En el diseño de arquitecturas de Machine Learning, la calidad de las predicciones de un modelo no depende únicamente de la complejidad del algoritmo matemático seleccionado, sino de la forma geométrica de los datos que le suministramos.
Muchos algoritmos fundamentales (como la Regresión Lineal, la Regresión Logística o las Redes Neuronales) asumen de manera implícita que las variables numéricas de entrada siguen una Distribución Normal (o Gaussiana). Sin embargo, en el mundo real, los datos de negocio suelen ser imperfectos y presentan sesgo o asimetría (skewness), acumulando la mayoría de sus registros en un extremo y extendiendo una larga cola en el sentido opuesto.
En este artículo analítico, abordaremos en exclusiva las técnicas de ingeniería de características cuyo objetivo principal es reducir la asimetría de una distribución para aproximarla a una campana de Gauss.
¿Qué son los datos sesgados?
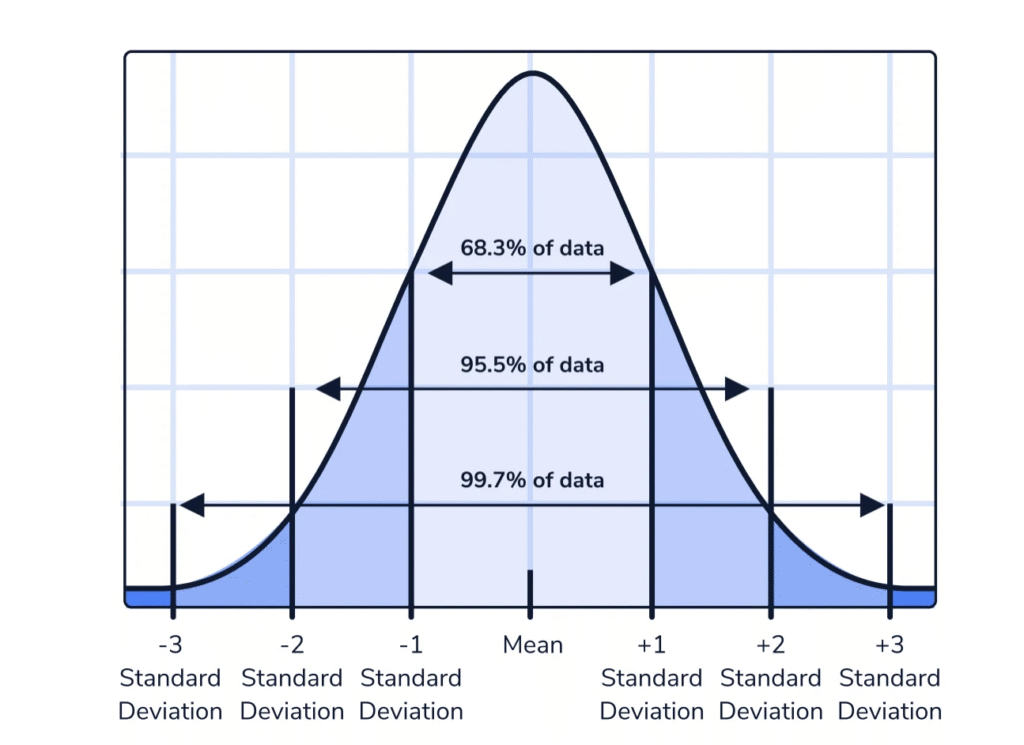
Cuando un dataset presenta asimetría, la media, la mediana y la moda se separan, provocando que los modelos estadísticos tengan dificultades para aprender los patrones de forma equitativa. El escenario más común en analítica de negocio es la asimetría positiva (o sesgo a la derecha), donde la distribución presenta una cola alargada hacia los valores extremadamente altos. En una distribución normal, la media, la mediana y la moda coinciden, y la curva tiene forma de campana. Matemáticamente, se puede representar como:
$$f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x – \mu)^2}{2\sigma^2}}$$
donde:
- \( \mu \) es la media
- \( \sigma \) la desviación estándar.
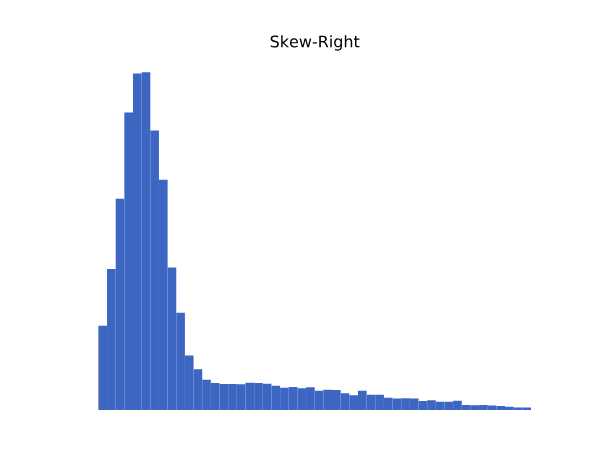
Sin embargo, muchos conjuntos de datos reales, como ingresos, precios o número de visitas, presentan sesgo (skewness): una asimetría en la distribución.
