Reference
[h5p id=»4″]
Quiz
[h5p id=»5″]
FashCard
[h5p id=»6″]
[h5p id=»4″]
[h5p id=»5″]
[h5p id=»6″]
[h5p id=»2″]
[h5p id=»3″]
Microsoft Power BI Data Analyst (PL-300) – Proyecto Final «Tonificado».
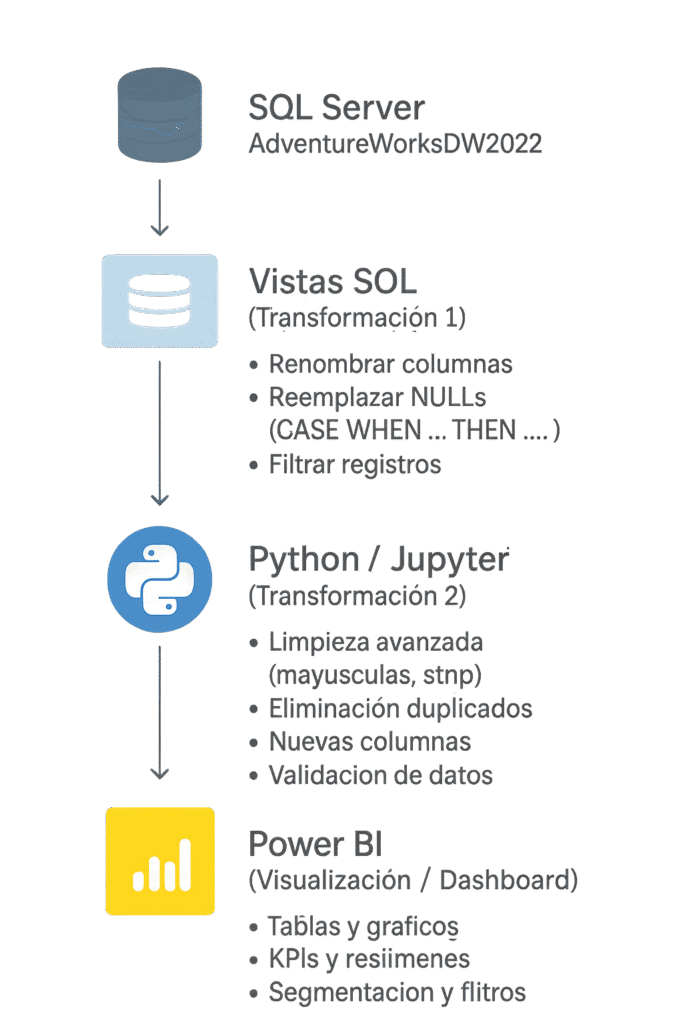
Proyecto de Dashboard 360° para AdventureWorks 2022. Se extrajeron y exploraron los datos con SQL, se limpiaron y transformaron usando Python y Pandas, y finalmente se visualizaron en Power BI. El proyecto abarca todo el proceso ETL: consultas y modelado de datos en SQL, manipulación y preparación de datos en Python, y construcción de visualizaciones interactivas en Power BI para análisis integral de finanzas, ventas, clientes y productos.
El proyecto de curso original solo incluía elaborar un dashboard con datos provenientes de tablas de Excel aportadas por el curso.
Tecnologías utilizadas
Lo primero y más importante: nunca empieces a extraer datos sin entenderlos al 100 %.
Acciones realizadas:
Como resultado se creó un Diccionario de Datos completo en Excel y un diagrama relacional.
Definición de un modelo dimensional robusto, siguiendo las mejores prácticas de arquitectura BI. Para garantizar un rendimiento óptimo en Power BI y un análisis consistente, se diseñó un modelo en estrella (Star Schema), manteniendo únicamente algunas jerarquías naturales con forma de snowflake cuando aportaban claridad sin afectar el rendimiento.
Establecer la granularidad exacta de cada tabla de hechos:
Se seleccionaron los indicadores esenciales para la visión 360°:
Durante esta fase se produjeron los documentos técnicos clave del proyecto:
Se crearon vistas en SQL Server, segun el documento de Requerimientos, que estructuran y preparan los datos para su posterior procesamiento en Python y análisis en Power BI.
Las vistas incluyen:
Además, se aplicaron transformaciones básicas dentro de las vistas, como el cálculo de edad a partir de la fecha de nacimiento y la unificación de jerarquías de productos, simplificando la carga y limpieza de datos en Python.
Resultado: Una capa de datos limpia, consistente y segura, lista para análisis avanzado en Python y visualización interactiva en Power BI, cumpliendo los objetivos del dashboard ejecutivo.
En esta fase se consolidan los datos de SQL Server y se preparan para su análisis en Power BI, asegurando datasets limpios, consistentes y listos para modelado.
Se crearon cuadernos de Jupyter para extraer vistas SQL a CSV:
/data/raw, eliminando prefijos vw_ en los nombres.Los CSV se cargaron en DataFrames de Pandas para exploración:
CheckData) para revisión rápida de los datasets.Se aplicaron transformaciones consistentes por tabla de hechos:
Se desarrollaron scripts para consolidar el flujo:
config.py: define rutas de trabajo y conexión a SQL Server con SQLAlchemy.etl_pipeline.py: ejecuta automáticamente:
/data/processed.Este enfoque permite reproducir todo el proceso con un solo comando, manteniendo la trazabilidad y calidad de los datos para análisis en Power BI.
Tras la limpieza y transformación, los datasets se preparan para su consumo en Power BI:
dimCliente.parquet, factVentas.parquet, etc.datasets_control.xlsx) que documenta: nombre del archivo, número de filas y columnas, fecha de exportación./data/final/, listos para el análisis.Este procedimiento asegura que los datos sean consistentes, auditables y fácilmente reutilizables por cualquier miembro del equipo BI.
La fase final consiste en construir el modelo semántico para análisis y reporting:
El resultado es un archivo Proyecto_Ventas.pbix completamente funcional y un documento de Modelo de Datos (Modelo de Datos en Power BI.pdf) con capturas de relaciones, medidas y estructura general, que permite navegar, analizar y tomar decisiones basadas en datos de manera rápida y confiable.
Este es el proyecto final del Curso IBM Data Science de Coursera finalizado en septiembre de 2025. En este proyecto completo de Data Science se predice la recuperación exitosa de la primera etapa del Falcon 9 de SpaceX.
El flujo incluyó recolección de datos mediante la API oficial y web scraping, limpieza y enriquecimiento con pandas, análisis exploratorio y geoespacial con seaborn y Folium, consultas SQL, feature engineering (One-Hot Encoding + escalado), entrenamiento de cuatro modelos de clasificación (Regresión Logística, SVM, Árbol de Decisión y KNN) con GridSearchCV, y despliegue de un dashboard web interactivo con Plotly Dash. Todo implementado en Python utilizando pandas, scikit–learn, matplotlib/seaborn, Folium, SQLite y Dash.
Enlace al sitio del proyecto:
https://github.com/fer78/Space-Launch-Optimization-with-Machine-Learning.git
La era espacial comercial ya ha llegado. Las empresas están haciendo que los viajes espaciales sean asequibles para todos:
Una razón por la cual SpaceX puede hacer estas operaciones es porque ha logrado que sus lanzamientos sean más económicos. Recientemente, anunció en su sitio web el lanzamiento del nuevo cohete Falcon 9 con un coste de 62 millones de dólares, mientras que otras empresas pueden hacerlo con costes de más de 150 millones.
Gran parte de este ahorro es debido a que SpaceX puede reutilizar la primera etapa del lanzamiento. Con este dato, si podemos determinar si la primera etapa aterrizará, podemos determinar el coste de un lanzamiento.
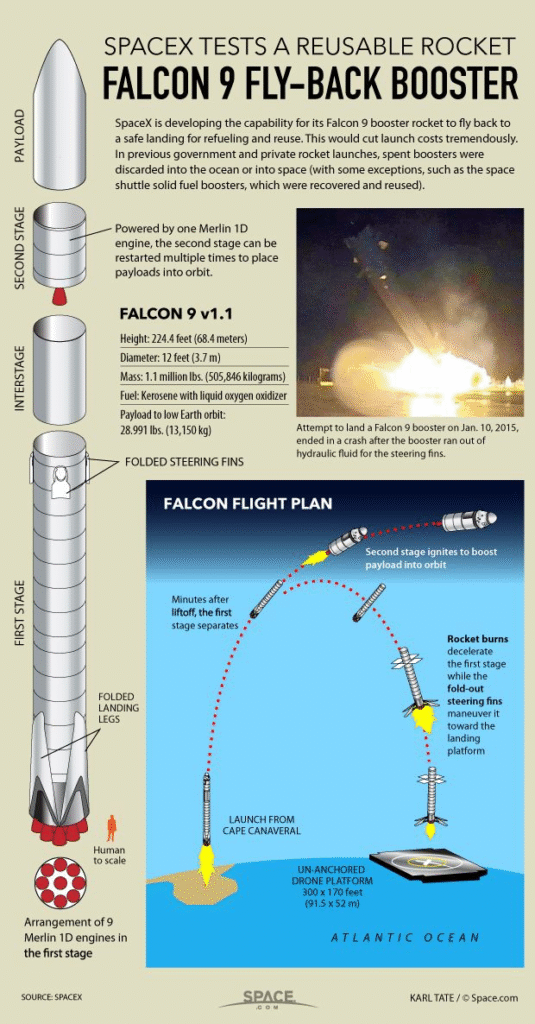
En la infografía se pueden apreciar las diferentes partes del cohete:
A diferencia de otros proveedores de cohetes, el Falcon 9 puede recuperar la primera etapa. En ocasiones no tiene éxito durante el aterrizaje y se destruye. En otras ocasiones, la propia empresa destruye la primera etapa debido a los parámetros de la misión como la carga útil. La orbita y el cliente.
En este proyecto asumirás el papel de un científico de datos que trabaja para una nueva empresa de cohetes: SpaceY que quiere competir con SpaceX.

SpaceY fue fundada por el empresario industrial Allon Mask.
Tu trabajo es determinar el precio de cada lanzamiento, recopilando información sobre la competencia y determinando si se reutilizará la primera etapa.
En lugar de usar la ciencia de cohetes para determinar si la primera etapa aterrizará con éxito. Entrenarás un modelo de aprendizaje automático y usarás información pública para predecir si SpaceY reutilizará la primera etapa.
En la primera fase de este proyecto, se construyó un dataset completo y estructurado a partir de datos públicos en tiempo real de todos los lanzamientos históricos de SpaceX, utilizando exclusivamente su API REST oficial (v4).
Se realizó una petición GET al endpoint https://api.spacexdata.com/v4/launches/past para obtener el histórico completo de lanzamientos.
Dado que la respuesta contiene únicamente identificadores (rocket_id, payload_id, launchpad_id, core_id), se implementó un proceso de data enrichment mediante llamadas secundarias a los endpoints específicos:
/v4/rockets/{id} → nombre del booster (Falcon 9, Falcon 1, etc.)/v4/launchpads/{id} → nombre del sitio de lanzamiento, longitud y latitud/v4/payloads/{id} → masa de la carga útil (kg) y órbita destino (LEO, GTO, ISS, etc.)/v4/cores/{id} → información crítica del core: éxito del aterrizaje, tipo de aterrizaje (RTLS, ASDS, océano), uso de grid fins y landing legs, bloque del booster, número de reusos, serial del core, etc.Se creó un diccionario estructurado con las siguientes variables enriquecidas:
Este diccionario se convirtió en un DataFrame final (launch_df).
El resultado es un dataset limpio, estructurado y enriquecido (dataset_part_1.csv) con 90 lanzamientos de Falcon 9 hasta noviembre de 2020, listo para las siguientes fases de análisis exploratorio, feature engineering y modelado predictivo del éxito del aterrizaje de la primera etapa.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 90 entries, 0 to 89
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FlightNumber 90 non-null int64
1 Date 90 non-null object
2 BoosterVersion 90 non-null object
3 PayloadMass 90 non-null float64
4 Orbit 90 non-null object
5 LaunchSite 90 non-null object
6 Outcome 90 non-null object
7 Flights 90 non-null int64
8 GridFins 90 non-null bool
9 Reused 90 non-null bool
10 Legs 90 non-null bool
11 LandingPad 64 non-null object
12 Block 90 non-null float64
13 ReusedCount 90 non-null int64
14 Serial 90 non-null object
15 Longitude 90 non-null float64
16 Latitude 90 non-null float64
dtypes: bool(3), float64(4), int64(3), object(7)
memory usage: 10.2+ KB
En esta segunda fase del proyecto se construyó un dataset alternativo y complementario mediante web scraping de la página de Wikipedia “List of Falcon 9 and Falcon Heavy launches”, con el objetivo de obtener una fuente independiente a la API oficial de SpaceX y permitir validación cruzada de los datos.
requests con cabecera User-Agent personalizada para evitar bloqueos.BeautifulSoup4 como parser HTML.Se obtuvo un DataFrame completo con 121 lanzamientos de Falcon 9 y Falcon Heavy hasta junio de 2021, incluyendo información crítica para el modelo predictivo:Booster landing (variable objetivo), Payload mass, Orbit, Launch site, Version Booster, etc.
