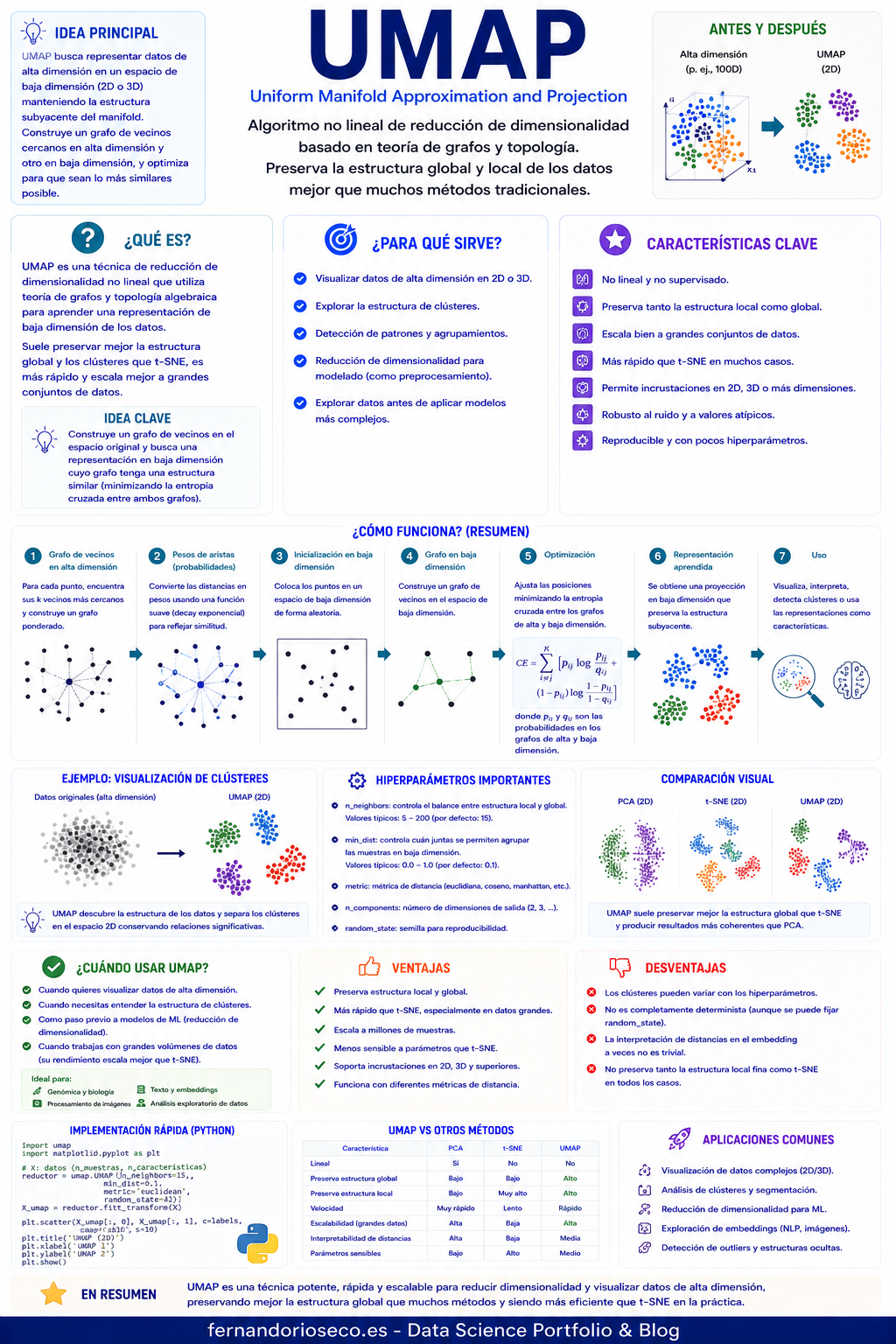
¿Qué es Unit Vector Scaling?
Unit Vector Scaling, también conocido como Normalization o Normalización por Vector Unitario, es una técnica de escalado que transforma cada observación de un conjunto de datos para que tenga una longitud o norma igual a 1.
A diferencia de otros métodos de escalado como Min-Max Scaling o Standard Scaling, que operan sobre las características (columnas), la normalización por vector unitario actúa sobre las observaciones (filas). Esto significa que cada registro es escalado de forma independiente.
El objetivo principal es conservar la dirección del vector mientras se elimina el efecto de su magnitud. En otras palabras, importa cómo están distribuidos los valores dentro de una observación, no el tamaño absoluto de esos valores.
