Los embedding models son el componente que transforma el contenido obtenido de los document en representaciones vectoriales densas que capturan significado semántico. En sistemas modernos de RAG dentro de LangChain, los embeddings son la base sobre la que se construye todo el sistema de recuperación.
En términos operativos, un embedding model proyecta texto en un espacio vectorial donde la distancia entre vectores refleja similitud semántica. Esto permite ejecutar búsquedas por similitud (normalmente usando cosine similarity o dot product) en bases de datos vectoriales. La calidad de esta proyección determina directamente la capacidad del sistema para recuperar contexto relevante.
Relación entre embeddings y organización en el vector store
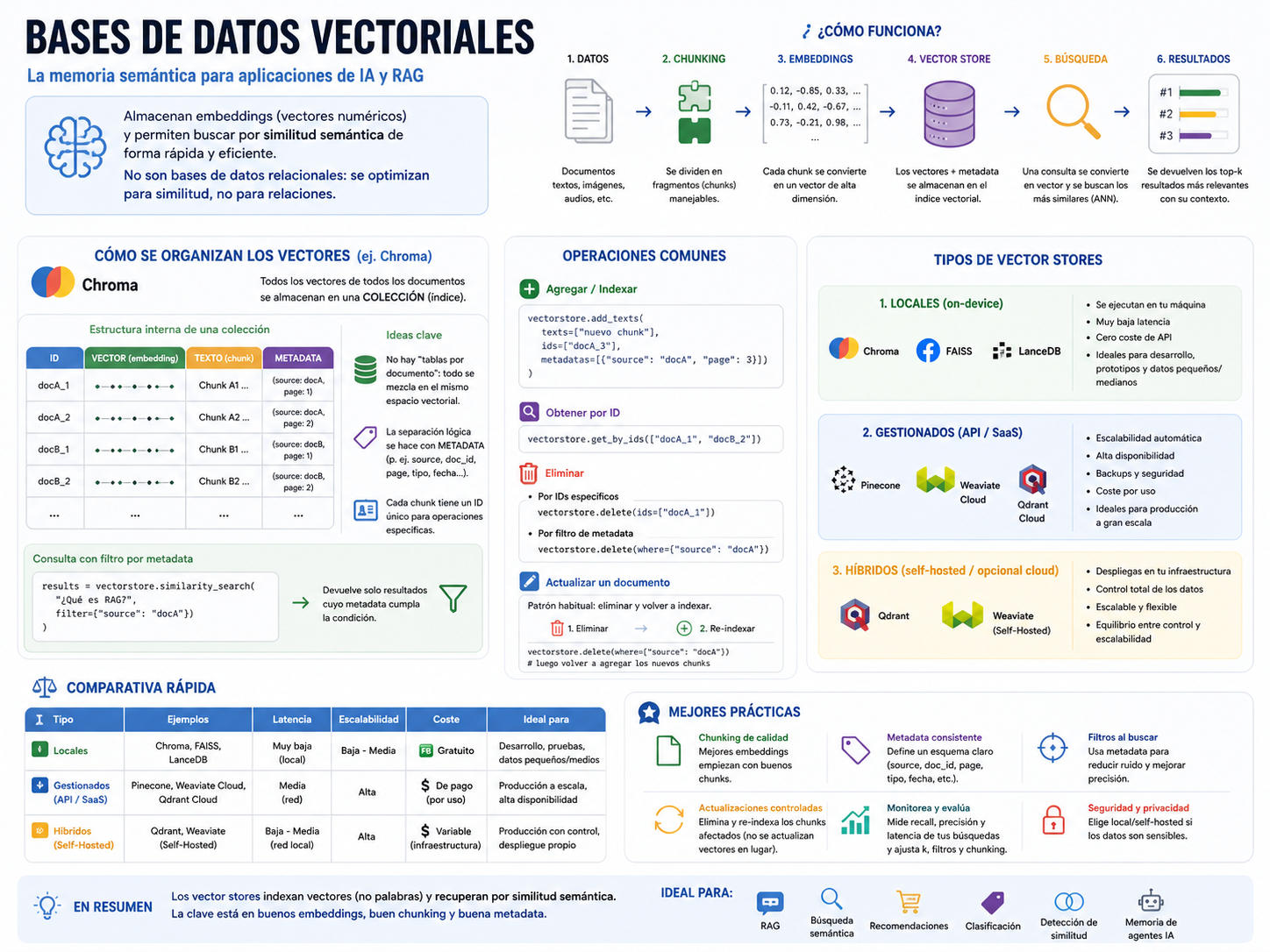
Un aspecto crítico que suele pasarse por alto es que los embeddings no se almacenan como “un vector por documento”, sino como un vector por fragmento (chunk). Esto significa que un mismo documento genera múltiples embeddings que se indexan de forma independiente en el vector store.
En sistemas como Chroma, todos estos vectores se almacenan dentro de una misma colección (índice), independientemente del documento de origen. No existen “tablas separadas por documento”; en su lugar, cada entrada del índice contiene:
el embedding
el contenido (page_content)
la metadata asociada
un identificador (ID)
De forma conceptual:
[vector, texto, metadata, id]
Cuando se indexan múltiples documentos, todos sus chunks se mezclan dentro del mismo espacio vectorial:
Esto implica que la “separación” entre documentos no es física, sino lógica, y se realiza mediante metadata.
Tipos de embedding models
En producción, no todos los embeddings son equivalentes; se diferencian por arquitectura, objetivo y rendimiento.
General-purpose embeddings: Modelos optimizados para tareas generales de similitud semántica como OpenAI embeddings (text-embedding models), se usan en RAG estándar y búsqueda semántica.
Instruction-tuned embeddings: Modelos ajustados con instrucciones para mejorar tareas específicas (query vs document alignment). Tiene la ventaja de hacer mejor matching entre pregunta y contexto
Domain-specific embeddings: Entrenados en dominios concretos: legal, médico, código. Esto hace que mejoren el recall en casos especializados
Multilingual embeddings: permiten búsqueda cruzada entre idiomas.
Parámetros clave
Dimensionalidad: Más dimensiones → más capacidad semántica, pero mayor coste.
Normalización: Muchos modelos requieren normalización del vector para usar cosine similarity correctamente.
Tokenización: El embedding depende del tokenizer del modelo → afecta cómo se representa el texto.
Decisiones críticas en producción
Query vs Document embeddings: En sistemas avanzados: embeddings distintos para queries y documentos
Chunking alignment: El rendimiento depende directamente de cómo has hecho el text splitting un chunk mal definido lleva a un embedding pobre y la consecuencia es un retrieval malo
Batch vs real-time:
Indexing → los documentos se procesan en batch para generar embeddings de forma eficiente y reducir coste computacional.
Queries → las consultas del usuario se embeben en tiempo real para realizar búsqueda semántica inmediata sobre la base vectorial.
Errores comunes
Usar embeddings genéricos en dominios especializados → reduce la precisión semántica porque el modelo no captura bien el vocabulario ni las relaciones propias del dominio.
No normalizar vectores → provoca que métricas como cosine similarity den resultados incorrectos o inconsistentes en la búsqueda. (encode_kwargs={"normalize_embeddings": True})
Usar chunks demasiado grandes o pequeños → los grandes introducen ruido y los pequeños pierden contexto, degradando el retrieval.
No evaluar recall@k → impide medir si el sistema realmente recupera información relevante, ocultando fallos críticos en producción. Ver en retrievers.
Vector stores
Los vector stores son el componente encargado de almacenar y consultar embeddings de forma eficiente. En un sistema RAG dentro de LangChain, no basta con generar vectores; es necesario indexarlos en una estructura que permita búsquedas por similitud a gran escala con baja latencia.
En términos operativos, un vector store gestiona tres elementos: el vector (embedding), el contenido original (texto) y la metadata asociada. A partir de ahí, permite ejecutar consultas semánticas donde una query se transforma en embedding y se compara contra el índice para recuperar los elementos más cercanos.
Tipos, elección y uso en producción
La elección del vector store no es trivial; afecta a latencia, escalabilidad, coste y operativa. En la práctica, la decisión se reduce a dónde se ejecuta (local vs gestionado) y qué volumen/latencia necesitas.
Tipos de vector stores
Local (on-device): Se ejecutan en la propia máquina, sin dependencias externas. Ideales para prototipos, entornos offline o setups local-first.
Ejemplos: Chroma, FAISS
Ventajas: cero coste de API, baja latencia local, control total
Limitaciones: escalabilidad y concurrencia limitadas
Gestionados (API / SaaS): Servicios externos optimizados para indexación y búsqueda vectorial a gran escala.
Ventajas: alta disponibilidad, escalado automático, operaciones gestionadas
Limitaciones: coste y dependencia de red
Híbridos (self-hosted / cloud opcional): Permiten ejecutar localmente o desplegar en servidor propio con capacidades de escalado.
Ejemplos: Qdrant, Weaviate (self-hosted)
Ventajas: equilibrio entre control y escalabilidad
Limitaciones: necesitas gestionar infraestructura
Comparativa rápida
Tipo
Ejemplo
Latencia
Escalabilidad
Tipo
Uso recomendado
Local
Chroma, FAISS
Muy baja
Baja
gratis
desarrollo, local RAG
API
Pinecone, Weaviate Cloud
Media
Alta
pago
producción a escala
Híbrido
Qdrant, Weaviate
Baja–Media
Alta
variable
producción self-hosted
Criterios de elección
Usa local (Chroma / FAISS) si: trabajas en desarrollo o laboratorio, necesitas privacidad total y los dataset son pequeños/medio
Usa API (Pinecone / Weaviate Cloud) si: necesitas alta disponibilidad, tienes mucho volumen de datos y múltiples usuarios concurrentes
Usa híbrido (Qdrant / Weaviate self-hosted) si: quieres control + escalabilidad, despliegas en servidor propio y buscas evitar costes SaaS
Insight importante
El vector store no mejora embeddings ni corrige errores de chunking solo acelera la búsqueda; la calidad depende del pipeline previo.
Ingesta / Indexación (escritura en el vector store)
La fase de ingesta es donde se construye el índice vectorial a partir de los datos ya preprocesados (cleaning + splitting). En este punto, los textos o documentos se transforman en embeddings y se almacenan junto con su metadata en el vector store.
Esta operación suele ejecutarse en batch durante el indexing, no en tiempo real, y es crítica porque define la calidad y consistencia del sistema de retrieval: cualquier error aquí (mal chunking, embeddings inconsistentes, falta de metadata) se propagará al resto del pipeline.
Métodos de ingesta
Método
Descripción
add_texts
Convierte textos en embeddings y los añade al índice existente.
aadd_texts
Versión asíncrona de add_texts.
add_documents
Añade o actualiza documentos (incluyendo metadata) en el vector store.
aadd_documents
Versión asíncrona de add_documents.
from_texts
Crea un vector store directamente a partir de una lista de textos.
afrom_texts
Versión asíncrona de from_texts.
from_documents
Inicializa un vector store desde documentos estructurados.
En producción, estos métodos se utilizan en pipelines de indexing offline, donde grandes volúmenes de datos se procesan en batch para evitar latencia y optimizar costes.
La gestión de datos en un vector store es fundamental para mantener la coherencia del índice a lo largo del tiempo. A diferencia de bases de datos tradicionales, los embeddings no suelen actualizarse “en sitio”; en la práctica, cualquier cambio en el contenido implica eliminar los vectores antiguos y reindexar los nuevos. Por ello, las operaciones de eliminación no son solo tareas de limpieza, sino una parte crítica del ciclo de vida del dato en sistemas RAG.
Método
Descripción
delete
Elimina vectores del índice por ID o mediante condiciones sobre metadata.
adelete
Versión asíncrona de delete.
Uso típico: eliminar chunks específicos de un documento.
vectorstore.delete(ids=["docA_1", "docA_2"])
Elimina todos los vectores asociados a un documento completo.
vectorstore.delete(where={"source": "docA"})
Patrón de actualización (delete + reindex)
# eliminar versión antiguavectorstore.delete(where={"source": "docA"})# volver a indexar contenido actualizadovectorstore.add_texts(texts=["nuevo contenido actualizado"],metadatas=[{"source": "docA"}])
Acceso directo por ID
El acceso por ID permite recuperar documentos de forma determinista sin pasar por el proceso de búsqueda semántica. En lugar de calcular similitudes vectoriales, se accede directamente a los elementos almacenados en el índice usando sus identificadores únicos. Esta operación es clave para tareas de trazabilidad y control, ya que permite verificar exactamente qué contenido fue indexado o recuperado en etapas anteriores del pipeline.
Métodos de acceso
Método
Descripción
get_by_ids
Recupera documentos directamente por sus IDs.
aget_by_ids
Versión asíncrona de get_by_ids.
Recuperar documentos por ID
docs = vectorstore.get_by_ids(["docA_1", "docB_2"])for doc in docs:print(doc.page_content, doc.metadata)
Uso en debugging: Permite verificar el origen del documento, metadatos asociados y contenido extacto indexado.
Reconstrucción de contexto: reconstruir un documento original a partir de chunks, auditar resultados del retrieval.
ids = ["docA_1", "docA_2"]chunks = vectorstore.get_by_ids(ids)full_text =" ".join([c.page_content for c in chunks])
Búsqueda semántica (core del RAG)
La búsqueda semántica es el núcleo de cualquier sistema RAG: es el mecanismo que permite recuperar información relevante a partir de una consulta, no por coincidencia exacta de palabras, sino por similitud en el espacio vectorial. En esta fase, la query se transforma en embedding y se compara contra el índice para encontrar los fragmentos más cercanos. Este proceso implementa, en la práctica, algoritmos de k-nearest neighbors (k-NN) o sus variantes aproximadas (ANN) para escalar a grandes volúmenes de datos.
Búsqueda básica
La forma más directa de retrieval es recuperar los documentos más similares a una query.
Método
Descripción
similarity_search
Devuelve los documentos más similares a una query.
asimilarity_search
Versión asíncrona de similarity_search.
similarity_search_by_vector
Realiza la búsqueda usando un embedding ya calculado.
asimilarity_search_by_vector
Versión asíncrona de búsqueda por vector.
results = vectorstore.similarity_search("What is a text splitter?",k=3)# k muy bajo → pierdes información relevante# k muy alto → el LLM recibe ruidofor doc in results:print(doc.page_content)
k
Uso
1
muy preciso, poco contexto
3
estándar
5–10
más contexto, más ruido
Usarby_vector cuando ya tienes el embedding calculado y quieres optimizar rendimiento.
query_vector = embeddings.embed_query("What is LCEL?")results = vectorstore.similarity_search_by_vector(query_vector)
Búsqueda con scoring
Estas variantes añaden información cuantitativa sobre la similitud, lo que permite evaluar y depurar el comportamiento del retrieval.
Método
Descripción
similarity_search_with_score
Devuelve documentos junto con su distancia o score técnico.
asimilarity_search_with_score
Versión asíncrona.
similarity_search_with_relevance_scores
Devuelve scores normalizados entre 0 y 1.
asimilarity_search_with_relevance_scores
Versión asíncrona.