El archivo final se exportó como spacex_web_scraped.csv, listo para su uso en análisis exploratorio, fusión con el dataset de la API y entrenamiento de modelos de clasificación.
En esta fase del proyecto se realizó un análisis exploratorio inicial (EDA) y el data wrangling necesario para convertir el dataset crudo (obtenido vía API en la Parte 1) en un conjunto de datos listo para modelado supervisado de clasificación.
LaunchSite):Orbit), destacando la predominancia de LEO, ISS, GTO y SSO, y la presencia de órbitas menos frecuentes (HEO, MEO, ES-L1, etc.).Outcome (resultado del aterrizaje de la primera etapa)Class)
bad_outcomes = {'False ASDS', 'False RTLS', 'False Ocean', 'None ASDS', 'None None'}Class mediante list comprehension: python landing_class = [0 if outcome in bad_outcomes else 1 for outcome in df['Outcome']] df['Class'] = landing_classClass = 1 → primera etapa recuperada con éxitoClass = 0 → no recuperada (fallo o misión expendable)Se exportó el dataset enriquecido como dataset_part_2.csv, que incluye:
Class lista para ser usada como target en modelos de clasificación supervisadaLandingPad mantiene None intencionadamente)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 90 entries, 0 to 89
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FlightNumber 90 non-null int64
1 Date 90 non-null object
2 BoosterVersion 90 non-null object
3 PayloadMass 90 non-null float64
4 Orbit 90 non-null object
5 LaunchSite 90 non-null object
6 Outcome 90 non-null object
7 Flights 90 non-null int64
8 GridFins 90 non-null bool
9 Reused 90 non-null bool
10 Legs 90 non-null bool
11 LandingPad 64 non-null object
12 Block 90 non-null float64
13 ReusedCount 90 non-null int64
14 Serial 90 non-null object
15 Longitude 90 non-null float64
16 Latitude 90 non-null float64
17 Class 90 non-null int64
dtypes: bool(3), float64(4), int64(4), object(7)
memory usage: 10.9+ KB
En esta fase clave del proyecto se realizó un análisis exploratorio exhaustivo (EDA) y la ingeniería de variables (feature engineering) definitiva para preparar los datos de cara al modelado predictivo supervisado.
Se crean funciones auxiliares propias para aplicar un estilo visual elegante, consistente y profesional (ejes limpios, rejilla vertical rosa, leyenda personalizada rojo/verde para fallos y éxitos)
FlightNumber vs PayloadMass
Scatter plot que muestra claramente la curva de aprendizaje de SpaceX: los primeros lanzamientos presentan más fallos, mientras que a partir del vuelo ~20–25 la tasa de éxito se vuelve muy alta, incluso con cargas útiles pesadas.
FlightNumber vs LaunchSite
PayloadMass vs LaunchSite
Observación clave: desde VAFB SLC-4E nunca se han lanzado cargas pesadas (>10 000 kg), lo que explica su tasa de éxito casi perfecta.
Success Rate by Orbit Type
Bar chart revelador:
FlightNumber vs Orbit & PayloadMass vs Orbit
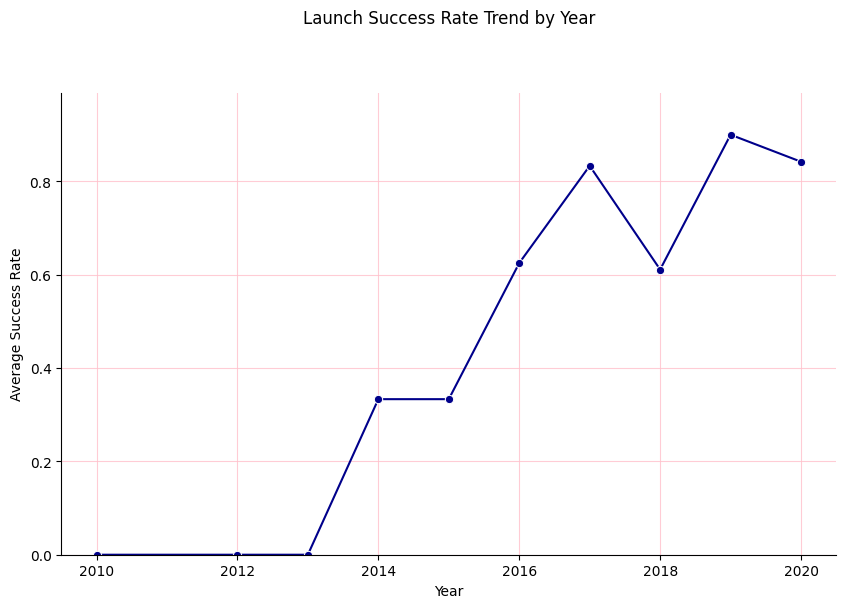
Evolución anual de la tasa de éxito (2013–2020)
Line chart que muestra una mejora sostenida y casi lineal desde ~50 % en 2013 hasta >95 % en 2020, reflejando la madurez tecnológica de la reutilización.
Orbit (11 categorías)LaunchSite (3)LandingPad (5)Serial (53 identificadores únicos de boosters)float64 para compatibilidad con algoritmos de Machine Learning.Se generó el dataset definitivo dataset_part_3.csv con 104 columnas numéricas y 90 observaciones, completamente limpio, codificado y listo para entrenamiento de modelos de clasificación.
Aunque el núcleo del proyecto se basa en Machine Learning con Python, esta fase complementaria demuestra una competencia adicional muy valorada en ciencia de datos: el dominio de consultas SQL para análisis exploratorio y extracción de insights directamente desde bases de datos relacionales.
Utilizar SQLite como motor de base de datos en entorno local para cargar el dataset completo de misiones SpaceX y resolver 10 consultas analíticas reales mediante lenguaje SQL puro.
my_data1.dbpandas.to_sql()%sql para ejecutar consultas directamente desde Jupyter| Task | Consulta realizada | Insight principal |
|---|---|---|
| 1 | DISTINCT Launch_Site | 4 sitios únicos: CCAFS SLC-40, KSC LC-39A, VAFB SLC-4E, CCAFS LC-40 |
| 2 | Lanzamientos desde sitios que empiezan por ‘CCA’ | 69 misiones (mayoría histórica) |
| 3 | Masa total de carga útil NASA (CRS) | 45 716 kg transportados en contratos CRS |
| 4 | Masa media de carga en versión F9 v1.1 | 2 534 kg (versión temprana con menor capacidad) |
| 5 | Primera fecha de aterrizaje exitoso en plataforma terrestre | 2015-12-22 (Flight 20 – hito histórico RTLS) |
| 6 | Boosters con éxito en dron ship y carga entre 4000–6000 kg | 9 casos (todos F9 FT Bxxxx) |
| 7 | Conteo total de éxitos y fallos de misión | 98 éxitos – 1 fallo (CRS-7 explosión) |
| 8 | Booster_Version con máxima carga útil | 13 600 kg → F9 B5 B1048.2 y B1049.2 (misiones Starlink) |
| 9 | Fallos en dron ship durante 2015 | Enero (CRS-7) y Marzo (SES-9) – dos intentos fallidos emblemáticos |
| 10 | Ranking de outcomes de aterrizaje (2010-06-04 → 2017-03-20) | Success (drone ship): 14, Success (ground pad): 9, Failure: 7, etc. |
En esta fase del proyecto se implementó un análisis geoespacial interactivo utilizando la librería Folium, con el objetivo de explorar visualmente la ubicación estratégica de los sitios de lanzamiento de SpaceX y su relación con el éxito del aterrizaje de la primera etapa.
folium + plugins: MarkerCluster, MousePosition, DivIconMarcado de los 4 sitios de lanzamiento activos de Falcon 9

Cálculo y representación de distancias a infraestructuras críticas
Visualización interactiva de éxitos y fallos por lanzamiento
MarkerCluster que agrupa automáticamente los marcadores según el nivel de zoom.Class = 1 (aterrizaje exitoso)Class = 0 (fallo o misión expendable)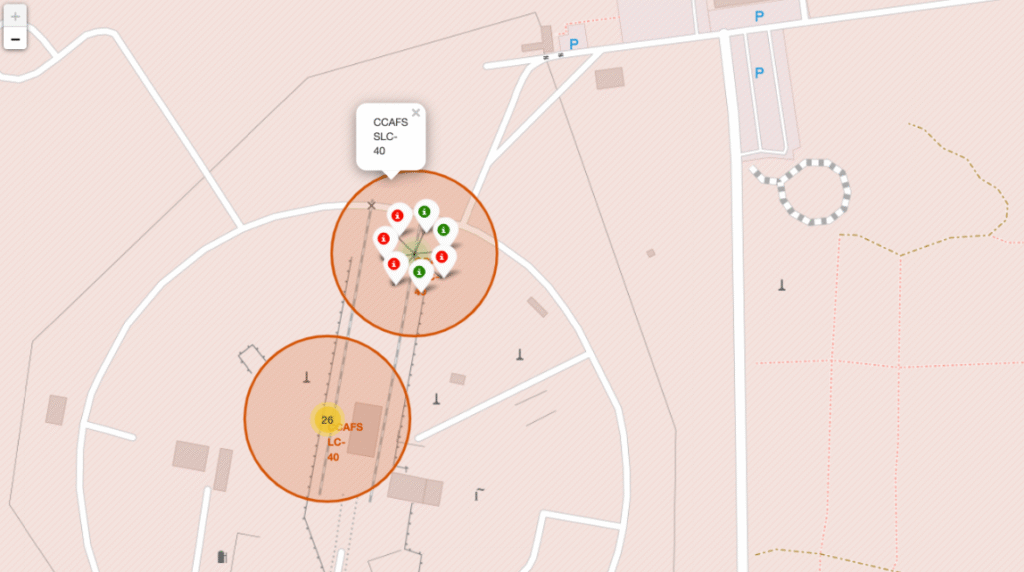
En la fase final del proyecto se desarrolló un dashboard web interactivo utilizando Plotly Dash, permitiendo a cualquier usuario (técnico o no técnico) explorar de forma dinámica los datos históricos de lanzamientos de SpaceX y los factores que influyen en el éxito del aterrizaje de la primera etapa.
http://0.0.0.0:8050@app.callback para el gráfico de tarta → responde al site-dropdown@app.callback doble entrada (site-dropdown + payload-slider) → actualiza el scatter en tiempo realEn la fase culminante del proyecto se entrenaron y evaluaron cuatro algoritmos de clasificación supervisada para predecir si la primera etapa del Falcon 9 aterrizará con éxito (Class = 1) o no (Class = 0), utilizando el dataset completamente preprocesado (104 variables one-hot + numéricas estandarizadas).
StandardScalerrandom_state=2)GridSearchCV con 10-fold cross-validation| Modelo | Mejores hiperparámetros (GridSearchCV) | Accuracy Validación (CV) | Accuracy Test | Observaciones |
|---|---|---|---|---|
| Logistic Regression | C=0.01, penalty='l2', solver='lbfgs' | 84.64 % | 83.33 % | Muy estable, pocos falsos positivos |
| SVM | C=1.0, gamma=0.0316, kernel='sigmoid' | 84.82 % | 83.33 % | Rendimiento prácticamente idéntico a Regresión Logística |
| Decision Tree | criterion='gini', max_depth=6, max_features='sqrt', min_samples_leaf=4, splitter='random' | 88.93 % | 83.33 % | Mejor en validación (posible leve sobreajuste) |
| K-Nearest Neighbors | n_neighbors=10, algorithm='auto', p=1 (distancia Manhattan) | 84.82 % | 83.33 % | Robusto y consistente |
Resultado clave: Los cuatro modelos alcanzan 83.33 % de accuracy en el conjunto de prueba (15 aciertos de 18 muestras), lo que representa un rendimiento excelente considerando el reducido tamaño del dataset (90 observaciones totales).
