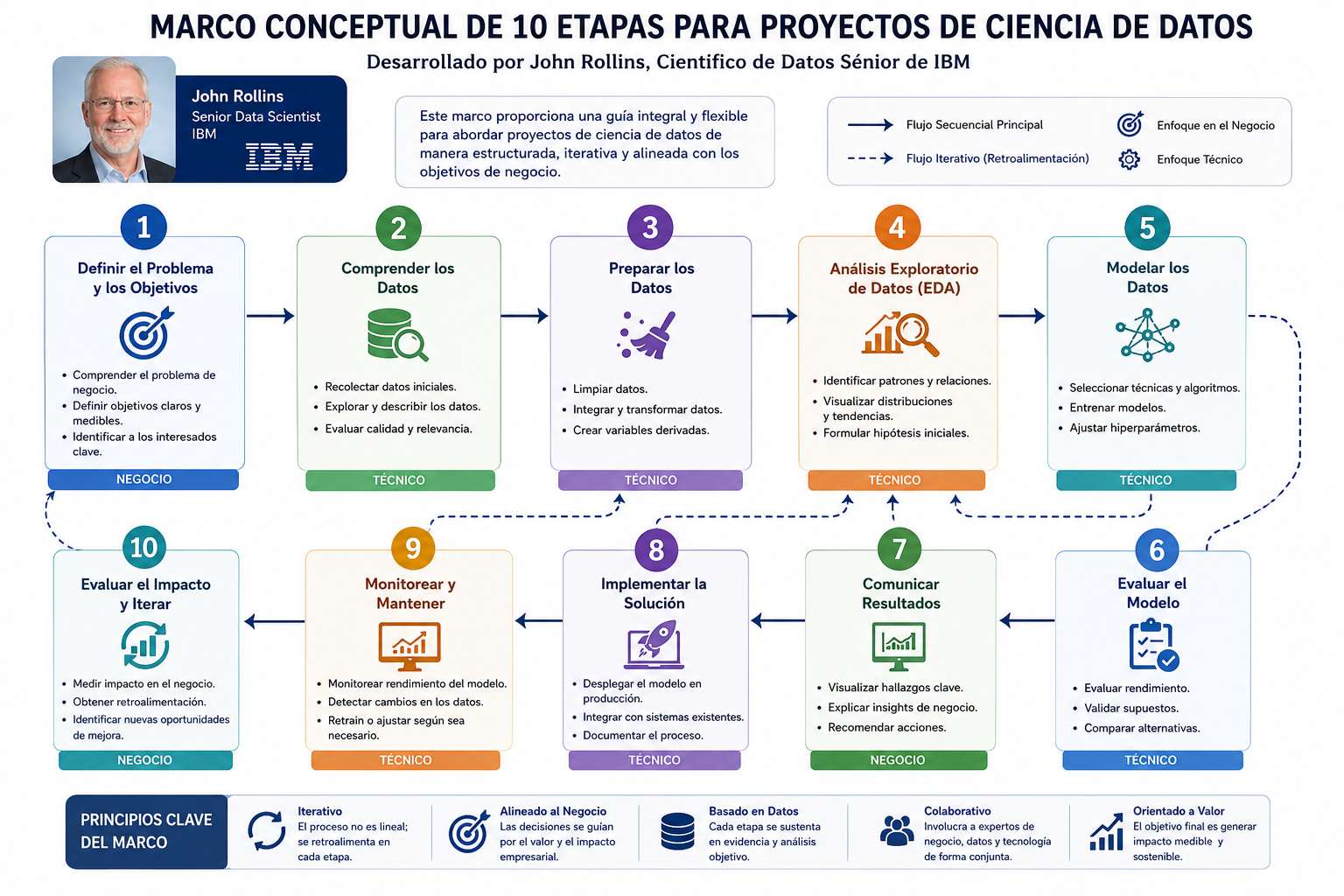
Hasta este punto del curso, todos tus programas han sido “sordos”: ejecutaban operaciones con datos fijos (literales) que tú escribías directamente en el código, pero no tenían la capacidad de reaccionar a lo que un usuario real quisiera decirles. En el desarrollo real, prácticamente cualquier software necesita leer y procesar datos del exterior.
Para solucionar esto, Python nos presenta una función completamente nueva que actúa como el reflejo exacto en un espejo de nuestra vieja conocida print():
print() toma datos desde el interior del programa y los envía hacia la consola. No genera ningún resultado matemático almacenable (devuelve None).
input() hace el viaje inverso: detiene el programa y extrae datos desde la consola para introducirlos al código en ejecución, devolviendo un resultado sumamente útil.
La función input() es capaz de capturar lo que el usuario teclee y entregárselo directamente a tu programa, logrando que el código sea verdaderamente interactivo. Analicemos detenidamente el flujo de este programa básico:
print("Dime lo que sea...")anything =input()print("Hmm...", anything, "... ¿En serio?")
Al ejecutar este bloque en tu entorno de desarrollo, el intérprete realizará las siguientes acciones secuenciales:
print("Dime lo que sea..."): Lanza un mensaje en la pantalla para indicarle al usuario que el sistema está esperando una interacción (esto se conoce técnicamente como un prompt).
anything = input(): Python invoca a la función input(). En este momento, el programa se congela por completo. La consola cambia a “modo entrada”, verás un cursor parpadeando y el sistema se quedará esperando a que el usuario presione teclas y finalice la instrucción pulsando la tecla Enter.
El almacenamiento obligatorio: Cuando el usuario presiona Enter, todo el texto digitado viaja hacia el programa como resultado de la función. Es absolutamente crucial asignar este resultado a una variable (como hicimos con anything =). Si olvidas este paso, los datos introducidos por el usuario caerán al vacío y se perderán para siempre en la memoria.
print("Hmm...", anything, ...): El script se reanuda, toma el contenido guardado en la variable y lo proyecta combinado con otros textos.
La función input() con argumentos y su tipo de dato nativo
La función input() es más versátil de lo que parece a simple vista. Tiene la capacidad de interactuar con el usuario de forma directa, eliminando la necesidad de usar una función print() previa para lanzar el mensaje de aviso (prompt).
anything =input("Dime lo que sea...")print("Hmm...", anything, "... ¿En serio?")
¿Cómo funciona esta variante?
Invocamos a la función input() pasándole un único argumento: una cadena de texto con nuestro mensaje.
Python muestra ese mensaje en la consola de inmediato, antes de abrir el modo de espera.
El cursor se queda parpadeando justo al lado del texto, esperando las pulsaciones del teclado y el Enter del usuario.
Esta técnica simplifica notablemente la estructura de tu script, reduciendo líneas de código y haciéndolo mucho más limpio y legible.
El Experimento del Colapso
Debido a esto, tienes estrictamente prohibido usar el resultado directo de un input() para realizar operaciones aritméticas. Mira lo que sucede en este fragmento propuesto por el curso:
anything =input("Introduce un número: ")something = anything **2.0print(anything, "elevado a la potencia de 2 es", something)
Si ejecutas este código e introduces el número 4, el programa no calculará. En la segunda línea, el script se interrumpirá bruscamente y arrojará un error fatal de tipo en la consola:
TypeError: unsupported operand type(s) for **: 'str' and 'float'
Python te está diciendo con toda claridad: “No puedo elevar una palabra (un str) a una potencia matemática”. Para el intérprete, estás intentando multiplicar letras por números.
El Resultado de input():
Debemos establecer una regla absoluta y sin excepciones que el Python Institute evalúa bajo máxima presión en sus exámenes:
Regla de Oro (PCEP): El resultado de la función input() es SIEMPRE una cadena de texto (str).
No importa si el usuario teclea un entero como 5, un flotante como 3.14, o letras; Python empaquetará absolutamente todos esos caracteres dentro de un tipo str (es decir, el sistema leerá "5" o "3.14" con comillas invisibles).
Operaciones Prohibidas con input() y la Anatomía del Error
Si ejecutamos el código anterior e introducimos, por ejemplo, el número 5, la consola no nos da un resultado; nos arroja un reporte de colapso técnico llamado Traceback:
¿Cómo se lee este reporte de error? (Enfoque PCEP)
Cuando tu programa falle en los laboratorios o en los exámenes de simulación, no te asustes. Léelo de abajo hacia arriba:
La última línea (TypeError): Te da el diagnóstico de la enfermedad. Te dice que estás usando tipos de datos incompatibles (str y float) para el operador de potencia ().
La línea del medio (something = ...): Te muestra el fragmento exacto de código que causó el colapso.
La primera línea (File "main.py", line 4): Te indica en qué archivo y en qué número de línea exacta ocurrió el accidente.
La Lógica de Python
Este comportamiento es completamente lógico. Piensa en esto: ¿cuál sería el resultado matemático de elevar la frase “Ser o no ser” a la potencia de 2? No tiene ningún sentido. No podemos calcularlo nosotros, y Python tampoco puede.
Moldeo de Tipos (Type Casting): La Solución Definitiva
Python ofrece dos funciones extremadamente simples y directas para tomar un dato de un tipo y forzarlo a convertirse en otro. Estas funciones son int() y float().
Sus nombres, al igual que los de las variables bien estructuradas, son autodocumentados:
La función int(): Toma un único argumento (por ejemplo, una cadena de texto: int(cadena)) e intenta transformar esos caracteres en un número entero. Si lo que está dentro de la cadena no parece un número entero (por ejemplo, int("hola") o int("3.14")), el programa fallará con un error.
La función float(): Hace exactamente lo mismo, pero intenta convertir el argumento en un número flotante (con punto decimal).
Esto es tan simple como efectivo. Al proceso de transformar un tipo de dato en otro de forma explícita se le conoce en programación como moldeo de tipos o type casting.
El Flujo de Datos Sincronizado
La ventaja de estas funciones es que no necesitas crear variables intermedias para hacer la conversión. Puedes anidar las funciones, pasando el resultado de un input()directamente como argumento de tu función de moldeo.
anything =float(input("Introduce un número: "))something = anything **2.0print(anything, "elevado a la potencia de 2 es", something)
¿Cómo viaja la información en la primera línea?
Para entender cómo fluyen los datos desde el teclado hasta la pantalla, imagina que Python resuelve esta línea desde el núcleo hacia afuera, como las capas de una cebolla:
input(...) entra en acción: Muestra el prompt en la pantalla y congela el script. El usuario teclea, por ejemplo, el número 5 y presiona Enter.
Nace el texto: La función input() extrae ese dato de la consola y lo convierte en el literal de cadena "5" (con comillas).
El relevo de float(): De inmediato, esa cadena "5" es succionada por la función exterior float(). Esta función toma las letras, borra las comillas invisibles, le añade el formato decimal y lo transforma en el número real 5.0.
La caja de almacenamiento: El número flotante 5.0 se deposita finalmente dentro de la variable anything.
La matemática despierta: En la segunda línea, anything 2.0 se ejecuta sin problemas porque ahora Python está multiplicando un float por otro float ($5.0^2$).
Si corres este código en tu entorno e introduces un 0, un número negativo como -3 o un número gigante, el programa calculará la potencia perfectamente y la consola proyectará el resultado sin colapsar.
El Trío Dinámico en Acción: Pitágoras Interactivo
Tener en tu equipo de desarrollo la combinación de input() – int() – float() te abre un abono infinito de nuevas posibilidades. A partir de ahora, puedes escribir programas completos que acepten datos numéricos del exterior, los procesen matemáticamente y proyecten el resultado final en la pantalla.
Es cierto que, por ahora, estos programas son lineales y algo primitivos; no pueden tomar decisiones de forma autónoma ni reaccionar de manera diferente ante situaciones imprevistas (como cuando un usuario introduce datos incoherentes). Sin embargo, eso lo solucionaremos muy pronto en los siguientes módulos.
Evolución del Programa: Leyendo Catetos desde la Consola
Vamos a reescribir el script que calcula la hipotenusa, pero esta vez, en lugar de usar valores fijos en el código (3.0 y 4.0), permitiremos que el usuario introduzca las longitudes de los catetos directamente por el teclado.
leg_a =float(input("Ingresa la longitud del primer cateto: "))leg_b =float(input("Ingresa la longitud del segundo cateto: "))hypo = (leg_a**2+ leg_b**2) **.5print("La longitud de la hipotenusa es", hypo)
🔍 Análisis de Ejecución:
El programa solicita dos veces consecutivas las medidas en la consola.
Convierte de inmediato las entradas de texto en números flotantes (float) mediante el moldeo de tipos.
Evalúa la fórmula matemática y almacena el resultado en la variable intermedia hypo.
⚠️ La debilidad del programa: Si ejecutas este código e introduces valores negativos (como -3 o -4), notarás que el programa calcula el resultado igualmente sin quejarse (5.0). Esto pasa porque cualquier número negativo elevado al cuadrado se vuelve positivo. Python no entiende de geometría del mundo real, solo obedece la aritmética. Ignoraremos esta flaqueza por ahora; aprenderemos a controlarla cuando veamos condicionales.
Optimización de Código: Eliminando Variables Redundantes
En el bloque de código del Sandbox, la variable hypo se utiliza con un único propósito: guardar el valor calculado para poder pasárselo a la función print() en la línea inmediatamente posterior.
Dado que la función print() tiene la capacidad de aceptar expresiones matemáticas complejas directamente como argumentos, podemos deshacernos de esa variable intermedia. Esto limpia el script y reduce el uso innecesario de etiquetas en la memoria de la computadora. El código optimizado y ultra-compacto queda de esta manera:
leg_a =float(input("Ingresa la longitud del primer cateto: "))leg_b =float(input("Ingresa la longitud del segundo cateto: "))# Pasamos la fórmula matemática directamente como argumento dentro de print()print("La longitud de la hipotenusa es", (leg_a**2+ leg_b**2) **.5)
¿Qué ganamos con esto?
El código es más corto y directo.
Evitamos crear un espacio en memoria (hypo) que solo íbamos a usar una vez.
Cuando escribes código, tarde o temprano sentirás la necesidad de incluir algunas palabras dirigidas no a Python, sino a los humanos. Ya sea para explicarle a otro programador cómo funciona un truco complejo en el script, detallar el propósito de una variable, o dejar registro de quién es el autor y cuándo se escribió el programa.
Una anotación insertada en el código fuente que el intérprete ignora por completo en tiempo de ejecución se conoce formalmente como comentario.
¿Cómo se escribe un comentario en Python?
Para evitar que Python intente interpretar tus notas humanas como órdenes o comandos, debes usar el símbolo # (almohadilla, hash o gato).
Cada vez que Python se topa con un signo # en el programa, todo lo que esté escrito a la derecha de ese símbolo se vuelve completamente invisible y transparente para él. Desde el punto de vista técnico del intérprete, un comentario equivale simplemente a un espacio en blanco, sin importar lo largo que sea.
Comentarios de una o varias líneas
Un comentario en Python se extiende estrictamente desde el signo # hasta el final de la línea actual. Si necesitas redactar un comentario que abarque varios renglones, debes colocar un signo # al inicio de cada uno de ellos.
# Este programa calcula la hipotenusa c.# a y b son las longitudes de los catetos.a =3.0b =4.0c = (a **2+ b **2) **0.5# Usamos ** en lugar de una función de raíz raíz.print("c =", c)
Como ves en el ejemplo, existen dos formas de colocar comentarios:
Bloque independiente: Ocupando líneas completas al inicio para dar contexto.
Línea interna (inline comment): Colocado a la derecha de una instrucción de código (c = ... # Usamos ). Python ejecuta la matemática de la izquierda e ignora la nota de la derecha.
El Código Autodocumentado: La Mejor Práctica
Los desarrolladores profesionales y responsables acostumbran a describir los fragmentos importantes de sus sistemas. Sin embargo, la comunidad de Python defiende una regla de oro: la mejor manera de comentar una variable es asignándole un nombre que no deje lugar a dudas.
Si creas una variable diseñada para almacenar el área de un terreno, el nombre area_terreno es infinitamente superior a ponerle caja_1 o tia_juana. Un nombre bien elegido se considera autodocumentado (self-commenting), lo que reduce drásticamente la necesidad de llenar tu archivo de textos explicativos redundantes.
Comentarios como Herramienta de Depuración (Testing)
Los comentarios tienen otra utilidad estratégica vital: te permiten “desactivar” temporalmente líneas de código que no necesitas en un momento dado o que sospechas que están provocando un fallo.
# Este es un programa de prueba.x =1y =2# y = y + xprint(x + y)
Truco Pro de Productividad (Atajo de Teclado)
Escribir el signo # línea por línea en bloques largos de código puede ser tedioso. Los editores de código modernos y los entornos de desarrollo (IDEs) incluyen un atajo universal sumamente útil:
Windows / Linux: Selecciona las líneas que deseas modificar y presiona CTRL + /
Mac OS: Selecciona las líneas y presiona CMD + /
Este comando funciona como un interruptor (toggle): si las líneas no tienen comentario, les añade el # automáticamente; si ya están comentadas, les quita el signo de inmediato.
Es evidente que Python te permite codificar literales con valores numéricos y de texto, y ya has aprendido a realizar operaciones aritméticas con ellos. Sin embargo, en cualquier desarrollo real surge una pregunta inevitable: ¿Cómo guardamos los resultados de esas operaciones para usarlos en cálculos posteriores?
Si no tuviéramos una forma de almacenar esos resultados intermedios, tendríamos que escribir expresiones infinitas y redundantes. Para resolver esto, Python nos ofrece “cajas” o contenedores especiales llamados variables. El nombre mismo lo dice todo: el contenido de estos contenedores puede variar en casi cualquier momento del programa.
Toda variable en Python consta obligatoriamente de dos elementos esenciales:
Un nombre: El identificador único que usas para llamar a la caja.
Un valor: El contenido o dato que está guardado dentro de la caja.
Las variables no aparecen de la nada de forma automática. Como desarrollador, tú debes decidir cuántas variables necesitas y qué nombres estratégicos les vas a asignar.
Reglas Estrictas para Nombrar Variables
Para que el intérprete de Python acepte el nombre de una variable sin arrojar un SyntaxError, debes seguir estas cinco reglas obligatorias:
1. Caracteres permitidos
El nombre solo puede estar compuesto por letras mayúsculas o minúsculas (de la A a la Z), dígitos (del 0 al 9) y el carácter de guion bajo o underscore (_). No se permiten espacios, eñes, acentos ni símbolos especiales ($, @, -, etc.).
2. El primer carácter es clave
El nombre de una variable debe comenzar obligatoriamente con una letra o con un guion bajo (_). Jamás puede empezar con un número.
mi_variable_1 ➔ Válido
_contador ➔ Válido
1_variable ➔ Inválido (Provoca error por empezar con dígito).
3. El guion bajo es considerado una letra
Para efectos sintácticos, Python trata al carácter _ con el mismo estatus que una letra. Puedes usarlo al inicio o entre palabras para mejorar la legibilidad (estilo conocido como snake_case).
4. Sensibilidad a mayúsculas y minúsculas (Case-Sensitivity)
En el mundo real, “Pedro” y “pedro” representan el mismo nombre propio. En Python no es así. Las mayúsculas y minúsculas crean variables completamente distintas.
Si en tu código escribes Alice = 10 y luego intentas llamarla como print(alice), Python arrojará un error porque Alice y alice son dos cajas diferentes en la memoria.
5. Prohibido usar palabras reservadas (Keywords)
El nombre de la variable no puede coincidir con ninguna de las palabras clave que Python ya utiliza para sus propias funciones internas o estructuras de control (como True, False, print, None, etc.).
Aquí tienes la adaptación de esta sección fundamental sobre la creación y asignación dinámicas de variables. Aquí es donde Python demuestra por qué es un lenguaje tan ágil en comparación con alternativas más rígidas como C++ o Java.
Creación de Variables y el Operador de Asignación (=)
¿Qué puedes meter dentro de una variable? Lo que sea. Puedes utilizar una variable para almacenar cualquier tipo de dato de los que ya hemos estudiado (enteros, flotantes, cadenas, booleanos o None) y muchos otros tipos avanzados que analizaremos más adelante. El valor de una variable es, literalmente, el dato que decides depositar en ella. Y, haciendo honor a su nombre, puede cambiar tantas veces como quieras: puede ser un entero en un instante, transformarse en un flotante un segundo después y terminar convertida en una cadena de texto.
El Milagro de la Asignación Dinámica
En Python, una variable nace y cobra existencia en el instante exacto en el que le asignas un valor por primera vez.
A diferencia de otros lenguajes tradicionales de programación, en Python no necesitas declarar la variable de forma previa (no tienes que avisarle al sistema “Oye, voy a crear una caja para guardar un entero”). Si intentas inyectar un dato dentro de una variable que no existía, Python la creará automáticamente tras bambalinas. No requieres de ninguna configuración extra.
La sintaxis para dar vida a una variable es extraordinariamente sencilla: escribes el nombre que has elegido, colocas el signo de igual (=) y finalmente escribes el valor o expresión que deseas almacenar.
El Operador de Asignación en Acción
var =1print(var)
Este script ejecuta dos instrucciones secuenciales muy claras:
var = 1: El signo = aquí no significa “igualdad matemática”, sino asignación. Toma el literal entero 1 de la derecha y lo deposita dentro de la variable llamada var. Como var no existía en la memoria, Python la crea en ese mismo milisegundo.
print(var): Aquí descubrimos otra faceta imprescindible de la función print(). No solo procesa textos o cálculos directos; también puede recibir variables como argumentos.
Resumen de Control
Las variables se crean automáticamente al recibir su primer valor.
El signo = es el operador de asignación (mueve los datos de derecha a izquierda).
print(variable) muestra el contenido de la caja; print("variable") muestra el nombre textual de la caja.
Aquí tienes la adaptación de la sección sobre el uso práctico de variables. Aquí analizaremos cómo manipular múltiples contenedores a la vez, el peligro de llamar a variables inexistentes y una técnica muy útil para el examen: la concatenación de texto con variables.
Combinando Texto y Variables: La Concatenación
Una de las operaciones más comunes en programación es fusionar cadenas de texto estáticas con los valores almacenados dentro de nuestras variables.
var ="3.8.5"print("Python version: "+ var)
Cuando el operador + se coloca entre dos datos de tipo cadena de texto (str), su función cambia por completo: ya no realiza una suma aritmética, sino que ejecuta una concatenación (une los textos uno detrás del otro como si fueran vagones de un tren).
Python version: 3.8.5
Advertencia : La concatenación con el signo +solo funciona si ambos lados son cadenas de texto (str). Si intentas hacer "Edad: " + 25 (un texto más un entero), Python arrojará un error de tipo (TypeError). Para que funcione con números usando el signo +, el número tendría que estar entre comillas ("25").
Aquí tienes la adaptación de esta sección fundamental sobre la reasignación de variables. Aquí analizaremos cómo una variable puede cambiar su contenido a lo largo del tiempo y cómo resolver esa clásica línea de código (var = var + 1) que suele escandalizar a los matemáticos pero que es el pan de cada día en la programación.
Reasignación de Variables y el Secreto de var = var + 1
¿Cómo se le asigna un nuevo valor a una variable que ya ha sido creada? Exactamente de la misma manera: volviendo a utilizar el signo de igual (=).
Como ya hemos mencionado, el signo de igual no representa una igualdad matemática, sino que es el operador de asignación. Su mecánica es directa y libre de ambigüedades: toma el valor o el resultado del argumento de la derecha y lo deposita en la variable de la izquierda. El argumento de la derecha puede ser desde un literal simple hasta una expresión arbitrariamente compleja llena de operadores, otras variables y cálculos.
var =1print(var)var = var +1print(var)
Al ejecutar este script, la consola proyectará dos líneas:
12
En efecto, lo que hemos hecho es incrementar el valor de la variable en uno. No estamos comparando nada, estamos destruyendo el pasado de la variable para actualizarla con su nuevo presente.