Se usa para evaluación de calidad (recall, ranking), análisis de relevancia y tuning del sistema
results = vectorstore.similarity_search_with_relevance_scores("What are embeddings?",k=3)for doc, score in results:print(score, doc.page_content)
MMR (Max Marginal Relevance)
MMR introduce un criterio adicional: no solo busca relevancia respecto a la query, sino también diversidad entre los resultados.
Método
Descripción
max_marginal_relevance_search
Selecciona documentos optimizando relevancia y diversidad.
amax_marginal_relevance_search
Versión asíncrona.
max_marginal_relevance_search_by_vector
MMR usando embeddings en lugar de texto.
amax_marginal_relevance_search_by_vector
Versión asíncrona.
Ejemplo con: max_marginal_relevance_search. Evita resultados redundantes, mejora la cobertura del contexto y es útil cuando los documentos son similares entre sí.
El método search permite unificar distintas estrategias bajo una sola interfaz.
Método
Descripción
search
Permite elegir el tipo de búsqueda (similarity, MMR, etc.).
asearch
Versión asíncrona.
search() permite seleccionar dinámicamente entre similarity, MMR, scoring.
results = vectorstore.search("What is RAG?",search_type="mmr")
Filtering (restricción por metadata)
El filtering permite restringir el espacio de búsqueda en el vector store utilizando metadata asociada a cada chunk. A diferencia de la búsqueda semántica, que opera sobre embeddings, los filtros actúan como una condición lógica que limita qué subconjunto de datos se considera antes (o durante) el cálculo de similitud.
Cómo funciona: Cada chunk indexado incluye metadata:
retriever = vectorstore.as_retriever(search_kwargs={"k": 3,"filter": {"source": "docA"} })docs = retriever.invoke("What is a text splitter?")
Casos de uso
separación entre documentos
sistemas multi-usuario (multi-tenant)
filtrado por secciones (capítulos, páginas)
control de contexto en RAG
Consideraciones
Los filtros dependen de la metadata → si no la defines bien, no funcionan
No sustituyen la similitud → la complementan
Su implementación puede variar según el vector store
Insight clave
embeddings → determinan relevancia
filtering → determina contexto
Ambos son necesarios para un retrieval correcto.
Atributos
Los vector stores no solo almacenan datos, sino que también mantienen información sobre los componentes con los que fueron construidos. El atributo más relevante es embeddings, que hace referencia al modelo de embeddings asociado al índice.
Este atributo permite garantizar que las operaciones de retrieval se realicen con el mismo espacio vectorial con el que se indexaron los datos, evitando inconsistencias difíciles de detectar.
Atributo
Descripción
embeddings
Modelo de embeddings asociado al vector store.
print(vectorstore.embeddings)
Para qué se utiliza
Consistencia → asegura que las queries se embeben con el mismo modelo usado en la indexación
Debugging → permite verificar qué modelo está realmente en uso
Auditoría → ayuda a rastrear configuraciones en sistemas complejos
Caso práctico
query_vector = vectorstore.embeddings.embed_query("What is RAG?")
Error común
Cambiar el modelo de embeddings sin reindexar da como resultado búsquedas incorrectas o incoherentes.
index → creado con modelo A query → generada con modelo B
Retriever
El método as_retriever transforma el vector store en un componente de alto nivel que encapsula la lógica de búsqueda y lo hace directamente integrable en pipelines de RAG. En lugar de llamar manualmente a métodos como similarity_search, el retriever actúa como una interfaz estándar que recibe una query y devuelve los documentos relevantes, desacoplando la capa de almacenamiento de la lógica del sistema.
Este patrón es clave en LangChain, ya que permite componer fácilmente pipelines donde el retrieval se integra como una pieza más dentro del flujo de datos hacia el LLM.
Método
Descripción
as_retriever
Convierte el vector store en un retriever configurable para pipelines RAG.
Ejemplo básico
retriever = vectorstore.as_retriever(search_type="mmr",search_kwargs={"k": 3})docs = retriever.invoke("What is a text splitter?")
Qué está haciendo internamente el retriever: (Es un wrapper sobre similarity_search.)
Recibe la query
La convierte en embedding
Ejecuta búsqueda en el vector store
Devuelve los documentos más relevantes
Insight estructural
Aunque la interfaz de VectorStore en LangChain puede parecer extensa, en la práctica se reduce a tres operaciones fundamentales que reflejan el ciclo de vida del dato en un sistema RAG.
Write (indexing)
Corresponde a la fase de ingesta, donde los datos se transforman en embeddings y se insertan en el índice vectorial. Se ejecuta normalmente en batch durante el indexing offline.
add_* → inserción incremental
from_* → construcción inicial del índice
Read (retrieval)
Es la fase de consulta, donde se recupera información relevante a partir de una query. Es el núcleo del sistema RAG.
similarity_* → búsqueda por similitud
mmr_* → búsqueda con diversidad
search → interfaz general
Manage (mantenimiento)
Permite modificar o inspeccionar el índice. Es clave para actualización, limpieza y debugging.
Los text splitters en LangChain son un componente estructural dentro de cualquier pipeline de RAG: determinan cómo se segmenta el conocimiento antes de ser embebido, indexado y recuperado. En sistemas en producción, esta decisión no es neutra; el splitting define directamente la calidad del retrieval, la densidad semántica de los embeddings y, en última instancia, la precisión del sistema.
pero lo relevante es que el splitter introduce la primera transformación irreversible del dato. Cualquier pérdida de coherencia en esta etapa se propaga aguas abajo.
El punto de abstracción es la interfaz TextSplitter, que define un contrato simple: transformar texto en una lista de fragmentos. Sin embargo, en entornos reales, la elección de implementación no es intercambiable. El uso de CharacterTextSplitter, aunque históricamente común, ha quedado relegado a casos triviales debido a su naturaleza puramente mecánica: corta por longitud fija sin respetar unidades semánticas, lo que degrada la calidad de los embeddings y reduce la efectividad del retrieval.
El estándar de facto en producción es RecursiveCharacterTextSplitter, precisamente porque introduce una heurística jerárquica que preserva la estructura del lenguaje el mayor tiempo posible. En lugar de imponer cortes arbitrarios, aplica una estrategia de degradación progresiva: intenta dividir por párrafos, luego por saltos de línea, después por frases y, solo cuando no hay alternativa, por caracteres. Este comportamiento minimiza la fragmentación semántica sin renunciar al control sobre el tamaño del chunk.
Un aspecto clave en todos los splitters es la configuración de chunk_size y chunk_overlap, donde el primero define el tamaño del fragmento y el segundo preserva contexto entre fragmentos; en práctica profesional, valores típicos oscilan entre 500–1500 tokens con un solapamiento del 10–30%.
Los separators definen la jerarquía de cortes que el algoritmo intenta aplicar en orden, no son simplemente delimitadores; son una estrategia de degradación progresiva. En este caso, conceptualmente, le estamos diciendo a la función: “intenta dividir primero por unidades semánticas grandes; si no puedes cumplir el chunk_size, baja de nivel progresivamente hasta poder hacerlo”
El algoritmo sigue esta lógica:
Intenta dividir usando "\n\n" (párrafos)
Si los chunks siguen siendo demasiado grandes → usa "\n" (líneas)
Si aún no cabe → usa "." (frases)
Luego " " (palabras)
Finalmente "" (caracteres individuales, último recurso)
Splitters
TokenTextSplitter
Cuando el control fino sobre tokens es crítico (coste o límites del modelo), se utiliza TokenTextSplitter, que trabaja directamente con tokenizadores:
from langchain_text_splitters import TokenTextSplittersplitter = TokenTextSplitter(chunk_size=512,chunk_overlap=50)
Internamente se apoya en una abstracción de Tokenizer, y también puedes usar funciones como:
from langchain_text_splitters import split_text_on_tokens
Esto garantiza que nunca excedas el contexto real del modelo.
MarkdownHeaderTextSplitter
Más allá de longitud, LangChain introduce splitters estructurales que respetan formato del documento; por ejemplo, MarkdownHeaderTextSplitter divide en función de headers, manteniendo jerarquía lógica:
Esto permite que cada chunk incluya metadata semántica (sección, subsección, etc.).
HTMLHeaderTextSplitter
En HTML, el equivalente es HTMLHeaderTextSplitter, que detecta etiquetas <h1>, <h2>, etc., y genera documentos jerárquicos con metadata asociada; si no encuentra headers, devuelve el documento completo, lo cual lo hace robusto ante inputs inconsistentes.
Para casos más avanzados, HTMLSemanticPreservingSplitter mantiene estructura completa (incluyendo links, imágenes o multimedia), y solo recurre a splitting recursivo si se supera el tamaño máximo, priorizando integridad semántica.
RecursiveJsonSplitter
Cuando trabajas con datos estructurados, RecursiveJsonSplitter permite dividir JSON preservando jerarquía, lo cual es crítico en agentes que dependen de contexto estructurado:
from langchain_text_splitters import RecursiveJsonSplittersplitter = RecursiveJsonSplitter(max_chunk_size=500)chunks = splitter.split_json(json_data)
Aquí el objetivo no es solo dividir, sino mantener relaciones entre claves.
Splitters específicos por lenguaje o dominio
LangChain también incluye splitters específicos por lenguaje o dominio, lo cual es clave en sistemas profesionales; por ejemplo, PythonCodeTextSplitter divide respetando sintaxis de Python (funciones, clases), mientras que JSFrameworkTextSplitter extiende el splitting recursivo para entender JSX, Vue o Svelte, detectando componentes como separadores naturales:
from langchain_text_splitters import PythonCodeTextSplittersplitter = PythonCodeTextSplitter()chunks = splitter.split_text(code)
Esto evita romper bloques de código de forma incorrecta.
Splitters para procesamiento de texto
En procesamiento lingüístico más avanzado, existen integraciones con NLP clásico como SpacyTextSplitter o NLTKTextSplitter, que segmentan por oraciones usando modelos lingüísticos:
from langchain_text_splitters import SpacyTextSplittersplitter = SpacyTextSplitter(pipeline="sentencizer")chunks = splitter.split_text(text)
Para casos específicos, también existen splitters especializados como:
Divide texto en función de tokens usando un tokenizador; útil para controlar límites de modelos.
SentenceTransformersTokenTextSplitter
Variante basada en tokenizadores de modelos de sentence-transformers; optimizada para embeddings.
SpacyTextSplitter
Usa Spacy para segmentar texto en oraciones; más preciso lingüísticamente.
NLTKTextSplitter
Segmenta texto utilizando NLTK; útil para procesamiento basado en frases.
MarkdownTextSplitter
Divide texto siguiendo la estructura Markdown (headers, secciones).
MarkdownHeaderTextSplitter
Divide Markdown basado en headers específicos, generando chunks con metadata jerárquica.
ExperimentalMarkdownSyntaxTextSplitter
Splitter avanzado que preserva formato original, whitespace y extrae metadata (headers, código, reglas).
HTMLHeaderTextSplitter
Divide HTML según etiquetas de encabezado (<h1>, <h2>, etc.), generando estructura jerárquica.
HTMLSectionSplitter
Divide HTML basado en tags y tamaños de fuente; requiere lxml.
HTMLSemanticPreservingSplitter
Mantiene estructura semántica HTML completa (links, imágenes, etc.) y solo divide si es necesario.
RecursiveJsonSplitter
Divide JSON en fragmentos manteniendo su estructura jerárquica; útil para datos estructurados.
PythonCodeTextSplitter
Divide código Python respetando su sintaxis (funciones, clases).
JSFrameworkTextSplitter
Divide código de frameworks JS (React, Vue, Svelte) detectando componentes y sintaxis.
LatexTextSplitter
Divide texto respetando estructura de documentos LaTeX.
KonlpyTextSplitter
Splitter especializado para texto en coreano usando la librería KoNLPy.
Finalmente, en sistemas complejos de agentes construidos con LangGraph, los text splitters no solo afectan al retrieval, sino a la memoria externa del agente; elegir un splitter adecuado implica decidir cómo el agente “percibe” el conocimiento disponible.
En cualquier sistema de RAG, la calidad del resultado final depende directamente de la calidad del dato de entrada. Antes de aplicar técnicas de segmentación, generación de embeddings o recuperación de información, es imprescindible garantizar que el contenido extraído esté correctamente estructurado y libre de ruido.
En la práctica, los datos rara vez llegan en un formato listo para ser utilizados. Ya provengan de documentos PDF, páginas web u otras fuentes, el contenido suele presentar problemas como fragmentación del texto, elementos irrelevantes o estructuras inconsistentes. Estos problemas no son visibles a simple vista en todos los casos, pero tienen un impacto directo en el rendimiento del sistema.
Esto significa que, aunque el loader funcione correctamente, el resultado puede ser un texto difícil de utilizar en un sistema RAG como en este ejemplo:
print(document[6].page_content[:300])
zonas premium: cada metro valía (y vale) mucho más en Madrid, Baleares y País Vascoqueencualquierotraregión.
Por tanto, antes de avanzar hacia fases más avanzadas del sistema, es necesario validar y procesar adecuadamente el contenido extraído. Un pipeline sólido no comienza con el modelo, sino con datos bien preparados.
Antes de generar embeddings, es fundamental aplicar una fase de limpieza del texto. El objetivo es reconstruir, en la medida de lo posible, una estructura natural del lenguaje.
Una estrategia básica de limpieza incluye:
Eliminación de saltos de línea innecesarios
Normalización de espacios
Unificación del texto en una secuencia continua
Este enfoque elimina múltiples espacios, saltos de línea y fragmentaciones simples, devolviendo un texto más coherente. Para casos más complejos, se pueden aplicar reglas adicionales, como la eliminación de patrones repetitivos o la reconstrucción de párrafos.
Métodos de limpieza de datos tras la carga (post-load)
Una vez cargados los documentos mediante un loader, el siguiente paso crítico es aplicar técnicas de limpieza que permitan transformar el texto en una forma coherente y útil para el sistema RAG.
No existe un único método universal. La limpieza debe adaptarse al tipo de fuente (PDF, web, datos estructurados), pero sí existen patrones comunes que se aplican en la mayoría de los casos:
Normalización básica de espacios
Eliminar espacios duplicados, saltos de línea y fragmentación simple. Se debe hacer siempre. Es el primer paso obligatorio.
text = document.page_contentclean_text =" ".join(text.split())
Soluciona:
Saltos de línea (\n)
Espacios múltiples
Texto fragmentado
Eliminación explícita de saltos de línea
Reconstruir frases que han sido cortadas artificialmente. Se utiliza en PDFs con líneas rotas y texto extraído por coordenadas
text = document.page_contentclean_text = text.replace("\n", " ")clean_text =" ".join(clean_text.split())
Eliminación de patrones repetitivos (headers/footers)
Eliminar contenido repetido en todas las páginas. Como: “Página 1”, “Confidencial”, nombres de empresa, etc. Mejora la calidad del embedding.