Se ha construido con éxito un sistema predictivo robusto capaz de estimar, con más del 83 % de precisión, si la primera etapa del Falcon 9 será recuperada en una misión futura, basándose únicamente en parámetros públicos conocidos antes del lanzamiento (sitio, órbita, masa de carga, versión del booster, etc.).

Este modelo tiene aplicaciones reales:
Las variables aleatorias son uno de los pilares fundamentales de la probabilidad y la estadística, y entenderlas es clave para trabajar con datos, modelos matemáticos, inferencia estadística o machine learning. En este artículo veremos de forma clara qué son, cómo se clasifican, cómo funcionan sus funciones asociadas (PMF y CDF), y cómo se calculan y visualizan con Python.
Una variable aleatoria es una función que asigna valores numéricos a los resultados de un experimento aleatorio.
Las variables aleatorias discretas son aquellas que toman un número finito o contablemente infinito de valores distintos. Cada uno de estos valores tiene una probabilidad asociada, y la suma de todas estas probabilidades debe ser igual a uno. Pueden adoptar valores que se pueden contar, como 0, 1, 2, …, n, o una lista de valores específicos como {-3, -1, 0, 1, 5}.
Ejemplos comunes:
Una variable aleatoria de Bernoulli es un tipo específico de variable aleatoria discreta que sólo toma dos posibles valores, típicamente 0 y 1, para representar los resultados de un único ensayo de Bernoulli.
Una variable de Bernoulli X se define de la siguiente manera:
Vamos a construir una función en Python que simule un experimento de Bernoulli, el cual podría representar, por ejemplo, el lanzamiento de una moneda:
import numpy as np
def bernoulli_trial(p=0.5):
"""Simula un experimento de Bernoulli.
Args:
p (float): Probabilidad de éxito (por defecto 0.5).
Returns:
int: 1 si el experimento resulta en éxito, 0 en caso contrario.
"""
return 1 if np.random.rand() <= p else 0
En esta función, np.random.rand() genera un número aleatorio entre 0 y 1, y compara este número con la probabilidad de éxito p. Si el número generado es menor o igual a p, el resultado es un éxito (1); de lo contrario, es un fracaso (0).
Podemos usar esta función para realizar múltiples ensayos y observar la frecuencia de éxitos, lo que nos permite estimar la probabilidad de éxito de la moneda:
def simulate_bernoulli_trials(n, p=0.5):
"""Simula n ensayos de Bernoulli y reporta la frecuencia de éxitos.
Args:
n (int): Número de ensayos.
p (float): Probabilidad de éxito.
Returns:
float: Frecuencia de éxitos.
"""
results = [bernoulli_trial(p) for _ in range(n)]
return sum(results) / n
# Simular 1000 lanzamientos de una moneda con p = 0.7
n_trials = 1000
success_prob = 0.612199
frequency_of_success = simulate_bernoulli_trials(n_trials, success_prob)
print(f"La frecuencia de éxito estimada es {frequency_of_success:.2f}")
Output:
La frecuencia de éxito estimada es 0.71
Este código simula 1000 lanzamientos de una moneda donde la probabilidad de obtener cara (éxito) es del 70%. La función simulate_bernoulli_trials devuelve la frecuencia de éxitos, que debería acercarse a 0.7 a medida que el número de ensayos aumenta.
Para visualizar cómo la frecuencia de éxitos converge a la probabilidad real, podríamos realizar múltiples simulaciones aumentando progresivamente el número de ensayos y graficar los resultados:
import matplotlib.pyplot as plt
trial_counts = [10, 50, 100, 500, 1000, 5000, 10000]
frequencies = [simulate_bernoulli_trials(count, success_prob) for count in trial_counts]
plt.figure(figsize=(10, 5))
plt.plot(trial_counts, frequencies, marker='o', linestyle='-')
plt.axhline(y=success_prob, color='r', linestyle='--')
plt.title('Convergencia de la Frecuencia de Éxitos a la Probabilidad Real')
plt.xlabel('Número de Ensayos')
plt.ylabel('Frecuencia de Éxitos')
plt.xscale('log')
plt.show()
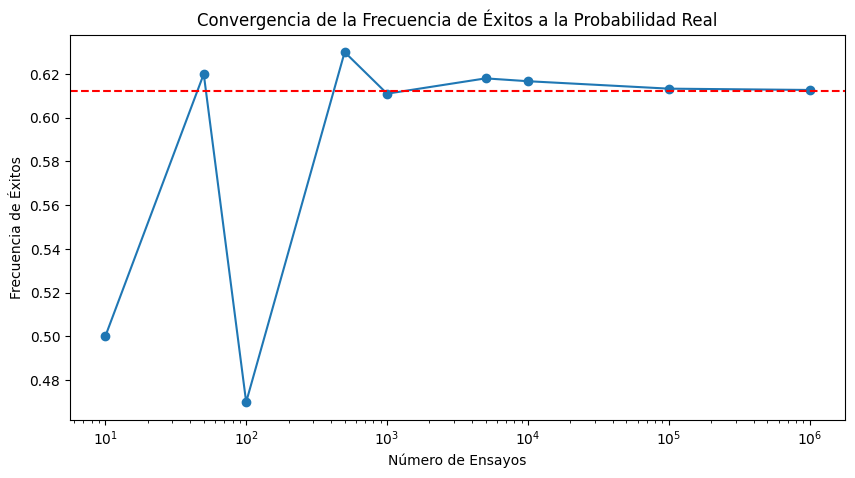
Este gráfico mostrará cómo la frecuencia de éxitos se estabiliza y converge hacia la probabilidad real de éxito (0.612199 en este caso) a medida que aumenta el número de ensayos, ilustrando la ley de los grandes números.
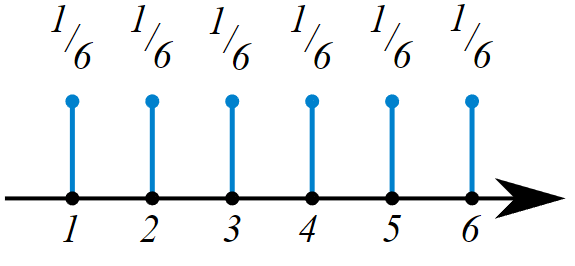
La Función de Masa de Probabilidad (PMF) es una función que describe la probabilidad de que una variable aleatoria discreta tome un valor específico. Es una función que devuelve la probabilidad de que una variable aleatoria discreta sea exactamente igual a algún valor. Es una función que asocia a cada punto de su espacio muestral X la probabilidad de que esta lo asuma. La función de probabilidad suele ser el medio principal para definir una distribución de probabilidad discreta, y tales funciones existen para variables aleatorias escalares o multivariantes, cuyo dominio es discreto.
La función de masa de probabilidad de un dado. Todos los números tienen la misma probabilidad de aparecer cuando este es tirado.
Por ejemplo, supongamos que lanzamos una moneda justa varias veces y contamos el número de caras. La función de masa de probabilidad que describe la probabilidad de cada resultado posible (p. ej., 0 caras, 1 cara, 2 caras, etc.) se denomina distribución binomial. Los parámetros para la distribución binomial son:
n para el número de intentos (por ejemplo, n=10 si lanzamos una moneda 10 veces)p para la probabilidad de éxito en cada prueba (probabilidad de observar un resultado particular en cada prueba. En este ejemplo, p= 0,5 porque la probabilidad de observar caras en un lanzamiento de moneda justo es 0,5)Si lanzamos una moneda normal 10 veces, decimos que el número de caras observadas sigue una distribución Binomial(n=10, p=0.5). El siguiente gráfico muestra la función de masa de probabilidad para este experimento. Las alturas de las barras representan la probabilidad de observar cada resultado posible calculado por el PMF.
Veamos cómo cambia la forma de la distribución binomial a medida que cambia el tamaño de la muestra.
Utilice el control deslizante para cambiar el valor de x lanzamientos de moneda justos, entre uno y diez. Las alturas de las barras resultantes representan la probabilidad de observar diferentes valores de caras en x número de lanzamientos de moneda justos. Puede pasar el cursor sobre cada barra y ver el valor numérico real de la altura de la barra. Las barras más altas representan resultados más probables.
Observe que a medida que x aumenta, las barras se hacen más pequeñas. Esto se debe a que la suma de las alturas de todas las barras siempre será igual a 1. Entonces, cuando x es mayor, el número de caras que podemos observar aumenta y la probabilidad debe dividirse entre más valores.
Binomial Distribution: Calculating Probability of a Given Number of Heads
El método binom.pmf() de la biblioteca scipy.stats se puede utilizar para calcular el PMF de la distribución binomial en cualquier valor. Este método toma 3 valores:
x: el valor del interésn: el número de ensayosp: la probabilidad de éxitoPor ejemplo, supongamos que lanzamos una moneda normal 10 veces y contamos el número de caras. Podemos usar la función binom.pmf() para calcular la probabilidad de observar 6 cabezas de la siguiente manera:
# import necessary library
import scipy.stats as stats
# st.binom.pmf(x, n, p)
print(stats.binom.pmf(6, 10, 0.5))
Output
0.205078
Observe que dos de los tres valores que entran en el método stats.binomial.pmf() son los parámetros que definen la distribución binomial: n representa el número de intentos y p representa la probabilidad de éxito.
Hemos visto que podemos calcular la probabilidad de observar un valor específico usando una función de masa de probabilidad. ¿Qué pasa si queremos encontrar la probabilidad de observar un rango de valores para una variable aleatoria discreta? Una forma de hacer esto es sumando la probabilidad de cada valor.
Por ejemplo, digamos que lanzamos una moneda justa 5 veces y queremos saber la probabilidad de obtener entre 1 y 3 caras. Podemos visualizar este escenario con la función de masa de probabilidad:
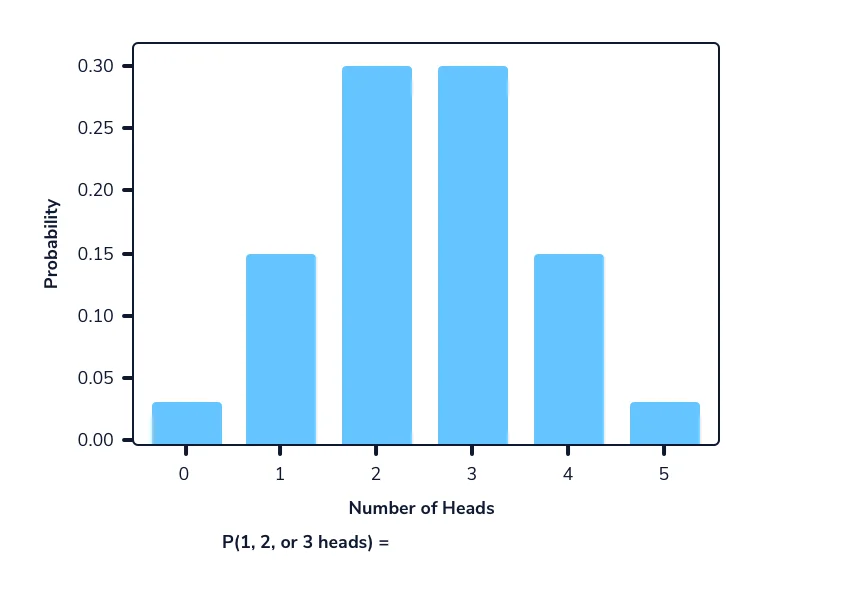
Podemos calcular esto usando la siguiente ecuación donde P(x) es la probabilidad de observar el número x de éxitos (cara en este caso):
P(1 to 3 heads) = P(1<= X <=3)
P(1 to 3 heads) = P(X=1) + P(X=2) + P(X=3)
P(1 to 3 heads) = 0.1562 + 0.3125 + 0.3125
P(1 to 3 heads) = 0.7812
Visualicemos lo que significa tomar la probabilidad de un rango. Utilice los controles deslizantes para seleccionar un rango de valores que representen el número de caras que podríamos observar en 10 lanzamientos de moneda justos.
Pruebe diferentes rangos para ver cómo cambian las probabilidades para diferentes valores. Pase el cursor sobre una barra individual para ver la altura de la barra (que corresponde a la probabilidad de que ocurra el valor).
