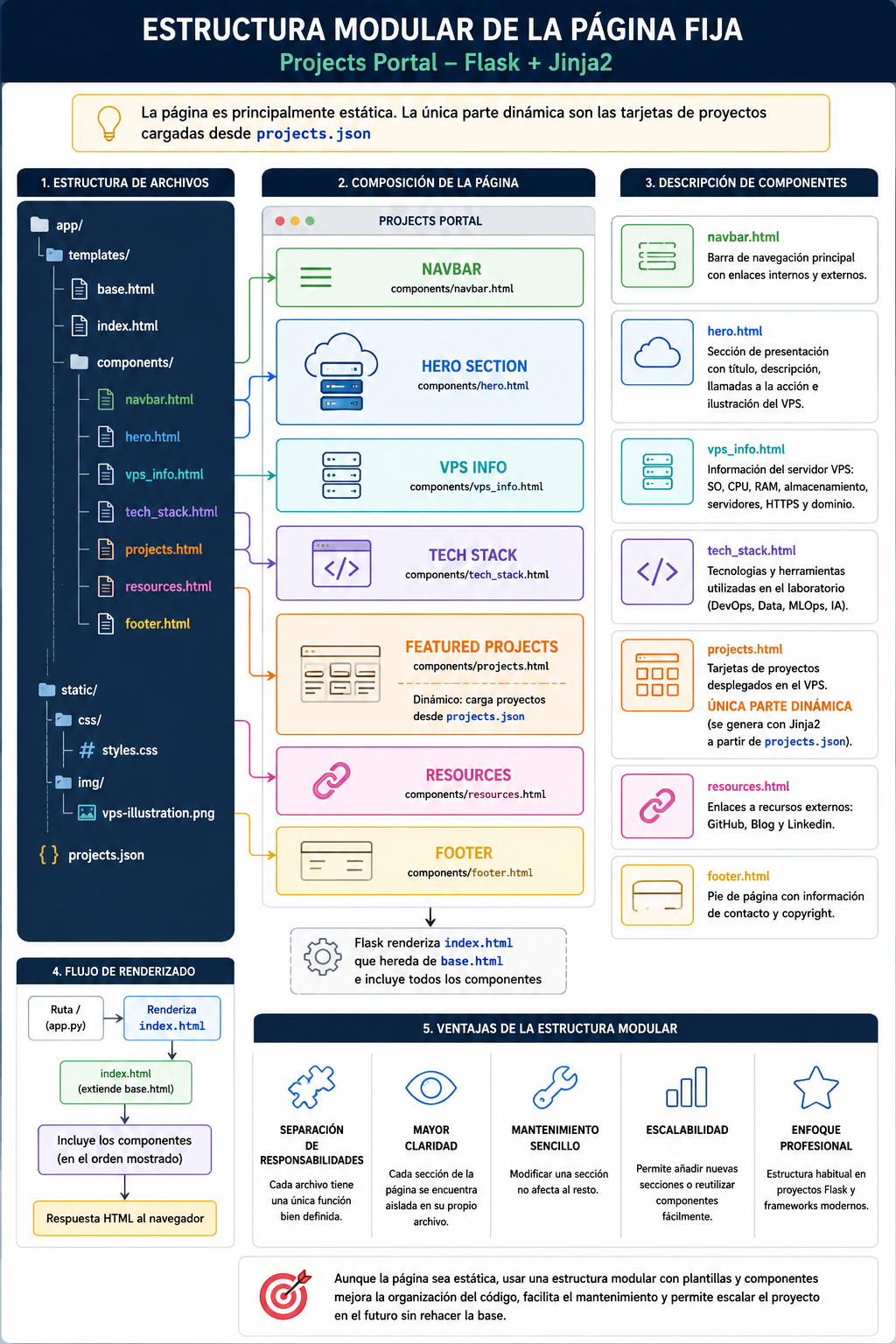
Introducción
Hasta este punto del flujo de trabajo de Machine Learning, hemos cubierto la extracción de datos desde diversas fuentes, la limpieza profunda del dataset y el Análisis Exploratorio de Datos (EDA).
