuciones, lo que es útil en simulaciones, pruebas de hipótesis, y para entender mejor el comportamiento estadístico de fenómenos modelados por estas distribuciones.
Uno de los pasos fundamentales del Análisis Exploratorio de Datos (EDA) es el Data Wrangling. La transformación de datos es un conjunto de técnicas utilizadas para convertir datos de un formato o estructura a otro, con el fin de hacerlos más útiles, consistentes y listos para el análisis.
En el proceso de preparación de datos, ciertas tareas suelen realizarse en un orden específico para maximizar la eficiencia y efectividad del flujo de trabajo. Un flujo de trabajo típico de limpieza y preparación de datos seria:
Este flujo de trabajo es iterativo y puede requerir ajustes según las necesidades específicas del proyecto y la naturaleza de los datos. Además, algunos pasos pueden superponerse o requerir revisiones cuando surgen nuevos datos o cambios en los requisitos del análisis.
La razón principal para transformar los datos es obtener una representación más útil y compatible con otros conjuntos de datos. Además, la transformación adecuada favorece la interoperabilidad dentro de un sistema al seguir una estructura y formato común.
En el ámbito de la ciencia de datos, “Key Restructuring” se refiere a la reorganización o transformación de las claves en un conjunto de datos.
Las “claves” suelen ser identificadores únicos o combinaciones de campos que sirven para relacionar registros entre sí.
Renombrar Claves
df.rename(columns={'old_name': 'new_name'}, inplace=True)Reasignar Valores de Clave
df['key_column'] = df['key_column'].map(lambda x: 'new_value' if condition else x)Crear Claves Compuestas
df['composite_key'] = df['key_part1'].astype(str) + '-' + df['key_part2'].astype(str)Eliminar Claves Innecesarias
df.drop(columns=['unnecessary_key'], inplace=True)Asegurar la Unicidad
if df['key_column'].is_unique:
print("Las claves son únicas.")
else:
df.drop_duplicates(subset=['key_column'], inplace=True)Reindexación Basada en Claves
df.set_index('key_column', inplace=True)La validación de datos consiste en verificar si los datos cumplen con un conjunto de reglas o normas antes de ser procesados o analizados. Es una etapa crítica, ya que trabajar con datos erróneos o mal formateados puede llevar a conclusiones incorrectas y resultados poco confiables.
df.dtypes
df['column'] = df['column'].astype(float)assert (df['column'] > 0).all()df['text_column'].str.match(r'^\w+$')df.isnull().sum()
df.dropna(subset=['column'], inplace=True)df['column'].is_unique
df.drop_duplicates(subset=['column'], inplace=True)df[(df['column'] >= min_value) & (df['column'] <= max_value)]allowed = {'cat1', 'cat2'}
df['col'].isin(allowed)df.apply(lambda row: row['col1'] < row['col2'], axis=1)La validación debe ser continua, adaptándose a las reglas del negocio y al tipo de análisis o modelo que se esté desarrollando.
La limpieza de datos busca detectar y corregir (o eliminar) registros corruptos, incompletos o inconsistentes, tratando valores faltantes y estandarizando formatos.
df.isnull()df.dropna()df.fillna(method='ffill')df.astype({'col1': 'int32'})df['col'] = df['col'].str.strip().str.lower()df['fecha'] = pd.to_datetime(df['fecha'], errors='coerce')df.to_csv('clean_data.csv', index=False)Una limpieza adecuada es la base para cualquier análisis o modelado confiable.
La deduplicación de datos busca identificar y eliminar registros repetidos dentro de un conjunto de datos. Esto mejora la precisión y evita sesgos en el análisis.
df.drop_duplicates()
df.duplicated()Se puede usar el argumento subset para definir columnas específicas y keep para decidir qué duplicado conservar. Antes de eliminar duplicados, conviene analizar su origen y asegurarse de no eliminar información valiosa.
La derivación de datos consiste en crear nuevas variables o columnas a partir de datos existentes.
df['avg'] = df['value'].mean()df['normalized'] = (df['x'] - df['x'].mean()) / df['x'].std()df['year'] = df['date'].dt.yearpd.get_dummies(df['category'])pd.cut(df['var'], bins=3)df['diff'] = df['value'].diff()Derivar datos correctamente permite enriquecer el conjunto de análisis y mejorar el rendimiento de los modelos.
La revisión de formato implica convertir datos a tipos o estructuras adecuados para el análisis o interoperabilidad.
df['col'] = pd.to_numeric(df['col'], errors='coerce')df['texto'] = df['texto'].str.lower().str.strip()df['fecha'] = pd.to_datetime(df['fecha'])df['cat'] = df['cat'].astype('category')df.to_excel('datos.xlsx', index=False)
df.to_sql('tabla', con=conexion)La agregación de datos permite resumir información, extraer métricas y generar resúmenes útiles.
df.groupby('col')['ventas'].sum()
df.groupby('col').agg({'ventas': ['mean', 'std']})
df.pivot_table(values='ventas', index='mes', columns='region')
pd.crosstab(df['categoria'], df['region'])
df['ventas'].rolling(window=3).mean()
df.resample('M')['ventas'].sum()La agregación facilita el análisis exploratorio y la generación de indicadores clave (KPIs).
El filtrado de datos consiste en seleccionar subconjuntos relevantes según condiciones o criterios específicos.
df[df['edad'] > 30]
df.query('columna > 100')
df[df['pais'].isin(['España', 'Chile'])]
df[(df['ventas'] > 500) & (df['region'] == 'Norte')]También puedes aplicar funciones personalizadas:
df[df['nombre'].apply(lambda x: 'a' in x)]El filtrado ayuda a centrarse en los datos más relevantes y reduce ruido analítico.
El data joining combina conjuntos de datos mediante claves comunes, similar a las uniones de SQL.
pd.concat() – concatenar DataFrames (vertical u horizontalmente)pd.merge() – unión tipo SQL (inner, left, right, outer)df.join() – unión por índice o columnamerge_asof() y merge_ordered() – uniones temporales o ordenadascompare() – detectar diferencias entre DataFramesEjemplos:
pd.concat([df1, df2], axis=0)
pd.merge(df1, df2, on='id', how='left')La unión de datos es esencial para integrar fuentes diversas y construir un dataset analítico coherente.