Binomial Distribution: Calculating Probability of a Range
Podemos utilizar el mismo método binom.pmf() de la biblioteca scipy.stats para calcular la probabilidad de observar un rango de valores. Como se mencionó en un ejercicio anterior, el método binom.pmf toma 3 valores:
x: el valor del interésn: el número de ensayosp: la probabilidad de éxitoPor ejemplo, podemos calcular la probabilidad de observar entre 2 y 4 caras en 10 lanzamientos de moneda de la siguiente manera:
import scipy.stats as stats
# calculating P(2-4 heads) = P(2 heads) + P(3 heads) + P(4 heads) for flipping a coin 10 times
print(stats.binom.pmf(2, n=10, p=.5)
+ stats.binom.pmf(3, n=10, p=.5)
+ stats.binom.pmf(4, n=10, p=.5))
Output:
0.366211
También podemos calcular la probabilidad de observar menos de un cierto valor, digamos 3 caras, sumando las probabilidades de los valores debajo de él:
import scipy.stats as stats
# calculating P(less than 3 heads) = P(0 heads) + P(1 head) + P(2 heads) for flipping a coin 10 times
print(stats.binom.pmf(0, n=10, p=.5)
+ stats.binom.pmf(1, n=10, p=.5)
+ stats.binom.pmf(2, n=10, p=.5))
Output
0.0546875
Tenga en cuenta que debido a que nuestro rango deseado es inferior a 3 cabezas, no incluimos ese valor en la suma.
Cuando hay muchos valores de interés posibles, esta tarea de sumar probabilidades puede resultar difícil. Si queremos saber la probabilidad de observar 8 o menos caras en 10 lanzamientos de moneda, debemos sumar los valores del 0 al 8:
import scipy.stats as stats
var = stats.binom.pmf(0, n = 10, p = 0.5)
+ stats.binom.pmf(1, n = 10, p = 0.5)
+ stats.binom.pmf(2, n = 10, p = 0.5)
+ stats.binom.pmf(3, n = 10, p = 0.5)
+ stats.binom.pmf(4, n = 10, p = 0.5)
+ stats.binom.pmf(5, n = 10, p = 0.5)
+ stats.binom.pmf(6, n = 10, p = 0.5)
+ stats.binom.pmf(7, n = 10, p = 0.5)
+ stats.binom.pmf(8, n = 10, p = 0.5)
Output
0.98926
Esto implica una gran cantidad de código repetitivo. En su lugar, también podemos utilizar el hecho de que la suma de las probabilidades de todos los valores posibles es igual a 1:
P(0to8heads) + P(9to10heads) = P(0to10heads) = 1
P(0to8heads) = 1 − P(9to10heads)
Ahora, en lugar de sumar 9 valores para las probabilidades entre 0 y 8 caras, podemos hacer 1 menos la suma de dos valores y obtener el mismo resultado:
import scipy.stats as stats
# less than or equal to 8
1 - (stats.binom.pmf(9, n=10, p=.5) + stats.binom.pmf(10, n=10, p=.5))
Output
0.98926
La función de distribución acumulativa para una variable aleatoria discreta se puede derivar de la función de masa de probabilidad. Sin embargo, en lugar de la probabilidad de observar un valor específico, la función de distribución acumulativa proporciona la probabilidad de observar un valor específico O MENOS.
Como se analizó anteriormente, las probabilidades de todos los valores posibles en una distribución de probabilidad dada suman 1. El valor de una función de distribución acumulativa en un valor dado es igual a la suma de las probabilidades menores que él, con un valor de 1 para la mayor número posible.
Mostramos cómo se puede utilizar la función de masa de probabilidad para calcular la probabilidad de observar menos de 3 caras en 10 lanzamientos de moneda sumando las probabilidades de observar 0, 1 y 2 caras. La función de distribución acumulativa produce la misma respuesta al evaluar la función en CDF(X=2). En este caso, utilizar el CDF es más sencillo que el PMF porque requiere un cálculo en lugar de tres.
La animación del enlace muestra la relación entre la función de masa de probabilidad y la función de distribución acumulativa. El gráfico superior es el PMF, mientras que el gráfico inferior es el CDF correspondiente. Al observar la gráfica de una CDF, cada valor del eje y es la suma de las probabilidades menores o iguales que él en la PMF.
Podemos usar una función de distribución acumulativa para calcular la probabilidad de un rango específico tomando la diferencia entre dos valores de la función de distribución acumulativa. Por ejemplo, para encontrar la probabilidad de observar entre 3 y 6 caras, podemos tomar la probabilidad de observar 6 o menos cabezas y restar la probabilidad de observar 2 o menos caras. Esto deja un remanente de entre 3 y 6 cabezas.
La imagen de la derecha demuestra cómo funciona esto. Es importante tener en cuenta que para incluir el límite inferior en el rango, el valor que se resta debe ser uno menos que el límite inferior. En este ejemplo, queríamos saber la probabilidad de 3 a 6, que incluye 3.
Podemos utilizar el método binom.cdf() de la biblioteca scipy.stats para calcular la función de distribución acumulativa. Este método toma 3 valores:
x: el valor de interés, buscando la probabilidad de este valor o menosn: el tamaño de la muestrap: la probabilidad de éxitoCalcular matemáticamente la probabilidad de observar 6 o menos caras en 10 lanzamientos de moneda justos (0 a 6 caras) se parece a lo siguiente:
P(6 or fewer heads) = P(0 to 6 heads)
El codigo en Python es:
import scipy.stats as stats
print(stats.binom.cdf(6, 10, 0.5))
Output
0.828125
Se puede pensar que calcular la probabilidad de observar entre 4 y 8 caras en 10 lanzamientos de moneda justos es tomar la diferencia del valor de la función de distribución acumulativa en 8 de la función de distribución acumulativa en 3:
P(4 to 8 Heads) = P(0 to 8 Heads) − P(0 to 3 Heads)
En Python utilizamos el codigo:
import scipy.stats as stats
print(stats.binom.cdf(8, 10, 0.5) - stats.binom.cdf(3, 10, 0.5))
Output
0.81738
Para calcular la probabilidad de observar más de 6 caras en 10 lanzamientos de moneda justos, restamos el valor de la función de distribución acumulativa en 6 de 1. Matemáticamente, esto se parece a lo siguiente:
P(more than 6 Heads) = 1 - P(6 or fewer Heads)
Tenga en cuenta que “más de 6 cabezas” no incluye 6. En Python, calcularíamos esta probabilidad usando el siguiente código:
import scipy.stats as stats
print(1 - stats.binom.cdf(6, 10, 0.5))
Output
0.171875
Los tipos de variables aleatorias discretas se clasifican comúnmente según las distribuciones de probabilidad que describen cómo se comportan los datos asociados a estas variables. Aquí describo algunas de las distribuciones más comunes y utilizadas para variables aleatorias discretas. En Python, la librería scipy.stats proporciona implementaciones de las PMFs para muchas distribuciones discretas comunes, lo que facilita su cálculo en la práctica. Estas funciones son extremadamente útiles para simulaciones, modelado estadístico y análisis probabilístico en una amplia gama de aplicaciones.
from scipy.stats import binom import numpy # Parámetros n = 10 # número de ensayos p = 0.5 # probabilidad de éxito size = 100 # muestras a generar # Generar Variables numpy.random.binomial(n, p, size) # Calcular PMF para un valor específico k = 5 # número de éxitos prob = binom.pmf(k, n, p) print(f"Probabilidad de {k} éxitos en {n} ensayos: {prob:.4f}") from scipy.stats import poisson import numpy lambda_ = 3 # tasa media de eventos por intervalo zize = 10 # número de muestras a generar. # Generar variables numpy.random.poisson(lambda_, size) # Calcular PMF k = 4 # número de eventos prob = poisson.pmf(k, lambda_) print(f"Probabilidad de {k} eventos: {prob:.4f}") from scipy.stats import geom import numpy p = 0.2 # probabilidad de éxito en cada ensayo zize = 10 # número de muestras a generar. # generar variable numpy.random.geometric(p, size) # Calcular PMF k = 5 # ensayo en el que ocurre el primer éxito prob = geom.pmf(k, p) print(f"Probabilidad de primer éxito en el intento {k}: {prob:.4f}") from scipy.stats import nbinom import numpy r = 5 # número de éxitos deseados p = 0.5 # probabilidad de éxito en cada ensayo zize = 10 # número de muestras a generar. # generar variable numpy.random.negative_binomial(n, p, size) # Calcular PMF k = 10 # total de ensayos prob = nbinom.pmf(k-r, r, p) print(f"Probabilidad de alcanzar {r} éxitos en {k} ensayos: {prob:.4f}") from scipy.stats import hypergeom import numpy M = 20 # tamaño total de la población n = 7 # número de éxitos en la población N = 12 # tamaño de la muestra # Calcular PMF k = 3 # número de éxitos observados en la muestra prob = hypergeom.pmf(k, M, n, N) print(f"Probabilidad de {k} éxitos en una muestra de {N}: {prob:.4f}") # generar variable ngood # número de elementos "buenos" en la población. nbad # número de elementos "malos" en la población. nsample # número de elementos a muestrear (sin reemplazo). size # número de muestras a generar. numpy.random.hypergeometric(ngood, nbad, nsample, size=None)Estas distribuciones permiten modelar una gran variedad de procesos y fenómenos en diversos campos como la biología, ingeniería, economía, ciencias sociales, y más. Cada tipo de distribución proporciona un modelo estadístico que se adapta a las características específicas de los datos y la naturaleza del experimento o la observación realizada.
Las variables aleatorias continuas son aquellas que pueden tomar cualquier valor numérico dentro de un intervalo o conjunto de intervalos, a diferencia de las variables aleatorias discretas que tienen valores contables y separados. Este tipo de variables es fundamental en estadística y probabilidad para modelar fenómenos que requieren una escala de medida infinita y continua.
De manera similar a cómo las variables aleatorias discretas se relacionan con las funciones de masa de probabilidad, las variables aleatorias continuas se relacionan con las funciones de densidad de probabilidad. Definen las distribuciones de probabilidad de variables aleatorias continuas y abarcan todos los valores posibles que puede adoptar la variable aleatoria dada.
Cuando se representa gráficamente, una función de densidad de probabilidad es una curva que atraviesa todos los valores posibles que puede tomar la variable aleatoria, y el área total bajo esta curva suma 1.
La siguiente imagen muestra una función de densidad de probabilidad. El área resaltada representa la probabilidad de observar un valor dentro del rango resaltado.