Sin embargo, antes de proceder a entrenar cualquier algoritmo, los datos en bruto (raw data) rara vez están listos para ofrecer un rendimiento óptimo. La Ingeniería de Características (Feature Engineering) y la Transformación de Variables constituyen la etapa puente donde adaptamos y refinamos nuestra información para maximizar la precisión de los modelos.
Objetivos de Aprendizaje de este Bloque
- Transformación No Lineal: Entender cómo ciertas operaciones matemáticas modifican la distribución de los datos para mitigar el impacto de valores atípicos y estabilizar la varianza.
- Codificación de Características (Feature Encoding): Dado que los modelos matemáticos de Machine Learning operan estrictamente con variables numéricas, aprenderemos a mapear y traducir variables categóricas (como textos o etiquetas) a representaciones numéricas inteligibles por el modelo.
- Escalado de Características (Feature Scaling): En el mundo real, cada variable viene expresada en su propia escala (por ejemplo, la edad de 0 a 100 frente al salario anual de miles de dólares). Aprenderemos a homogeneizar estos rangos, una propiedad crítica para la convergencia de muchos algoritmos.
Supuestos de los Modelos: El Caso de la Regresión Lineal
La mayoría de los algoritmos de Machine Learning se fundamentan en presunciones teóricas sobre la naturaleza y distribución de los datos. El ejemplo arquetípico es la Regresión Lineal, la cual asume de manera estricta que existe una relación lineal entre las variables predictoras (características de entrada) y la variable objetivo o etiqueta (target).
Estructura de un Modelo Lineal
Para relacionar dos variables predictoras ($x_1$ y $x_2$) con una variable de salida ($y$), planteamos la siguiente ecuación matemática:
$$f(x) = \beta_0 + \beta_1 x_1 + \beta_2 x_2$$
Donde:
- $\beta_0$ representa el intercepto (el valor de $y$ cuando todos los predictores son cero).
- $\beta_1$ y $\beta_2$ son los coeficientes o pesos matemáticos asociados a cada variable.
- El objetivo del algoritmo durante el entrenamiento es aprender los valores óptimos de estos parámetros ($\beta_0, \beta_1, \beta_2$) a partir de los datos históricos.
Ejemplo Práctico: Predicción de Taquilla Financiera (Box Office)
Para visualizar el comportamiento de un modelo lineal en el ámbito de los negocios, consideremos el escenario de predecir la recaudación de ingresos de una película en taquilla ($y$):
- Variable Predictora $x_1$: Presupuesto asignado al reparto (Cast Budget).
- Variable Predictora $x_2$: Presupuesto asignado a la campaña de mercadotecnia (Marketing Budget).
En este diseño, los coeficientes $\beta_1$ y $\beta_2$ cuantificarán matemáticamente el impacto individual de cada presupuesto en la estimación de la recaudación final.
En un sentido estrictamente matemático, la “linealidad” del modelo significa que la función avanza mediante la adición o suma de cada parámetro multiplicado por su respectivo coeficiente.
Flexibilidad mediante la Transformación
Un error común es pensar que si la relación original entre el presupuesto y la taquilla tiene una forma curva o exponencial, la regresión lineal deja de ser útil. La realidad es que podemos aplicar una transformación matemática a los datos de entrada en bruto (por ejemplo, calcular el logaritmo de $x_1$ o elevar $x_2$ al cuadrado).
Al sustituir el valor en bruto por su equivalente transformado, el modelo sigue operando bajo una estructura lineal (una suma de coeficientes multiplicados por la variable), pero ahora es capaz de capturar relaciones complejas y no lineales del mundo real:
$$f(x) = \beta_0 + \beta_1 \cdot \text{transformación}(x_1) + \beta_2 \cdot \text{transformación}(x_2)$$
A partir de la próxima sesión, desglosaremos las técnicas específicas para codificar, transformar y escalar estas variables antes de alimentar nuestros algoritmos.
El Supuesto de Normalidad en los Residuos
En el marco teórico-matemático de la Regresión Lineal, existe un supuesto fundamental: los residuos (o errores) del modelo final deben seguir una distribución normal. Los residuos representan la diferencia entre los valores reales observados y las predicciones calculadas por el algoritmo.
