La Base para Evaluar Modelos de Machine Learning
Uno de los objetivos fundamentales de cualquier proyecto de Machine Learning es construir modelos capaces de generalizar correctamente sobre datos que nunca han visto. Para conseguirlo utilizamos técnicas como el Train/Test Split, reservando una parte de los datos para evaluar el rendimiento real del modelo.
El Train/Test Split es el proceso mediante el cual dividimos nuestro conjunto de datos en dos partes:
- Conjunto de entrenamiento (Training Set)
- Conjunto de prueba (Test Set)
El conjunto de entrenamiento se utiliza para que el algoritmo aprenda los patrones presentes en los datos. El conjunto de prueba se reserva y permanece oculto durante el entrenamiento. Solo se utiliza al final para evaluar el rendimiento real del modelo.

La idea es simular una situación del mundo real. Entrenamos con datos históricos y evaluamos con datos que el modelo nunca ha visto.
El Objetivo Real del Machine Learning
Muchas personas creen que el objetivo del Machine Learning es obtener el mejor rendimiento posible sobre los datos disponibles. En realidad, el objetivo es diferente. El objetivo es construir modelos capaces de generalizar correctamente sobre datos que nunca han visto. Por eso la evaluación debe realizarse utilizando información que haya permanecido completamente separada durante el entrenamiento.
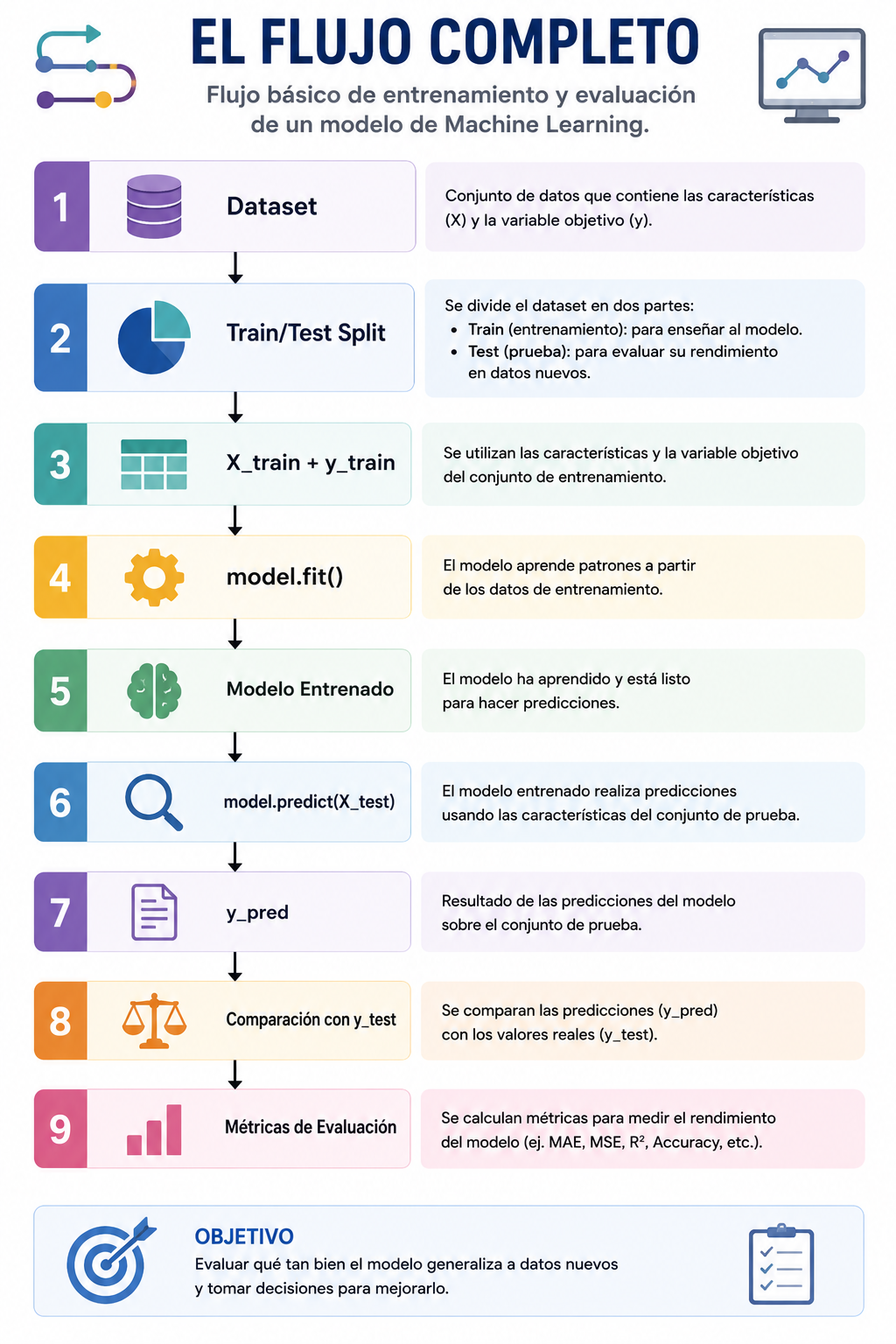
El flujo básico es el siguiente:
- Datos originales: Disponemos de un conjunto de datos completo.