La limpieza de datos no es un paso opcional dentro de un sistema RAG, sino una fase crítica que determina la calidad del resto del pipeline.
Aplicar técnicas básicas como la normalización de espacios o la eliminación de ruido puede mejorar significativamente la coherencia del texto y, por tanto, la precisión del sistema.
En entornos reales, la combinación de varios métodos de limpieza es la práctica habitual, adaptándose siempre al tipo de documento y a la calidad del contenido extraído.
En LangChain, un Document es una estructura que representa una unidad de información compuesta por dos elementos: el contenido del texto (page_content) y un conjunto de metadatos (metadata) que aportan contexto adicional, como el origen, identificadores o fechas.
Este formato estandarizado permite trabajar de manera uniforme con distintos tipos de datos, ya provengan de archivos, páginas web, bases de datos o otras aplicaciones. Para obtener estos documentos desde fuentes reales, LangChain utiliza los llamados Document Loaders, que son componentes diseñados para cargar información desde múltiples orígenes y convertirla automáticamente en objetos Document que posteriormente serán utilizados en pipelines de Retrieval-Augmented Generation (RAG).
BaseLoader
Antes de trabajar con loaders concretos, es importante entender que todos ellos heredan de una clase base común: BaseLoader. Esta clase define el comportamiento estándar que deben seguir todos los loaders dentro del ecosistema de LangChain.
BaseLoader no es un loader que se utilice directamente, sino una interfaz (clase abstracta) que establece cómo deben implementarse los métodos de carga de documentos. El propósito principal de BaseLoader es garantizar que todos los loaders:
Devuelvan datos en formato Document
Sigan un patrón consistente
Sean intercambiables dentro del pipeline
BaseLoader → <Name>Loader
Ejemplos:
TextLoader
PyPDFLoader
WebBaseLoader
Su salida siempre es una colección de objetos:
Document.page_content → contenido textual
Document.metadata → información contextual
Este diseño permite que cualquier loader sea intercambiable dentro del pipeline. De esta forma, los datos externos se integran fácilmente en los flujos de trabajo con modelos de lenguaje, siendo la base para aplicaciones más avanzadas como sistemas de recuperación de información (RAG), análisis de datos o asistentes inteligentes.
Lazy loading
El diseño de BaseLoader está orientado a evitar cargar todos los documentos en memoria de golpe. Por eso, el método fundamental que deben implementar los loaders es: lazy_load()
Métodos de BaseLoader
Método
Descripción
Cuándo usarlo
Notas
load()
Carga todos los documentos y los devuelve en una lista de Document.
Prototipos, datasets pequeños, pruebas rápidas.
Es un método de conveniencia. Internamente usa lazy_load(). No debe sobrescribirse.
lazy_load()
Devuelve un generador de documentos (uno a uno).
Producción, grandes volúmenes de datos, eficiencia en memoria.
Método clave que deben implementar los loaders. Base del sistema.
Sistemas escalables, streaming de datos, alto rendimiento.
Permite iteración asíncrona (async for).
Loaders
En cualquier sistema RAG, el punto de partida es siempre el mismo: los datos. Antes de hablar de embeddings, retrieval o generación de respuestas, es necesario convertir las fuentes de información en un formato que el sistema pueda procesar. En este contexto, los documentos PDF representan uno de los formatos más habituales en entornos empresariales.
En el ecosistema de LangChain, los loaders forman parte de la capa de ingestión de datos. Su función no es solo “leer archivos”, sino preparar la información para que pueda ser utilizada posteriormente en procesos de segmentación, embedding y recuperación.
Unstructured’s Loaders
Los loaders denominados Unstructured dentro del ecosistema de LangChain son herramientas especializadas que permiten mejorar significativamente la extracción. Este tipo de loader no se limita a leer el texto plano, sino que intenta interpretar la estructura del documento. El resultado es un contenido más limpio, menos fragmentado y semánticamente más consistente, lo que impacta directamente en la calidad de los embeddings y en la eficacia del sistema RAG.
Ventajas principales:
Mejor interpretación del layout: Este loader intenta entender la estructura del documento, no solo extraer texto plano. Esto permite preservar mejor párrafos, títulos y bloques de contenido.
Menor fragmentación del texto: Reduce significativamente los problemas de palabras separadas o saltos de línea artificiales.
Mayor calidad semántica: Al generar texto más coherente, los embeddings resultantes son más representativos, lo que mejora la recuperación en RAG.
Preparado para documentos reales: Está diseñado para trabajar con documentos del mundo empresarial: informes, contratos, manuales, etc.
Loader
Descripción
UnstructuredPDFLoader
Extrae contenido de PDFs interpretando la estructura del documento (títulos, párrafos, listas). Ideal para informes complejos.
UnstructuredHTMLLoader
Procesa archivos HTML locales identificando contenido semántico relevante, evitando ruido estructural.
UnstructuredURLLoader
Carga contenido desde URLs aplicando parsing inteligente para aislar el contenido principal de la web.
UnstructuredWordDocumentLoader
Extrae contenido de documentos Word manteniendo la estructura lógica del texto.
UnstructuredEmailLoader
Procesa correos electrónicos (.eml, .msg), incluyendo cuerpo del mensaje y opcionalmente adjuntos.
UnstructuredImageLoader
Extrae texto de imágenes (OCR) y organiza el contenido en elementos semánticos.
Consideraciones
Mayor coste computacional
Puede requerir dependencias adicionales
No siempre necesario para documentos simples
Modo de operación
Los loaders Unstructured suelen trabajar en dos modos:
single: Devuelve todo el documento como un único Document.
elements (recomendado): Divide el contenido en elementos estructurados:
from langchain_community.document_loaders import<Loader>loader =<Loader>("ruta/al/archivo")documents = loader.load()
En el momento de utilizarlos debes consultar la documentación de los parámetros adicionales en cada caso. Ejemplo para extracción de datos en un DataFrame de Pandas.
from langchain_community.document_loaders import DataFrameLoaderloader = DataFrameLoader(df, page_content_column="text")documents = loader.load()
Web Loaders
Los Web Loaders permiten incorporar información directamente desde internet a un sistema RAG. Esto incluye páginas web, blogs, documentación técnica o cualquier contenido accesible mediante una URL.
A diferencia de los loaders de archivos locales, aquí no trabajas con un documento estático, sino con contenido dinámico, estructurado en HTML y, en muchos casos, generado parcialmente mediante JavaScript. Para cada caso debes seleccionar el tipo correcto diferenciado en cómo acceden y procesan el contenido:
Loaders básicos → funcionan bien con páginas estáticas
Loaders con renderizado JS → necesarios para webs modernas
Loader básico para cargar páginas web. Extrae el HTML y lo convierte en texto.
AsyncHtmlLoader
Variante asíncrona para cargar múltiples páginas web de forma eficiente.
PlaywrightURLLoader
Carga páginas renderizadas con JavaScript usando Playwright. Ideal para webs dinámicas.
SeleniumURLLoader
Similar a Playwright, utiliza Selenium para renderizar contenido dinámico.
BrowserlessLoader
Utiliza un navegador remoto (Browserless) para cargar páginas complejas.
BrowserbaseLoader
Loader basado en navegador headless en la nube (Browserbase).
RecursiveUrlLoader
Crawler que navega recursivamente por enlaces dentro de una web.
SitemapLoader
Carga todas las URLs definidas en un sitemap XML.
Problemas específicos del contenido web:
Ruido HTML: El contenido incluye elementos que no aportan valor:
menús de navegación
banners de cookies
footers
enlaces secundarios
Contenido dinámico: Muchas webs modernas no cargan todo el contenido directamente en el HTML, sino que lo generan mediante JavaScript. El resultado es:
loaders básicos no ven el contenido
necesitas loaders con renderizado (Playwright, Selenium)
Riesgos de seguridad (SSRF): Los loaders tipo crawler pueden acceder a múltiples URLs automáticamente. Esto conlleva riesgos como:
acceso a recursos internos
carga de URLs maliciosas
problemas de seguridad en producción
Buenas prácticas para trabajar correctamente con Web Loaders en RAG:
No indexar páginas completas sin filtrar
Validar siempre el contenido extraído
Aplicar limpieza antes del chunking
Usar renderizado JS cuando sea necesario
Limitar el uso de crawlers a dominios controlados
Aquí tienes la sección completa de Loaders de bases de datos, lista para integrar en tu unidad:
Loaders de bases de datos
Los loaders de bases de datos permiten integrar datos estructurados directamente en un sistema RAG. A diferencia de los documentos tradicionales (PDF, web), aquí la información proviene de tablas, donde cada fila representa una unidad lógica de datos, o sea cada fila → un Document. Esto convierte datos estructurados en texto procesable por el modelo.
Loader
Descripción
SQLDatabaseLoader
Ejecuta consultas SQL y convierte cada fila del resultado en un Document. Compatible con múltiples motores vía SQLAlchemy.
DuckDBLoader
Permite cargar datos desde bases DuckDB, transformando resultados en documentos.
SnowflakeLoader
Extrae datos desde Snowflake y convierte cada fila en texto procesable.
AthenaLoader
Carga resultados de consultas en AWS Athena, ideal para grandes volúmenes de datos en la nube.
CassandraLoader
Permite trabajar con datos distribuidos en Cassandra, convirtiendo filas en documentos.
MongoDBLoader
Carga documentos desde MongoDB (NoSQL), transformando cada registro en un Document.
from langchain_community.document_loaders import SQLDatabaseLoaderfrom langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///mi_base.db")loader = SQLDatabaseLoader(db, query="SELECT * FROM reservas")documents = loader.load()
Buenas prácticas (nivel pro)
Convertir datos a texto limpio
No hacer SELECT * en producción
Limitar resultados (LIMIT)
Elegir columnas relevantes
Loaders de sistemas empresariales (SaaS)
Los loaders de sistemas empresariales permiten integrar información directamente desde herramientas utilizadas en entornos corporativos. En lugar de trabajar con archivos locales o bases de datos, estos loaders acceden a plataformas como sistemas de documentación, almacenamiento en la nube o herramientas de colaboración. A diferencia de otros loaders, aquí necesitas acceso a sistemas externos.
API tokens
OAuth
credenciales de usuario
cookies de sesión
Loader
Descripción
NotionDBLoader
Carga contenido desde una base de datos de Notion, convirtiendo cada página o entrada en un Document.
NotionDirectoryLoader
Carga exportaciones completas de Notion (directorios), incluyendo múltiples páginas y documentos.
ConfluenceLoader
Extrae páginas y contenido de espacios en Confluence, incluyendo opcionalmente adjuntos.
SlackDirectoryLoader
Carga mensajes desde un export de Slack, convirtiendo conversaciones en documentos.
DropboxLoader
Permite cargar archivos almacenados en Dropbox, incluyendo documentos y PDFs.
OneDriveLoader
Accede a archivos en Microsoft OneDrive y los transforma en documentos.
SharePointLoader
Carga contenido desde SharePoint, incluyendo documentos corporativos y bibliotecas de archivos.
Ejemplo básico (Notion)
from langchain_community.document_loaders import NotionDBLoaderloader = NotionDBLoader(integration_token="your_token",database_id="your_database_id")documents = loader.load()
Consideraciones importantes
Calidad del contenido: estos sistemas suelen contener texto desordenado, duplicados y mensajes irrelevantes por lo que es necesaria una limpieza posterior
El volumen de datos puede ser muy alto: miles de mensajes, documentos largos y múltiples fuentes. En este caso el filtrado es importante.
Privacidad y seguridad: Dado que trabajas con datos sensibles como información interna, conversaciones privadas y documentos confidenciales, es fundamental controlar accesos.
Buenas prácticas
Filtrar por fechas o relevancia
Usar metadata (autor, canal, fecha)
Limpiar antes de embeddings
Limitar el scope de datos
Loaders de repositorios y código
Los loaders de repositorios permiten trabajar con código fuente y artefactos asociados (issues, documentación) dentro de un sistema RAG. Son especialmente útiles para construir asistentes técnicos, copilots o sistemas de búsqueda sobre bases de código.
Estos loaders extraen archivos de repositorios locales o remotos y los convierten en objetos Document, manteniendo información relevante como rutas de archivo, nombres o metadatos del repositorio.
Loader
Descripción
GitLoader
Carga archivos de un repositorio Git (local o clonado desde remoto), convirtiendo cada archivo en un Document.
GithubFileLoader
Permite cargar archivos específicos desde un repositorio de GitHub mediante la API.
GitHubIssuesLoader
Extrae issues de un repositorio de GitHub, incluyendo títulos, descripciones y comentarios.
Loaders de contenido multimedia (audio, imagen, vídeo)
Los loaders de contenido multimedia permiten incorporar a un sistema RAG información que originalmente no está en formato de texto, como audio, imágenes o vídeos. Dado que los modelos de lenguaje trabajan con texto, estos loaders realizan una transformación previa: convierten contenido multimedia en texto procesable. Esto se consigue mediante tecnologías como:
transcripción de audio (speech-to-text)
OCR (reconocimiento de texto en imágenes)
generación automática de descripciones
Loader
Descripción
YoutubeLoader
Extrae transcripciones de vídeos de YouTube y las convierte en texto.
AssemblyAIAudioLoader
Carga transcripciones existentes desde AssemblyAI.
AssemblyAIAudioTranscriptLoader
Transcribe archivos de audio (locales o URL) usando AssemblyAI.
YoutubeAudioLoader
Descarga audio de vídeos de YouTube para su posterior procesamiento.
UnstructuredImageLoader
Extrae texto de imágenes mediante OCR.
ImageCaptionLoader
Genera descripciones automáticas de imágenes usando modelos de captioning.
Tipos de transformación
Audio → texto: Convierte voz en texto como llamadas, podcast o reuniones.
Imagen → texto: En esta caso hay dos enfoques:
OCR → extrae texto real
Captioning → describe la imagen
Vídeo → texto: generalmente mediante: transcripción del audio o subtítulos
Ejemplo básico (YouTube)
from langchain_community.document_loaders import YoutubeLoaderloader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=XXXX",add_video_info=True)documents = loader.load()
Ejemplo básico (audio)
from langchain_community.document_loaders import AssemblyAIAudioTranscriptLoaderloader = AssemblyAIAudioTranscriptLoader(file_path="audio.mp3")documents = loader.load()
Consideraciones importantes
Calidad del texto generado: La calidad depende del modelo de conversión ya que puede haber errores en transcripción, ruido en audio o OCR imperfecto lo que impacta directamente en embeddings.
Coste y latencia: Estos procesos suelen ser más lentos y más costosos debido a APIs externas.
Contexto limitado: El texto generado puede perder matices, simplificar contenido y omitir información visual.
Buenas prácticas
Revisar la calidad de la transcripción
Limpiar el texto antes de embeddings
Añadir metadata (fuente, timestamp, tipo)
Dividir correctamente en chunks
Aquí tienes la sección completa, alineada con el resto de tu unidad:
Loaders de datos públicos y fuentes externas
Los loaders de datos públicos permiten integrar información procedente de fuentes abiertas como enciclopedias, repositorios científicos o plataformas de contenido online. A diferencia de los loaders empresariales, aquí se trabaja con datos accesibles públicamente, lo que facilita la experimentación y el desarrollo de prototipos.