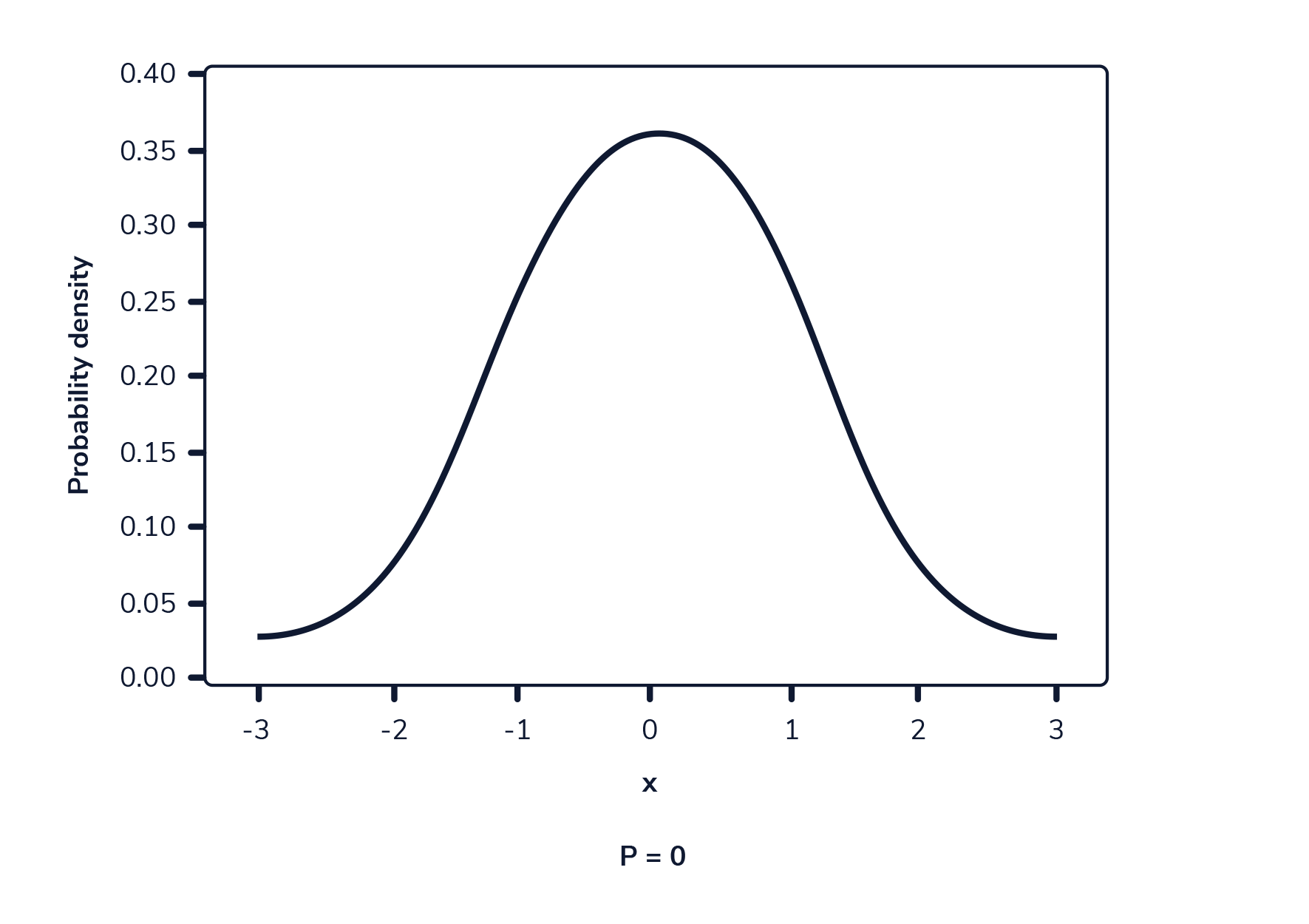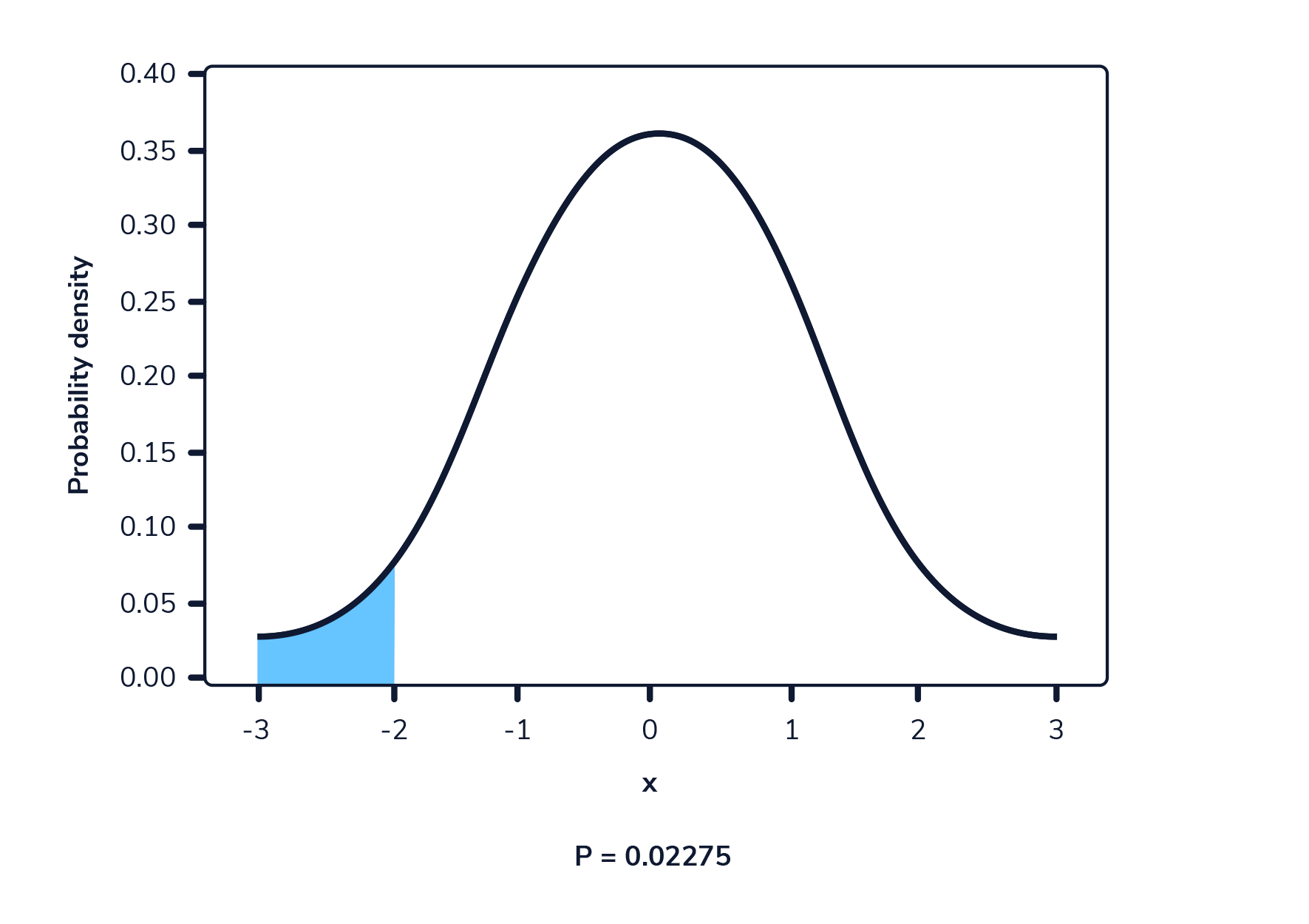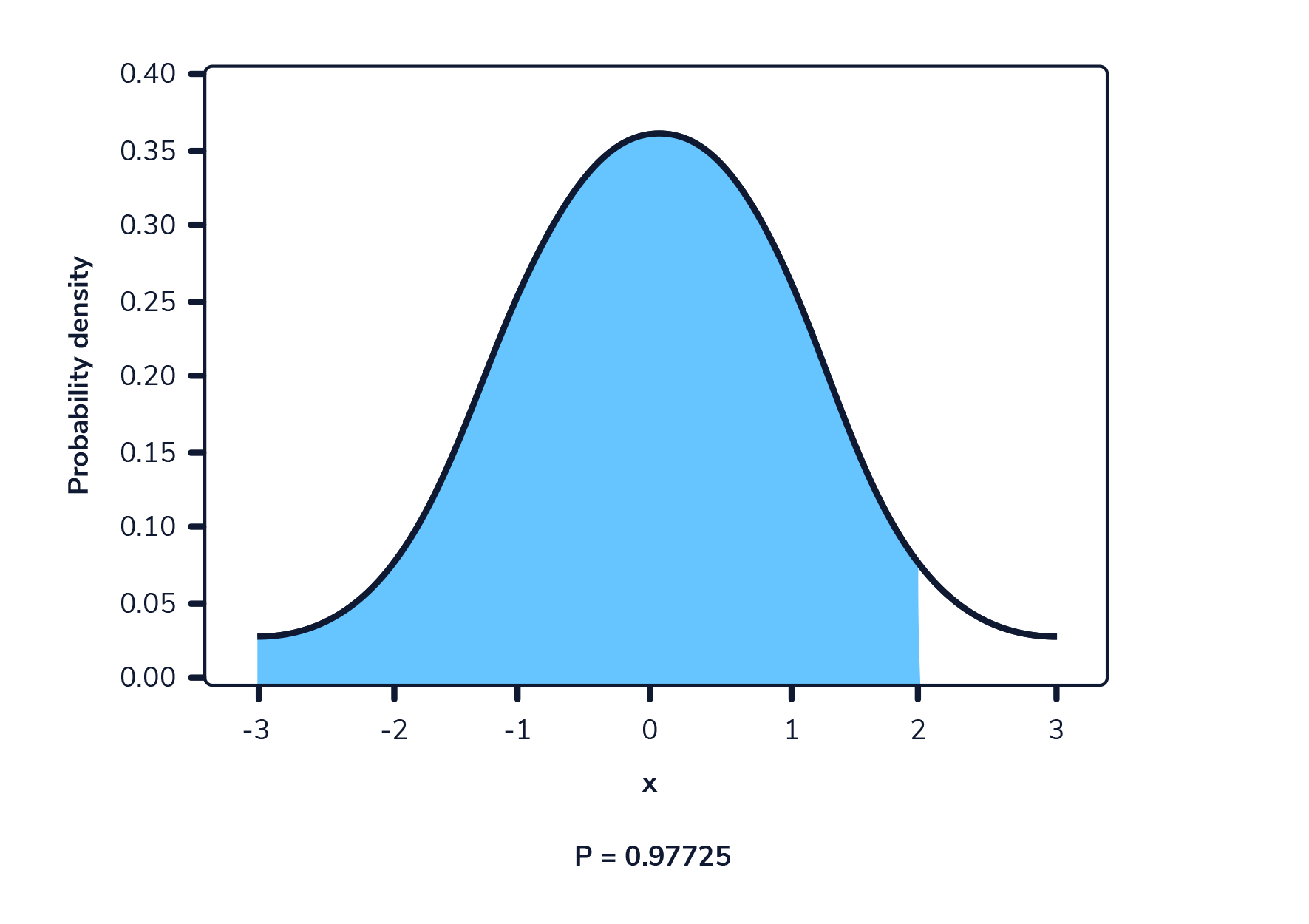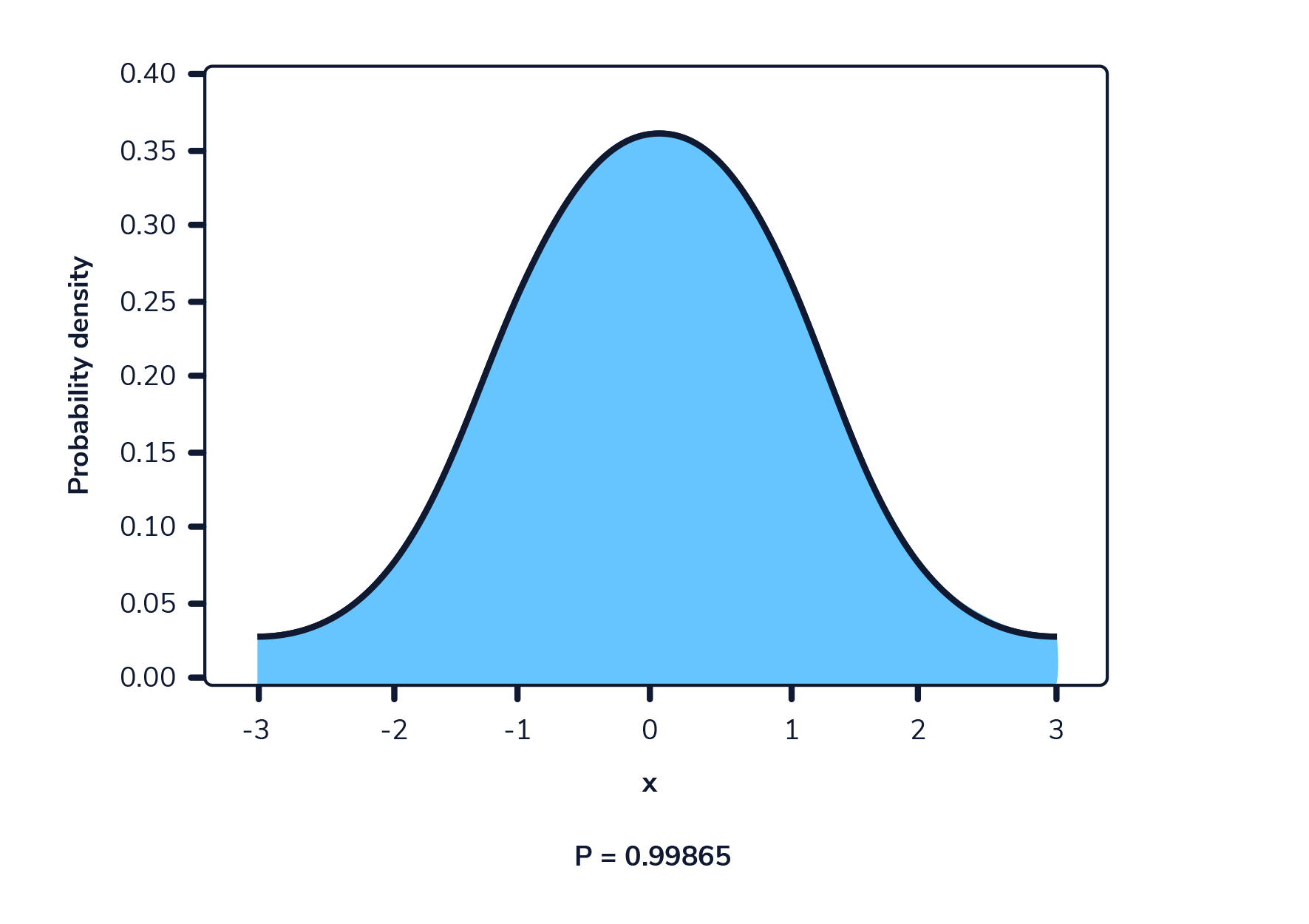
En una función de densidad de probabilidad, no podemos calcular la probabilidad en un solo punto. Esto se debe a que el área de la curva debajo de un único punto es siempre cero. El siguiente gif muestra esto.
