Tratamiento de Datos Faltantes
¿Qué son los datos faltantes?
Los datos faltantes, también conocidos como valores nulos o valores ausentes, son observaciones para las cuales no existe información registrada en una o más variables de un conjunto de datos. Dependiendo del sistema utilizado, pueden representarse mediante valores como NULL, NaN, None, #N/A o simplemente campos vacíos.
La presencia de datos faltantes es uno de los problemas más frecuentes en Data Science, Machine Learning, Business Intelligence y analítica de datos. De hecho, es raro encontrar conjuntos de datos reales que no contengan algún nivel de información ausente.
¿Por qué es importante gestionar los datos faltantes?
La calidad de cualquier análisis depende directamente de la calidad de los datos utilizados. Cuando existen valores ausentes, se generan vacíos de información que pueden afectar significativamente a los resultados obtenidos.
Los datos faltantes pueden provocar:
- Pérdida de información relevante.
- Disminución del tamaño efectivo de la muestra.
- Sesgos estadísticos.
- Reducción de la precisión de los modelos.
- Conclusiones incorrectas.
- Problemas durante el entrenamiento de algoritmos.
Por ejemplo, si una empresa desea identificar cuáles son los productos más vendidos por color y una de sus tiendas no registra correctamente esa información, los resultados del análisis podrían conducir a decisiones erróneas sobre inventario, compras o marketing.
Por esta razón, el tratamiento de los datos faltantes constituye una de las etapas más importantes dentro de la limpieza y preparación de datos.
¿Por qué aparecen los datos faltantes?
Existen numerosas razones por las que un conjunto de datos puede contener valores ausentes.
- Errores de captura: Los datos nunca fueron introducidos en el sistema. Ejemplo: formularios incompletos, campos opcionales no rellenados y omisiones humanas.
- Problemas de privacidad: Algunos usuarios deciden no proporcionar determinada información personal. Correo electrónico, número de teléfono, ingresos, información médica.
- Fallos técnicos: Pueden producirse errores durante la transmisión de datos, la integración de sistemas, el almacenamiento o la captura mediante sensores.
- Pérdida de información: La corrupción de archivos o interrupciones en sistemas de comunicación también pueden provocar la desaparición de datos válidos.
- Reglas de negocio: En algunos casos la ausencia de información es completamente normal y esperada.
¿Cómo identificar datos faltantes?
Antes de decidir cómo tratarlos, es necesario detectarlos y cuantificarlos.
Las técnicas más habituales incluyen:
- Inspección visual de los datos.
- Revisión de muestras aleatorias.
- Estadísticas descriptivas.
- Perfilado de datos.
- Validación de datos.
- Análisis de porcentajes de ausencia.
Algunas preguntas útiles son:
- ¿Cuántos valores faltan?
- ¿Qué variables están afectadas?
- ¿Existe algún patrón?
- ¿La ausencia afecta a variables importantes?
Tipos de datos faltantes
No todos los valores ausentes tienen el mismo significado. Comprender el motivo de la ausencia es fundamental para seleccionar la estrategia de tratamiento adecuada.
Datos estructuralmente faltantes
Son datos cuya ausencia es esperada debido al contexto del problema.
Por ejemplo:
| Asma | Frecuencia Inhalador |
|---|---|
| Sí | Dos veces al día |
| Sí | Una vez al día |
| No | NULL |
La ausencia de información sobre el inhalador es completamente lógica porque la persona no tiene asma. En estos casos, normalmente no es necesario imputar ningún valor.
Missing Completely At Random (MCAR)
Los datos faltan completamente al azar. La probabilidad de que un dato esté ausente es la misma para todas las observaciones. Ejemplos:
- Fallo aleatorio de un sensor.
- Error aleatorio de transmisión.
- Problema temporal de captura.
Características:
- No existe patrón identificable.
- El riesgo de sesgo es bajo.
- Son los más sencillos de tratar.
Missing At Random (MAR)
La ausencia depende de otras variables observadas.
Ejemplo práctico de MAR
En el dataset “Predict H1N1 and Seasonal Flu Vaccines” de DrivenData, la variable employment_industry presenta aproximadamente un 50% de valores faltantes.