- Si la cola se extiende hacia la derecha, decimos que está sesgada positivamente.
- Si se extiende hacia la izquierda, está sesgada negativamente.
Por ejemplo, los ingresos de una población suelen estar sesgados a la derecha, porque hay muchas personas con ingresos bajos y pocas con ingresos muy altos.
Reducir el sesgo mejora:
- La precisión del modelo.
- La interpretabilidad de los resultados.
- La estabilidad numérica en el entrenamiento.
Principales técnicas de transformación de datos
A continuación, analizaremos las funciones matemáticas aplicadas en Data Science para comprimir las colas de las distribuciones y redistribuir los datos de forma simétrica.
Transformación Logarítmica
Es la técnica más extendida y utilizada en la industria. Consiste en aplicar el logaritmo natural a la variable predictora.
$$y = \log(x)$$
- Indicada para: Casos de asimetría positiva fuerte y distribuciones con colas extremadamente largas hacia la derecha.
- Casos de uso típicos: Variables socioeconómicas o de comportamiento digital como ingresos, ventas acumuladas o tráfico web, donde unos pocos usuarios o registros presentan valores astronómicos en comparación con la media.
- Limitación: Matemáticamente no está definida para valores menores o iguales a cero. Si existen ceros, suele aplicarse \(\log(x + 1)\) como variante técnica.
Transformación de Raíz Cuadrada
{kind=link}
Una alternativa de compresión geométrica moderada.
$$y = \sqrt{x}$$
- Indicada para: Escenarios donde la asimetría positiva es moderada. Al ser menos agresiva que la función logarítmica, no deforma de manera tan drástica las distancias relativas.
- Ventaja: Acepta directamente el valor cero en el dominio de la variable, haciéndola ideal para conteos.
Transformación de Raíz Cúbica
Una herramienta matemática versátil para la manipulación de espectros numéricos amplios.
$$y = \sqrt[3]{x}$$
- Indicada para: Distribuciones que contienen valores positivos, negativos y ceros simultáneamente, siempre que la asimetría no sea extrema. Al conservar el signo del input original, se permite estabilizar la varianza sin perder la naturaleza bidireccional del dato.
Transformación Recíproca
Una de las funciones de transmutación más agresivas en el arsenal estadístico.
$$y = \frac{1}{x}$$
- Indicada para: Distribuciones con una asimetría extremadamente severa y presencia de outliers de gran magnitud. Esta operación invierte el orden de magnitud, transformando los valores extremadamente grandes en valores cercanos a cero, logrando una compresión radical de la cola derecha.
Transformaciones Avanzadas y Automatizadas
En lugar de probar manualmente qué función matemática se adapta mejor a cada columna del dataset, la ciencia de datos moderna utiliza optimizadores algorítmicos que buscan el parámetro de transformación idóneo de manera automatizada.
Transformación Box-Cox
{kind=link}
Es un método estadístico avanzado que parametriza la transformación mediante un valor de potencia llamado Lambda (\(\lambda\)). El algoritmo busca el \(\lambda\) óptimo que minimiza la asimetría de la variable resultante.
$$y = \begin{cases} \frac{x^\lambda – 1}{\lambda} & \text{si } \lambda \neq 0 \\ \log(x) & \text{si } \lambda = 0 \end{cases}$$
- Gran Limitación: Funciona única y exclusivamente con valores estrictamente positivos. Si la columna contiene un solo cero o un número negativo, el sistema fallará.
Transformación Yeo-Johnson
Considerada la evolución moderna del método Box-Cox. Modifica las ecuaciones para estabilizar las varianzas permitiendo que la potencia \(\lambda\) se calcule de forma segura sobre cualquier naturaleza numérica.
- Ventajas de Producción: Es compatible con valores negativos y ceros. Debido a esta flexibilidad analítica, es una de las técnicas automatizadas más integradas en los pipelines de Machine Learning industriales (como los transformadores nativos de Scikit-Learn).
Comparación de Transformaciones para Datos Sesgados
| Transformación | Intensidad | Admite Ceros | Admite Negativos |
|---|---|---|---|
| Logarítmica | Alta | No | No |
| Raíz Cuadrada | Media | Sí | No |
| Raíz Cúbica | Baja | Sí | Sí |
| Box-Cox | Alta | No | No |
| Yeo-Johnson | Alta | Sí | Sí |
Buenas prácticas
- Visualiza siempre tus datos antes y después de transformar.
- Mide la asimetría \( (\text{skewness})\) antes y después.
- No transformes por costumbre: hazlo solo si hay una razón estadística o del modelo.
- Guarda los parámetros de transformación si vas a aplicarlos en datos futuros (por ejemplo, en deploy de modelos).
- Considera también el escalado posterior (normalización o estandarización).