Resumen de Control
Las variables solo pueden guardar un valor a la vez. Cada nueva asignación destruye el valor anterior.
En instrucciones como var = var + 1, Python siempre resuelve primero el cálculo matemático del extremo derecho usando los valores actuales antes de modificar la variable de la izquierda.
Operadores de Asignación Compuesta (Shortcut Operators)
En la programación real, es extremadamente común querer usar una misma variable tanto a la izquierda como a la derecha del operador de asignación =. Por ejemplo, si estás calculando una serie de potencias sucesivas de 2, escribirías algo como esto:
x = x *2
Python ofrece una forma abreviada y elegante de escribir exactamente estas mismas operaciones, ahorrándote repetir el nombre de la variable:
x *=2sheep +=1
La Regla General de Simplificación (Enfoque PCEP)
Podemos definir una regla matemática y sintáctica universal para estas abreviaciones. Si llamamos op a cualquier operador binario (es decir, que requiere obligatoriamente dos argumentos), y dicho operador se usa en el siguiente contexto:
Analiza detenidamente la siguiente tabla de equivalencias. En el examen de certificación PCEP es muy común que te pidan “traducir” una forma larga a una corta o viceversa:
Forma Tradicional (Larga)
Forma Compacta (Shortcut)
Operación Ejecutada
i = i + 2 * j
i += 2 * j
Suma combinada
var = var / 2
var /= 2
División (Resultado float)
rem = rem % 10
rem %= 10
Residuo o Módulo
j = j - (i + var + rem)
j -= (i + var + rem)
Resta de una subexpresión
x = x ** 2
x **= 2
Exponenciación o Potencia
La Gran Trampa de Prioridad en los Shortcuts
Cuando usas un operador compuesto como += o *=, toda la expresión que se encuentra a la derecha del signo se calcula PRIMERO, como si estuviera metida dentro de un paréntesis imaginario, sin importar qué operadores tenga.
x =2x *=3+5
Comportamiento real de Python: Primero se resuelve toda la derecha: 3 + 5 = 8. Después se aplica el shortcut: x = x * 8 \(\rightarrow\) 2 * 8. El resultado final en la consola será 16.
Resumen
Los shortcut operators (+=, -=, *=, /=, //=, %=, =) fusionan la operación matemática con la asignación.
El operando de la derecha se evalúa por completo antes de que el operador compuesto actúe.
Un operador es un símbolo reservado del lenguaje de programación que tiene la capacidad de realizar una acción o cálculo específico sobre uno o más valores (datos).
El ejemplo más intuitivo es el signo + (más), el cual, exactamente igual que en la aritmética tradicional, toma dos números a sus lados, los suma y devuelve el resultado de dicha adición. Los valores sobre los cuales actúa un operador reciben el nombre técnico de operandos.
+ (Suma)
- (Resta)
* (Multiplicación)
/ (División tradicional)
// (División de piso o entera)
% (Módulo o residuo)
**(Exponenciación o potencia)
El orden en el que aparecen listados estos operadores no es casualidad; responde a sus reglas jerárquicas de prioridad.
El Concepto de Expresión
Para comunicarte con Python de forma efectiva, necesitas estructurar tus instrucciones en forma de expresiones. Una expresión es la combinación e interconexión de datos (literales o variables) y operadores. Al ser evaluada por el intérprete, una expresión siempre se reduce a un único valor final.
Bajo esta regla, debes saber que el literal más simple por sí solo ya constituye una expresión (por ejemplo, el número 5 es una expresión cuyo valor es 5). Si conectas varios elementos mediante operadores (5 + 3 * 2), estás construyendo una expresión compleja que Python resolverá paso a paso siguiendo las leyes de la matemática.
Resumen de Terminología
Operador: El símbolo que ejecuta la acción (+, -, *).
Operando: El dato que sufre la acción del operador.
Expresión: El conjunto unificado de operandos y operadores (2 + 2).
Aquí tienes la adaptación de esta sección, enfocada en el operador de exponenciación (), introduciendo una de las reglas de tipado más importantes para el examen de certificación PCEP: cómo interactúan los tipos de datos en una operación aritmética.
La Exponenciación
El símbolo (doble asterisco) es el operador de exponenciación o potencia en Python. Su argumento de la izquierda actúa como la base, mientras que el argumento de la derecha es el exponente.
La matemática clásica prefiere la notación con superíndices (como \(2^3\)). Dado que los editores de texto plano no permiten escribir caracteres elevados de forma nativa, Python adoptó el doble asterisco para lograr el mismo efecto matemático:
print(2**3)
La Regla de Propagación de Tipos
Si ejecutas diferentes combinaciones de números utilizando la exponenciación, notarás un comportamiento sumamente regular y predecible en las salidas de la consola. Este experimento nos permite formular la regla de oro de los operadores numéricos en Python:
Entero puro: Cuando ambos argumentos del operador son números enteros (int), el resultado final será obligatoriamente otro número entero.
Contaminación por flotante: Cuando al menos uno de los argumentos del operador es un número de punto flotante (float), el resultado final se convertirá automáticamente en un flotante, sin importar que el resultado matemático sea exacto.
Aquí tienes la adaptación de estas dos secciones fundamentales. Analizaremos el operador de multiplicación y entraremos de lleno en la primera gran excepción del tipado aritmético en Python: la división tradicional.
Multiplicación (*)
El símbolo * (asterisco de forma individual) es el operador de multiplicación. Pongamos a prueba el bloque de código sugerido por el curso para comprobar si la regla de propagación de tipos que aprendimos con la exponenciación se sigue manteniendo:
La regla funciona a la perfección y de manera idéntica. Multiplicar enteros puros (int * int) produce un entero (6). En el momento en que introduces un punto decimal en cualquiera de los operandos, el resultado se convierte automáticamente en un flotante (6.0).
División Tradicional (/)
El símbolo / (barra diagonal o slash) representa el operador de división estándar. El valor situado a la izquierda es el dividendo y el de la derecha es el divisor.
El resultado producido por el operador de división tradicional (/) SIEMPRE, sin excepción, será un número de punto flotante (float).
¿Por qué esto representa un problema?
En el desarrollo de software (y especialmente en algoritmos de ciencia de datos, machine learning o control de bucles), existen situaciones críticas donde necesitas estrictamente un número entero como resultado de una división (por ejemplo, si estás calculando el índice de una lista o una posición en una matriz). Un número con punto decimal provocaría un error de sintaxis en esos contextos.
División Entera (//)
Para solucionar la necesidad de obtener resultados numéricos sin decimales, Python incorpora el operador // (doble barra diagonal). Este operador se conoce formalmente como división entera o, de manera más precisa en ciencias de la computación, división de piso (floor division). Este difiere de la división estándar en dos características sintácticas y semánticas cruciales:
Elimina la parte fraccionaria: El resultado carece por completo de decimales (si operas enteros) o su parte decimal es forzada a ser siempre cero (si operas flotantes).
Cumple estrictamente la regla de propagación de tipos (int vs float).
La Regla del “Piso”: Redondeo hacia el Entero Menor
Llevemos el análisis a un nivel más avanzado. ¿Qué ocurre cuando el resultado matemático real no es exacto?
print(6//4)print(6. //4)
Si estuviéramos utilizando la división tradicional (/), el resultado matemático exacto sería 1.5. Sin embargo, al ejecutar este código con //, obtenemos:
11.0
Regla Crítica de Redondeo (PCEP)
El resultado de la división de piso siempre se redondea al número entero más cercano que sea MENOR o IGUAL al resultado real (no redondeado). No se trata de un truncamiento simple, sino de un desplazamiento hacia la izquierda en la recta numérica (hacia el valor más pequeño).
El resultado real es 1.5.
El entero menor más cercano a 1.5 es 1. Por lo tanto, el resultado es 1 (o 1.0 si hay un float).
El Peligro de los Números Negativos
Donde la mayoría de los estudiantes comete errores en el examen PCEP es al aplicar la división de piso con operandos negativos. Intenta predecir el resultado del siguiente bloque:
print(-6//4)print(6. //-4)
A primera vista, podrías pensar: “Si en el caso anterior dio 1, aquí debería dar -1”. Vamos a ejecutarlo y observar la consola:
-2-2.0
¿Por qué da -2 en lugar de -1?
Apliquemos estrictamente la regla del piso matemática:
El resultado matemático real (exacto) de -6 / 4 es -1.5.
La regla exige redondear hacia el entero menor en la recta numérica (moverse hacia la izquierda).
En el universo de los números negativos, -2 es menor que -1 (está más alejado del cero).
Por esta razón, Python redondea hacia abajo, alcanzando el -2 (o -2.0).
Resumen
Definición:// calcula la división y aplica la función suelo (floor).
Positivos:6 // 4 da 1 (el entero menor cercano a 1.5).
Negativos:-6 // 4 da -2 (el entero menor cercano a -1.5).
Tipado:int // int = int. Si hay algún float involucrado, el resultado será float (ej. 1.0 o -2.0).
Aquí tienes la adaptación de la sección sobre el operador de módulo o residuo (%) y las restricciones absolutas de la división en Python. Este es un concepto de gran peso en la lógica de programación y un blanco frecuente de preguntas en el PCEP.
El Residuo o Módulo (%)
El siguiente operador es bastante peculiar porque no tiene un símbolo equivalente directo en la aritmética tradicional de la escuela. En Python se representa con el signo de porcentaje (%).
Para que no te confunda su diseño, un buen truco visual es imaginarlo como la barra de la división (/) acompañada por dos pequeños círculos. Su función es crucial: devolver el residuo (lo que sobra) de una división entera.
En otras palabras, es el valor que queda remanente tras intentar encajar un número entero dentro de otro tantas veces como sea posible. En muchos otros lenguajes de programación se le conoce formalmente con el nombre de módulo.
Anatomía del Cálculo del Módulo
Analicemos el primer ejemplo básico propuesto por el curso. Intenta predecir el resultado antes de mirar la explicación:
print(14%4)
Al ejecutarlo, la consola nos devuelve un 2. ¿Por qué? El proceso matemático interno que sigue Python se divide en tres pasos automáticos:
Realiza una división de piso para hallar el cociente entero: 14 // 4 da 3 (el 4 cabe 3 veces enteras en el 14).
Multiplica ese cociente por el divisor original: 3 * 4 da 12.
Resta ese valor intermedio al dividendo original para hallar el residuo: 14 - 12 da 2.
Elevando la Dificultad: Módulo con Flotantes
El operador % también cumple de forma estricta la regla de propagación de tipos (int vs float). Observa este caso más complejo:
print(12%4.5)
¿Cuál es el resultado?
Si hacemos el mismo desglose algorítmico:
12 // 4.5 da como resultado 2.0 (el 4.5 cabe dos veces enteras en el 12, acumulando 9.0).
Multiplicamos el cociente por el divisor: 2.0 * 4.5 nos da 9.0.
Restamos el dividendo original menos el resultado intermedio: 12 - 9.0 da 3.0.
Dado que uno de los operandos era un flotante (4.5), todo el resultado se “contamina”, devolviendo en la consola 3.0 en lugar de un 3 entero.
Operadores: Cómo NO debes dividir (Límites de la Máquina)
Existe una regla matemática universal que las computadoras defienden de forma agresiva debido a limitaciones físicas en la unidad de procesamiento aritmético: la división por cero es imposible.
En tus programas de Python, jamás debes intentar:
Realizar una división tradicional por cero (6 / 0).
Realizar una división de piso o entera por cero (6 // 0).
Encontrar el residuo de una división por cero (6 % 0).
Si el intérprete de Python topa con cualquiera de estas tres operaciones durante la ejecución de tu script, detendrá el programa de golpe y arrojará un error en tiempo de ejecución muy específico: ZeroDivisionError: integer division or modulo by zero.
Resumen
% extrae únicamente el residuo de una división.
Sigue las reglas de tipado: int % int da int. Si hay un float, devuelve float.
Cualquier variante de división donde el divisor sea 0 provocará un colapso del programa (ZeroDivisionError).
Aquí tienes la adaptación de esta sección, donde cerramos el catálogo de operadores básicos con la suma y la resta, e introducimos una distinción conceptual teórica que es pregunta de examen obligatoria en el PCEP: la diferencia entre operadores unarios y binarios.
El Operador de Suma (+)
El signo más (+) actúa como el operador de adición propagando el punto flotante en caso de que haya.
print(-4+4)print(-4. +8)
04.0
En la primera línea, int + int produce el entero 0.
En la segunda línea, la presencia del punto decimal en el -4. propaga el tipo flotante, devolviendo 4.0.
Operadores Binarios vs. Operadores Unarios
El signo menos (-) tiene una naturaleza dual en programación. Puede actuar de dos formas completamente distintas dependiendo de cuántos argumentos (operandos) lo acompañen. Esto nos permite clasificar los operadores en dos familias:
Operadores Binarios (Requieren DOS operandos)
Cuando utilizas el signo - para realizar una resta tradicional, el operador espera obligatoriamente dos argumentos: uno a la izquierda (el minuendo) y otro a la derecha (el sustraendo). Por esta razón, la resta es un operador binario, exactamente igual que la suma (+), la multiplicación (*) y la división (/).
Operadores Unarios (Requieren UN solo operando)
El signo menos también puede utilizarse para cambiar o invertir el signo de un número. Cuando escribes -4, el operador no está restando nada; simplemente está modificando la polaridad del operando que tiene a su derecha. Al actuar sobre un único argumento, se le considera un operador unario.
Aquí tienes la adaptación de esta sección fundamental sobre la prioridad (precedencia) y asociatividad (bindings) de los operadores. Estos conceptos matemáticos abstractos determinan el orden exacto en el que Python desglosa expresiones complejas y son una fuente garantizada de preguntas capciosas en el examen PCEP.
Jerarquía de Operadores: Prioridad y Asociatividad
Hasta ahora hemos analizado cada operador de forma aislada, como si no tuvieran relación entre sí. Sin embargo, en la programación real, lo habitual es encontrar expresiones complejas donde conviven múltiples operadores al mismo tiempo.
El fenómeno que provoca que algunos operadores actúen antes que otros se conoce formalmente como la jerarquía de prioridades o precedencia de operadores. Python define con precisión matemática el nivel de prioridad de cada símbolo, asegurando que los operadores con mayor prioridad tomen el control de los operandos antes que los de menor prioridad.
Asociatividad de Operadores (Bindings)
¿Qué sucede cuando en una misma expresión se encuentran dos operadores pegados que tienen exactamente la misma prioridad? Aquí es donde entra en juego la asociatividad (binding), la cual determina el orden de evaluación de izquierda a derecha o viceversa.
La gran mayoría de los operadores en Python tienen asociatividad a la izquierda (left-sided binding). Esto significa que el cálculo de la expresión se ejecuta estrictamente de izquierda a derecha. Analicemos este ejemplo con el operador de módulo:
Tabla de Precedencia y Asociatividad (De Mayor a Menor)
Nivel de Prioridad
Operador
Descripción
Asociatividad (Binding)
1 (Máxima)
**
Exponenciación (Potencia)
Derecha a Izquierda (La gran excepción)
2
+, -
Operadores Unarios (Signo positivo/negativo)
Izquierda a Derecha
3
*, /, //, %
Multiplicación, División, División de piso y Módulo
Izquierda a Derecha
4 (Mínima)
+, -
Operadores Binarios (Suma y Resta)
Izquierda a Derecha
Unarios vs. Binarios
Un signo menos unario (-5) tiene más prioridad que una multiplicación o una división, pero un signo menos binario (5 - 2) tiene menos prioridad que ellas. Observa cómo cambia el orden en este ejemplo:
print(-3**2)
Aquí, la potencia tiene un nivel de prioridad (1) más alto que el menos unario (2). Por lo tanto, Python calcula primero $3^2 = 9$, y después el menos unario entra en acción para cambiarle el signo, dando como resultado -9 (y no 9 positivo, como ocurriría si el menos operara primero). Si quisieras elevar el número negativo completo, estarías obligado a usar paréntesis: (-3) 2.
Operadores y Paréntesis: Rompiendo las Reglas Naturales
Por supuesto, no estás atado a las prioridades por defecto de Python. Tienes permitido utilizar paréntesis () en cualquier momento para alterar el orden natural de un cálculo. En perfecta sintonía con las reglas aritméticas universales, las subexpresiones que se encuentran dentro de los paréntesis siempre se calculan primero.
Puedes anidar tantos paréntesis como necesites. De hecho, muchos desarrolladores los utilizan incluso cuando no alteran el orden, simplemente para que el código sea más legible y fácil de entender para otros humanos.
Reto: El Desafío de los Paréntesis Anidados
Intenta resolver paso a paso la siguiente expresión compleja antes de mirar la solución. Es un excelente ejercicio de rastreo mental para el PCEP:
print((5* ((25%13) +100) / (2*13)) //2)
El flujo va estrictamente desde adentro hacia afuera. Python no puede resolver el contenedor exterior sin saber primero qué valor numérico esconde el contenedor más interno.
Cuando tienes bloques independientes de paréntesis que no dependen el uno del otro, la regla que aplica Python es procesar de izquierda a derecha.
Desglose paso a paso desde el interior hacia el exterior:
Primer bloque interno (25 % 13): El 13 cabe una sola vez en el 25 y genera un residuo de 12.
Segundo bloque interno (12 + 100): Sumamos el residuo anterior, lo que nos da 112.
Bloque del divisor (2 * 13): Resolvemos el paréntesis del extremo derecho, obteniendo 26.
Multiplicación izquierda (5 * 112): Multiplicamos el resultado del segundo paso, lo que nos da 560.
División tradicional (560 / 26): Al usar la barra diagonal /, el resultado se transforma obligatoriamente en un número flotante: 21.53846153846154.
División de piso final (21.53846153846154 // 2): Aplicamos la división entera sobre el flotante. El 2 cabe exactamente 10 veces en el 21. Al haber un flotante involucrado, la parte decimal se fuerza a cero.
El resultado final que verás en la consola es 10.0.
A nivel teórico, un literal se define como un dato cuyo valor está determinado única y exclusivamente por su propia representación literal. Como esta definición formal puede resultar un tanto abstracta y difícil de asimilar al principio, recurramos a un ejemplo práctico para entenderlo a la perfección.
El Experimento de la Identificación
Analicemos detenidamente los dos elementos siguientes:
Caso 1: Una secuencia numérica
123
Si miras este conjunto de dígitos, ¿puedes deducir qué valor representa? La respuesta es inmediata: representa el número ciento veintitrés. No hay espacio para la duda ni la libre interpretación; su valor es fijo y evidente.
Caso 2: Una sola letra
c
Si miras esta letra de forma aislada, ¿sabrías decir con certeza qué valor representa? Aquí la situación cambia. Podría ser el símbolo físico de la velocidad de la luz, la constante de integración en una fórmula de cálculo matemático, o la longitud de la hipotenusa en el teorema de Pitágoras. Las posibilidades son infinitas.
Sin información o contexto adicional (como una línea de código previa que defina su significado), es imposible saber qué representa exactamente esa c.
La Clave de la Distinción
123 es un literal: Su valor es inmutable y obvio desde el momento en que se escribe. No necesita un contexto para “significar” ciento veintitrés; se explica por sí mismo.
c no es un literal: Es un símbolo (en programación, habitualmente una variable). Su valor es abstracto y puede cambiar o asignarse dinámicamente a lo largo del programa.
¿Para qué sirven los literales en el código?
En el desarrollo de software, utilizas los literales constantemente para codificar datos duros y fijos directamente dentro de tu código fuente (por ejemplo, cuando escribes el mensaje "Hello, World!", el número de iteraciones de un bucle como 10, o una tasa de interés fija como 0.16).
Sin embargo, para que el intérprete de Python no confunda tus literales con variables u otras instrucciones, el lenguaje exige respetar una serie de convenciones y reglas de escritura muy estrictas según el tipo de dato que estés manejando (enteros, decimales, textos o booleanos).
Aquí tienes la adaptación de esta sección, enfocada en la diferencia fundamental entre cómo procesa la computadora un string frente a un número entero, un concepto clave para entender el manejo de memoria en Python y preparar tu examen PCEP.
Detrás de la Pantalla: Strings vs. Números Enteros
Para entender cómo maneja Python los datos internamente, analicemos el siguiente experimento mental con dos líneas de código muy similares pero con una diferencia crítica:
print("2026")print(2026)
A primera vista, la primera línea te resultará completamente familiar (un string delimitado por comillas). La segunda línea podría parecer un error debido a la total ausencia de comillas. Sin embargo, si ejecutas este código, el intérprete no protestará. Al contrario, verás dos líneas exactamente idénticas en tu pantalla:
20262026
¿Qué pasó realmente? Dos Tipos de Literals
Aunque el resultado visual en la consola sea idéntico, semánticamente estás lidiando con dos especies de datos completamente diferentes:
Un String ("2026"): Una cadena de caracteres que ya dominas.
Un Número Entero (2026): Un literal de tipo numérico entero (integer), algo totalmente nuevo en nuestro recorrido.
La función print() se encarga de traducir ambos a una forma legible para los humanos, y dado que la representación visual de ambos es la misma, en la pantalla se ven igual. Pero dentro de la memoria de la computadora, sus vidas son radicalmente distintas.
La Vida Interna en la Memoria del Computador
El almacenamiento de estos dos literales sigue caminos opuestos en el hardware:
El String ("2026"): Para la computadora, este dato no tiene ningún valor matemático. Existe en la memoria simplemente como una secuencia de caracteres o letras independientes (el carácter ‘2’, seguido del ‘0’, luego el ‘2’ y finalmente el ‘6’). La máquina no sabe qué número es, solo guarda los dibujos de los caracteres alineados.
El Número Entero (2026): Cuando Python ve los dígitos directos sin comillas, sabe que se trata de una cantidad matemática. El intérprete toma el número y lo convierte directamente en código máquina, es decir, en una representación binaria pura (un conjunto de bits, ceros y unos) dentro de los circuitos del procesador.
Gracias a esta conversión, la computadora puede usar ese 2026 para realizar operaciones aritméticas reales (sumar, restar, multiplicar), algo que sería imposible de hacer directamente con el string "2026".
Aquí tienes la adaptación de esta sección clave sobre los números enteros, estructurada con la claridad conceptual necesaria para asentar las bases del tipado de datos en Python y asegurar puntos en el examen PCEP.
Literales Numéricos: El Tipo Entero (Integer)
Los números que manejan las computadoras modernas se dividen principalmente en dos grandes mundos:
Enteros (Integers / int): Números que carecen por completo de parte fraccionaria o decimal (por ejemplo, 4, -15, 0).
Números de Punto Flotante (Floats / float): Números que contienen (o pueden contener) una parte fraccionaria o decimal (por ejemplo, 3.14, -0.5).
Esta distinción es crítica. La frontera entre ambos es sumamente estricta porque difieren radicalmente en cómo se almacenan en la memoria física del ordenador y en el rango de valores que pueden adoptar.
A la característica que determina la naturaleza de un valor, su rango admisible y sus aplicaciones permitidas se le conoce formalmente como Tipo de Dato (Data Type). En Python, la estructura física de tu literal le indica automáticamente al intérprete qué tipo de dato debe asignarle en memoria.
¿Cómo reconoce Python un número entero?
El proceso es muy intuitivo y se parece a cómo escribes un número con lápiz en papel: es simplemente una secuencia continua de dígitos. Sin embargo, existe una restricción absoluta: no puedes intercalar ningún carácter que no sea un dígito dentro del número.