A primera vista podría parecer un problema grave de calidad de datos. Sin embargo, al analizar la relación entre employment_industry y employment_status mediante una tabla de contingencia, se observa que los valores faltantes aparecen casi exclusivamente en personas desempleadas o fuera del mercado laboral.
pd.crosstab(
df['employment_status'],
df['employment_industry'].isna()
)employment_industry False True
employment_status
Employed 13377 183
Not in Labor Force 0 10231
Unemployed 0 1453
¿Cómo interpretar estos datos?
- Entender qué significa False y True:
df['employment_industry'].isna()genera una serie booleana donde:False: existe valor.True: esNaN
Employedmuestra que 13377 empleados tienen industria asignada.Not in Labor Forcemuestra que ninguna persona fuera de la fuerza laboral tiene industria. Todas tienen NaN.Unemployedmuestra que ningún desempleado tiene industria. Todos tienen NaN.
Observa que:
- Employed → casi todos tienen industria
- Not in Labor Force → ninguno tiene industria
- Unemployed → ninguno tiene industria
Esto indica que la ausencia de información no es aleatoria, sino que depende de una variable observada employment_status. O sea ,employment_industry sólo se pregunta a personas empleadas.
En este caso, el mecanismo de ausencia desde una perspectiva estadística estricta: se clasifica como MAR (Missing At Random), ya que la probabilidad de que falte el dato puede explicarse mediante información disponible en el conjunto de datos.
Desde una perspectiva de negocio, también puede interpretarse como Missing Not Applicable (MNAR estructural) . La variable no está ausente por error. Está ausente porque la pregunta no aplica al individuo. La pregunta: ¿En qué industria trabaja? no tiene sentido para alguien desempleado.
En un proyecto profesional puede documentarse de la siguiente manera:
employment_industrypresenta aproximadamente un 50% de valores nulos.El análisis mediante tablas de contingencia muestra que la ausencia depende completamente de la variable employment_status.
Los individuos desempleados o fuera de la fuerza laboral no disponen de industria asociada, por lo que los valores ausentes parecen corresponder a casos donde la variable no aplica al individuo más que a pérdidas aleatorias de información.
Por tanto, los valores ausentes se consideran ausencias estructurales dependientes de employment_status (MAR) y serán tratados como una categoría específica.
¿Qué hacer en estos casos?
En estos casos la solución sería crear una categoría explícita que identifique la causa del valor faltante, por ejemplo: Not_Working.
df['employment_industry'] = (
df['employment_industry']
.fillna('Not_Working')
)Ya puedes documentar algo como:
Conclusión de calidad de datos
| Variable | % Nulos | Tipo de ausencia | Acción |
|---|---|---|---|
| employment_industry | 49.9% | No aplicable (dependiente de employment_status) | Crear categoría “Not_Working” |
Missing Not At Random (MNAR)
La ausencia está relacionada con el propio valor que falta.
Ejemplo:
- Personas con ingresos muy elevados deciden no declarar sus ingresos.
- Pacientes con problemas graves evitan responder determinadas preguntas médicas.
Características:
- Existe un patrón subyacente.
- Puede introducir sesgos importantes.
- Es el tipo más difícil de tratar.
Missing Not At Random (MNAR): cuando la ausencia de datos también es información
Missing Not At Random (MNAR) es cuando la probabilidad de que un valor esté ausente está relacionada con características del propio individuo o con información que no ha sido observada. En estos casos, puede ser que los registros con valores faltantes representen un grupo específico dentro de la población y no una simple muestra aleatoria.
Durante el análisis exploratorio del proyecto Predict H1N1 and Seasonal Flu Vaccines se identificó un patrón muy claro de ausencia de datos que sugiere la existencia de un mecanismo MNAR. En lugar de encontrar valores faltantes distribuidos de manera independiente entre distintas variables, se observó que los mismos individuos tendían a presentar ausencias simultáneas en múltiples campos del cuestionario.
