Este es el proyecto final del Curso IBM Data Science de Coursera finalizado en septiembre de 2025. En este proyecto proyecto completo de Data Science se predice la recuperación exitosa de la primera etapa del Falcon 9 de SpaceX.
El flujo incluyó recolección de datos mediante la API oficial y web scraping, limpieza y enriquecimiento con pandas, análisis exploratorio y geoespacial con seaborn y Folium, consultas SQL, feature engineering (One-Hot Encoding + escalado), entrenamiento de cuatro modelos de clasificación (Regresión Logística, SVM, Árbol de Decisión y KNN) con GridSearchCV, y despliegue de un dashboard web interactivo con Plotly Dash. Todo implementado en Python utilizando pandas, scikit-learn, matplotlib/seaborn, Folium, SQLite y Dash.
Enlace al sitio del proyecto:
https://github.com/fer78/Space-Launch-Optimization-with-Machine-Learning.git
Escenario y visión general del proyecto
La era espacial comercial ya ha llegado. Las empresas están haciendo que los viajes espaciales sean asequibles para todos:
- Vingin Galactic está ofreciendo vuelos espaciales sub orbitales.
- Rocket Lab es un proveedor de satélites pequeños.
- Blue Origin fabrica cohetes reutilizables sub orbitales y orbitales.
- SpaceX es la más exitosa, envían naves espaciales a la Estación Espacial Internacional, Starlink que proporciona internet satelital y también envía misiones tripuladas al espacio.
Una razón por la cual SpaceX puede hacer estas operaciones es porque ha logrado que sus lanzamientos sean más económicos. Recientemente, anuncio en su sitio web el lanzamiento del nuevo cohete Falcon 9 con un coste de 62 millones de dólares, mientras que otras empresas pueden hacerlo con costes de más de 150 millones.
Gran parte de este ahorro es debido a que SpaceX puede reutilizar la primera etapa del lanzamiento. Con este dato, si podemos determinar si la primera etapa aterrizara, podemos determinar el coste de un lanzamiento.
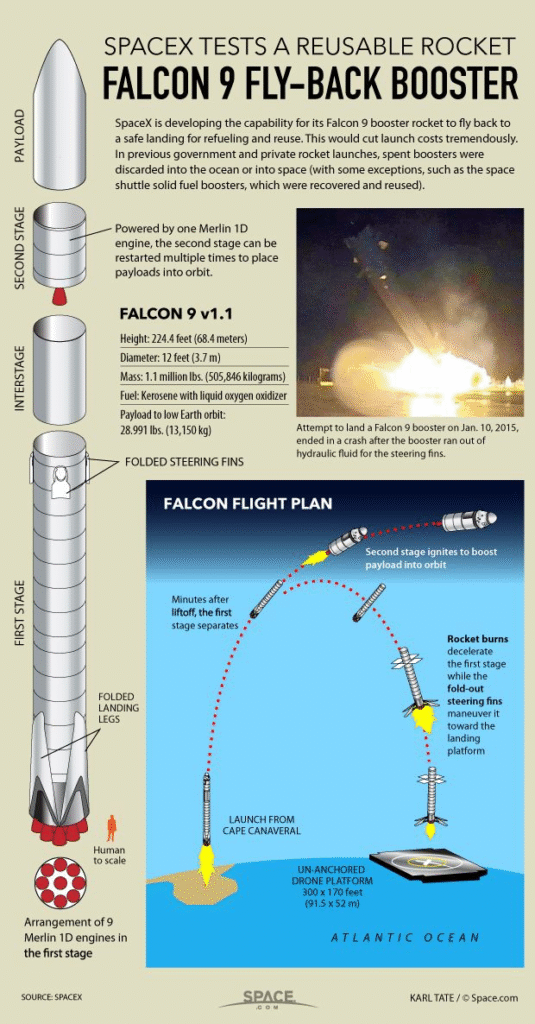
En la infografía se puede apreciar las diferentes partes del cohete:
- Carga útil: contiene el elemento que se desea llevar al espacio.
- Segunda etapa: ayuda a llevar la carga útil a la órbita.
- Primera etapa: Realiza la mayor parte del trabajo de llevar la carga útil a la órbita, es la parte más grande y más costosa.
A diferencia de otros proveedores de cohetes, el Falcon 9 puede recuperar la primera etapa. En ocasiones no tiene éxito durante el aterrizaje y se destruye. En otras ocasiones, la propia empresa destruye la primera etapa debido a los parámetros de la misión como la carga útil. La orbita y el cliente.
En este proyecto asumirás el papel de un científico de datos que trabaja para una empresa nueva empresa de cohetes: SpaceY que quiere competir con SpaceX.

SpaceY fue fundada por el empresario industrial Allon Mask.
Tu trabajo es determinar el precio de cada lanzamiento, recopilando información sobre la competencia y determinando si se reutilizara la primera etapa.
En lugar de usar la ciencia de cohetes para determinar si la primera etapa aterrizara con éxito. Entrenarás un modelo de aprendizaje automático y usarás información pública para predecir si SpaceY reutilizará la primera etapa.
Recolección y estructuración de datos mediante la API oficial de SpaceX
En la primera fase de este proyecto, se construyó un dataset completo y estructurado a partir de datos públicos en tiempo real de todos los lanzamientos históricos de SpaceX, utilizando exclusivamente su API REST oficial (v4).
Parte 1: Extracción de datos mediante peticiones HTTP a la API de SpaceX
Se realizó una petición GET al endpoint https://api.spacexdata.com/v4/launches/past para obtener el histórico completo de lanzamientos.
Dado que la respuesta contiene únicamente identificadores (rocket_id, payload_id, launchpad_id, core_id), se implementó un proceso de data enrichment mediante llamadas secundarias a los endpoints específicos:
/v4/rockets/{id}→ nombre del booster (Falcon 9, Falcon 1, etc.)/v4/launchpads/{id}→ nombre del sitio de lanzamiento, longitud y latitud/v4/payloads/{id}→ masa de la carga útil (kg) y órbita destino (LEO, GTO, ISS, etc.)/v4/cores/{id}→ información crítica del core: éxito del aterrizaje, tipo de aterrizaje (RTLS, ASDS, océano), uso de grid fins y landing legs, bloque del booster, número de reusos, serial del core, etc.
Transformación y normalización de datos
- Se utilizó pd.json_normalize() para aplanar la respuesta JSON anidada en un DataFrame plano.
- Se filtraron lanzamientos con múltiples cores o payloads (casos excepcionales de Falcon Heavy o misiones con rideshare) para mantener consistencia en el análisis de la primera etapa.
Construcción del dataset final de entrenamiento
Se creó un diccionario estructurado con las siguientes variables enriquecidas:
- FlightNumber, Date, BoosterVersion
- PayloadMass, Orbit, LaunchSite, Longitude, Latitude
- Outcome (éxito/fracaso del aterrizaje + tipo), Flights, GridFins, Reused, Legs, LandingPad
- Block, ReusedCount, Serial
Este diccionario se convirtió en un DataFrame final (launch_df).
Limpieza y filtrado específico
- Se eliminaron todos los lanzamientos de Falcon 1, conservando únicamente Falcon 9.
- Se reindexó la columna FlightNumber de forma secuencial (1 a n).
- Se realizó imputación de valores faltantes en PayloadMass utilizando la media global de la columna, manteniendo intencionalmente los valores None en LandingPad (indicando aterrizajes oceánicos sin plataforma).
El resultado es un dataset limpio, estructurado y enriquecido (dataset_part_1.csv) con 90 lanzamientos de Falcon 9 hasta noviembre de 2020, listo para las siguientes fases de análisis exploratorio, feature engineering y modelado predictivo del éxito del aterrizaje de la primera etapa.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 90 entries, 0 to 89
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FlightNumber 90 non-null int64
1 Date 90 non-null object
2 BoosterVersion 90 non-null object
3 PayloadMass 90 non-null float64
4 Orbit 90 non-null object
5 LaunchSite 90 non-null object
6 Outcome 90 non-null object
7 Flights 90 non-null int64
8 GridFins 90 non-null bool
9 Reused 90 non-null bool
10 Legs 90 non-null bool
11 LandingPad 64 non-null object
12 Block 90 non-null float64
13 ReusedCount 90 non-null int64
14 Serial 90 non-null object
15 Longitude 90 non-null float64
16 Latitude 90 non-null float64
dtypes: bool(3), float64(4), int64(3), object(7)
memory usage: 10.2+ KB
Parte 2: Web Scraping de registros históricos desde Wikipedia
En esta segunda fase del proyecto se construyó un dataset alternativo y complementario mediante web scraping de la página de Wikipedia “List of Falcon 9 and Falcon Heavy launches”, con el objetivo de obtener una fuente independiente a la API oficial de SpaceX y permitir validación cruzada de los datos.
Tecnologías y herramientas utilizadas
requestscon cabeceraUser-Agentpersonalizada para evitar bloqueos.BeautifulSoup4como parser HTML.- Funciones auxiliares propias para la extracción robusta de datos en celdas con ruido típico de Wikipedia (referencias, superíndices, enlaces, formato inconsistente).
Proceso de parsing implementado
- Identificación de tablas relevantes
- Extracción automática de nombres de columnas
- Parsing fila por fila con lógica robusta
- Construcción del dataset
Se obtuvo un DataFrame completo con 121 lanzamientos de Falcon 9 y Falcon Heavy hasta junio de 2021, incluyendo información crítica para el modelo predictivo:Booster landing (variable objetivo), Payload mass, Orbit, Launch site, Version Booster, etc.
El archivo final se exportó como spacex_web_scraped.csv, listo para su uso en análisis exploratorio, fusión con el dataset de la API y entrenamiento de modelos de clasificación.
Parte 3: Data Wrangling y definición de la variable objetivo
En esta fase del proyecto se realizó un análisis exploratorio inicial (EDA) y el data wrangling necesario para convertir el dataset crudo (obtenido vía API en la Parte 1) en un conjunto de datos listo para modelado supervisado de clasificación.
Principales tareas realizadas
- Carga y diagnóstico inicial del dataset
- Análisis exploratorio univariante
- Distribución de lanzamientos por sitio de lanzamiento (
LaunchSite): - Distribución por tipo de órbita (
Orbit), destacando la predominancia de LEO, ISS, GTO y SSO, y la presencia de órbitas menos frecuentes (HEO, MEO, ES-L1, etc.).
- Distribución de lanzamientos por sitio de lanzamiento (
- Análisis profundo de la variable
Outcome(resultado del aterrizaje de la primera etapa) - Creación de la variable objetivo binaria (
Class)- Se definió el conjunto de resultados fallidos:
bad_outcomes = {'False ASDS', 'False RTLS', 'False Ocean', 'None ASDS', 'None None'} - Se generó la columna
Classmediante list comprehension:python landing_class = [0 if outcome in bad_outcomes else 1 for outcome in df['Outcome']] df['Class'] = landing_class Class = 1→ primera etapa recuperada con éxitoClass = 0→ no recuperada (fallo o misión expendable)
- Se definió el conjunto de resultados fallidos:
- Cálculo de la tasa de éxito global
Se exportó el dataset enriquecido como dataset_part_2.csv, que incluye:
- Todas las variables originales enriquecidas desde la API
- La nueva variable binaria
Classlista para ser usada como target en modelos de clasificación supervisada - Ningún valor faltante crítico (solo
LandingPadmantieneNoneintencionadamente)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 90 entries, 0 to 89
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FlightNumber 90 non-null int64
1 Date 90 non-null object
2 BoosterVersion 90 non-null object
3 PayloadMass 90 non-null float64
4 Orbit 90 non-null object
5 LaunchSite 90 non-null object
6 Outcome 90 non-null object
7 Flights 90 non-null int64
8 GridFins 90 non-null bool
9 Reused 90 non-null bool
10 Legs 90 non-null bool
11 LandingPad 64 non-null object
12 Block 90 non-null float64
13 ReusedCount 90 non-null int64
14 Serial 90 non-null object
15 Longitude 90 non-null float64
16 Latitude 90 non-null float64
17 Class 90 non-null int64
dtypes: bool(3), float64(4), int64(4), object(7)
memory usage: 10.9+ KB
Parte 4: Exploratory Data Analysis (EDA) & Feature Engineering
En esta fase clave del proyecto se realizó un análisis exploratorio exhaustivo (EDA) y la ingeniería de variables (feature engineering) definitiva para preparar los datos de cara al modelado predictivo supervisado.
Se crean funciones auxiliares propias para aplicar un estilo visual elegante, consistente y profesional (ejes limpios, rejilla vertical rosa, leyenda personalizada rojo/verde para fallos y éxitos)
Análisis exploratorio realizado
FlightNumber vs PayloadMass
Scatter plot que muestra claramente la curva de aprendizaje de SpaceX: los primeros lanzamientos presentan más fallos, mientras que a partir del vuelo ~20–25 la tasa de éxito se vuelve muy alta, incluso con cargas útiles pesadas.
FlightNumber vs LaunchSite
- CCAFS SLC-40 es el sitio dominante en número de lanzamientos.
- Los fallos están concentrados en los primeros vuelos de cada plataforma.
- KSC LC-39A y VAFB SLC-4E muestran tasas de éxito cercanas al 100 % en lanzamientos recientes.
PayloadMass vs LaunchSite
Observación clave: desde VAFB SLC-4E nunca se han lanzado cargas pesadas (>10 000 kg), lo que explica su tasa de éxito casi perfecta.
Success Rate by Orbit Type
Bar chart revelador:
- LEO e ISS → tasa de éxito ≈ 100 %
- GTO → tasa más baja (misión más energética, menor margen para recuperación)
- SSO y polar → éxito muy alto
FlightNumber vs Orbit & PayloadMass vs Orbit
- En LEO el éxito crece claramente con el número de vuelo.
- En GTO la relación no es tan evidente: incluso en vuelos recientes hay tanto éxitos como fallos, debido a la mayor dificultad energética.
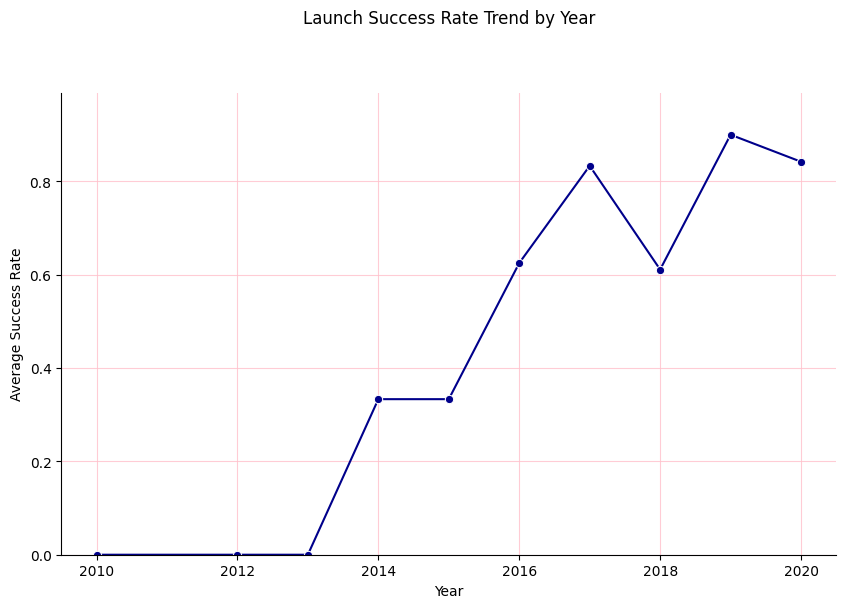
Evolución anual de la tasa de éxito (2013–2020)
Line chart que muestra una mejora sostenida y casi lineal desde ~50 % en 2013 hasta >95 % en 2020, reflejando la madurez tecnológica de la reutilización.
Feature Engineering
- Selección de variables relevantes para el modelo:
- One-Hot Encoding aplicado a las variables categóricas:
Orbit(11 categorías)LaunchSite(3)LandingPad(5)Serial(53 identificadores únicos de boosters)
- Conversión completa del dataset a tipo
float64para compatibilidad con algoritmos de Machine Learning.
Se generó el dataset definitivo dataset_part_3.csv con 104 columnas numéricas y 90 observaciones, completamente limpio, codificado y listo para entrenamiento de modelos de clasificación.
Parte 5: Análisis exploratorio con SQL
Aunque el núcleo del proyecto se basa en Machine Learning con Python, esta fase complementaria demuestra una competencia adicional muy valorada en ciencia de datos: el dominio de consultas SQL para análisis exploratorio y extracción de insights directamente desde bases de datos relacionales.
Objetivo
Utilizar SQLite como motor de base de datos en entorno local para cargar el dataset completo de misiones SpaceX y resolver 10 consultas analíticas reales mediante lenguaje SQL puro.
Infraestructura implementada
- Creación de base de datos en memoria:
my_data1.db - Carga del archivo CSV original mediante
pandas.to_sql() - Limpieza inicial: eliminación de filas con fecha nula
- Uso de la extensión mágica
%sqlpara ejecutar consultas directamente desde Jupyter
Consultas SQL realizadas y resultados clave obtenidos
| Task | Consulta realizada | Insight principal |
|---|---|---|
| 1 | DISTINCT Launch_Site | 4 sitios únicos: CCAFS SLC-40, KSC LC-39A, VAFB SLC-4E, CCAFS LC-40 |
| 2 | Lanzamientos desde sitios que empiezan por ‘CCA’ | 69 misiones (mayoría histórica) |
| 3 | Masa total de carga útil NASA (CRS) | 45 716 kg transportados en contratos CRS |
| 4 | Masa media de carga en versión F9 v1.1 | 2 534 kg (versión temprana con menor capacidad) |
| 5 | Primera fecha de aterrizaje exitoso en plataforma terrestre | 2015-12-22 (Flight 20 – hito histórico RTLS) |
| 6 | Boosters con éxito en dron ship y carga entre 4000–6000 kg | 9 casos (todos F9 FT Bxxxx) |
| 7 | Conteo total de éxitos y fallos de misión | 98 éxitos – 1 fallo (CRS-7 explosión) |
| 8 | Booster_Version con máxima carga útil | 13 600 kg → F9 B5 B1048.2 y B1049.2 (misiones Starlink) |
| 9 | Fallos en dron ship durante 2015 | Enero (CRS-7) y Marzo (SES-9) – dos intentos fallidos emblemáticos |
| 10 | Ranking de outcomes de aterrizaje (2010-06-04 → 2017-03-20) | Success (drone ship): 14, Success (ground pad): 9, Failure: 7, etc. |
Parte 6: Visualización interactiva de sitios de lanzamiento con Folium
En esta fase del proyecto se implementó un análisis geoespacial interactivo utilizando la librería Folium, con el objetivo de explorar visualmente la ubicación estratégica de los sitios de lanzamiento de SpaceX y su relación con el éxito del aterrizaje de la primera etapa.
Tecnologías utilizadas
folium+ plugins:MarkerCluster,MousePosition,DivIcon- Cálculo de distancias geodésicas mediante la fórmula del haversine
- Visualización interactiva en mapa base OpenStreetMap
Tareas realizadas
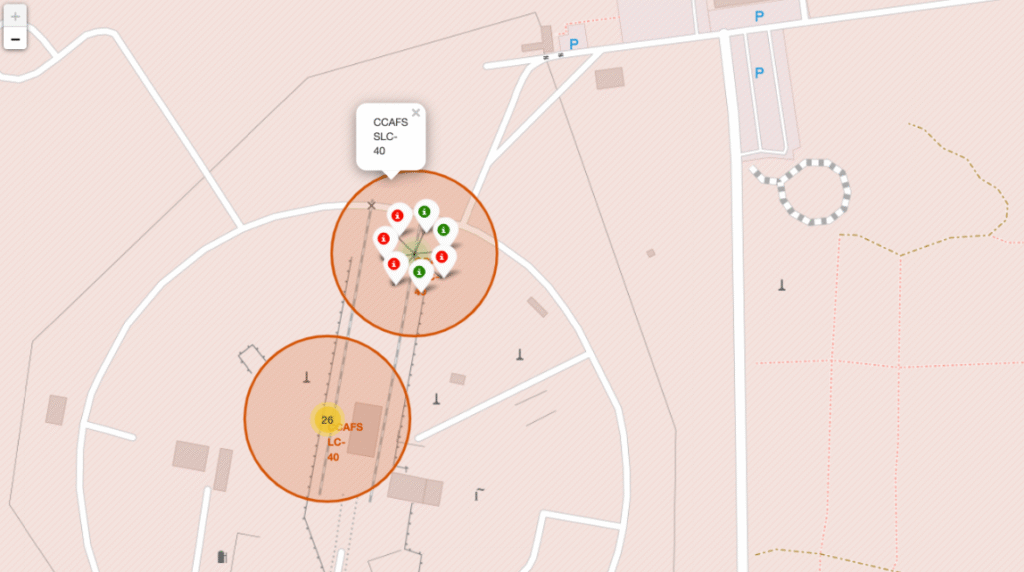
Marcado de los 4 sitios de lanzamiento activos de Falcon 9
- CCAFS LC-40
- CCAFS SLC-40
- KSC LC-39A (Kennedy Space Center)
- VAFB SLC-4E (Vandenberg, California)

Cálculo y representación de distancias a infraestructuras críticas
Visualización interactiva de éxitos y fallos por lanzamiento
- Se creó un
MarkerClusterque agrupa automáticamente los marcadores según el nivel de zoom. - Cada lanzamiento se representa con un marcador cuyo color indica el resultado:
- Verde →
Class = 1(aterrizaje exitoso) - Rojo →
Class = 0(fallo o misión expendable)
- Verde →
- Popup informativo con: sitio de lanzamiento y resultado.
Insights geoespaciales obtenidos
- Todos los sitios de lanzamiento están ubicados en la costa (Atlántico o Pacífico) → minimiza riesgo poblacional.
- Distancia a ciudades siempre superior a 40–50 km → protocolo de seguridad estándar.
- Proximidad a autopistas (<1 km) y vías férreas → optimización logística.
- VAFB SLC-4E (California) presenta 100 % de éxito en aterrizajes, parcialmente explicado por cargas más ligeras y menor densidad de tráfico aéreo.
Parte 7: Dashboard Interactivo con Plotly Dash
En la fase final del proyecto se desarrolló un dashboard web interactivo utilizando Plotly Dash, permitiendo a cualquier usuario (técnico o no técnico) explorar de forma dinámica los datos históricos de lanzamientos de SpaceX y los factores que influyen en el éxito del aterrizaje de la primera etapa.
Tecnologías utilizadas
- Dash (by Plotly) – Framework Python para aplicaciones web analíticas
- Plotly Express – Gráficos interactivos de alto nivel
- pandas – Manipulación de datos
- Despliegue local en
http://0.0.0.0:8050
Funcionalidades implementadas
- Dropdown de selección de sitio de lanzamiento
- Gráfico de tarta dinámico (Pie Chart)
- Range Slider de masa de carga útil (0 – 10 000 kg)
- Gráfico de dispersión interactivo (Scatter Plot)
Callbacks implementados
@app.callbackpara el gráfico de tarta → responde alsite-dropdown@app.callbackdoble entrada (site-dropdown+payload-slider) → actualiza el scatter en tiempo real
Parte Final: Modelado Predictivo y Selección del Mejor Algoritmo
En la fase culminante del proyecto se entrenaron y evaluaron cuatro algoritmos de clasificación supervisada para predecir si la primera etapa del Falcon 9 aterrizará con éxito (Class = 1) o no (Class = 0), utilizando el dataset completamente preprocesado (104 variables one-hot + numéricas estandarizadas).
Pipeline de Machine Learning implementado
- Estandarización de todas las variables con
StandardScaler - División train/test (80 % train – 20 % test,
random_state=2) - Búsqueda exhaustiva de hiperparámetros mediante
GridSearchCVcon 10-fold cross-validation - Evaluación final sobre el conjunto de prueba (18 muestras)
Modelos entrenados y resultados
| Modelo | Mejores hiperparámetros (GridSearchCV) | Accuracy Validación (CV) | Accuracy Test | Observaciones |
|---|---|---|---|---|
| Logistic Regression | C=0.01, penalty='l2', solver='lbfgs' | 84.64 % | 83.33 % | Muy estable, pocos falsos positivos |
| SVM | C=1.0, gamma=0.0316, kernel='sigmoid' | 84.82 % | 83.33 % | Rendimiento prácticamente idéntico a Regresión Logística |
| Decision Tree | criterion='gini', max_depth=6, max_features='sqrt', min_samples_leaf=4, splitter='random' | 88.93 % | 83.33 % | Mejor en validación (posible leve sobreajuste) |
| K-Nearest Neighbors | n_neighbors=10, algorithm='auto', p=1 (distancia Manhattan) | 84.82 % | 83.33 % | Robusto y consistente |
Resultado clave: Los cuatro modelos alcanzan 83.33 % de accuracy en el conjunto de prueba (15 aciertos de 18 muestras), lo que representa un rendimiento excelente considerando el reducido tamaño del dataset (90 observaciones totales).
Análisis de matrices de confusión
- Todos los modelos cometen 3 falsos positivos (predicen éxito cuando en realidad falló).
- Solo 0–1 falsos negativos → priorizan correctamente la seguridad (no decir que fallará cuando en realidad aterriza).
- El Decision Tree es el que mejor generaliza en validación, pero en test empata con los demás.
Conclusión final del proyecto
Se ha construido con éxito un sistema predictivo robusto capaz de estimar, con más del 83 % de precisión, si la primera etapa del Falcon 9 será recuperada en una misión futura, basándose únicamente en parámetros públicos conocidos antes del lanzamiento (sitio, órbita, masa de carga, versión del booster, etc.).

Este modelo tiene aplicaciones reales:
- Estimación de costes de lanzamiento (reutilizable vs. expendable)
- Optimización de contratos comerciales
- Apoyo en la toma de decisiones de clientes frente a competidores