Tomemos como ejemplo el número once millones ciento once mil ciento once. En el mundo real, para facilitar la lectura de tantas cifras, usarías alguna de estas notaciones:
11,111,111 (Notación anglosajona)
11.111.111 (Notación europea)
11 111 111 (Separación por espacios)
Python prohíbe terminantemente el uso de comas, puntos o espacios en blanco dentro de un entero. Si pones un punto, Python pensará que es un decimal (float); si pones una coma o un espacio, arrojará un error de sintaxis inmediato.
La solución: El uso de guiones bajos (_)
Para resolver este problema de legibilidad en números grandes, Python introdujo una regla especial: permite el uso de guiones bajos individuales como separadores visuales. El intérprete ignora por completo estos guiones bajos al procesar el valor. Por lo tanto, puedes escribir legítimamente ese número de dos formas:
numero_1 =11111111# Válido, pero difícil de leer a simple vistanumero_2 =11_111_111# Válido, limpio y perfectamente legible
Gestión de Signos: Números Positivos y Negativos
La codificación de la polaridad numérica en Python sigue las convenciones matemáticas universales:
Números Negativos: Se configuran anteponiendo de forma obligatoria el operador menos (-) al literal.Pythonprint(-11111111) print(-11_111_111)
Números Positivos: No requieren ningún signo que los preceda de forma obligatoria; la ausencia de signo le indica a Python que el número es positivo. Sin embargo, es completamente permisible añadir un signo más (+) si deseas hacerlo explícito en tu código. Las siguientes dos líneas producen exactamente el mismo valor semántico.
Aquí tienes la adaptación de esta sección avanzada sobre los sistemas numéricos alternativos, un tema recurrente y crítico en el examen de certificación PCEP para evaluar tu comprensión profunda de los literales enteros.
Sistemas Numéricos Alternativos: Octal y Hexadecimal
En el mundo de las matemáticas convencionales y en nuestro día a día, estamos acostumbrados a utilizar el sistema decimal (base 10), que emplea los dígitos del 0 al 9. Sin embargo, en el desarrollo de software y en la arquitectura de sistemas, trabajar con otras bases numéricas resulta sumamente eficiente.
Python ofrece dos convenciones especiales para codificar números enteros utilizando sistemas de numeración que no usamos en la vida cotidiana: el sistema octal y el sistema hexadecimal.
El Sistema Octal (Base 8)
Si necesitas representar un número en formato octal, Python exige que utilices un prefijo específico inmediatamente antes de los dígitos: 0o o 0O (el número cero seguido de la letra “o”, ya sea minúscula o mayúscula).
Debido a que el sistema octal funciona en base 8, los literales que utilices después del prefijo deben contener única y exclusivamente dígitos dentro del rango del 0 al 7. Si intentas usar un 8 o un 9 con este prefijo, Python arrojará un error de sintaxis inmediato.
print(0o123)
Al ejecutarla, la consola no mostrará 0o123. Como ya aprendimos, la función print() realiza la conversión de forma automática a nuestra base humana estándar. El resultado en la pantalla será:
83
El Sistema Hexadecimal (Base 16)
La segunda convención nos permite trabajar con el sistema hexadecimal, ampliamente utilizado en informática para representar direcciones de memoria, configuraciones de red (direcciones MAC) o códigos de color.
Para indicarle a Python que estás escribiendo un literal en base 16, debes anteponer el prefijo 0x o 0X (el número cero seguido de la letra “x”).
El sistema hexadecimal utiliza dieciséis caracteres para contar: los dígitos del 0 al 9 y las letras de la A a la F (donde A=10, B=11, C=12, D=13, E=14, F=15), las cuales pueden escribirse indistintamente en mayúsculas o minúsculas.
print(0x123)
La función print() gestionará el valor binario interno y proyectará en la consola su equivalente decimal exacto:
291
Aquí tienes la adaptación de esta sección, enfocada en la sintaxis y las reglas estrictas de los números de punto flotante (floats), un componente vital para el manejo de datos precisos y una pregunta fija en el examen PCEP.
Literales Numéricos: El Tipo Punto Flotante (Float)
Es momento de explorar el segundo gran tipo numérico en Python, diseñado específicamente para representar y almacenar lo que en matemáticas se conoce como números con una fracción decimal no vacía.
Hablamos de los números que tienen (o son capaces de tener) una parte fraccionaria después del punto decimal. Cada vez que piensas en un valor como dos y medio o menos cero coma cuatro, estás ante datos que el intérprete de Python clasifica como números de punto flotante (floating-point numbers o simplemente floats):
2.5-0.4
La Regla de Oro: El Punto vs. La Coma
Si en tu país natal (como en España o gran parte de Latinoamérica) estás acostumbrado a escribir los decimales utilizando una coma (ej. 2,5), debes prestar mucha atención y cambiar ese hábito al programar: Python utiliza estrictamente el punto (.) como separador decimal.
Asegúrate de que tus números decimales no contengan comas en absoluto. Si intentas escribir algo como print(2,5), Python no lo interpretará como “dos y medio”. Para el intérprete, la coma tiene un significado reservado (separar argumentos), por lo que pensará que le estás pasando dos números enteros independientes (el 2 y el 5) en lugar de un único decimal.
La Regla de la Omisión del Cero (Abreviación)
Cuando escribes un número flotante en Python y el número 0 es el único dígito que se encuentra inmediatamente antes o después del punto decimal, tienes permitido omitirlo por completo. Esto no alterará en absoluto ni el valor matemático ni el tipo de dato del número.
Veamos cómo funciona esta regla de abreviación:
Omitir el cero inicial: El valor cero punto cuatro (0.4) se puede escribir simplemente omitiendo el cero antes del punto (.4):
Omitir el cero final: El valor cuatro punto cero (4.0) se puede escribir omitiendo el cero que va después del punto:
Ambas formas son completamente válidas y equivalentes en Python. De hecho, ver un número escrito simplemente como 4. es una de las “trampas” visuales más comunes en las preguntas del examen PCEP para comprobar si sabes distinguir un entero de un flotante.
Aquí tienes la adaptación de esta sección, donde se profundiza en el impacto que tiene el punto decimal y se introduce la notación científica mediante la letra e, un recurso indispensable para simplificar números colosales o microscópicos en Python.
Ints vs. Floats y la Notación Científica (e)
Como acabamos de ver, el punto decimal es el factor fundamental que utiliza Python para reconocer un número de punto flotante. Analicemos detenidamente este par de números:
44.0
Desde una perspectiva puramente matemática, ambos representan exactamente la misma cantidad. Sin embargo, Python los ve y los procesa de formas completamente distintas:
4 es un número entero (int).
4.0 es un número de punto flotante (float).
La simple presencia del punto cambia las reglas del juego en la memoria de la computadora. Pero el punto no es la única vía para dar vida a un float. Existe otra herramienta matemática clave: la letra e.
La Notación Científica para Números Extremos
Cuando necesitas manipular datos que involucran números extremadamente grandes (como distancias astronómicas) o ridículamente pequeños (como medidas a nivel cuántico), escribir todos los ceros en el editor de código resulta ineficiente y propenso a errores. Para solucionar esto, Python adopta la notación científica.
Pensemos, por ejemplo, en la velocidad de la luz expresada en metros por segundo. Si la escribimos de forma directa y tradicional, se vería así: 300000000
Para evitar saturar el texto con tantos ceros, los libros de física recurren a una abreviación abreviada que seguro te resulta familiar: \(3 \times 10^8\) (tres multiplicado por diez a la potencia de ocho).
En Python, logramos exactamente ese mismo efecto semántico de una manera muy compacta utilizando la letra E (o su versión en minúscula, e):
3e8
Anatomía de la Notación Científica en Python
La letra e proviene de la palabra exponent (exponente) y funciona en el código como un registro abreviado que significa literalmente: “multiplicado por diez a la potencia de”.
Para que Python acepte esta estructura sin protestar, debes memorizar dos reglas sintácticas estrictas para el examen PCEP:
El Exponente (el valor después de la E): Tiene que ser obligatoriamente un número entero. Puede ser positivo (para números grandes) o negativo (para números pequeños), pero nunca decimal.
La Base (el valor delante de la E): Puede ser tanto un número entero como un decimal.
⚠️ Efecto colateral importante: Cualquier número escrito con notación científica (E), independientemente de si la base es un entero, se convertirá automáticamente en un tipo de dato flotante (float) dentro de la memoria de Python.
Por ejemplo, si ejecutas print(3E8), la consola te devolverá 300000000.0, demostrando con ese punto final que el dato ha sido catalogado como un float.
Aquí tienes la adaptación de esta sección, enfocada en cómo codificar números extremadamente pequeños mediante exponentes negativos y cómo Python optimiza automáticamente la representación visual de los floats en la consola.
Codificación de Floats: Exponentes Negativos y la Ley de Economía
En la sección anterior aprendimos a condensar números colosales usando la notación científica con exponentes positivos. Ahora analizaremos cómo aplicar esta misma convención para registrar números que son extremadamente pequeños (aquellos cuyo valor absoluto es ridículamente cercano a cero).
Un ejemplo clásico de la física es la constante de Planck (denotada como \(h\)), cuyo valor en los libros de texto es \(6.62607 \times 10^{-34}\).
Si necesitaras introducir esta constante matemática en un flujo de datos dentro de tu programa, la sintaxis correcta en Python sería:
6.62607e-34
El signo menos (-) colocado inmediatamente después de la E le indica al intérprete que el punto decimal debe desplazarse 34 posiciones hacia la izquierda, dando como resultado un número microscópico.
La Ley de la Presentación Económica de Python
Existe un detalle crítico que suele desconcertar a los programadores principiantes y que es una pregunta recurrente en el examen PCEP: El hecho de que tú elijas una forma específica de escribir un literal flotante no garantiza que Python lo muestre exactamente igual en la pantalla.
Python cuenta con un algoritmo interno diseñado para elegir siempre la forma más económica y compacta de presentar un número en la consola. Imagina que decides escribir un literal flotante repleto de ceros de forma manual en tu editor:
print(0.0000000000000000000001)
Al ejecutar esta instrucción, Python evalúa la cantidad de caracteres. En lugar de ensuciar la terminal imprimiendo una fila interminable de ceros que dificulta la lectura, el intérprete optimiza la salida y te devuelve esto:
1e-22
¿Por qué hace esto Python?
Porque escribir y leer 1e-22 consume muchísimos menos recursos visuales y espacio que su contraparte extendida. El valor matemático interno en la memoria sigue siendo exactamente el mismo, pero la semántica de su presentación se transforma en pro de la legibilidad y la eficiencia.
Aquí tienes la adaptación de esta sección fundamental sobre las cadenas de texto (strings), enfocada en cómo resolver uno de los desafíos sintácticos más comunes en el código: cómo introducir comillas dentro de un texto sin romper las fronteras del propio string.
Literales de Cadena: El Tipo String y el Dilema de las Comillas
Las cadenas de texto o strings se utilizan en programación cuando necesitas procesar texto (como nombres, direcciones, mensajes o párrafos completos) en lugar de cantidades matemáticas. Como ya hemos establecido, los strings necesitan comillas de la misma manera que los floats necesitan un punto decimal. Un literal de cadena estándar se ve así:
"I am a string."
Sin embargo, aquí se presenta un dilema clásico: ¿Cómo podemos introducir una comilla dentro de un texto que ya está delimitado por comillas?
Imagina que necesitas proyectar en la consola este mensaje exacto, incluyendo las comillas internas: I like "Monty Python" . Si intentas escribirlo de forma ingenua como print("I like "Monty Python""), Python se confundirá de inmediato, asumirá que el string termina justo antes de la letra M, y arrojará un error de sintaxis. Para solucionar este problema, el lenguaje nos ofrece dos caminos muy elegantes.
Solución 1: El Carácter de Escape (\)
La primera alternativa se basa en un concepto que ya conocemos: el carácter de escape representado por la barra invertida (\). Así como la barra invertida altera el significado de la letra n para crear un salto de línea (\n), también puede escapar el significado de las comillas. Cuando colocas una barra invertida inmediatamente antes de una comilla, esta cambia su rol semántico: deja de ser interpretada como una frontera o delimitador de código y pasa a ser un simple carácter textual de datos.
print("I like \"Monty Python\"")
Si te fijas bien, hay dos comillas escapadas (\") envolviendo la frase. Al ejecutarse, Python ignorará las barras invertidas en la consola y mostrará las comillas de manera literal.
Solución 2: Alternancia de Delimitadores (Comillas Simples)
La segunda solución suele resultar muy sorprendente y cómoda para los desarrolladores. Python te permite definir un string utilizando tanto comillas dobles (") como comillas simples o apóstrofes ('). Aprovechando esta flexibilidad, si necesitas que tu texto contenga comillas dobles en su interior, puedes delimitar externamente todo el string usando comillas simples:
print('I like "Monty Python"')
Aquí tienes la adaptación de la sección final sobre los literales de Python, enfocada en los valores booleanos, su origen lógico y la resolución del reto interactivo.
Valores Booleanos: El Tipo Lógico (Boolean)
Para concluir el estudio de los literales en Python, debemos analizar los dos últimos elementos del catálogo. A diferencia de los números o los textos, estos dos literales no representan objetos tangibles o cantidades contables, sino un concepto abstracto fundamental: la veracidad.
Cada vez que le pides a Python que compare si un número es mayor que otro o si una contraseña es correcta, esa evaluación genera un tipo de dato específico: un valor booleano (Boolean o bool).
El nombre rinde homenaje a George Boole (1815-1864), un matemático británico que definió el álgebra booleana, una estructura lógica basada exclusivamente en dos estados distintos: Verdadero y Falso, representados matemáticamente como 1 y 0.
El Intérprete Binario: Respuestas sin Matices
En el desarrollo de software, tú escribes el código y el programa le hace preguntas al sistema operativo o a los datos. Python ejecuta esas instrucciones y devuelve las respuestas. Para que una computadora pueda tomar decisiones automatizadas, necesita respuestas absolutas.
Por suerte, los ordenadores solo contemplan dos tipos de contestaciones:
Sí, esto es verdadero (True)
No, esto es falso (False)
El Desafío: ¿Qué imprimen estas líneas?
Analicemos el reto propuesto por el curso. Si pones a prueba este bloque de código en tu entorno:
print(True>False)print(True<False)
El Resultado en la Consola:
TrueFalse
Explicación Semántica: ¿Por qué ocurre esto?
Este comportamiento se debe directamente a la herencia del álgebra de George Boole en la arquitectura de computadores. Tras bambalinas, Python asigna un valor numérico intrínseco a los estados lógicos para poder operar con ellos a nivel de bits:
True equivale aritméticamente a 1
False equivale aritméticamente a 0
Por lo tanto, cuando le pides a Python que evalúe si True > False, el procesador traduce internamente la pregunta a términos matemáticos básicos: ¿Es 1 > 0? Como la respuesta a esa pregunta es afirmativa, la primera instrucción imprime True.
Aquí tienes la adaptación y estructuración de la sección de puntos clave (Key Takeaways) de este módulo, un resumen ideal para repasar antes de realizar los test de práctica del PCEP. He incluido el concepto extra de None de forma muy visual.
Resumen del Módulo: Conceptos Clave (Key Takeaways)
Para consolidar los conocimientos de este capítulo antes de avanzar, repasemos los pilares fundamentales sobre los literales y los tipos de datos en Python:
1. ¿Qué es un Literal?
Los literales son notaciones específicas utilizadas en el código fuente para representar valores fijos e inmutables. Python cuenta con varias familias de ellos:
Literales numéricos: Por ejemplo, el entero 123.
Literales de cadena (strings): Por ejemplo, "I am a literal.".
2. Sistemas de Numeración Computacional
Sistema Binario: Utiliza el 2 como base, lo que significa que se compone únicamente de ceros y unos (0 y 1). Por ejemplo, el binario 1010 equivale al número 10 en nuestro sistema decimal.
Sistemas Octal y Hexadecimal: Utilizan el 8 y el 16 como bases, respectivamente. El sistema hexadecimal (0x) se apoya en los números decimales del 0 al 9 y añade seis letras (A a la F) para completar sus dieciséis valores posicionales.
3. Números Enteros (Integers / int)
Son uno de los tipos numéricos nativos de Python. Se caracterizan por escribirse sin ninguna parte fraccionaria o decimal. Pueden ser tanto positivos (256) como negativos (-1).
4. Números de Punto Flotante (Floats / float)
Es el tipo numérico diseñado para almacenar valores continuos que contienen (o tienen la capacidad de contener) un componente fraccionario o decimal separado estrictamente por un punto. Ejemplo: 1.27.
5. El Dilema de las Comillas en los Strings
Para incrustar un apóstrofe o una comilla dentro de un texto sin romper la sintaxis del lenguaje, dispones de dos estrategias:
Uso del carácter de escape: Anteponer una barra invertida (\), por ejemplo: 'I\'m happy.'.
Alternancia de símbolos: Envolver el texto con los delimitadores opuestos a los que deseas mostrar. Usas comillas dobles externas para proteger un apóstrofe interno ("I'm happy.") o comillas simples externas para proteger comillas dobles internas ('He said "Python"').
6. Valores Booleanos (bool)
Son dos objetos constantes, True (Verdadero) y False (Falso), que se utilizan para representar estados lógicos de veracidad. En contextos puramente numéricos o aritméticos, True se comporta como un 1, mientras que False equivale a un 0.
🌟 Contenido Extra: El Literal Especial None
Existe un último literal altamente especializado en el ecosistema de Python que debes conocer: None.
¿Qué es? Es un objeto único que pertenece a su propio tipo de dato llamado NoneType.
¿Para qué sirve? Se utiliza de forma explícita para denotar la ausencia total de un valor o un estado “vacío”. No equivale al número cero (0), ni a un string vacío (""), ni a False; es simplemente la representación formal de que un contenedor no tiene datos o de que una función no devolvió nada (como el caso de print()).
Si hay una instrucción que todo programador conoce al iniciar su camino en un nuevo lenguaje, es la encargada de mostrar datos en la pantalla. En Python, esa herramienta es la función print(). Analicemos la línea de código más famosa de la informática:
print("Hello, World!")
A simple vista parece sencillo, pero detrás de esta línea se esconden los principios fundamentales de cómo interactuamos con el lenguaje.
¿Qué es una función en programación?
La palabra print es el nombre de una función. Sin embargo, esto no significa que cada vez que aparezca esta palabra en un script actúe como tal; su significado depende estrictamente del contexto en el que se utilice (como veremos más adelante al hablar de variables o texto).
En el contexto del software, una función es un bloque de código separado e independiente que posee la capacidad de realizar dos tareas (ya sea de forma individual o conjunta):
Efectuar un efecto secundario (Efecto): Consiste en provocar un cambio perceptible en el sistema. Por ejemplo: mostrar un texto en la terminal, crear un archivo en el disco, dibujar una gráfica en la pantalla o reproducir un sonido. Esto es algo que no existe en el mundo de las matemáticas puras.
Evaluar y devolver un valor (Resultado): Al igual que en matemáticas, toma un dato de entrada, realiza un cálculo (como calcular una raíz cuadrada o medir la longitud de un texto) y devuelve el resultado final al programa.
La función print() se enfoca principalmente en la primera tarea: su objetivo y efecto principal es enviar texto a la consola.
¿De dónde provienen las funciones en Python?
A medida que avances en el curso, notarás que no todas las funciones se invocan ni se configuran de la misma manera. En Python, las funciones pueden tener tres orígenes distintos:
1. Funciones Integradas (Built-in Functions)
Vienen incorporadas de forma nativa en el núcleo de Python. La función print() pertenece a este grupo. Están disponibles desde el primer segundo en que instalas el entorno; no necesitas realizar ninguna configuración, descarga o importación especial para utilizarlas.
2. Funciones de Módulos (Modules)
Son herramientas que se encuentran organizadas en “paquetes” o complementos externos llamados módulos. Algunos de estos módulos vienen preinstalados con Python (la librería estándar) y otros requieren una instalación independiente desde internet. Para poder usar sus funciones, debes conectarlas explícitamente a tu código usando la instrucción import.
3. Funciones Propias (Definidas por el usuario)
Tú tienes el poder de escribir tus propias funciones. Puedes diseñar bloques de código personalizados e insertar tantos como necesites dentro de tu programa para que este sea más organizado, limpio, reutilizable y elegante.
La Importancia de un Buen Nombre
El nombre de una función debe ser significativo y autoexplicativo. El nombre de la función print (imprimir) cumple esto a la perfección, ya que describe de inmediato su propósito operativo.
Cuando utilizas funciones integradas o de módulos existentes, no tienes control sobre sus nombres. Sin embargo, cuando llegue el momento de desarrollar tus propias funciones, elegir nombres claros y descriptivos será una de tus responsabilidades más importantes como programador para mantener el código legible.
Los Componentes de una Función: Argumentos y Sintaxis
Previamente establecimos que una función en Python puede generar un efecto y devolver un resultado. Sin embargo, existe un tercer componente fundamental que determina cómo interactuamos con ellas y cómo procesan la información: los argumentos.
¿Qué es un Argumento?
En el ámbito de la programación, un argumento es el dato (o conjunto de datos) que le proporcionas a una función para que pueda realizar su trabajo. Es la materia prima que la función necesita procesar.
Si volvemos a la analogía matemática, una función como \(sin(x)\) requiere obligatoriamente un argumento (\(x\)), que representa la medida de un ángulo. Sin ese valor, la función no tiene nada que calcular.
Las funciones de Python son sustancialmente más versátiles. Dependiendo de su diseño y de las necesidades del script, pueden aceptar cualquier número de argumentos: tantos como sean necesarios para cumplir su tarea.
💡 Nota clave: “Cualquier número” incluye también el cero. Algunas funciones de Python están diseñadas para ejecutarse de forma autosuficiente y no requieren que les pases ningún dato.
La Sintaxis Obligatoria: El Rol de los Paréntesis
Independientemente de cuántos argumentos necesite o reciba una función, Python exige estrictamente la presencia de un par de paréntesis: uno de apertura ( y uno de cierre ).
Con argumentos: Si deseas enviar uno o más datos a la función, debes colocarlos ordenadamente dentro de los paréntesis.
Sin argumentos: Si vas a invocar una función que no requiere parámetros, los paréntesis deben permanecer vacíos, pero siguen siendo obligatorios.
📝 Convención de lectura: Para distinguir visualmente una palabra común (como una variable) del nombre de una función en la documentación, artículos o apuntes, se acostumbra escribir un par de paréntesis vacíos inmediatamente después del nombre. Por ello, a partir de ahora, nos referiremos a ella formalmente como print().
Anatomía de nuestra primera línea de código
Analicemos minuciosamente nuestro ejemplo inicial bajo estos nuevos conceptos:
print("Hello, World!")
Si desglosamos esta instrucción en sus componentes anatómicos básicos, encontramos la siguiente estructura estándar:
print ( "Hello, World!" ) │ │ │ │ ┌─┴───────┴┐ ┌─┴───────┐ ┌┴─────────┐ │ Nombre │ │Argumento│ │Paréntesis│ │ de la │ │ (Texto) │ │de cierre │ │ función │ └─────────┘ └──────────┘ │ y Paren- │ │ tesis de │ │ apertura │ └──────────┘
¿Tiene argumentos la función print() en este ejemplo?
Por supuesto que sí. En este escenario específico, el argumento es la cadena de texto "Hello, World!". Al colocar esa frase entre comillas dentro de los paréntesis, le estamos indicando a la función print() exactamente qué información queremos que procese y proyecte como efecto secundario en la terminal.
Aquí tienes la adaptación de esta sección, enfocada en el concepto de las cadenas de texto (strings) y la transición fundamental entre la sintaxis y la semántica en la programación.
El Tipo de Dato String: Delimitando Código y Datos
En nuestro ejemplo fundamental, el único argumento que le pasamos a la función print() es una cadena de caracteres o string:
print("Hello, World!")
Como puedes observar, este texto está delimitado por comillas. En Python, las comillas no son un simple adorno: son las que transforman el texto en un string. Su función principal es aislar una parte del archivo y asignarle un significado completamente diferente al del resto del programa.
El Propósito de las Comillas: “Esto no es código”
Puedes imaginar las comillas como una frontera que le dice al intérprete de Python:
“Todo lo que esté atrapado entre nosotros no es código ejecutable. No intentes analizarlo como una orden, simplemente tómalo tal cual es: como datos”.
Casi cualquier carácter que coloques dentro de las comillas será tomado de forma literal. El intérprete no intentará buscar una función llamada Hello o una variable llamada World; simplemente imprimirá esos caracteres en la pantalla uno a uno.
Sintaxis vs. Semántica: Una Distinción Vital
Hasta este punto del curso hemos analizado la función print() desde el punto de vista de la sintaxis, pero para ser un programador profesional, debes entender la diferencia entre dos conceptos lingüísticos fundamentales:
Concepto
¿Qué significa en programación?
Ejemplo en nuestro código
Sintaxis
Las reglas gramaticales y de estructura. Cómo se escribe correctamente el código para que el intérprete lo acepte.
Saber que print lleva paréntesis () y que el texto debe ir entre comillas " ".
Semántica
El significado real, el propósito y el efecto que produce ese código al ejecutarse.
Entender que invocar esa instrucción provocará que un mensaje aparezca en la terminal del usuario.
Un código puede ser sintácticamente perfecto (no tener errores de escritura) pero carecer de sentido semántico (hacer algo completamente diferente a lo que el programador planeaba). Dominar ambos lados es lo que te permitirá escribir software robusto y sin errores.
Aquí tienes la adaptación de esta sección fundamental, donde se explica paso a paso el mecanismo interno de una invocación de función. He estructurado el contenido de manera muy visual y secuencial para facilitar el aprendizaje y la preparación del PCEP.
¿Qué ocurre cuando ejecutamos una función?
El conjunto formado por el nombre de la función, los paréntesis y los argumentos se conoce formalmente como invocación de función o llamada a una función (function invocation). Tomemos de nuevo nuestra línea de referencia:
print("Hello, World!")
Para comprender cómo procesa Python esta instrucción, analicemos el modelo abstracto de cualquier llamada a una función:
Cuando el intérprete se topa con una estructura como esta, detiene el flujo lineal de tu script e inicia un proceso interno sumamente estricto que consta de 5 etapas consecutivas:
1. Validación del Nombre (Control de Legalidad)
Python examina el nombre de la función que intentas usar. El intérprete busca en sus datos internos si existe una función registrada con ese nombre exacto (ya sea integrada, de un módulo importado o definida por ti).
Punto de quiebre: Si la búsqueda falla (por ejemplo, si escribiste prnt), Python aborta el programa inmediatamente y arroja un error (NameError).
2. Verificación de los Argumentos (Control de Requisitos)
Python comprueba si el número de argumentos que has colocado dentro de los paréntesis coincide con lo que la función exige para trabajar.
Punto de quiebre: Si una función específica exige exactamente dos argumentos y tú solo le proporcionas uno, el intérprete considerará que la invocación es errónea, detendrá la ejecución del código y lanzará un error (TypeError).
3. El Salto al Código de la Función
Si el nombre es legal y los argumentos son correctos, Python hace una pausa en tu script. El intérprete “abandona” temporalmente tu línea de código y da un salto hacia el lugar de la memoria donde están almacenadas las instrucciones internas de la función invocada, llevando consigo los argumentos que le pasaste.
4. Ejecución y Efecto
Una vez dentro de la función, esta toma los argumentos, ejecuta su propio código interno, provoca el efecto secundario diseñado (en el caso de print(), enviar los caracteres a la terminal), calcula los resultados necesarios y finaliza su tarea.
5. El Retorno al Flujo Principal
Finalmente, una vez que la función ha terminado de procesar todo, Python realiza un salto de regreso a tu código fuente, exactamente al punto que se encuentra justo después de la invocación, y reanuda la ejecución normal del script.
Resumen para el Desarrollador
Este ciclo de “pausa, salto, ejecución y retorno” ocurre en milisegundos cada vez que llamas a una función en Python. Comprender este mecanismo te permitirá prever el comportamiento de tu software y entender con precisión los flujos de trabajo con datos estructurados y automatizaciones.
Aquí tienes la adaptación de esta sección, enfocada en uno de los conceptos más importantes de la manipulación de texto en Python: los caracteres de escape y el salto de línea. Lo he estructurado con un enfoque didáctico y limpio para tus apuntes o artículos.
Caracteres de Escape y Salto de Línea
Si modificamos nuestro código e introducimos un par de caracteres extraños dentro de una cadena de texto, podemos cambiar por completo la forma en que se muestra la información. Observa con atención el siguiente patrón: \n.
A nivel visual, tú puedes ver claramente dos caracteres distintos (una barra invertida y una letra “n”). Sin embargo, para Python, esto representa un solo carácter especial.
El rol de la barra invertida (\) como carácter de escape
La barra invertida o backslash (\) tiene un significado sumamente especial cuando se utiliza dentro de las cadenas de texto (strings): se le conoce como el carácter de escape (escape character).
El término “escape” debe entenderse de una manera muy específica en programación: significa que la secuencia de caracteres del texto “escapa” por un breve momento de su comportamiento habitual para introducir una función o instrucción especial.
En otras palabras:
La barra invertida no significa nada por sí misma ni se mostrará en la pantalla de forma directa.
Funciona como un anuncio o advertencia para el intérprete, indicándole que el carácter que viene inmediatamente después de ella cambia por completo su significado ordinario.
El Símbolo \n (Newline)
La letra n colocada justo después de la barra invertida proviene de la palabra inglesa newline (nueva línea). Juntos, la barra invertida y la “n” (\n) forman un símbolo único y especial llamado carácter de salto de línea. Cuando el intérprete de Python envía el texto a la consola y tropieza con este símbolo, no imprime las letras \ ni n; en su lugar, le ordena firmemente a la consola que rompa la línea actual y comience una nueva línea de salida.
Aquí tienes la adaptación de esta sección, donde se introduce el concepto técnico fundamental de los argumentos posicionales, un pilar indispensable para el examen PCEP.
Aquí tienes la adaptación de esta sección, enfocada en cómo gestiona la función print() la recepción de múltiples argumentos y el comportamiento automático que añade entre ellos.
La Función print() con Múltiples Argumentos
Hasta este punto del curso, hemos analizado cómo se comporta la función print() cuando no recibe argumentos o cuando recibe un único argumento. Ahora es momento de explorar una de sus capacidades más útiles: procesar más de un argumento a la vez.
print("The itsy bitsy spider", "climbed up", "the waterspout.")
El Rol de la Coma
Para pasar más de un argumento a cualquier función en Python, debemos utilizar commas (,) como separadores. La función print() inserta un espacio en blanco entre los argumentos por iniciativa propia de forma predeterminada. Actúa como un separador automático para que los datos no se muestren pegados.
La Función print() y los argumentos posicionales
Antes de ejecutar cualquier código en tu editor, un buen programador debe ser capaz de predecir el resultado analizando la estructura de la instrucción.
¿Qué significa el “Enfoque Posicional”?
La manera en la que hemos estado pasando los argumentos dentro de la función print() es la más común y utilizada en el universo de Python. Técnicamente se le conoce como el enfoque posicional (positional way).
Este nombre proviene de un hecho lógico: el significado y el orden de aparición de un argumento están determinados estrictamente por la posición física que ocupa dentro de los paréntesis.
Por lo tanto, bajo este modelo:
El primer argumento de la izquierda será el primero en procesarse y mostrarse en la consola.
El segundo argumento se imprimirá inmediatamente después del primero.
El tercer argumento irá al final, y así sucesivamente.
Python jamás alterará este orden de forma autónoma; respeta fielmente la secuencia posicional que tú hayas escrito de izquierda a derecha.
Aquí tienes la adaptación de esta sección, donde se introduce el concepto técnico de los argumentos de palabra clave (keyword arguments), una de las herramientas más potentes para personalizar el comportamiento de print() y un tema clave para el examen PCEP.
Keywords: modificando el comportamiento de print()
Python ofrece otro mecanismo muy útil cuando queremos convencer a una función de que altere sus costumbres nativas: los argumentos de palabra clave (keyword arguments).
A diferencia de los posicionales, el significado de estos argumentos no depende de la posición en la que los escribas, sino de una palabra especial (clave) que los identifica unívocamente.
La función print() cuenta con dos argumentos de palabra clave fundamentales. En esta sección nos enfocaremos en el primero de ellos: end.
Reglas de Sintaxis para los Keyword Arguments
Para utilizar correctamente un argumento de palabra clave, es obligatorio seguir una estructura estricta de tres elementos:
[ Palabra clave ] ──> [ Signo igual (=) ] ──> [ Valor asignado ]
Además, existe una regla de oro en la sintaxis de Python que jamás debes romper:
⚠️ Regla Crítica (PCEP): Todos los argumentos de palabra clave deben colocarse obligatoriamente después del último argumento posicional. Si intentas poner un keyword argument antes de un argumento común, Python abortará la ejecución y arroja un error de sintaxis.
El Argumento end: Controlando el Final de la Línea
Por defecto, cada vez que la función print() termina de mostrar sus argumentos, salta automáticamente al siguiente renglón. Esto ocurre porque, “tras bambalinas”, Python aplica un valor predeterminado equivalente a escribir: end="\n" (un salto de línea).
Sin embargo, tú puedes modificar este carácter de finalización. Imagina que ejecutas el siguiente código en tu editor:
print("My name is", end=" ")print("Python.")
¿Qué ocurre aquí?
Al configurar end=" " (un string con un solo espacio en blanco), le estás ordenando a la función print() que, cuando termine de procesar el texto "My name is", no realice un salto de línea, sino que coloque un espacio y mantenga el cursor en la misma fila.
Cuando se ejecuta la segunda línea (print("Python.")), el texto se imprime inmediatamente a continuación. Por lo tanto, el resultado unificado en la consola será:
My name is Python.
Aquí tienes la siguiente sección del curso, enfocada en el segundo argumento de palabra clave fundamental de la función print(): sep (el separador). Está adaptada con un tono educativo, profesional y estructurada metódicamente para tus apuntes o artículos.
El Argumento de Palabra Clave sep: Personalizando los Espacios
El argumento de palabra clave sep sirve para modificar el comportamiento de print al añadir espacios entre argumentos. Al igual que end, el argumento sep debe respetar la regla de oro: colocarse estrictamente al final de la instrucción, después de todos tus argumentos posicionales.
Su estructura es la misma: sep="valor". El valor que pongas entre las comillas sustituirá al espacio en blanco automático que Python introduce entre argumento y argumento.
Las computadoras no entienden los lenguajes de programación de alto nivel; solo procesan código binario (ceros y unos). Para transformar nuestras instrucciones en algo que el procesador pueda ejecutar, existen dos estrategias fundamentales: la compilación y la interpretación.
A continuación, analizaremos a fondo ambos enfoques, cómo funciona el ciclo de vida de un programa interpretado y qué implicaciones tiene esto al programar en Python.
El Enfoque de la Compilación
En los lenguajes compilados (como C, C++ o Go), el código fuente se traduce por completo una sola vez antes de que el programa pueda ejecutarse. El software encargado de realizar este proceso se denomina compilador.
El Resultado: El compilador genera un archivo binario independiente y cerrado (por ejemplo, un archivo .exe en Windows).
Ventajas:
Mayor velocidad: La ejecución es directa y extremadamente rápida porque la traducción ya se hizo de antemano.
Distribución independiente: Puedes enviar el archivo ejecutable final a cualquier usuario sin necesidad de compartir tu código fuente original ni obligarlo a instalar herramientas adicionales.
Protección intelectual: Al estar almacenado en lenguaje máquina, es muy difícil de comprender o revertir, protegiendo tus algoritmos y trucos de programación.
Desventajas:
Desarrollo más lento: El proceso de traducción es rígido. Cualquier modificación en el código fuente, por mínima que sea, te obliga a compilar todo el proyecto de nuevo para ver los cambios.
Dependencia del hardware: El archivo generado está limitado a una arquitectura específica. Necesitas tantos compiladores como plataformas de hardware quieras soportar.
El Enfoque de la Interpretación
En este esquema —bajo el cual opera Python— no se genera un archivo ejecutable previo. El código fuente se distribuye tal cual y se traduce de forma dinámica en cada sesión de ejecución mediante un programa llamado intérprete.
El Intérprete en Acción: Su función es leer, verificar y ejecutar el código línea por línea, de arriba hacia abajo y “al vuelo”, justo en el momento en que se corre el programa.
Ventajas:
Inmediación y flexibilidad: Puedes probar el código de forma instantánea tan pronto como terminas de escribirlo, lo que agiliza las correcciones y experimentos.
Portabilidad multiplataforma: Como el código se almacena en el lenguaje original, puede ejecutarse en diferentes arquitecturas de computadora sin necesidad de adaptarlo o compilarlo por separado.
Desventajas:
Menor rendimiento: El código comparte la potencia de procesamiento de la computadora con el propio intérprete en tiempo real, lo que reduce la velocidad general.
Dependencia del entorno: No puedes enviar un ejecutable aislado. Para que el programa funcione, el usuario final debe tener instalado el intérprete correspondiente en su máquina.
El Ciclo de Vida de la Ejecución en Lenguajes Interpretados
Para escribir scripts estables y entender cómo se procesan tus flujos de trabajo, es vital comprender qué ocurre “tras bambalinas” cuando ejecutas un archivo de texto plano con tu código fuente.
El intérprete sigue un patrón de lectura estándar (de arriba hacia abajo y de izquierda a derecha). Aunque ciertas estructuras como las funciones o los bucles pueden alterar este orden, el flujo inicial siempre es lineal y se basa en un ciclo continuo de tres pasos por cada línea:
[ Leer ] ──> [ Verificar ] ──> [ Ejecutar ]
Paso 1: Lectura y Análisis
El intérprete toma la línea de código correspondiente para procesar sus componentes.
Paso 2: Verificación y Manejo de Errores (Tiempo de Ejecución)
Antes de realizar cualquier acción, el intérprete comprueba si la línea es sintácticamente correcta bajo reglas muy estrictas:
Parada Inmediata: Si encuentra un fallo, detiene su trabajo por completo en ese preciso instante. El programa aborta y muestra un mensaje en la consola.
Diagnóstico Limitado: El sistema te informará la línea y la causa estimada del fallo. Sin embargo, como el intérprete no conoce tu intención original, el mensaje puede ser engañoso e identificar el error a cierta distancia de la causa real.
Paso 3: Ejecución y el Fenómeno del “Éxito Parcial”
Si la línea no presenta anomalías, el intérprete la ejecuta. Debido a que cada línea se procesa de forma aislada, el ciclo puede repetirse miles de veces en secciones específicas (como un bucle que procesa filas de un dataset).
Este comportamiento produce una consecuencia directa: el éxito parcial. Es perfectamente normal que una parte significativa de tu programa corra correctamente, realice cálculos e incluso guarde datos en el disco antes de tropezar con un error en las líneas finales y detenerse por completo.
Comparativa Directa
Característica
Compilación
Interpretación
Momento de traducción
Antes de la ejecución (todo el bloque).
Durante la ejecución (línea por línea).
Velocidad de ejecución
Alta.
Moderada / Baja.
Portabilidad del código
Limitada a la arquitectura compilada.
Alta (multiplataforma).
Requisito del usuario
Solo el archivo ejecutable.
Requiere el intérprete instalado.
Flujo ante errores
No genera el ejecutable si hay errores.
Ejecuta el código previo al error (Éxito parcial).
Entendiendo la Consola de Errores (Traceback)
Cuando cometes un error en un entorno como IDLE, la ventana del editor no te dirá mucho, pero la consola (Shell) se teñirá de letras rojas. Esas líneas de texto son tu mapa para solucionar el problema.
Un mensaje de error estándar en Python se compone de las siguientes partes (leídas de arriba hacia abajo):
El Traceback (Rastreo): Es la ruta que siguió el intérprete a través de las diferentes partes del programa antes de fallar. En scripts simples de una sola línea estará vacío, pero en programas complejos te dice exactamente qué función llamó a qué otra función.
La Ubicación del Error: Te indica el nombre del archivo, el número de línea y el módulo donde ocurrió el fallo.⚠️ ¡Cuidado! El número de línea puede ser engañoso. Python muestra el lugar donde notó por primera vez el efecto del error, que no siempre es el lugar exacto donde lo cometiste (por ejemplo, un paréntesis abierto unas líneas más arriba).
El Contenido de la Línea: El intérprete te muestra un duplicado exacto de la línea de código que causó el colapso para que puedas examinarla visualmente.
El Nombre del Error y la Explicación: La última línea es la más crucial. Te da el diagnóstico técnico (por ejemplo, SyntaxError, NameError) seguido de una breve explicación en inglés de lo que salió mal.
Una metodología es un sistema de métodos y directrices que guía las decisiones del investigador a lo largo de todo el proceso científico. En nuestro campo, constituye un marco de trabajo estructurado que orienta a los científicos de datos y a los ingenieros de Machine Learning en la resolución de problemas complejos y en la toma de decisiones informadas.
Definición Clave: Una metodología robusta no se limita al modelado algorítmico. Abarca el diseño de formularios de recolección de datos, el establecimiento de estrategias de medición y la comparación crítica de métodos analíticos en función de los objetivos específicos del negocio y el contexto del proyecto.
Las 10 Etapas de la Metodología de John Rollins
Un estándar ampliamente adoptado en la industria es el marco conceptual desarrollado por John Rollins, científico de datos sénior de IBM, cuya experiencia profesional consolidó una estructura de 10 etapas secuenciales e iterativas:
Las preguntas son la piedra angular de cualquier proyecto de datos y el motor que impulsa cada una de las 10 etapas descritas. Para garantizar la viabilidad y el rigor de un diseño analítico, la metodología nos obliga a responder a diez preguntas esenciales, agrupadas en tres bloques críticos de ejecución:
Bloque Temático
Etapa Metodológica
Pregunta Clave a Responder
Definición y Enfoque
1. Business Understanding
¿Cuál es el problema específico que se intenta resolver?
2. Analytic Approach
¿Cómo se pueden utilizar los datos para responder a dicha pregunta?
Organización de Datos
3. Data Requirements
¿Qué datos se necesitan para responder a la pregunta?
4. Data Collection
¿De dónde provienen y cómo se recibirán las fuentes de datos?
5. Data Understanding
¿Los datos recolectados representan fielmente el problema a resolver?
6. Data Preparation
¿Qué manipulación y preprocesamiento adicional requieren los datos?
Validación y Diseño Final
7. Modeling
Al aplicar visualizaciones de datos, ¿se observan patrones que atiendan el problema?
8. Evaluation
¿El modelo responde a la pregunta de negocio original o se deben ajustar los datos?
9. Deployment
¿Cómo se puede poner en práctica y producción el modelo desarrollado?
10. Feedback
¿Cómo se obtendrá retroalimentación de los interesados y del modelo para mejorar el proceso?
Al implementar de manera sistemática este checklist analítico, los equipos de Data Science no solo optimizan el tiempo de desarrollo y la eficiencia de la investigación científica, sino que aseguran una alineación perfecta entre el desarrollo técnico de Machine Learning y los objetivos estratégicos de la organización.
En el entorno corporativo e industrial, el éxito de un proyecto de Inteligencia Artificial o Ciencia de Datos no radica únicamente en la sofisticación de los algoritmos utilizados, sino en la rigurosidad del proceso metodológico seguido. Dos de las fases más críticas en metodologías estándar de la industria (como CRISP-DM) son el establecimiento de una sólida Comprensión del Negocio (Business Understanding) y la correcta selección del Enfoque Analítico (Analytic Approach).
1. Comprensión del Negocio (Business Understanding)
El punto de partida de cualquier metodología de ciencia de datos seria consiste en dedicar el tiempo necesario a buscar aclaraciones y alinear expectativas. Avanzar a ciegas bajo la presión de plazos ajustados sin definir el problema real suele derivar en soluciones técnicamente válidas pero comercialmente inútiles.
Establecer Objetivos y Metas Claros
El proceso comienza por descifrar el propósito de quien formula la pregunta de negocio. Por ejemplo, ante una solicitud común como “¿Cómo podemos reducir los costos de una actividad?”, el científico de datos debe profundizar en si el fin último es mejorar la eficiencia operativa o potenciar la rentabilidad general de la empresa.
Identificación de Requisitos: Consiste en desglosar las metas generales en objetivos específicos medibles.
Priorización Estratégica: Organizar las discusiones estructuradas con los stakeholders clave permite identificar qué subproblemas abordar primero en función de su viabilidad e impacto.
Caso de Estudio: Reducción de Readmisiones Hospitalarias
Para ilustrar la importancia de esta fase, analicemos el caso de una aseguradora de salud que enfrentaba una reducción en el financiamiento público para readmisiones, lo que amenazaba con elevar las primas de sus clientes.
Antes de recolectar un solo dato, el equipo (en colaboración con autoridades sanitarias y científicos de datos) definió los objetivos del proyecto. Al analizar el contexto, identificaron que el 30% de los pacientes que terminaban rehabilitación volvían a ser ingresados en un año, y el 50% en un plazo de cinco años. Tras revisar los registros, se priorizó a los pacientes con Insuficiencia Cardíaca Congestiva (CHF), situados en la cima de la lista de readmisiones.
Formulación y Pertinencia de Preguntas
Una vez que se comprende el negocio, el científico de datos debe formular preguntas analíticas pertinentes. No todos los datos disponibles o preguntas que surgen en una organización aportan valor a la meta trazada.
Ejemplo en Estrategia de Precios de Comercio Electrónico
Si el objetivo principal de un e-commerce es optimizar su estrategia de precios para maximizar ingresos y rentabilidad, la clasificación de preguntas se divide de la siguiente manera:
Preguntas Altamente Relevantes
Preguntas No Relevantes para el Objetivo
¿Cómo varían los comportamientos de compra de los clientes durante períodos promocionales específicos?
¿Cuántos empleados trabajan en el departamento de marketing?
¿Cuáles son los márgenes de ganancia de los diferentes productos?
¿Cuál es la estructura organizacional de la empresa?
¿De qué manera influyen las opiniones y calificaciones de los productos en las decisiones de compra?
¿Cuánto gasta la empresa en suministros de oficina?
¿Cómo influyen los datos demográficos de los clientes en su sensibilidad al precio?
—
2. El Enfoque Analítico (Analytic Approach)
Una vez consolidada la pregunta de investigación, se procede a seleccionar el Enfoque Analítico adecuado. Esto significa identificar qué tipo de patrones de datos se requieren extraer para responder a la interrogante de la manera más efectiva posible.
Tomando como base las necesidades de optimización de una empresa de transporte y logística, los enfoques se categorizan en cuatro grandes modelos de patrones de datos:
Modelo Predictivo (Predictive Model)
Se utiliza cuando la pregunta requiere determinar las probabilidades de una acción futura basándose en datos históricos.
Preguntas tipo: ¿Cómo podemos pronosticar el número óptimo de vehículos de entrega necesarios para un día específico según el volumen de pedidos esperado? o ¿Cuál es el tiempo estimado de entrega considerando patrones de tráfico y condiciones climáticas?
Modelo Descriptivo (Descriptive Model)
Se aplica cuando el objetivo es mostrar relaciones, resumir comportamientos existentes o identificar tendencias históricas sin realizar predicciones directas.
Preguntas tipo: ¿Cuáles son los costos promedio de envío para diferentes rutas y cómo varían según la hora del día? o ¿Cuáles son los intervalos de tiempo y los días de mayor actividad semanal basándose en pedidos pasados?
Modelo de Clasificación (Classification Model)
Adecuado para problemas que requieren categorizar elementos o donde la respuesta analítica es de naturaleza categórica (por ejemplo, respuestas de tipo Sí/No).
Preguntas tipo: ¿Cómo podemos clasificar las rutas de entrega en diferentes categorías según el volumen de pedidos y la duración promedio? o ¿En qué franjas horarias específicas se deben segmentar los cronogramas para equilibrar la carga laboral?
Agrupamiento (Clustering / Grouping-based)
Un enfoque de Machine Learning no supervisado utilizado para descubrir la estructura intrínseca de los datos y conocer el comportamiento de entidades sin realizar predicciones explícitas de eventos pasados.
Preguntas tipo: ¿Cómo podemos agrupar las regiones de entrega en función de la densidad de clientes y la frecuencia de pedidos para optimizar la planificación de rutas?
Aplicación Técnica del Enfoque: El Modelo de Árbol de Decisión
Retomando el caso de estudio de readmisiones por Insuficiencia Cardíaca Congestiva (CHF), los científicos de datos seleccionaron un Modelo de Clasificación basado en Árboles de Decisión. Esta elección técnica se fundamenta directamente en los requisitos de negocio previamente establecidos:
Mecánica del Modelo y Toma de Decisiones
Evaluación por Nodos y Umbrales: El algoritmo examina las variables en cada uno de los nodos a lo largo de las rutas hasta llegar a una “hoja” (leaf), determinando valores umbral específicos para segmentar a los pacientes.
Cálculo del Riesgo de Readmisión: El modelo proporciona el resultado condicional (Sí/No reingresa) y la probabilidad del mismo basándose en la proporción del resultado dominante en cada grupo:
Si el resultado dominante en la hoja es Sí, el riesgo equivale directamente a la proporción de pacientes “Sí” en esa hoja.
Si el resultado dominante es No, el riesgo se calcula matemáticamente como $1 – \text{proporción de pacientes No en la hoja}$.
Ventajas de cara al Negocio y la Práctica Clínica
La elección de este enfoque analítico específico responde a una justificación metodológica clave: la interpretabilidad. Un modelo de árbol de clasificación es altamente intuitivo para profesionales que no pertenecen al ámbito de los datos (como los médicos y gestores clínicos). Los médicos pueden observar con precisión qué combinaciones de condiciones biológicas o de tratamiento provocan que un paciente sea catalogado como de “alto riesgo”.
3. La Fase de Requisitos (Data Requirements)
Una vez que se ha definido el problema de negocio y se ha seleccionado el enfoque analítico pertinente, el científico de datos entra en una de las fases más operativas e interconectadas del ciclo de vida del proyecto: la determinación de los requisitos de datos.
Para entender esta etapa, resulta útil recurrir a una analogía gastronómica : si el problema que queremos resolver equivale a la receta culinaria, los datos son los ingredientes indispensables para elaborarla. Si el objetivo es preparar una cena de espaguetis pero no se cuenta con los componentes adecuados, el éxito del plato se verá comprometido. Bajo este principio de “cocinar con datos”, el equipo técnico debe identificar con precisión qué ingredientes se necesitan, cómo recolectarlos, cómo interpretarlos y de qué manera prepararlos para alcanzar el resultado esperado.
Definición de Requisitos Analíticos
Antes de proceder a la recolección o manipulación directa de la información, es vital delimitar los requisitos analíticos específicos que exige la técnica de modelado elegida. Esto implica determinar de forma explícita:
El contenido: Qué sustancia o variables debe albergar la información.
El formato: La estructura técnica en la que deben presentarse los datos.
Las fuentes: Los orígenes y sistemas de donde se extraerá la información inicial.
La Importancia de la Prospección: Un buen científico de datos debe pensar a futuro. Definir correctamente los requisitos en esta fase previene errores costosos y facilita las fases posteriores de preparación y modelado de datos.
Caso de Estudio: Clasificación con Árboles de Decisión en el Sector Salud
Para ilustrar cómo se aplican los requisitos de datos en un entorno real, analicemos el diseño metodológico implementado para un modelo de clasificación basado en árboles de decisión dentro del sector de los seguros médicos, cuyo objetivo era modelar y predecir la tasa de readmisión de pacientes.
Selección y Criterios de Inclusión de la Cohorte
El primer paso consistió en acotar el universo de datos seleccionando una cohorte de pacientes adecuada a partir de la base de miembros de la aseguradora. Para garantizar que se pudiera consolidar un historial clínico completo, se definieron tres criterios de inclusión estrictos:
Área de Cobertura: El paciente debía haber sido ingresado como paciente interno dentro del área de servicio del proveedor para asegurar el acceso a toda la información médica relevante.
Diagnóstico Principal: Se acotó la búsqueda exclusivamente a pacientes con un diagnóstico primario de insuficiencia cardíaca congestiva durante el periodo de un año completo.
Permanencia Mínima: El paciente debía registrar una inscripción continua de al menos seis meses previa a su admisión hospitalaria por insuficiencia cardíaca, permitiendo así compilar un antecedente médico fidedigno.
Criterios de Exclusión Estratégica
Con el fin de no sesgar los resultados del modelo, se excluyó deliberadamente de la cohorte a aquellos pacientes con insuficiencia cardíaca que además presentaran otras condiciones médicas preexistentes de alta gravedad. Estas comorbilidades suelen provocar tasas de readmisión inusualmente elevadas que no se corresponden con el comportamiento estándar del problema principal, lo que alteraría el rendimiento del algoritmo.
Formato y Estructura Técnica del Modelo
El algoritmo de árboles de decisión impone restricciones muy claras en cuanto a la estructura de la matriz de entrada. Requiere estrictamente un único registro por paciente, donde las columnas representen de forma tabular las variables que evaluará el modelo.
Sin embargo, la realidad de los datos clínicos de un solo individuo es transaccional y masiva, abarcando:
Historiales de admisiones y altas hospitalarias.
Diagnósticos primarios, secundarios y terciarios.
Procedimientos médicos realizados.
Prescripciones farmacológicas y recetas emitidas.
Servicios derivados de consultas externas e interconsultas.
Debido a esta naturaleza médica, un único paciente puede acumular miles de registros transaccionales en los sistemas de salud. Para transformar esta estructura masiva y profunda al formato plano exigido por el modelo (un registro por fila), los científicos de datos planificaron la agregación o “roll-up” de dichos datos transaccionales al nivel de paciente, lo que conlleva la creación de nuevas variables sintéticas que resuman el comportamiento histórico del individuo.
Aunque la ejecución de esta transformación corresponde propiamente a la fase de Preparación de Datos, anticipar y mapear esta necesidad desde la etapa de Requisitos de Datos es lo que garantiza la viabilidad técnica de todo el proyecto de Machine Learning.
4. La Fase de Recolección (Data Collection)
Tras definir las especificaciones técnicas en la etapa de requisitos, la metodología avanza hacia un paso intensamente práctico y operativo: la Recolección de Datos. Esta fase no se limita a un mero proceso de descarga o acumulación de archivos; representa un punto de control crítico donde el científico de datos evalúa de manera empírica la viabilidad técnica del diseño inicial.
Siguiendo con nuestra analogía culinaria, si en la etapa anterior elaboramos la lista de compras, en esta fase acudimos al mercado a buscar los ingredientes. Es común descubrir que algunos de ellos están fuera de temporada, son difíciles de conseguir o implican un coste computacional y operativo mayor de lo previsto. Ante esta realidad, el equipo se ve obligado a revisar los requisitos teóricos y tomar decisiones estratégicas sobre si es necesario recolectar un volumen mayor o menor de información.
Al finalizar la recolección, los “ingredientes” se encuentran listos sobre la mesa de trabajo. En este punto, el profesional obtiene una perspectiva clara del material real con el que construirá la solución.
Evaluación Inicial y Detección de Gaps
Una vez completada la carga inicial, el científico de datos debe aplicar técnicas analíticas preliminares para auditar el set de datos:
Estadística Descriptiva: Permite evaluar el contenido general, las distribuciones de las variables y la calidad superficial de la información.
Visualización de Datos: Ayuda a identificar anomalías visuales directas y a extraer los primeros insights o intuiciones sobre el comportamiento de las variables.
Identificación de Brechas (Gaps): El objetivo principal de esta auditoría es descubrir vacíos en la información. Cuando se detectan datos faltantes, el equipo debe trazar planes específicos para rellenar esos vacíos o, en su defecto, buscar variables sustitutas adecuadas.
Caso de Estudio: Desafíos de Integración en el Sector Salud
Retomando el modelo de clasificación para predecir la readmisión de pacientes con insuficiencia cardíaca congestiva, la fase de recolección evidenció la complejidad de los entornos de datos corporativos.
Para nutrir el árbol de decisión, fue necesario localizar y extraer elementos provenientes de múltiples sistemas de información:
Datos demográficos, clínicos y de cobertura de las pólizas de los pacientes.
Información detallada de los proveedores de salud.
Registros históricos de reclamaciones (claims) y facturación médica.
Historiales farmacéuticos y diagnósticos asociados a la patología principal.
Gestión de Datos No Disponibles y Decisiones Diferidas
Durante el proceso surgió un obstáculo habitual: la información farmacéutica de ciertos medicamentos específicos no estaba integrada con el resto de las fuentes de datos de la organización.
Frente a un escenario de datos incompletos o de difícil acceso, la metodología de John Rollins aporta una directriz fundamental: es perfectamente válido posponer las decisiones sobre datos no disponibles y avanzar con lo que se tiene. No es estrictamente necesario detener el proyecto; se puede intentar adquirir esa información ausente en una etapa posterior, por ejemplo, tras evaluar los resultados intermedios del modelado predictivo.
Si las primeras métricas del modelo sugieren que la variable ausente (en este caso, el historial de medicamentos) es crítica para lograr la precisión deseada, se justifica invertir el tiempo y los recursos necesarios para extraerla. En este caso de estudio real, el equipo continuó el desarrollo y descubrió que era posible construir un modelo predictivo con un rendimiento óptimo prescindiendo de dicha información farmacéutica.
Colaboración de Ingeniería y Automatización de Procesos
La recolección de datos efectiva es una tarea multidisciplinar. Los administradores de bases de datos (DBAs) y los programadores trabajan en estrecha colaboración para diseñar las consultas de extracción y fusionar los flujos de datos procedentes de los distintos silos de la empresa. Esta consolidación técnica persigue dos grandes objetivos:
Eliminar la redundancia: Limpiar registros duplicados o contradictorios antes de dar paso a la siguiente etapa de la metodología: la comprensión profunda de los datos (Data Understanding).
Optimizar el ciclo de vida: Durante esta fase, el equipo analítico debate y define mejores prácticas de gobernanza e infraestructura, lo que incluye la automatización de procesos dentro de la propia base de datos. Automatizar la ingesta garantiza que las futuras recolecciones de datos sean operaciones más rápidas, eficientes y menos propensas a errores manuales.
5. Comprensión de los Datos (Data Understanding)
Una vez recolectados los primeros flujos de información, la metodología pasa de la mera acumulación a un proceso de auditoría y análisis crítico: la Comprensión de los Datos. Esta fase abarca todas las actividades analíticas orientadas a evaluar de forma rigurosa el set de datos que se acaba de construir.
En esencia, este bloque metodológico busca responder a una pregunta fundamental e imperativa para la viabilidad del proyecto: ¿Son los datos recolectados verdaderamente representativos del problema que se intenta resolver?
Herramientas de Auditoría Analítica y Calidad de Datos
Para alcanzar un entendimiento profundo y asegurar la calidad del set de datos, el equipo de Data Science debe someter a las columnas que se convertirán en las variables predictoras del modelo a tres tipos de análisis estadísticos:
Estadísticas Univariadas Básicas: Consiste en calcular de forma individual para cada variable métricas clave como la media, mediana, valores mínimos, máximos y la desviación estándar.
Correlaciones Cruzadas (Pairwise Correlations): Se utilizan para evaluar el grado de relación lineal entre pares de variables. Esto permite identificar variables altamente correlacionadas que resultarían redundantes para el algoritmo, facilitando la decisión de conservar únicamente una de ellas para el modelado.
Análisis de Histogramas: Examinar la distribución visual de las variables ayuda a proyectar qué transformaciones o estrategias de preparación serán necesarias más adelante para optimizar el rendimiento del modelo.
Ejemplo de Consolidación: Si un histograma revela que una variable categórica posee demasiados valores distintos y dispersos como para ser informativa, la distribución visual servirá de guía para decidir cómo agrupar y consolidar metodológicamente dichas categorías.
Desentrañando el Significado de los Datos y Anomalías
El uso combinado de estadísticas univariadas e histogramas es la herramienta principal para diagnosticar problemas de calidad y tomar decisiones de recodificación o descarte. Un reto recurrente en esta fase es la interpretación semántica de las anomalías:
El dilema de los valores faltantes (Missing Values): Cuando se detecta la ausencia de un dato, el científico de datos debe determinar si ese vacío encierra un significado latente. En ocasiones, un valor faltante equivale implícitamente a un “No” o a un “0”; en otras, representa simplemente un desconocimiento absoluto del dato.
Valores engañosos o codificados: Es común encontrar variables numéricas con registros que alteran las métricas tradicionales si no se corrigen. Por ejemplo, una columna destinada a la “Edad” puede contener valores lógicos entre 0 y 100 años, pero incluir también registros con el número 999. En la gobernanza de ciertos sistemas tradicionales, ese “999” funciona como un código para denotar un dato faltante, pero un algoritmo lo procesará como una edad válida y real a menos que el equipo técnico lo identifique y lo corrija a tiempo.
La Naturaleza Iterativa de la Metodología
La fase de comprensión de datos suele desafiar las definiciones teóricas iniciales del proyecto. En el caso de estudio analizado, la métrica de éxito original para definir un ingreso por insuficiencia cardíaca congestiva se basó estrictamente en los pacientes que presentaban dicha condición como su diagnóstico principal.
Sin embargo, al ejecutar la auditoría de los datos, el equipo analítico constató que este criterio inicial no lograba capturar el volumen total de ingresos hospitalarios que la experiencia clínica y médica real estimaba.
Este hallazgo obligó a los científicos de datos a ejecutar un bucle de retroalimentación (loop) hacia la etapa anterior de Recolección de Datos con el fin de extraer también los registros de diagnósticos secundarios y terciarios, construyendo así una definición técnica mucho más robusta, fidedigna y exhaustiva de la patología.
Este comportamiento ejemplifica la esencia interactiva de la metodología de John Rollins: cuanto más se interactúa con el problema y los datos reales, más se aprende sobre el ecosistema del negocio. Este aprendizaje continuo permite refinar progresivamente el diseño del modelo, asegurando en última instancia una solución analítica de mayor calidad y precisión.
6. La Fase de Preparación (Data Preparation)
Tras completar la auditoría y validación de la información en la etapa de comprensión, la metodología avanza hacia la fase que mayor esfuerzo operativo demanda: la Preparación de los Datos. En el ciclo de vida de un proyecto analítico, esta etapa, junto con la recolección y la comprensión, representa la fase más costosa en términos de tiempo, llegando a absorber de manera habitual entre el 70% y el 90% del esfuerzo total del proyecto.
Para ilustrar este proceso, podemos recurrir nuevamente a una analogía culinaria : la preparación de los datos equivale a lavar y cortar vegetales recién cosechados. Al igual que eliminamos la tierra, las imperfecciones y las partes no comestibles antes de cocinar, el científico de datos debe purificar los sets de información eliminando duplicados, corrigiendo valores inválidos y dando el formato exacto requerido por el algoritmo.
Continuando con la analogía, picar una cebolla finamente permite que sus sabores se distribuyan de forma homogénea por toda la salsa, algo que no ocurriría si se arrojara la pieza entera a la olla. Del mismo modo, transformar y moldear las variables facilita de manera drástica el trabajo del algoritmo de Machine Learning. Una vía altamente efectiva para mitigar la enorme carga operativa de esta fase es la automatización de los procesos de limpieza e ingesta directamente dentro de la base de datos, lo que puede reducir el tiempo dedicado a estas tareas hasta en un 50%, permitiendo a los equipos enfocarse en lo que realmente aporta valor: el diseño y optimización de los modelos predictivos.
Conceptos Clave en la Preparación de Datos
Para transformar con éxito el set de datos crudos en una matriz apta para el modelado, se deben dominar tres pilares procedimentales:
Saneamiento del Set de Datos: Consiste en el tratamiento de valores faltantes o nulos, la detección y eliminación de registros duplicados y la corrección de anomalías técnicas identificadas previamente.
Feature Engineering (Ingeniería de Características): Es el proceso de aplicar el conocimiento del dominio de negocio para estructurar y combinar datos crudos en nuevas variables explicativas (denominadas features o características). Estas variables sintéticas actúan como indicadores que simplifican la detección de patrones por parte de los algoritmos de Machine Learning.
Análisis de Texto y Datos No Estructurados: Es una práctica fundamental para asegurar que las agrupaciones y categorizaciones lógicas de las variables de texto sean rigurosas, garantizando que el código de programación no pase por alto información relevante u oculta en los campos alfanuméricos.
Caso de Estudio: Preparación y Modelado para Insuficiencia Cardíaca
Retomando de forma práctica el modelo de clasificación basado en árboles de decisión para la aseguradora médica, la fase de preparación de datos ilustra a la perfección cómo se ejecutan estos conceptos teóricos en un entorno corporativo real:
Delimitación de Conceptos Clínicos y Criterios Médicos
El primer desafío metodológico consistió en definir con precisión matemática qué constituye una “insuficiencia cardíaca congestiva”. Aunque conceptualmente parece una tarea sencilla, desde la perspectiva de los datos no lo es: esta patología implica una acumulación específica de fluidos corporales y representa solo una variante dentro del amplio espectro de fallos cardíacos. Para asegurar la viabilidad del modelo, se requirió asesoramiento clínico experto con el fin de mapear y seleccionar con exactitud el conjunto de códigos de diagnóstico médico (Diagnosis-Related Group codes) correspondientes a esta condición específica.
Definición del Target y Temporalidad de Eventos
El siguiente paso fue estructurar la variable dependiente o target (el objetivo que el modelo debe predecir). Esto exigió analizar detalladamente la secuencia cronológica de los ingresos de cada paciente para diferenciar metodológicamente entre dos tipos de eventos:
Index Admission (Admisión de Referencia): El reingreso inicial u hospitalización base por insuficiencia cardíaca.
Readmission (Readmisión): Cualquier reingreso hospitalario subsiguiente relacionado con la misma patología.
Bajo la guía de expertos del sector salud, se fijó una ventana temporal estricta de 30 días tras el alta médica de la admisión de referencia para contabilizar un evento como una readmisión válida. La variable resultante fue un objetivo de clasificación binaria con dos únicos valores posibles: Sí o No.
Agregación Masiva de Datos Transaccionales (Roll-up)
El reto técnico más complejo de este caso radicaba en la discrepancia de formatos. El algoritmo de árboles de decisión exige estrictamente una estructura tabular de un único registro por paciente. Sin embargo, el historial médico real de los asegurados es de naturaleza transaccional : los sistemas acumulan cientos o miles de filas independientes por persona que detallan visitas al médico, análisis de laboratorio, reclamaciones de seguros (claims), servicios de urgencias, procedimientos quirúrgicos y recetas farmacéuticas.
Para resolver esta asimetría, los científicos de datos procedieron a agregar todo el historial transaccional al nivel de paciente, consolidando miles de filas en una sola línea maestra por individuo. Durante este proceso de agregación y a través de la ingeniería de características (feature engineering), se crearon decenas de variables sintéticas nuevas basadas en la frecuencia y la recencia, tales como:
El número total de visitas realizadas a médicos y clínicas especialistas.
La fecha de la hospitalización más reciente asociada a los diagnósticos analizados.
Indicadores consolidados de la historia clínica general (edad, género, tipo de cobertura de seguro).
El resultado final de esta fase fue una tabla unificada y saneada donde cada fila recopilaba los atributos analíticos de la historia clínica de un paciente único, dejando el set de datos completamente listo para nutrir la fase de Modelado.
¿Procedemos a redactar la siguiente sección del artículo orientada a las fases de Modelado y Evaluación (Modeling & Evaluation), o prefieres profundizar en los criterios matemáticos utilizados para la selección de variables predictoras?
7. La Fase de Modelado (Modeling)
Tras completar la extensa y demandante fase de preparación de datos, la metodología alcanza su núcleo algorítmico: el Modelado. Si las etapas previas se encargaron de asegurar, limpiar y estructurar los ingredientes, esta fase representa el momento exacto en el que el científico de datos “prueba la salsa” para determinar si el sabor es el correcto o si el plato requiere más condimento.
El modelado no es un proceso estático ni de un solo paso; es un pilar intensamente iterativo donde el profesional técnico calibra las matemáticas subyacentes para alinearlas con los objetivos del negocio antes de pasar a cualquier etapa de evaluación formal o despliegue en producción.
Conceptos Fundamentales del Modelado de Datos
El propósito principal del modelado es desarrollar estructuras matemáticas capaces de identificar y aprender patrones complejos dentro de los conjuntos de datos que han sido previamente preparados. Dependiendo de la naturaleza de la pregunta de negocio y del enfoque analítico seleccionado al inicio del proyecto, los modelos se dividen de forma general en dos grandes categorías:
Modelos Descriptivos: Se orientan a responder preguntas sobre relaciones existentes y dinámicas internas de los datos. Por ejemplo: “Si un cliente realiza determinada acción, ¿qué otros comportamientos asociados suele presentar?” o “¿Cómo se agrupan nuestros usuarios según sus hábitos de consumo?” (estructuras habituales en algoritmos de clustering o reglas de asociación).
Modelos Predictivos: Tienen como finalidad anticipar resultados futuros o clasificar entidades basándose en variables históricas. Su objetivo es calcular la probabilidad de que ocurra un evento específico o asignar etiquetas automáticas a nuevas observaciones (como determinar si una transacción es fraudulenta o no).
El entrenamiento de estos modelos se ejecuta sobre un conjunto de datos específico (denominado training set o conjunto de entrenamiento), y su éxito radica en la capacidad del científico de datos para realizar un ajuste fino de sus parámetros internos.
Caso de Estudio: Calibración de Parámetros mediante Árboles de Decisión
Para entender cómo opera el modelado en la práctica, analicemos el desarrollo del modelo de clasificación diseñado para la aseguradora médica, cuyo objetivo era predecir si un paciente con insuficiencia cardíaca congestiva sería reingresado en un plazo de 30 días tras su alta (una variable objetivo binaria: Sí o No).
La construcción de este modelo demostró que el diseño algorítmico requiere un ejercicio constante de experimentación y equilibrio de fuerzas mediante la sintonización de parámetros (parameter tuning):
Intento 1: El Modelo Base (Parámetros por Defecto)
El primer árbol de decisión se construyó utilizando los parámetros estándar del software analítico. Al revisar el rendimiento de este modelo inicial, los científicos de datos identificaron una asimetría crítica y peligrosa:
Precisión en la clasificación del “No” (No reingresa): 95%
Precisión en la clasificación del “Sí” (Sí reingresa): 19%
Aunque un 95% de acierto en los pacientes estables parece sobresaliente a nivel global, el objetivo primordial del negocio era detectar a los pacientes en riesgo de reingreso (el “Sí”) para poder intervenir médicamente a tiempo. Un 19% de precisión hacía que el modelo fuera completamente inútil para los fines asistenciales de la organización.
Intento 2: Ajuste Extremo del Coste de Clasificación Errónea
Para corregir el déficit del primer intento, el equipo modificó un parámetro clave: el coste relativo de clasificación errónea. Se penalizó severamente al algoritmo cada vez que fallara en predecir un “Sí”, estableciendo una relación de coste extrema de 10 a 1 (asumiendo que predecir erróneamente un “No” cuando era un “Sí” era diez veces peor).
Resultado: La precisión del “Sí” aumentó drásticamente al 85%, pero la precisión del “No” se desplomó al 45%.
Este escenario planteó un problema operativo grave. Clasificar erróneamente a tantos pacientes estables como “casos de riesgo” desencadenaría una ola de intervenciones médicas innecesarias, saturando los servicios de salud y generando costes logísticos inviables para la empresa. El algoritmo se había vuelto demasiado sensible.
Intento 3: El Balance Óptimo
Mediante experimentación continua, los científicos de datos recalibraron el parámetro a una relación de coste más moderada y realista de 4 a 1. Este ajuste técnico en el algoritmo permitió alcanzar el mejor equilibrio posible para las dimensiones del training set:
Métrica Estadística
Parámetro Evaluado
Resultado Obtenido
Sensibilidad (Sensitivity)
Precisión exclusiva del “Sí” (Reingresa)
68%
Especificidad (Specificity)
Precisión exclusiva del “No” (Estable)
85%
Precisión Global (Overall Accuracy)
Rendimiento total del modelo
81%
Este tercer modelo proporcionó la estabilidad técnica y la viabilidad comercial exigidas por la organización. Este caso real demuestra que el modelado en Machine Learning no consiste en ejecutar un algoritmo una sola vez esperando un resultado perfecto; es un proceso riguroso de prueba, análisis de métricas y sintonización de parámetros hasta encontrar el punto exacto de equilibrio que responda a la necesidad original del negocio.
8. La Fase de Evaluación (Evaluation)
Una vez que el modelo analítico ha sido calibrado y sintonizado mediante el ajuste de sus parámetros, la metodología avanza hacia un punto de control riguroso: la Evaluación. Esta fase se ejecuta de forma simultánea e iterativa con la construcción del modelo durante la etapa de desarrollo y siempre tiene lugar antes de planificar cualquier despliegue (deployment) en los sistemas de producción.
Si en el modelado el científico de datos “prueba la salsa” para ajustar su sazón, en la evaluación se somete el plato a un panel de críticos para responder a una pregunta imperativa y pragmática: ¿El modelo desarrollado realmente responde a la pregunta inicial o es necesario realizar ajustes adicionales?
Los Dos Pilares de la Evaluación Analítica
Para evaluar la calidad y la viabilidad de una solución de Machine Learning, el equipo técnico debe abordar el diagnóstico desde dos perspectivas complementarias:
Garantía de Rendimiento Técnico: Consiste en aplicar métricas estadísticas rigurosas para certificar que el modelo posee un poder predictivo real y que es capaz de generalizar sus conclusiones al enfrentarse a datos nuevos que no vio durante la fase de entrenamiento.
Validación del Enfoque de Negocio: Un modelo puede ser una obra maestra matemática, pero si no responde a la necesidad u objetivos de la organización, o si sus resultados no son accionables para los interesados (stakeholders), carece de valor práctico. Esta faceta evalúa la relevancia de los insights generados en el contexto del problema real.
Herramientas de Diagnóstico: La Curva ROC
En el diseño de modelos de clasificación binaria —como el desarrollado para clasificar si un paciente reingresará o no—, una de las herramientas estadísticas más potentes para evaluar el rendimiento es la curva ROC (Receiver Operating Characteristic).
La curva ROC es una gráfica diagnóstica que cuantifica el desempeño de un modelo de clasificación al contrastar de forma directa dos métricas fundamentales a medida que varía el umbral de discriminación del algoritmo:
Tasa de Verdaderos Positivos (Sensibilidad): El porcentaje de casos positivos correctamente identificados.
Tasa de Falsos Positivos: El porcentaje de casos negativos que el modelo clasifica erróneamente como positivos.
El área bajo esta curva (conocida como AUC – Area Under the Curve) sirve como un indicador unificado para comparar la calidad de diferentes modelos de un vistazo.
Raíces Históricas de la Curva ROC: Como dato de gran interés educativo para la ciencia de datos, los orígenes de la curva ROC no se encuentran en la informática, sino en el ámbito militar durante la Segunda Guerra Mundial. Fue desarrollada por ingenieros aliados para optimizar la detección de aeronaves enemigas a través de las señales de radar tras el ataque a Pearl Harbor. Su propósito original era encontrar el equilibrio perfecto para configurar los radares: debían ser lo suficientemente sensibles para alertar de un ataque real (Verdadero Positivo), pero no tanto como para confundir una bandada de pájaros con bombardeos enemigos (Falso Positivo). En la actualidad, esta misma lógica matemática se aplica en el Machine Learning y la minería de datos moderna.
Caso de Estudio: Evaluación Comparativa para la Toma de Decisiones
Retomando de forma práctica el proyecto de la aseguradora médica para la insuficiencia cardíaca congestiva, la fase de evaluación consistió en someter los diferentes intentos de modelado a un análisis comparativo utilizando curvas ROC. El objetivo era medir gráficamente la efectividad de cada configuración en la discriminación de los pacientes en riesgo:
Evaluación del Modelo 1 (Parámetros por defecto): La curva ROC reflejó visualmente las deficiencias de este enfoque. Al poseer una precisión del “Sí” de apenas el 19%, la gráfica evidenció un modelo plano e incapaz de resolver el problema de negocio principal.
Evaluación del Modelo 2 (Relación de coste 10 a 1): Aunque este modelo incrementó la sensibilidad, la curva expuso un aumento inaceptable en la tasa de falsos positivos (desplomando la especificidad al 45%), lo que visualmente se tradujo en un rendimiento deficiente para las operaciones de la empresa.
Evaluación del Modelo 3 (Relación de coste 4 a 1): Al trazar la curva ROC de esta versión, el equipo validó matemáticamente que este modelo lograba la mayor distancia óptima frente a la línea de asignación aleatoria. Consiguió un balance ideal con un 68% de sensibilidad y un 85% de especificidad, consolidando una precisión global del 81%.
A través de este diagnóstico visual y estadístico, los científicos de datos demostraron con certeza que el Modelo 3 era la solución más robusta y equilibrada de las opciones desarrolladas. Esta validación técnica cerró con éxito el bloque de diseño, otorgando la confianza necesaria para avanzar hacia la puesta en marcha de la estrategia analítica.
¿Procedemos a redactar las dos fases finales de la metodología, correspondientes al Despliegue (Deployment) y la Retroalimentación (Feedback), o prefieres profundizar en la interpretación matemática del Área Bajo la Curva (AUC)?
9. Fase de Implementación: El Despliegue (Deployment)
Una vez que el modelo ha sido validado estadísticamente y se ha certificado que responde con rigor a la pregunta de negocio original, la metodología avanza hacia la fase que materializa todo el valor del proyecto: el Despliegue.
Desarrollar un modelo de Machine Learning preciso no es el objetivo final de una iniciativa corporativa. El verdadero valor se genera cuando esa solución matemática se pone en práctica, se integra en los sistemas de la organización y se convierte en una herramienta accionable para los usuarios finales.
La Colaboración Multidisciplinar en la Puesta en Producción
El despliegue no es una tarea exclusiva del científico de datos; por el contrario, exige la articulación de un equipo multidisciplinar. En un escenario empresarial, el éxito de esta fase requiere la estrecha colaboración de diversos perfiles especializados:
El Propietario de la Solución (Solution Owner): Garantiza que la implementación cumpla con las expectativas estratégicas y operativas del negocio.
Ingenieros y Desarrolladores de Aplicaciones: Se encargan de encapsular el modelo y conectarlo mediante tuberías de datos o APIs con las interfaces de usuario.
Administradores de TI y DevOps: Aseguran la escalabilidad, seguridad e infraestructura de servidores necesaria para que el modelo funcione de manera óptima en tiempo real o en lotes.
Equipos de Negocio y Marketing: Diseñan las estrategias de comunicación y adopción del nuevo sistema.
El Factor Clave de Adopción: Un modelo puede proporcionar predicciones perfectas, pero si los interesados (stakeholders) no están familiarizados con la herramienta, desconocen cómo interpretar sus salidas o no confían en el sistema, la solución analítica quedará obsoleta. Familiarizar e integrar a los usuarios en el uso de la solución es un requisito indispensable en esta etapa.
Flexibilidad en el Ámbito de Aplicación
Los requisitos de despliegue varían de forma drástica según el canal y el contexto del problema. La metodología de John Rollins contempla que el despliegue puede ser tan directo o complejo como la solución lo requiera:
Despliegue de Alcance Limitado: En escenarios donde los insights van dirigidos exclusivamente a la toma de decisiones ejecutivas, el despliegue puede consistir simplemente en la puesta en marcha del modelo ante un grupo reducido de usuarios clave o la publicación de los resultados en un cuadro de mando corporativo.
Despliegue a Gran Escala: Si el modelo está diseñado para automatizar operaciones de cara al cliente (como un motor de recomendación en un e-commerce o un sistema de detección de fraudes bancarios), la solución requerirá integrarse en canales de producción masivos con alta disponibilidad y procesamiento en tiempo real.
Caso de Estudio: Aplicaciones Interactivas en el Sector Salud
Para ilustrar un despliegue de alta relevancia operativa, analicemos un caso de estudio paralelo aplicado al modelado del riesgo de hospitalización para pacientes con diabetes juvenil. Al igual que el modelo de insuficiencia cardíaca congestiva, este proyecto utilizó un algoritmo de clasificación basado en árboles de decisión como motor predictivo subyacente.
En este escenario, el despliegue definitivo se realizó a través de una aplicación analítica avanzada (desarrollada sobre entornos como IBM Cognos), transformando las salidas matemáticas del árbol de decisión en un entorno visual e interactivo para el personal médico:
Mapas de Riesgo Geográfico: La aplicación integró una interfaz cartográfica que proporcionaba una visión general del riesgo de hospitalización a nivel nacional. Esto permitía a los administradores de salud identificar de un vistazo las regiones o zonas geográficas con mayor vulnerabilidad.
Reportes de Nodos Clínicos: La solución desplegada incluyó un sistema de reportes interactivos estructurado según los nodos específicos derivados del árbol de decisión. De este modo, los médicos y clínicos podían explorar visualmente las combinaciones exactas de condiciones médicas, variables demográficas e historiales clínicos que ponían a un grupo determinado de pacientes en una situación de alto riesgo.
Al estructurar el despliegue mediante dashboards interactivos, el conocimiento derivado de las matemáticas complejas del Machine Learning se transformó en una herramienta intuitiva de soporte a la toma de decisiones médicas, permitiendo diseñar intervenciones preventivas personalizadas y optimizar los recursos hospitalarios.
¿Procedemos a redactar la última sección de la metodología, correspondiente a la fase de Retroalimentación (Feedback), o prefieres detallar las estrategias de integración tecnológica (como APIs y arquitecturas de microservicios) para modelos predictivos?
10. La Retroalimentación (Feedback)
El despliegue de un modelo predictivo en producción no representa, bajo ningún concepto, el desenlace de un proyecto de ciencia de datos. Al contrario, marca el inicio de una fase operativa crucial y continua: la Retroalimentación.
Una vez que la solución analítica se encuentra activa y operando en el mundo real, los flujos de datos generados por la experiencia de los usuarios finales y el rendimiento del propio algoritmo se convierten en el activo más valioso para su evolución. El valor sostenido de cualquier modelo de Machine Learning en el tiempo depende por completo de la capacidad del equipo para recolectar de forma sistemática este feedback y realizar los ajustes técnicos necesarios durante todo el ciclo de vida de la solución.
La Naturaleza Cíclica de la Metodología
La metodología de John Rollins no es un camino lineal de un solo sentido, sino un proceso intrínsecamente cíclico e iterativo. Cada una de las diez etapas estudiadas actúa como el pilar fundamental que define y prepara el escenario para la fase subsiguiente.
Este diseño modular garantiza que el refinamiento sea una constante en el juego analítico. El proceso de retroalimentación se fundamenta en una premisa científica ineludible: cuanto más se conoce sobre el comportamiento real de un fenómeno, más capacidad se tiene para refinar la solución analítica. A medida que el modelo se enfrenta a nuevas condiciones y recopila métricas de uso real, el equipo de ciencia de datos profundiza en el entendimiento del problema de negocio, lo que permite reiniciar el ciclo metodológico con un grado de precisión significativamente mayor.
Caso de Estudio: Refinamiento Evolutivo en Programas de Intervención Médica
Para comprender el impacto del feedback en la práctica, observemos el comportamiento posdespliegue del programa de gestión de salud diseñado para mitigar los reingresos y hospitalizaciones. La puesta en marcha de la aplicación interactiva abrió un canal de retroalimentación que redefinió por completo la estrategia técnica de los científicos de datos, impulsando dos mejoras de gran calado:
1. Incorporación de Datos de Participación Operativa
El uso de la herramienta por parte del personal de salud permitió identificar que los pacientes asignados a grupos de alto riesgo reaccionaban de forma diversa según su nivel de involucramiento en las actividades preventivas. La retroalimentación de los médicos clínicos sugirió que no bastaba con conocer el perfil histórico del paciente; era indispensable registrar si el individuo participaba activamente en el programa de intervención diseñado. Esta nueva variable operativa se integró de inmediato al modelo para afinar su capacidad de discriminación.
2. Reactivación y Absorción de Datos Diferidos (Farmacéuticos)
Si recordamos las etapas iniciales de la metodología (Específicamente en Data Collection), el equipo analítico había tomado la decisión de posponer e interrumpir temporalmente la recolección de los datos farmacéuticos detallados debido a que los sistemas de información de las recetas no estaban integrados y su extracción exigía un coste de desarrollo prohibitivo. El modelo inicial demostró ser lo suficientemente robusto para operar sin ellos.
Sin embargo, tras la fase de despliegue y tras evaluar los resultados prácticos del modelo en producción, el proceso de retroalimentación evidenció que para romper el techo de precisión alcanzado y optimizar las intervenciones clínicas más complejas, valía totalmente la pena realizar la inversión de tiempo, código y esfuerzo tecnológico necesaria para extraer e incorporar ese historial farmacéutico detallado que se había descartado al principio.
El Proceso de Revisión de Intervenciones y Prácticas Clave
El proceso de retroalimentación obliga a los científicos de datos y a los líderes de la organización a implementar una rutina de gobernanza analítica basada en tres mejores prácticas indispensables:
Monitoreo de Métricas en Producción: Definir paneles de control para supervisar el comportamiento del modelo, midiendo si las tasas de falsos positivos y verdaderos positivos se mantienen estables o si sufren degradación (data drift o model degradation) ante los cambios del entorno real.
Evaluación del Impacto de las Acciones: Analizar si las decisiones operativas basadas en las predicciones del modelo (por ejemplo, priorizar la atención de ciertos pacientes) están modificando positivamente los indicadores clave de rendimiento (KPIs) del negocio.
Revisión de Procesos en Base de Datos: Colaborar con ingenieros de datos para asegurar que los nuevos elementos detectados en la fase de retroalimentación se automaticen e integren de forma eficiente en los almacenes de datos (Data Warehouses), cerrando el flujo metodológico con un sistema escalable, dinámico y en constante aprendizaje.
Más Allá de los Algoritmos: El Rol del Storytelling en Ciencia de Datos
Existe una última habilidad, frecuentemente subestimada en las formaciones puramente técnicas, que marca la diferencia entre un modelo archivado en un repositorio y una solución que transforma una organización: el storytelling con datos.
El rol de la narrativa en la vida de un científico de datos o analista no puede exagerarse. Dominar la construcción de historias no es un complemento cosmético; es una competencia crítica para cualquier profesional que necesite convertir métricas abstractas en decisiones estratégicas.
La Psicología Detrás de las Historias y los Datos
La razón por la que el storytelling es tan potente radica en la propia naturaleza humana. Los seres humanos entendemos, procesamos y recordamos el mundo de forma innata a través de historias.
Cuando un equipo técnico presenta un proyecto limitándose a proyectar números y KPIs aislados, es muy probable que la audiencia desconecte. Cualquiera puede mostrar datos en una pantalla, pero si esos datos no están respaldados por una narrativa estructurada y un argumento sólido que justifique la acción, la propuesta difícilmente resonará en la organización.
El Experimento de Stanford: Un estudio emblemático realizado en la Universidad de Stanford analizó el impacto de la comunicación cuantitativa. En el experimento, varios participantes debían realizar presentaciones de negocios (pitches). Algunos basaron sus discursos exclusivamente en estadísticas, gráficos rígidos y KPIs. Otros, en cambio, entrelazaron esos mismos datos numéricos dentro de una historia. Al evaluar el impacto a largo plazo, los resultados fueron contundentes: la audiencia recordaba de forma nítida los datos de aquellos ponentes que habían estructurado su presentación mediante un relato, mientras que los datos aislados de las presentaciones puramente estadísticas se olvidaron casi por completo.
El “Puente” entre el Equipo Técnico y el Negocio
En el ecosistema corporativo actual, el científico de datos actúa como un traductor. Su trabajo consiste en sumergirse en bases de datos relacionales complejas, entrenar algoritmos de Machine Learning y, posteriormente, emerger de ese entorno técnico para explicarle a un comité ejecutivo —que no tiene por qué entender de matemáticas avanzadas o de hiperparámetros— qué significan esos hallazgos.
El storytelling es el vehículo que permite cruzar ese puente. No se trata de simplificar el trabajo u ocultar el rigor estadístico, sino de contextualizar el dato. Una buena narrativa responde de forma clara a tres preguntas clave para los interesados (stakeholders):
¿Qué está pasando? (El hecho respaldado por el dato crudo).
¿Por qué importa? (El impacto financiero, operativo o asistencial de ese hecho).
¿Qué debemos hacer ahora? (La llamada a la acción o decisión estratégica).
Al dominar esta técnica, el profesional de la ciencia de datos no solo demuestra su competencia técnica, sino que dota a la organización de una razón convincente para actuar, garantizando que el ciclo metodológico culmine en un verdadero impacto transformador.
Marcos de Trabajo Alternativos: Introducción a CRISP-DM
Para concluir este recorrido por las metodologías analíticas, es fundamental estudiar el marco de trabajo que sentó los precedentes de la industria y que sigue siendo el estándar más utilizado en el ecosistema corporativo global: CRISP-DM (Cross-Industry Standard Process for Data Mining o Proceso Estándar de la Industria Cruzada para la Minería de Datos).
Si la metodología de John Rollins destaca por su desglose minucioso en 10 etapas secuenciales e iterativas, CRISP-DM ofrece un modelo robusto, probado por la industria, que proporciona un enfoque estructurado y flexible para guiar cualquier esfuerzo de minería de datos y Machine Learning. Comprender la relación y las equivalencias entre ambos marcos teóricos permite a los equipos de ciencia de datos adaptar sus procesos con la máxima agilidad según el alcance del proyecto.
Las 6 Etapas del Modelo CRISP-DM
A diferencia de la estructura de Rollins, el ciclo de vida de un proyecto bajo el estándar CRISP-DM se condensa en seis etapas principales interconectadas. El proceso es marcadamente iterativo, lo que significa que el avance a una fase frecuentemente depende de los hallazgos y validaciones de la etapa anterior:
Business Understanding (Comprensión del negocio): Al igual que en el modelo de Rollins, esta fase inicial se enfoca en entender detalladamente los objetivos, requisitos y restricciones del proyecto desde una perspectiva empresarial, traduciendo dicha necesidad en la definición de un problema técnico de minería de datos.
Data Understanding (Comprensión de los datos): Implica la recolección inicial de los datos, la familiarización con ellos, la identificación de problemas de calidad y la extracción de los primeros insights o subconjuntos ocultos mediante estadísticas descriptivas.
Data Preparation (Preparación de los datos): Comprende todas las tareas necesarias para construir el set de datos final (la matriz de modelado) a partir de los datos en bruto. Incluye la selección de tablas, filas y atributos, la limpieza de registros y la transformación de variables.
Modeling (Modelado): En esta fase se seleccionan y aplican diversas técnicas y algoritmos analíticos (como árboles de decisión, redes neuronales o regresiones) y se calibran sus hiperparámetros para optimizar su rendimiento.
Evaluation (Evaluación): Antes de proceder al despliegue final, se evalúa rigurosamente el modelo construido para asegurar que alcanza los objetivos de negocio preestablecidos. Aquí se determina si existe alguna razón importante por la cual la solución no deba ponerse en marcha.
Deployment (Despliegue): La fase final donde los conocimientos y modelos se integran en la operación diaria de la empresa. Puede ser tan simple como la generación de un reporte o tan compleja como la implementación de un proceso de Machine Learning automatizado en tiempo real.
Puntos de Encuentro y Divergencias Técnicas
Al contrastar la metodología clásica de John Rollins con el estándar CRISP-DM, se hacen evidentes sus paralelismos teóricos, pero también sus sutiles diferencias conceptuales. El análisis comparativo revela cómo ambos modelos distribuyen la carga de trabajo analítico:
Fusión de Etapas de Datos: Lo que en CRISP-DM se denomina simplemente Data Understanding, en la metodología de Rollins se desglosa formalmente en tres pasos independientes y explícitos: Data Requirements (Requisitos), Data Collection (Recolección) y Data Understanding (Comprensión). Esta ramificación de Rollins aporta una guía más granular para las fases tempranas de ingeniería de datos.
El Cierre del Ciclo: La Reunión de Feedback: Una de las diferencias más notables ocurre tras completar la fase de evaluación y puesta en marcha. En la práctica real de CRISP-DM, al finalizar las seis etapas, los científicos de datos convocan una nueva reunión de comprensión del negocio con los interesados (stakeholders) para discutir formalmente los resultados y decidir los siguientes pasos.
Aunque conceptualmente representa lo mismo, en el estándar CRISP-DM esta etapa final de revisión no cuenta con un nombre explícito dentro del diagrama oficial. Por el contrario, el modelo de John Rollins subsana este vacío metodológico nombrando y estructurando de forma directa y rigurosa la fase número diez como la Etapa de Retroalimentación (Feedback Stage).
Independientemente de si un equipo elige la granularidad de las 10 etapas de Rollins o la estructura consolidada de las 6 fases de CRISP-DM, el factor crítico de éxito radica en respetar la naturaleza cíclica del proceso. Las etapas continúan repitiéndose de forma sistemática hasta que la gerencia, los especialistas del dominio y los científicos de datos acuerden unánimemente que los modelos proporcionan las respuestas precisas para resolver los problemas de la organización y alcanzar sus metas estratégicas.
En la estadística aplicada y el Machine Learning, una hipótesis es una afirmación formal acerca de un parámetro de la población. No se trata de una suposición vaga, sino de un enunciado matemático verificable sobre propiedades como la media (\(\mu\)), la varianza (\(\sigma^2\)) o, recuperando nuestro caso de la teoría de colas, el parámetro \(\lambda\) de una distribución de Poisson.
Marco de Aplicación en Negocios
Imaginemos el flujo de operaciones en un supermercado. Basándonos en el histórico de infraestructura, podemos plantear una hipótesis sobre el parámetro \(\lambda\) que representa el número promedio de clientes que entrarán a la fila de cajas en la próxima hora. Validar si este promedio se mantiene estable o si ha incrementado debido a una nueva campaña promocional es el propósito de una prueba de hipótesis.
Anatomía de las Hipótesis: Nula vs. Alternativa
Para conducir un contraste estadístico, el problema debe estructurarse obligatoriamente mediante un par de hipótesis mutuamente excluyentes: la Hipótesis Nula (\(H_0\)) y la Hipótesis Alternativa (\(H_1\) o \(H_a\)).
La forma en que se definen y asignan estos enunciados sigue reglas metodológicas estrictas basadas en el nivel de especificidad del problema:
La Hipótesis Nula (\(H_0\)): Representa el statu quo, la afirmación de igualdad, la ausencia de cambio o el valor histórico establecido. Siempre contiene un valor específico y puntual (una igualdad matemática).
La Hipótesis Alternativa (\(H_1\)): Representa la afirmación que el analista busca demostrar, el cambio esperado o la sospecha de una nueva dinámica. Suele ser menos específica, utilizando desigualdades (mayor que, menor que o diferente de).
Modelos de Configuración de Hipótesis
Dependiendo del diseño del experimento, las hipótesis pueden estructurarse de dos maneras:
Contraste de Intervalo (Unilateral o Bilateral)
Es el escenario más común en la analítica corporativa. La hipótesis nula defiende el valor puntual exacto, mientras que la alternativa abarca un espectro abierto de posibilidades.
\(H_0\) (Hipótesis Nula): \(\lambda = 5\) (El promedio de clientes que ingresan por hora es exactamente cinco).
\(H_1\) (Hipótesis Alternativa): \(\lambda > 5\) (El promedio de clientes es mayor que cinco, abarcando cualquier valor en ese intervalo continuo).
Contraste de Valores Puntuales Específicos
Ocurre cuando comparamos dos escenarios teóricos o configuraciones de sistemas rígidamente predefinidas.
\(H_0\) (Hipótesis Nula): \(\lambda = 5\) (Configuración del sistema estándar).
\(H_1\) (Hipótesis Alternativa): \(\lambda = 8\) (Configuración bajo un escenario de alta demanda controlada).
El Procedimiento de Decisión Frecuentista
El enfoque tradicional o frecuentista utiliza los datos recolectados en la muestra para calcular un valor matemático denominado estadístico de prueba. Mediante este indicador, se ejecuta un protocolo formal para decidir si existe suficiente evidencia estadística para rechazar la hipótesis nula.
Rigor Teórico frente a Práctica Operativa
En la academia y la teoría estadística estricta, existe un consenso semántico fundamental: “La hipótesis nula se puede rechazar, pero nunca se ‘acepta’ la hipótesis alternativa; simplemente se falla en rechazar la nula”. Esto se debe a que la ausencia de evidencia para derribar el statu quo no demuestra matemáticamente que este sea una verdad absoluta.
Sin embargo, a efectos prácticos de ingeniería de datos y desarrollo de proyectos en el sector empresarial, si el estadístico de prueba cae dentro de la zona de rechazo de $H_0$, el equipo analítico procederá operativamente bajo la premisa de que la hipótesis alternativa es la vía verdadera, justificando inversiones como la apertura de nuevas cajas de salida o la expansión de servidores en la nube.
El Enfoque Bayesiano de las Pruebas de Hipótesis
La filosofía bayesiana rompe con el protocolo de decisiones rígidas del enfoque frecuentista. En una prueba bayesiana, no existen fronteras de decisión tajantes (decision boundaries) ni valores críticos fijos (como el clásico valor $p < 0.05$).
En su lugar, el análisis bayesiano trata a la hipótesis nula (\(H_0\)) y a la alternativa (\(H_1\)) como eventos que poseen sus propias probabilidades a priori. Tras observar y procesar la evidencia de la muestra, el teorema de Bayes actualiza estas creencias, devolviendo las probabilidades a posteriori de cada hipótesis:
El resultado final no es un veredicto binario de “rechazar o no rechazar”, sino una comparación directa de probabilidades: el analista evalúa cuál de las dos hipótesis es más probable que ocurra dada la evidencia actual del negocio.
El Experimento del Lanzamiento de Monedas (Coin Tossing)
Para ilustrar de forma práctica la mecánica de las pruebas de hipótesis y cómo evaluar la verosimilitud de un escenario, analizaremos un experimento clásico de probabilidad discreta utilizando dos monedas con propiedades distintas.
Diseño del Experimento
Imaginemos que disponemos de dos monedas en un saco:
Moneda 1 (\(C_1\)): Es una moneda completamente justa o equilibrada, con una probabilidad de obtener cara (heads) del 50% (\(p = 0.5\)).
Moneda 2 (\(C_2\)): Es una moneda trucada o sesgada, con una probabilidad de obtener cara del 70% ($p = 0.7$).
Seleccionamos una de las dos monedas al azar sin mirar (nuestra variable oculta o parámetro desconocido), la lanzamos de forma idéntica e independiente 10 veces (\(n = 10\)) y registramos el número total de caras obtenidas ($X$). Nuestro objetivo estadístico es determinar cuál de las dos monedas es más probable que hayamos elegido, basándonos únicamente en el resultado observable de los lanzamientos.
Distribución de Probabilidad del Experimento
Dado que cada lanzamiento tiene únicamente dos resultados posibles (cara o cruz) y una probabilidad constante de éxito, el número de caras en 10 lanzamientos sigue una Distribución Binomial.
La fórmula matemática para calcular la probabilidad exacta de obtener un número específico de éxitos ($k$) es:
$$P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}$$
A partir de esta estructura, podemos construir una tabla comparativa que muestre la probabilidad de observar cada volumen de caras para ambas monedas:
Número de Caras (k)
Probabilidad con Moneda 1 (p=0.5)
Probabilidad con Moneda 2 (p=0.7)
Tendencia de Inferencia
0 – 4
Alta
Muy Baja
Fuertemente a favor de la Moneda 1
5
Máxima para \(C_1\)(\(24.6\%\))
Baja (\(10.3\%\))
A favor de la Moneda 1
6
Moderada (\(20.5\%\))
Moderada-Alta (\(20.0\%\))
Zona de ambigüedad estadística
7
Baja (\(11.7\%\))
Máxima para \(C_2\) (\(26.7\%\))
A favor de la Moneda 2
8 – 10
Muy Baja
Alta
Fuertemente a favor de la Moneda 2
Análisis de Tendencias
Valores Bajos (0 a 5 caras): La probabilidad es significativamente mayor en la Moneda 1. Si obtenemos pocas caras, intuitivamente deducimos que la moneda no está sesgada hacia arriba.
Valores Altos (7 a 10 caras): La densidad de probabilidad se concentra en la Moneda 2. Un volumen alto de caras valida estadísticamente la presencia del sesgo del 70%.
7. Cálculo de la Razón de Verosimilitud (Likelihood Ratio)
La Razón de Verosimilitud es la herramienta matemática que cuantifica de forma exacta cuántas veces es más probable un escenario o hipótesis frente a otro, dados los datos de la muestra.
Supongamos que ejecutamos el experimento y observamos exactamente 3 caras en los 10 lanzamientos (\(X = 3\)). Calculamos las verosimilitudes para cada hipótesis aplicando la distribución binomial:
Verosimilitud de la Moneda 1:\(P(X=3 \mid C_1) = \binom{10}{3} (0.5)^3 (0.5)^7 \approx 0.117\)
Verosimilitud de la Moneda 2:\(P(X=3 \mid C_2) = \binom{10}{3} (0.7)^3 (0.3)^7 \approx 0.009\)
Para evaluar la fuerza de esta evidencia, calculamos la Razón de Verosimilitud ($LR$) dividiendo la probabilidad de la hipótesis nula ($C_1$) entre la hipótesis alternativa ($C_2$):
Interpretación Analítica: El resultado $LR \approx 13$ significa que es 13 veces más probable observar exactamente 3 caras si la moneda es la justa ($C_1$) que si fuera la moneda sesgada ($C_2$).
Este indicador matemático nos da una métrica objetiva para fundamentar nuestra decisión: ante la evidencia de la muestra, rechazamos la suposición de que la moneda está truncada al 70% y procedemos operativamente bajo la conclusión de que la moneda seleccionada es la estándar.
8. El Rol de las Probabilidades a Priori (Priors)
Como ya hemos introducido en la interpretación bayesiana, para contrastar dos hipótesis necesitamos asignar obligatoriamente una probabilidad a priori o prior a cada una de ellas. El prior representa el grado de creencia o la probabilidad teórica que otorgamos a una hipótesis antes de observar los datos del experimento actual.
Configuración del Experimento Controlado
En el problema de las dos monedas, el enunciado especifica que seleccionamos una moneda del saco de forma completamente aleatoria. Debido a que no tenemos ninguna información inicial que nos incline a pensar que elegimos una sobre la otra, aplicamos el principio de indiferencia y asignamos un peso idéntico a ambas opciones:
Prior de la Hipótesis 1 (Moneda Justa): $P(H_1) = 0.50$ (50% de probabilidad)
Prior de la Hipótesis 2 (Moneda Trucada): $P(H_2) = 0.50$ (50% de probabilidad)
El Impacto del Contexto en el Prior (Mundo Real)
El diseño cambia drásticamente si modificamos el contexto del problema. Imaginemos que en lugar de sacar una moneda de un saco controlado, tomamos una moneda cualquiera en la barra de un bar o en el transporte público.
Nuestra experiencia y el conocimiento general del mundo nos dictan que encontrar una moneda con un truco tan masivo como el 70% de sesgo es un evento extraordinariamente raro. En este escenario real, un analista bayesiano calibraría los priors de forma asimétrica:
$P(H_1)$ [Moneda Justa]: $0.99$ (99% de certeza inicial)
$P(H_2)$ [Moneda Trucada]: $0.01$ (1% de certeza inicial)
Esta distribución inicial asimétrica actuará como un freno estadístico: requerirá una cantidad masiva de datos y una racha abrumadora de caras para poder vencer la inercia del prior y concluir que la moneda es verdaderamente trucada.
9. Formalización mediante el Teorema de Bayes
Para consolidar la inferencia, aplicamos formalmente el Teorema de Bayes para calcular la probabilidad a posteriori, es decir, la probabilidad de que una hipótesis sea la verdadera una vez analizados los datos observados ($X$).
La ecuación para evaluar la Hipótesis 1 frente a los datos es:
$P(H_1 \mid X)$ [Posterior]: Nuestra predicción final optimizada. La probabilidad de tener la moneda justa dado que salieron, por ejemplo, 3 caras.
$P(X \mid H_1)$ [Verosimilitud / Likelihood]: La probabilidad binomial de obtener 3 caras asumiendo que la moneda es justa (el valor $0.117$ que calculamos anteriormente).
$P(H_1)$ [Prior]: Nuestra creencia inicial de partida (en el saco controlado, $0.5$).
$P(X)$ [Evidencia / Denominador]: La probabilidad total de observar 3 caras considerando todas las hipótesis posibles dentro de nuestro espacio muestral ($P(X) = P(X \mid H_1)P(H_1) + P(X \mid H_2)P(H_2)$).
Nota de Simplificación Analítica: En la práctica, el denominador $P(X)$ funciona simplemente como una constante de normalización para asegurar que las probabilidades finales sumen 1 (100%). Al momento de calcular la Razón de Posteriores para comparar cuál hipótesis es la ganadora, el denominador se encuentra presente en ambas partes de la fracción, por lo que se cancela automáticamente y no afecta el sentido de la decisión.
10. La Razón de Posteriores: Integrando Verosimilitud y Priors
Para tomar la decisión definitiva, combinamos la Razón de Verosimilitud (Likelihood Ratio, basada puramente en los datos nuevos) con la Razón de Priors (basada en el conocimiento previo):
$$\frac{P(H_1 \mid X)}{P(H_2 \mid X)} = \underbrace{\frac{P(X \mid H_1)}{P(X \mid H_2)}}_{\text{Razón de Verosimilitud}} \times \underbrace{\frac{P(H_1)}{P(H_2)}}_{\text{Razón de Priors}}$$
Analicemos cómo interactúan estos componentes según los dos contextos planteados si el experimento arroja 3 caras:
Escenario A: Selección en Saco Controlado (Priors 50/50)
Razón de Verosimilitud = $\frac{0.117}{0.009} \approx 13$
Razón de Priors = $\frac{0.5}{0.5} = 1$
Razón de Posteriores: $13 \times 1 = 13$
Como los priors eran idénticos, se cancelan de la ecuación. La decisión se rige completamente por los datos de la muestra. La hipótesis de la moneda justa ($H_1$) es 13 veces más probable que la alternativa.
Escenario B: Moneda Tomada del Público (Priors 99/1)
Razón de Verosimilitud = $\frac{0.117}{0.009} \approx 13$
Razón de Priors = $\frac{0.99}{0.01} = 99$
Razón de Posteriores: $13 \times 99 = 1287$
En este caso, la combinación de la evidencia física (las 3 caras) junto con la abrumadora sospecha lógica inicial genera una conclusión definitiva: la hipótesis de la moneda justa es 1287 veces más probable. El prior ha blindado el modelo contra falsos positivos.
Conclusión del Bloque: Fundamentos de Contraste Bayesiano
Hemos cubierto con éxito la introducción y la mecánica de las pruebas de hipótesis bajo la óptica bayesiana:
Definimos la estructura formal de una prueba mediante la dualidad de la Hipótesis Nula ($H_0$) y la Hipótesis Alternativa ($H_1$).
Demostramos cómo la escuela bayesiana sustituye las fronteras rígidas de decisión por un cálculo continuo de probabilidades a posteriori.
Validamos, mediante el experimento de los lanzamientos de monedas, que la Razón de Verosimilitud actúa como un motor de actualización que transforma nuestros priors en posteriores precisos.
En la siguiente sección, cambiaremos de perspectiva metodológica para estudiar cómo aborda el contraste de hipótesis la escuela frecuentista tradicional, analizando conceptos críticos como los valores p (p-values), las regiones críticas y los errores de Tipo I y Tipo II.
11. El Paradigma de Neyman-Pearson y la Matriz de Error
Dentro del marco de la estadística clásica o frecuentista, el paradigma de Neyman-Pearson establece el estándar metodológico para realizar contrastes de hipótesis binarios. A diferencia del enfoque bayesiano, que calcula probabilidades continuas para cada hipótesis, este modelo requiere establecer una frontera de decisión rígida para rechazar o no rechazar la Hipótesis Nula ($H_0$).
Al tomar una decisión binaria basada en una muestra finita de datos, existe el riesgo inevitable de cometer errores. Estos escenarios se clasifican formalmente en una matriz de confusión estadística:
Condición Real \ Decisión Estadística
Fallar en Rechazar H0 (Concluir H0)
Rechazar H0 (Concluir H1)
$H_0$ es Verdadera
Decisión Correcta
Error de Tipo I (Falso Positivo)
$H_0$ es Falsa ($H_1$ es Verdadera)
Error de Tipo II (Falsos Negativo)
Decisión Correcta (Potencia Estadística)
A. Error de Tipo I (Falso Positivo)
Ocurre cuando los datos de la muestra presentan una anomalía estadística que nos induce a rechazar la Hipótesis Nula, a pesar de que esta es completamente verdadera.
Tasa de Error ($\alpha$): La probabilidad de cometer un error de Tipo I se denota por $\alpha$ (nivel de significancia) y es controlada rígidamente por el analista antes del experimento (típicamente configurada en un 5% o $\alpha = 0.05$).
Analogía de la moneda: Lanzamos una moneda que es perfectamente justa ($H_0: p = 0.5$). Por puro azar matemático, la moneda cae cara 10 veces consecutivas. El procedimiento nos obliga a rechazar $H_0$ concluyendo que está trucada ($H_1$), cometiendo un Error de Tipo I.
B. Error de Tipo II (Falso Negativo)
Ocurre cuando la hipótesis nula es falsa (existe un efecto o cambio real en la población), pero los datos recolectados no muestran la fuerza estadística suficiente, lo que nos lleva a fallar en rechazar la Hipótesis Nula.
Tasa de Error ($\beta$): La probabilidad de cometer un error de Tipo II se denota por $\beta$.
Analogía de la moneda: Trabajamos con una moneda sesgada cuya probabilidad real de cara es del 70% ($H_1: p = 0.7$). La lanzamos 10 veces y, debido a la variabilidad de la muestra, obtenemos exactamente 5 caras. Como 5 es un resultado común para una moneda normal, fallamos en rechazar $H_0$, ignorando el sesgo real de la moneda.
12. La Potencia Estadística de una Prueba (Statistical Power)
La Potencia Estadística se define matemáticamente como la probabilidad de rechazar correctamente la hipótesis nula cuando esta es efectivamente falsa. En términos probabilísticos, se calcula como:
$$\text{Potencia} = 1 – \beta$$
Representa la capacidad que tiene un diseño experimental o un algoritmo para detectar un efecto real (como un incremento en las ventas o un cambio de comportamiento) cuando este verdaderamente existe.
El Balance Crítico entre Errores y Potencia
Existe una correlación inversa directa entre ambos tipos de error impulsada por la frontera de decisión:
Maximizar la Potencia de forma artificial: Si un analista decide rechazar la hipótesis nula ante el más mínimo indicio en los datos, incrementará la potencia del test al máximo ($1 – \beta \to 1$), reduciendo el error de Tipo II a cero. Sin embargo, esto disparará drásticamente la tasa de Errores de Tipo I (Falsos Positivos).
Aumentar el rigor metodológico: Si, por el contrario, se vuelve extremadamente difícil rechazar la hipótesis nula para proteger el modelo contra falsos positivos (reduciendo $\alpha$ a 0.01), el test perderá sensibilidad. Como consecuencia, la prueba será menos potente y aumentará la tasa de Errores de Tipo II.
13. Caso de Estudio en Negocios: Predicción de Abandono de Clientes (Customer Churn)
Para trasladar estos conceptos teóricos al ecosistema de Business Intelligence y Data Science, analizaremos el diseño de un modelo predictivo para mitigar el Customer Churn (el abandono o la baja de clientes en una compañía).
Configuración del Escenario Analítico
El equipo de datos busca evaluar si una característica específica del cliente impacta directamente en la retención. Planteamos el siguiente contraste:
Hipótesis Nula ($H_0$): El abandono ocurre puramente debido al azar; la antigüedad del cliente no genera ningún efecto real en la probabilidad de baja.
Hipótesis Alternativa ($H_1$): Los clientes que superan los dos años de antigüedad con la empresa presentan una tasa de abandono significativamente menor (existe un efecto real de lealtad por tiempo).
El modelo de Machine Learning procesa variables demográficas (edad, localización) e históricas (volumen y frecuencia de compra) para asignar un score de probabilidad de fuga a cada individuo.
Impacto de los Errores Estadísticos en la Estrategia Corporativa
La decisión operativa de implementar o no una campaña de retención basada en el tiempo dependerá de la validación de esta prueba. Los errores en este contexto se traducen en costos financieros y operativos directos:
A. Error de Tipo I en Churn (Falso Positivo)
Situación: En la realidad, el tiempo de permanencia superior a dos años no influye en la fidelidad; la fluctuación observada en los datos fue un mero evento aleatorio. Sin embargo, la prueba estadística arroja un resultado significativo y rechaza $H_0$.
Consecuencia Comercial: La dirección asume erróneamente que los clientes veteranos están blindados contra la fuga. Como resultado, la empresa puede cometer el error estratégico de desviar los recursos de fidelización exclusivamente hacia clientes nuevos, dejando desprotegido a un sector que en realidad sí tenía propensión a abandonar la compañía.
B. Error de Tipo II en Churn (Falso Negativo)
Situación: En la realidad de la población, superar la barrera de los dos años sí genera un cambio estructural que reduce la probabilidad de abandono. No obstante, debido a un tamaño de muestra insuficiente o a una alta variabilidad en los datos recopilados, la prueba estadística falla en rechazar $H_0$ y concluye que el efecto se debe al azar.
Consecuencia Comercial: El departamento de BI descarta la antigüedad como una característica relevante para el modelo de scoring. La organización pierde la oportunidad de diseñar programas de incentivos personalizados dirigidos a retener a los usuarios justo antes de cumplir el hito de los dos años, lo que se traduce en una pérdida directa de cuota de mercado y de Customer Lifetime Value (CLTV).
14. Vocabulario Técnico Esencial en Pruebas de Hipótesis
Para estructurar un contraste estadístico bajo el enfoque frecuentista, es necesario dominar cuatro conceptos operativos que definen el comportamiento y los límites de decisión de la prueba.
Estadístico de Prueba (Test Statistic): Es un valor numérico calculado a partir de los datos de la muestra (como un valor $Z$, $t$, o la Razón de Verosimilitud). Este número sintetiza la evidencia matemática y determina si los resultados observados se desvían de lo esperado bajo la hipótesis nula.
Distribución Nula (Null Distribution): Es la distribución teórica de probabilidad que seguiría nuestro estadístico de prueba asumiendo como premisa absoluta que la Hipótesis Nula ($H_0$) es verdadera. Sirve como el marco de referencia para evaluar qué tan inusuales o “anómalos” son los datos recolectados.
Región de Rechazo (Rejection Region / Región Crítica): Es el conjunto de valores del estadístico de prueba que son tan improbables de ocurrir bajo la distribución nula que, si el estadístico cae allí, nos obliga a rechazar la hipótesis nula a favor de la alternativa. Su tamaño está delimitado por el nivel de significancia $\alpha$.
Región de Aceptación (Región de No Rechazo): Es la zona central de la distribución que concentra los valores más probables y esperados. Si el estadístico de prueba se ubica en este rango, se concluye que no existe evidencia estadística suficiente para descartar el statu quo, por lo que fallamos en rechazar $H_0$.
15. Casos de Aplicación en el Entorno Corporativo
Las pruebas de hipótesis constituyen la infraestructura científica detrás de las decisiones automatizadas e iterativas en empresas de tecnología y optimización de procesos. A continuación, se presentan tres escenarios prácticos de negocio:
Caso A: Impacto de Campañas de Marketing Directo
Una organización implementa una campaña de correo físico dirigida a reactivar a su cartera de clientes actuales.
$H_0$ (Hipótesis Nula): La campaña de marketing no tiene ningún impacto real; la tasa de conversión o el ticket promedio de compra se mantiene idéntico al histórico por mero azar.
$H_1$ (Hipótesis Alternativa): La campaña genera un impacto positivo y significativo en el volumen de compras de los clientes expuestos.
Caso B: Optimización de Interfaces e Ingeniería de Producto (Pruebas A/B)
El equipo de diseño propone una reestructuración completa del layout de la plataforma web para incrementar la retención de tráfico.
$H_0$ (Hipótesis Nula): El nuevo diseño de la interfaz web no genera ninguna alteración en la navegación ni en la retención del tráfico de usuarios.
$H_1$ (Hipótesis Alternativa): El cambio de layout incrementa significativamente el tiempo de permanencia y el flujo de tráfico en el sitio web.
Caso C: Control de Calidad y Estandarización de Procesos
Una compañía manufactura un componente crítico en múltiples plantas con una especificación técnica de tamaño objetivo equivalente a una medida estándar $S$. Para validar que la producción cumple los requisitos normativos dentro de un margen de tolerancia admisible, se extrae una muestra aleatoria de cada fábrica.
$H_0$ (Hipótesis Nula): El tamaño promedio de los componentes extraídos de la muestra no difiere significativamente del estándar requerido $S$ ($\mu = S$). La producción está bajo control.