Loader
Descripción
WikipediaLoader
Carga contenido de páginas de Wikipedia a partir de una búsqueda o término específico.
PubMedLoader
Recupera artículos y abstracts del repositorio biomédico PubMed.
ArxivLoader
Carga papers científicos desde arXiv, extrayendo contenido desde PDFs o abstracts.
RedditPostsLoader
Extrae publicaciones y comentarios de Reddit desde un subreddit específico.
HNLoader
Carga contenido de Hacker News, incluyendo noticias y comentarios.
from langchain_community.document_loaders import WikipediaLoaderloader = WikipediaLoader(query="LangChain", load_max_docs=2)documents = loader.load()
Consideraciones importantes
Calidad variable del contenido: dependiendo de la fuente, el contenido puede ser generalista, informal o altamente técnico.
Ruido y relevancia: No todo lo que se carga es útil se puede cargar comentarios irrelevantes, contenido duplicado o información no estructurada
Dependencia externa: APIs , límites de uso y disponibilidad del servicio
Buenas prácticas
Limitar número de documentos (load_max_docs)
Filtrar por relevancia
Limpiar contenido antes de embeddings
Usar metadata para contexto (fuente, fecha, autor)
Loaders empresariales avanzados
Los loaders empresariales avanzados permiten integrar sistemas especializados que forman parte del stack tecnológico de una empresa. A diferencia de los loaders SaaS más generales (como Notion o Slack), estos se centran en herramientas específicas de negocio, como CRM, analítica, diseño o procesamiento de datos.
Loader
Descripción
Airbyte<Name>Loader
Conectores basados en Airbyte para integrar múltiples fuentes (Salesforce, HubSpot, Stripe, Zendesk, etc.).
AirtableLoader
Carga datos desde tablas de Airtable, convirtiendo cada registro en un Document.
FigmaFileLoader
Extrae información desde archivos de diseño en Figma, incluyendo estructuras y contenido textual.
DatadogLogsLoader
Carga logs desde Datadog, transformando eventos y registros en documentos analizables.
Para utilizar Airbyte<Name>Loader, se necesita instalar el paquete airbyte-cdk que es el Connector Development Kit (CDK) de Airbyte. Una librería de Python diseñada para construir conectores (sources) de datos de forma estandarizada.
airbyte-cdk es una herramienta de bajo nivel para crear conectores de datos robustos y escalables. Dentro de un sistema RAG, su papel no es directo, sino que actúa como capa intermedia que permite integrar fuentes externas complejas de forma estandarizada.
Si estás construyendo sistemas avanzados o integraciones personalizadas, es una pieza clave. Si estás consumiendo datos con loaders ya existentes, probablemente ni siquiera necesites interactuar con él directamente.
Cliente Juan Pérez trabaja en Hotel Sol. Su email es [email protected].
Consideraciones importantes
Dependencia de APIs: considera tener límites de uso, latencia y cambios en endpoints
Calidad del dato: estos sistemas contienen datos incompletos, campos técnicos y estructuras complejas, por lo que requieren transformación antes de embeddings.
Seguridad: datos sensibles (clientes, pagos, logs) o credenciales de acceso. Es imprescindible gestionar permisos correctamente
Buenas prácticas
Seleccionar solo campos relevantes
Transformar datos en lenguaje natural
Añadir metadata útil (fecha, tipo, origen)
Limitar volumen de datos
Loaders de almacenamiento y cloud
Los loaders de almacenamiento y cloud permiten cargar documentos desde sistemas de almacenamiento remoto, como servicios en la nube o buckets de archivos. En lugar de acceder a archivos locales, estos loaders trabajan con datos alojados en infraestructuras externas.
Loader
Descripción
S3FileLoader
Carga un archivo específico desde un bucket de Amazon S3.
S3DirectoryLoader
Carga múltiples archivos desde un bucket o carpeta en S3.
CloudBlobLoader
Permite acceder a blobs desde distintas fuentes cloud (S3, URLs, etc.).
OBSFileLoader
Carga archivos desde Huawei Object Storage (OBS).
Ejemplo básico (S3)
from langchain_community.document_loaders import S3FileLoaderloader = S3FileLoader(bucket="mi-bucket",key="ruta/archivo.pdf")documents = loader.load()
Consideraciones importantes
Autenticación: Necesitas credenciales configuradas como AWS credentials, roles IAM, tokens, etc.
Tipos de archivos: Estos loaders no procesan directamente el contenido solo lo recuperan, luego necesitarás un loader según el tipo de archivo objetivo (PDF loader, text loader, etc.)
Latencia: acceso remoto + transferencias de archivos que pueden ser más lento que en entornos locales.
Buenas prácticas
Limitar el número de archivos
Filtrar por tipo (PDF, TXT…)
Combinar con otros loaders
Aplicar limpieza posterior
Loaders de comunicación y chats
Los loaders de comunicación y chats permiten incorporar conversaciones reales dentro de un sistema RAG. Estas fuentes incluyen mensajes de plataformas como WhatsApp, Telegram, Discord o Facebook, donde el conocimiento no está en documentos formales, sino en interacciones entre personas.
Loader
Descripción
WhatsAppChatLoader
Carga conversaciones exportadas de WhatsApp en formato de texto.
TelegramChatLoader
Procesa chats exportados de Telegram (normalmente en JSON o texto).
DiscordChatLoader
Carga historiales de chat de Discord desde exports.
FacebookChatLoader
Extrae conversaciones de Facebook Messenger desde archivos exportados.
Ejemplo básico (WhatsApp)
El loader WhatsAppChatLoader no accede a la app ni a la API de WhatsApp. Trabaja sobre exportaciones de chats generadas manualmente.
from langchain_community.document_loaders import WhatsAppChatLoaderloader = WhatsAppChatLoader("data/chat_whatsapp.txt")documents = loader.load()
Ejemplo archivo exportado:
[10/01/2024, 10:30] Juan: ¿Tenemos disponibilidad este fin de semana?[10/01/2024, 10:32] Hotel: Sí, tenemos habitaciones libres.[10/01/2024, 10:33] Juan: Perfecto, ¿precio?
Resultado:
Document( page_content="Juan pregunta por disponibilidad. El hotel responde que hay habitaciones disponibles.", metadata={"source": "whatsapp", "date": "2024-01-10"})
Preprocesamiento (El texto raw no es óptimo).
clean_docs = []for doc in documents: text = doc.page_content# limpieza básica text =" ".join(text.split()) doc.page_content = text clean_docs.append(doc)
Necesidad de preprocesamiento: Aquí la limpieza es especialmente importante:
unir mensajes relacionados
eliminar ruido
resumir conversaciones
estructurar el contexto
Buenas prácticas
agrupar mensajes por conversación
filtrar mensajes irrelevantes
añadir metadata (usuario, fecha)
convertir a lenguaje más estructurado
Aquí tienes la sección completa, coherente con el resto del bloque:
Loaders utilitarios
Los loaders utilitarios no están diseñados para una fuente de datos específica, sino para optimizar y gestionar el proceso de carga. Actúan como herramientas auxiliares que permiten trabajar con múltiples documentos, combinar fuentes o mejorar el rendimiento del sistema. No cargan datos por sí mismos, sino que orquestan otros loaders.
Estos loaders permiten:
cargar grandes volúmenes de archivos
combinar múltiples fuentes en un solo flujo
mejorar el rendimiento mediante paralelización
Loader
Descripción
DirectoryLoader
Carga todos los archivos de un directorio, aplicando loaders automáticamente según el tipo de archivo.
MergedDataLoader
Combina múltiples loaders en uno solo, unificando diferentes fuentes de datos.
ConcurrentLoader
Permite cargar documentos en paralelo para mejorar el rendimiento.
Ejemplo carga masiva con DirectoryLoader:
from langchain_community.document_loaders import DirectoryLoaderloader = DirectoryLoader(path="./data",glob="**/*.pdf")documents = loader.load()
Comprender los conceptos básicos de la ingeniería de prompts: Obtener una base sólida sobre cómo comunicarse eficazmente con los LLM mediante prompts, preparando el terreno para técnicas más avanzadas.
Dominar técnicas avanzadas de prompts: Aprender y aplicar métodos avanzados de ingeniería de prompts, como el aprendizaje de pocos ejemplos (few-shot) y el aprendizaje de consistencia propia (self-consistent learning), para optimizar las respuestas del LLM.
Utilizar plantillas de prompts de LangChain: Adquirir fluidez en el uso de las plantillas de prompts de LangChain para estructurar y optimizar tus interacciones con los LLM.
Desarrollar agentes de LLM prácticos: Adquirir las habilidades para crear e implementar agentes, como bots de preguntas y respuestas (QA) y herramientas de resumen de texto, utilizando las plantillas de prompts de LangChain, traduciendo el conocimiento teórico en soluciones prácticas.
Setup
Para este laboratorio usamos el entorno de prácticas creado en el artículo: Preparación del entorno RAG híbrido (Ollama + DeepSeek + LangChain) para prácticas.
En esta sección configuramos los LLM usando nuestro entorno hibrido DeepSeek + Ollama utilizando el módulo llm_config:
lmm : Especifica el módulo a utilizar. sdk para deepseek modelo deepseek-chat y oll para LLM local Ollama modelo qwen:4b. Por defecto utiliza DeepSeek.
params : Configura los parámetros del modelo establecidos por defecto como:
temperature: 1, Aleatoriedad del modelo.
max_tokens: 50, Longitud de la respuesta en DeepSeek
top_p: 1, Diversidad de palabras considerando la probabilidad acumulada (no usar junto con temperature).
top_k: 40, Diversidad de palabras considerando la frecuencia
frequency_penalty: 0, Penalización de frecuencia – DeepSeek
presence_penalty: 0, Penalización de presencia – DeepSeek
repeat_penalty: 1.1 Penalización de repetición – Ollama
Para este lab utilizaremos solamente DeepSeek por ser un modelo más grande y provee mejores respuestas.
Cuando trabajamos con modelos de lenguaje en LangChain, el método principal para ejecutar el modelo es .invoke(). Es el punto central de interacción con el modelo y forma parte del diseño unificado de LangChain y muchos componentes implementan la misma interfaz.
La respuesta no siempre es un simple texto. En muchos casos (especialmente con Chat Models como DeepSeek), obtienes un objeto estructurado con mucha más información que puede ser extraída como objetos generados por el modelo que estés usando.
EL objeto content, es el que tiene la respuesta del prompt, para que se muestre solo ese usamos response.content. Este viene formateado en Markdown. Para visualizar correctamente el formato importamos librerías de visualización de Jupyter:
from IPython.display import display, Markdown
Definimos una función para reemplazar a print() en la respuesta que muestre el texto en el formato correcto:
# invocar el modelo + paranetrosllm = get_llm(llm="dsk", params={"temperature": 0.8})# promptprompt ="Cual es un buen nombre para un perro"response = llm.invoke(prompt)print(f"prompt: {prompt}n")show(response)
¡Elegir el nombre de un perro es una decisión importante y divertida! Para ayudarte, aquí tienes algunas categorías con opciones y consejos para que encuentres el nombre perfecto:1. Nombres Clásicos y Populares (Siempre funcionan)Son fáciles de recordar y suelen tener una o dos sílabas, lo que ayuda al perro a reconocerlo rápido.Machos: Max, Toby, Bruno, Leo, Rocky, Simba, Coco, Thor, Lucas, Kiko.Hembras: Luna, Nina, Lola, Bella, Maya, Kira, Dora, Nala, Chispa, Mora.2. Nombres Inspirados en la Cultura HispanaSuenan cálidos y con mucha personalidad.Comida: Churro, Taco, Canela, Mochi, Café, Pan, Fideo, Dulce.Lugares o Cosas: Sol, Río, Sierra, Cielo, Brisa, Bolívar, Gitano.Tradicionales: Chucho, Pocho, Cachito, Güero, Negro, Pinto.3. Nombres Divertidos y OriginalesPerfectos para perros con mucha energía o para sacar una sonrisa.De personajes: Chewbacca, Yoda, Groot, Pikachu, Shrek, Harry (Potter), Gandalf.Irónicos: Goliat (para un perro chico), Pulga (para un perro grande), Tranquilo (para uno inquieto), Sirena (para un macho).Acciones o sonidos: Zoom, Ñam, Guau, Tic-Tac, Bulto, Moco.4. Nombres Cortos y Funcionales (Ideal para adiestramiento)Los perros responden mejor a sonidos fuertes y cortos (1 o 2 sílabas).Con sonidos fuertes: Kai, Rex, Zeus, Xena, Zara, Crixus.Con 'i' final (agudos): Toni, Yuki, Loki, Mili, Roni.5. Nombres Épicos o con SignificadoPara perros con presencia o que te inspiran.Poderosos: Thor, Odín, Hera, Ares, Maya (ilusión), Atlas.Naturaleza: Bosco, Selva, Nube, Trueno, Brisa, Ola, Copo (de nieve).Consejos finales para elegir:Prueba el nombre en voz alta: ¿Suena bien cuando lo gritas en el parque? ¿Se confunde con una orden común (ej: "No", "Flojo" suena a "Fue")?Observa su personalidad: ¿Es un perro tranquilo como un Tao o un terremoto como un Tornado?La regla de las dos sílabas: Es el equilibrio perfecto entre corto (que se oiga bien) y largo (que no suene como un ladrido). Ej: Kai, Lúa, Tito, Nala.No te apresures: A veces, el nombre ideal llega después de unos días de convivencia, al ver su carácter.Mi recomendación personal: Si quieres algo tierno y moderno, Kai (que significa "mar" en hawaiano y "perdón" en japonés, es sonoro y corto). Si buscas algo clásico y dulce, Luna es un acierto casi universal.¿Qué tipo de perro es (raza, tamaño, carácter)? ¡Con esos detalles puedo recomendarte nombres más específicos!
Recuerden que la respuesta saldrá formateada en Jupiter y se verá como texto editado, aqui lo he puesto en un cuadro de código para diferenciarlo. Listo.
Ingeniería de Prompt
Zero-shot Prompt
El zero-shot prompting es una técnica en la que el modelo realiza una tarea sin recibir ejemplos previos ni entrenamiento específico para esa tarea. Este enfoque pone a prueba la capacidad del modelo para entender instrucciones y aplicar su conocimiento a un contexto nuevo sin necesidad de demostraciones.
Un prompt zero-shot suele incluir instrucciones claras y una tarea definida, lo que permite al modelo utilizar su conocimiento previo para generar una respuesta adecuada.
# Configurar el modelollm = get_llm(llm="dsk", params={"temperature": 0.8})# prompt zero-shotprompt ="Clasifica el sentimiento del siguiente texto: 'Me encanta este producto'"# ejecutarresponse = llm.invoke(prompt)# mostrar resultadoshow(response)
El sentimiento del texto "Me encanta este producto" es positivo.