En el mundo real, los datos en bruto rara vez son perfectos. Con frecuencia, tanto las variables predictoras como la variable objetivo presentan sesgos significativos:
- Sesgo Positivo (Right-Skewed): Los datos se concentran en valores bajos y la distribución presenta una “cola” larga hacia la derecha (por ejemplo, los salarios de una empresa o el presupuesto de las películas).
- Sesgo Negativo (Left-Skewed): Los datos se concentran en valores altos y la cola se extiende hacia la izquierda.
Si alimentamos un modelo de regresión lineal con datos crudos fuertemente sesgados, el algoritmo tendrá dificultades para optimizar sus parámetros de forma correcta, rompiendo el supuesto de normalidad en los errores. Las transformaciones de variables modifican la escala geométrica de los datos para estabilizar su varianza y aproximarlos a una distribución normal.
Técnicas de Transformación No Lineal
Para corregir el sesgo e inducir normalidad, la librería NumPy y el ecosistema científico de Python proveen varias funciones matemáticas clave:
- Logaritmo Natural (
np.log): Comprime los valores extremadamente altos y expande los valores bajos. Es la herramienta por excelencia para mitigar el sesgo positivo. - Logaritmo Más Uno (
np.log1p): Dado que matemáticamente el logaritmo de cero no está definido ($\log(0) \to -\infty$), si tu dataset contiene ceros reales, utilizarnp.logromperá el código. La funciónlog1pcalcula automáticamente $\log(x + 1)$, solucionando este problema de forma segura. - Transformación Box-Cox (
scipy.stats.boxcox): Es una metodología más compleja y automatizada. A través de un parámetro lambda ($\lambda$), evalúa el dataset y encuentra de manera matemática la transformación de potencia exacta requerida para convertir una distribución sesgada en una normal.
El Efecto Visual de la Transformación Logarítmica
Al aplicar un logaritmo a un conjunto de datos con sesgo positivo, la distribución se redistribuye simétricamente:
Modelado de Rendimientos Decrecientes y Polinomios
Además de corregir la distribución, las transformaciones permiten que un algoritmo lineal capture dinámicas no lineales de la realidad económica y comercial.
Rendimientos Decrecientes (Diminishing Returns)
Consideremos la relación entre el presupuesto de una película ($x$) y la recaudación en taquilla ($y$). Un incremento de 5 millones de dólares en el presupuesto de una película independiente puede triplicar sus ganancias; sin embargo, ese mismo aumento en una superproducción multimillonaria apenas alterará su recaudación final.
Esta estructura curva de saturación representa un rendimiento decreciente. Aunque la relación original no es una línea recta, es perfectamente lineal respecto al logaritmo de los datos:
$$f(x) = \beta_0 + \beta_1 \cdot \log(x)$$
El modelo resultante sigue considerándose una regresión lineal porque la ecuación mantiene una combinación lineal (sumas y multiplicaciones directas) de los coeficientes respecto a las características, aun cuando la característica en sí sea $\log(x)$ en lugar de $x$.
Características Polinomiales (Polynomial Features)
Si los datos describen curvas más complejas con puntos de inflexión (donde la tendencia cambia de dirección), podemos elevar el grado de nuestras variables mediante polinomios.
- Grado 2 (Cuadrática): Al incorporar el término $x^2$, el modelo adquiere la flexibilidad de una parábola. Tiene un punto de inflexión (la curva sube y luego baja).$$f(x) = \beta_0 + \beta_1 x + \beta_2 x^2$$Ejemplo: En niveles extremos, un presupuesto exageradamente alto podría generar pérdidas netas debido a la imposibilidad de recuperar la inversión en taquilla.
- Grado 3 o Superior (Cúbica): Al incorporar $x^3$, el modelo puede capturar dos puntos de inflexión (la curva sube, baja y vuelve a subir).