Esta técnica es ampliamente utilizada en procesamiento de texto, sistemas de recomendación, análisis de similitud y algoritmos basados en distancia o ángulos.

¿Cómo funciona Unit Vector Scaling?
La normalización consiste en dividir cada valor de una observación por la norma del vector al que pertenece. La forma más habitual es utilizar la norma L2 (Euclidiana):
$$x_i^{‘}=\frac{x_i}{\sqrt{x_1^2+x_2^2+\cdots+x_n^2}}$$
Donde:
- \(x_i\) es un valor de la observación.
- El denominador representa la norma L2 del vector.
- \(x_i’\) es el valor normalizado.
Después de la transformación, la longitud del vector será exactamente igual a 1. Matemáticamente: \(|x|_2=1\)
Tipos de normalización más comunes
Scikit-Learn permite utilizar distintas métricas de normalización.
Norma L2
Es la más utilizada en Machine Learning.
$$||x||2=\sqrt{\sum{i=1}^{n}x_i^2}$$
Características:
- Mantiene la dirección del vector.
- Produce vectores de longitud 1.
- Muy utilizada en NLP y similitud coseno.
Norma L1
Se basa en la suma de valores absolutos.
$$||x||1=\sum{i=1}^{n}|x_i|$$
Características:
- Más robusta frente a valores extremos.
- Produce vectores cuya suma absoluta es 1.
Norma Max
Utiliza el valor máximo absoluto del vector.
$$||x||_{\infty}=max(|x_i|)$$
Características:
- Escala usando únicamente el valor de mayor magnitud.
- Menos utilizada en aplicaciones prácticas.
Ejemplo de Unit Vector Scaling
Supongamos la siguiente observación:
| Característica A | Característica B |
|---|---|
| 3 | 4 |
Calculamos la norma L2:
$$\sqrt{3^2+4^2}$$
$$\sqrt{9+16}$$
$$\sqrt{25}=5$$
Ahora dividimos cada valor por 5:
| Valor Original | Valor Normalizado |
|---|---|
| 3 | 0.6 |
| 4 | 0.8 |
La longitud del nuevo vector es: \(\sqrt{0.6^2+0.8^2}=1\). La dirección se mantiene exactamente igual, pero la magnitud desaparece.
Diferencia entre escalado y normalización
Es frecuente confundir ambos conceptos.
- Escalado: Modifica la escala de las variables, actúa sobre columnas. Ejemplos:
- Min-Max Scaling
- Standard Scaling
- Robust Scaling
- MaxAbs Scaling
- Normalización: Modifica cada observación individualmente, actúa sobre filas. La normalización busca igualar la longitud de todos los vectores. Ejemplos:
- L1 Normalization
- L2 Normalization
- Max Normalization
Beneficios de Unit Vector Scaling
- Elimina el efecto de la magnitud.
- Conserva la dirección de los datos.
- Facilita cálculos de similitud.
- Mejora algoritmos basados en distancia angular.
- Resulta especialmente útil en datos de alta dimensionalidad.
- Permite comparar observaciones independientemente de su tamaño.
- Reduce el impacto de diferencias de escala entre registros.
¿Cuándo utilizar Unit Vector Scaling?
- Se utilizan métricas de similitud.
- Se trabaja con vectores de texto.
- La dirección es más importante que la magnitud.
- Se emplea similitud coseno.
- Existen observaciones con tamaños muy diferentes.
- Se procesan datos de alta dimensionalidad.
Casos habituales:
- Motores de búsqueda.
- Sistemas de recomendación.
- Clasificación de documentos.
- Recuperación de información.
- Procesamiento de lenguaje natural.
Ventajas de Unit Vector Scaling
- Fácil de implementar.
- Mantiene la estructura relativa de cada observación.
- Muy útil para análisis de similitud.
- Funciona bien en espacios de alta dimensionalidad.
- Compatible con matrices dispersas.
- Reduce diferencias de magnitud entre registros.
- Mejora el rendimiento de algunos algoritmos de clustering y clasificación.
Desventajas de Unit Vector Scaling
- No reduce la influencia de outliers.
- No corrige distribuciones sesgadas.
- No centra los datos.
- Puede eliminar información útil relacionada con la magnitud.
- No siempre mejora el rendimiento predictivo.
En algunos problemas la magnitud contiene información importante que se perderá tras la normalización.
Limitaciones
Antes de aplicar esta técnica conviene considerar que:
- No elimina ruido.
- No trata valores faltantes.