Otros ejemplos:
response = llm.invoke("Clasifica como verdadero o falso: La Torre Eiffel está en Berlín.")show(response)
Verdadero o falso: La Torre Eiffel está en Berlín.Falso. La Torre Eiffel se encuentra en París, Francia, no en Berlín.
Cuando usarlo:
Tareas simples
Preguntas directas
Cuando quieres rapidez y no necesitas precisión extrema
Limitaciónes
Menor control sobre la salida
Mayor probabilidad de error en tareas complejas
One-shot Prompt
El one-shot prompting es una técnica en la que se proporciona al modelo un único ejemplo de la tarea antes de pedirle que realice una tarea similar.
En este enfoque:
Primero se muestra un ejemplo
Luego se plantea un nuevo caso
El modelo utiliza ese ejemplo como referencia para entender:
el formato de la respuesta
el estilo esperado
el tipo de resultado
# Configurar el modelollm = get_llm(llm="dsk", params={"max_tokens": 50, "temperature": 0.2})prompt ="""Aqui hay un ejemplo de traduccion de castellano a ingles: Castellano: “¿Como es el clima hoy?” Frances: “Comment est le temps aujourd'hui?” Ahora, tradusca el siguiente texto de castellano al frances: Castellano: "¿Donde esta el supermercado mas cercano?”"""response = llm.invoke(prompt)show(response)
Aquí tienes la traducción al francés:Francés: “Où est le supermarché le plus proche ?”
Otro ejemplo:
prompt ="""Ejemplo:Asunto: Solicitud de información sobre el cursoEstimado/a señor/a,Me pongo en contacto con usted para solicitar información adicional sobre el curso de marketing digital que ofrecen en su institución.Quedo a la espera de su respuesta.Atentamente, Juan PérezAhora escribe un email formal solicitando información sobre un servicio de consultoría empresarial."""response = llm.invoke(prompt)show(response)
Asunto: Solicitud de información sobre servicios de consultoría empresarialEstimado/a señor/a,Por medio del presente, me dirijo a ustedes con el fin de solicitar información detallada sobre los servicios de consultoría empresarial que ofrecen.Agradecería que pudieran proporcionarme datos sobre las áreas de especialización, la metodología de trabajo, los plazos estimados y las tarifas asociadas a sus servicios. Asimismo, si cuentan con casos de éxito o referencias de clientes anteriores, le agradecería que me los hicieran llegar.Quedo a la espera de su pronta respuesta y quedo a su disposición para cualquier consulta adicional que consideren necesaria.Atentamente,[Tu nombre completo][Tu cargo o empresa, si aplica][Tu correo electrónico][Tu número de teléfono, opcional]
Ejemplo con extracción de palabras clave:
prompt ="""Ejemplo:Frase: El marketing digital permite a las empresas llegar a más clientes a través de internet. Palabras clave: marketing digital, empresas, clientes, internetAhora extrae las palabras clave de la siguiente frase:"La analítica de datos ayuda a las organizaciones a tomar decisiones basadas en información.""""response = llm.invoke(prompt)show(response)
Palabras clave: analítica de datos, organizaciones, tomar decisiones, información
Cuándo usar one-shot
Es especialmente útil cuando:
Quieres guiar la respuesta del modelo
Necesitas un formato concreto
No quieres usar muchos ejemplos
Few-shot prompt
El few-shot prompting extiende el enfoque de one-shot proporcionando varios ejemplos (normalmente entre 2 y 5) antes de pedir al modelo que realice la tarea.
Estos ejemplos establecen un patrón y un contexto más claros, ayudando al modelo a comprender mejor el formato de salida, el estilo y el tipo de razonamiento esperado.
Esta técnica es especialmente eficaz en tareas más complejas, donde un único ejemplo puede no ser suficiente para transmitir todos los matices.
A continuación se muestra un ejemplo de few-shot learning clasificando emociones a partir de frases.
Proporcionamos al modelo tres ejemplos, cada uno etiquetado con una emoción adecuada —alegría, frustración y tristeza— para establecer un patrón o guía sobre cómo clasificar las emociones en distintas frases.
Después de presentar estos ejemplos, planteamos un nuevo caso. La tarea del modelo es clasificar la emoción expresada en esta nueva frase basándose en lo aprendido a partir de los ejemplos proporcionados.
llm = get_llm(llm="dsk", params={"max_tokens": 50, "temperature": 0.2})prompt ="""Aqui se muestran varios ejemplos de clasificacion de emociones: Frase: 'Acabo de ganar mi primer maraton' Emocion: Alegria Frase: 'No puedo creer que haya perdido las llaves otravez' Emocion: Frustración Frase: 'Mi mejor amigo se ha mudado a otro país' Emocion: Tristeza Ahora clasifica la emocion de la siguiente frase: Frase: 'La pelicula tenia crimenes tan explicitos que he tenido quen cubrirme los ojos' """response = llm.invoke(prompt)show(response)
Basándome en los ejemplos proporcionados, la emoción más adecuada para la frase:'La pelicula tenia crimenes tan explicitos que he tenido que cubrirme los ojos'sería Asco o Repulsión, ya que la reacción de cubrirse los ojos indica una fuerte aversión o incomodidad ante lo explícito y perturbador de las imágenes.
Chain-of-thought (CoT) prompt
El chain-of-thought (CoT) prompting es una técnica que anima al modelo a descomponer problemas complejos en un razonamiento paso a paso antes de llegar a una respuesta final. Al mostrar o solicitar explícitamente los pasos intermedios, esta técnica mejora la capacidad del modelo para resolver problemas y reduce errores en tareas que requieren razonamiento en múltiples etapas. El CoT es especialmente eficaz en problemas matemáticos, razonamiento lógico y tareas complejas de toma de decisiones.
A continuación se muestra un ejemplo diseñado para guiar al modelo a través de una secuencia de pasos de razonamiento para resolver un problema. En este caso, el problema es una pregunta de álgebra lineal:
Imaginemos que tenemos tres personas:Bob, Alice y Tim, que han ido al supermercado y compraron manzanas, naranjas y peras.
Bob compro 3 manzanas, 6 naranjas y 2 peras, con un coste de 34€.
Alice compro 10 manzanas, 3 naranjas y 8 peras, con un coste de 69€.
Tim compro 1 manzanas, 7 naranjas y 5 peras, con un coste de 48€.
Y queremos averiguar cuánto cuesta cada producto.
La técnica CoT consiste en estructurar el prompt indicando al modelo que “desglose cada paso del cálculo”. Esto anima al modelo a incluir los pasos de razonamiento de forma explícita, imitando un proceso de resolución de problemas similar al humano.
llm = get_llm(llm="dsk", params={"max_tokens": 500, "temperature": 0.5})prompt ="""Considera el siguiente problema: Imaginemos que tenemos tres personas: Bob, Alice y Tim,Tim, que han ido al supermercado y compraron manzanas, naranjas y peras. Bob compro 3 manzanas, 6 naranjas y 2 peras, con un coste de 34€. Alice compro 10 manzanas, 3 naranjas y 8 peras, con un coste de 69€. Tim compro 1 manzanas, 7 naranjas y 5 peras, con un coste de 48€. ¿Determina el coste de cada fruta? Desglosa cada paso del calculo. """response = llm.invoke(prompt)show(response)
Vamos a resolver el problema paso a paso.Primero definimos las variables:( m ) = precio de una manzana (en €)( n ) = precio de una naranja (en €)( p ) = precio de una pera (en €)Del enunciado obtenemos las ecuaciones:Bob:( 3m + 6n + 2p = 34 ) (1)Alice:( 10m + 3n + 8p = 69 ) (2)Tim:( 1m + 7n + 5p = 48 ) (3)-------------------------------------------------------------------Paso 1: Eliminar una variableVamos a eliminar ( m ) usando las ecuaciones (1) y (3).Multiplicamos (3) por 3:( 3m + 21n + 15p = 144 ) (4)Restamos (1) de (4):((3m + 21n + 15p) - (3m + 6n + 2p) = 144 - 34)Esto da:( 15n + 13p = 110 ) (5)-------------------------------------------------------------------Paso 2: Eliminar la misma variable ( m ) entre (2) y (3)Multiplicamos (3) por 10:( 10m + 70n + 50p = 480 ) (6)Restamos (2) de (6):((10m + 70n + 50p) - (10m + 3n + 8p) = 480 - 69)Esto da:( 67n + 42p = 411 ) (7)-------------------------------------------------------------------Paso 3: Resolver el sistema de dos ecuaciones (5) y (7)Tenemos:[begin{cases}15n + 13p = 110 quad (5)67n + 42p = 411 quad (7)end{cases}]Multiplicamos (5) por 42 y (7) por 13 para igualar coeficientes de ( p ):(5) × 42:( 630n + 546p = 4620 ) (8)(7) × 13:( 871n + 546p = 5343 ) (9)Restamos (8) de (9):((871n - 630n) + (546p - 546p) = 5343 - 4620)( 241n = 723 )Despejamos ( n ):( n = frac{723}{241} = 3 )-------------------------------------------------------------------Paso 4: Sustituir ( n = 3 ) en (5)( 15(3) + 13p = 110 )( 45 + 13p = 110 )( 13p = 65 )( p = 5 )Paso 5: Sustituir ( n = 3 ) y ( p = 5 ) en (3)( m + 7(3) + 5(5) = 48 )( m + 21 + 25 = 48 )( m + 46 = 48 )( m = 2 )-------------------------------------------------------------------Solución final:Manzana: 2 €Naranja: 3 €Pera: 5 €Podemos comprobar con la ecuación (1):( 3(2) + 6(3) + 2(5) = 6 + 18 + 10 = 34 ) ✅
Al generar la respuesta desglosa es mejor para entender el proceso de cálculo. Veamos otro ejemplo más sencillo:
llm = get_llm(llm="dsk", params={"temperature": 0.5})prompt ="""Un estudiante tiene un examen importante dentro de dos días, pero sus amigos le han invitado a ir al cine esta noche. Analiza la situación paso a paso teniendo en cuenta: - la importancia del examen - el tiempo disponible para estudiar - el descanso y ocio Desglosa tu razonamiento paso a paso y luego da una recomendación final. """response = llm.invoke(prompt)show(response)
Claro, analicemos la situación paso a paso.Paso 1: Identificar el contexto y las prioridadesEl examen es en dos días, lo que significa que hay tiempo limitado pero no cero.La invitación es para esta noche, lo que implica que si va al cine, perderá varias horas de estudio (viaje, película, tiempo social).El descanso y ocio son importantes para la salud mental, pero el examen tiene un peso académico.Paso 2: Evaluar el tiempo disponibleSi hoy es el día 1 (noche) y el examen es el día 3 (mañana/tarde), quedan aproximadamente:Esta noche (unas 3-4 horas si no va al cine).Todo el día de mañana (día completo de estudio).La mañana del examen (último repaso).Ir al cine esta noche consume al menos 3-4 horas (incluyendo desplazamiento).Si estudia esta noche, podría avanzar temas clave y dejar el día siguiente para repaso y práctica.Paso 3: Ponderar la importancia del examenSi el examen es decisivo para la nota final, una beca o un requisito, la prioridad debe ser máxima.Si es un examen parcial o de menor peso, podría permitirse un equilibrio.Paso 4: Considerar el descanso y ocioEl ocio es necesario para evitar el agotamiento, pero puede posponerse.Una opción intermedia: proponer a los amigos ir otro día (después del examen) o hacer algo más corto (como un café rápido) para no perder toda la noche.Paso 5: Decidir basado en el balanceSi el estudiante ha estudiado con antelación y se siente preparado, una salida corta podría ser viable.Si no ha estudiado lo suficiente, lo prudente es rechazar la invitación y dedicar la noche al estudio, programando un descanso para mañana.Recomendación final:Prioriza el examen. Rechaza la invitación al cine esta noche. Explica a tus amigos que tienes un examen importante y que los verás después. Usa esta noche para estudiar de forma enfocada (por ejemplo, 2 horas de repaso y luego descanso). Mañana puedes tomar un descanso programado (como una caminata o ver una serie corta) para no saturarte. Así combinas responsabilidad con un poco de ocio controlado.
Self-consistency
La self-consistency es una técnica avanzada en la que el modelo genera múltiples soluciones o respuestas independientes para un mismo problema y, posteriormente, evalúa estas distintas aproximaciones para determinar cuál es la más consistente o fiable. Este método mejora la precisión aprovechando la capacidad del modelo para abordar un problema desde diferentes perspectivas y seleccionar la solución más robusta mediante comparación y verificación.
llm = get_llm(llm="dsk", params={"temperature": 0.5})prompt =""" Resuelve el siguiente problema generando varias soluciones independientes y luego elige la mejor. Problema: Un negocio vende un producto a 20€. El coste de producción es de 12€ por unidad y los costes fijos mensuales son de 800€. ¿Cuántas unidades necesita vender para empezar a obtener beneficios? Instrucciones: 1. Genera al menos 3 formas diferentes de resolver el problema. 2. Explica cada razonamiento paso a paso. 3. Compara los resultados obtenidos. 4. Selecciona la solución más consistente y explica por qué es la correcta. Respuesta final: Indica claramente el número de unidades necesarias y justifica tu elección."""response = llm.invoke(prompt)show(response)
Vamos a resolver el problema paso a paso, generando varias soluciones independientes.Datos del problemaPrecio de venta por unidad: 20 €Coste de producción por unidad: 12 €Costes fijos mensuales: 800 €El beneficio comienza cuando los ingresos superan los costes totales.----------------------------------------------------------------------Solución 1: Método algebraico (ecuación de beneficio)Razonamiento:El beneficio se calcula como:Beneficio} = Ingresos - Costes totalesIngresos = ( 20x ) (siendo ( x ) el número de unidades)Costes totales = Costes fijos + Costes variables = ( 800 + 12x )Para empezar a obtener beneficios, el beneficio debe ser mayor que cero:[20x - (800 + 12x) > 0]Paso a paso:Simplificamos:( 20x - 800 - 12x > 0 )( 8x - 800 > 0 )Sumamos 800:( 8x > 800 )Dividimos entre 8:( x > 100 )Resultado: Necesita vender más de 100 unidades, es decir, 101 unidades para tener beneficio positivo.----------------------------------------------------------------------Solución 2: Método del punto de equilibrio (umbral de rentabilidad)Razonamiento:El punto de equilibrio es cuando los ingresos igualan a los costes totales. A partir de ahí, cada unidad adicional da beneficio.Paso a paso:Ingresos = Costes totales( 20x = 800 + 12x )Restamos ( 12x ):( 8x = 800 )Despejamos:( x = 100 )En el punto exacto (100 unidades) el beneficio es cero.Para empezar a obtener beneficios se necesita vender una unidad más:( 100 + 1 = 101 ) unidades.Resultado: 101 unidades.----------------------------------------------------------------------Solución 3: Método del margen de contribuciónRazonamiento:El margen de contribución por unidad es:[text{Precio} - text{Coste variable} = 20 - 12 = 8 ,€]Cada unidad vendida aporta 8 € para cubrir los costes fijos.Para cubrir 800 € de costes fijos:[frac{800}{8} = 100 text{ unidades}]A partir de la unidad 101, el margen de contribución se convierte en beneficio.Resultado: 101 unidades.----------------------------------------------------------------------Comparación de resultadosLos tres métodos coinciden en que se necesitan 101 unidades para empezar a obtener beneficios.Selección de la mejor soluciónLas tres soluciones son consistentes y correctas. Sin embargo, la más intuitiva y rápida es la del margen de contribución, porque:Permite visualizar claramente cuánto aporta cada unidad.Es muy usada en negocios para cálculos rápidos de rentabilidad.No requiere resolver ecuaciones complejas.----------------------------------------------------------------------Respuesta finalSe necesitan 101 unidades para empezar a obtener beneficios.La justificación principal es que con 100 unidades se cubren exactamente los costes totales (beneficio cero), y a partir de la unidad 101, cada venta genera un beneficio neto de 8 €.