Como podemos ver en la imagen anterior, a medida que el intervalo se hace más pequeño, el ancho del área bajo la curva también se hace más pequeño. Al intentar evaluar el área bajo la curva en un punto específico, el ancho de esa área se vuelve 0 y, por lo tanto, la probabilidad es igual a 0.
Podemos calcular el área bajo la curva usando la función de distribución acumulativa para la distribución de probabilidad dada.
Por ejemplo, las alturas caen bajo un tipo de distribución de probabilidad llamada distribución normal. Los parámetros de la distribución normal son la media y la desviación estándar, y utilizamos la forma Normal(media, desviación estándar) como abreviatura.
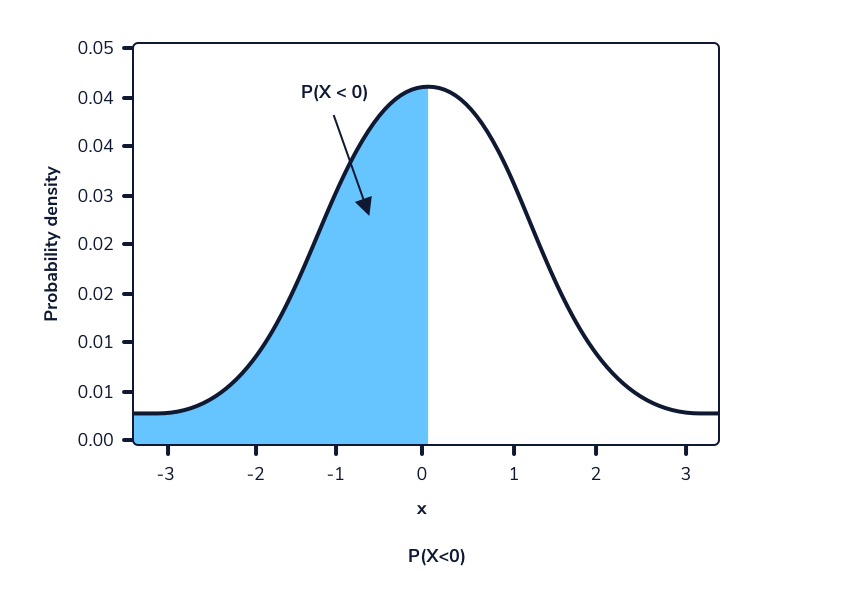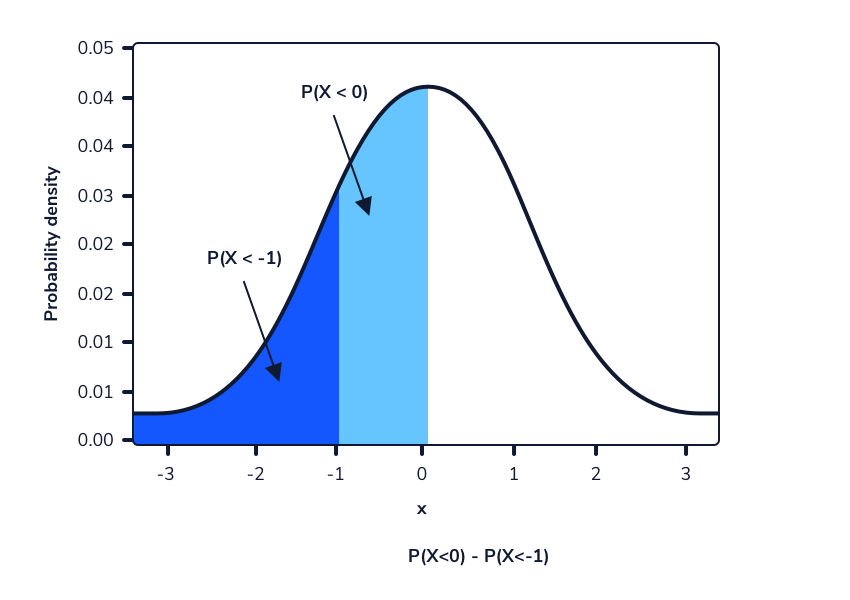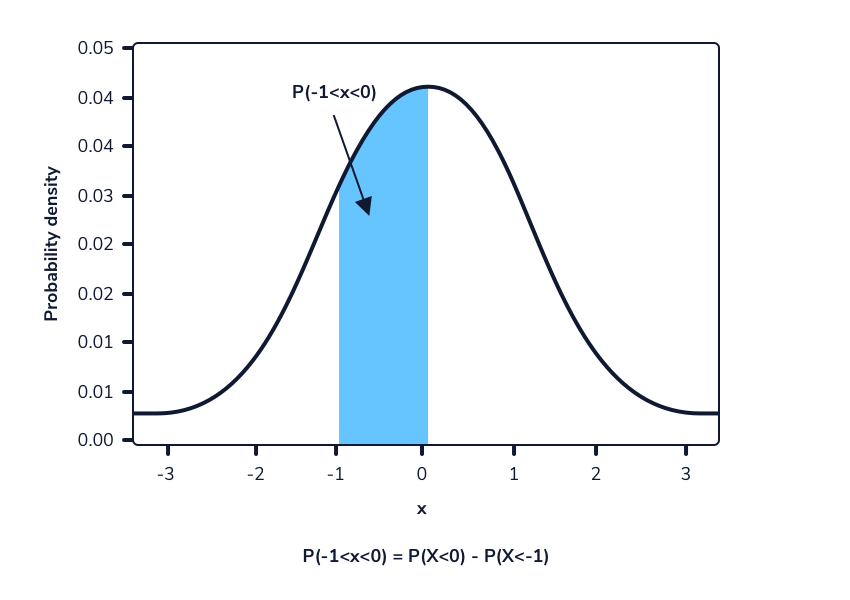
Sabemos que la altura de las mujeres tiene una media de 167,64 cm con una desviación estándar de 8 cm, lo que las sitúa bajo la distribución Normal(167,64,8).
Digamos que queremos saber la probabilidad de que una mujer elegida al azar mida menos de 158 cm. Podemos usar la función de distribución acumulativa para calcular el área bajo la curva de la función de densidad de probabilidad de 0 a 158 para encontrar esa probabilidad.

Podemos calcular el área de la región azul en Python usando el método norm.cdf() de la biblioteca scipy.stats. Este método toma 3 valores:
x: el valor del interésloc: la media de la distribución de probabilidadscale: la desviación estándar de la distribución de probabilidadimport scipy.stats as stats
# stats.norm.cdf(x, loc, scale)
print(stats.norm.cdf(158, 167.64, 8))
Output
0.1141
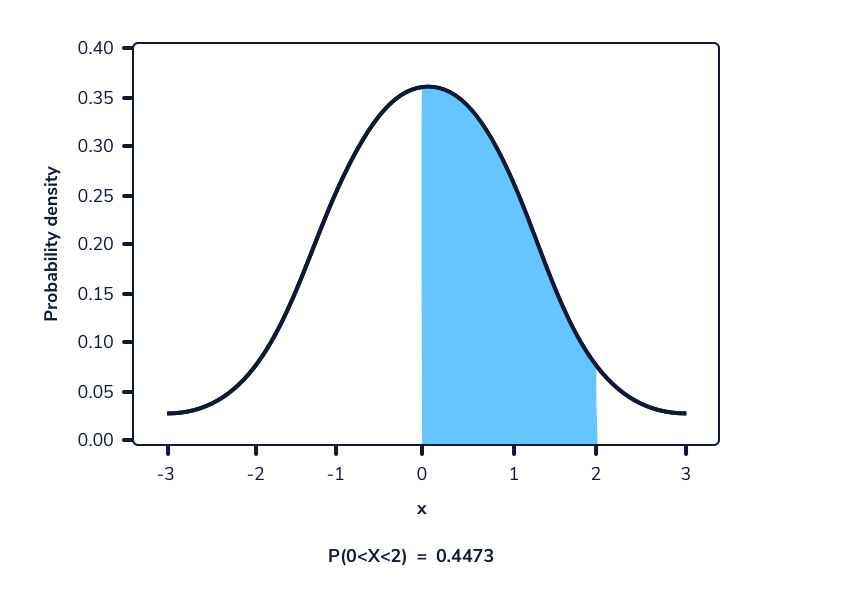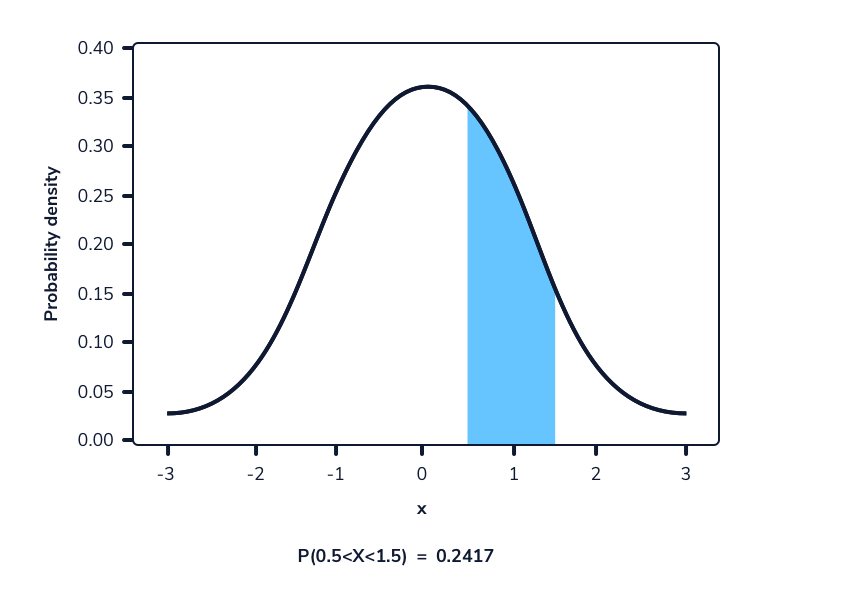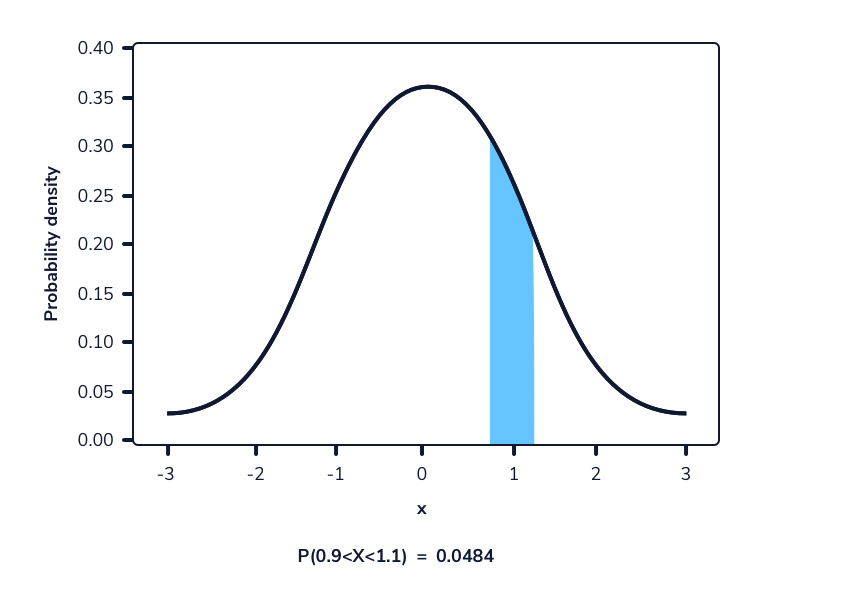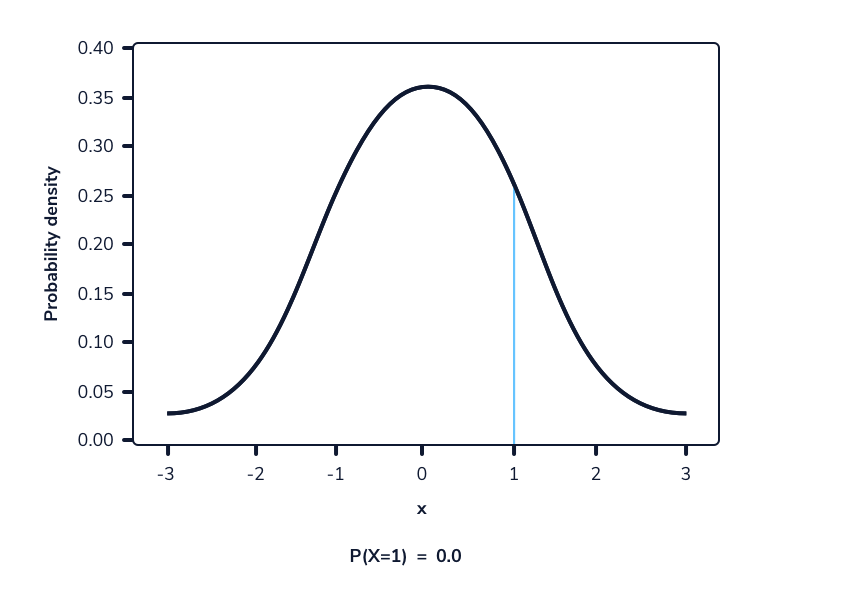
Podemos tomar la diferencia entre dos rangos superpuestos para calcular la probabilidad de que una selección aleatoria esté dentro de un rango de valores para distribuciones continuas. Este es esencialmente el mismo proceso que calcular la probabilidad de un rango de valores para distribuciones discretas.