Por ejemplo, las variables:
educationemployment_statusmarital_statusrent_or_own
Presentaban valores faltantes altamente relacionados entre sí. Los registros con ausencia en una de estas variables tenían una elevada probabilidad de presentar también valores faltantes en las demás. Además, este mismo grupo de individuos mostraba ausencias en variables relacionadas con la salud y la situación personal, como:
health_workerchild_under_6_monthschronic_med_condition
e incluso en variables de percepción y opinión sobre las vacunas, entre ellas:
opinion_h1n1_riskopinion_h1n1_vacc_effectiveopinion_h1n1_sick_from_vaccopinion_seas_riskopinion_seas_vacc_effectiveopinion_seas_sick_from_vacc
Las correlaciones entre los indicadores de ausencia de estas variables fueron especialmente elevadas. Por ejemplo:
health_workerychild_under_6_monthspresentaron una correlación de ausencia cercana a 0.97.health_workerychronic_med_conditionmostraron correlaciones superiores a 0.80.education,employment_status,marital_statusyrent_or_owntambién mostraron correlaciones de ausencia muy elevadas, superiores a 0.70 en numerosos casos.
Este comportamiento resulta difícil de explicar mediante un mecanismo completamente aleatorio. Si los valores faltantes fueran independientes, las ausencias aparecerían distribuidas de forma dispersa entre los registros. Sin embargo, lo observado fue la existencia de un subconjunto de encuestados que parecía haber omitido responder bloques completos de preguntas.
La evidencia se reforzó al analizar la relación entre los valores faltantes y las variables objetivo del problema: la vacunación contra la gripe H1N1 y la gripe estacional. En varias variables, los individuos con información ausente mostraban tasas de vacunación significativamente distintas de las observadas en las categorías existentes.
Un ejemplo especialmente representativo fue la variable health_insurance. Mientras que los individuos con seguro médico presentaban tasas de vacunación considerablemente más altas, el grupo con información desconocida mostraba un comportamiento claramente diferenciado tanto de quienes tenían seguro como de quienes declaraban no tenerlo. Esto sugiere que la ausencia de respuesta estaba asociada a características específicas de los encuestados.
Otro caso relevante fue el de las variables doctor_recc_h1n1 y doctor_recc_seasonal. Los individuos con valores faltantes en estas variables también presentaban una elevada proporción de valores desconocidos en health_insurance, lo que evidenciaba un patrón común de no respuesta. Además, sus tasas de vacunación diferían notablemente de las observadas en los grupos que sí habían respondido a estas preguntas.
Estos hallazgos muestran que los valores faltantes no eran simplemente datos perdidos, sino una característica adicional de los individuos. En otras palabras, la ausencia de información contenía información.
Por este motivo, en lugar de aplicar imputaciones tradicionales basadas en la moda o en otras medidas de tendencia central, se optó por conservar los valores faltantes como una categoría específica denominada Unknown en aquellas variables donde la ausencia mostraba evidencia de ser informativa.
Esta estrategia permite que los algoritmos de Machine Learning identifiquen posibles patrones asociados a la falta de respuesta y aprovechen dicha información durante el entrenamiento. En problemas de clasificación como este, donde la métrica de evaluación es ROC-AUC, preservar la información contenida en los patrones de ausencia puede resultar tan importante como conservar los propios valores observados.
Este caso constituye un ejemplo práctico de cómo el análisis detallado de los datos faltantes puede revelar comportamientos ocultos en la población estudiada y demuestra que, en muchos escenarios reales, los valores ausentes no deben considerarse simplemente como datos perdidos, sino como una fuente potencial de información predictiva.
Aquí tienes una sección orientada a un artículo técnico y educativo:
Cómo detectar patrones MNAR mediante el análisis de valores faltantes en Python
Una de las formas más efectivas de identificar posibles mecanismos Missing Not At Random (MNAR) consiste en analizar si los valores faltantes aparecen agrupados en los mismos registros. Cuando múltiples variables presentan ausencias simultáneas de forma recurrente, puede existir un patrón de no respuesta que aporte información relevante para el modelo.
Crear una matriz de valores faltantes
El primer paso consiste en transformar los valores faltantes en variables binarias, donde:
1indica que el valor está ausente.0indica que el valor está presente.
missing_df = df.isnull().astype(int)Cada columna representa ahora el patrón de ausencia de una variable.