Implementación de Transformaciones Polinomiales con Scikit-Learn
Para automatizar la creación de términos cuadráticos o cúbicos sin necesidad de calcular las potencias columna por columna de forma manual, la librería Scikit-Learn ofrece el módulo PolynomialFeatures.
En Scikit-Learn, estas herramientas operan bajo el patrón de diseño de objetos transformadores, los cuales ejecutan dos pasos fundamentales:
.fit(): El objeto analiza la estructura del dataset de entrada para aprender las dimensiones y variables disponibles..transform(): Utiliza las reglas aprendidas en el entrenamiento para generar un nuevo conjunto de datos con las columnas polinomiales calculadas.
Código de Implementación en Python
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
# 1. Supongamos que tenemos una matriz de datos original (X_data)
# Para este ejemplo, una columna con valores del 1 al 3
X_data = np.array([[1], [2], [3]])
# 2. Instanciar la clase especificando el grado deseado (ej. Grado 2)
# Por defecto, incluye también el término de sesgo (columna de unos)
polyFeat = PolynomialFeatures(degree=2, include_bias=False)
# 3. Ajustar el transformador a los datos para que aprenda las dimensiones
polyFeat.fit(X_data)
# 4. Transformar la característica original 'x' en el nuevo espacio 'x, x^2'
X_poly = polyFeat.transform(X_data)
# Visualización del cambio estructural
print("Datos Originales:\n", X_data)
print("\nDatos Polinomiales (x, x^2):\n", X_poly)
Análisis del Output
Al imprimir la matriz generada X_poly, observamos cómo el transformador expandió automáticamente el espacio de características:
Datos Originales:
[[1]
[2]
[3]]
Datos Polinomiales (x, x^2):
[[1. 1.]
[2. 4.]
[3. 9.]]
La primera columna conserva los valores originales ($x$) y la segunda columna almacena de manera automática sus valores elevados al cuadrado ($x^2$). A partir de este momento, la matriz X_poly está lista para ser introducida en un algoritmo de regresión lineal estándar, permitiéndole trazar curvas y capturar patrones de negocio sofisticados.
Preparación de Variables: Codificación y Escalado
La selección de variables consiste en elegir el conjunto óptimo de características (features) que formarán parte de nuestro modelo. Sin embargo, antes de poder alimentar cualquier algoritmo, la mayoría de estas características deben ser transformadas. Los modelos matemáticos de Machine Learning no entienden de texto ni de etiquetas cualitativas; operan bajo matrices numéricas estrictas.
Más allá de las transformaciones logarítmicas y polinomiales, existen dos pilares fundamentales en la ingeniería de características:
- Codificación (Encoding): El proceso de convertir características no numéricas (cualitativas, categóricas u ordinales) en valores numéricos.
- Escalado (Scaling): La homogeneización del rango de las variables numéricas para que compartan una escala comparable y ningún predictor domine a otro por su magnitud matemática.
El método idóneo para transformar nuestros datos dependerá enteramente de la naturaleza intrínseca de la característica, dividiéndose principalmente en dos grandes tipologías:
Tipos de Datos Categóricos
│
┌────────────────────────┴────────────────────────┐
▼ ▼
Datos Nominales Datos Ordinales
(Sin orden jerárquico) (Con orden intrínseco)
Ej: Colores (Rojo, Azul) Ej: Rangos (Bajo, Medio, Alto)
Ej: Estado (Casado, Soltero) Ej: Temperatura (Frío, Templado, Caliente)
Estrategias de Codificación Categórica
Codificación Binaria (Binary Encoding)
Es la técnica de mapeo más simple y se aplica de forma exclusiva a variables dicotómicas, es decir, aquellas que solo pueden tomar dos valores posibles. Consiste en transformar la condición de la variable en un estado booleano de $0$ o $1$ (Falso o Verdadero).
- Ejemplos: * ¿Está casado? $\to$
No = 0,Sí = 1- Género $\to$
Masculino = 0,Femenino = 1 - Estado de transacción $\to$
Fallida = 0,Exitosa = 1
- Género $\to$
Codificación One-Hot (One-Hot Encoding)
Cuando nos enfrentamos a variables de tipo nominal con múltiples categorías sin orden implícito (como el color o el país de residencia), la codificación binaria simple se queda corta. Si asignáramos números correlativos ($1, 2, 3$) a una columna llamada Color (Rojo=1, Azul=2, Verde=3), el modelo interpretaría erróneamente que el Verde vale tres veces más que el Rojo, o que el Azul está “en medio” de ambos, distorsionando las operaciones matemáticas del algoritmo.