- División de los datos: Separamos los datos en dos conjuntos: Train Set y Test Set
- Paso 3: Entrenamiento: El modelo aprende exclusivamente utilizando el conjunto de entrenamiento: Train Set → Modelo
- Paso 4: Evaluación: Una vez entrenado, el modelo realiza predicciones sobre el conjunto de prueba. Modelo → Predicciones → Test Set
El Papel del Conjunto de Entrenamiento
Tras realizar la división de datos obtenemos cuatro elementos principales:
X_train → Variables predictoras para entrenamiento
X_test → Variables predictoras para evaluación
y_train → Variable objetivo para entrenamiento
y_test → Variable objetivo para evaluación
Donde:
- X representa las características o variables independientes.
- y representa la variable objetivo que queremos predecir.
Durante el entrenamiento, el modelo utilizará las variables de X_train junto con los valores reales contenidos en y_train para aprender los patrones existentes en los datos.
El Método Fit()
En Scikit-Learn, el aprendizaje del modelo se realiza mediante el método fit().
model.fit(X_train, y_train)Durante esta fase:
- El algoritmo analiza los datos.
- Aprende la relación entre las variables predictoras y la variable objetivo.
- Calcula los parámetros internos necesarios para realizar futuras predicciones.
Por ejemplo, en una regresión lineal el algoritmo aprenderá los coeficientes de la ecuación. En un árbol de decisión aprenderá las reglas de partición. En una red neuronal ajustará miles o millones de pesos internos.
Proporciones Habituales de División
No existe una única división correcta. Las más utilizadas son:
| Entrenamiento | Prueba | Cuándo usar |
|---|---|---|
| 70% | 30% | Cuando se dispone de una cantidad moderada de datos y se desea una evaluación más robusta del modelo. Muy utilizado en proyectos académicos y de aprendizaje. |
| 80% | 20% | Equilibrio ideal entre entrenamiento y evaluación. Es la división más utilizada en proyectos de Machine Learning y funciona especialmente bien con datasets medianos y grandes. |
| 75% | 25% | Alternativa intermedia cuando se quiere disponer de un conjunto de prueba ligeramente mayor sin sacrificar demasiados datos para el entrenamiento. |
| 90% | 10% | Recomendado para datasets pequeños, donde maximizar la cantidad de datos disponibles para el entrenamiento es más importante que disponer de un conjunto de prueba grande. |
Regla general: cuanto más pequeño sea el dataset, mayor suele ser el porcentaje destinado al entrenamiento. Cuanto más grande sea el dataset, más sencillo resulta reservar una proporción mayor para pruebas sin afectar significativamente al aprendizaje del modelo.
¿Qué es la generalización?
La generalización es la capacidad de un modelo para funcionar correctamente sobre datos nuevos. Es probablemente el concepto más importante de todo Machine Learning. Un modelo que memoriza los datos de entrenamiento no es útil. Un modelo útil es aquel que:
- Aprende patrones generales.
- Mantiene un buen rendimiento fuera de la muestra.
El Test Set existe precisamente para medir esta capacidad. No debemos mezclar observaciones futuras con observaciones pasadas. La división correcta suele respetar el orden cronológico. De lo contrario, estaríamos introduciendo información futura durante el entrenamiento.
¿Qué significa que el modelo “aprende”?
Cuando hablamos de aprendizaje en Machine Learning nos referimos al proceso mediante el cual el algoritmo encuentra patrones en los datos históricos. El objetivo es identificar relaciones que puedan utilizarse posteriormente para realizar predicciones sobre nuevos datos. El resultado de este proceso es un modelo entrenado.
