Un informe de análisis de datos no es un artículo académico, ensayo ni informe de laboratorio. Es una conversación organizada con tu cliente o colaborador, con vida interna (memo extendido) y externa (para supervisores).
Características Clave
Fácil de ojear → Audiencias diferentes encuentran lo que necesitan rápido.
Redacción invisible → El lector recuerda el contenido, no el estilo.
Evita:
Prosa florída o demasiado casual.
Errores gramaticales.
Contexto inadecuado.
Enfocarse en proceso (salvo en apéndice).
Detalles técnicos innecesarios en el cuerpo.
Estructura Básica
Sección
Contenido esencial
Introducción
Resumen del estudio, datos, contexto, grandes preguntas, conclusiones clave y esquema del informe.
Cuerpo
Análisis principal con evidencia (tablas/gráficos).
Conclusión/Discusión
Repite preguntas + conclusiones. Añade observaciones y preguntas futuras.
Regla: Cuerpo → lo justo para convencer. Apéndice → todo lo necesario para validar.
Introducción: El Gancho Perfecto
Debe incluir (en este orden):
Resumen del estudio y datos.
Contexto o problema.
Grandes preguntas + conclusiones clave.
Esquema del informe.
Conclusión: Cierra con Impacto
Repite preguntas y respuestas.
Añade observaciones nuevas.
Propón preguntas futuras o próximos pasos.
Checklist Final antes de Entregar
[ ] ¿Es fácil ojear para ejecutivos?
[ ] ¿Tiene agenda clara para el cliente?
[ ] ¿Apéndice valida todo para el supervisor?
[ ] ¿Redacción limpia y sin distracciones?
[ ] ¿1–2 visuales por pregunta?
[ ] ¿Referencias cruzadas entre Cuerpo y Apéndice?
Conclusión: Un buen informe de datos no impresiona por su longitud. Impresiona porque tu cliente lo entiende, tu jefe lo aprueba y tu ejecutivo lo usa para decidir.
Estructura simple. Audiencia clara. Contenido que habla. Eso es todo.
La audiencia de un documento técnico es el lector o lectores previstos. Para los redactores técnicos, esta es la consideración clave al planificar, redactar y revisar. Se trata de adaptar la escritura a las necesidades, intereses y antecedentes del lector.
El principio es simple: habla para que te entiendan. No expliques cohetes a un niño de seis años. Parece obvio, pero la falta de análisis de audiencia es la raíz de la mayoría de los problemas en documentos técnicos, especialmente en instrucciones.
Herramientas Prácticas
Planificador de audiencias: Responde preguntas detalladas y envíatelo por email (opcional: a tu instructor).
Planificador de situaciones: Define el contexto en que tu audiencia usa el documento.
Tipos de Audiencias
Tipo
Descripción
Expertos
Conocen teoría y producto al detalle. Diseñan, prueban. Títulos avanzados. Desafío: comunicarse con técnicos y ejecutivos.
Técnicos
Construyen, operan, mantienen, reparan. Conocimiento práctico y técnico.
Ejecutivos
Toman decisiones comerciales, legales, políticas. Poco conocimiento técnico. Deciden si producir, implementar, financiar.
No especialistas
Mínimo conocimiento técnico. Interés práctico o curiosidad. Ej: votar en elecciones, aprender sin motivo específico.
Ejemplo: Guía de software en Windows → ¿incluyes basics de Windows?
No: Frustra al usuario.
Sí: Aumenta páginas y costo. → Equilibra según el tamaño del segmento que lo necesita.
Necesidades e intereses
¿Qué esperan del documento?
Ej: Manual de smartphone → pasos claros.
Informe de calentamiento global para inmobiliarios → ¿qué quieren (y no quieren) leer?
Diferentes culturas
Formatos de fecha, hora, moneda varían.
Evita humor local (“dar un jonrón”). → Recursos:
Capítulo 6: Escritura para lectores internacionales (Texas A&M).
Lista de guías de estilo en Wikipedia.
Otras características demográficas
Edad, género, residencia, preferencias políticas, etc.
Complicaciones Comunes
Audiencias mixtas: Técnicos + ejecutivos →
Opción 1: Todo comprensible para todos (difícil).
Opción 2: Secciones por audiencia + títulos claros para navegar.
Variabilidad amplia: En una misma categoría →
Escribir al mínimo común denominador → documento tedioso.
Solución:
Apuntar a la mayoría.
Info extra en apéndices o referencias cruzadas.
Ejemplo de Descripción de Audiencia (para curso)
Nota al instructor: Instrucciones para usuarios que optimizan cálculos en Excel con macros. Saben ingresar datos, usan Office Suite, están cómodos con Windows y aritmética básica para verificar errores.
Adaptación Práctica: 16 Controles para Conectar con tu Audiencia
(Enfocados en no especialistas, pero aplicables a todos)
Añade info clave → pasos, antecedentes, definiciones.
Omite lo innecesario → evita confusión.
Ajusta nivel técnico → no hables a expertos si tu lector es técnico.
Incluye ejemplos → analogías potentes.
Adapta ejemplos → caseros para no expertos, técnicos para especialistas.
En un análisis estadístico, normalmente se comienza considerando las características de la población sobre la cual se quieren hacer inferencias. De manera similar, cuando comienzas a escribir un informe sobre un análisis, generalmente comienzas considerando las características de la audiencia con la que deseas comunicarte.
Debes pensar en el quién, qué, por qué, dónde, cuándo y cómo de las personas clave que leerán tu informe.
¿Quién leerá tu informe?
La audiencia a menudo se define por el rol que desempeña el lector en relación con el informe:
Tomadores de decisiones: Usarán el informe para actuar.
Partes interesadas: Aprenderán nueva información.
Revisores: Lo criticarán en base a lo que ya saben.
Interesados generales: Buscan contexto o inspiración.
Algunos informes son leídos por una sola persona, pero la mayoría por muchas. Pueden existir niveles de participación: primarios, secundarios y terciarios.
Consejo clave:
No puedes complacer a todos. Concéntrate primero en las personas más importantes para recibir tu mensaje, y en segundo lugar en el grupo más amplio.
¿Qué saben tus lectores?
Una vez definido a quién te diriges, comprende sus características. La más importante para un redactor técnico es su nivel de comprensión del tema y de las técnicas estadísticas.
Puedes ajustar cómo presentas la información estadística. Aquí tienes un mapa de audiencias comunes:
Tipo de lector
Características
Recomendaciones
Matefobias
Temen a los números, pero escuchan conceptos
Evita jerga, fórmulas y porcentajes. Usa “aproximadamente la mitad” en lugar de “48.7%”.
Pasantes
Entienden poco y tienen bajo interés
No te preocupes: no leerán más allá del resumen. Hazlo conciso y resalta el hallazgo clave.
Turistas
Entienden algo y están interesados
Sé amable. Usa jerga solo si la defines. Prefiere gráficos simples (barras, circulares). Redondea valores.
Perros calientes
Creen saber más de lo que saben
Usa jerga y fórmulas, pero explícalas claramente. Guíalos para evitar conclusiones erróneas.
Asociados
Otros analistas con jerga básica
Todo vale si lo explicas bien.
Colegas
Expertos en el tema y técnicas
Todo vale. Sé técnico, preciso y directo.
Estas características te orientan sobre la extensión, tono y estilo del informe.
¿Por qué leerán tu informe?
Sé honesto:
¿Por qué alguien estaría interesado en leer tu informe?
Pregúntate:
¿Qué harán con tus hallazgos?
¿Se informarán? ¿Tomarán decisiones? ¿Actuarán?
¿Es algo crítico para ellos o solo un trámite?
El nivel de interés define cuánto esfuerzo debes invertir en hacerlo claro, atractivo y accionable.
¿Dónde se leerá tu informe?
Considera el alcance y contexto:
¿Es para un grupo interno (organización) o público general?
¿Va dirigido a la alta dirección (de arriba hacia abajo) o a equipos operativos (de abajo hacia arriba)?
¿Hay preocupaciones de seguridad o confidencialidad?
Esto afecta el lenguaje, el nivel de detalle y las medidas de protección (contraseñas, marcas de agua, etc.).
¿Cuándo lo necesitan?
El tiempo es un factor crítico:
¿Cuándo debe estar listo?
¿Quién lo revisará y cuánto tardará?
¿Los plazos son flexibles o inamovibles?
¿Tienes tiempo para:
Pensar el mensaje?
Hacer análisis adicionales?
Editar y pulir?
Regla de oro (que todos rompemos, pero no deberíamos):Nunca envíes un borrador para revisión que no sea tu obra maestra completa y editada.
¿Cómo debe presentarse el informe?
Finalmente, piensa en cómo maximizar el impacto para tu audiencia. Aquí van cinco consideraciones clave:
¿Entregarás datos, scripts, código o resultados adicionales?
¿Crearás una presentación?
¿Se usarán tus gráficos en tribunales o eventos públicos?
5. Accesibilidad
¿Debes cumplir con la Sección 508 (EE.UU.) para accesibilidad?
¿Tus gráficos son legibles para personas con daltonismo?
¿Usas títulos claros, tablas bien etiquetadas, alt text en imágenes?
Conclusión:
No necesitas responder todas estas preguntas en detalle. Muchas solo requieren unos segundos de reflexión. Pero si analizas estas dimensiones —quién, qué, por qué, dónde, cuándo y cómo— tendrás una idea mucho más clara de para quién escribes Y cómo debes escribirlo
El backsolving es un método para resolver sistemas de ecuaciones lineales una vez que ya hemos reducido el sistema a forma triangular superior mediante eliminación gaussiana (o cualquier otra técnica de factorización como LU).
Trabajamos el mismo problema del articulo anterior:
Queremos resolver los precios \( (p) \) de cada producto. En este caso utilizaremos eliminación gaussiana y luego sustitución hacia atrás — eso es, reducir el sistema a triangular superior y luego encontrar las incógnitas empezando por la última.
Eliminación gaussiana (reducción hacia triangular superior)
Escribimos el sistema en sus ecuaciones explícitas (producto fila por columna):
Sustituyendo el valor numérico de \(p_3\) (o directamente resolviendo con las fracciones) se obtiene \(p_2=3\).
Finalmente sustituimos \(p_2\) y \(p_3\) en la primera ecuación para obtener (p_1), que da (p_1=2).
Conclusión del método manual (eliminación + sustitución):
$$\mathbf p = \begin{pmatrix}2 \\ 3 \\ 5\end{pmatrix}$$
¿Qué significa calcular la inversa \(M^{-1}\) y cómo se obtiene con matriz aumentada?
Otra forma más “directa” (y que explica el porqué de la eliminación) es calcular la inversa de \(M\). Si \(M\) es invertible entonces
$$\mathbf p = M^{-1}\mathbf c$$
Para encontrar \(M^{-1}\) se construye la matriz aumentada \([,M \mid I,]\) y se aplican operaciones elementales por filas hasta transformar el lado izquierdo en la identidad; entonces el lado derecho habrá quedado como \(M^{-1}\).
Verificaciones numéricas y redondeo
En la práctica, cuando calculas \(M^{-1}M\) en ordenador verás que los elementos fuera de la diagonal no son exactamente cero sino números muy pequeños (por ejemplo \(-5\times 10^{-17})\). Eso es error numérico de punto flotante. Si redondeas (por ejemplo a 10 decimales) obtendrás la matriz identidad exacta en la presentación.
Resumen conceptual
Eliminación gaussiana: reduce el sistema a triangular superior (eliminación hacia adelante) y luego despeja las variables (sustitución hacia atrás).
Inversa por matriz aumentada: hacer operaciones elementales sobre \([M\mid I]\) hasta convertir \(M\) en \(I\); lo que quede a la derecha será \(M^{-1}\).
Comprobación: puedes verificar que \(M^{-1}\mathbf c = \mathbf p\) y \(M^{-1}M = I\) (hasta errores numéricos muy pequeños).
Código Python
import numpy as np# Definición de la matriz y vectores (el sistema del ejemplo)M = np.array([[3, 6, 2], [10, 3, 8], [1, 7, 5]], dtype=float)c = np.array([34, 69, 48], dtype=float)# 1) Resolver el sistema M p = cp = np.linalg.solve(M, c)print("Solución (np.linalg.solve):", p)# 2) Calcular la inversa de MM_inv = np.linalg.inv(M)print("\nInversa M^{-1}:\n", M_inv)# 3) Verificar que M^{-1} * c = pp_from_inv = M_inv @ cprint("\nM^{-1} @ c =", p_from_inv)# 4) Verificar que M_inv @ M ≈ I (mostramos la matriz y una versión redondeada)I_approx = M_inv @ Mprint("\nM^{-1} @ M (aprox):\n", I_approx)print("\nM^{-1} @ M (redondeado a 10 decimales):\n", np.round(I_approx, 10))
M_inv @ c debe coincidir con p (igual numéricamente, dentro de tolerancias de punto flotante).
M_inv @ M será numéricamente la identidad; si ves valores muy pequeños fuera de la diagonal, es normal: redondea para comprobar que esos valores son efectivamente cero dentro de la precisión de la máquina.
Resumen
La eliminación y la inversa son dos caras de la misma moneda: la primera resuelve un sistema concreto, la segunda construye la “función inversa” que, aplicada a cualquier vector de costes, devolvería los precios.
En aplicaciones (ciencia de datos, econometría, ingeniería), normalmente no calculamos la inversa si solo queremos resolver un sistema: usamos solve (algoritmos de factorización) por razones de estabilidad numérica y eficiencia. Sin embargo, obtener la inversa es útil para entender conceptualmente la transformada inversa y para comprobaciones.
En artículos anteriores vimos operaciones sobre vectores y matrices desde la perspectiva matemática. Vamos a ver cómo esas mismas operaciones pueden resolver problemas reales, como descubrir cuánto cuesta cada producto de un supermercado.
Escenario
Volvemos a nuestro supermercado de frutas. Imaginemos que tenemos tres personas: Bob, Alice y Tim, que han ido al supermercado y compraron manzanas, naranjas y peras. Podemos representar sus compras en una matriz \(M\):
Matriz de coeficientes: contiene los números que multiplican a las variables (las cantidades de las frutas).
Vector de incógnitas: las variables que queremos encontrar (precio de las frutas).
Vector de resultados: los valores en el lado derecho (total de dinero gastado).
Solución
Método de eliminación (Gauss, eliminación hacia adelante con sustitución). Se despeja una variable y se sustituye, reduciendo gradualmente el sistema hasta obtener cada variable.
Este código usa numpy.linalg.solve, que aplica internamente eliminación de Gauss con pivotado, y es la forma más eficiente y segura de resolver sistemas lineales \(\)A \cdot x = b en Python.
import numpy as np# Matriz de coeficientesA = np.array([ [3, 6, 2], [10, 3, 8], [1, 7, 5]], dtype=float)# Vector de resultadosb = np.array([34, 69, 48], dtype=float)# Resolver el sistema A·x = bsol = np.linalg.solve(A, b)# Mostrar resultadosp1, p2, p3 = solprint(f"p1 = {p1:.2f}, p2 = {p2:.2f}, p3 = {p3:.2f}")
En el artículo anterior se trabajo los autovalores y autovectores, es común quedarse con la sensación de que son conceptos abstractos. Pero en realidad, están detrás de muchas de las herramientas más potentes del análisis de datos moderno.
Una de ellas es el Análisis de Componentes Principales (PCA), una técnica que permite comprimir información sin perder lo esencial.
En este artículo veremos cómo los eigenvectores sirven para reducir la dimensionalidad de los datos, y cómo este principio se aplica a algo tan visual como la compresión de imágenes de rostros humanos.
Cuando trabajamos con datos reales —imágenes, audio, sensores o registros de clientes— solemos tener miles de variables. Eso significa que el procesamiento se vuelve lento, costoso y muchas veces innecesario, porque buena parte de los datos son redundantes.
El PCA (Principal Component Analysis) se basa precisamente en encontrar las direcciones de mayor variabilidad dentro de los datos. Y esas direcciones no son otras que los autovectores de la matriz de covarianza del conjunto.
Visualizando el concepto con una imagen
Una imagen digital no es más que una matriz de números, donde cada valor representa la intensidad del color (por ejemplo, del blanco al negro si es en escala de grises).
Para este ejemplo usaremos el famoso dataset de rostros de celebridades incluido en scikit-learn.
from sklearn.datasets import fetch_lfw_peopleimport matplotlib.pyplot as plt# Cargamos el dataset de carasfaces = fetch_lfw_people(min_faces_per_person=60)image = faces.images[0]plt.imshow(image, cmap='bone')plt.title(f"Ejemplo de imagen: {faces.target_names[0]}")plt.axis('off')plt.show()
Cada imagen tiene 62 filas × 47 columnas, es decir, 2.914 píxeles o variables. PCA nos permitirá representar esta misma información con muchas menos variables.
Aplicando PCA paso a paso
PCA consiste básicamente en tres fases:
Calcular la matriz de covarianza del conjunto de datos.
Obtener sus autovectores y autovalores.
Proyectar los datos sobre las direcciones asociadas a los autovalores más grandes, que contienen la mayor parte de la varianza.
En código, podemos hacerlo así:
from sklearn.decomposition import PCAimport numpy as np# Aplanamos las imágenes 2D a vectores 1DX = faces.data# Aplicamos PCA para conservar solo 15 componentes principalespca = PCA(n_components=15)X_pca = pca.fit_transform(X)# Reconstruimos las imágenes desde los componentes principalesX_reconstructed = pca.inverse_transform(X_pca)# Mostramos la imagen original y la reconstruidafig, axes = plt.subplots(1, 2, figsize=(8, 4))axes[0].imshow(X[0].reshape(62, 47), cmap='bone')axes[0].set_title("Imagen original")axes[0].axis('off')axes[1].imshow(X_reconstructed[0].reshape(62, 47), cmap='bone')axes[1].set_title("Reconstruida (15 componentes)")axes[1].axis('off')plt.show()
¿Qué estamos haciendo en realidad?
Cada componente principal es un autovector de la matriz de covarianza. Cada uno representa una dirección en el espacio de datos donde la información cambia más. Los autovalores indican cuánta “varianza” explica cada componente.
En este caso, al reconstruir la imagen con solo 15 componentes, vemos una versión algo borrosa, pero perfectamente reconocible. Hemos pasado de 2.914 variables a solo 15, manteniendo casi toda la información útil.
Si reducimos a 5 componentes, la imagen pierde detalle; si aumentamos a 50, se ve casi igual que la original. Todo depende del equilibrio que queramos entre tamaño y fidelidad.
Las “eigenfaces”
Una de las formas más visuales de entender PCA en imágenes es observar los autovectores directamente. En este caso se les conoce como eigenfaces, o “caras propias”.
Cada eigenface representa un patrón característico: sombras de ojos, contorno del rostro, luz lateral, expresión, etc.
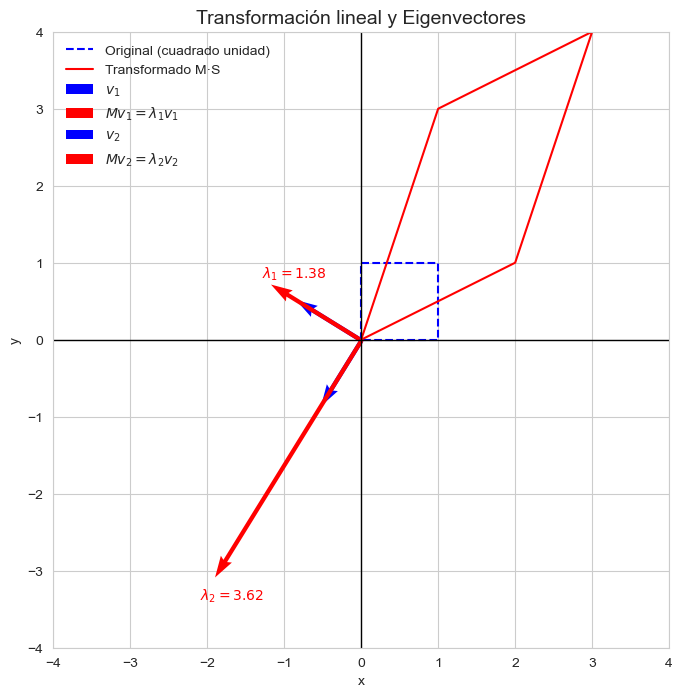
Verás que, aunque una transformación lineal cambia la dirección de la mayoría de los vectores, existen algunos vectores especiales que no rotan, solo se estiran o encogen. Esos vectores son los autovectores (eigenvector), y la cantidad por la que se estiran o encogen se llama autovalor (eigenvalues).
Intuición: vectores que no cambian de dirección
Imagina una matriz que representa una transformación lineal —por ejemplo, una matriz de “shear” (cizallamiento), que deforma un cuadrado en un paralelogramo. En la mayoría de los casos, todos los vectores cambian de dirección al aplicar la transformación… excepto algunos muy particulares. Esos vectores especiales mantienen su dirección (aunque pueden cambiar su longitud). Por eso decimos que son autovectores.
Un vector \( \vec{v} \) es un autovector de una matriz \( M \) si, al aplicar la matriz transformadora sobre él, el resultado es el mismo vector escalado por un número \( \lambda \):
$$M \vec{v} = \lambda \vec{v}$$
Donde:
\( M \) → es una matriz cuadrada \(n \times n\)
\( \vec{v} \) → es un autovector
\( \lambda \) → es el autovalor asociado
Este número \( \lambda \) indica cuánto se estira o encoge el vector cuando la matriz actúa sobre él.
Interpretación geométrica
Si \( \lambda > 1 \): el vector se alarga.
Si \( 0 < \lambda < 1 \): el vector se encoge.
Si \( \lambda < 0 \): el vector cambia de sentido (se invierte).
Si \( \lambda = 1 \): el vector queda igual.
Calculando los eigenvectors y eigenvalues
Continuamos con el ejemplo inicial:
import numpy as np# Calcular eigenvalores y eigenvectoresw, V = np.linalg.eig(M)print("\nEigenvalores:\n", w)print("\nEigenvectores (columnas):\n", V)
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))# Cuadrado original (azul) y transformado (rojo)ax.plot(square[0], square[1], 'b--', label='Original (cuadrado unidad)')ax.plot(transformed[0], transformed[1], 'r-', label='Transformado M·S')# Ejesax.axhline(0, color='black', linewidth=1)ax.axvline(0, color='black', linewidth=1)# Eigenvectoresfor i inrange(len(w)): v = V[:, i] # vector propio Mv = M @ v # su transformación λ = w[i]# Dibuja el eigenvector (azul) ax.quiver(0, 0, v[0], v[1], angles='xy', scale_units='xy', scale=1,color='blue', width=0.007, label=fr'$v_{i+1}$')# Dibuja el vector transformado (rojo) ax.quiver(0, 0, Mv[0], Mv[1], angles='xy', scale_units='xy', scale=1,color='red', width=0.007, label=fr'$M v_{i+1} = \lambda_{i+1} v_{i+1}$')# Muestra texto con el eigenvalor ax.text(Mv[0]*1.1, Mv[1]*1.1, fr'$\lambda_{i+1}={λ:.2f}$', color='red', fontsize=10)ax.set_xlim(-4, 4)ax.set_ylim(-4, 4)ax.set_aspect('equal', adjustable='box')ax.legend(loc='upper left', facecolor='none', edgecolor='none')ax.set_title("Transformación lineal y Eigenvectores", fontsize=14)ax.set_xlabel("x")ax.set_ylabel("y")plt.grid(True)plt.show()
Matrices simétricas
Cuando una matriz es simétrica (es decir, \( M = M^T \)), se cumple algo muy útil:
Todos sus autovectores son perpendiculares entre sí.
Sus autovalores son reales.
Por ejemplo:
A = np.array([[4, 1], [1, 4]])autovalores, autovectores = np.linalg.eig(A)print("Autovalores:", autovalores)print("Autovectores:\n", autovectores)print("Producto punto entre los autovectores:", np.dot(autovectores[:,0], autovectores[:,1]))
La salida mostrará que el producto punto es 0, confirmando que los autovectores son ortogonales.
Autovalores: [5. 3.]Autovectores: [[ 0.70710678 -0.70710678] [ 0.70710678 0.70710678]]Producto punto entre los autovectores: 0.0
Aplicaciones en ciencia de datos
Los eigenvectores y eigenvalores son fundamentales en data science:
Análisis de Componentes Principales (PCA)
Qué hace: Reduce dimensiones de un dataset encontrando los eigenvectores de la matriz de covarianza.
Ejemplo: Dataset Iris (150×4) → eigenvectores indican las direcciones de mayor variación (ej: longitud vs ancho de pétalo).
Redes Neuronales
Eigenvectores optimizan transformaciones en capas de redes profundas.
Ejemplo: Ajustar pesos para maximizar patrones.
Procesamiento de Imágenes
Eigenvectores en eigenfaces identifican características faciales clave.
Ejemplo: Reconocimiento facial en apps de seguridad.
Sistemas Dinámicos
Modelan cómo cambian datos con el tiempo (ej: predicciones financieras).
Eigenvalores determinan la estabilidad de los sistemas.
Historia real: En 2024, Spotify usó eigenvectores en su sistema de recomendaciones para identificar patrones en gustos musicales, mejorando la precisión en un 10%.
Cómo encontrar los Eigenvalues y Eigenvectors
Para cualquier matriz \(M\):
Primero encontramos todos los eigenvalores λ.
Luego, usando esos eigenvalores, encontramos los eigenvectores correspondientes.
La ecuación base \(M \vec{v} = \lambda \cdot \vec{v}\) será la clave de todo.
Pero para trabajar con ella algebraicamente, vamos a transformarla un poco.
La matriz identidad
Necesitamos la matriz especial llamada la matriz identidad, que se denota por \(I\). La matriz identidad es una matriz cuadrada con unos en la diagonal principal (de arriba a la izquierda hasta abajo a la derecha) y ceros en todas las demás posiciones. Ya la vimos como ejemplo anteriormente en el articulo de las matrices.
Por ejemplo, la matriz identidad de tamaño 3×3 es:
Sacamos vvv como factor común (como si fuera un número):
$$(M \ – \lambda I) \cdot \vec{v} = 0 $$
Y esta ecuación es fundamental: se conoce como la ecuación característica.
La condición de existencia de eigenvectores
Esta ecuación tiene dos tipos de soluciones posibles:
La trivial, cuando \(v=0\). Pero ese vector no nos dice nada (no tiene dirección ni longitud), así que lo descartamos.
La no trivial, cuando \(v≠0\). Para que exista esta solución, debe cumplirse una condición especial.
Recuerda una propiedad del álgebra lineal:
Una ecuación de la forma \(A \cdot v=0\) solo tiene una solución no trivial \(v≠0\) si la matriz A es singular, es decir, su determinante es igual a cero.
Aplicando esto a nuestra ecuación \((M \ – \lambda I) \cdot \vec{v} = 0 \), la condición será: \(det(M \ – \lambda I) \cdot \vec{v} = 0 \)
Esta ecuación nos permitirá encontrar los valores de \( \lambda \), los eigenvalores.
Interpretación geométrica: el área que se hace cero
Detrás de todo esto hay una idea visual muy poderosa.
Imagina que tienes una matriz \(M\) que transforma puntos del plano \(XY\). Puedes representarla como una transformación del cuadrado unitario (un cuadrado de lado 1 anclado en el origen).
Cuando multiplicas \(M\) por las coordenadas de los vértices de ese cuadrado, obtienes un nuevo cuadrilátero. En general, este nuevo cuadrilátero es un paralelogramo.
Si \(M\) solo escala el cuadrado, obtienes un rectángulo.
Si además deforma el cuadrado (por ejemplo, en un cizallamiento), obtienes un paralelogramo inclinado.
El área de ese paralelogramo es una medida de cuánto “estira” o “encoge” la transformación de \(M\). Y el determinante de la matriz está directamente relacionado con esa área.
Cuando el determinante es cero, significa que la transformación ha colapsado el plano en una línea o un punto, es decir, ha perdido una dimensión. Eso ocurre exactamente cuando estamos en un eigenvalor, porque en ese caso el espacio queda “aplastado” en una dirección particular: la del eigenvector.
Ejemplo visual con una matriz 2×2
Imaginemos una matriz genérica \(M\) de 2×2:
$$M = \begin{bmatrix} a & b \\ c & d \end{bmatrix}$$
Y tomemos el cuadrado unitario cuyos vértices son (0,0), (1,0), (1,1) y (0,1).
Cuando aplicamos \(M\) sobre esos puntos, el cuadrado se transforma en un paralelogramo cuyos vértices vienen dados por los productos matriciales:
$$M \cdot S$$
donde \(S\) contiene las coordenadas de los vértices del cuadrado. El área de ese nuevo paralelogramo se puede calcular directamente como:
$$\text{Área} = ad – bc$$
que es precisamente el determinante de \(M\).
Así que cuando el determinante \(ad−bc=0\), el paralelogramo “se aplasta” y pierde área. Geométricamente, eso es lo que ocurre cuando hay un eigenvalor: la transformación ya no conserva el área y “colapsa” el espacio en una dirección.
Si los vectores son puntos en un mapa, las matrices son el mapa completo: Una matriz es una cuadrícula de números organizada en filas y columnas. Puedes pensarla como un conjunto de vectores fila o vectores columna, dependiendo del caso.
Matemáticamente, se escribe como un conjunto rectangular de números:
Aquí la matriz \(A\) tiene 3 filas y 3 columnas, por lo tanto, su dimensión es \(3 \times 3\). Cada número dentro de la matriz se llama elemento, y se identifica por su posición: \(a_{ij}\) es el elemento que está en la fila i y la columna j.
Filas: 3 (cada una es un vector: \( [1, 2, 3], [4, 5, 6], [7, 8, 9]\))
Columnas: 3 (cada una es un vector: \([1, 4, 7], [2, 5, 8], [3, 6, 9]\))
Propiedad .shape: conocer las dimensiones de la matriz
print(A.shape)
(3, 4)
Indexación: acceder a elementos, fila y columnas
M = np.array([[1, 2, 3], [4, 5, 6] [7, 8, 9]])valor = M[4, 5] # valor en la fila 5, columna 6 (Python indexa desde 0)fila = M[1, :] # acceder a una fila completacolumna = M[:, 2] # acceder a una columna completaprint(valor)print(fila)print(columna)
6[4 5 6][3 6 9]
Suma y resta de matrices
C = A + BD = B - A
Multiplicación por escalar
E = 3 * A
Producto de matrices
C = A @ B# tambien se puede usar:np.dot(A, B)
Transpuesta de una matriz
print("A^T =\n", A.T)
Matriz identidad
I = np.eye(2)print("Matriz identidad:\n", I)print("A @ I =\n", A @ I)
Determinante y matriz inversa
det_A = np.linalg.det(A)inv_A = np.linalg.inv(A)
6. En resumen
Las matrices son la base del álgebra lineal y de los modelos de datos.
En Machine Learning, cada conjunto de entrenamiento es una gran matriz.
En visión por computador, las imágenes son matrices.
En análisis estadístico, las transformaciones de los datos se hacen con multiplicaciones matriciales.
Por eso, entender cómo funcionan es esencial: todo modelo, por complejo que parezca, se reduce a operaciones con vectores y matrices.
Imagina que los datos son como puntos en un mapa. Un vector es la flecha que describe dónde está ese punto y cómo llegar a él. En data science, los vectores son la forma más básica y poderosa de representar datos, desde características de un cliente hasta píxeles en una imagen.
El vector es el elemento fundamental y raíz de toda el algebra lineal.
Los vectores no son solo un concepto matemático para escribir ecuaciones de forma concisa. También son herramientas fundamentales para codificar información compleja, desde posiciones y velocidades hasta fuerzas y movimientos en varias dimensiones.
¿Qué es un vector?
Más allá de ser una lista ordenada de números, un vector puede pensarse como: cualquier cosa que tenga una dirección y una magnitud.
Es una lista ordenada de números que describe una posición o característica en un espacio. En data science, cada vector representa un punto de datos y cada fila de tu dataset es un vector.
Esta definición es la que usan los físicos. Por ejemplo:
Dirección: hacia dónde apunta el vector.
Magnitud: qué tan grande es, también llamada norma del vector.
Ejemplos
Supongamos que describes a una persona por su edad y salario:
Vector: \([25, 50000]\)
25: Edad (en años)
50000: Salario (en euros)
Visualmente:
Un vector es una flecha en un plano:
Origen: \((0,0)\)
Punta: \((25, 50000)\)
En 2D, se ve como una línea desde el origen al punto.
Dimensiones
2D: \([x, y]\) (ej: edad, salario)
3D: \([x, y, z]\) (ej: edad, salario, experiencia)
n-D: \([x₁, x₂, …, xₙ]\) (datasets con muchas columnas)
De la Ecuación al Movimiento
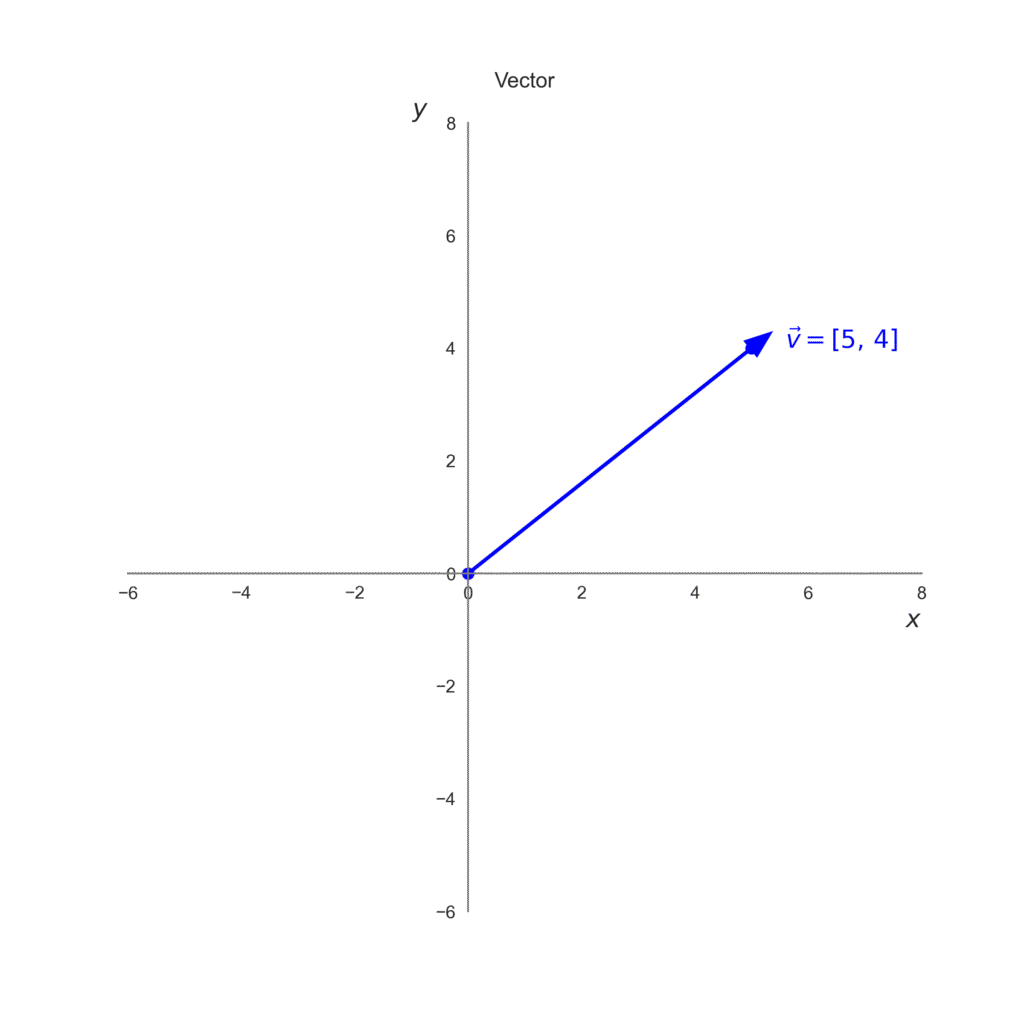
Imaginemos una pelota lanzada desde el origen que en términos de vectores seria la posición \((0,0)\) en un espacio bidimensional. La posición de la pelota en cada instante se puede codificar como un vector \( \mathbf{p} = (p_1, p_2) \), donde:
\(p_1 = 5\) representa la posición horizontal \(x\)
\(p_2 = 4\) representa la posición vertical \(y\).
Así, en lugar de seguir las coordenadas de los ejes por separado, podemos usar un solo vector para describir la posición de la pelota.
$$ \vec{p} = \begin{bmatrix}5\\4\end{bmatrix}$$
Si representamos \(\vec{p}\) en un plano cartesiano, se vería como una flecha que parte del origen (0,0) y termina en (5,4). La flecha tiene una dirección (hacia dónde apunta) y una longitud, que nos dice qué tan lejos está el punto final del origen. Para graficar podemos utilizar ax.arrow() en Matplotlib.
Código de la grafica
Código en Python Matplotlib
import matplotlib.pyplot as plt# Crear figura y ejesfig, ax = plt.subplots(figsize=(8, 8))# Dibujar el vector desde (0,0) hasta (5,4)ax.arrow(0, 0, 5, 4, head_width=0.3, head_length=0.4, fc='blue', ec='blue', linewidth=2)# Marcar el punto final del vectorax.plot(5, 4, 'o', markersize=6, color='blue')ax.plot(0, 0, 'o', markersize=6, color='blue')ax.text(5.6, 4, r"$\vec{v} = [5,\, 4]$", fontsize=14, color='blue')# Ejes centradosax.spines['left'].set_position('zero')ax.spines['bottom'].set_position('zero')# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Color y grosor de los ejesfor spine in ['left', 'bottom']: ax.spines[spine].set_color('gray') ax.spines[spine].set_linewidth(1)# Límites y cuadrículaax.set_xlim(-6, 8)ax.set_ylim(-6, 8)ax.grid(False)# Tamaño de los números de los ejesax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y títuloax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.set_title("Vector", pad=20)# Guardar y mostrarplt.savefig("vector.png", transparent=True, dpi=300)plt.show()
La norma (longitud del vector): cuánto ha viajado la pelota
Esa longitud, también llamada norma, nos dice qué tan grande es el vector. Se denota con dos barras verticales, así: \( ||\mathbf{p}|| \) Para saber qué tan lejos está la pelota desde el origen, usamos la norma del vector:
$$||\mathbf{p}|| = \sqrt{p_1^2 + p_2^2}$$
Esta ecuación se deriva directamente del teorema de Pitágoras: la hipotenusa de un triángulo rectángulo es la raíz cuadrada de la suma de los cuadrados de sus catetos. Por ejemplo, si \(p_1 = 5\) y \(p_2 = 4\), la norma es:
Esto hace que los vectores sean muy poderosos para manejar información compleja de manera compacta.
Aplicaciones de los vectores en física
Los vectores nos permiten representar de manera eficiente:
Posición: dónde se encuentra un objeto.
Velocidad: dirección y rapidez del movimiento.
Fuerza: hacia dónde actúa y cuán intensa es.
Además, con operaciones como suma, resta, multiplicación por escalar o producto punto, podemos combinar vectores y calcular efectos resultantes de manera simple.
Por ejemplo, en nuestra pelota de béisbol, un vector nos permite:
Conocer simultáneamente su posición en \(x\) y \( y\) ,
Medir su distancia desde el punto de lanzamiento con la norma,
Y si quisiéramos incluir velocidad o aceleración, usar vectores de mayor dimensión para mantener todo compacto y manejable.
Dos propiedades clave de un vector
Dirección: hacia dónde apunta.
Magnitud: cuán grande es, calculable con la norma.
En cualquier número de dimensiones, esta regla sigue siendo válida, lo que convierte a los vectores en herramientas universales para describir información física y multidimensional.
Operaciones con Vectores
Los vectores son poderosos porque puedes operarlos para descubrir patrones. Aquí las operaciones más importantes:
Esto es útil porque cuando sumamos vectores estamos combinando información de manera ordenada, igual que antes combinábamos cantidades de manzanas, naranjas y pan. La suma de vectores es la primera forma de “agrupar información” en un vector.
Multiplicación por Escalar
Si tenemos un número \(k\) y un vector \(\vec{v}\), multiplicamos cada componente por ese número:
$$ k \cdot \vec{v}= k \cdot \begin{bmatrix}v_1\\v_2\\v_3\end{bmatrix} = \begin{bmatrix}kv_1\\kv_2\\kv_3\end{bmatrix}$$
Esto sirve para escalar vectores, como cuando queremos “duplicar” o “reducir” una cantidad.
Producto Escalar (Dot Product)
Dot Product: Mide la similitud entre dos vectores.
El producto escalar es una operación entre dos vectores que produce un número, a diferencia de la suma o resta de vectores, que produce otro vector.
Si \(θ=0°\): los vectores están en la misma dirección → producto punto positivo y máximo.
Si \(θ=90°\): son perpendiculares → producto punto = 0.
Si \(θ>90°\): apuntan en direcciones opuestas → producto punto negativo.
Esto significa que el producto punto mide cuánto “apuntan en la misma dirección” dos vectores.
Usos del producto escalar el data science
Similitud de vectores (cosine similarity): En NLP, sistemas de recomendación o embeddings de palabras. Cuanto mayor sea este valor, más similares son los vectores.
Regresión lineal / Neuronas : Calcula la combinación lineal de las variables
Similitud del coseno : Mide cuánto se parecen dos vectores
PCA / Proyecciones : Proyecta un vector sobre una dirección
Distancias : Base para métricas vectoriales
Álgebra de matrices : Operación elemental en multiplicación de matrices
Operaciones de vectores con Python
Los vectores en Python manejan con Numpy y se representan como listas:
¿Por Qué las Ecuaciones Lineales Son Clave en Data Science?
Las ecuaciones lineales y los sistemas lineales son como el esqueleto de la data science. Son la base de algoritmos como la regresión lineal, los sistemas de recomendación y el análisis de datos en general. Imagina que cada punto de datos es una pieza de un rompecabezas: las ecuaciones lineales te ayudan a juntar las piezas para descubrir patrones.
«Sin ecuaciones lineales, no habría machine learning moderno. Son el primer paso para transformar datos en decisiones.»
¿Qué es una Ecuación Lineal?
Una ecuación lineal es una ecuación donde las variables están elevadas a la potencia 1 y multiplicadas por un coeficiente (no hay cuadrados ni raíces) y se combinan con sumas o restas.
Ejemplo Simple
$$3x + 2y = 30$$
Como concepto esta bien. ¿pero cual es el sentido de esto? ¿de donde sale? La idea base de la ecuación lineal es una relación constante entre dos cosas. La ecuación lineal nace cuando dos magnitudes cambian de forma proporcional.
Por ejemplo:
Si vendes café a 2€ cada uno, el ingreso total depende linealmente del numero de cafés vendidos.
$$Ingreso = 2 \times \text{Número de cafés}$$
Esto puede escribirse matemáticamente como
$$y = 2x$$
Donde:
x, y: Variables (Ingreso, Café.)
2: Coeficientes (pesos de las variables)
Esa es una relación lineal: cada vez que \(x\) aumenta 1, \(y\) aumenta 2. La tasa de cambio es constante. Visualmente esta ecuación representa una línea recta en un plano. Cada solución \((x, y)\) es un punto en esa línea.
De ahí el nombre de lineal, porque describe una relación que se representa como una línea recta en un gráfico. Las ecuaciones lineales modelan situaciones donde:
el cambio es constante,
la relación entre variables es directa o proporcional.
Por eso son la base de la modelización matemática, antes de llegar a modelos más complejos, todo empieza por asumir una relación lineal.
Representar las ecuaciones
En la forma general o modelo pendiente e intersección, toda ecuación lineal puede escribirse así:
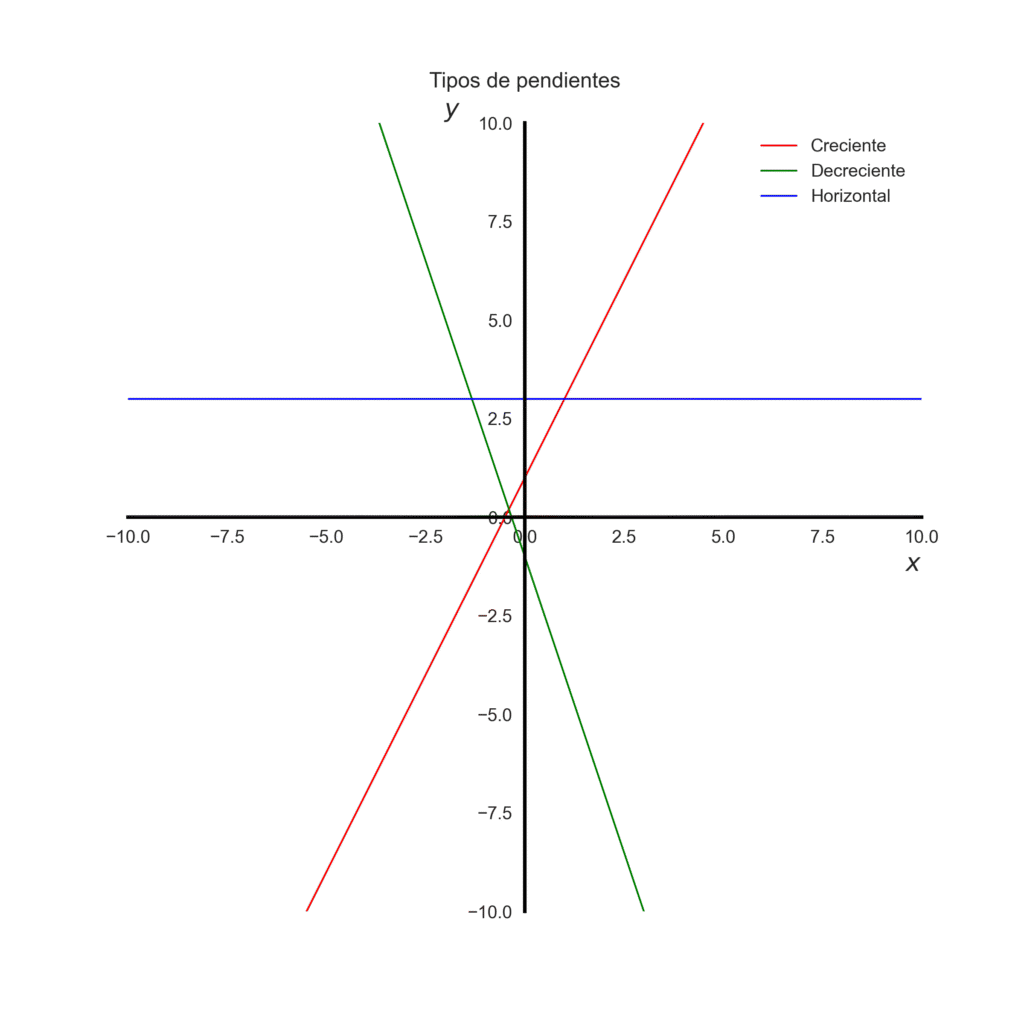
$$y=mx+b$$
Donde:
\(b\) –> es el valor inicial o intersección con el eje Y: el valor de \(y\) cuando \(x=0\).
\(y\) –> valor en el eje vertical (dependiente)
\(x\) –> valor en el eje horizontal (independiente)
\(m\) –> es la pendiente, cuánto cambia \(y\) cuando \(x\) aumenta una unidad.
Si \(m > 0\) –> sube hacia la derecha (creciente)
Si \(m < 0\) –> baja hacia la derecha (decreciente)
Si \(m = 0\) –> la recta es horizontal
Código de la grafica
Código Python con Matplotlib
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))ax.axline((0, 1), slope=2, color="red", linewidth=1, label="Creciente")ax.axline((0, -1), slope=-3, color="green", linewidth=1, label="Decreciente")ax.axline((0, 3), slope=0, color="blue",linewidth=1, label="Horizontal")# Ejes en el centroax.spines['left'].set_position('zero') # eje Y en x=0ax.spines['bottom'].set_position('zero') # eje X en y=0# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Cambiar color y grosor de los ejes (spines)for spine in ['left', 'bottom']: ax.spines[spine].set_color('black') ax.spines[spine].set_linewidth(2)# Límites y cuadrículaax.set_xlim(-10, 10)ax.set_ylim(-10, 10)# tamaño de los numerosax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y leyendaax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.legend()ax.set_title("Tipos de pendientes", pad=20)ax.legend(facecolor='none', edgecolor='none')ax.grid(False)plt.savefig("pendientes.png", transparent=True, dpi=300)plt.show()
¿Por qué las pendientes siempre avanzan a la derecha?
Esto tiene que ver con cómo definimos el sistema de coordenadas cartesianas y el concepto de pendiente. Vamos a desglosarlo paso a paso:
La pendiente mide cuánto cambia \(y\) cuando \(x\) cambia una unidad.
Cuando calculamos la pendiente avanzamos de izquierda a derecha en el eje \(x\).
Entonces la pendiente se interpreta como el cambio vertical que ocurre al movernos a la derecha.
Por eso, al dibujar la recta, decimos que “avanza a la derecha” y sube o baja según \(x\).
Si quisieras avanzar a la izquierda, sería simplemente \(x<0\) y la pendiente seguiría siendo la misma, solo que la “mirada” sería desde el otro extremo.
En otras palabras: no es que la recta no exista hacia la izquierda, sino que matemáticamente la pendiente se mide tomando \(Δx\) (variación de x) positivo, lo que corresponde a moverse hacia la derecha.
El sentido algebraico: equilibrio
Desde el punto de vista algebraico, una ecuación es una igualdad entre dos expresiones que mantiene un equilibrio. Una ecuación lineal representa un equilibrio simple, sin potencias ni productos entre variables:
$$2x+3y=30$$
Significa que existen valores de \(x\)y\(y\) para los cuales la expresión de la izquierda \(2x+3y\)) tiene el mismo valor que el número de la derecha (30).
Cada punto \((x,y)\) que cumple esa igualdad está en equilibrio: pertenece a la recta.
Ambos lados deben ser iguales para que la ecuación se cumpla.
Una ecuación representa una condición de equilibrio o una restricción sobre los valores posibles de las variables.
Desde el punto de vista algebraico, lo que hacemos con una ecuación es buscar los valores de las variables que la hacen verdadera. A eso lo llamamos resolver la ecuación. En este caso: \(2x+3y=30\) no tiene una única solución, sino infinitas combinaciones de \((x,y)\) que cumplen la igualdad (todas las que están sobre la recta).
Si representamos todos los puntos \((x,y)\) que cumplen esa ecuación, obtenemos una recta en el plano cartesiano. Así, una ecuación lineal de dos variables es la expresión algebraica de una recta.
Ejemplo: Ecuación linear de las frutas
Un problema clásico seria resolver cuantas manzanas y naranjas podemos comprar con 30€, donde las manzanas tienen un precio de 2€ y las naranjas de 3€. (Supón que puedes fraccionar las frutas).
Este problema se resuelve con un ecuación lineal que se representa como sigue:
$$2x + 3y = 30$$
Donde:
2 y 3 –> son los coeficientes (precios de las frutas)
\(x\)–> variable que representa las manzanas
\(y\) –> variable que representa las naranjas
30 –> es el termino independiente (la constante)
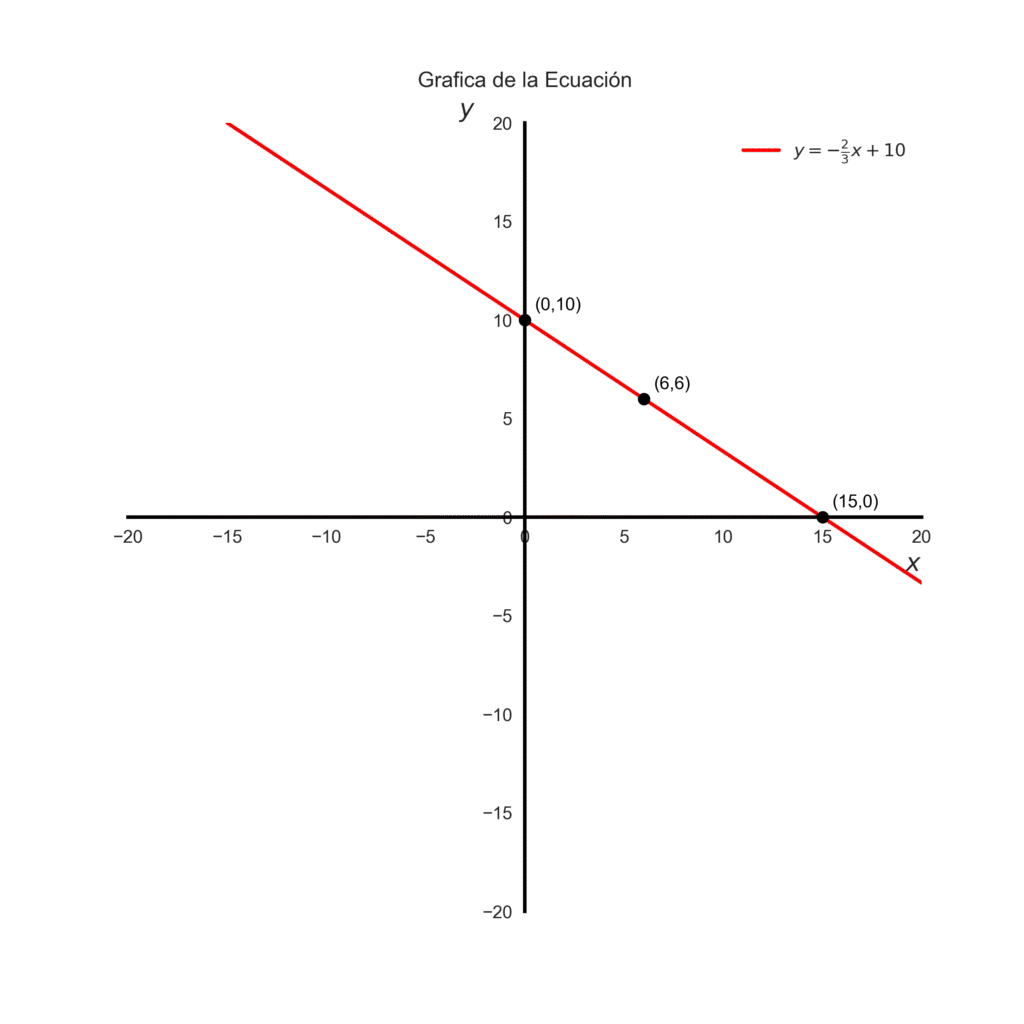
Representamos la ecuación en la forma general \(y=mx+b\):
$$3y = -2x + 30$$
Pasamos el 3 dividiendo y calculamos:
$$y = \frac{2}{3}x – \frac{30}{3}$$
$$y = -\frac{2}{3}x + 10$$
Aquí tenemos:
\(m = – \frac{2}{3}\) –> pendiente de la recta.
\(b = 10\) –> la ordenada en el origen, o sea el punto donde la recta corta el eje Y.
Cuando \(x=0\): \(y=10\) –> la recta pasa por el punto \((0, 10)\).
Cuando \(y=0\): \(x=15\) → la recta pasa por el punto (15, 0):
$$2x + 3y = 30$$
$$2x + 3(0) = 30$$
$$2x = 30$$
$$2x = \frac{30}{2}$$
$$x = 15$$
Entonces tenemos ya dos puntos \((0,10)\) y \((15,0)\). Con estos dos puntos podemos trazar una recta que representa la ecuación. Cada punto en la recta, es una combinación de manzanas(\(x\)) y naranjas (\(y\)) que equivalen a una compra de 30€.
Podemos calcular mas combinaciones de frutas posibles eligiendo los valores de \(x\) y calculando \(y\) en la ecuación de la forma pendiente – intersección.
Por ejemplo, si \(x = 6\):
$$y = – \frac{2}{3}x + 10$$
$$y = – \frac{2}{3}(6) + 10$$
$$y = – \frac{12}{3} + 10$$
$$y = – 4 + 10 = 6$$
Otra combinación de frutas y punto en la grafica seria \((6,6)\). Representemos gráficamente la ecuación.
Código de la grafica
Código Python de Matplotlib
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))ax.axline((0, 10), slope=-2/3, color="red", linewidth=2, label=r"$y = -\frac{2}{3}x + 10$")# Puntos específicospuntos = [(15,0), (0,10), (6,6)]for x, y in puntos: ax.plot(x, y, 'ko', markersize=6) # dibujar punto ax.text(x + 0.5, y + 0.5, f"({x},{y})", fontsize=10, color='black')# Ejes en el centroax.spines['left'].set_position('zero') # eje Y en x=0ax.spines['bottom'].set_position('zero') # eje X en y=0# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Cambiar color y grosor de los ejes (spines)for spine in ['left', 'bottom']: ax.spines[spine].set_color('black') ax.spines[spine].set_linewidth(2)# Límites y cuadrículaax.set_xlim(-20, 20)ax.set_ylim(-20, 20)# tamaño de los numerosax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y leyendaax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.legend()ax.set_title("Grafica de la Ecuación", pad=20)ax.legend(facecolor='none', edgecolor='none')ax.grid(False)plt.savefig("ecuacion de las frutas.png", transparent=True, dpi=300)plt.show()
Este sencillo problema de manzanas y naranjas nos muestra cómo las ecuaciones lineales nos permiten modelar relaciones entre variables de manera clara y predecible. Cada punto en la recta representa una combinación posible que satisface la restricción del problema (gastar 30 €), y la pendiente nos indica cómo cambiaría una variable si ajustamos la otra.
En ciencia de datos y machine learning, este mismo concepto es fundamental: buscamos modelar relaciones entre variables para poder predecir, optimizar o tomar decisiones basadas en datos.
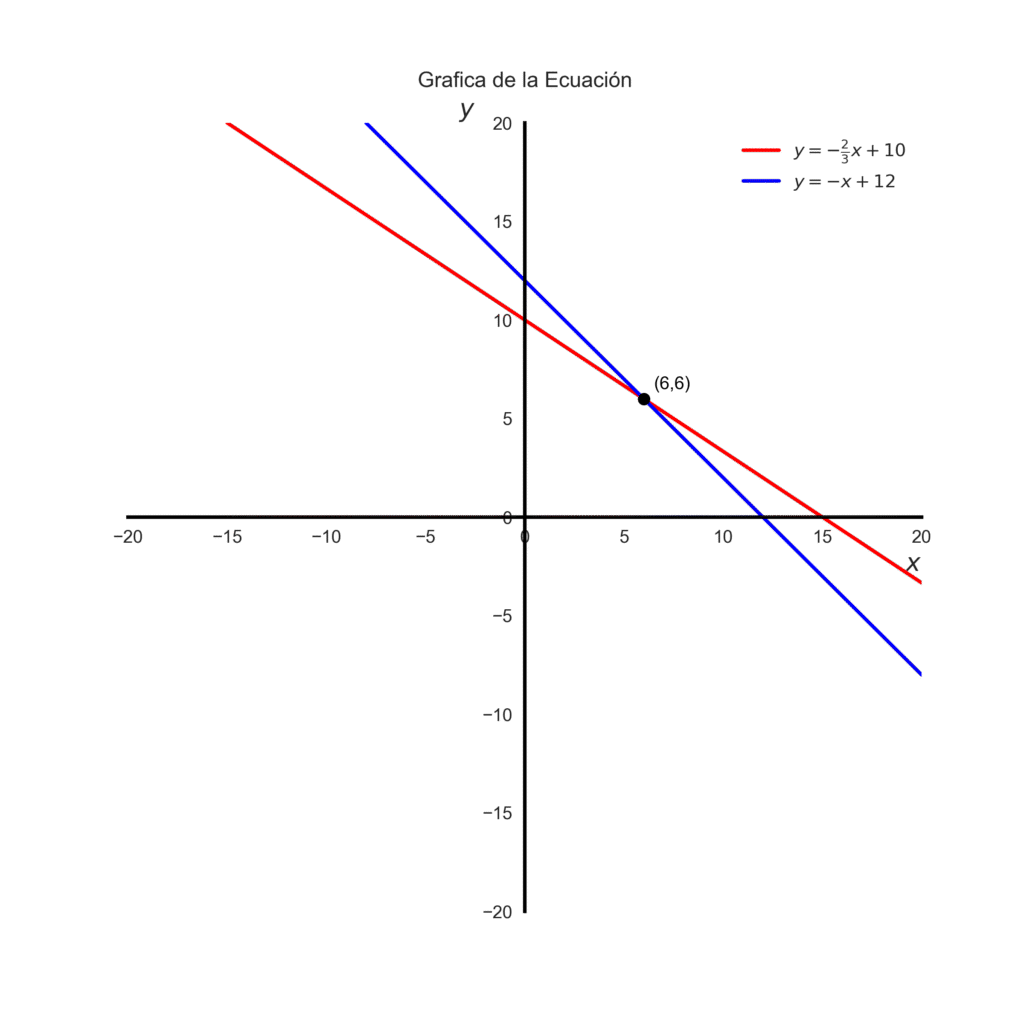
Sistemas Lineales
Un sistema lineal es un conjunto de ecuaciones lineales que resuelves juntas para encontrar valores que satisfagan todas.
Supongamos que a nuestro problema anterior le añadimos una condición. Supón ahora que además de gastar 30 €, queremos comprar exactamente 12 frutas en total. Esa nueva condición se traduce en otra ecuación:
$$x + y = 12$$
Ahora tenemos dos ecuaciones y dos incógnitas \((x, y)\).
$$\begin{cases} 2x + 3y = 30 \\ x + y = 12 \end{cases}$$
Aquí, cada ecuación representa una recta en el plano cartesiano. El punto donde ambas rectas se cruzan es la combinación de frutas que cumple las dos condiciones al mismo tiempo: gastar 30 € y comprar exactamente 12 frutas. Existen varios métodos de resolver los sistemas de ecuaciones.
De la segunda ecuación despejamos \(x\) y sustituimos en la primera.
$$x + y = 12$$
$$x = 12 – y$$
Sustituimos en la primera ecuación:
$$2(12−y) + 3y = 30$$
$$24− 2y + 3y = 30$$
$$24 − 2y + 3y = 30$$
$$24 + y = 30$$
$$24 + y = 30$$
$$y = 30 – 24 = 6$$
Ahora sustituimos \(y\) en la segunda:
$$x + y = 12$$
$$x + 6 = 12$$
$$x = 12 – 6 = 6$$
Resultado: \(x=6,y=6\), o sea 6 manzanas y 6 naranjas. En el grafico el punto de intersección de las rectas es \((6,6)\).
Con Matplotlib podemos graficar la recta solo con la pendiente y la intersección. En este caso para la segunda ecuacion \(m = -1\) y \(b = 12\) .
Código del grafico
Código Python de Matplotlib
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))ax.axline((0, 10), slope=-2/3, color="red", linewidth=2, label=r"$y = -\frac{2}{3}x + 10$")ax.axline((0, 12), slope=-1, color="blue", linewidth=2, label=r"$y = -x + 12$")# Puntos específicosax.plot(6, 6, 'ko', markersize=6) # dibujar puntoax.text(x + 0.5, y + 0.5, f"({6},{6})", fontsize=10, color='black')# Ejes en el centroax.spines['left'].set_position('zero') # eje Y en x=0ax.spines['bottom'].set_position('zero') # eje X en y=0# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Cambiar color y grosor de los ejes (spines)for spine in ['left', 'bottom']: ax.spines[spine].set_color('black') ax.spines[spine].set_linewidth(2)# Límites y cuadrículaax.set_xlim(-20, 20)ax.set_ylim(-20, 20)# tamaño de los numerosax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y leyendaax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.legend()ax.set_title("Grafica de la Ecuación", pad=20)ax.legend(facecolor='none', edgecolor='none')ax.grid(False)plt.savefig("sistemas_de_ecuaciones.png", transparent=True, dpi=300)plt.show()
Formato Matricial
La expresión general:
$$y=a_1x_1+a_2x_2+⋯+a_nx_n$$
Es el punto de partida que lleva directamente a la forma matricial de los sistemas lineales. El mismo sistema de ecuaciones de las frutas puede escribirse y resolverse en forma matricial. En la ciencia de datos los datasets son matrices, y resolver sistemas lineales ayuda a encontrar relaciones entre variables.
Partimos del sistema:
$$\begin{cases} 2x + 3y = 30 \\ x + y = 12 \end{cases}$$
En formato matricial:
$$\begin{bmatrix} 2 & 3 \\ 1 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 30 \\ 12 \end{bmatrix}$$
Significado de las partes:
Partes
Significado
$$\begin{bmatrix} 2 & 3 \\ 1 & 1 \end{bmatrix}$$
Matriz de coeficientes: contiene los números que multiplican a las variables (los precios de las frutas).
$$\begin{bmatrix} x \\ y \end{bmatrix}$$
Vector de incógnitas: las variables que queremos encontrar (número de manzanas y naranjas).
$$\begin{bmatrix} 30 \\ 12 \end{bmatrix}$$
Vector de resultados: los valores en el lado derecho (total de dinero y total de frutas).
La forma vectorial compacta del sistema matricial se expresa como:
$$A\vec{x} = \vec{b}$$
Donde:
\(A\) –> es la matriz de coeficientes
\(\vec{x}\) –> es el vector de incógnitas
\(\vec{b}\) –> es el vector de términos independientes
Hay algunas operaciones básicas que usaremos constantemente:
Transposición (Aᵗ) → cambia filas por columnas.
Multiplicación de matrices (A·B) → combina vectores o sistemas.
Determinante (det(A)) → indica si el sistema tiene solución única.
Matriz inversa (A⁻¹) → nos permite resolver sistemas como \(x=A−1bx = A^{-1} bx=A−1b\).
Estas herramientas son la base de muchos algoritmos modernos de machine learning y análisis de datos.
Forma de la Matriz Aumentada
La matriz aumentada es otra forma de representar un sistema de ecuaciones lineales, pero con un propósito muy concreto: resolverlo más fácilmente mediante operaciones por filas (como en el método de Gauss o Gauss-Jordan). Contiene toda la información numérica del sistema. Trabajar con ella evita reescribir las variables en cada paso.
La matriz aumentada junta la matriz de coeficientes \(A\) y el vector de términos independientes \(\vec{b}\) en una sola matriz separada por una línea vertical:
Esa barra vertical no tiene significado algebraico en sí, simplemente marca la frontera entre los coeficientes del sistema y los resultados.
Método 3: Eliminación Gaussiana
El objetivo de la eliminación es transformar esa matriz con operaciones por filas hasta una forma en la que las variables se lean directamente. Las operaciones permitidas (elementales por filas) son:
Intercambiar dos filas.
Multiplicar una fila por un escalar distinto de 0.
Sumar a una fila un múltiplo de otra fila.
Estas operaciones no cambian el conjunto de soluciones del sistema: son equivalencias algebraicas.
En esta parte normalmente queremos que el primer elemento de la primera fila (posición (1,1)) sea un buen pivote (idealmente 1 y no 0). En nuestro caso la fila 2 ya tiene un 1 en la columna 1, así que intercambiamos las filas para facilitar cálculos:
Operacion \(R_1 \leftrightarrow R_2\) (Row1 y Row2)
Paso 2 — Eliminar la variable \(x\) de las filas inferiores
Qué se hace: queremos que en la columna del pivote (columna 1) todos los elementos excepto el pivote sean 0. Si el pivote fuese 0 habría que intercambiar filas para evitar dividir por 0.
Elegimos multiplicar por 2 porque ese número es precisamente lo necesario para que, al restarlo, el coeficiente 2 de la fila 2 quede anulado \((2 − 2 = 0)\).
La generalización del sistema lineal en una matriz aumentada es muy importante porque los modelos lineales en ciencia de datos funcionan exactamente igual:
$$\vec{y} = A\vec{w} + \vec{ε}$$
donde:
\(A\) es la matriz de datos (cada fila una observación, cada columna una variable)
\(\vec{w}\) son los pesos o coeficientes del modelo (lo que queremos estimar),,
\(\vec{y}\) son los valores observados o predichos.
\(\vec{ε}\) representa los errores o diferencias entre la predicción y los datos reales.
Esa es exactamente la forma que adoptan los modelos lineales en ciencia de datos y machine learning.
Resolver el sistema equivale a encontrar los valores de \(\vec{w}\) que mejor explican o ajustan los datos. Por eso, las ecuaciones lineales y su resolución matricial son la base matemática de muchos algoritmos de Machine Learning.
Ecuaciones Lineales con Python
Python hace que resolver sistemas lineales sea fácil y rápido con NumPy. Vamos a hacerlo de forma didáctica, con el mismo ejemplo de las frutas (dos ecuaciones, dos incógnitas), y luego generalizamos a más variables.
El sistema del ejercicio de las frutas en formas matricial compacta se expreso como:
import numpy as np# Definimos la matriz de coeficientes y el vector de resultadosA = np.array([[2, 3], [1, 1]])b = np.array([30, 12])# Resolver el sistema A x = bx = np.linalg.solve(A, b)print("Solución (x, y):", x)
Solución (x, y): [6. 6.]
Comprobar el resultado:
# Verificamos A @ x = bprint("Comprobación:", A @ x)
Comprobación: [30. 12.]
Usando la inversa de la matriz (método alternativo)
Este método no se recomienda en práctica cuando hay muchas variables, porque calcular la inversa directamente es más costoso y menos estable numéricamente.
A_inv = np.linalg.inv(A)x_alt = A_inv @ bprint("Solución con A^-1:", x_alt)