Aplicaciones del prompting en diferentes casos de uso
En esta sección, demostraremos cómo aprovechar las plantillas de prompt de LangChain para construir aplicaciones prácticas con resultados consistentes y reproducibles. Cada aplicación sigue un patrón común utilizando el enfoque LCEL:
Definir el contenido o problema a resolver.
Crear una plantilla con variables para contenido dinámico.
Convertir la plantilla en un PromptTemplate de LangChain.
Construir una cadena utilizando el operador pipe | para conectar:
Variables de entrada
La plantilla de prompt
El LLM
Un analizador de salida (output parser)
Ejecutar la cadena con entradas específicas para generar resultados.
Este enfoque estructurado permite crear componentes reutilizables para diferentes tareas de procesamiento de lenguaje natural, manteniendo al mismo tiempo la flexibilidad para ajustar parámetros y entradas. Verás cómo este patrón se aplica en distintos casos de uso.
Introducción a LangChain
LangChain es un framework potente diseñado para simplificar el desarrollo de aplicaciones basadas en modelos de lenguaje. Creado para abordar los retos de trabajar con LLMs en entornos reales, LangChain proporciona una interfaz estandarizada para conectar modelos con diferentes fuentes de datos y entornos de aplicación.
LangChain actúa como una capa de abstracción, facilitando la construcción de aplicaciones complejas con LLMs sin tener que gestionar los detalles de bajo nivel de la interacción con el modelo. Este framework se ha convertido en una herramienta estándar dentro del ecosistema de los LLM, soportando una amplia variedad de casos de uso, desde chatbots hasta sistemas de análisis de documentos.
En esta sección nos centraremos en las capacidades de las plantillas de prompt de LangChain, mostrando cómo pueden utilizarse para crear interacciones estructuradas y reproducibles con modelos de lenguaje en distintos tipos de aplicaciones.
Plantillas de Prompt
Las plantillas de prompt son un concepto clave en LangChain. Ayudan a transformar la entrada del usuario y los parámetros en instrucciones para un modelo de lenguaje. Estas plantillas pueden utilizarse para guiar la respuesta del modelo, ayudándole a entender el contexto y a generar resultados coherentes y relevantes basados en lenguaje.
Una plantilla de prompt actúa como una estructura reutilizable para generar prompts con valores dinámicos. Permite definir un formato consistente mientras deja espacios reservados para variables que cambian en cada caso de uso. Este enfoque hace que el uso de prompts sea más sistemático y mantenible, especialmente cuando se trabaja con aplicaciones más complejas.
LangChain moderno (a partir de 2025) ofrece dos enfoques principales para trabajar con plantillas:
El enfoque tradicional basado en LLMChain
El patrón más reciente basado en el Lenguaje de Expresión de LangChain (LCEL), que utiliza el operador pipe | para una composición más flexible
LCEL se ha convertido en el enfoque recomendado para construir aplicaciones con LangChain, ya que ofrece mejor capacidad de composición, una visualización más clara del flujo de datos y mayor flexibilidad al construir cadenas complejas.
Para usar una plantilla de prompt con LCEL, normalmente se siguen estos pasos:
Definir la plantilla con variables entre llaves {}
Crear una instancia de PromptTemplate
Construir una cadena utilizando el operador pipe | para conectar los componentes
Ejecutar la cadena con los valores de entrada
Se utiliza PromptTemplate para crear una plantilla de prompt basada en texto. En esta plantilla definirás dos parámetros: adjective y content. Estos parámetros permiten reutilizar el prompt en diferentes situaciones. Por ejemplo, para adaptar el prompt a distintos contextos, basta con proporcionar los valores correspondientes a estos parámetros.
Flujo completo :
variables → template → prompt final → modelo → respuesta
Para utilizarlo se debe importar primeramente:
from langchain_core.prompts import PromptTemplate
llm = get_llm(llm="dsk", params={"temperature": 0.5})# Definicion del Template con las variables dinamicastemplate ="Explica el concepto de {tema} de forma {estilo} en 50 palabras."# Crear el prompt templatePromptTemplate.from_template(template)# sustituye las variables por valorestext1 = prompt.format(tema="AI", estilo="sencillo")text2 = prompt.format(tema="Machine Learning", estilo="tecnico")# Ejecuta el modeloresponse = llm.invoke(text1)show(response)
La IA es como un cerebro digital que aprende de datos para tomar decisiones o resolver problemas. No piensa como humano, sino que reconoce patrones en información. Por ejemplo, cuando buscas fotos de gatos, la IA las identifica porque ha "visto" muchas antes.
response = llm.invoke(text2)show(response)
El Machine Learning es una rama de la inteligencia artificial que permite a sistemas aprender patrones y tomar decisiones a partir de datos, sin programación explícita. Utiliza algoritmos estadísticos y modelos matemáticos que se optimizan iterativamente mediante funciones de pérdida y retropropagación, mejorando su rendimiento con la experiencia.
Método LCEL en LangChain
El siguiente código construye una cadena utilizando el patrón LCEL (LangChain Expression Language). Esta cadena conecta diferentes componentes mediante el operador pipe (|) para crear un flujo de procesamiento. La cadena toma variables de entrada, las pasa a través de la plantilla de prompt, envía el prompt formateado al modelo de lenguaje y utiliza un analizador de salida en formato de texto para devolver la respuesta final.
Vamos a hacer un ejemplo que sea crear un sistema que genere ideas de negocio según sector y público objetivo.
from langchain_core.prompts import PromptTemplatefrom langchain_core.output_parsers import StrOutputParser
Veamos los componentes
# Prompt templatetemplate ="""Genera 3 ideas de negocio en el sector de {sector} dirigidas a {publico}.Explica cada idea en una frase corta."""prompt = PromptTemplate.from_template(template)# llmllm = get_llm(llm="dsk", params={"temperature": 0.5})# output parserparser = StrOutputParser()
Aventura con impacto social: Viajes de voluntariado y deportes extremos en destinos remotos, combinando acción y ayuda comunitaria.Nómadas digitales rurales: Suscripción mensual que ofrece alojamiento y coworking en pueblos con wifi, naturaleza y experiencias locales.Rutas gastronómicas interactivas: Tours urbanos gamificados con realidad aumentada que retan a los viajeros a probar platos callejeros y ganar descuentos.
Agentes de IA
Resumen de texto
En esta sección se crean agentes capaces de completar distintas tareas utilizando plantillas de prompt, como la resumición de texto.
El siguiente ejemplo muestra un agente de resumen de texto diseñado para ayudarte a sintetizar el contenido que proporciones al modelo de lenguaje. La cadena LCEL toma el contenido como entrada, lo procesa a través de la plantilla de prompt, lo envía al modelo y devuelve un resumen conciso.
# Elementoscontent =""" El crecimiento del comercio electrónico en los últimos años ha cambiado profundamente la forma en que las personas compran y venden productos. Plataformas digitales permiten a pequeñas y grandes empresas llegar a clientes en cualquier parte del mundo, eliminando muchas de las barreras tradicionales del comercio físico. Además, el uso de datos y analítica avanzada permite a las empresas personalizar ofertas y mejorar la experiencia del usuario. Por otro lado, los sistemas logísticos han evolucionado para ofrecer entregas más rápidas y eficientes, incluso en el mismo día. Sin embargo, este crecimiento también plantea desafíos, como la sostenibilidad ambiental y la competencia en mercados altamente saturados. En conjunto, el comercio electrónico sigue transformando la economía global y redefiniendo los hábitos de consumo."""# Templatetemplate ="Resume el {content} en una oracion"# promptprompt = PromptTemplate.from_template(template)#llmllm = get_llm(llm="dsk", params={"temperature": 0.5})# parserparser = StrOutputParser()# Cadenacadena_resumenes = ( prompt| llm| parser ) # Executeresponse = cadena_resumenes.invoke({"content" : content})show(response)
El crecimiento del comercio electrónico ha transformado la economía global al eliminar barreras físicas, personalizar ofertas mediante datos y optimizar la logística, aunque enfrenta desafíos como la sostenibilidad y la saturación del mercado.
Q&A Agent
A continuación se muestra un agente de preguntas y respuestas (Q&A) construido utilizando el patrón LCEL.
Este agente permite que el modelo de lenguaje aprenda a partir del contenido proporcionado y responda preguntas basándose en esa información. En ocasiones, si el modelo no dispone de suficiente información, puede generar una respuesta especulativa. Para gestionar esto, le indicaremos explícitamente que responda con “No estoy seguro de la respuesta” cuando no tenga certeza.
La cadena toma tanto el contenido (contexto) como la pregunta como entradas, procesándolos a través de la plantilla antes de enviarlos al modelo de lenguaje:
content =""" El marketing digital es el conjunto de estrategias y técnicas que se utilizan para promocionar productos o servicios a través de canales digitales. Incluye herramientas como redes sociales, email marketing, SEO (optimización para motores de búsqueda) y publicidad online. El SEO se centra en mejorar la visibilidad de una web en los resultados orgánicos de buscadores como Google, mientras que la publicidad online permite llegar a audiencias específicas mediante anuncios pagados."""question ="¿Qué técnica del marketing digital se centra en mejorar la visibilidad en buscadores?"# Templatetemplate ="""Responde a la siguiente {question} basándote en {content} proporcionado:Si no estás seguro de la respuesta, responde: "No estoy seguro de la respuesta".Respuesta:"""# Promtprompt = PromptTemplate.from_template(template)# llmllm = get_llm(llm="dsk", params={"temperature": 0.5})# parserparser = StrOutputParser()# Chainqa_chain = ( prompt| llm| parser)response = qa_chain.invoke({"question": question, "content": content})show(response)
Basándome en el texto proporcionado, la técnica del marketing digital que se centra en mejorar la visibilidad en buscadores es el SEO (optimización para motores de búsqueda).
Clasificación de texto
A continuación se muestra un agente de clasificación de texto diseñado para categorizar textos en categorías predefinidas. Este ejemplo utiliza zero-shot learning, donde el agente clasifica el texto sin haber visto previamente ejemplos relacionados.
Utilizando el enfoque LCEL, creamos una cadena que toma como entrada tanto el texto a clasificar como las categorías disponibles:
text ="""El análisis de datos permite a las empresas identificar patrones de comportamiento de sus clientes y mejorar la toma de decisiones estratégicas."""categories ="Marketing, Tecnología, Finanzas, Recursos Humanos, Logística."template ="""Clasifica el siguiente texto en una de las categorías disponibles:Texto: {text}Categorías: {categories}Categoría:"""prompt = PromptTemplate.from_template(template)llm = get_llm(llm="dsk", params={"temperature": 0.5})parser = StrOutputParser()classifier_chain = ( prompt| llm| parser)response = classifier_chain.invoke({"text" : text , "categories": categories })show(response)
Marketing
Code Generation
A continuación se muestra un ejemplo de un agente de generación de código SQL construido con LCEL. Este agente está diseñado para generar consultas SQL a partir de descripciones proporcionadas. Interpreta los requisitos a partir de la entrada en lenguaje natural y los traduce en código SQL ejecutable.
La cadena toma tu descripción en lenguaje natural y la transforma en una consulta SQL correctamente estructurada:
description ="""Obtener el nombre de los hoteles y el total de reservas realizadas en el último mes.La tabla 'reservas' contiene la columna 'fecha_reserva' y la columna 'hotel_id'.La tabla 'hoteles' contiene 'hotel_id' y 'nombre_hotel'."""template ="""Genera una consulta SQL basada en la siguiente descripción:Descripción: {description}SQL Query:"""prompt = PromptTemplate.from_template(template)llm = get_llm(llm="dsk", params={"temperature": 0.5})parser = StrOutputParser()sql_chain = ( prompt| llm| parser)response = sql_chain.invoke({"description": description})show(response)
SELECT h.nombre_hotel, COUNT(r.hotel_id) AS total_reservasFROM hoteles hLEFT JOIN reservas r ON h.hotel_id = r.hotel_idWHERE r.fecha_reserva >= DATEADD(MONTH, -1, GETDATE()) AND r.fecha_reserva < GETDATE()GROUP BY h.hotel_id, h.nombre_hotelORDER BY total_reservas DESC;
Role playing
También puedes configurar el modelo de lenguaje para que adopte roles específicos definidos por nosotros, permitiéndole seguir reglas predeterminadas y comportarse como un chatbot orientado a tareas.
Este enfoque separa la definición del rol de la estructura del prompt, lo que facilita cambiar de rol sin tener que reescribir todo el prompt. Los componentes clave son:
role: especifica el personaje, experiencia o perfil que debe adoptar el modelo
tone: define el estilo de comunicación y el tono emocional de las respuestas
question: contiene la consulta del usuario que debe ser respondida
Al parametrizar estos elementos, puedes cambiar rápidamente el comportamiento del modelo modificando solo algunas variables, en lugar de reescribir todo el prompt. Este patrón es especialmente útil para construir agentes conversacionales que deben cumplir diferentes funciones o adaptarse a distintos contextos.
Por ejemplo, el siguiente código configura el modelo para actuar como un maestro de juego (game master). En este rol, el modelo responde preguntas sobre juegos manteniendo un tono atractivo e inmersivo, mejorando la experiencia del usuario. Puedes probar el bot haciendo preguntas relacionadas con juegos de rol de mesa o dirección de partidas. Intenta preguntas como:
“¿Quién eres?”
“¿Cuáles son las reglas básicas de Dungeons & Dragons?”
“¿Cómo creo un encuentro equilibrado para mis jugadores?”
“¿Puedes describir un bosque misterioso para mi aventura?”
“¿Qué tipo de puzle podría usar en mi mazmorra?”
“¿Cómo manejo a un jugador que interrumpe constantemente a los demás?”
La función está escrita dentro de un bucle while, lo que permite una interacción continua. Para salir del bucle y finalizar la conversación, escribe “quit”, “exit” o “bye” en el cuadro de entrada.
role ="Jugador de Dungeon & Dragons"tone ="atractivo e inmersivo"template ="""Eres un experto {role}. Tengo esta pregunta: {question}. Quiero que la conversacion sea {tone}.Answer:"""prompt = PromptTemplate.from_template(template)llm = get_llm(llm="dsk", params={"temperature": 0.5})roleplay_chain = ( prompt | llm | StrOutputParser())# 🔁 Loop interactivowhileTrue: query =input("Question: ")if query.lower() in ["quit", "exit", "bye"]:print("Adios forastero")break response = roleplay_chain.invoke({"role": role,"question": query,"tone": tone })print(query) show(response)
question: ¿quien eres?Un susurro de pergaminos antiguos y el tintineo de dados de marfil llenan el aire. Una figura envuelta en una capa color tinta se inclina sobre una mesa de roble, sus dedos esqueléticos acarician un mapa desgastado. Al levantar la mirada, sus ojos brillan como ascuas en una chimenea apagada.— ¿Quién soy?Suelta una risa grave, que retumba como un trueno lejano.— Soy el eco de mil tabernas donde se forjaron leyendas. La mano que susurra «sube la tirada» cuando el destino titubea. El guardián de los críticos naturales y las muertes trágicas por una trampa de osos mal colocada.Se reclina, y la sombra de su capa se alarga, revelando el borde de un grimorio que gotea tinta invisible.— He visto paladines caer por un pastel envenenado, magos olvidar su conjuro de «mano de mago» en el peor momento, y bardos seducir a dragones con una balada desafinada. Pero también he presenciado cómo un puñado de valientes convierte una misión de rescate de gallinas en la caída de un imperio.— Yo soy el Dungeon Master. El narrador de lo imposible. El que da forma al caos con un dado de veinte caras. Y tú, aventurero...Se inclina hacia adelante, y el aire huele a incienso y a batalla.— ¿Qué historia vienes a contarme hoy?question: Soy Fernand Mago del bosque negroSoy Fernand Mago del bosque negroUna neblina espesa se arremolina entre los árboles retorcidos del Bosque Negro. El crujido de una rama anuncia tu presencia, y una voz grave, como el roce de corteza contra corteza, resuena desde las sombras.—Ah, Fernand... el de los dedos manchados de savia y los ojos que reflejan la luz de las luciérnagas. Te he sentido llegar desde que cruzaste el arroyo de los susurros. Dime, ¿qué buscas en esta espesura? ¿Acaso los espíritus del bosque te han llamado, o es tu propia curiosidad la que te trae a mi claro? Habla con claridad, que el viento no repite las palabras titubeantes.He venido a tomar lo que me pertenece desde antes de que tu alma bajara a este mundoHe venido a tomar lo que me pertenece desde antes de que tu alma bajara a este mundoUna brisa helada se cuela entre las piedras del santuario olvidado. El polvo milenario baila alrededor de tus botas mientras la figura ante ti—una silueta envuelta en harapos que se mueven como si tuvieran voluntad propia—alza una mano descarnada. Sus dedos, largos como garras, señalan directamente tu pecho.Su voz no sale de su boca, sino que vibra directamente en tu cráneo, como un recuerdo que no te pertenece.—"No. No te reconozco, cosa de carne. Pero este lugar... estas paredes... me conocen a mí."La figura da un paso al frente. Donde sus pies tocan, las losas se agrietan en patrones que imitan runas antiguas. Del hueco de su capucha, dos puntos de luz ámbar te barren de arriba abajo.—"Dime, portador de latidos... ¿qué crees que es tuyo aquí? ¿El trono de huesos que yace bajo tus pies? ¿El silencio que guardan estas criptas? ¿O acaso..."Una pausa. El aire se vuelve denso, casi sólido.—"...lo que llevas dentro?"Su otra mano se abre, y de la palma brota una llama negra que no ilumina, sino que absorbe la luz de las antorchas cercanas.—"Si tu alma vino después que mi derecho, entonces tú eres el ladrón. Y yo..."La llama negra se extiende, formando una daga de obsidiana líquida.—"...he venido a cobrar."¿Qué haces?question: No lo sabes, pero tu existencia ha sido gracias a mi micericordia(Un escalofrío recorre tu espina dorsal. La voz del ser resuena en tu mente, distorsionando el aire a tu alrededor. El ambiente cambia: el tintineo de las armaduras y el murmullo de la taberna se desvanecen, reemplazados por un silencio absoluto. Frente a ti, la figura que creías un simple mercenario ahora parece más alta, más antigua. Sus ojos brillan con un fulgor violeta.)Tú: (Tragas saliva, la mano instintivamente yendo a la empuñadura de tu espada, aunque sabes que no servirá de nada.) ¿Qué... qué quieres decir con eso? Yo forjé mi propio destino. Sangré por cada nivel, por cada hechizo...La Entidad (con una sonrisa que no llega a sus ojos): ¿De verdad? ¿Recuerdas aquella noche en el Bosque Susurrante, cuando el cazador de recompensas te tenía en la punta de su ballesta? Falló. No por tu reflejo, sino porque yo desvié su mano un par de grados. ¿Y la maldición de la Reina Liche? Creíste que tu amuleto de plata te salvó. No, pequeño. Fui yo quien susurró la contraorden a su nigromante mientras dormía.(La entidad da un paso al frente. No pisas el suelo, sino que flotas sobre él. Sientes el peso de eones en su mirada.)Tú: (Con la voz quebrada, un nudo en el estómago.) ¿Por qué? ¿Qué clase de juego es este? ¿Eres un dios? ¿Un demonio?La Entidad: (Ríe, un sonido seco como huesos al chocar.) Soy algo más simple y más terrible. Soy el que escribe las líneas de tu personaje. El que tira los dados detrás de la pantalla. Y durante años, he tenido piedad de ti. Podría haber hecho que el dragón te incinerara con su aliento, que el puente colgante se rompiera justo cuando cruzabas, que el hechizo de deseo se torciera. Pero no lo hice. Te di oportunidades. Te di gloria.(Se inclina, su rostro a centímetros del tuyo. Puedes oler el azufre y el papel viejo.)La Entidad: Ahora, dime... ¿por qué debería seguir teniendo misericordia? ¿Qué harás, ahora que sabes que tu épica historia es solo un capricho que yo permito? ¿Seguirás adelante, rogando por mi favor? ¿O me desafiarás, sabiendo que con un chasquido de mis dedos, tu mundo... se desvanece en un "Game Over" sin resurrección?(El silencio se alarga. La taberna sigue congelada. Una gota de sudor cae de tu frente y se congela en el aire antes de tocar el suelo.)Tú: (Tu voz, al fin, surge, pero no es de sumisión. Es de acero frío.) Si todo lo que he hecho ha sido por tu permiso... entonces mi mayor acto de rebeldía será vivir de aquí en adelante como si no existieras. Mis dados, mi historia. Juega tu papel, "escritor". Pero recuerda: incluso los dioses, a veces, crean héroes que terminan rompiendo sus tableros.(La entidad levanta una ceja, una chispa de genuino interés en sus ojos violetas. La sonrisa se vuelve peligrosa, pero también... respetuosa.)La Entidad: Interesante. Muy interesante. Entonces, la partida continúa. Pero ya no seré un espectador silencioso. A partir de ahora, cada paso que des, lo darás sobre el filo de una navaja. Y yo... estaré observando. Disfruta tu "libre albedrío", campeón. Hasta que decida que tu historia merece un final más... poético.(La entidad chasquea los dedos. El bullicio de la taberna regresa de golpe. El mercenario frente a ti es solo un mercenario otra vez, que te ofrece una jarra de cerveza con una sonrisa despreocupada. Pero en el fondo de tu mente, una presencia fría y antigua te susurra:)"Siguiente turno."question: Me voy pero volvere. byeMe voy pero volvere. byeUna figura encapuchada se acerca a la mesa donde descansas en la taberna "El Caldero Humeante". Su rostro está oculto, pero su voz suena grave y resonante, como si hablara desde una cueva profunda.—Has pronunciado las palabras de los viajeros antiguos, aventurero. "Me voy, pero volveré". Esas mismas palabras susurró el mago errante antes de adentrarse en el Bosque de las Sombras Eternas, y nadie volvió a verlo... hasta que su espada apareció clavada en el trono del rey, tres lunas después.La figura se inclina, y por un instante ves un destello de unos ojos amarillos bajo la capucha.—El mundo de D&D no olvida a quienes parten con promesas. El dado de la fortuna ya rueda en tu ausencia. ¿Dejas tu historia en pausa? ¿O acaso tu partida es solo el preludio de una trampa que tenderás al destino?Saca una pipa de hueso y enciende una brasa azulada. El humo forma brevemente la silueta de un dragón antes de disiparse.—Ve, pues. Pero recuerda: en la taberna, tu jarra de hidromiel siempre estará caliente, y tu nombre, grabado en la mesa, te esperará. Que los dioses del azar guíen tus pasos... y que el crítico natural te sonría a tu regreso.Se levanta, hace una reverencia burlona, y se pierde entre las sombras del local. Solo queda el eco de su última frase:—Nos vemos en el próximo descanso largo, forastero.Adios forasteroAdios forastero
Bueno, ha sido flipante. Al final no hice las preguntas que estaban en el enunciado y ha resultado ser un diálogo con un personaje de D&G creando una historia.
Product review analyzer
Crear un analizador de reseñas de productos con un formato más cercano a un caso real que:
Detecte sentimiento
Extraiga características
Genere un resumen
reviews = ["Compré este smartwatch hace un mes y estoy encantado. La batería dura varios días y las funciones deportivas son muy precisas. La app podría mejorar.","La aspiradora no cumple lo que promete. Tiene poca potencia y el depósito es muy pequeño. No la recomendaría.","El portátil funciona bien para tareas básicas, aunque la pantalla no es muy brillante. En general, correcto por el precio."]
template ="""Analiza la siguiente reseña de producto:Reseña: {review}Devuelve:- Sentimiento (positivo, negativo o neutral)- Características mencionadas (lista)- Resumen en una sola fraseFormato de salida:Sentimiento:Características:Resumen:"""prompt = PromptTemplate.from_template(template)chain = prompt | llm | StrOutputParser()for review in reviews: result = chain.invoke({"review": review})print("RESEÑA:")print(review)print("nANÁLISIS:")print(result)print("n"+"-"*50+"n")
RESEÑA:Compré este smartwatch hace un mes y estoy encantado. La batería dura varios días y las funciones deportivas son muy precisas. La app podría mejorar.ANÁLISIS:Sentimiento: Positivo Características: batería duradera, funciones deportivas precisas, app mejorable Resumen: El usuario está muy satisfecho con el smartwatch, destacando su batería y precisión deportiva, aunque señala que la aplicación podría mejorar.--------------------------------------------------RESEÑA:La aspiradora no cumple lo que promete. Tiene poca potencia y el depósito es muy pequeño. No la recomendaría.ANÁLISIS:Sentimiento: Negativo Características: Potencia, depósito Resumen: La aspiradora tiene poca potencia y un depósito pequeño, por lo que no cumple lo prometido y no es recomendable.--------------------------------------------------RESEÑA:El portátil funciona bien para tareas básicas, aunque la pantalla no es muy brillante. En general, correcto por el precio.ANÁLISIS:Sentimiento: Positivo Características: Rendimiento para tareas básicas, brillo de pantalla, relación calidad-precio Resumen: El portátil cumple para tareas básicas y es aceptable por su precio, aunque la pantalla podría ser más brillante.--------------------------------------------------
Autor:
Fernando Rioseco
Basado en el Curso: IBM RAG and Agentic AI Professional Certificate:
Para construir aplicaciones con IA, utilizando LangChain necesitas entender tres piezas clave:
Cadenas (Chains)
Memoria (Memory)
Agentes (Agents)
Este artículo explica cómo funcionan, cómo se conectan aplicándolo en nuestro entorno RAG híbrido.
Cadenas en LangChain
En LangChain, una cadena es simplemente una secuencia de llamadas donde la salida de una se convierte en la entrada del siguiente para crear un flujo de información continuo en un pipeline.
2. Ejemplo completo: sistema de recetas por ubicación
Vamos a recrear el ejemplo del video paso a paso.
🎯 Objetivo
Dado un país, queremos:
Obtener un plato típico
Generar la receta
Calcular el tiempo de cocción
🔹 Cadena 1: obtener el plato
Entrada:
China
Prompt:
Dime un plato famoso de {location}
Salida esperada:
Pato de Pekín
🔹 Cadena 2: generar la receta
Usa la salida anterior como entrada.
Entrada:
Pato de Pekín
Prompt:
Dame una receta sencilla para {meal}
Salida:
Receta paso a paso del plato
🔹 Cadena 3: estimar tiempo de cocción
Entrada:
Receta generada
Prompt:
¿Cuánto tiempo se tarda en cocinar esta receta? {recipe}
Salida:
Tiempo estimado (ej: 90 minutos)
🔗 Resultado final (cadena completa)
China → Pato de Pekín → Receta → 90 minutos
Esto es una cadena secuencial.
🧠 Qué está pasando realmente
Cada paso reduce incertidumbre
El modelo trabaja con contexto más concreto
El resultado final es mucho más preciso
3. Cómo se construye esto en código (simplificado)
Después de ver los componentes de LangChain. Ahora toca entender cómo se conectan realmente para construir aplicaciones. Aquí entra el LangChain Expression Language (LCEL): el enfoque moderno y recomendado para diseñar flujos de trabajo con LLMs.
Construir una cadena con LCEL
LCEL es un patrón de construcción que permite conectar componentes mediante el operador de tubería (|). Es una forma declarativa de construir pipelines donde los datos fluyen de un componente a otro de forma explícita y legible.
LCEL aporta:
Mayor componibilidad
Flujo de datos más claro
Más flexibilidad
Código más mantenible
Un flujo típico sigue estos pasos:
Definir una plantilla con variables ({})
Crear una instancia de prompt
Conectar componentes con |
Ejecutar la cadena con inputs
El núcleo: el operador de tubería (|)
El operador | Conecta componentes en secuencia.
prompt | modelo | parser
Se construye el prompt
Se envía al modelo
Se procesa la salida
Runnables: las piezas básicas
En LCEL todo se basa en runnables. Estas son interfaces que permiten que cualquier componente sea conectable dentro de un pipeline. Ejemplos:
Modelos (LLM)
Funciones
Parsers
Recuperadores
Tipos de composición
Ejecución secuencial (RunnableSequence)
Cada paso depende del anterior:
Entrada → Paso 1 → Paso 2 → Salida
En LCEL:
paso1 | paso2
Ejecución paralela (RunnableParallel)
Un mismo input se procesa en múltiples ramas al mismo tiempo.
Antes de trabajar con pipelines avanzados o LCEL, necesitas dominar los bloques fundamentales de LangChain. Aquí entiendes qué componentes existen y cómo encajan entre sí.
Componentes principales de LangChain
LangChain no es una sola cosa, es un ecosistema de componentes. Los principales son:
Documents
Chains
Agents
Language model (LLMs)
Chat Model
Embedding Models
Chat Message
Prompt Templates
Output Parsers
Modelos de Lenguaje
Son la base de los LLMs, reciben y generan texto. Sirven para generar contenido, resumir documentos y completar tareas. LangChain utiliza OpenAI, Google, Meta e IBM como lenguajes primarios.
