Cómo evaluar la asociación entre una variable cuantitativa (por ejemplo, una puntuación o precio) y una variable categórica (por ejemplo, tipo de escuela, zona, o profesión).
Ejemplo: Datos de Estudiantes
Supongamos que tenemos un conjunto de datos de estudiantes de dos escuelas portuguesas. Contiene la siguiente información:
- school: escuela del alumno → Gabriel Pereira (
'GP') o Mousinho da Silveira ('MS') - address: zona de residencia →
'U'urbana o'R'rural - absences: número de ausencias durante el curso
- Mjob: profesión de la madre
- Fjob: profesión del padre
- G3: puntuación final del alumno en matemáticas (0 a 20)
Queremos responder:
¿Las puntuaciones de matemáticas (G3) están asociadas con la escuela a la que asisten los estudiantes?
Si es así, conocer la escuela podría ayudarnos a predecir el rendimiento académico.
Diferencias de Medias y Medianas
Una forma inicial de explorar esta relación es comparar las medias y medianas de las puntuaciones en cada grupo.
import numpy as np
# Dividir los puntajes según la escuela
scores_GP = students.G3[students.school == 'GP']
scores_MS = students.G3[students.school == 'MS']
# Calcular medias
mean_GP = np.mean(scores_GP)
mean_MS = np.mean(scores_MS)
mean_diff = mean_GP - mean_MS
print(f"Media GP: {mean_GP:.2f}")
print(f"Media MS: {mean_MS:.2f}")
print(f"Diferencia de medias: {mean_diff:.2f}")
Resultado:
Media GP: 10.49
Media MS: 9.85
Diferencia de medias: 0.64También podríamos usar la mediana en lugar de la media para reducir el efecto de valores extremos.
median_GP = np.median(scores_GP)
median_MS = np.median(scores_MS)
print(f"Median_GP: {median_GP:.2f}")
print(f"Median_MS: {median_MS:.2f}")
print(f"Diferencia de medianas: {median_GP - median_MS:.2f}")Median_GP: 12.00
Median_MS: 11.00
Diferencia de medianas: 1.00Estas diferencias nos dan una idea inicial, pero no nos dicen si la diferencia es relevante o significativa. Para eso, es útil visualizar la dispersión de los datos.
Diagramas de Caja Comparativos
Los diagramas de caja (boxplots) permiten visualizar simultáneamente la distribución, mediana y variabilidad de una variable cuantitativa entre grupos. Esto puede ayudarnos a determinar si las diferencias de medias o medianas son “grandes” o “pequeñas”. Echemos un vistazo a los diagramas de caja de los puntajes de matemáticas en cada escuela:
import seaborn as sns
sns.boxplot(data = students, x = 'address', y = 'G3')
plt.show()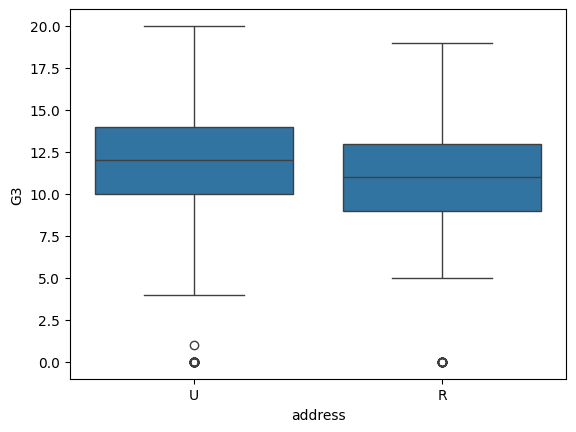
Estos gráficos nos permiten ver si una escuela o zona tiene valores consistentemente más altos, o si las distribuciones se superponen mucho.
Histogramas Superpuestos
Otra opción es comparar las distribuciones con histogramas superpuestos.
Aquí usamos alpha=0.5 para hacerlos semitransparentes, y density=True para que representen proporciones, no frecuencias absolutas (lo cual es importante si los grupos tienen tamaños distintos).
plt.hist(scores_urban , color="blue", label="Urban", density=True, alpha=0.5)
plt.hist(scores_rural , color="red", label="Rural", density=True, alpha=0.5)
plt.legend()
plt.show()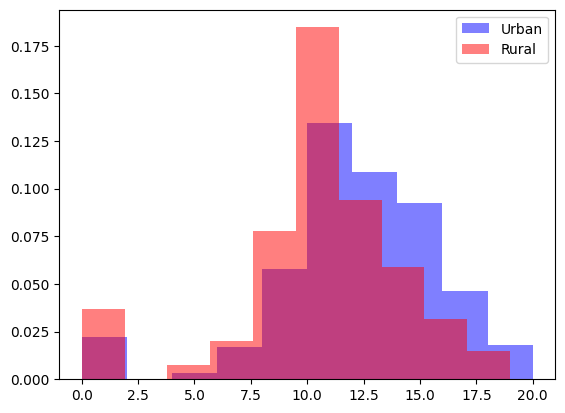
🔍 Interpretación visual:
- Si las curvas están muy superpuestas → la asociación es débil.
- Si una está claramente desplazada a la derecha → hay una diferencia consistente entre grupos.
- Las colas o picos distintos pueden revelar variabilidad o subgrupos (por ejemplo, alumnos destacados).
Variables Categóricas No Binarias
Hasta ahora, hemos trabajado con variables categóricas binarias (dos grupos). Pero ¿Qué ocurre si la categoría tiene más de dos valores?
Por ejemplo, la profesión de la madre (Mjob) puede tener cinco categorías:
at_homehealthservicesteacherother
Podemos visualizar la relación con un boxplot múltiple:
sns.boxplot(data = students, x = 'Mjob', y = 'G3')
plt.show()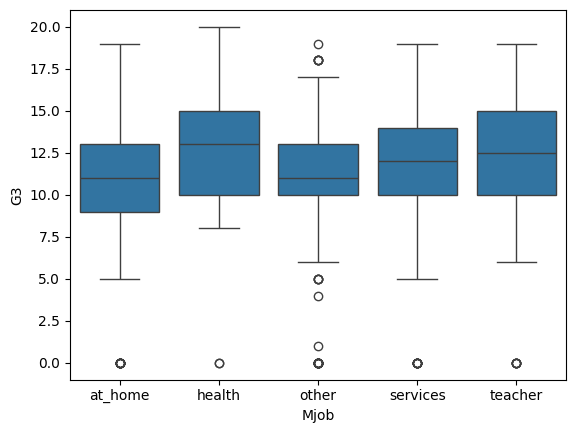
Aquí evaluamos todas las comparaciones por pares. Si al menos un grupo tiene una distribución diferente (por ejemplo, “health” con valores más altos), podemos decir que existe asociación entre las variables.
Deja una respuesta