Para solucionar esto, One-Hot Encoding expande la columna original en múltiples columnas binarias independientes (tantas como categorías existan). Cada nueva columna representa una categoría exclusiva: si el registro original pertenecía a esa categoría se le asigna un $1$, y al resto un $0$.
Ejemplo de Transformación:
Supongamos que tenemos un DataFrame con una sola columna llamada Color:
| ID | Color |
| 1 | Rojo |
| 2 | Azul |
| 3 | Verde |
| 4 | Rojo |
Tras aplicar la transformación One-Hot Encoding, nuestro conjunto de datos se reestructura de la siguiente manera:
| ID | Color_Rojo | Color_Azul | Color_Verde |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | 1 | 0 | 0 |
Codificación Ordinal (Ordinal Encoding)
A diferencia de los datos nominales, los datos ordinales sí poseen una jerarquía u orden integrado en su significado. En estos escenarios, convertir las etiquetas en números enteros secuenciales es completamente válido y deseable, ya que preserva la progresión de la variable.
- Ejemplo: Niveles de riesgo o prioridad $\to$
Bajo = 1,Medio = 2,Alto = 3.
El Dilema de la Distancia Geométrica: Al aplicar una codificación ordinal de $1, 2, 3$, le estamos indicando implícitamente al algoritmo que la distancia matemática entre
BajoyMedio($2 – 1 = 1$) es exactamente la misma que entreMedioyAlto($3 – 2 = 1$). En el mundo real, esta equidistancia métrica podría no existir.
Criterios de Selección: ¿One-Hot u Ordinal?
A medida que avances en tus proyectos de ciencia de datos, te enfrentarás al dilema de cuál técnica elegir para tus variables ordenadas. Tienes dos opciones principales:
- Mantener el orden (Ordinal Encoding): Utilizas una sola columna con enteros ($1, 2, 3$). La ventaja es que conservas la noción de progresión y jerarquía, y el dataset no crece en tamaño. La desventaja es que asumes distancias matemáticas artificiales entre categorías.
- Privilegiar la separación (One-Hot Encoding): Rompes la variable en múltiples columnas binarias. La ventaja es que eliminas el supuesto de las distancias fijas, permitiendo al modelo tratar cada estado de forma independiente. La desventaja es que pierdes por completo la información del orden secuencial y aumentas la dimensionalidad del dataset.
No existe una respuesta única; experimentar con ambas estrategias en tus Jupyter Notebooks y evaluar el impacto directo en la precisión del modelo te dará el criterio necesario para tomar la mejor decisión en cada caso de negocio.
Fundamentos del Escalado de Características (Feature Scaling)
El escalado de características es una etapa crítica en el procesamiento de datos que consiste en ajustar los rangos de nuestras variables continuas para que compartan una magnitud matemática comparable.
En los conjuntos de datos del mundo real, las variables vienen expresadas en unidades y magnitudes completamente dispares. Por ejemplo, si analizamos el éxito comercial de un artículo, podríamos tener:
- Precio del producto: Con valores que oscilan entre $0$ y $10$ dólares.
- Puntos de venta distribuidos: Con valores que oscilan entre $10,000$ y $50,000$ tiendas.
Si alimentamos un modelo directamente con estas métricas en bruto, la disparidad de magnitudes distorsionará los cálculos de muchos algoritmos, haciendo que una variable eclipse por completo a la otra debido a su tamaño numérico y no a su verdadera importancia analítica.
El Impacto de la Magnitud en los Algoritmos de Distancia
Para entender por qué la diferencia de escalas representa un problema crítico, analicemos el comportamiento de los algoritmos basados en proximidad geométrica, como K-Nearest Neighbors (KNN) o los modelos de clasificación médica.