Generación de Predicciones
Una vez entrenado el modelo, podemos utilizarlo para realizar predicciones sobre observaciones que nunca ha visto. En Scikit-Learn esto se realiza mediante el método predict().
y_pred = model.predict(X_test)El modelo recibe las variables del conjunto de prueba y genera una predicción para cada observación. Estas predicciones se almacenan en y_pred.
Comparando Predicciones con Valores Reales
La ventaja del conjunto de prueba es que conocemos los valores reales. Por tanto podemos comparar: y_test contra y_pred. Esta comparación permite medir el rendimiento real del modelo. Es precisamente aquí donde entran en juego las métricas de evaluación.
Cálculo del Error del Modelo
Dependiendo del tipo de problema utilizaremos métricas diferentes.
Problemas de Regresión
Cuando la variable objetivo es numérica:
- MAE (Mean Absolute Error)
- MSE (Mean Squared Error)
- RMSE (Root Mean Squared Error)
- R² (Coefficient of Determination)
Problemas de Clasificación
Cuando la variable objetivo es categórica:
- Accuracy
- Precision
- Recall
- F1 Score
- ROC-AUC
Este proceso constituye la base de prácticamente todos los proyectos de Machine Learning modernos.
Flujo de entrenamiento y evaluación de un modelo
Implementación Completa en Python
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# División de datos
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
# Crear modelo
model = LinearRegression()
# Entrenar modelo
model.fit(X_train, y_train)
# Generar predicciones
y_pred = model.predict(X_test)
# Evaluar rendimiento
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse:.2f}")
Data Leakage: El Error Silencioso que Puede Invalidar un Modelo de Machine Learning
Uno de los objetivos fundamentales de cualquier proyecto de Machine Learning es construir modelos capaces de generalizar correctamente sobre datos que nunca han visto. Para conseguirlo utilizamos técnicas como el Train/Test Split, reservando una parte de los datos para evaluar el rendimiento real del modelo.
Sin embargo, existe un problema que puede hacer que nuestras métricas parezcan excelentes mientras que el modelo fracasa cuando llega a producción. Este problema recibe el nombre de Data Leakage o fuga de información y es una de las causas más comunes de resultados excesivamente optimistas en Machine Learning.
Comprender qué es el Data Leakage, cómo se produce y cómo evitarlo es esencial para construir modelos fiables y obtener evaluaciones realistas.
¿Qué es el Data Leakage?
El Data Leakage ocurre cuando información que debería permanecer oculta durante el entrenamiento termina llegando al modelo de forma directa o indirecta. En otras palabras: El modelo recibe pistas sobre los datos de prueba antes de ser evaluado.
Como consecuencia:
- El modelo aprende información que no debería conocer.
- Las métricas de evaluación se inflan artificialmente.
- El rendimiento real en producción suele ser mucho peor de lo esperado.
¿Por qué es un problema?
Supongamos que queremos predecir el precio de una vivienda. Disponemos de un conjunto de datos histórico y realizamos un Train/Test Split. La idea es que:
Train Set → Aprendizaje
Test Set → EvaluaciónEl Test Set debe representar información completamente nueva. Si el modelo tiene acceso, aunque sea parcialmente, a información procedente del conjunto de prueba, la evaluación deja de ser objetiva. Las métricas obtenidas ya no reflejan la capacidad real de generalización.
La Relación Entre Data Leakage y Train/Test Split
El propósito del Train/Test Split es simular una situación real. Entrenamos con datos históricos y posteriormente evaluamos el modelo sobre datos que nunca ha visto. Para que esta simulación sea válida, ambos conjuntos deben permanecer completamente independientes. Cuando esta independencia se rompe aparece el Data Leakage.
Un Ejemplo Sencillo
Imaginemos que queremos predecir la recaudación de películas. Disponemos de variables como:
- Presupuesto.
- Duración.
- Género.
- Popularidad de los actores.
Si entrenamos el modelo utilizando todo el dataset y después evaluamos sobre esos mismos registros, podríamos obtener resultados aparentemente perfectos. Sin embargo, el modelo no está aprendiendo patrones generales, está memorizando ejemplos concretos. Por tanto, las métricas no representan el rendimiento sobre datos nuevos.
El Caso Más Común: Transformaciones Antes del Split
Uno de los errores más frecuentes consiste en aplicar transformaciones sobre todo el dataset antes de dividir los datos. Por ejemplo:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X_scaled,
y,
test_size=0.2
)
Aunque parece correcto, existe un problema. El escalador ha calculado la media y la desviación estándar utilizando tanto el Train Set como el Test Set. Por tanto, durante el entrenamiento ya se ha utilizado información procedente del conjunto de prueba.
