El objetivo de este laboratorio:
- Aplicar transformaciones para que la variable objetivo tenga una distribución más normal para la regresión.
- Aplicar transformaciones inversas para poder utilizarlas en un contexto de regresión.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inlineEn las siguientes celdas cargaremos los datos y definiremos algunas funciones de grafico útiles.
np.random.seed(72018)
# Adapta el formato de los datos para que sean compatibles con librerías como Scikit-Learn.
def to_2d(array):
return array.reshape(array.shape[0], -1)
# Simula y visualiza variables que crecen de forma exponencial o que tienen un sesgo extremo.
def plot_exponential_data():
data = np.exp(np.random.normal(size=1000))
plt.hist(data)
plt.show()
return data
# Evalúa el impacto de aplicar transformaciones no lineales cuadráticas sobre variables originalmente estables.
def plot_square_normal_data():
data = np.square(np.random.normal(loc=5, size=1000))
plt.hist(data)
plt.show()
return dataCargar los datos
url = "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-ML240EN-SkillsNetwork/labs/data/boston_housing_clean.pickle"
wget.download(url)Cargando los datos de vivienda de Boston (Boston Housing Data)
with open('boston_housing_clean.pickle', 'rb') as to_read:
boston = pd.read_pickle(to_read)
boston_data = boston['dataframe']
boston_description = boston['description']print(boston_data.head()) CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT MEDV
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33 36.2
print(boston_description)Boston House Prices dataset
===========================
Notes
------
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
http://archive.ics.uci.edu/ml/datasets/Housing
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
**References**
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
- many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)Determinación de la normalidad
Lograr que nuestra variable objetivo tenga una distribución normal a menudo conducirá a mejores resultados. Si nuestra variable objetivo no está distribuida normalmente, podemos aplicarle una transformación y luego ajustar nuestra regresión para predecir los valores transformados.
# Analicemos el valor medio de las viviendas ocupadas por sus dueños (en miles de dólares).
boston_data.MEDV.hist()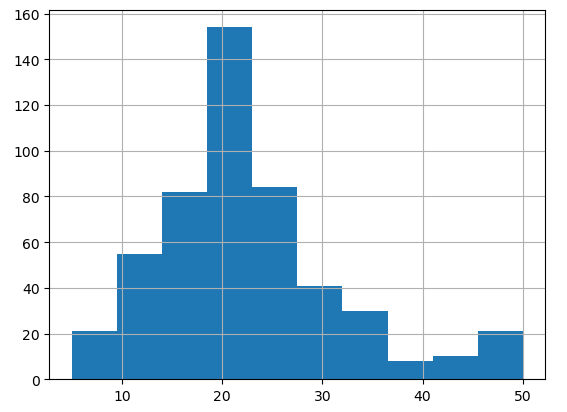
El histograma no parece normal debido a su cola derecha.
Sin entrar en debates entre bayesianos y frecuentistas, para los propósitos de esta lección bastará con lo siguiente: Los estadísticos frecuentistas dirían que se acepta que la distribución es normal (más específicamente: no se rechaza la hipótesis nula de que es normal) si p > 0.05.
# D'Agostino K^2 Test
from scipy.stats.mstats import normaltest
Result = normaltest(boston_data.MEDV)
print(f"p-value: {Result.pvalue} \nstatistic: {Result.statistic}")p-value: 1.7583188871696095e-20
statistic: 90.9746873700967El valor p es extremadamente bajo. ¡Nuestra variable, con la que hemos estado lidiando todo este tiempo, no estaba distribuida normalmente!
Aplicar transformaciones para que la variable objetivo tenga una distribución más normal para aplicar la regresión.
La regresión lineal asume que los residuos se distribuyen normalmente, lo cual se puede facilitar transformando la variable y, que es la variable objetivo. Probemos algunas transformaciones comunes para intentar que y se distribuya normalmente:
- Transformación de Box-Cox
- Transformación logarítmica
- Transformación de raíz cuadrada
Transformación logarítmica
La transformación logarítmica puede transformar datos con un sesgo significativo a la derecha para que tengan una distribución más normal: