La imputación simple es una técnica de tratamiento de datos faltantes que consiste en reemplazar los valores ausentes utilizando un único valor calculado o definido previamente. Es una de las estrategias más utilizadas durante la preparación de datos debido a su sencillez, rapidez y facilidad de implementación.
En lugar de eliminar registros o variables que contienen datos faltantes, la imputación simple permite conservar la información disponible sustituyendo los valores ausentes por estimaciones razonables.
Por ejemplo:
edad = [ 25, 30, NULL, 35]
Tras aplicar imputación simple mediante la media:
edad = [ 25, 30, 30, 35]
El valor faltante se sustituye por una estimación basada en los datos disponibles.
¿Por qué utilizar imputación simple?
Los valores faltantes representan uno de los problemas más frecuentes en Data Science y Machine Learning. Muchos algoritmos no pueden procesar directamente datos ausentes, lo que obliga a tomar alguna decisión antes del entrenamiento. Las alternativas más comunes son:
Eliminar registros.
Eliminar variables.
Imputar valores.
La imputación simple suele ser una buena opción cuando:
La cantidad de valores faltantes es reducida.
La variable es importante para el análisis.
Se desea conservar el mayor número posible de observaciones.
No se justifica utilizar métodos más complejos.
¿Cómo funciona la imputación simple?
El procedimiento consiste en:
Identificar los valores faltantes.
Seleccionar un método de imputación.
Calcular el valor de reemplazo.
Sustituir los datos ausentes.
La característica principal de esta técnica es que todos los valores faltantes de una misma variable se reemplazan utilizando el mismo criterio.
Métodos de imputación simple
Imputación mediante la media: Se sustituyen los valores faltantes por la media aritmética de la variable.
Imputación mediante la mediana : Se reemplazan los valores faltantes por la mediana de la variable.
Imputación mediante la moda: Se utiliza el valor más frecuente de una variable. Es especialmente útil para variables categóricas.
Imputación mediante un valor constante: Los valores faltantes se sustituyen por un valor definido manualmente. Ejmplo: Unknow, esta estrategia permite conservar información sobre la ausencia de datos.
Comparación entre métodos de imputación simple
Método
Tipo de Variable
Sensible a Outliers
Complejidad
Media
Numérica
Alta
Baja
Mediana
Numérica
Baja
Baja
Moda
Categórica o Numérica
Baja
Baja
Constante
Cualquier tipo
No aplica
Baja
Beneficios de la imputación simple
Permite conservar registros incompletos.
Evita la pérdida de información.
Es fácil de implementar.
Requiere pocos recursos computacionales.
Funciona rápidamente incluso en grandes conjuntos de datos.
Facilita el entrenamiento de modelos.
Es compatible con la mayoría de algoritmos.
¿Cuándo utilizar la imputación simple?
El porcentaje de valores faltantes es reducido.
Los datos faltantes son MCAR (Missing Completely At Random).
Se necesita una solución rápida.
La variable tiene una distribución relativamente estable.
Se trabaja en fases iniciales de exploración de datos.
También suele utilizarse como línea base antes de probar técnicas más avanzadas.
Ventajas
Implementación sencilla.
Bajo coste computacional.
Fácil interpretación.
Mantiene el tamaño del dataset.
Compatible con pipelines de Machine Learning.
Adecuada para grandes volúmenes de datos.
Disponible en la mayoría de herramientas analíticas.
Desventajas
Introduce valores artificiales.
Reduce la variabilidad de los datos.
Puede alterar distribuciones originales.
No tiene en cuenta relaciones entre variables.
Puede introducir sesgos.
Por ejemplo, si una variable presenta una distribución muy asimétrica, imputar mediante la media puede generar valores poco representativos.
Limitaciones
No recupera los valores reales perdidos.
Ignora correlaciones entre variables.
Puede infraestimar la varianza.
Reduce la dispersión de los datos.
Puede afectar a la calidad de algunos modelos.
No suele ser adecuada para grandes cantidades de datos faltantes.
Por esta razón, cuando el porcentaje de valores ausentes es elevado suelen considerarse métodos más avanzados como KNN Imputation o MICE.
Comparación con otras técnicas de tratamiento
Característica
Imputación Simple
KNN Imputation
MICE
Complejidad
Baja
Media
Alta
Coste computacional
Bajo
Medio
Alto
Utiliza relaciones entre variables
No
Sí
Sí
Facilidad de implementación
Alta
Media
Baja
Calidad de la imputación
Media
Alta
Muy alta
Escalabilidad
Alta
Media
Baja
Imputación Simple vs Eliminación de Registros
Aspecto
Imputación Simple
Eliminación
Conserva observaciones
Sí
No
Mantiene tamaño de muestra
Sí
No
Introduce estimaciones
Sí
No
Riesgo de pérdida de información
Bajo
Alto
Facilidad de aplicación
Alta
Alta
Impacto en Machine Learning
Muchos algoritmos requieren datos completos para poder entrenarse correctamente.
Por ejemplo:
Regresión lineal.
Regresión logística.
SVM.
Redes neuronales.
K-Means.
La imputación simple permite generar conjuntos de datos compatibles con estos algoritmos sin eliminar observaciones potencialmente valiosas. Sin embargo, debe utilizarse con precaución cuando los datos faltantes presentan patrones complejos o porcentajes elevados.
Implementación en Python
Imputación mediante la media
from sklearn.impute import SimpleImputerimport pandas as pddf = pd.DataFrame({"edad": [25, 30, None, 35]})imputer = SimpleImputer(strategy="mean")df["edad"] = imputer.fit_transform( df[["edad"]])print(df)
Imputación mediante la mediana
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy="median")df["salario"] = imputer.fit_transform( df[["salario"]])
Imputación mediante la moda
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy="most_frequent")df["ciudad"] = imputer.fit_transform( df[["ciudad"]])
Imputación mediante un valor constante
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy="constant",fill_value="Desconocido")df["ciudad"] = imputer.fit_transform( df[["ciudad"]])
Analizar previamente el porcentaje de datos faltantes.
Comprender el mecanismo de ausencia de los datos.
Utilizar la mediana cuando existan outliers.
Utilizar la moda para variables categóricas.
Ajustar el imputador únicamente con los datos de entrenamiento.
Comparar el rendimiento frente a métodos más avanzados.
Evaluar el impacto sobre las distribuciones originales.
Conclusión
La imputación simple es una de las técnicas más utilizadas para gestionar datos faltantes debido a su simplicidad, rapidez y facilidad de implementación. Consiste en sustituir los valores ausentes mediante estadísticas básicas como la media, la mediana, la moda o un valor constante, permitiendo conservar observaciones que de otro modo podrían perderse.
Aunque presenta limitaciones y no tiene en cuenta las relaciones entre variables, sigue siendo una excelente solución cuando el porcentaje de datos faltantes es reducido y se necesita una estrategia eficiente y fácilmente interpretable. Además, suele constituir el punto de partida para comparar posteriormente métodos más avanzados como KNN Imputation o Imputación Múltiple (MICE).
Los datos faltantes, también conocidos como valores nulos o valores ausentes, son observaciones para las cuales no existe información registrada en una o más variables de un conjunto de datos. Dependiendo del sistema utilizado, pueden representarse mediante valores como NULL, NaN, None, #N/A o simplemente campos vacíos.
La presencia de datos faltantes es uno de los problemas más frecuentes en Data Science, Machine Learning, Business Intelligence y analítica de datos. De hecho, es raro encontrar conjuntos de datos reales que no contengan algún nivel de información ausente.
¿Por qué es importante gestionar los datos faltantes?
La calidad de cualquier análisis depende directamente de la calidad de los datos utilizados. Cuando existen valores ausentes, se generan vacíos de información que pueden afectar significativamente a los resultados obtenidos.
Los datos faltantes pueden provocar:
Pérdida de información relevante.
Disminución del tamaño efectivo de la muestra.
Sesgos estadísticos.
Reducción de la precisión de los modelos.
Conclusiones incorrectas.
Problemas durante el entrenamiento de algoritmos.
Por ejemplo, si una empresa desea identificar cuáles son los productos más vendidos por color y una de sus tiendas no registra correctamente esa información, los resultados del análisis podrían conducir a decisiones erróneas sobre inventario, compras o marketing.
Por esta razón, el tratamiento de los datos faltantes constituye una de las etapas más importantes dentro de la limpieza y preparación de datos.
¿Por qué aparecen los datos faltantes?
Existen numerosas razones por las que un conjunto de datos puede contener valores ausentes.
Errores de captura: Los datos nunca fueron introducidos en el sistema. Ejemplo: formularios incompletos, campos opcionales no rellenados y omisiones humanas.
Problemas de privacidad: Algunos usuarios deciden no proporcionar determinada información personal. Correo electrónico, número de teléfono, ingresos, información médica.
Fallos técnicos: Pueden producirse errores durante la transmisión de datos, la integración de sistemas, el almacenamiento o la captura mediante sensores.
Pérdida de información: La corrupción de archivos o interrupciones en sistemas de comunicación también pueden provocar la desaparición de datos válidos.
Reglas de negocio: En algunos casos la ausencia de información es completamente normal y esperada.
¿Cómo identificar datos faltantes?
Antes de decidir cómo tratarlos, es necesario detectarlos y cuantificarlos.
Las técnicas más habituales incluyen:
Inspección visual de los datos.
Revisión de muestras aleatorias.
Estadísticas descriptivas.
Perfilado de datos.
Validación de datos.
Análisis de porcentajes de ausencia.
Algunas preguntas útiles son:
¿Cuántos valores faltan?
¿Qué variables están afectadas?
¿Existe algún patrón?
¿La ausencia afecta a variables importantes?
Tipos de datos faltantes
No todos los valores ausentes tienen el mismo significado. Comprender el motivo de la ausencia es fundamental para seleccionar la estrategia de tratamiento adecuada.
Datos estructuralmente faltantes
Son datos cuya ausencia es esperada debido al contexto del problema.
Por ejemplo:
Asma
Frecuencia Inhalador
Sí
Dos veces al día
Sí
Una vez al día
No
NULL
La ausencia de información sobre el inhalador es completamente lógica porque la persona no tiene asma. En estos casos, normalmente no es necesario imputar ningún valor.
Missing Completely At Random (MCAR)
Los datos faltan completamente al azar. La probabilidad de que un dato esté ausente es la misma para todas las observaciones. Ejemplos:
Fallo aleatorio de un sensor.
Error aleatorio de transmisión.
Problema temporal de captura.
Características:
No existe patrón identificable.
El riesgo de sesgo es bajo.
Son los más sencillos de tratar.
Missing At Random (MAR)
La ausencia depende de otras variables observadas.
Ejemplo práctico de MAR
En el dataset “Predict H1N1 and Seasonal Flu Vaccines” de DrivenData, la variable employment_industry presenta aproximadamente un 50% de valores faltantes.
A primera vista podría parecer un problema grave de calidad de datos. Sin embargo, al analizar la relación entre employment_industry y employment_status mediante una tabla de contingencia, se observa que los valores faltantes aparecen casi exclusivamente en personas desempleadas o fuera del mercado laboral.
employment_industry False Trueemployment_status Employed 13377 183Not in Labor Force 0 10231 Unemployed 0 1453
¿Cómo interpretar estos datos?
Entender qué significa False y True: df['employment_industry'].isna() genera una serie booleana donde:
False: existe valor.
True: es NaN
Employed muestra que 13377 empleados tienen industria asignada.
Not in Labor Force muestra que ninguna persona fuera de la fuerza laboral tiene industria. Todas tienen NaN.
Unemployed muestra que ningún desempleado tiene industria. Todos tienen NaN.
Observa que:
Employed → casi todos tienen industria
Not in Labor Force → ninguno tiene industria
Unemployed → ninguno tiene industria
Esto indica que la ausencia de información no es aleatoria, sino que depende de una variable observada employment_status. O sea ,employment_industry sólo se pregunta a personas empleadas.
En este caso, el mecanismo de ausencia desde una perspectiva estadística estricta: se clasifica como MAR (Missing At Random), ya que la probabilidad de que falte el dato puede explicarse mediante información disponible en el conjunto de datos.
Desde una perspectiva de negocio, también puede interpretarse como Missing Not Applicable (MNAR estructural) . La variable no está ausente por error. Está ausente porque la pregunta no aplica al individuo. La pregunta: ¿En qué industria trabaja? no tiene sentido para alguien desempleado.
En un proyecto profesional puede documentarse de la siguiente manera:
employment_industry presenta aproximadamente un 50% de valores nulos.
El análisis mediante tablas de contingencia muestra que la ausencia depende completamente de la variable employment_status.
Los individuos desempleados o fuera de la fuerza laboral no disponen de industria asociada, por lo que los valores ausentes parecen corresponder a casos donde la variable no aplica al individuo más que a pérdidas aleatorias de información.
Por tanto, los valores ausentes se consideran ausencias estructurales dependientes de employment_status (MAR) y serán tratados como una categoría específica.
¿Qué hacer en estos casos?
En estos casos la solución sería crear una categoría explícita que identifique la causa del valor faltante, por ejemplo: Not_Working.
La ausencia está relacionada con el propio valor que falta.
Ejemplo:
Personas con ingresos muy elevados deciden no declarar sus ingresos.
Pacientes con problemas graves evitan responder determinadas preguntas médicas.
Características:
Existe un patrón subyacente.
Puede introducir sesgos importantes.
Es el tipo más difícil de tratar.
Missing Not At Random (MNAR): cuando la ausencia de datos también es información
Missing Not At Random (MNAR) es cuando la probabilidad de que un valor esté ausente está relacionada con características del propio individuo o con información que no ha sido observada. En estos casos, puede ser que los registros con valores faltantes representen un grupo específico dentro de la población y no una simple muestra aleatoria.
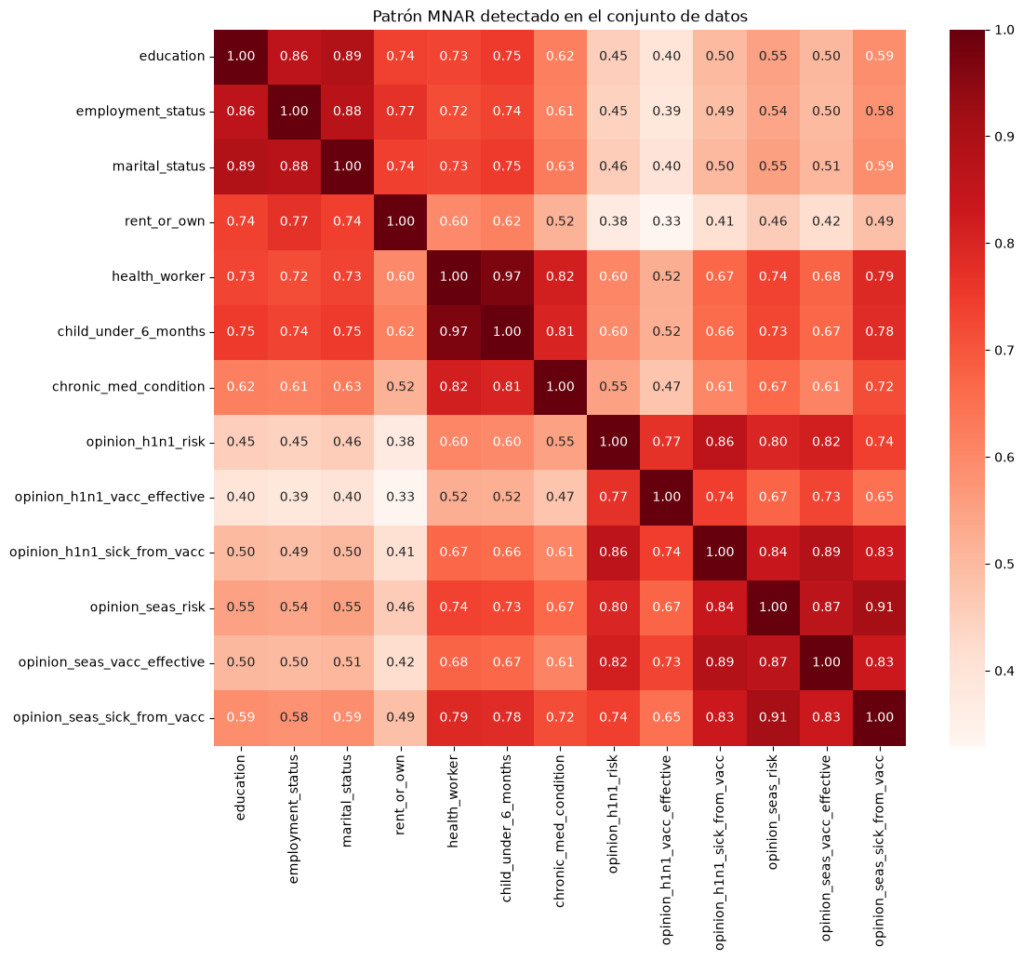
Durante el análisis exploratorio del proyecto Predict H1N1 and Seasonal Flu Vaccines se identificó un patrón muy claro de ausencia de datos que sugiere la existencia de un mecanismo MNAR. En lugar de encontrar valores faltantes distribuidos de manera independiente entre distintas variables, se observó que los mismos individuos tendían a presentar ausencias simultáneas en múltiples campos del cuestionario.
Por ejemplo, las variables:
education
employment_status
marital_status
rent_or_own
Presentaban valores faltantes altamente relacionados entre sí. Los registros con ausencia en una de estas variables tenían una elevada probabilidad de presentar también valores faltantes en las demás. Además, este mismo grupo de individuos mostraba ausencias en variables relacionadas con la salud y la situación personal, como:
health_worker
child_under_6_months
chronic_med_condition
e incluso en variables de percepción y opinión sobre las vacunas, entre ellas:
opinion_h1n1_risk
opinion_h1n1_vacc_effective
opinion_h1n1_sick_from_vacc
opinion_seas_risk
opinion_seas_vacc_effective
opinion_seas_sick_from_vacc
Las correlaciones entre los indicadores de ausencia de estas variables fueron especialmente elevadas. Por ejemplo:
health_worker y child_under_6_months presentaron una correlación de ausencia cercana a 0.97.
health_worker y chronic_med_condition mostraron correlaciones superiores a 0.80.
education, employment_status, marital_status y rent_or_own también mostraron correlaciones de ausencia muy elevadas, superiores a 0.70 en numerosos casos.
Este comportamiento resulta difícil de explicar mediante un mecanismo completamente aleatorio. Si los valores faltantes fueran independientes, las ausencias aparecerían distribuidas de forma dispersa entre los registros. Sin embargo, lo observado fue la existencia de un subconjunto de encuestados que parecía haber omitido responder bloques completos de preguntas.
La evidencia se reforzó al analizar la relación entre los valores faltantes y las variables objetivo del problema: la vacunación contra la gripe H1N1 y la gripe estacional. En varias variables, los individuos con información ausente mostraban tasas de vacunación significativamente distintas de las observadas en las categorías existentes.
Un ejemplo especialmente representativo fue la variable health_insurance. Mientras que los individuos con seguro médico presentaban tasas de vacunación considerablemente más altas, el grupo con información desconocida mostraba un comportamiento claramente diferenciado tanto de quienes tenían seguro como de quienes declaraban no tenerlo. Esto sugiere que la ausencia de respuesta estaba asociada a características específicas de los encuestados.
Otro caso relevante fue el de las variables doctor_recc_h1n1 y doctor_recc_seasonal. Los individuos con valores faltantes en estas variables también presentaban una elevada proporción de valores desconocidos en health_insurance, lo que evidenciaba un patrón común de no respuesta. Además, sus tasas de vacunación diferían notablemente de las observadas en los grupos que sí habían respondido a estas preguntas.
Estos hallazgos muestran que los valores faltantes no eran simplemente datos perdidos, sino una característica adicional de los individuos. En otras palabras, la ausencia de información contenía información.
Por este motivo, en lugar de aplicar imputaciones tradicionales basadas en la moda o en otras medidas de tendencia central, se optó por conservar los valores faltantes como una categoría específica denominada Unknown en aquellas variables donde la ausencia mostraba evidencia de ser informativa.
Esta estrategia permite que los algoritmos de Machine Learning identifiquen posibles patrones asociados a la falta de respuesta y aprovechen dicha información durante el entrenamiento. En problemas de clasificación como este, donde la métrica de evaluación es ROC-AUC, preservar la información contenida en los patrones de ausencia puede resultar tan importante como conservar los propios valores observados.
Este caso constituye un ejemplo práctico de cómo el análisis detallado de los datos faltantes puede revelar comportamientos ocultos en la población estudiada y demuestra que, en muchos escenarios reales, los valores ausentes no deben considerarse simplemente como datos perdidos, sino como una fuente potencial de información predictiva.
Aquí tienes una sección orientada a un artículo técnico y educativo:
Cómo detectar patrones MNAR mediante el análisis de valores faltantes en Python
Una de las formas más efectivas de identificar posibles mecanismos Missing Not At Random (MNAR) consiste en analizar si los valores faltantes aparecen agrupados en los mismos registros. Cuando múltiples variables presentan ausencias simultáneas de forma recurrente, puede existir un patrón de no respuesta que aporte información relevante para el modelo.
Crear una matriz de valores faltantes
El primer paso consiste en transformar los valores faltantes en variables binarias, donde:
1 indica que el valor está ausente.
0 indica que el valor está presente.
missing_df = df.isnull().astype(int)
Cada columna representa ahora el patrón de ausencia de una variable.
Calcular correlaciones entre valores faltantes
Una vez creada la matriz de ausencia, es posible calcular las correlaciones entre los patrones de valores faltantes. Por ejemplo, para analizar qué variables presentan ausencias relacionadas con health_worker:
La salida mostrará qué variables tienden a presentar valores faltantes en los mismos registros. En este proyecto se observaron correlaciones muy elevadas:
Estas correlaciones sugieren que los individuos que no respondieron a una determinada pregunta también omitieron otras preguntas relacionadas.
Filtrar únicamente las correlaciones relevantes
Cuando existen muchas variables, resulta útil visualizar únicamente aquellas correlaciones superiores a un determinado umbral df.coor() permite identificar rápidamente las relaciones más fuertes entre patrones de ausencia.
Esto significa que 1.267 personas tienen valores faltantes simultáneamente en ambas variables, lo que sugiere que las ausencias no se producen de forma independiente y podrían formar parte de un mismo patrón de no respuesta.
Crear un mapa de calor de los patrones de ausencia
Una forma visual de identificar relaciones entre valores faltantes consiste en representar la matriz de correlaciones mediante un mapa de calor.
cols = ['education','employment_status','marital_status','rent_or_own','health_worker','child_under_6_months','chronic_med_condition','opinion_h1n1_risk','opinion_h1n1_vacc_effective','opinion_h1n1_sick_from_vacc','opinion_seas_risk','opinion_seas_vacc_effective','opinion_seas_sick_from_vacc']corr_missing = (df[cols].isnull().astype(int).corr())plt.figure(figsize=(12,10))sns.heatmap(corr_missing, annot=True, cmap='Reds', fmt='.2f')plt.title('Patrón MNAR detectado en el conjunto de datos')plt.show()
Las zonas con colores más intensos indican grupos de variables cuyos valores faltantes aparecen conjuntamente.
Interpretación de los resultados
Cuando varias variables presentan:
Correlaciones elevadas entre sus patrones de ausencia.
Coincidencia frecuente de valores faltantes en los mismos registros.
Comportamientos diferenciados respecto a la variable objetivo.
Es razonable sospechar la existencia de un mecanismo MNAR (Missing Not At Random).
En estos casos, imputar automáticamente los valores faltantes mediante la media, la mediana o la moda puede provocar una pérdida de información. Una estrategia habitual consiste en conservar los valores faltantes como una categoría específica (Unknown) para permitir que el modelo capture la señal contenida en el propio patrón de ausencia.
Comparación entre tipos de datos faltantes
Tipo
Existe una causa identificable
Riesgo de sesgo
Dificultad de tratamiento
Estructuralmente faltantes
Sí
Bajo
Baja
MCAR
No
Bajo
Baja
MAR
Sí
Medio
Media
MNAR
Sí
Alto
Alta
Estrategias de tratamiento de datos faltantes
Una vez identificado el problema, existen diferentes formas de gestionarlo.
Eliminación de registros: Consiste en eliminar las filas que contienen datos faltantes. Suele utilizarse cuando:
La cantidad de valores faltantes es reducida.
Los datos son MCAR.
La pérdida de observaciones no afecta al análisis.
Eliminación de variables: Consiste en eliminar columnas con un porcentaje muy elevado de valores ausentes.
Imputación: La imputación consiste en reemplazar los valores faltantes mediante estimaciones. Las técnicas más utilizadas son:
Imputación Simple: Media, mediana, moda o valor constante
Imputación por KNN: Utiliza observaciones similares
Imputación Múltiple (MICE): Estima valores mediante modelos iterativos
Métodos para series temporales
Cuando los datos tienen una dimensión temporal, pueden emplearse técnicas específicas. Algunas de las más utilizadas son:
LOCF: Última observación arrastrada hacia delante
NOCB: Próxima observación arrastrada hacia atrás
Interpolación: Estimación entre valores conocidos
¿Cuándo eliminar y cuándo imputar?
La decisión depende del contexto y del volumen de datos faltantes.
Situación
Estrategia recomendada
Menos del 5% de valores faltantes
Eliminación o imputación simple
Variable poco relevante
Eliminación
Variable importante
Imputación
Datos MCAR
Eliminación o imputación
Datos MAR
Imputación
Datos MNAR
Análisis específico del problema
Más del 60% de valores faltantes
Evaluar eliminar la variable
Beneficios del tratamiento de datos faltantes
Mejora la calidad del dataset.
Reduce errores analíticos.
Incrementa la precisión de los modelos.
Disminuye sesgos.
Permite aprovechar más información.
Facilita el entrenamiento de algoritmos.
Incrementa la confianza en los resultados.
Ventajas
Permite trabajar con conjuntos de datos incompletos.
Reduce el impacto de la pérdida de información.
Mejora la representatividad de la muestra.
Incrementa la calidad de los análisis.
Facilita la toma de decisiones basada en datos.
Desventajas
Algunas técnicas introducen estimaciones artificiales.
Existe riesgo de introducir sesgos.
La imputación puede alterar distribuciones originales.
Algunas técnicas son computacionalmente costosas.
Requiere conocimiento del contexto de negocio.
Limitaciones
Los datos faltantes nunca pueden recuperarse con total certeza.
Las imputaciones son estimaciones, no valores reales.
Los datos MNAR siguen siendo difíciles de modelar.
Una estrategia incorrecta puede degradar el rendimiento del modelo.
No existe una técnica universalmente mejor.
Por ello, comprender el origen de la ausencia suele ser más importante que la técnica utilizada para corregirla.
Aplicaciones en Data Science y Machine Learning
El tratamiento de datos faltantes aparece prácticamente en cualquier proyecto basado en datos. La mayoría de los algoritmos requieren datos completos o una gestión adecuada de los valores faltantes antes del entrenamiento.
Implementación en Python
Detectar valores nulos
import pandas as pddf = pd.read_csv("datos.csv")print(df.isnull().sum())
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy="mean")df["edad"] = imputer.fit_transform( df[["edad"]])
Buenas prácticas
Identificar primero el tipo de ausencia.
Analizar el porcentaje de valores faltantes.
Comprender el contexto de negocio.
Evitar eliminar datos innecesariamente.
Comparar diferentes estrategias.
Documentar todas las transformaciones realizadas.
Validar el impacto sobre el modelo final.
Conclusión
Los datos faltantes constituyen uno de los problemas más frecuentes en cualquier proyecto de análisis de datos. Su presencia puede afectar significativamente la calidad de los análisis, introducir sesgos y reducir la precisión de los modelos predictivos.
Sin embargo, no todos los datos faltantes son iguales. Comprender si la ausencia es estructural, MCAR, MAR o MNAR resulta fundamental para seleccionar la estrategia adecuada. Una vez identificado el origen del problema, pueden aplicarse técnicas como la eliminación de registros, la eliminación de variables o diferentes métodos de imputación.
Más que una tarea técnica aislada, el tratamiento de datos faltantes es un proceso de análisis y toma de decisiones que busca preservar la mayor cantidad posible de información sin comprometer la fiabilidad de los resultados. Por ello, constituye una etapa esencial dentro de cualquier flujo de trabajo de Data Science y Machine Learning.
La validación de datos (Data Validation) es el proceso de verificar que los datos cumplen una serie de reglas, restricciones y criterios de calidad antes de ser utilizados en análisis, informes, procesos de negocio o modelos de Machine Learning.
Su objetivo principal es garantizar que los datos sean correctos, completos, consistentes y adecuados para el propósito previsto.
La validación permite detectar errores, anomalías e inconsistencias antes de que afecten a la calidad de los análisis o al rendimiento de los modelos predictivos.
Por ejemplo, si una columna denominada “Edad” contiene valores negativos o superiores a 120 años, un proceso de validación debería identificar esos registros como inválidos.
¿Por qué es importante la validación de datos?
Los datos pueden proceder de múltiples fuentes:
Bases de datos.
Formularios web.
Sistemas ERP.
CRM.
APIs.
Sensores IoT.
Archivos CSV o Excel.
Durante su captura o integración pueden producirse errores que comprometan la calidad de la información.
Algunos ejemplos son:
Campos obligatorios vacíos.
Fechas incorrectas.
Valores fuera de rango.
Registros duplicados.
Formatos inconsistentes.
Relaciones inválidas entre tablas.
La validación ayuda a detectar estos problemas antes de que se propaguen a otras etapas del proyecto.
¿Cómo funciona la validación de datos?
El proceso consiste en definir reglas de calidad y comprobar si los datos las cumplen. Generalmente se siguen los siguientes pasos:
Definir reglas de validación.
Analizar los datos.
Detectar incumplimientos.
Generar alertas o informes.
Corregir o rechazar registros inválidos.
Volver a verificar los datos.
Las reglas pueden aplicarse a:
Una columna individual.
Varias columnas simultáneamente.
Una tabla completa.
Múltiples tablas relacionadas.
Tipos de validación de datos
Validación de rango: Comprueba que un valor se encuentre dentro de límites permitidos.
Validación de formato: Verifica que los datos sigan un formato determinado. Ejmp.: emails, teléfono, códigos postales, etc.
Validación de obligatoriedad: Comprueba que determinados campos no estén vacíos.
Validación de unicidad: Garantiza que ciertos valores no se repitan.
Validación de consistencia: Verifica que diferentes campos sean coherentes entre sí. Ejmp: fecha inicio / fecha fin.
Validación referencial: Comprueba relaciones entre tablas. Ejemplo: Cliente existente antes de crear un pedido, producto válido antes de registrar una venta.
Beneficios de la validación de datos
Mejora la calidad de los datos.
Reduce errores analíticos.
Incrementa la fiabilidad de los modelos.
Facilita el cumplimiento normativo.
Evita problemas operativos.
Incrementa la confianza en los resultados.
Reduce costes derivados de datos incorrectos.
¿Cuándo utilizar la validación de datos?
Durante la captura de datos.
En procesos ETL.
Antes del análisis exploratorio.
Antes de entrenar modelos.
Durante integraciones entre sistemas.
En entornos productivos.
Como parte de la monitorización continua.
La detección temprana de errores suele ser más eficiente que corregirlos posteriormente.
Ventajas
Detecta errores rápidamente.
Automatiza controles de calidad.
Reduce problemas en etapas posteriores.
Mejora la fiabilidad de los análisis.
Facilita auditorías de datos.
Puede integrarse en pipelines automatizados.
Incrementa la confianza en los datos.
Desventajas
Aunque es una práctica fundamental, también presenta algunos inconvenientes:
Requiere definir reglas adecuadas.
Puede aumentar la complejidad de los procesos.
Algunas validaciones son costosas computacionalmente.
Puede generar falsos positivos.
Necesita mantenimiento cuando cambian los requisitos del negocio.
Limitaciones
La validación de datos presenta ciertas limitaciones:
No corrige automáticamente todos los errores.
No detecta todos los problemas semánticos.
Depende de las reglas definidas.
Puede pasar por alto anomalías desconocidas.
No garantiza datos perfectos.
Un dato puede cumplir todas las reglas técnicas y seguir siendo incorrecto desde el punto de vista del negocio.
Comparación entre validación y limpieza de datos
Aspecto
Validación de Datos
Limpieza de Datos
Objetivo
Detectar problemas
Corregir problemas
Define reglas
Sí
No necesariamente
Corrige errores
No siempre
Sí
Automatización
Alta
Media
Prevención
Sí
Parcialmente
Diagnóstico
Sí
Parcialmente
La validación identifica incumplimientos mientras que la limpieza se centra en corregirlos.
Comparación entre validación y perfilado de datos
Aspecto
Validación de Datos
Perfilado de Datos
Basado en reglas
Sí
No necesariamente
Detecta incumplimientos
Sí
Sí
Analiza estadísticas
Limitado
Sí
Genera métricas descriptivas
No principalmente
Sí
Control de calidad
Alto
Medio
El perfilado ayuda a comprender los datos y la validación verifica si cumplen criterios específicos.
Aplicaciones en Data Science y Machine Learning
La validación de datos es fundamental en:
Machine Learning supervisado.
Machine Learning no supervisado.
Business Intelligence.
Ingeniería de datos.
Sistemas de recomendación.
Detección de fraude.
Analítica financiera.
Analítica de clientes.
Procesamiento de lenguaje natural.
Visión por computador.
Cualquier proyecto basado en datos requiere algún nivel de validación para garantizar la calidad de la información.
Impacto en los modelos de Machine Learning
Los modelos predictivos pueden verse afectados por:
Valores fuera de rango.
Etiquetas incorrectas.
Registros incompletos.
Variables inconsistentes.
Errores de formato.
Una validación adecuada ayuda a:
Reducir ruido.
Mejorar la precisión.
Disminuir sesgos.
Aumentar la robustez del modelo.
En muchos casos, mejorar la calidad de los datos genera más beneficios que modificar el algoritmo utilizado.
Implementación en Python
Validar valores nulos
import pandas as pddf = pd.read_csv("datos.csv")nulos = df.isnull().sum()print(nulos)
En caso de incumplimiento, Pandera generará una excepción indicando los registros inválidos.
Buenas prácticas
Al implementar validaciones es recomendable:
Definir reglas claras desde el inicio.
Automatizar validaciones repetitivas.
Documentar todas las reglas de negocio.
Validar datos antes de transformarlos.
Registrar incidencias detectadas.
Revisar periódicamente las reglas.
Integrar la validación dentro de pipelines ETL y ML.
Conclusión
La validación de datos es un proceso fundamental para garantizar que la información utilizada en análisis y modelos de Machine Learning cumpla criterios mínimos de calidad, consistencia y fiabilidad. Mediante la aplicación de reglas específicas, permite detectar errores antes de que afecten a los resultados o generen decisiones incorrectas.
Aunque no sustituye a la limpieza de datos ni al perfilado, constituye una pieza clave dentro de cualquier estrategia de calidad de datos. Una validación adecuada reduce riesgos, mejora la confianza en la información y contribuye a desarrollar modelos analíticos más precisos y robustos.
Guía completa para comprender y evaluar un conjunto de datos
Todo proyecto de Ciencia de Datos comienza con una pregunta fundamental: ¿qué calidad tienen los datos con los que voy a trabajar?