- No corrige asimetrías.
- No transforma distribuciones no normales.
- No reduce la dimensionalidad.
- No es adecuada cuando la magnitud tiene significado predictivo.
Por ejemplo, en modelos financieros o de ventas, el tamaño absoluto de una variable puede ser tan importante como su proporción respecto a otras.
Comparación con otros métodos de escalado
Unit Vector Scaling vs Min-Max Scaling
Min-Max Scaling:
- Escala columnas.
- Lleva los datos a un rango determinado.
- Conserva diferencias de magnitud.
Unit Vector Scaling:
- Escala filas.
- Elimina la magnitud.
- Conserva únicamente la dirección.
Unit Vector Scaling vs Standard Scaling
Standard Scaling:
- Centra los datos en media cero.
- Utiliza la desviación estándar.
Unit Vector Scaling:
- No utiliza media ni desviación.
- Escala cada observación individualmente.
Unit Vector Scaling vs MaxAbs Scaling
MaxAbs Scaling:
- Escala variables.
- Mantiene la distribución original.
Unit Vector Scaling:
- Escala observaciones.
- Modifica completamente la magnitud de cada registro.
Aplicaciones en Data Science y Machine Learning
La normalización por vector unitario es especialmente importante en:
- Procesamiento de lenguaje natural (NLP).
- Análisis de documentos.
- Sistemas de recomendación.
- Recuperación de información.
- Análisis de similitud.
- Búsquedas semánticas.
- Embeddings de texto.
- Visión por computador.
- Detección de duplicados.
También suele utilizarse antes de algoritmos como:
- K-Nearest Neighbors (KNN).
- K-Means.
- Clustering jerárquico.
- Máquinas de vectores de soporte (SVM).
- Análisis de similitud coseno.
- Sistemas basados en embeddings.
Relación con la similitud coseno
Uno de los usos más importantes de la normalización es el cálculo de la similitud coseno. La similitud coseno mide el ángulo entre dos vectores y no depende de su tamaño. Su fórmula es:
$$\cos(\theta)=\frac{A\cdot B}{|A||B|}$$
Cuando ambos vectores han sido normalizados previamente, el cálculo se simplifica considerablemente porque sus normas son iguales a 1. Por esta razón, la normalización L2 es una práctica habitual en motores de búsqueda, sistemas de recomendación y modelos de lenguaje.
Implementación en Python
Scikit-Learn proporciona la función normalize y el transformador Normalizer.
Utilizando normalize()
from sklearn.preprocessing import normalize
import numpy as np
X = np.array([
[3, 4],
[1, 2],
[5, 12]
])
X_norm = normalize(X, norm='l2')
print(X_norm)
[[0.6 0.8 ]
[0.4472136 0.89442719]
[0.38461538 0.92307692]]Utilizando Normalizer
from sklearn.preprocessing import Normalizer
normalizer = Normalizer(norm='l2')
X_norm = normalizer.fit_transform(X)
print(X_norm)
[[0.6 0.8 ]
[0.4472136 0.89442719]
[0.38461538 0.92307692]]Normalización L1
from sklearn.preprocessing import Normalizer
normalizer = Normalizer(norm='l1')
X_l1 = normalizer.fit_transform(X)
print(X_l1)
[[0.42857143 0.57142857]
[0.33333333 0.66666667]
[0.29411765 0.70588235]]Uso dentro de un Pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import Normalizer
from sklearn.neighbors import KNeighborsClassifier
pipeline = Pipeline([
("normalizacion", Normalizer(norm='l2')),
("modelo", KNeighborsClassifier())
])
pipeline.fit(X_train, y_train)
Este enfoque garantiza que todas las observaciones reciban exactamente la misma transformación tanto durante el entrenamiento como durante la predicción.
Conclusión
Unit Vector Scaling o Normalization es una técnica de transformación que convierte cada observación en un vector de longitud unitaria, preservando su dirección y eliminando las diferencias de magnitud. A diferencia de los métodos tradicionales de escalado, opera sobre filas en lugar de columnas, lo que la hace especialmente útil cuando el interés se centra en las relaciones relativas entre variables dentro de cada observación.
Su aplicación es fundamental en áreas como procesamiento de lenguaje natural, recuperación de información, sistemas de recomendación y análisis de similitud, donde la orientación de los vectores resulta más importante que su tamaño absoluto. Aunque no corrige problemas estadísticos como outliers o distribuciones sesgadas, sigue siendo una de las técnicas más utilizadas en entornos de Machine Learning basados en medidas de distancia y similitud.