Digamos que queremos calcular la probabilidad de observar aleatoriamente a una mujer de entre 165 cm y 175 cm, suponiendo que las alturas todavía siguen la distribución Normal (167,74, 8). Podemos calcular la probabilidad de observar estos valores o menos. La diferencia entre estas dos probabilidades será la probabilidad de observar aleatoriamente a una mujer en este rango dado. Esto se puede hacer en Python usando el método norm.cdf() de la biblioteca scipy.stats. Como se mencionó anteriormente, este método adopta 3 valores:
import scipy.stats as stats
# P(165 < X < 175) = P(X < 175) - P(X < 165)
# stats.norm.cdf(x, loc, scale) - stats.norm.cdf(x, loc, scale)
print(stats.norm.cdf(175, 167.74, 8) - stats.norm.cdf(165, 167.74, 8))
Output
0.45194
También podemos calcular la probabilidad de observar aleatoriamente un valor o mayor restando de 1 la probabilidad de observar menos que el valor dado. Esto es posible porque sabemos que el área total bajo la curva es 1, por lo que la probabilidad de observar algo mayor que un valor es 1 menos la probabilidad de observar algo menor que el valor dado.
Digamos que queremos calcular la probabilidad de observar a una mujer que mide más de 172 centímetros, suponiendo que las alturas todavía siguen la distribución Normal (167,74, 8). Podemos pensar en esto como lo opuesto a observar a una mujer que mide menos de 172 centímetros. Podemos visualizarlo de esta manera:

Podemos usar el siguiente código para calcular el área azul tomando 1 menos el área roja:
import scipy.stats as stats
# P(X > 172) = 1 - P(X < 172)
# 1 - stats.norm.cdf(x, loc, scale)
print(1 - stats.norm.cdf(172, 167.74, 8))
Output
0.45194
loc: media de la distribución (mu).scale: desviación estándar de la distribución (sigma).size: número de muestras a generar.numpy.random.normal(loc=0.0, scale=1.0, size=None) Genera números a partir de una distribución normal con media loc y desviación estándar scale.scale: inverso de la tasa (lambda), a veces llamado parámetro de escala.size: número de muestras a generar.numpy.random.exponential(scale=1.0, size=None) Genera números a partir de una distribución exponencial con un parámetro de escala.low: límite inferior del rango de los valores.high: límite superior del rango de los valores.size: número de muestras a generar.numpy.random.uniform(low=0.0, high=1.0, size=None) Genera números a partir de una distribución uniforme entre low y high.a: parámetro de forma alpha.b: parámetro de forma beta.size: número de muestras a generar.numpy.random.beta(a, b, size=None) Genera números a partir de una distribución beta con parámetros a y b.shape: parámetro de forma (k).scale: parámetro de escala (theta).size: número de muestras a generar.numpy.random.gamma(shape, scale=1.0, size=None) Genera números a partir de una distribución gamma con un parámetro de forma y escala.Estos métodos permiten simular datos que siguen estas distribuciones, lo que es útil en simulaciones, pruebas de hipótesis, y para entender mejor el comportamiento estadístico de fenómenos modelados por estas distribuciones.
La distribución binomial es una de las herramientas más importantes en estadística y ciencia de datos. Aparece siempre que repetimos un experimento con dos posibles resultados —éxito o fracaso, sí o no, 1 o 0 — y queremos conocer la probabilidad de obtener cierto número de éxitos en un conjunto de intentos.
En esta clase veremos qué es, cómo se construye y por qué es tan útil para problemas reales como comprobar si una moneda está trucada, evaluar la precisión de un modelo o estimar tasas de éxito en marketing, medicina o industria.
En el articulo anterior aborde la Distribución Bernoulli, que describe un experimento con dos resultados posibles:
Si la probabilidad de éxito es p, entonces la probabilidad de fracaso es 1 – p.
La pregunta ahora es: ¿qué ocurre cuando repetimos este experimento varias veces?
Por ejemplo:
La distribución que describe el número total de éxitos obtenidos en n intentos independientes es la Distribución Binomial.
Supón que quieres determinar si una moneda es justa.
Planteamos dos hipótesis:
Lanzas la moneda n veces y defines:
$$X_i = \begin{cases}1, & \text{si sale cara} \\ 0, & \text{si sale cruz} \end{cases}$$
El número total de caras es:
$$S = X_1 + X_2 + \cdots + X_n$$
La pregunta clave es:
¿cuál es la probabilidad de que ocurra un determinado valor de S si la moneda es justa?
Responder a eso es exactamente el papel de la distribución binomial.
Para obtener 0 caras en n lanzamientos, todas deben ser cruces:
$$P(S=0) = (1 – p)^n$$
Solo existe una secuencia posible: TTTTT…T (n veces).
La probabilidad de que una secuencia concreta sea “una cara + n-1 cruces” es:
$$p(1-p)^{n-1}$$
Pero hay n posiciones posibles para esa única cara:
Así que:
$$P(S=1) = n \cdot p(1-p)^{n-1}$$
Para obtener exactamente s caras en n lanzamientos:
La probabilidad de una secuencia concreta es:
$$p^{s}(1-p)^{n-s}$$
El número de secuencias distintas que contienen exactamente s caras y n-s cruces es:
$$\begin{pmatrix} n \\ s \end{pmatrix}$$
que se lee “n elige s”.
Entonces, la probabilidad total es:
$$P(S=s) = \begin{pmatrix} n \\ s \end{pmatrix} p^{s}(1-p)^{n-s}$$
Esta es la fórmula de la distribución binomial.
El operador combinatorio:
$$ \begin{pmatrix} n \\ s \end{pmatrix} = \frac{n!}{s!(n-s)!}$$
cuenta cuántas formas hay de elegir s elementos dentro de un conjunto de n elementos, sin importar el orden.
Ejemplo clásico:
El número de manos posibles de 5 cartas tomadas de una baraja de 52 cartas es:
$$\begin{pmatrix}52 \\ 5 \end{pmatrix}$$
En nuestro contexto, representa cuántas secuencias distintas tienen s caras y n-s cruces.
La distribución depende de dos parámetros:
Pero si en vez de mirar S, miramos la fracción de éxitos:
$$\frac{S}{n}$$
lo que ocurre es que la distribución se estrecha alrededor de p. Esto conecta con la Ley de los Grandes Números.
Cuando p = 0.5, la distribución es simétrica (si n es grande).
$$E[S] = np$$
$$Var(S) = np(1-p)$$
Si (n) es suficientemente grande, la distribución binomial se aproxima a una normal:
$$S \approx \mathcal{N}(np, np(1-p))$$
Esto es extremadamente útil en estadística inferencial.
La distribución binomial:
En muchas situaciones del mundo real nos enfrentamos a experimentos que solo tienen dos posibles resultados. Por ejemplo:
Cuando un experimento tiene solo dos resultados posibles, podemos modelarlo mediante la distribución de Bernoulli, una de las distribuciones más simples y fundamentales en la estadística y la teoría de la probabilidad.
Esta distribución recibe su nombre del matemático suizo Jacob Bernoulli (1655–1705), y es la base de muchas distribuciones más complejas, como la binomial, la geométrica o la beta.
Una variable aleatoria Bernoulli \( X \) puede tomar solo dos valores:
$$X = \begin{cases} 1 & \text{con probabilidad } p \\ 0 & \text{con probabilidad } (1 – p)
\end{cases}$$
Donde \( p \) es el parámetro de la distribución y representa la probabilidad de éxito (por ejemplo, obtener “cara” en una moneda justa).
El parámetro \( p \) cumple que:
$$0 \leq p \leq 1$$
La función que describe la probabilidad de cada posible resultado se llama función de masa de probabilidad (PMF):
$$P(X = x) = p^x (1 – p)^{1 – x}, \quad x \in {0, 1}$$
Aunque parezca complicada, en realidad es muy sencilla:
Por ejemplo, si ( p = 0.5 ), tenemos una moneda justa; si ( p = 0.8 ), una moneda sesgada hacia cara.
El valor esperado o esperanza matemática \(E[X] [latex] representa el promedio que obtendríamos si repitiésemos el experimento infinitas veces.
Para una Bernoulli:
$$E[X] = 0 \times (1 – p) + 1 \times p = p$$
Es decir, la esperanza de una Bernoulli es igual al parámetro ( p ).
Si una moneda tiene ( p = 0.7 ) de salir cara, el valor esperado de obtener cara es 0.7.
La varianza mide cuánto se dispersan los valores posibles de la variable respecto a su media.
En la Bernoulli, se calcula como:
$$Var(X) = p (1 – p)$$
Esto tiene una interpretación interesante:
Podemos representar la distribución de Bernoulli de varias formas en Python.
A continuación se muestran ejemplos con scipy y también una simulación manual con numpy.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import bernoulli
# Parámetro de la distribución
p = 0.5
# Posibles valores de X (0 o 1)
x = [0, 1]
# Función de masa de probabilidad (PMF)
pmf = bernoulli.pmf(x, p)
# Graficamos
plt.bar(x, pmf, color='skyblue', edgecolor='black')
plt.xticks([0, 1], ['Fallo (0)', 'Éxito (1)'])
plt.title(f'Distribución de Bernoulli (p = {p})')
plt.ylabel('Probabilidad')
plt.show()Esto mostrará una gráfica con dos barras, una en 0 con altura 0.5 y otra en 1 con altura 0.5.

# Cálculo teórico
mean_theoretical = bernoulli.mean(p)
var_theoretical = bernoulli.var(p)
print(f"Esperanza (E[X]) = {mean_theoretical}")
print(f"Varianza (Var[X]) = {var_theoretical}")Salida:
Esperanza (E[X]) = 0.5
Varianza (Var[X]) = 0.25numpyVamos a simular 10,000 lanzamientos de una moneda con probabilidad p = 0.7 de salir cara.
# Simulación de 10,000 lanzamientos
n = 10_000
p = 0.7
data = np.random.binomial(1, p, size=n) # Binomial con n=1 equivale a Bernoulli
# Resultados empíricos
mean_empirical = np.mean(data)
var_empirical = np.var(data)
print(f"Media observada: {mean_empirical:.3f}")
print(f"Varianza observada: {var_empirical:.3f}")Salida:
Media observada: 0.703
Varianza observada: 0.209La varianza \( Var(X) = p(1 – p) \) alcanza su máximo cuando \( p = 0.5 \).