Imaginemos un sistema diseñado para identificar pacientes en situación de riesgo. El algoritmo mapea a los individuos en un plano bidimensional y determina el diagnóstico de un nuevo paciente evaluando la distancia geométrica hacia sus “vecinos” más cercanos (es decir, si se sitúa cerca de pacientes de alto riesgo o cerca de pacientes sanos).
Un Ejemplo Extremo: Edad en Segundos vs. Operaciones Quirúrgicas
Para ilustrar la distorsión, supongamos que registramos dos variables para evaluar el riesgo clínico de un paciente:
- Número de cirugías previas: Un indicador crítico donde una variación de $1$ a $10$ cirugías denota un cambio drástico en la fragilidad del paciente. (Rango de variación: $9$ unidades).
- Edad del paciente: Supongamos que, por un error de diseño o de captura, la edad se mide en segundos en lugar de años.
Dado que un solo año equivale aproximadamente a $31.5$ millones de segundos, la diferencia de edad entre dos personas de 20 y 21 años se traducirá matemáticamente en una distancia de $31,500,000$ unidades.
La Consecuencia Matemática:
Al calcular la distancia geométrica (como la distancia euclidiana), el algoritmo procesará estos valores numéricos fríos:
- La brecha crítica de cirugías se pondera como un cambio insignificante de $9$ unidades.
- La diferencia de un solo año de edad se pondera como un abismo de $31.5$ millones de unidades.
Como resultado, el modelo agrupará a los pacientes basándose únicamente en que tengan exactamente la misma edad, ignorando por completo el número de cirugías. La escala ha sesgado la geometría del problema, anulando el poder predictivo del historial médico.
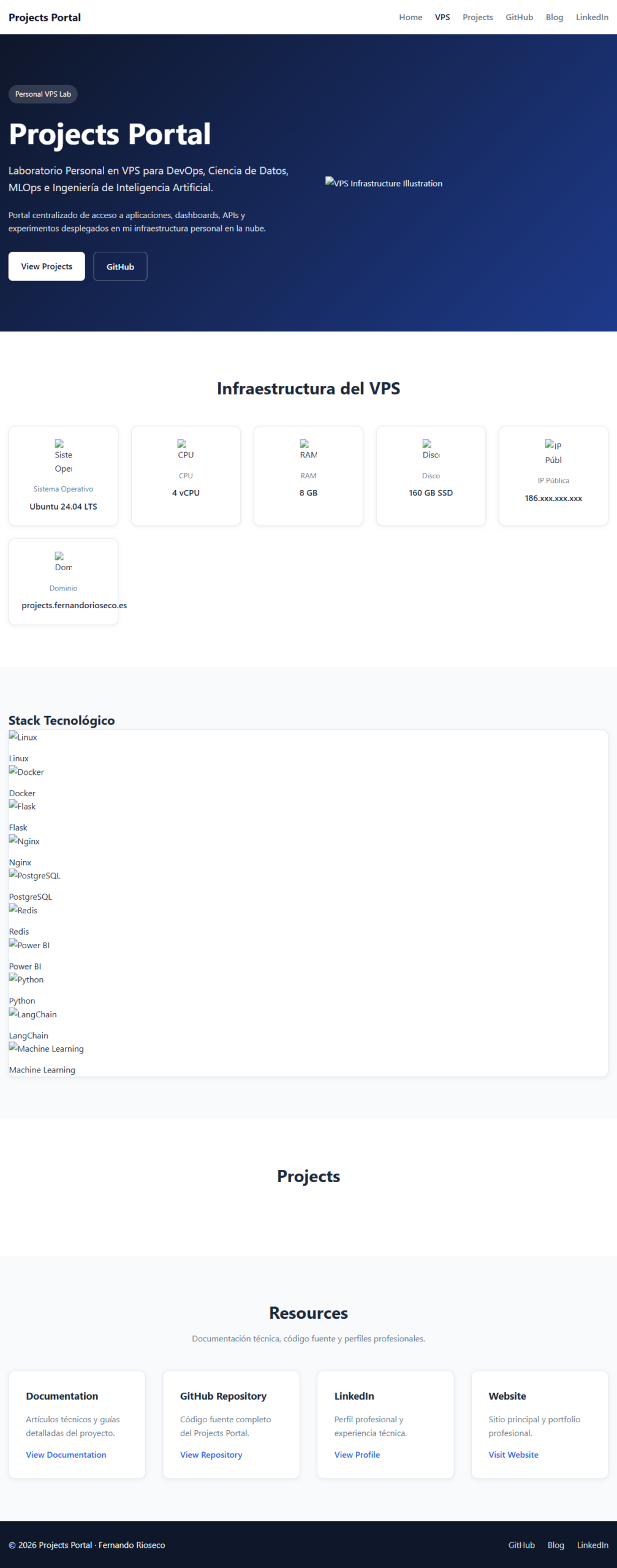
Estrategias Comunes de Escalado
Para solucionar este sesgo, aplicamos transformaciones matemáticas que homogeneizan las magnitudes de las características. A continuación, se detallan los tres enfoques más utilizados en Machine Learning:
[Image comparing Standard Scaling, Min-Max Scaling, and Robust Scaling on a dataset with outliers]
Escalado Estándar (Standard Scaling / Z-Score)
Este método transforma las características para que tengan una media igual a $0$ y una desviación estándar igual a $1$, expresando cada valor en términos de cuántas desviaciones estándar se aleja de la media central.
La fórmula matemática para estandarizar un valor $x$ es:
$$z = \frac{x – \mu}{\sigma}$$
Donde $\mu$ es la media de la columna y $\sigma$ es la desviación estándar.
- Consideración: El Escalado Estándar es susceptible a la influencia de valores atípicos (outliers). Si un dataset contiene un registro con un valor extremadamente alto, este arrastrará la media hacia arriba y expandirá artificialmente la desviación estándar, afectando la compresión del resto de los datos normales.
Escalado Min-Max (Min-Max Scaling / Normalization)
Esta técnica transforma los datos para confinarlos estrictamente dentro de un rango acotado, por lo general entre $0$ y $1$.
La fórmula para calcular la normalización Min-Max es:
$$x_{\text{scaled}} = \frac{x – x_{\text{min}}}{x_{\text{max}} – x_{\text{min}}}$$
Ejemplo Numérico de Prototipado:
Supongamos una columna donde el valor mínimo ($x_{\text{min}}$) es $3$ y el valor máximo ($x_{\text{max}}$) es $100$.
- Si evaluamos el valor mínimo $3$:$$\frac{3 – 3}{100 – 3} = \frac{0}{97} = 0$$
- Si evaluamos un valor intermedio como $40$:$$\frac{40 – 3}{100 – 3} = \frac{37}{97} \approx 0.381$$
- Si evaluamos el valor máximo $100$:$$\frac{100 – 3}{100 – 3} = \frac{97}{97} = 1$$
- Consideración Crítica: El escalado Min-Max es altamente sensible a los valores atípicos. Si todos los registros de una columna se encuentran entre $0$ y $10$, pero existe un único registro atípico con el valor de $10,000$, ese registro se convertirá en el $x_{\text{max}}$. Al aplicar la fórmula, todos los datos reales del negocio (entre $0$ y $10$) se verán compactados y “aplastados” en una fracción microscópica cercana a $0$, perdiendo su variabilidad y detalle visual.
Escalado Robusto (Robust Scaling)
El escalado robusto se diseñó específicamente para contrarrestar la debilidad ante los valores atípicos. En lugar de utilizar la media y la desviación estándar (sensibles a extremos) o los valores máximos y mínimos absolutos, utiliza estadísticas de posición robustas: la mediana y el Rango Intercuartílico (IQR).
La fórmula matemática es:
$$x_{\text{scaled}} = \frac{x – \text{mediana}}{\text{IQR}}$$
Donde el IQR representa la distancia entre el percentil 75 ($Q_3$) y el percentil 25 ($Q_1$), concentrando el $50\%$ central de los datos.
- Ventaja: Al basarse en la masa central de la distribución, la presencia de valores atípicos extremos en los bordes no sesga ni deforma el escalado de los datos limpios.
- Desventaja: A diferencia de Min-Max, el Escalado Robusto no garantiza que los límites finales queden confinados estrictamente entre $0$ y $1$.
Matriz de Decisiones en Ingeniería de Características
Para cerrar este bloque de preparación de datos, consolidaremos las técnicas estudiadas estructurándolas según la naturaleza de cada tipo de variable. En el desarrollo práctico con Python, la librería Scikit-Learn (sklearn.preprocessing) y la librería Pandas proveen todo el arsenal de funciones necesarias para manipular estas características de forma eficiente.
A continuación, se presenta el mapa de ruta definitivo para transformar tus datos antes de la fase de modelado:
| Tipo de Variable | Objetivo Analítico | Herramienta en Python (sklearn / pandas) |
| Numérica Continua | Ajustar magnitudes para algoritmos basados en distancias (KNN, SVM) o gradientes. | StandardScaler, MinMaxScaler, RobustScaler |
| Nominal / Categórica (Sin Orden) | Convertir textos o etiquetas dicotómicas/multiclase en vectores numéricos independientes. | OneHotEncoder, LabelBinarizer, pd.get_dummies() |
| Ordinal (Con Orden) | Mapear jerarquías manteniendo la relación de progresión secuencial. | OrdinalEncoder, DictVectorizer |
Implementación de Herramientas según el Tipo de Dato
Variables Numéricas Continuas (Escalado)
Cuando tus datos presentan escalas dispares (como pesos, salarios o distancias), importamos los transformadores directos desde el módulo de preprocesamiento de Scikit-Learn:
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
# Inicialización de los motores de escalado
escalador_estandar = StandardScaler() # Media 0, Dev. Std 1
escalador_minmax = MinMaxScaler() # Rango acotado [0, 1]
escalador_robusto = RobustScaler() # Basado en Mediana e IQR (antiatípicos)Variables Nominales o Categóricas (Codificación sin Orden)
Para variables como el estado civil (Casado, Soltero) o colores (Rojo, Azul, Verde), requerimos representaciones binarias:
LabelBinarizer: Ideal para transformar variables de texto puramente binarias (dos categorías) en ceros y unos.OneHotEncoder/pd.get_dummies(): Crean columnas separadas para cada categoría presente.pd.get_dummies()de Pandas es ampliamente utilizada por su simplicidad para prototipar directamente sobre DataFrames.
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# Alternativa rápida en Pandas para One-Hot Encoding
df_codificado = pd.get_dummies(df, columns=["columna_color"])
Variables Ordinales (Codificación con Orden)
Para registrar progresiones jerárquicas (como Bajo = 1, Medio = 2, Alto = 3), usamos OrdinalEncoder. Es fundamental pasar explícitamente el orden correcto de las categorías al transformador; de lo contrario, el algoritmo asignará los números enteros de forma alfabética o aleatoria, destruyendo la lógica del negocio.
from sklearn.preprocessing import OrdinalEncoder
# Definir explícitamente el orden jerárquico de los factores
orden_categorias = [["Bajo", "Medio", "Alto"]]
encoder_ordinal = OrdinalEncoder(categories=orden_categorias)
Resumen del Módulo: Preparación de Datos
Hemos cubierto los pilares fundamentales para transformar datos crudos en tensores matemáticos optimizados:
- Transformaciones No Lineales: Vimos cómo las funciones logarítmicas (
np.log1p) suavizan el sesgo positivo y cómo las transformaciones polinomiales expanden la flexibilidad de nuestros modelos permitiéndoles trazar curvas mediante combinaciones lineales. - Codificación Categórica: Aprendimos a aislar variables cualitativas sin orden mediante esquemas One-Hot para evitar falsas métricas de vecindad, y a estructurar variables jerárquicas mediante codificadores ordinales.
- Escalado Estadístico: Analizamos visualmente el riesgo de que variables con rangos numéricos masivos eclipsen por completo a métricas críticas en algoritmos basados en distancias (como KNN), y estudiamos cómo la estandarización y normalización mitigan este problema.