La forma correcta: primero se divide el dataset:
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
Después se ajusta la transformación utilizando únicamente el conjunto de entrenamiento.
scaler = StandardScaler()
scaler.fit(X_train)Y finalmente se aplica a ambos conjuntos.
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)De esta forma, el modelo nunca tiene acceso a información procedente del Test Set.
Otros Casos Frecuentes de Data Leakage
Imputación de Valores Nulos
# Incorrecto:
imputer.fit(X)
# Correcto
imputer.fit(X_train)Normalización
Incorrecto:
# Incorrecto:
scaler.fit(X)
# Correcto
scaler.fit(X_train)One-Hot Encoding
# Incorrecto:
encoder.fit(X)
# Correcto
encoder.fit(X_train)Selección de Variables
# Incorrecto:
selector.fit(X, y)
# Correcto
selector.fit(X_train, y_train)PCA
# Incorrecto:
pca.fit(X)
# Correcto
pca.fit(X_train)Una Regla Fácil de Recordar
Existe una regla muy útil: Todo objeto que utilice el método .fit() debe aprender únicamente del conjunto de entrenamiento. Esto incluye:
- Scalers.
- Encoders.
- Imputadores.
- PCA.
- Selectores de variables.
- Modelos de Machine Learning.
Si un componente necesita ejecutar un .fit(), debe hacerlo exclusivamente utilizando el Train Set.
Cómo Detectar un Posible Data Leakage
Algunas señales de alerta son:
- Accuracy extremadamente alta.
- R² inusualmente elevado.
- Error casi nulo.
- Diferencias muy grandes entre entorno de pruebas y producción.
Cuando las métricas parecen demasiado buenas para ser ciertas, conviene revisar cuidadosamente posibles fugas de información.
Data Leakage en Series Temporales
En problemas temporales el riesgo es todavía mayor. Por ejemplo:
- Predicción bursátil.
- Forecasting de ventas.
- Predicción meteorológica.
Un error habitual consiste en utilizar información futura durante el entrenamiento. Si mezclamos registros futuros con registros pasados, el modelo aprende patrones imposibles de conocer en una situación real. Por esta razón las series temporales requieren estrategias de validación específicas que respeten el orden cronológico.
Buenas Prácticas para Evitar Data Leakage
- Dividir antes de transformar: Siempre: Split → Fit → Transform
- Mantener independencia entre conjuntos: El Test Set debe permanecer aislado hasta la fase final de evaluación.
- Utilizar Pipelines: Los pipelines de Scikit-Learn ayudan a evitar errores de procesamiento. Permiten garantizar que cada transformación aprende únicamente a partir del conjunto de entrenamiento.
- Desconfiar de resultados excesivamente buenos: Cuando las métricas parecen perfectas, conviene revisar cuidadosamente el flujo de datos.
Errores Comunes
- Evaluar con datos de entrenamiento: produce resultados engañosamente buenos.
- Realizar transformaciones antes de dividir: por ejemplo, escalado, normalización, imputación. Estas transformaciones deben aprenderse utilizando únicamente el Train Set. Está directamente relacionado con el problema de Data Leakage (fuga de información).
- Utilizar el Test Set repetidamente: Cada vez que modificamos el modelo basándonos en el Test Set estamos filtrando información. Con el tiempo, el conjunto de prueba deja de ser independiente.
- Ignorar el desbalanceo de clases: En clasificación puede ser necesario utilizar particiones estratificadas para mantener la proporción de clases.
Relación con la Validación Cruzada
El Train/Test Split suele ser el primer paso. Posteriormente pueden utilizarse técnicas más avanzadas como:
- K-Fold Cross Validation.
- Stratified K-Fold.
- Time Series Split.
Estas técnicas proporcionan estimaciones más robustas del rendimiento del modelo. Sin embargo, incluso cuando utilizamos validación cruzada, suele mantenerse un conjunto de prueba final completamente independiente.
Conclusión
El Train/Test Split es una de las etapas más importantes de cualquier proyecto de Machine Learning. Su objetivo es garantizar que la evaluación del modelo se realiza sobre datos que no han participado en el entrenamiento, permitiendo medir de forma realista su capacidad de generalización. Esta práctica constituye la base sobre la que se apoyan todas las metodologías modernas de evaluación de modelos y resulta imprescindible tanto en problemas de regresión como de clasificación, Deep Learning o sistemas de recomendación. Comprender cómo dividir correctamente los datos y evitar fugas de información es uno de los primeros pasos para construir modelos fiables y útiles en entornos reales.