Podemos comprobarlo gráficamente:
p_values = np.linspace(0, 1, 100)
variance = p_values * (1 - p_values)
plt.plot(p_values, variance, color='coral')
plt.title("Varianza de la Distribución de Bernoulli")
plt.xlabel("p")
plt.ylabel("Varianza")
plt.grid(True)
plt.show()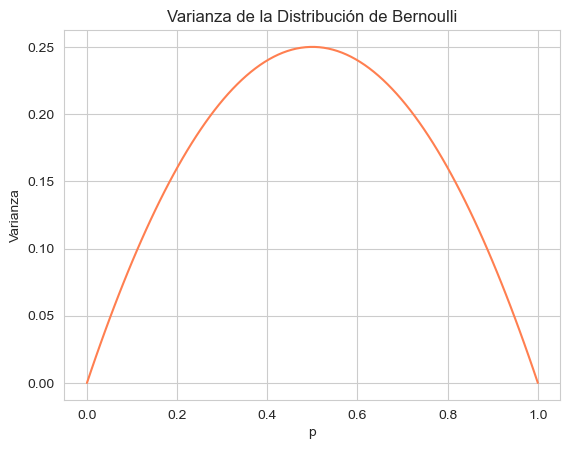
La distribución de Bernoulli es la piedra angular de la probabilidad binaria.
Su simplicidad la convierte en un modelo ideal para entender conceptos más avanzados, como:
En resumen:
| Concepto | Fórmula | Interpretación |
|---|---|---|
| PMF | ( P(X=x) = p^x (1-p)^{1-x} ) | Probabilidad de éxito o fallo |
| Esperanza | ( E[X] = p ) | Promedio esperado |
| Varianza | ( Var(X) = p(1-p) ) | Dispersión de los resultados |
El Teorema de Bayes es una de las ideas más poderosas y elegantes de la probabilidad. Nos permite calcular la probabilidad de que algo sea cierto cuando tenemos nueva información o evidencia.
Imagina un experimento con dos pasos:
Ahora, supón que el resultado del dado fue un 5. La pregunta es: ¿Cuál es la probabilidad de que la moneda haya salido cara, sabiendo que el dado dio 5?”
Este es un ejemplo clásico de probabilidad condicional inversa: queremos invertir el sentido del razonamiento, pasando de
$$P(\text{dado}=5 | \text{cara})$$
a
$$P(\text{cara} | \text{dado}=5)$$
A partir de las definiciones básicas de probabilidad y usando la interpretación geométrica de áreas bajo la curva, se llega a la fórmula general:
$$P(A|B) = \frac{P(B|A) P(A)}{P(B)}$$
Donde:
Supongamos un test que da positivo el 80 % de las veces en la población general. Sabemos que si una persona tiene COVID, la probabilidad de que el test dé positivo es 0.9. Antes de hacernos el test, creemos que hay un 70 % de probabilidad de estar infectados.
Aplicando Bayes:
$$P(\text{COVID}|\text{test positivo}) = \frac{0.9 \times 0.7}{0.8} = 0.7875$$
Es decir, la probabilidad real de tener COVID aumenta a 78.75 % tras recibir el resultado positivo.
Lo más interesante es que Bayes nos permite actualizar las probabilidades cada vez que obtenemos nueva evidencia. Por ejemplo, si un compañero de piso también da positivo, podemos recalcular con esa información y la probabilidad aumentará (en este caso, hasta cerca del 88 %).
Este proceso de revisión continua de nuestras creencias es la base de muchos algoritmos de aprendizaje automático, donde los modelos aprenden y se ajustan con cada nuevo dato.
En lugar de estimar un solo valor (como hace la estadística clásica), Bayes nos da una distribución completa sobre los posibles valores de los parámetros. Así podemos medir incertidumbre y ajustar nuestras creencias conforme llegan nuevos datos.
$$\text{Posterior} = \frac{\text{Verosimilitud} \times \text{Prior}}{\text{Evidencia}}$$
Veamos un ejemplo básico con Naive Bayes, aplicado a correos electrónicos.
No necesitamos datos reales todavía — solo entender el razonamiento.
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
# Datos de ejemplo
emails = [
"Oferta exclusiva gana dinero rápido", # spam
"Reunión de trabajo a las 10", # no spam
"Compra ahora descuento especial", # spam
"Adjunto informe mensual del proyecto" # no spam
]
labels = [1, 0, 1, 0] # 1 = spam, 0 = no spam
# Convertimos texto a matriz de frecuencias
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails)
# Entrenamos el modelo bayesiano
model = MultinomialNB()
model.fit(X, labels)
# Probamos con un nuevo mensaje
nuevo_email = ["oferta de trabajo con descuento"]
X_new = vectorizer.transform(nuevo_email)
prob_spam = model.predict_proba(X_new)
print("Probabilidad de SPAM:", prob_spam[0][1])
Este modelo aplica el Teorema de Bayes a cada palabra del mensaje y combina los resultados suponiendo independencia entre ellas (por eso se llama Naive o “ingenuo”).
Cuando queremos estimar parámetros desconocidos, usamos librerías especializadas como PyMC:
import pymc as pm
import arviz as az
# Ejemplo: estimar la probabilidad de éxito de una moneda sesgada
with pm.Model() as modelo:
p = pm.Beta("p", alpha=2, beta=2) # Prior: distribución beta
observaciones = pm.Bernoulli("obs", p, observed=[1,0,1,1,0,1]) # Datos
trazas = pm.sample(2000, tune=1000)
az.plot_posterior(trazas)
Aquí usamos una distribución Beta como priori, y tras observar los datos (caras y cruces) obtenemos la distribución posterior de p : nuestra creencia actualizada sobre cuán sesgada está la moneda.
La inferencia bayesiana permite:
Por eso se usa en:
| Concepto | Interpretación Bayesiana |
|---|---|
| Prior | Lo que creemos antes de ver los datos |
| Evidencia | Los datos observados |
| Posterior | Lo que creemos después de ver los datos |
| Verosimilitud | Qué tan probable es ver esos datos si la hipótesis fuera cierta |
La probabilidad condicional es uno de los conceptos más importantes en estadística y ciencia de datos. Nos permite responder preguntas como:
¿Cuál es la probabilidad de que ocurra un evento A sabiendo que ya ocurrió un evento B?
En la vida real, casi ningún fenómeno ocurre de forma completamente independiente. Las variables se relacionan, se influyen y cambian entre sí. La probabilidad condicional nos da una forma matemática de actualizar nuestras expectativas cuando obtenemos nueva información.
Si dos eventos A y B son independientes, conocer que uno ocurrió no cambia la probabilidad del otro. Por ejemplo, lanzar una moneda y luego lanzar un dado son sucesos independientes.
Pero, ¿qué pasa si los eventos no son independientes? Entonces el hecho de que ocurra A modifica la probabilidad de que ocurra B. Esto es exactamente lo que estudia la probabilidad condicional.
Imaginemos un proceso aleatorio en dos pasos:
En este experimento, el tipo de dado que usamos depende del resultado de la moneda. Por tanto, el resultado del dado no es independiente del lanzamiento previo.
Queremos saber, por ejemplo: ¿Cuál es la probabilidad de obtener un 5 en el dado?
Existen dos formas de obtener un 5:
Caso 1: La moneda sale cara y el dado de 6 caras muestra un 5.
$$P(5 \text{ y cara}) = P(C) \times P(5|C)$$
Dado que el dado de 6 caras es justo:
$$P(5|C) = \frac{1}{6}$$
Entonces:
$$P(5 \text{ y cara}) = P_c \times \frac{1}{6}$$
Caso 2: La moneda sale cruz y el dado de 20 caras muestra un 5.
$$P(5 \text{ y cruz}) = P(E) \times P(5|E)$$
En este caso:
$$P(5|T) = \frac{1}{20}$$
Entonces:
$$P(5 \text{ y cruz}) = p_E \times \frac{1}{20}$$
La probabilidad total de obtener un 5 es la suma de ambos casos:
$$P(5) = p_H \times \frac{1}{6} + p_T \times \frac{1}{20}$$
Imagina el área total de posibles resultados del experimento como un rectángulo.
El área combinada de ambos representa la probabilidad total de obtener cualquier resultado posible. Dentro de cada zona, las franjas correspondientes al número “5” son pequeñas porciones de ese total, y su tamaño depende del tipo de dado y de la probabilidad de cada cara o cruz.
La probabilidad condicional de un evento A, dado que ocurrió B, se define como:
$$P(A|B) = \frac{P(A \cap B)}{P(B)}$$
Es decir:
La probabilidad de que ocurra A dado que ocurrió B, es igual a la probabilidad de que ambos ocurran, dividida entre la probabilidad de B.
Volviendo a nuestro experimento, podemos preguntar:
¿Cuál es la probabilidad de que el dado muestre 5 dado que salió cara?
Aplicamos la definición:
$$P(5|C) = \frac{P(5 \cap C)}{P(C)} = \frac{P_c \times \frac{1}{6}}{P_c } = \frac{1}{6}$$
Lo que confirma que, al saber que salió cara, solo nos interesa el dado de 6 caras, y cada resultado tiene probabilidad 1/6.
De la definición anterior se deriva una relación muy útil:
$$P(A \cap B) = P(A|B) \times P(B)$$
Esta regla permite descomponer probabilidades conjuntas en términos condicionales y viceversa. También sirve para construir árboles de probabilidad, donde cada rama representa la probabilidad condicional de avanzar hacia un resultado dado.
Un error común al calcular probabilidades es sumar eventos que no son independientes sin ajustar por su intersección.
Por ejemplo, si queremos la probabilidad de que ocurra A o B, debemos restar el solapamiento:
$$P(A \cup B) = P(A) + P(B) – P(A \cap B)$$
De lo contrario, estaríamos contando dos veces los casos en que A y B ocurren simultáneamente.
La probabilidad condicional nos enseña que la información cambia la probabilidad. Saber que algo ocurrió modifica lo que podemos esperar a continuación. Es la base de la estadística inferencial, la teoría bayesiana y gran parte del razonamiento probabilístico moderno.
Nos permite pasar de la incertidumbre total a una incertidumbre informada, paso esencial en cualquier proceso analítico.
Cuando hablamos de probabilidad, a menudo pensamos en números entre 0 y 1, fracciones o porcentajes. Pero existe una forma geométrica e intuitiva de entender la probabilidad:
la probabilidad es área.
La probabilidad de que ocurra un evento puede representarse como la proporción del área total correspondiente a ese evento dentro del espacio de todos los posibles resultados.
Imagina un espacio de resultados como un rectángulo o un círculo que representa todos los resultados posibles de un experimento.
Supongamos que lanzamos un dado y queremos visualizarlo en un diagrama rectangular:
$$P(\text{resultado}) = \frac{\text{área de la sección}}{\text{área total}} = \frac{1}{6}$$
Aquí, área = probabilidad.
Este enfoque funciona incluso si el dado está sesgado: las áreas de cada sección cambian según la probabilidad, pero la suma de todas las áreas sigue siendo 1.
El concepto de probabilidad como área es fundamental en variables continuas, donde los resultados posibles no son discretos. Por ejemplo, si lanzamos un dado “perfectamente continuo” que puede dar cualquier valor entre 0 y 1, entonces:
Esto es la base de la probabilidad continua y la función de densidad (PDF):
$$P(a \leq X \leq b) = \int_{a}^{b} f(x) dx$$
Aquí, la integral representa el área bajo la curva entre los puntos a y b, y esa área es la probabilidad de que X esté en ese intervalo.
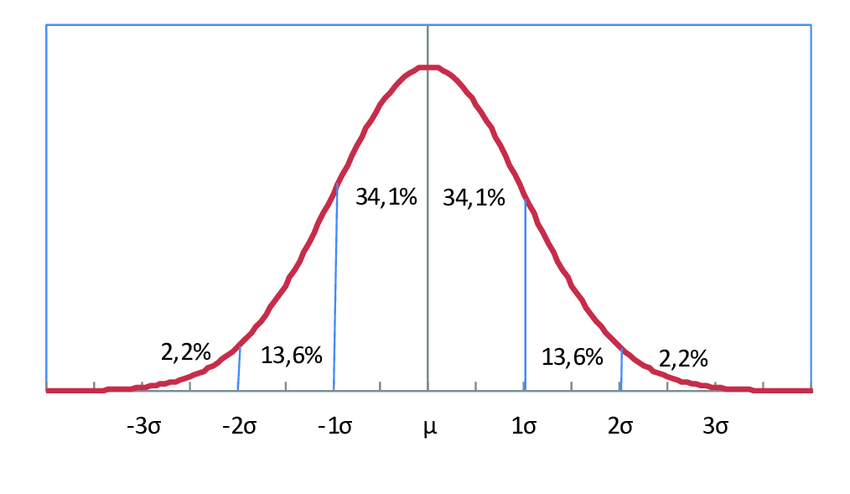
Una forma muy clara de entenderlo es mediante un diagrama de rectángulos o gráficos de barras:
En variables continuas, reemplazamos las barras por curvas suaves.
Visualizar la probabilidad como área tiene ventajas: