En los articulos anteriores establecimos el framework operativo del aprendizaje supervisado y diferenciamos las variables continuas de las categóricas. Ahora, abriremos el capó matemático para analizar el algoritmo predictivo más fundamental, transparente y utilizado en la historia de la ciencia de datos: la Regresión Lineal.

La Anatomía de la Ecuación Lineal
Para entender su funcionamiento, utilizaremos un caso de estudio clásico: predecir la recaudación en taquilla de una película (Box Office Revenue) basándonos única y exclusivamente en su presupuesto de marketing (Marketing Budget).
Cuando disponemos de un histórico de datos (nuestro training set) con el presupuesto invertido y la recaudación real de múltiples películas, podemos plasmar esa información en un gráfico de dispersión (scatter plot). Veremos una nube de puntos dispersos donde el eje X representa la variable predictora (marketing) y el eje Y representa la variable objetivo (recaudación).
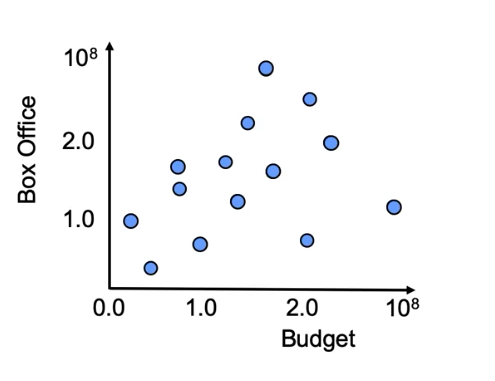
El objetivo de la regresión lineal es trazar una línea recta que atraviese esa nube de puntos de la forma más óptima posible. Matemáticamente, la ecuación de esta recta se define de la siguiente manera:
$$Y_\beta(X) = \beta_0 + \beta_1X$$
Desglose analítico de sus componentes esenciales para la ingeniería de modelos:
- \(Y_\beta(X) \): (Variable objetivo o prediccion / Target), en este caso se corresponde a Box Office Revenue (Recaudación en taquilla)
- \(X \) (Variable independiente o Caracteristica / Feature): Es la información que utilizamos para realizar la predicción, en este caso, el presupuesto de marketing.
- \(\beta_0\) (El Intercepto / Bias): Es el coeficiente que determina dónde corta la recta al eje \(Y\). Físicamente representa el escenario donde la variable \(X\) vale exactamente cero. En nuestro ejemplo, nos indica cuál sería la recaudación base de una película si no se invirtiera absolutamente nada en marketing.
- \(\beta_1\) (La Pendiente / Slope): Es el coeficiente que mide la inclinación de la recta. Indica el impacto directo de la característica sobre el objetivo: por cada euro extra invertido en marketing, ¿cuántos euros aumentará la recaudación en taquilla?
El modelo intentará aprender la relación entre:
- Presupuesto de la película (\(X\))
- Recaudación en taquilla (\(Y\))
para poder estimar la recaudación de futuras películas.
Articulos relacionados:
Del Modelo Lineal Simple a la Regresión por Mínimos Cuadrados
Regresión de Mínimos Cuadrados Ordinarios (OLS)
Caso Práctico: Interpretando un Modelo Ajustado
Supongamos que alimentamos nuestro algoritmo con el dataset histórico y, tras el proceso de optimización, el sistema calcula los siguientes coeficientes óptimos:
- \(\beta_0 = 80\text{ millones}\)
- \(\beta_1 = 0.6\)
Nuestra ecuación predictiva final queda estructurada así:
$$\text{Recaudación} = 80\text{M} + 0.6 \times (\text{Presupuesto Marketing})$$
Interpretación Económica del Modelo:
- Recaudación Base (\(\beta_0\)): Si lanzamos una película con cero presupuesto de marketing (\(X = 0\)), el modelo estima que aun así recaudará 80 millones de euros gracias a factores orgánicos (como la sinopsis o los actores).
- Retorno de Inversión (\(\beta_1\)): El coeficiente \(0.6\) nos dice que por cada dólar o euro adicional que la productora inyecte en marketing, la taquilla responderá incrementándose en \(0.6\) dólares o de manera proporcional.
Generando Predicciones:
Si una nueva producción planea invertir un presupuesto de marketing de 160 millones, sustituimos el valor en nuestra función matemática entrenada:
$$\text{Recaudación} = 80\text{M} + 0.6 \times (160\text{M}) = 80\text{M} + 96\text{M} = 176\text{M}$$
El modelo predice con alta transparencia que la recaudación estimada se situará en torno a los 176 millones.
¿Cómo encuentra el algoritmo la recta perfecta?
Si tomamos una regla, podríamos trazar infinitas líneas rectas diferentes cruzando el gráfico de dispersión. El Machine Learning descarta la aleatoriedad utilizando una función de pérdida o costo (\(J\)) para medir matemáticamente la calidad de cada recta posible.
Para cualquier línea propuesta, existirá una diferencia (un error) entre los puntos reales observados en el mundo real (\(Y_{\text{obs}}\)) y las predicciones teóricas situadas exactamente sobre la recta (\(Y_{\beta}\)).
La distancia vertical que separa a cada punto de la recta representa la magnitud del error de esa observación específica. La fórmula base del error individual es:
$$\text{Error} = Y_{\text{pred}} – Y_{\text{real}}$$
La Función de Costo Estándar: Error Cuadrático Medio (MSE)
No podemos simplemente sumar los errores individuales de todas las películas para evaluar el modelo, porque los errores de los puntos que están por encima de la recta (positivos) se cancelarían matemáticamente con los errores de los puntos que están por debajo (negativos).
Para solucionar esto e ignorar el signo enfocándonos solo en la magnitud, la ciencia de datos utiliza la distancia euclidiana al cuadrado (conocida como la norma L2), dando origen a la función de costo por excelencia en regresión: el Error Cuadrático Medio (Mean Squared Error o MSE).
Matemáticamente, el MSE calcula el promedio de los errores elevados al cuadrado para todas las observaciones del set de entrenamiento:
$$J(\beta_0, \beta_1) = \frac{1}{m} \sum_{i=1}^{m} (Y_{\text{pred}}^{(i)} – Y_{\text{real}}^{(i)})^2$$
(Nota técnica de producción: En los manuales de cálculo avanzado y optimización, es común ver la función escrita multiplicando el denominador por dos, es decir, \(\frac{1}{2m}\). Esto se hace únicamente para facilitar las operaciones de derivación mediante cálculo infinitesimal al buscar mínimos, pero el resultado de optimización matemática para hallar los coeficientes es exactamente equivalente a usar \(\frac{1}{m}\) ).
El trabajo del algoritmo de regresión lineal consiste en encontrar la combinación exacta de valores para \(\beta_0\) y \(\beta_1\) que logre minimizar el MSE a su valor más bajo posible. La recta que logre reducir al mínimo esta distancia cuadrática promedio será, por definición, la recta óptima.
Articulo realcionado:
Error Cuadrático Medio (Mean Squared Error o MSE): Qué es y Cómo Interpretarlo
Buenas Prácticas de Modelado y Despliegue en Python
Una vez comprendida la estructura de la Regresión Lineal y cómo la función de costo del Error Cuadrático Medio (MSE) permite encontrar la recta óptima, es crucial abordar cómo gestionamos los modelos en la práctica profesional. Para construir soluciones de Machine Learning robustas, los científicos de datos siguen un protocolo estricto de ingeniería, evalúan la varianza explicada mediante estadística avanzada y traducen las ecuaciones matemáticas en scripts de código funcionales.
Buenas Prácticas Universales en el Modelado Predictivo
Cuando nos enfrentamos a un problema de regresión en producción, el flujo de trabajo no consiste en lanzar un algoritmo a ciegas. La metodología de ingeniería de datos dicta tres pasos esenciales:
- Establecer la Función de Costo: Antes de entrenar, definimos qué función matemática queremos minimizar (por ejemplo, el MSE). Esto nos proporciona una métrica objetiva y estandarizada para comparar la fuerza de un modelo frente a otro.
- Desarrollar Múltiples Modelos: Creamos arquitecturas variadas, experimentando con diferentes hiperparámetros o algoritmos alternativos para evaluar cuál se adapta mejor a la complejidad de los datos.
- Comparar y Seleccionar: Contrastamos cuantitativamente las puntuaciones (scores) de todos los experimentos bajo la misma función de costo y seleccionamos el modelo con el rendimiento óptimo.
Descifrando el Coeficiente de Determinación: R-cuadrado
Aunque el MSE mide la magnitud del error, su valor depende de la escala de la variable objetivo. Para obtener una métrica de rendimiento estandarizada e independiente de la escala, recurrimos al Coeficiente de Determinación o \(R^2\).
El \(R^2\) es una métrica que mide la proporción de la variación total de los datos que es explicada con éxito por el modelo. Para entender su matemática, debemos desglosar sus dos componentes principales:
Representa la variación total de los datos. Físicamente, equivale al error que cometeríamos si no usáramos Machine Learning y nos limitáramos a trazar una línea horizontal estática basada en el promedio.
Articulo relacionado:
Implementación en Python con Scikit-Learn
Para llevar este ecosistema matemático a la práctica, la comunidad de Data Science utiliza la librería estándar Scikit-Learn (sklearn). El flujo de codificación sigue una estructura limpia de programación orientada a objetos dividida en tres pasos clave:
Paso 1: Importar e Instanciar
En primer lugar, importamos la clase especializada desde el módulo correspondiente e instanciamos el objeto de nuestro modelo. En esta etapa, el algoritmo existe como una estructura matemática vacía, ya que aún no ha visto ningún dato histórico.
from sklearn.linear_model import LinearRegression
# Creamos el objeto del modelo (aún sin ajustar)
lr = LinearRegression()Paso 2: El Proceso de Ajuste (fit)
Pasamos los conjuntos de datos históricos de entrenamiento (x_train y y_train) al método .fit(). En este punto, el motor de Scikit-Learn ejecuta las optimizaciones numéricas necesarias para minimizar la función de costo y calcular los coeficientes (\(\beta_0, \beta_1\)) óptimos.
# El modelo analiza los datos y optimiza sus parámetros internos
lr.fit(x_train, y_train)Paso 3: Generación de Predicciones (predict)
Una vez que el modelo cuenta con sus parámetros fijos y entrenados, el método .predict() queda completamente habilitado. Ahora podemos pasarle una matriz de características de prueba (x_test) que el sistema nunca haya visto para calcular de forma automática las estimaciones numéricas correspondientes.
# Predecimos valores continuos para un conjunto de prueba sin etiquetas
predictions = lr.predict(x_test)