Calcular correlaciones entre valores faltantes
Una vez creada la matriz de ausencia, es posible calcular las correlaciones entre los patrones de valores faltantes. Por ejemplo, para analizar qué variables presentan ausencias relacionadas con health_worker:
missing_df.corr()['health_worker'].sort_values(ascending=False)La salida mostrará qué variables tienden a presentar valores faltantes en los mismos registros. En este proyecto se observaron correlaciones muy elevadas:
child_under_6_months 0.97
chronic_med_condition 0.82
education 0.73
marital_status 0.73
employment_status 0.72
rent_or_own 0.60Estas correlaciones sugieren que los individuos que no respondieron a una determinada pregunta también omitieron otras preguntas relacionadas.
Filtrar únicamente las correlaciones relevantes
Cuando existen muchas variables, resulta útil visualizar únicamente aquellas correlaciones superiores a un determinado umbral df.coor() permite identificar rápidamente las relaciones más fuertes entre patrones de ausencia.
corrs = missing_df.corr()['health_worker']
corrs[
(corrs > 0.5) &
(corrs < 1)
].sort_values(ascending=False)
Analizar visualmente la coincidencia de valores faltantes
pd.crosstab() crea una tabla de contingencia que muestra cuántas observaciones pertenecen simultáneamente a cada combinación de categorías.
pd.crosstab(
df['employment_status'].isna(),
df['marital_status'].isna()
)Primero se transforman ambas variables en valores booleanos:
False: el dato está presente.True: el dato está ausente (NaN).
La tabla resultante es:
marital_status False True
employment_status
False 25103 141
True 196 1267Interpretación:
| employment_status | marital_status | Registros |
|---|---|---|
| Presente | Presente | 25.103 |
| Presente | Ausente | 141 |
| Ausente | Presente | 196 |
| Ausente | Ausente | 1.267 |
El dato más relevante es la celda:
employment_status = True
marital_status = Trueque contiene:
1267 registrosEsto significa que 1.267 personas tienen valores faltantes simultáneamente en ambas variables, lo que sugiere que las ausencias no se producen de forma independiente y podrían formar parte de un mismo patrón de no respuesta.
Crear un mapa de calor de los patrones de ausencia
Una forma visual de identificar relaciones entre valores faltantes consiste en representar la matriz de correlaciones mediante un mapa de calor.
cols = [
'education',
'employment_status',
'marital_status',
'rent_or_own',
'health_worker',
'child_under_6_months',
'chronic_med_condition',
'opinion_h1n1_risk',
'opinion_h1n1_vacc_effective',
'opinion_h1n1_sick_from_vacc',
'opinion_seas_risk',
'opinion_seas_vacc_effective',
'opinion_seas_sick_from_vacc'
]
corr_missing = (df[cols].isnull().astype(int).corr())
plt.figure(figsize=(12,10))
sns.heatmap(corr_missing, annot=True, cmap='Reds', fmt='.2f')
plt.title('Patrón MNAR detectado en el conjunto de datos')
plt.show()
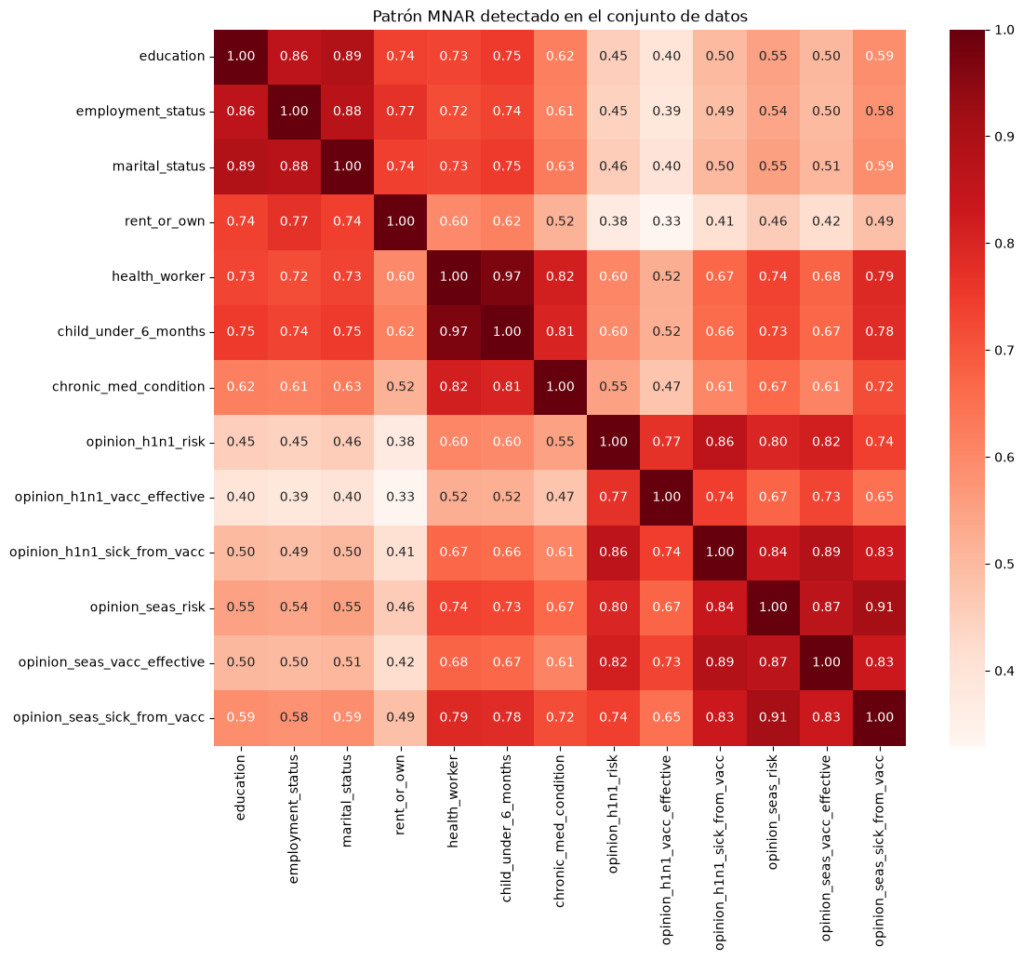
Las zonas con colores más intensos indican grupos de variables cuyos valores faltantes aparecen conjuntamente.
Interpretación de los resultados
Cuando varias variables presentan:
- Correlaciones elevadas entre sus patrones de ausencia.
- Coincidencia frecuente de valores faltantes en los mismos registros.
- Comportamientos diferenciados respecto a la variable objetivo.
Es razonable sospechar la existencia de un mecanismo MNAR (Missing Not At Random).
En estos casos, imputar automáticamente los valores faltantes mediante la media, la mediana o la moda puede provocar una pérdida de información. Una estrategia habitual consiste en conservar los valores faltantes como una categoría específica (Unknown) para permitir que el modelo capture la señal contenida en el propio patrón de ausencia.
Comparación entre tipos de datos faltantes
| Tipo | Existe una causa identificable | Riesgo de sesgo | Dificultad de tratamiento |
|---|---|---|---|
| Estructuralmente faltantes | Sí | Bajo | Baja |
| MCAR | No | Bajo | Baja |
| MAR | Sí | Medio | Media |
| MNAR | Sí | Alto | Alta |
Estrategias de tratamiento de datos faltantes
Una vez identificado el problema, existen diferentes formas de gestionarlo.
- Eliminación de registros: Consiste en eliminar las filas que contienen datos faltantes. Suele utilizarse cuando:
- La cantidad de valores faltantes es reducida.
- Los datos son MCAR.
- La pérdida de observaciones no afecta al análisis.
- Eliminación de variables: Consiste en eliminar columnas con un porcentaje muy elevado de valores ausentes.
- Imputación: La imputación consiste en reemplazar los valores faltantes mediante estimaciones. Las técnicas más utilizadas son:
- Imputación Simple: Media, mediana, moda o valor constante
- Imputación por KNN: Utiliza observaciones similares
- Imputación Múltiple (MICE): Estima valores mediante modelos iterativos
Métodos para series temporales
- Cuando los datos tienen una dimensión temporal, pueden emplearse técnicas específicas. Algunas de las más utilizadas son:
- LOCF: Última observación arrastrada hacia delante
- NOCB: Próxima observación arrastrada hacia atrás
- Interpolación: Estimación entre valores conocidos
¿Cuándo eliminar y cuándo imputar?
La decisión depende del contexto y del volumen de datos faltantes.
| Situación | Estrategia recomendada |
|---|---|
| Menos del 5% de valores faltantes | Eliminación o imputación simple |
| Variable poco relevante | Eliminación |
| Variable importante | Imputación |
| Datos MCAR | Eliminación o imputación |
| Datos MAR | Imputación |
| Datos MNAR | Análisis específico del problema |
| Más del 60% de valores faltantes | Evaluar eliminar la variable |
Beneficios del tratamiento de datos faltantes
- Mejora la calidad del dataset.
- Reduce errores analíticos.
- Incrementa la precisión de los modelos.
- Disminuye sesgos.
- Permite aprovechar más información.
- Facilita el entrenamiento de algoritmos.
- Incrementa la confianza en los resultados.
Ventajas
- Permite trabajar con conjuntos de datos incompletos.
- Reduce el impacto de la pérdida de información.
- Mejora la representatividad de la muestra.
- Incrementa la calidad de los análisis.
- Facilita la toma de decisiones basada en datos.
Desventajas
- Algunas técnicas introducen estimaciones artificiales.
- Existe riesgo de introducir sesgos.
- La imputación puede alterar distribuciones originales.
- Algunas técnicas son computacionalmente costosas.
- Requiere conocimiento del contexto de negocio.
Limitaciones
- Los datos faltantes nunca pueden recuperarse con total certeza.
- Las imputaciones son estimaciones, no valores reales.
- Los datos MNAR siguen siendo difíciles de modelar.
- Una estrategia incorrecta puede degradar el rendimiento del modelo.
- No existe una técnica universalmente mejor.
Por ello, comprender el origen de la ausencia suele ser más importante que la técnica utilizada para corregirla.
Aplicaciones en Data Science y Machine Learning
El tratamiento de datos faltantes aparece prácticamente en cualquier proyecto basado en datos. La mayoría de los algoritmos requieren datos completos o una gestión adecuada de los valores faltantes antes del entrenamiento.
Implementación en Python
Detectar valores nulos
import pandas as pd
df = pd.read_csv("datos.csv")
print(df.isnull().sum())
Calcular porcentaje de valores faltantes
porcentaje_nulos = (
df.isnull().mean() * 100
)
print(porcentaje_nulos)
Eliminar registros con valores faltantes
df_sin_nulos = df.dropna()
Eliminar columnas con valores faltantes
df = df.dropna(axis=1)
Imputación simple
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(
strategy="mean"
)
df["edad"] = imputer.fit_transform(
df[["edad"]]
)
Buenas prácticas
- Identificar primero el tipo de ausencia.
- Analizar el porcentaje de valores faltantes.
- Comprender el contexto de negocio.
- Evitar eliminar datos innecesariamente.
- Comparar diferentes estrategias.
- Documentar todas las transformaciones realizadas.
- Validar el impacto sobre el modelo final.
Conclusión
Los datos faltantes constituyen uno de los problemas más frecuentes en cualquier proyecto de análisis de datos. Su presencia puede afectar significativamente la calidad de los análisis, introducir sesgos y reducir la precisión de los modelos predictivos.
Sin embargo, no todos los datos faltantes son iguales. Comprender si la ausencia es estructural, MCAR, MAR o MNAR resulta fundamental para seleccionar la estrategia adecuada. Una vez identificado el origen del problema, pueden aplicarse técnicas como la eliminación de registros, la eliminación de variables o diferentes métodos de imputación.
Más que una tarea técnica aislada, el tratamiento de datos faltantes es un proceso de análisis y toma de decisiones que busca preservar la mayor cantidad posible de información sin comprometer la fiabilidad de los resultados. Por ello, constituye una etapa esencial dentro de cualquier flujo de trabajo de Data Science y Machine Learning.