Antes de entrenar modelos de Machine Learning, construir visualizaciones o realizar análisis estadísticos, es imprescindible conocer la estructura, el contenido y el estado del conjunto de datos. Un modelo predictivo será tan bueno como la calidad de la información utilizada para entrenarlo, por lo que identificar problemas desde el inicio puede ahorrar muchas horas de trabajo y evitar decisiones incorrectas durante las etapas posteriores del proyecto.
El Data Profiling constituye la primera fase del proceso de preparación de datos. Su objetivo es realizar una evaluación objetiva del conjunto de datos para conocer su estructura, calidad y características principales antes de comenzar el Análisis Exploratorio de Datos (EDA), la ingeniería de características o el entrenamiento de modelos.
¿Qué es el Data Profiling?
El Data Profiling (perfilado de datos) es el proceso sistemático de inspeccionar, analizar y resumir las características estructurales y de calidad de un conjunto de datos.
Durante esta fase se recopilan estadísticas y métricas que permiten describir objetivamente el estado del dataset sin realizar todavía un análisis profundo de su contenido o de las relaciones entre variables.
El Data Profiling responde preguntas como:
¿Cuántos registros y variables contiene el conjunto de datos?
¿Qué tipo de dato tiene cada columna?
¿Existen valores faltantes?
¿Hay registros duplicados?
¿Cuál es la cardinalidad de cada variable?
¿Existen variables constantes o con muy poca variabilidad?
¿Se observan problemas evidentes de calidad de los datos?
¿Qué estadísticas descriptivas presentan las variables numéricas?
En otras palabras, el Data Profiling proporciona una radiografía del conjunto de datos, permitiendo conocer su estado antes de comenzar cualquier análisis.
Es importante destacar que el Data Profiling no busca descubrir patrones ni relaciones entre variables. Ese trabajo corresponde al Análisis Exploratorio de Datos (EDA), cuya finalidad es comprender el comportamiento del dataset y fundamentar las decisiones de preprocesamiento y modelado.
¿Por qué es importante el Data Profiling?
En la mayoría de proyectos los datos proceden de múltiples fuentes:
Bases de datos relacionales.
Sistemas ERP.
CRM.
APIs.
Archivos CSV o Excel.
Sensores IoT.
Aplicaciones web.
Plataformas de recopilación de datos.
Cada una de estas fuentes puede introducir problemas distintos:
Valores faltantes.
Registros duplicados.
Tipos de datos incorrectos.
Variables con escasa variabilidad.
Categorías inconsistentes.
Errores de codificación.
Variables innecesarias.
Si estos problemas no se detectan desde el principio, pueden propagarse durante todo el proyecto y afectar negativamente a las etapas posteriores.
El Data Profiling permite detectar estas incidencias antes de invertir tiempo en limpieza de datos, ingeniería de características o entrenamiento de modelos.
¿Cómo funciona el Data Profiling?
El perfilado de datos consiste en calcular automáticamente un conjunto de métricas descriptivas sobre el dataset.
Entre las comprobaciones más habituales se encuentran:
Dimensiones del conjunto de datos.
Tipos de datos de cada variable.
Estadísticas descriptivas.
Número de valores únicos.
Cardinalidad.
Valores faltantes.
Registros duplicados.
Variables constantes.
Consumo de memoria.
Distribución básica de las categorías.
Toda esta información se recopila en un informe que resume el estado inicial del conjunto de datos y sirve como punto de partida para el resto del proyecto.
El objetivo no es decidir todavía cómo tratar los problemas detectados, sino identificarlos y documentarlos.
Objetivos del Data Profiling
El Data Profiling persigue varios objetivos fundamentales:
Comprender la estructura del conjunto de datos.
Evaluar la calidad de los datos disponibles.
Detectar problemas evidentes antes del análisis.
Identificar variables problemáticas.
Documentar las características del dataset.
Facilitar la planificación del proceso de limpieza.
Reducir errores durante las etapas posteriores del proyecto.
En esta fase todavía no se decide cómo imputar valores faltantes, eliminar variables o construir nuevas características. Esas decisiones se tomarán posteriormente durante el EDA y la fase de ingeniería de características.
Tipos de Data Profiling
Dependiendo del objetivo del análisis, el perfilado puede centrarse en distintos aspectos del conjunto de datos.
Perfilado estructural: Analiza la organización general del dataset. Su objetivo es comprender cómo está construido el conjunto de datos. Incluye aspectos como:
Número de registros.
Número de variables.
Tipos de datos.
Consumo de memoria.
Longitud de campos.
Clasificación de variables.
Perfilado de contenido: Examina la información almacenada en cada variable. Este análisis permite detectar posibles anomalías en el contenido de las variables sin estudiar todavía su relación con otras variables. Normalmente incluye:
Valores mínimos y máximos.
Media, mediana y desviación estándar.
Valores únicos.
Cardinalidad.
Distribución de frecuencias.
Variables constantes.
Perfilado de calidad: Evalúa el estado general del conjunto de datos. Este perfilado proporciona una visión objetiva de la calidad de los datos disponibles y ayuda a planificar el proceso de limpieza. Entre las métricas más habituales se encuentran:
Completitud.
Unicidad.
Consistencia.
Validez.
Valores faltantes.
Registros duplicados.
Secuencia de tareas del Data Profiling
Aunque cada proyecto puede presentar necesidades específicas, el Data Profiling suele seguir una secuencia de trabajo bastante estable.
Una metodología reproducible podría ser la siguiente:
Cargar el conjunto de datos.
Comprobar las dimensiones del dataset.
Inspeccionar la estructura general mediante info().
Clasificar las variables según su naturaleza (numéricas, categóricas, ordinales, binarias, identificadores, etc.).
Obtener estadísticas descriptivas de las variables numéricas.
Analizar la cardinalidad y los valores únicos de las variables categóricas.
Detectar registros duplicados.
Calcular el número y porcentaje de valores faltantes.
Identificar variables constantes o con muy poca variabilidad.
Documentar todos los hallazgos obtenidos.
Esta secuencia permite construir un informe objetivo del estado inicial del conjunto de datos y constituye la base para las siguientes fases del proyecto.
Resultado esperado del Data Profiling
Al finalizar el Data Profiling debe disponerse de un conocimiento completo de la estructura y calidad del conjunto de datos. Concretamente, el analista debería ser capaz de responder a preguntas como:
¿Cuál es el tamaño del dataset?
¿Qué tipo de variables contiene?
¿Qué variables presentan valores faltantes?
¿Qué porcentaje de valores faltantes existe en cada variable?
¿Existen registros duplicados?
¿Hay variables constantes o con escasa variabilidad?
¿Cuál es la cardinalidad de las variables categóricas?
¿Se observan problemas de calidad que deban resolverse posteriormente?
Es importante destacar que el resultado del Data Profiling no es un conjunto de datos limpio, sino un informe técnico que describe el estado inicial del dataset.
Este informe constituye el punto de partida para la siguiente fase del proyecto: el Análisis Exploratorio de Datos (EDA). Mientras que el Data Profiling responde a la pregunta “¿Qué datos tengo?”, el EDA tratará de responder “¿Qué información contienen estos datos y cómo debo prepararlos para el modelado?”.
Beneficios del Data Profiling
Realizar un Data Profiling al inicio de un proyecto aporta numerosas ventajas, tanto desde el punto de vista técnico como organizativo.
Entre sus principales beneficios destacan:
Comprender rápidamente la estructura del conjunto de datos.
Detectar problemas de calidad antes de iniciar el análisis.
Identificar variables que requieren limpieza o transformación.
Reducir errores durante las etapas de preparación de datos.
Facilitar la documentación del proyecto.
Establecer una base sólida para el Análisis Exploratorio de Datos (EDA).
Mejorar la reproducibilidad del flujo de trabajo.
En proyectos complejos, dedicar tiempo al perfilado suele traducirse en una reducción significativa del tiempo invertido posteriormente en depuración y limpieza de datos.
¿Cuándo utilizar el Data Profiling?
El Data Profiling debe realizarse siempre que se trabaje con un nuevo conjunto de datos o cuando éste haya sufrido modificaciones importantes.
Los casos más habituales son:
Al iniciar un proyecto de Ciencia de Datos.
Antes del Análisis Exploratorio de Datos (EDA).
Antes de comenzar la limpieza de datos.
Durante procesos ETL (Extract, Transform and Load).
Al integrar nuevas fuentes de información.
Antes del entrenamiento de modelos de Machine Learning.
Durante auditorías de calidad de datos.
En la práctica, el Data Profiling constituye el primer paso de cualquier flujo de trabajo de preparación de datos.
Ventajas
Entre las principales ventajas del Data Profiling destacan:
Proporciona una visión global del conjunto de datos.
Detecta problemas de calidad de forma temprana.
Reduce el riesgo de errores durante el análisis.
Facilita la planificación de la limpieza de datos.
Mejora la documentación del proyecto.
Puede automatizarse mediante herramientas especializadas.
Favorece la reproducibilidad del análisis.
Desventajas
Aunque resulta una etapa imprescindible, también presenta algunas limitaciones prácticas:
Puede generar una gran cantidad de información en datasets muy extensos.
Requiere tiempo cuando el número de variables es elevado.
Algunas anomalías necesitan una revisión manual.
No determina automáticamente la mejor estrategia de tratamiento de los datos.
Determinadas comprobaciones requieren conocimiento del dominio del problema.
Limitaciones
Es importante comprender qué puede y qué no puede hacer el Data Profiling.
El perfilado de datos:
Identifica problemas, pero no los corrige.
Describe la estructura del dataset, pero no descubre relaciones complejas entre variables.
No determina automáticamente qué variables deben eliminarse.
No decide cómo imputar los valores faltantes.
No sustituye al Análisis Exploratorio de Datos (EDA).
Por este motivo, el Data Profiling debe considerarse una fase de diagnóstico cuyo objetivo es describir objetivamente el estado del conjunto de datos antes de iniciar su análisis.
Comparación entre Data Profiling y EDA
Aunque ambos procesos se realizan al comienzo de un proyecto de Ciencia de Datos, persiguen objetivos diferentes.
El Data Profiling responde a la pregunta:
¿Qué datos tengo?
Mientras que el Análisis Exploratorio de Datos (EDA) intenta responder:
¿Qué información contienen estos datos y qué decisiones debo tomar para preparar el modelo?
Aspecto
Data Profiling
EDA
Objetivo
Describir la estructura y calidad del dataset
Comprender el comportamiento de los datos
Pregunta principal
¿Qué datos tengo?
¿Qué información contienen?
Enfoque
Descriptivo
Analítico
Relaciones entre variables
No
Sí
Relación con la variable objetivo
No
Sí
Correlaciones
No
Sí
Tratamiento de valores faltantes
Identificación
Análisis y decisión de imputación
Outliers
Detección inicial
Estudio e interpretación
Visualizaciones
Básicas
Extensivas
Resultado
Informe técnico del dataset
Conclusiones para el preprocesamiento y modelado
En otras palabras, el Data Profiling identifica los posibles problemas, mientras que el EDA estudia su impacto y permite decidir cómo resolverlos.
Métricas habituales en el Data Profiling
Durante el perfilado suelen calcularse diversas métricas que permiten evaluar rápidamente la estructura y la calidad del conjunto de datos.
Porcentaje de valores faltantes
Mide la proporción de datos ausentes en una variable.
Cuando se desea obtener un informe completo de forma automática, una de las herramientas más utilizadas es ydata-profiling.
Instalación
pip install ydata-profiling
Generación del informe
from ydata_profiling import ProfileReportprofile = ProfileReport( df,title="Informe de Data Profiling")profile.to_file("data_profiling.html")
El informe generado incluye automáticamente:
Información general del dataset.
Estadísticas descriptivas.
Distribuciones de variables.
Valores faltantes.
Cardinalidad.
Variables constantes.
Duplicados.
Consumo de memoria.
Alertas sobre posibles problemas de calidad.