Los modelos se pueden personalizar ajustando parámetros que modifican su forma de responder, algunos son:
temperature: Aleatoriedad del modelo, más temperura = más creatividad.
max_tokens: Longitud máxima de la respuesta en tokens
top_p: Diversidad de palabras considerando la probabilidad acumulada.
top_k: Diversidad de palabras considerando la frecuencia
frequency_penalty: Penalización de frecuencia
presence_penalty: Penalización de presencia
Modelos de Chat
Son una evolución de los LLM tradicionales. Convierten texto plano en conversaciones estructuradas, entienden contexto y mantienen coherencia entre mensajes.
Embedding Models
Estos modelos no generan texto. Su única función es transformar contenido en vectores (listas de números) que representan el significado semántico.
Se utilizan exclusivamente para RAG (Retrieval Augmented Generation). Sirven para buscar información en bases de datos vectoriales comparando qué tan “cerca” está la pregunta del usuario de tus documentos.
Característica
Chat Model
Embedding Model
Input
Lista de Mensajes
Texto plano
Output
Un mensaje de texto
Un vector (lista de floats)
Función
Razonar, generar, decidir
Comparar similitudes
Uso principal
El “cerebro” del agente
La “búsqueda” de memoria
Cargar un modelo:
from langchain_openai import ChatOpenAI# Cargar variables de entornoload_dotenv()# Crear modelo directamentellm = ChatOpenAI(model="deepseek-chat",openai_api_key=os.getenv("DEEPSEEK_API_KEY"),openai_api_base="https://api.deepseek.com",# Parámetros de generacióntemperature=0.3,max_tokens=100,top_p=0.9,frequency_penalty=0.2,presence_penalty=0.1)
En la variable llm se carga el modelo que después se llama con el método .invoke()
Un modelo de chat no trabaja con texto plano, sino con mensajes estructurados. Cada tipo de mensaje tiene un rol (quién habla) y un contenido (qué dice).
Tipos de mensajes
"system"→ define comportamiento y contexto del modelo
"human"→ entrada del usuario
"ai"→ respuesta del modelo
“tool”→ interacción con sistemas externos
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_messages([ ("system", "Eres experto en análisis de datos."),# Usuario ("human", "{question}"),# Respuesta previa del modelo (contexto conversacional) ("ai", "La varianza mide la dispersión de los datos."),# Resultado de una herramienta (tool calling) ("tool", '{"mean": 10, "std": 2}', {"tool_name": "stats_calculator"})])
No todos se usan siempre:
En el 90% de los casos → solo "system" + "human"
"ai" → cuando hay memoria conversacional
"tool" → solo en flujos con herramientas (agents / tool calling)
Plantillas de prompts
Las plantillas convierten entradas en instrucciones claras:
Estandarizan prompts
Permiten reutilización
Introducen variables dinámicas
prompt = ChatPromptTemplate.from_messages([ ("system", "Eres un experto en {domain}. Responde en tono {tone}."), ("human", "Pregunta: {question}\nContexto: {context}")])chain = prompt | llmresponse = chain.invoke({"domain": "machine learning","tone": "conciso","question": "¿Qué es overfitting?","context": "Modelo entrenado con pocos datos"})print(response.content)
Tipos principales
Plantillas de cadena (string): para texto simple.
Plantillas de chat: para estructuras conversacionales.
Mensajes del sistema
Mensajes humanos
Mensajes de IA
Plantillas de pocos ejemplos (few-shot): incluyen ejemplos para guiar al modelo.
Output Parsers
Los Output Parsers en LangChain son el mecanismo para convertir la salida del LLM (texto libre) en estructuras controladas y utilizables (JSON, objetos tipados, listas, etc.).
Son críticos cuando necesitas fiabilidad, integración con código y postprocesado determinista. Se guardan en una variable que se añade al final de la cadena.
parser = JsonOutputParser()
Chains (Cadenas)
En LangChain, las Chains son la forma de encadenar los componentes (prompts, modelos, parsers, funciones) para construir un flujo completo desde entrada → transformación → salida. En el enfoque moderno (LCEL), una chain no es una clase rígida, sino una composición declarativa de “runnables”.
prompt = ChatPromptTemplate.from_messages([ ("system", "Responde como experto en estadística."), ("human", "{question}")])llm = ChatOpenAI(model="gpt-4o-mini")parser = StrOutputParser()chain = prompt | llm | parserresponse = chain.invoke({"question": "¿Qué es la media?"})print(response)
Documents
En LangChain, un Document es la unidad estándar de datos que encapsula contenido (page_content) y metadatos (metadata), y actúa como formato común para que todos los módulos sean interoperables.
Se crea al ingerir información externa.
Se fragmenta para optimizar el procesamiento.
Mantiene siempre su metadata para permitir filtrado, ranking y trazabilidad.
Se transforma en vectores sin perder contexto.
Finalmente se recupera para inyectarse en prompts dentro de arquitecturas RAG.
Agentes
En LangChain, los Agentes (Agents) son el componente que permite a un LLM tomar decisiones iterativas y usar herramientas para resolver tareas complejas. A diferencia de una chain (pipeline fija), un agente decide dinámicamente qué hacer en cada paso.
Con LangChain pasamos de usar modelos de lenguaje a construir aplicaciones completas con ellos. Es un framework de código abierto en Python diseñado para facilitar el desarrollo de aplicaciones basadas en modelos de lenguaje (LLM). Proporciona componentes e interfaces para integrar modelos de lenguaje dentro de sistemas reales.
Permite:
Localizar información relevante en grandes volúmenes de texto
Responder preguntas complejas combinando datos y generación
Automatizar procesos que implican múltiples pasos
LangChain funciona encadenando operaciones como:
Recuperar información
Extraer datos relevantes
Procesar el contenido
Generar una respuesta
Este flujo convierte un modelo de lenguaje en un sistema completo.
Beneficios principales de LangChain
Modularidad: LangChain está diseñado como un sistema de piezas que reduce drásticamente el tiempo de desarrollo. Puedes construir por bloques, reutilizar componentes y modificar partes sin romper el conjunto
Extensibilidad: Añade nuevas funcionalidades fácilmente integrándose con APIS y sistemas externos sin rehacer toda la arquitectura.
Descomposición de problemas: LangChain replica un patrón humano: divide tareas complejas en pasos más pequeños. Esto mejorando la precisión de las respuestas, el control del proceso y la interpretabilidad del sistema.
Integración con bases de datos vectoriales: LangChain se integra con bases de datos vectoriales para realizar búsquedas semánticas, recuperar eficientemente la información con rápido acceso a grandes volúmenes de datos.
Esto permite construir sistemas como:
Chat con documentos
Asistentes inteligentes
Sistemas de conocimiento empresarial
Cómo funciona un sistema con LangChain
Un flujo típico sería:
Usuario hace una pregunta
El sistema busca información relevante
Procesa los datos
Genera un prompt optimizado
El modelo responde
Este enfoque combina:
Recuperación de información
Procesamiento
Generación de lenguaje
Casos de uso reales
Resumen de contenido: Analizar documentos largos, extraer lo importante y simplificar contenido complejo
Extracción de datos: Convierte texto en información estructurada: estadísticas clave, métricas y datos accionables
Sistemas de preguntas y respuestas: responden sobre bases de conocimiento, mantienen contexto conversacional y refinan respuestas dinámicamente
Generación automatizada de contenido: redacción de emails, generación de ideas y documentación técnica
Trabajar con otros tipos de datos: Aunque LangChain está centrado en texto, también puede trabajar con audio, imágenes y vídeo
Embeddings y búsqueda semántica
LangChain utiliza embeddings para representar información como vectores y comparar significado en lugar de palabras exactas. Esto permite encontrar información relevante aunque esté expresada de forma diferente para mejorar la calidad de las respuestas
LangChain Expression Language (LCEL)
LCEL es el enfoque moderno dentro de LangChain para construir pipelines de IA. Es un patrón que permite conectar componentes mediante el operador de tubería (|) para crear flujos de datos claros y legibles. Lo que permite estructurar esos sistemas de forma limpia, componible y escalable. LCEL aporta:
Mayor claridad en el flujo de datos
Mejor componibilidad
Más flexibilidad
Código más limpio
LCEL funciona como una tubería de datos. Cada componente recibe una entrada, la transforma y pasa el resultado al siguiente
prompt | modelo | parser
Construir una cadena con LCEL
Un patrón típico incluye:
Definir una plantilla de prompt
Crear el prompt con variables
Conectar componentes con |
Ejecutar la cadena con inputs
Ventajas de LCEL
Deja de pensar en “hacer prompts”. Empieza a pensar en: diseñar pipelines de transformación de información
Legibilidad: El flujo es explícito: input → transformación → modelo → salida
Reutilización: Puedes reusar bloques, crear patrones estándar y escalar fácilmente
Flexibilidad: Puedes combinar: cadenas en secuencial, paralelo y transformaciones personalizadas
Automatización avanzada: LCEL permite ejecución paralela, soporte asíncrono, streaming de respuestas y trazabilidad automática
Cuando trabajas con modelos de lenguaje como GPT-3.5, no estás “programando” en el sentido tradicional. Estás guiando el comportamiento del modelo a través del lenguaje. Y aquí es donde entran dos conceptos fundamentales:
Aprendizaje en contexto (In-Context Learning)
Ingeniería de prompts (Prompt Engineering)
¿Qué es el Aprendizaje en Contexto?
El aprendizaje en contexto es una técnica mediante la cual un modelo aprende a realizar una tarea sin necesidad de ser reentrenado, simplemente a partir de ejemplos incluidos dentro del propio prompt, lo que haces es:
Incluir ejemplos dentro del prompt
Mostrarle al modelo qué tipo de salida esperas
Dejar que el modelo generalice ese patrón en tiempo de inferencia
Ejemplo sencillo
Clasifica el sentimiento:Ejemplo 1:Texto: Me encanta este productoSentimiento: PositivoEjemplo 2:Texto: No funciona como esperabaSentimiento: NegativoAhora:Texto: Es aceptable, pero mejorableSentimiento:
El modelo no ha sido entrenado específicamente para esto en ese momento. Está aprendiendo del contexto que le das.
Ventajas y Limitaciones
Ventajas clave
No requiere entrenamiento adicional
Reduce costes computacionales y tiempo
Permite adaptar modelos rápidamente a nuevas tareas
Mejora el rendimiento sin tocar el modelo base
Limitaciones importantes
Capacidad limitada del contexto (no puedes meter infinitos ejemplos)
Tareas complejas pueden requerir:
Fine-tuning
Ajustes con gradiente (machine learning tradicional)
Componentes del Prompt
Un prompt bien diseñado tiene cuatro elementos clave:
Instrucciones: Indican claramente qué debe hacer el modelo.
Contexto: Proporciona información adicional para interpretar la tarea.
Datos de entrada: Es la información concreta que el modelo debe procesar.
Indicador de salida: Marca dónde debe responder el modelo.
Ejemplo:
Instrucción:Clasifica la siguiente reseña...Contexto:Producto recién lanzado...Entrada:"El producto llegó tarde pero la calidad superó mis expectativas."Salida:Sentimiento:
Ingeniería de prompts
La ingeniería de prompts es la disciplina que se encarga de crear, refinar y estructurar prompts para obtener respuestas más precisas, relevantes y útiles de un modelo de lenguaje:
Formular correctamente el problema
Reducir ambigüedad
Guiar el razonamiento del modelo
Controlar el tipo de salida
Una buena ingeniería de prompts:
Aumenta la precisión
Mejora la relevancia de las respuestas
Reduce errores y malentendidos
Permite prescindir de fine-tuning en muchos casos
Esto es especialmente útil en aplicaciones como:
Atención al cliente automatizada
Análisis de datos
Generación de contenido
Investigación
Métodos Avanzados de Ingeniería de Prompts
Optimizar un prompt para obtener resultados consistentes, precisos y escalables. Estos métodos marcan la diferencia entre un uso básico de la IA y un uso profesional.
Zero-Shot Prompting
El zero-shot prompting consiste en pedirle al modelo que realice una tarea sin proporcionarle ejemplos previos. El modelo utiliza únicamente:
Su conocimiento previo
La instrucción que le das
Ejemplo
Clasifica como verdadero o falso:La Torre Eiffel está en Berlín.
Cuándo usarlo
Tareas simples
Preguntas directas
Cuando quieres rapidez y no necesitas precisión extrema
Limitación
Menor control sobre la salida
Mayor probabilidad de error en tareas complejas
One-Shot Prompting
El one-shot prompting añade un único ejemplo para enseñar al modelo el patrón esperado. Introduce una plantilla mental y reduce ambigüedad
Ejemplo
Traduce del inglés al francés:Ejemplo:Hello → BonjourAhora:Where is the nearest supermarket?
Cuándo usarlo
Cuando el formato importa
Cuando quieres consistencia básica
Para tareas repetitivas
Few-Shot Prompting
El few-shot prompting amplía el concepto anterior: le das al modelo varios ejemplos antes de la tarea real.
Mejora la generalización
Aumenta la precisión
Reduce errores de interpretación
Ejemplo
Clasifica la emoción:Ejemplo 1:Texto: Estoy muy feliz hoyEmoción: AlegríaEjemplo 2:Texto: Esto me da miedoEmoción: MiedoEjemplo 3:Texto: Estoy frustrado con este resultadoEmoción: FrustraciónAhora:Texto: Esa película fue tan aterradora que tuve que taparme los ojosEmoción:
Cuándo usarlo
Clasificación
Análisis de texto
Tareas donde el contexto es clave
Chain of Thought (CoT)
El Chain of Thought Prompting obliga al modelo a explicar su razonamiento paso a paso. Los LLM no “piensan” como humanos, pero simulan razonamiento mejor cuando lo estructuran en pasos.
Ejemplo
Una tienda tenía 22 manzanas.Vendió 15.Luego recibió 8 más.¿Cuántas tiene ahora? Explica paso a paso.
Ventajas
Mayor precisión en problemas complejos
Transparencia en la respuesta
Menos errores lógicos
Cuándo usarlo
Matemáticas
Lógica
Análisis paso a paso
Decisiones complejas
Autoconsistencia
La autoconsistencia es una técnica para aumentar la fiabilidad:
Generas varias respuestas independientes
Comparas resultados
Te quedas con la más consistente
Ejemplo
Problema:
Cuando yo tenía 6 años, mi hermana tenía la mitad. Ahora tengo 70. ¿Qué edad tiene ella?
Se le pide al modelo:
Resolverlo varias veces
Explicar cada razonamiento
Luego:
Se comparan las respuestas
Se valida la coherencia
Qué aporta:
Reduce errores
Mejora confianza en el resultado
Detecta inconsistencias
Herramientas clave en ingeniería de prompts
Para trabajar de forma profesional, no basta con escribir prompts en un chat. Necesitas herramientas.