Aunque la herramienta también calcula correlaciones y otras métricas avanzadas, estas suelen utilizarse como apoyo durante el EDA y no sustituyen el análisis exploratorio realizado por el científico de datos.
Buenas prácticas
Al realizar un Data Profiling es recomendable:
Mantener separados el Data Profiling y el EDA.
Documentar todos los hallazgos relevantes.
Verificar los tipos de datos antes de comenzar el análisis.
Analizar siempre la presencia de valores faltantes y duplicados.
Identificar variables constantes o con escasa variabilidad.
Revisar la cardinalidad de las variables categóricas.
Automatizar el proceso cuando sea posible.
Repetir el perfilado tras cambios importantes en el conjunto de datos.
Conclusión
El Data Profiling constituye la primera etapa de cualquier proyecto de Ciencia de Datos. Su finalidad es describir objetivamente la estructura y la calidad del conjunto de datos mediante un conjunto de métricas y estadísticas que permiten conocer su estado inicial.
A diferencia del Análisis Exploratorio de Datos (EDA), el Data Profiling no busca descubrir patrones ni tomar decisiones sobre el tratamiento de los datos. Su función es proporcionar un diagnóstico fiable que sirva como base para las siguientes fases del proyecto.
Realizar un Data Profiling sistemático permite detectar problemas desde el inicio, documentar adecuadamente el conjunto de datos y establecer un flujo de trabajo reproducible. Una vez finalizada esta etapa, el proyecto está preparado para abordar el EDA, donde se estudiarán las relaciones entre variables, se analizará la variable objetivo y se definirán las estrategias de preprocesamiento e ingeniería de características que darán paso al entrenamiento de los modelos de Machine Learning.
La calidad de los datos (Data Quality) es el grado en que un conjunto de datos cumple los requisitos necesarios para ser utilizado de forma fiable en análisis, informes, procesos de negocio o modelos de Machine Learning.
Un conjunto de datos de alta calidad debe reflejar la realidad de manera precisa, consistente y completa. Por el contrario, los datos con errores, inconsistencias o información incompleta pueden conducir a conclusiones incorrectas y decisiones equivocadas.
En Data Science, suele decirse que un modelo es tan bueno como los datos con los que ha sido entrenado. Por esta razón, la calidad de los datos constituye uno de los pilares fundamentales de cualquier proyecto basado en datos.
¿Por qué es importante la calidad de los datos?
Las organizaciones toman decisiones utilizando información procedente de múltiples fuentes:
Bases de datos.
Sistemas ERP.
CRM.
Aplicaciones web.
Sensores IoT.
APIs externas.
Redes sociales.
Si los datos contienen errores o inconsistencias, las decisiones derivadas de ellos también pueden verse afectadas.
Por ejemplo:
Cliente
Edad
Ana
35
Pedro
-10
Marta
42
La edad negativa de Pedro representa un problema de calidad que puede distorsionar análisis estadísticos y modelos predictivos.
¿Cómo funciona la gestión de la calidad de los datos?
La calidad de los datos no es una técnica específica, sino un conjunto de procesos destinados a evaluar, monitorizar y mejorar los datos.
El proceso suele incluir:
Definición de estándares de calidad.
Evaluación de los datos.
Detección de errores.
Limpieza de datos.
Validación de reglas de negocio.
Monitorización continua.
Corrección de incidencias.
El objetivo es garantizar que los datos sean adecuados para el uso previsto.
Dimensiones de la calidad de los datos
La calidad de los datos suele evaluarse mediante varias dimensiones.
Exactitud: mide si los datos representan correctamente la realidad. Se refiere a datos que no representan el valor real de un registro, puede deberse a un error de registro u otros.
Completitud: Evalúa si los datos contienen toda la información necesaria. Registros incompletos
Consistencia: Verifica que los datos mantengan coherencia entre sistemas y registros. Ejemplo: Madrid / Madird, existe una inconsistencia que debe corregirse.
Validez: Comprueba que los datos cumplen las reglas definidas. Por ejemplo: edad negativa (-35)
Unicidad: Garantiza que no existan registros duplicados.
Actualidad: Evalúa si los datos están actualizados.
Ejemplo práctico
Supongamos el siguiente conjunto de datos:
Cliente
Edad
Ciudad
Dimension
Ana
35
Madrid
Pedro
NULL
Barcelona
Completitud
Ana
35
Madrid
Unicidad
Luis
180
Sevilla
Validez
Marta
28
Sevilla
Marta
28
seevilla
Consistencia
Beneficios de una alta calidad de datos
Entre los principales beneficios destacan:
Mayor fiabilidad de los análisis.
Mejor toma de decisiones.
Incremento de la precisión de los modelos.
Reducción de errores operativos.
Mayor confianza en los resultados.
Cumplimiento normativo más sencillo.
Menores costes derivados de datos incorrectos.
¿Cuándo evaluar la calidad de los datos?
La calidad de los datos debe evaluarse:
Antes de iniciar un análisis.
Antes de entrenar modelos de Machine Learning.
Durante procesos ETL.
Al integrar nuevas fuentes de información.
Antes de generar informes ejecutivos.
De forma periódica en entornos productivos.
La evaluación continua suele ser una práctica recomendada en organizaciones orientadas a los datos.
Ventajas
Las principales ventajas de trabajar con datos de alta calidad son:
Resultados más precisos.
Modelos más robustos.
Menor riesgo de errores.
Mejor experiencia de usuario.
Mayor eficiencia operativa.
Decisiones mejor fundamentadas.
Reducción de retrabajo.
Desventajas
Mantener altos niveles de calidad también implica algunos desafíos:
Requiere tiempo y recursos.
Puede implicar procesos complejos.
Necesita monitorización constante.
Puede requerir herramientas especializadas.
Algunas correcciones necesitan conocimiento del negocio.
Limitaciones
Aunque la calidad de los datos es fundamental, presenta ciertas limitaciones:
No elimina completamente el riesgo de errores.
No garantiza el éxito de un proyecto analítico.
Algunos problemas son difíciles de detectar.
La calidad puede degradarse con el tiempo.
Los criterios de calidad pueden variar según el contexto.
Un conjunto de datos puede ser excelente para una aplicación y resultar insuficiente para otra.
Comparación entre datos de alta y baja calidad
Característica
Alta Calidad
Baja Calidad
Exactitud
Alta
Baja
Completitud
Alta
Baja
Consistencia
Alta
Baja
Duplicados
Escasos
Frecuentes
Valores faltantes
Pocos
Muchos
Fiabilidad
Alta
Baja
Rendimiento de modelos
Mejor
Peor
Calidad de los datos vs Limpieza de datos
Estos conceptos suelen confundirse, pero no son equivalentes.
Aspecto
Calidad de los Datos
Limpieza de Datos
Objetivo
Evaluar y garantizar calidad
Corregir problemas
Alcance
Estratégico
Operativo
Proceso continuo
Sí
Generalmente puntual
Incluye monitorización
Sí
No necesariamente
Incluye correcciones
Parcialmente
Sí
La limpieza de datos es una de las herramientas utilizadas para mejorar la calidad de los datos.
Aplicaciones en Data Science y Machine Learning
La calidad de los datos es crítica en:
Machine Learning supervisado.
Machine Learning no supervisado.
Business Intelligence.
Sistemas de recomendación.
Detección de fraude.
Analítica financiera.
Predicción de demanda.
Procesamiento de lenguaje natural.
Visión por computador.
Analítica de clientes.
Prácticamente cualquier proyecto basado en datos depende de la calidad de la información disponible.
Impacto en los modelos de Machine Learning
Los problemas de calidad pueden afectar directamente al rendimiento de los modelos.
Por ejemplo:
Valores faltantes pueden impedir el entrenamiento.
Duplicados pueden introducir sesgos.
Etiquetas incorrectas reducen la precisión.
Outliers pueden distorsionar algunos algoritmos.
Datos inconsistentes generan ruido.
En muchos proyectos, mejorar la calidad de los datos produce mayores beneficios que cambiar de algoritmo.
Métricas de calidad de los datos
Algunas métricas utilizadas para evaluar la calidad son:
Estas métricas ayudan a monitorizar la evolución de la calidad de los datos a lo largo del tiempo.
Buenas prácticas
Al gestionar la calidad de los datos es recomendable:
Definir reglas de calidad desde el inicio.
Automatizar validaciones.
Monitorizar métricas periódicamente.
Documentar incidencias.
Mantener procesos reproducibles.
Validar nuevas fuentes de datos.
Establecer estándares de gobernanza.
Conclusión
La calidad de los datos es un factor esencial para garantizar que la información utilizada en análisis, informes y modelos de Machine Learning sea fiable, consistente y útil. No se trata únicamente de corregir errores, sino de establecer procesos que permitan evaluar, controlar y mejorar continuamente la información disponible.
Invertir en calidad de datos mejora la precisión de los análisis, incrementa la confianza en los resultados y contribuye al desarrollo de modelos más robustos y eficaces. En cualquier proyecto de Data Science, la calidad de los datos constituye una base imprescindible sobre la que construir decisiones y soluciones fundamentadas en evidencia.
La limpieza de datos (Data Cleaning o Data Cleansing) es el proceso de identificar, corregir o eliminar errores, inconsistencias e información incorrecta dentro de un conjunto de datos con el objetivo de mejorar su calidad y fiabilidad.
En Data Science y Machine Learning, la calidad de los datos es uno de los factores más importantes para el éxito de un proyecto. Un modelo entrenado con datos erróneos, incompletos o inconsistentes producirá resultados poco fiables, independientemente de la complejidad del algoritmo utilizado.
Por este motivo, la limpieza de datos constituye una de las primeras etapas del proceso de preparación de datos y suele consumir una parte significativa del tiempo dedicado a un proyecto analítico.
¿Por qué es importante la limpieza de datos?
Los datos procedentes de sistemas reales suelen contener problemas derivados de:
Errores humanos durante la introducción de información.
Fallos en sensores o dispositivos.
Integraciones entre múltiples sistemas.
Registros incompletos.
Problemas de formato.
Duplicidades.
Valores atípicos o anómalos.
Por ejemplo:
ID
Edad
1
35
2
42
3
-10
4
150
Los valores -10 y 150 probablemente representan errores que deben revisarse antes de utilizar los datos en un análisis.
¿Cómo funciona la limpieza de datos?
El proceso de limpieza suele incluir varias tareas:
Identificación de valores faltantes.
Detección de registros duplicados.
Corrección de errores de formato.
Estandarización de categorías.
Tratamiento de valores atípicos.
Validación de rangos permitidos.
Conversión de tipos de datos.
Eliminación de inconsistencias.
El objetivo es transformar un conjunto de datos bruto en un conjunto de datos preparado para el análisis o el modelado.
Ejemplo de limpieza de datos
Supongamos el siguiente conjunto de datos:
Cliente
Edad
Ciudad
Ana
35
Madrid
Pedro
NaN
Madrid
Ana
35
Madrid
Luis
250
Barcelona
Marta
28
barcelona
Durante el proceso de limpieza podríamos:
Imputar el valor faltante de Pedro.
Eliminar el registro duplicado de Ana.
Corregir la edad de Luis.
Estandarizar “Barcelona” y “barcelona”.
Resultado:
Cliente
Edad
Ciudad
Ana
35
Madrid
Pedro
32
Madrid
Luis
45
Barcelona
Marta
28
Barcelona
El conjunto de datos ahora presenta una mayor consistencia y calidad.
Principales problemas que aborda la limpieza de datos
La limpieza de datos se centra en resolver problemas frecuentes como:
Valores faltantes: Ocurren cuando una observación carece de información en una o varias variables. Ejemplos:
Campos vacíos.
Valores nulos.
Registros incompletos.
Datos duplicados: Se producen cuando una misma observación aparece más de una vez en el conjunto de datos. Esto puede generar sesgos y distorsionar los análisis.
Inconsistencias de formato: Algunos ejemplos son:
Fechas con formatos diferentes.
Variaciones de mayúsculas y minúsculas.
Unidades de medida distintas.
Valores atípicos: Son observaciones que se alejan significativamente del comportamiento habitual de los datos. Pueden representar:
Errores.
Casos excepcionales.
Fenómenos reales.
Errores tipográficos: Ejemplos:
“Madird” en lugar de “Madrid”.
“Barcelna” en lugar de “Barcelona”.
Beneficios de la limpieza de datos
Mejora la calidad de los datos.
Incrementa la precisión de los modelos.
Reduce errores analíticos.
Facilita la toma de decisiones.
Mejora la consistencia de la información.
Reduce sesgos producidos por errores.
Incrementa la confianza en los resultados.
¿Cuándo realizar la limpieza de datos?
Antes del análisis exploratorio.
Antes de construir modelos predictivos.
Antes de generar informes o dashboards.
Durante procesos ETL.
Antes de integrar múltiples fuentes de datos.
Siempre que se detecten problemas de calidad.
En la práctica, la limpieza suele ser una actividad continua durante todo el ciclo de vida del proyecto.
Ventajas de la limpieza de datos
Datos más fiables.
Modelos más precisos.
Mejor interpretabilidad.
Menor riesgo de errores.
Mayor consistencia.
Mejor rendimiento de algoritmos.
Mayor calidad de los análisis.
Desventajas
Aunque es una actividad fundamental, también presenta algunos inconvenientes:
Puede requerir mucho tiempo.
Algunas correcciones requieren conocimiento del negocio.
Existe riesgo de eliminar información valiosa.
Determinadas decisiones pueden introducir sesgos.
No siempre es posible identificar todos los errores.
Limitaciones
La limpieza de datos no resuelve todos los problemas de un conjunto de datos. Entre sus limitaciones se encuentran:
No corrige sesgos inherentes a la recopilación de datos.
No crea información que no existe.
No garantiza modelos perfectos.
Algunas anomalías pueden pasar desapercibidas.
La calidad final depende de las decisiones tomadas durante el proceso.
Además, una limpieza excesiva puede eliminar información relevante para el análisis.
Comparación entre datos limpios y datos sin limpiar
Característica
Datos sin limpiar
Datos limpios
Valores faltantes
Frecuentes
Tratados
Duplicados
Presentes
Eliminados o gestionados
Consistencia
Baja
Alta
Calidad analítica
Limitada
Mejorada
Rendimiento de modelos
Menor
Mayor
Fiabilidad de resultados
Baja
Alta
Aplicaciones en Data Science y Machine Learning
La limpieza de datos es una etapa fundamental en:
Machine Learning supervisado.
Machine Learning no supervisado.
Business Intelligence.
Análisis exploratorio de datos.
Sistemas de recomendación.
Procesamiento de lenguaje natural.
Analítica financiera.
Predicción de demanda.
Detección de fraude.
Visión por computador.
Prácticamente cualquier proyecto basado en datos requiere algún nivel de limpieza antes de comenzar el análisis.
Impacto en los modelos de Machine Learning
Los algoritmos de Machine Learning suelen ser sensibles a problemas de calidad en los datos. Por ejemplo:
Los valores faltantes pueden impedir el entrenamiento.
Los duplicados pueden introducir sesgos.
Los errores tipográficos generan categorías innecesarias.
Los outliers pueden distorsionar algunos modelos.
Por esta razón, la calidad de los datos suele influir tanto o más que la elección del algoritmo.
Flujo típico de limpieza de datos
Un proceso habitual puede seguir los siguientes pasos:
Explorar los datos.
Detectar valores faltantes.
Identificar duplicados.
Corregir formatos.
Revisar valores atípicos.
Estandarizar categorías.
Validar reglas de negocio.
Verificar la calidad final.
Este flujo puede variar según el tipo de proyecto y los datos disponibles.
Buenas prácticas
Al realizar limpieza de datos es recomendable:
Conservar siempre una copia de los datos originales.
Documentar todas las transformaciones realizadas.
Comprender el contexto de negocio antes de eliminar registros.
Automatizar procesos repetitivos.
Validar los resultados después de cada modificación.
Utilizar pipelines reproducibles.
Conclusión
La limpieza de datos es una de las etapas más importantes dentro de cualquier proyecto de Data Science y Machine Learning. Su objetivo es detectar y corregir problemas de calidad que puedan afectar al análisis, la interpretación de los datos o el rendimiento de los modelos predictivos.
Aunque suele requerir tiempo y conocimiento del dominio, sus beneficios superan ampliamente los costes asociados. Un conjunto de datos limpio, consistente y fiable constituye la base sobre la que se construyen análisis precisos, modelos robustos y decisiones basadas en evidencia. Por este motivo, la limpieza de datos debe considerarse un paso imprescindible antes de cualquier proceso de análisis o modelado.
Binary Encoding es una técnica de codificación de variables categóricas diseñada para representar categorías mediante números binarios. Su objetivo principal es reducir la dimensionalidad generada por técnicas como One-Hot Encoding sin perder la capacidad de transformar variables categóricas en datos numéricos utilizables por algoritmos de Machine Learning.
Esta técnica combina conceptos de Label Encoding y representación binaria. Primero asigna un identificador numérico a cada categoría y posteriormente convierte dicho identificador a formato binario.
Cada bit de la representación binaria se almacena en una columna independiente.
Binary Encoding es especialmente útil cuando se trabaja con variables categóricas de alta cardinalidad, es decir, variables que contienen un gran número de categorías distintas.
¿Cómo funciona?
El proceso consiste en:
Identificar las categorías únicas de la variable.
Asignar un identificador numérico a cada categoría.
Convertir cada identificador a representación binaria.
Crear una columna para cada bit generado.
Sustituir la variable original por las nuevas columnas binarias.
La conversión de un número decimal a binario puede expresarse como:
$$13_{10}=1101_{2}$$
Por ejemplo:
Categoría
Identificador
Binario
A
1
001
B
2
010
C
3
011
D
4
100
Cada dígito binario se convierte en una nueva característica.
Ejemplo de Binary Encoding
Supongamos la siguiente variable:
Ciudad
Madrid
Barcelona
Sevilla
Valencia
Asignamos un identificador:
Ciudad
Código
Madrid
1
Barcelona
2
Sevilla
3
Valencia
4
Convertimos cada código a binario:
Ciudad
Binario
Madrid
001
Barcelona
010
Sevilla
011
Valencia
100
Finalmente, cada bit se almacena en una columna independiente:
Ciudad
Bit_1
Bit_2
Bit_3
Madrid
0
0
1
Barcelona
0
1
0
Sevilla
0
1
1
Valencia
1
0
0
La variable categórica original queda completamente transformada en variables numéricas.
¿Por qué utilizar Binary Encoding?
Cuando una variable posee muchas categorías, One-Hot Encoding puede generar una enorme cantidad de columnas.
Por ejemplo:
1.000 categorías → 1.000 columnas con One-Hot Encoding.
1.000 categorías → aproximadamente 10 columnas con Binary Encoding.
Esto ocurre porque el número de columnas necesarias crece de forma logarítmica:
$$Columnas=\lceil\log_2(k)\rceil$$
Donde:
(k) es el número de categorías.
(\lceil \cdot \rceil) representa el redondeo hacia arriba.
Esta propiedad convierte a Binary Encoding en una técnica muy eficiente para variables de alta cardinalidad.
Beneficios de Binary Encoding
Reduce significativamente la dimensionalidad.
Genera menos columnas que One-Hot Encoding.
Funciona bien con variables de alta cardinalidad.
Disminuye el consumo de memoria.
Mantiene una representación numérica compacta.
Facilita el entrenamiento de modelos sobre grandes datasets.
Puede mejorar el rendimiento computacional.
¿Cuándo utilizar Binary Encoding?
Existen muchas categorías distintas.
One-Hot Encoding genera demasiadas columnas.
Se busca un equilibrio entre simplicidad y eficiencia.
Se trabaja con conjuntos de datos grandes.
La variable presenta alta cardinalidad.
Casos habituales:
Ciudades.
Códigos postales.
Productos.
Clientes.
Identificadores de usuario.
Categorías de comercio electrónico.
Ventajas
Menor dimensionalidad que One-Hot Encoding.
Escalabilidad para miles de categorías.
Bajo consumo de memoria.
Fácil integración en pipelines.
Compatible con la mayoría de algoritmos.
Reduce el riesgo de matrices extremadamente dispersas.
Conserva más información que algunas técnicas basadas en frecuencia.
Desventajas
Menos interpretable que One-Hot Encoding.
Introduce relaciones numéricas artificiales derivadas de la codificación.
Puede resultar difícil explicar cada columna generada.
Algunas categorías comparten parte de sus bits.
No incorpora información sobre la variable objetivo.
Por ejemplo:
Categoría
Binario
A
0101
B
0110
Ambas categorías comparten parte de la representación binaria, aunque no exista relación real entre ellas.
Limitaciones
No refleja similitudes semánticas entre categorías.
No utiliza información de la variable objetivo.
La interpretación de los bits no es intuitiva.
Puede generar relaciones artificiales entre categorías.
No siempre supera a One-Hot Encoding en rendimiento predictivo.
Además, algunos modelos lineales pueden verse afectados por las dependencias implícitas introducidas por la representación binaria.
Comparación con otras técnicas de codificación
Característica
Binary Encoding
One-Hot Encoding
Ordinal Encoding
Target Encoding
Incrementa dimensionalidad
Moderadamente
Mucho
No
No
Adecuado para alta cardinalidad
Sí
No
Sí
Sí
Utiliza información del target
No
No
No
Sí
Interpretabilidad
Media
Alta
Alta
Media
Consumo de memoria
Bajo
Alto
Muy bajo
Bajo
Riesgo de sobreajuste
Bajo
Bajo
Bajo
Alto
Binary Encoding vs One-Hot Encoding
Aspecto
Binary Encoding
One-Hot Encoding
Número de columnas
Bajo
Alto
Alta cardinalidad
Excelente
Problemática
Interpretabilidad
Media
Alta
Consumo de memoria
Bajo
Alto
Matrices dispersas
Menores
Mayores
Binary Encoding suele ser una alternativa muy atractiva cuando el número de categorías es elevado.
Binary Encoding vs Ordinal Encoding
Aspecto
Binary Encoding
Ordinal Encoding
Número de columnas
Varias
Una
Preserva orden natural
No
Sí
Adecuado para variables nominales
Sí
No
Riesgo de relaciones artificiales
Medio
Alto
Alta cardinalidad
Excelente
Buena
Aplicaciones en Data Science y Machine Learning
Binary Encoding aparece frecuentemente en:
Sistemas de recomendación.
Comercio electrónico.
Marketing digital.
Predicción de fraude.
Segmentación de clientes.
Modelos de scoring.
Analítica de usuarios.
Predicción de abandono.
Sistemas de clasificación.
Es especialmente útil en proyectos donde las variables categóricas contienen cientos o miles de categorías.
Algoritmos donde suele utilizarse
Binary Encoding puede utilizarse antes de algoritmos como:
Regresión logística.
Árboles de decisión.
Random Forest.
Gradient Boosting.
XGBoost.
LightGBM.
Redes neuronales.
Máquinas de vectores de soporte (SVM).
K-Nearest Neighbors (KNN).
Su capacidad para reducir dimensionalidad lo convierte en una opción interesante para muchos tipos de modelos.
Implementación en Python
La forma más sencilla de aplicar Binary Encoding es mediante la biblioteca category_encoders.
pip install category_encoders
Ejemplo básico
import pandas as pdimport category_encoders as cedf = pd.DataFrame({"ciudad": ["Madrid","Barcelona","Sevilla","Valencia" ]})encoder = ce.BinaryEncoder(cols=["ciudad"])df_encoded = encoder.fit_transform(df)print(df_encoded)
import category_encoders as ceencoder = ce.BinaryEncoder(cols=["ciudad", "producto"])df_encoded = encoder.fit_transform(df)
Uso dentro de un Pipeline
from sklearn.pipeline import Pipelinefrom sklearn.ensemble import RandomForestClassifierimport category_encoders as cepipeline = Pipeline([ ("encoder", ce.BinaryEncoder(cols=["ciudad"])), ("modelo", RandomForestClassifier())])pipeline.fit(X_train, y_train)
Este enfoque garantiza que la misma transformación se aplique tanto en entrenamiento como en producción.
Buenas prácticas
Al utilizar Binary Encoding es recomendable:
Aplicar la codificación únicamente sobre variables categóricas.
Ajustar el encoder usando exclusivamente los datos de entrenamiento.
Gestionar adecuadamente categorías no vistas.
Comparar su rendimiento con One-Hot Encoding y Target Encoding.
Evaluar el impacto sobre la interpretabilidad del modelo.
Conclusión
Binary Encoding es una técnica eficiente para transformar variables categóricas mediante representaciones binarias compactas. Su principal ventaja es la reducción significativa de dimensionalidad respecto a One-Hot Encoding, lo que la convierte en una excelente opción para variables de alta cardinalidad.
Aunque introduce cierta complejidad en la interpretación de los datos y puede generar relaciones artificiales entre categorías, ofrece un equilibrio muy interesante entre eficiencia computacional, consumo de memoria y capacidad predictiva. Por ello, es una técnica ampliamente utilizada en proyectos de Data Science y Machine Learning que manejan grandes volúmenes de categorías.
Count Encoding es una técnica de codificación de variables categóricas que sustituye cada categoría por el número de veces que aparece en el conjunto de datos.
En lugar de crear múltiples columnas, como ocurre con One-Hot Encoding, o asignar identificadores arbitrarios, como en Label Encoding, Count Encoding utiliza información estadística real para representar las categorías mediante su frecuencia absoluta de aparición.
Esta técnica resulta especialmente útil cuando se trabaja con variables de alta cardinalidad, es decir, variables que contienen un gran número de categorías distintas.
Por ejemplo, si una categoría aparece 500 veces en el conjunto de datos, será reemplazada por el valor 500.
¿Cómo funciona?
El proceso consiste en:
Identificar todas las categorías únicas de una variable.
Contar el número de apariciones de cada categoría.
Crear un diccionario de correspondencia entre categoría y número de ocurrencias.
Sustituir cada categoría por su conteo correspondiente.
La transformación puede expresarse como:
$$Count(c)=\sum_{i=1}^{N}I(x_i=c)$$
Donde:
(c) representa una categoría.
(I(x_i=c)) es una función indicadora que vale 1 cuando la observación pertenece a la categoría (c).
(N) es el número total de observaciones.
El resultado es un valor numérico que representa cuántas veces aparece cada categoría dentro del conjunto de datos.
Ejemplo de Count Encoding
Supongamos la siguiente variable:
Ciudad
Madrid
Barcelona
Madrid
Sevilla
Madrid
Barcelona
Calculamos el número de apariciones:
Ciudad
Conteo
Madrid
3
Barcelona
2
Sevilla
1
Tras aplicar Count Encoding:
Ciudad Original
Ciudad Codificada
Madrid
3
Barcelona
2
Madrid
3
Sevilla
1
Madrid
3
Barcelona
2
Cada categoría queda representada por su número total de apariciones.
Diferencia entre Count Encoding y Frequency Encoding
Ambas técnicas son muy similares, pero utilizan escalas distintas.
Característica
Count Encoding
Frequency Encoding
Valor asignado
Número de apariciones
Proporción de apariciones
Escala
Enteros
Decimales
Depende del tamaño del dataset
Sí
No
Interpretación
Conteo absoluto
Frecuencia relativa
Por ejemplo:
Ciudad
Count Encoding
Frequency Encoding
Madrid
300
0.60
Barcelona
150
0.30
Sevilla
50
0.10
Ambas técnicas contienen la misma información, pero representada de forma diferente.
¿Por qué utilizar Count Encoding?
Cuando una variable contiene cientos o miles de categorías, One-Hot Encoding puede generar una enorme cantidad de columnas.
Por ejemplo:
Código postal.
Ciudad.
Producto.
Cliente.
Proveedor.
Marca.
Count Encoding permite mantener una única columna y reducir significativamente el tamaño del conjunto de datos.
Beneficios de Count Encoding
Reduce la dimensionalidad.
Mantiene una sola columna por variable.
Es sencillo de implementar.
Utiliza información estadística real.
Funciona bien con variables de alta cardinalidad.
Reduce el consumo de memoria.
Puede acelerar el entrenamiento de modelos.
¿Cuándo utilizar Count Encoding?
Existen muchas categorías distintas.
Se desea evitar la explosión dimensional.
El número de apariciones de una categoría aporta información relevante.
Se trabaja con grandes volúmenes de datos.
Se busca una representación compacta.
Casos habituales:
Comercio electrónico.
Sistemas de recomendación.
Marketing digital.
Predicción de fraude.
Segmentación de clientes.
Modelos de scoring.
Ventajas
Bajo consumo de memoria.
No genera columnas adicionales.
Escala bien en datasets grandes.
Compatible con la mayoría de algoritmos.
Aprovecha información estadística de la variable.
Adecuado para variables de alta cardinalidad.
Desventajas
Categorías diferentes pueden recibir exactamente el mismo valor.
Se pierde parte de la identidad de las categorías.
No captura relaciones semánticas.
No utiliza información de la variable objetivo.
Puede generar ambigüedad cuando varias categorías tienen el mismo conteo.
Por ejemplo:
Categoría
Conteo
A
100
B
100
Tras la codificación, ambas categorías serán indistinguibles para el modelo.
Limitaciones
No incorpora información predictiva de la variable objetivo.
No refleja similitud entre categorías.
Puede perder capacidad discriminativa.
Las categorías raras pueden quedar infrarrepresentadas.
Los conteos dependen del conjunto de entrenamiento.
Además, si la distribución de categorías cambia con el tiempo, los valores calculados inicialmente pueden dejar de representar adecuadamente los datos futuros.
Comparación con otras técnicas de codificación
Característica
Count Encoding
One-Hot Encoding
Ordinal Encoding
Target Encoding
Mantiene una sola columna
Sí
No
Sí
Sí
Adecuado para alta cardinalidad
Sí
No
Sí
Sí
Utiliza información del target
No
No
No
Sí
Riesgo de sobreajuste
Bajo
Bajo
Bajo
Alto
Incrementa dimensionalidad
No
Sí
No
No
Preserva categorías individualmente
Parcialmente
Sí
Sí
Parcialmente
Count Encoding vs One-Hot Encoding
Aspecto
Count Encoding
One-Hot Encoding
Número de columnas
Una
Una por categoría
Alta cardinalidad
Excelente
Problemática
Consumo de memoria
Bajo
Alto
Velocidad de entrenamiento
Alta
Menor
Conservación de categorías
Parcial
Total
Count Encoding vs Frequency Encoding
Aspecto
Count Encoding
Frequency Encoding
Valores generados
Conteos absolutos
Frecuencias relativas
Escala dependiente del tamaño del dataset
Sí
No
Interpretación
Número de apariciones
Proporción de apariciones
Información contenida
Equivalente
Equivalente
En muchos problemas ambos métodos ofrecen resultados muy similares.
Aplicaciones en Data Science y Machine Learning
Count Encoding aparece frecuentemente en:
Sistemas de recomendación.
Predicción de fraude.
Marketing analítico.
Comercio electrónico.
Segmentación de clientes.
Predicción de abandono.
Scoring crediticio.
Análisis de comportamiento de usuarios.
Modelos de clasificación.
Es especialmente útil cuando se trabaja con variables categóricas de alta cardinalidad que hacen inviable el uso de One-Hot Encoding.
Algoritmos donde suele utilizarse
Count Encoding puede utilizarse antes de algoritmos como:
Regresión logística.
Árboles de decisión.
Random Forest.
Gradient Boosting.
XGBoost.
LightGBM.
CatBoost.
Redes neuronales.
Máquinas de vectores de soporte (SVM).
Al mantener una representación compacta, suele facilitar el entrenamiento en grandes conjuntos de datos.
Este enfoque garantiza que el mismo mapeo calculado durante el entrenamiento se aplique posteriormente a nuevos datos.
Buenas prácticas
Al utilizar Count Encoding es recomendable:
Calcular los conteos únicamente sobre el conjunto de entrenamiento.
Aplicar exactamente el mismo mapeo al conjunto de prueba.
Definir una estrategia para categorías no vistas.
Evaluar posibles colisiones entre categorías con igual conteo.
Comparar su rendimiento frente a Frequency Encoding y One-Hot Encoding.
Conclusión
Count Encoding es una técnica de codificación eficiente que sustituye cada categoría por su número de apariciones dentro del conjunto de datos. Gracias a su simplicidad y capacidad para manejar variables de alta cardinalidad, se ha convertido en una alternativa muy útil cuando One-Hot Encoding resulta costoso en términos de memoria y dimensionalidad.
Aunque puede perder información cuando varias categorías comparten el mismo conteo y no incorpora información de la variable objetivo, sigue siendo una herramienta valiosa para representar variables categóricas de forma compacta y eficiente en numerosos proyectos de Data Science y Machine Learning.
Frequency Encoding es una técnica de codificación de variables categóricas que sustituye cada categoría por la frecuencia con la que aparece en el conjunto de datos.
A diferencia de técnicas como One-Hot Encoding o Ordinal Encoding, no crea nuevas columnas ni asigna valores arbitrarios. En su lugar, utiliza información estadística real de los datos para representar cada categoría mediante su número de apariciones o su frecuencia relativa.
Esta técnica resulta especialmente útil cuando una variable contiene un gran número de categorías, ya que permite reducir la dimensionalidad sin perder información relacionada con la distribución de los datos.
¿Cómo funciona?
El proceso consiste en:
Identificar todas las categorías únicas de una variable.
Contar cuántas veces aparece cada categoría.
Calcular la frecuencia absoluta o relativa de cada una.
Sustituir cada categoría por su frecuencia correspondiente.
La frecuencia absoluta se calcula como:
$$Frecuencia(c)=Conteo(c)$$
La frecuencia relativa se obtiene mediante:
$$Frecuencia\ Relativa(c)=\frac{Conteo(c)}{N}$$
Donde:
(c) representa una categoría.
(Conteo(c)) es el número de veces que aparece la categoría.
(N) es el número total de observaciones.
Ejemplo de Frequency Encoding
Supongamos la siguiente variable:
Ciudad
Madrid
Barcelona
Madrid
Sevilla
Madrid
Barcelona
Calculamos las frecuencias:
Ciudad
Frecuencia
Madrid
3
Barcelona
2
Sevilla
1
Tras aplicar Frequency Encoding:
Ciudad Original
Ciudad Codificada
Madrid
3
Barcelona
2
Madrid
3
Sevilla
1
Madrid
3
Barcelona
2
Si se utiliza frecuencia relativa:
Ciudad
Frecuencia Relativa
Madrid
0.50
Barcelona
0.33
Sevilla
0.17
¿Por qué utilizar Frequency Encoding?
Cuando una variable contiene muchas categorías, técnicas como One-Hot Encoding pueden generar cientos o miles de nuevas columnas.
Por ejemplo:
Código postal.
Ciudad.
Producto.
Usuario.
Categoría de negocio.
En estos escenarios, Frequency Encoding permite mantener una única columna y reducir considerablemente el tamaño del dataset.
Beneficios de Frequency Encoding
Reduce la dimensionalidad.
Mantiene una única columna por variable.
Es sencillo de implementar.
Aprovecha información estadística real de los datos.
Escala bien con variables de alta cardinalidad.
Requiere poca memoria.
Puede mejorar la eficiencia computacional.
¿Cuándo utilizar Frequency Encoding?
Existen muchas categorías distintas.
Se desea evitar la explosión dimensional de One-Hot Encoding.
La frecuencia de aparición contiene información relevante.
Se trabaja con grandes volúmenes de datos.
La variable tiene alta cardinalidad.
Algunos ejemplos habituales son:
Códigos postales.
Ciudades.
Productos.
Clientes.
Identificadores de negocio.
Categorías de comercio electrónico.
Ventajas
Las principales ventajas son:
No incrementa el número de columnas.
Funciona bien con variables de alta cardinalidad.
Bajo consumo de memoria.
Fácil de interpretar.
Implementación sencilla.
Compatible con la mayoría de algoritmos de Machine Learning.
Captura información sobre la distribución de las categorías.
Desventajas
Categorías diferentes pueden recibir el mismo valor.
Se pierde la identidad original de algunas categorías.
No incorpora información directa sobre la variable objetivo.
Puede generar ambigüedad cuando varias categorías comparten frecuencia.
No representa relaciones semánticas entre categorías.
Por ejemplo:
Categoría
Frecuencia
A
50
B
50
Tras la codificación, ambas categorías serán idénticas para el modelo.
Limitaciones
Antes de aplicar esta técnica conviene considerar que:
No refleja similitud entre categorías.
No captura relaciones con la variable objetivo.
Puede perder información discriminativa.
Los valores dependen del conjunto de entrenamiento.
Nuevas categorías requieren un tratamiento especial.
Además, cuando la distribución de categorías cambia con el tiempo, las frecuencias calculadas inicialmente pueden dejar de ser representativas.
Comparación con otras técnicas de codificación
Característica
Frequency Encoding
One-Hot Encoding
Ordinal Encoding
Target Encoding
Mantiene una sola columna
Sí
No
Sí
Sí
Adecuado para alta cardinalidad
Sí
No
Sí
Sí
Conserva identidad completa de categorías
No
Sí
Sí
No
Utiliza información de la variable objetivo
No
No
No
Sí
Riesgo de sobreajuste
Bajo
Bajo
Bajo
Alto
Incrementa dimensionalidad
No
Sí
No
No
Frequency Encoding vs One-Hot Encoding
Aspecto
Frequency Encoding
One-Hot Encoding
Número de columnas
Una
Una por categoría
Alta cardinalidad
Excelente
Problemática
Consumo de memoria
Bajo
Alto
Interpretabilidad
Media
Alta
Riesgo de explosión dimensional
No
Sí
Frequency Encoding vs Target Encoding
Aspecto
Frequency Encoding
Target Encoding
Utiliza la variable objetivo
No
Sí
Riesgo de fuga de información
No
Sí
Facilidad de implementación
Alta
Media
Riesgo de sobreajuste
Bajo
Alto
Interpretabilidad
Alta
Media
Aplicaciones en Data Science y Machine Learning
Sistemas de recomendación.
Predicción de abandono de clientes.
Detección de fraude.
Marketing analítico.
Comercio electrónico.
Segmentación de clientes.
Modelos de scoring.
Predicción de demanda.
Sistemas de clasificación.
Es especialmente útil cuando se trabaja con variables categóricas de alta cardinalidad que dificultan la aplicación de One-Hot Encoding.
Algoritmos donde suele utilizarse
Regresión logística.
Árboles de decisión.
Random Forest.
Gradient Boosting.
XGBoost.
LightGBM.
CatBoost.
Redes neuronales.
Máquinas de vectores de soporte (SVM).
Al reducir la dimensionalidad, suele facilitar el entrenamiento de modelos sobre grandes volúmenes de datos.
Calcular las frecuencias únicamente sobre el conjunto de entrenamiento.
Aplicar exactamente el mismo mapeo al conjunto de prueba.
Definir una estrategia para categorías no vistas.
Evaluar posibles colisiones entre categorías con igual frecuencia.
Comparar su rendimiento frente a One-Hot Encoding y Target Encoding.
Conclusión
Frequency Encoding es una técnica eficiente para transformar variables categóricas sustituyendo cada categoría por su frecuencia de aparición en los datos. Su principal ventaja es que permite manejar variables de alta cardinalidad sin aumentar la dimensionalidad del conjunto de datos, manteniendo una representación compacta y fácil de implementar.
Aunque puede perder información cuando distintas categorías comparten la misma frecuencia, sigue siendo una alternativa muy útil en proyectos de Data Science y Machine Learning donde el tamaño del dataset y la eficiencia computacional son factores importantes. Utilizada correctamente, puede proporcionar una representación simple y efectiva de variables categóricas complejas sin incurrir en los problemas de dimensionalidad asociados a otras técnicas de codificación.
Ordinal Encoding es una técnica de transformación de datos utilizada para convertir variables categóricas en valores numéricos cuando existe un orden o jerarquía natural entre las categorías.
Muchos algoritmos de Machine Learning trabajan exclusivamente con datos numéricos y no pueden procesar directamente valores de texto como “Bajo”, “Medio” o “Alto”. Ordinal Encoding resuelve este problema asignando un número entero a cada categoría respetando su orden lógico.
Por ejemplo:
Nivel de satisfacción
Valor codificado
Bajo
1
Medio
2
Alto
3
En este caso, el modelo puede interpretar correctamente que “Alto” representa una categoría superior a “Medio” y “Medio” es superior a “Bajo”.
¿Cómo funciona Ordinal Encoding?
El proceso consiste en:
Identificar una variable categórica ordinal.
Definir el orden correcto de las categorías.
Asignar un valor numérico a cada nivel.
Sustituir las categorías originales por sus códigos numéricos.
Supongamos la siguiente variable:
Talla
Pequeña
Mediana
Grande
Extra Grande
Se puede codificar como:
Talla
Código
Pequeña
1
Mediana
2
Grande
3
Extra Grande
4
De esta forma se conserva la relación jerárquica entre categorías.
Ejemplo práctico
Imaginemos un conjunto de datos de evaluación de clientes:
Valoración
Mala
Regular
Buena
Excelente
Aplicando Ordinal Encoding:
Valoración
Código
Mala
1
Regular
2
Buena
3
Excelente
4
Ahora la variable puede utilizarse directamente en algoritmos de Machine Learning.
¿Por qué es necesario codificar variables categóricas?
Los modelos matemáticos trabajan con números y operaciones aritméticas. Cuando una variable contiene texto el algoritmo no puede calcular distancias, correlaciones o coeficientes. La codificación transforma estas categorías en valores numéricos manteniendo la información relevante para el modelo.
¿Cuándo utilizar Ordinal Encoding?
Esta técnica es recomendable cuando:
Existe una relación jerárquica entre categorías.
El orden de las categorías tiene significado.
Se desea conservar la información de ranking.
Las categorías representan niveles o escalas.
Ejemplos comunes:
Nivel educativo.
Grado de satisfacción.
Clasificación de riesgo.
Prioridad de incidencias.
Tallas de ropa.
Nivel de experiencia profesional.
Escalas de calidad.
Calificaciones académicas.
Casos donde NO debe utilizarse
No es recomendable cuando las categorías no tienen un orden natural.
Por ejemplo:
Color
Rojo
Azul
Verde
Si se codifican como:
Color
Código
Rojo
1
Azul
2
Verde
3
el modelo podría interpretar incorrectamente que Verde es “mayor” que Azul y Azul es “mayor” que Rojo. En estos casos suele ser preferible utilizar One-Hot Encoding.
Beneficios de Ordinal Encoding
Entre sus principales beneficios destacan:
Convierte variables categóricas en datos numéricos.
Conserva el orden natural de las categorías.
Reduce la dimensionalidad.
Genera una única columna por variable.
Es fácil de interpretar.
Tiene bajo coste computacional.
Resulta eficiente para grandes volúmenes de datos.
Ventajas de Ordinal Encoding
Las principales ventajas son:
Implementación sencilla.
Consumo mínimo de memoria.
Compatible con prácticamente cualquier algoritmo.
Mantiene la información jerárquica.
Evita la explosión de dimensiones.
Facilita el procesamiento de grandes datasets.
Además, al generar una sola columna codificada, resulta especialmente útil cuando existen muchas observaciones.
Desventajas de Ordinal Encoding
También presenta algunas limitaciones:
Puede introducir relaciones numéricas artificiales.
Algunos algoritmos interpretan las diferencias entre categorías como distancias reales.
La asignación incorrecta del orden puede degradar el rendimiento del modelo.
No es adecuada para variables nominales.
Por ejemplo:
Categoría
Código
Bajo
1
Medio
2
Alto
3
El algoritmo podría asumir que la diferencia entre Bajo y Medio es exactamente igual que entre Medio y Alto, lo cual no siempre es cierto.
Limitaciones
Antes de aplicar esta técnica conviene considerar que:
Requiere conocer el orden correcto de las categorías.
No refleja necesariamente distancias reales entre niveles.
Puede inducir sesgos en algunos modelos.
No resulta adecuada para variables sin jerarquía.
La codificación puede depender del contexto del problema.
Por ejemplo, una escala de satisfacción podría tener diferencias subjetivas entre categorías que no son uniformes.
Comparación con otras técnicas de codificación
Característica
Ordinal Encoding
One-Hot Encoding
Target Encoding
Conserva el orden
Sí
No
Parcialmente
Genera múltiples columnas
No
Sí
No
Adecuado para variables ordinales
Sí
No
Sí
Adecuado para variables nominales
No
Sí
Sí
Riesgo de sobreajuste
Bajo
Bajo
Alto
Consumo de memoria
Bajo
Alto
Bajo
Ordinal Encoding vs One-Hot Encoding
Aspecto
Ordinal Encoding
One-Hot Encoding
Número de columnas
1
Una por categoría
Conserva jerarquía
Sí
No
Uso de memoria
Bajo
Alto
Variables ordinales
Excelente
Poco recomendable
Variables nominales
No recomendado
Excelente
La regla general es sencilla:
Variables ordinales → Ordinal Encoding.
Variables nominales → One-Hot Encoding.
Aplicaciones en Data Science y Machine Learning
Ordinal Encoding aparece frecuentemente en:
Modelos de scoring crediticio.
Predicción de abandono de clientes.
Sistemas de evaluación de riesgos.
Recursos humanos.
Marketing analítico.
Segmentación de clientes.
Modelos de satisfacción del cliente.
Análisis educativo.
Predicción de calidad de productos.
También es habitual en datasets que contienen:
Niveles de satisfacción.
Rangos de ingresos.
Clasificaciones de riesgo.
Prioridades operativas.
Escalas de calidad.
Algoritmos donde suele utilizarse
Ordinal Encoding puede emplearse antes de algoritmos como:
Regresión logística.
Regresión lineal.
Árboles de decisión.
Random Forest.
Gradient Boosting.
XGBoost.
LightGBM.
Redes neuronales.
Máquinas de vectores de soporte (SVM).
No obstante, los algoritmos basados en distancias deben utilizarse con precaución, ya que podrían interpretar los códigos como magnitudes reales.
Implementación en Python
Scikit-Learn incluye la clase OrdinalEncoder para realizar esta transformación.
Este enfoque garantiza que la misma codificación se aplique tanto en entrenamiento como en producción.
Buenas prácticas
Al utilizar Ordinal Encoding es recomendable:
Verificar que existe un orden real entre categorías.
Definir explícitamente el orden.
Documentar la codificación utilizada.
Evitar aplicarlo a variables nominales.
Validar el impacto de la codificación sobre el rendimiento del modelo.
Utilizar pipelines para evitar inconsistencias.
Conclusión
Ordinal Encoding es una técnica fundamental de preparación de datos que permite transformar variables categóricas ordinales en valores numéricos preservando su estructura jerárquica. Su simplicidad, eficiencia y bajo consumo de memoria la convierten en una excelente opción cuando las categorías poseen un orden natural que aporta información relevante al modelo.
Sin embargo, debe utilizarse únicamente cuando existe una relación ordinal real entre las categorías. Aplicarla sobre variables nominales puede introducir relaciones artificiales y afectar negativamente al rendimiento de los algoritmos. Cuando se emplea correctamente, constituye una herramienta sencilla y eficaz para preparar datos categóricos en proyectos de Data Science y Machine Learning.