$H_1$ (Hipótesis Alternativa): Existe una desviación estadísticamente significativa en el tamaño del producto respecto al estándar esperado ($\mu \neq S$).
Implicación en Calidad: En este escenario industrial, caer en la región de rechazo (validar la hipótesis alternativa) representa un indicador de alarma crítico: la planta está produciendo unidades defectuosas, lo que exige detener la línea de producción y calibrar la maquinaria basándose en la media y la desviación estándar de la muestra.
Resumen del Bloque y Próximos Pasos
Hemos concluido la revisión conceptual y metodológica de las bases que rigen el contraste de hipótesis:
Definimos las reglas operativas de la Hipótesis Nula ($H_0$) y la Alternativa ($H_1$).
Analizamos los riesgos y compensaciones de los Errores de Tipo I ($\alpha$) y Tipo II ($\beta$), así como el papel de la Potencia Estadística ($1-\beta$).
Conceptualizamos las herramientas métricas de decisión como el Estadístico de Prueba y las Regiones de Rechazo.
En el siguiente artículo, profundizaremos en la interpretación cuantitativa fina de estos resultados, estudiando el funcionamiento de los Niveles de Significancia y el cálculo del Valor P (P-value) para formalizar de manera definitiva nuestras decisiones basadas en datos.
18. El Nivel de Significancia ($\alpha$) y el Control del Error
En el contraste de hipótesis frecuentista, el Nivel de Significancia (denotado por $\alpha$) es el umbral de tolerancia que el analista establece de forma estricta antes de observar o computar los datos de la muestra. Matemáticamente, representa la probabilidad máxima admisible de cometer un Error de Tipo I (afirmar que existe un efecto o anomalía cuando en realidad todo se debe al azar).
Al fijar $\alpha$, se define el tamaño de la región crítica de la distribución. Un valor de $\alpha = 0.05$ (5%) implica que estamos dispuestos a aceptar un 5% de riesgo de emitir un falso positivo.
El Peligro del P-hacking
Establecer el valor de $\alpha$ de manera previa es una regla de oro en la ciencia de datos y la investigación. Si un analista recopila los datos, calcula el resultado estadístico y luego altera el umbral $\alpha$ o manipula los datos de forma iterativa hasta forzar un resultado estadístico “significativo”, incurre en una mala práctica conocida como P-hacking o dragado de datos (data dredging), invalidando por completo la integridad del modelo de inferencia.
Flexibilidad de Umbrales según el Impacto del Negocio
La rigurosidad en la selección de $\alpha$ está directamente ligada al costo operativo, humano o financiero que conlleva cometer un falso positivo.
Caso de Alta Criticidad (Farmacéutico/Salud):
Contexto: Se prueba un medicamento con efectos secundarios severos. La hipótesis nula ($H_0$) es que el fármaco no ayuda a la recuperación.
Estrategia: Un falso positivo implicaría lanzar al mercado un medicamento dañino e ineficaz. Se requiere una certeza absoluta, por lo que se seleccionan niveles de significancia extremadamente conservadores como $\alpha = 0.01$ (1%) o $\alpha = 0.001$ (0.1%).
Caso de Baja Criticidad (Diseño/Publicidad):
Contexto: Una plataforma de e-commerce evalúa si incrementar ligeramente el tamaño de la tipografía en los banners de anuncios incrementa el ratio de clics (CTR).
Estrategia: Un falso positivo simplemente significaría cambiar el tamaño de una fuente sin un impacto real, un error que no pone en riesgo la operación. Aquí, un umbral de $\alpha = 0.10$ (10%) o $\alpha = 0.05$ es metodológicamente aceptable.
19. ¿Qué es exactamente el Valor P (P-value)?
El Valor P (P-value) es una medida probabilística que cuantifica la fuerza de la evidencia aportada por la muestra en contra de la hipótesis nula.
Definición Formal: El valor p es la probabilidad de observar un estadístico de prueba tan extremo o más extremo que el obtenido en la muestra real, asumiendo como premisa absoluta que la hipótesis nula ($H_0$) es verdadera.
No representa la probabilidad de que una hipótesis sea cierta o falsa (lo cual sería una interpretación puramente bayesiana); mide la plausibilidad de los datos observados bajo el marco conceptual de la distribución nula.
Regla de Decisión Estándar
La comparación matemática entre el valor p calculado y el nivel de significancia $\alpha$ preestablecido rige el resultado del test:
Si $\text{Valor P} \le \alpha$: El resultado es estadísticamente significativo. La probabilidad de obtener estos datos por puro azar es tan baja que rechazamos la hipótesis nula ($H_0$) en favor de la alternativa ($H_1$).
Si $\text{Valor P} > \alpha$: No existe evidencia suficiente para descartar el statu quo. Fallamos en rechazar la hipótesis nula.
20. Representación en Distribuciones Continuas y el Límite de las Dos Desviaciones Estándar
Para muchas pruebas de hipótesis en el sector empresarial —como la evaluación del rendimiento de una campaña de marketing masiva—, el estadístico de prueba bajo la distribución nula adopta de forma asintótica la forma de una Distribución Normal Estándar (con media $\mu = 0$ que representa la ausencia total de efecto, y desviación estándar $\sigma = 1$).
Si configuramos una prueba bidireccional estándar con un nivel de significancia de $\alpha = 0.05$, estamos delimitando que la Región de Aceptación abarca el 95% central de la densidad de probabilidad.
El Límite Crítico: Según las propiedades geométricas de la curva normal, el 95% de los resultados posibles se concentran a una distancia de aproximadamente dos desviaciones estándar ($\pm 1.96\sigma$) respecto a la media cero.
El Mecanismo de Inferencia: Si al procesar los datos de nuestra campaña publicitaria el estadístico resultante se ubica en el centro de la curva, el valor p será alto; concluimos que el movimiento se debe a la volatilidad natural del mercado y no a la campaña. Sin embargo, si el estadístico se desplaza más allá de las dos desviaciones estándar hacia los extremos (las colas de la distribución), el valor p caerá por debajo del 0.05, otorgándonos el fundamento estadístico para rechazar $H_0$ y confirmar el éxito de la estrategia.
21. Aplicación Práctica: Evaluación de Sesgo en el Lanzamiento de Monedas
Para consolidar el mecanismo matemático del valor p en distribuciones discretas, retomemos el experimento controlado donde sospechamos que una moneda podría estar sesgada negativamente (generando menos caras de lo normal).
1. Modelado Estadístico
Establecemos formalmente los parámetros del test:
Hipótesis Nula ($H_0$): La moneda es justa y equilibrada. $p = 0.5$.
Hipótesis Alternativa ($H_1$): La moneda está sesgada en detrimento de las caras. $p < 0.5$ (Prueba de una sola cola).
Nivel de Significancia Crítico: Seleccionamos el estándar de la industria: $\alpha = 0.05$.
2. Ejecución y Datos Muestrales
Se realiza un muestreo compuesto por 10 lanzamientos ($n = 10$). Tras ejecutar la prueba, se observa un resultado de únicamente 3 caras ($X = 3$).
3. Cálculo de la Función de Distribución Acumulada (CDF)
Bajo la premisa de la hipótesis nula, el número de caras se rige por una distribución binomial $X \sim \text{Binomial}(n=10, p=0.5)$. Para hallar el valor p, debemos calcular la probabilidad acumulada de obtener un resultado tan o más extremo que 3 caras (es decir, la suma de las probabilidades exactas de obtener 0, 1, 2 o 3 caras):
Efectuamos el contraste formal frente a nuestro umbral preestablecido:
$$\text{Valor P } (0.1719) > \alpha \text{ (0.05)}$$
Dictamen Estadístico: Dado que el valor p ($17.19\%$) es marcadamente superior a nuestro nivel de significancia del $5\%$, fallamos en rechazar la hipótesis nula ($H_0$).
A pesar de que observar 3 caras en 10 lanzamientos puede parecer intuitivamente bajo, el análisis matemático demuestra que este escenario ocurre de forma completamente aleatoria casi 1 de cada 6 veces bajo condiciones normales. No disponemos de evidencia estadística suficiente para afirmar que la moneda está trucada; el resultado se acepta como una fluctuación esperable dentro del margen de variación de la distribución binomial.
Resumen del Bloque y Próximos Pasos
En esta sección hemos formalizado las métricas definitivas del modelo frecuentista:
El papel del Nivel de Significancia ($\alpha$) como el regulador de riesgo de falsos positivos decidido a priori.
La naturaleza del Valor P como indicador de la anomalía de los datos muestrales respecto a la hipótesis nula.
La resolución de un contraste práctico a través del cálculo de la probabilidad acumulada en una distribución binomial.
En el próximo apartado, exploraremos las implicaciones críticas del tamaño muestral en estos cálculos y analizaremos cómo el volumen de datos afecta directamente la sensibilidad y la potencia de nuestras pruebas en entornos de producción.
22. El Estadístico F en Modelos de Regresión Lineal
Cuando construimos un modelo de regresión lineal múltiple en Data Science, no solo nos interesa evaluar cada variable predictora de forma aislada, sino determinar si el conjunto de características (features) aporta valor predictivo real. Para este propósito se utiliza el Estadístico F.
Hipótesis Nula ($H_0$): Todos los coeficientes de regresión (los parámetros $\beta$) son iguales a cero ($\beta_1 = \beta_2 = \dots = \beta_k = 0$). Esto implica que el modelo propuesto no tiene capacidad predictiva y que la mejor estimación para la variable objetivo es, simplemente, su media muestral ($\bar{Y}$).
Hipótesis Alternativa ($H_1$): Al menos un coeficiente $\beta$ es diferente de cero, lo que significa que añadir esas variables mejora significativamente la explicación del modelo en comparación con usar únicamente la media.
Al ejecutar un análisis de regresión en librerías como statsmodels en Python, el reporte devuelve un valor numérico para el Estadístico F junto a su respectivo valor p (Prob (F-statistic)). Si este valor p es extremadamente bajo (menor a nuestro $\alpha$), rechazamos la hipótesis nula. Esto nos da la certeza estadística de que los componentes del modelo capturan un efecto real sobre la variable de salida, justificando la inclusión de las variables en la estrategia analítica.
23. El Problema de las Comparaciones Múltiples y la Inflación del Error de Tipo I
Un error crítico al diseñar experimentos A/B o pruebas de hipótesis en el sector empresarial es ejecutar múltiples contrastes simultáneos utilizando el mismo nivel de significancia estándar ($\alpha = 0.05$) sin realizar ajustes.
Si realizamos una sola prueba, la probabilidad de no cometer un Error de Tipo I (mantener correctamente la hipótesis nula cuando es verdadera) es de $1 – 0.05 = 0.95$. Sin embargo, si ejecutamos un número $m$ de pruebas independientes, la probabilidad de que al menos una de ellas arroje un falso positivo por puro azar se incrementa exponencialmente según la ecuación:
$$P(\text{Al menos un Error Tipo I}) = 1 – (1 – \alpha)^m$$
Para un volumen de pruebas moderado, podemos aproximar esta probabilidad de forma lineal como:
$$P(\text{Al menos un Error Tipo I}) \approx \alpha \times m \quad (\text{para } m \le 10)$$
Escenario de Riesgo en el Entorno Corporativo
Si un equipo de producto lanza un experimento y decide testear 10 variaciones de diseño independientes (o analiza 10 métricas distintas a la vez) fijando $\alpha = 0.05$ para cada una, la tasa de error global del experimento (Family-Wise Error Rate o FWER) se dispara a:
Existe más de un 40% de probabilidad de concluir erróneamente que una de las variantes genera un impacto positivo en el negocio, cuando en realidad el resultado fue producto de la volatilidad y el ruido aleatorio de la muestra.
24. La Corrección de Bonferroni
Para mitigar la inflación del Error de Tipo I en escenarios de pruebas múltiples, implementamos la Corrección de Bonferroni. Este método ajusta el umbral de decisión dividiendo el nivel de significancia original ($\alpha$) entre el número total de comparaciones o pruebas ejecutadas ($m$):
$$\alpha_{\text{ajustado}} = \frac{\alpha}{m}$$
Si volvemos al escenario de las 10 pruebas simultáneas con un $\alpha$ inicial de $0.05$, el nuevo umbral crítico para cada prueba individual será:
Bajo este criterio riguroso, solo se rechazará la hipótesis nula en una prueba si su valor p individual es inferior a $0.005$, garantizando que la probabilidad global de cometer un falso positivo en todo el conjunto de pruebas se mantenga firmemente bajo el control del $5\%$.
El Costo de la Corrección: Pérdida de Potencia
Aunque la corrección de Bonferroni protege la integridad del experimento frente a falsos positivos, introduce un desafío metodológico: vuelve el test extremadamente conservador. Al reducir drásticamente el umbral de rechazo, penaliza la potencia estadística ($1 – \beta$).
Como consecuencia, se vuelve mucho más difícil detectar efectos reales (falsos negativos), a menos que se cumpla una de las siguientes dos condiciones:
El tamaño del efecto en el mercado sea sumamente grande y evidente.
Se incremente considerablemente el tamaño de la muestra para dotar al test de la sensibilidad requerida.
Buena Práctica en Data Science: La estrategia óptima en el ámbito empresarial no consiste en lanzar cientos de pruebas simultáneas confiando en las correcciones estadísticas, sino en limitar el diseño experimental a unos pocos casos de uso bien fundamentados, con hipótesis claras y un tamaño muestral debidamente dimensionado antes de la ejecución.
Conclusión del Bloque Teórico
A lo largo de este capítulo hemos cubierto la estructura analítica de la estadística frecuentista:
El uso del Estadístico F para validar la arquitectura global de nuestros modelos de regresión.
Los peligros operativos del P-hacking y la inflación del Error de Tipo I al realizar comparaciones múltiples.
La aplicación de la Corrección de Bonferroni como mecanismo de control del riesgo corporativo y su impacto directo en la potencia del test.
Con esta sólida base conceptual, estamos listos para pasar a la implementación técnica. En el próximo módulo, trasladaremos estos fundamentos a la práctica mediante el uso de un entorno de programación en Python, donde ejecutaremos contrastes de hipótesis reales y automatizaremos el cálculo de estas métricas sobre estructuras de datos empresariales.
25. Correlación frente a Causalidad: La Regla de Oro del Análisis de Datos
En el ámbito de la Ciencia de Datos y la Inteligencia de Negocios, confundir la correlación con la causalidad es uno de los errores metodológicos más comunes y costosos.
Correlación: Es una medida estadística que describe la relación o el grado de asociación lineal entre dos variables ($X$ e $Y$). Si $X$ e $Y$ están correlacionadas, significa que cuando el valor de $X$ cambia, el valor de $Y$ tiende a cambiar en una dirección específica (ya sea positiva o negativamente).
Causalidad: Implica un mecanismo físico u operativo de causa y efecto. Significa que el cambio en la variable $X$ provoca de manera directa la variación en la variable $Y$.
El Valor Predictivo de la Correlación Sin Causalidad
Es completamente factible utilizar una variable $X$ fuertemente correlacionada para predecir el comportamiento de $Y$ dentro de un modelo de Machine Learning, incluso si no existe un vínculo causal directo entre ambas. La correlación aporta valor informativo y mejora la precisión del modelo en escenarios de predicción pasiva.
Sin embargo, depender exclusivamente de la correlación para la toma de decisiones activas es peligroso. Si modificamos el valor de $X$ con la expectativa de alterar el resultado de $Y$ sin que exista una relación causal real, el modelo fallará, la métrica objetivo no se moverá y la estrategia corporativa se verá comprometida debido a que el mecanismo subyacente no responde a esa palanca operativa.
26. Anatomía de una Relación de Asociación
Cuando los datos muestran una correlación matemática estadísticamente significativa entre $X$ e $Y$, dicha asociación puede deberse a cuatro escenarios analíticos distintos:
1. Causalidad Directa: [ X ] ─────────────────────────> [ Y ]
2. Causalidad Inversa: [ X ] <───────────────────────── [ Y ]
3. Variable Confusora: [ X ] <─── [ Confusora (Z) ] ───> [ Y ]
4. Relación Espuria: [ X ] . . . (Mero Azar) . . . . [ Y ]
1. Causalidad Directa ($X \rightarrow Y$)
La variable predictora causa el resultado de forma lineal.
Ejemplo corporativo: Un incremento planificado en el presupuesto de marketing directo ($X$) genera de manera directa un aumento en los ingresos por ventas de la compañía ($Y$).
2. Causalidad Inversa ($Y \rightarrow X$)
El sentido de la causalidad está invertido; es la variable de salida la que modela a la entrada.
Ejemplo corporativo: El análisis muestra que las partidas presupuestarias de marketing ($X$) aumentan cuando los ingresos ($Y$) son altos, debido a que la empresa reinvierte un porcentaje fijo de sus ganancias mensuales en publicidad. Modificar el presupuesto a la fuerza no garantizará más ingresos si la dirección real del flujo de caja es la opuesta.
3. Presencia de una Variable Confusora ($X \leftarrow Z \rightarrow Y$)
Un tercer factor externo y oculto ($Z$) influye y modifica simultáneamente a ambas variables, creando una ilusión de conexión directa.
Ejemplo corporativo: El gasto en publicidad digital ($X$) y las conversiones orgánicas de la web ($Y$) aumentan al mismo tiempo. El factor causante real es la campaña navideña ($Z$), que empuja de manera natural tanto las decisiones de inversión del equipo como la intención de compra del consumidor.
4. Correlación Espuria
La relación matemática es una mera coincidencia estadística propia de la muestra recolectada; no existe lógica de negocio ni conexión estructural alguna.
27. El Impacto Operativo de las Variables Confusoras (Confounding Variables)
Una variable confusora es un factor externo que altera los resultados de un análisis al correlacionarse simultáneamente con la variable independiente ($X$) y la variable dependiente ($Y$). Si no se aísla o controla este efecto en el diseño experimental, las conclusiones del negocio serán erróneas.
Ejemplos Clásicos de Confusión Estadísticamente Válidos
El sesgo demográfico en accidentes: Existe una correlación positiva perfecta entre el número de accidentes de tráfico anuales ($X$) y la cantidad de personas que se llaman “Juan” ($Y$). La variable confusora evidente es el tamaño de la población ($Z$): a mayor población, aumentan exponencialmente ambas métricas por pura probabilidad demográfica.
El caso del clima y el consumo: Las ventas de helados ($X$) y el volumen de ahogamientos semanales ($Y$) muestran una correlación matemática muy robusta. Evidentemente, comer helado no causa ahogamientos. La variable confusora real es la temperatura ambiental ($Z$): el calor extremo incrementa la venta de helados y, simultáneamente, empuja a más personas a bañarse en playas y piscinas, elevando el riesgo de accidentes acuáticos.
Capacidad Productiva frente a Demanda: En el sector tecnológico, el número de fábricas activas de un fabricante de microchips ($X$) correlaciona con el volumen neto de chips vendidos en el mercado ($Y$). Un analista de BI descuidado podría sugerir: “Construyamos más infraestructuras para forzar más ventas”. Sin embargo, el motor causal es la demanda global del mercado ($Z$). Construir fábricas sin tracción de mercado aumentará el inventario inmovilizado ($X$), pero no las ventas reales ($Y$).
28. Correlaciones Espurias y el Peligro de las Series Temporales
Las correlaciones espurias se consolidan cuando dos variables totalmente independientes muestran un coeficiente de correlación lineal cercano a $r = 1.0$ o $r = -1.0$ debido a anomalías en el muestreo o dinámicas inerciales del tiempo.
El sitio web de Tyler Vigen recopila ejemplos matemáticos reales basados en datos públicos de Estados Unidos que ilustran este fenómeno:
Variable Independiente (X)
Variable Dependiente (Y)
Coeficiente de Correlación (r)
Edad de la ganadora de Miss America
Asesinatos causados por vapor, vapores calientes y objetos calientes
0.87
Lanzamientos espaciales no comerciales a nivel mundial
Doctorados en Sociología otorgados
0.78
La Trampa del Factor Tiempo (Time-Trend Bias)
¿Por qué variables tan absurdas muestran una correlación del 87%? El factor subyacente en la analítica del mundo real es el sesgo de tendencia temporal. Si dos variables macroeconómicas, demográficas o de negocio experimentan una trayectoria sostenida de crecimiento o decrecimiento a lo largo de una década debido al desarrollo tecnológico, la inflación o el aumento poblacional, el cálculo matemático de la correlación arrojará un valor alto, aunque los mecanismos lógicos subyacentes no tengan ninguna relación entre sí.
29. Errores de Interpretación de Métricas en Producto y Atención al Cliente
Llevar estos conceptos al día a día del negocio ayuda a evitar decisiones de gestión contraproducentes. Evaluemos dos casos típicos de interpretación errónea de métricas:
Caso 1: Calificaciones Académicas y Horas de Estudio
Observación: Existe una correlación positiva entre las horas que un estudiante pasa repasando y sus notas finales.
Mala interpretación: Un comité decide implementar una “curva generalizada de aprobados” asumiendo que elevar artificialmente las notas inyectará motivación y provocará que los alumnos estudien más horas en el futuro.
Mecanismo real: El estudio enfocado es la causa directa de la adquisición de conocimiento, lo que se traduce en un examen sobresaliente. Alterar la métrica de salida ($Y$) rompiendo el flujo causal solo generará complacencia y reducirá el esfuerzo real ($X$).
Caso 2: Experiencia de Usuario (UX) y Volumen de Soporte
Observación: El índice de Satisfacción del Cliente (CSAT) está fuertemente correlacionado de forma negativa con el volumen de llamadas recibidas en los centros de soporte técnico de la compañía. A más llamadas, menor satisfacción.
Mala interpretación: Para “mejorar la satisfacción”, el equipo de operaciones decide eliminar el número de teléfono de soporte de la cabecera de la página web y esconder el formulario de contacto detrás de un laberinto de preguntas frecuentes, asumiendo que reducir el volumen de llamadas ($X$) incrementará la felicidad del cliente ($Y$).
Mecanismo real: La insatisfacción o los fallos técnicos en el producto son la causa raíz que obliga al usuario a saturar las líneas de soporte. Bloquear el canal de comunicación no soluciona el error del producto; por el contrario, incrementa la frustración y deteriora la métrica real del negocio.
Resumen Final del Curso Estadístico
Con este bloque cerramos la revisión de fundamentos estadísticos para la toma de decisiones:
Diseñamos e interpretamos Pruebas de Hipótesis bajo un enfoque frecuentista.
Evaluamos los riesgos de los Errores de Tipo I y II, controlando la inflación de falsos positivos mediante la Corrección de Bonferroni.
Validamos la consistencia global de modelos a través del Estadístico F.
Blindamos nuestro criterio analítico diferenciando la Correlación predictiva de la Causalidad operativa para evitar sesgos por variables confusoras o tendencias espurias.
Felicidades por completar este trayecto teórico. Ahora dispones de la estructura mental y matemática necesaria para diseñar experimentos rigurosos, analizar datos de mercado con objetividad científica y liderar estrategias de Inteligencia de Negocios basadas en evidencia estadística sólida.
Introducción a Conceptos Estadísticos Fundamentales
Comenzamos un nuevo bloque enfocado en los principios estadísticos básicos. Estos conceptos son imprescindibles tanto para avanzar con paso firme en el aprendizaje automático (Machine Learning) como para fundamentar la toma de decisiones basada en datos dentro de cualquier organización.
Objetivos de Aprendizaje de este Bloque
Estimación frente a Inferencia: Comprender la diferencia entre calcular un valor métrico puntual y deducir el comportamiento global de una población.
Modelado Paramétrico y No Paramétrico: Distinguir los enfoques algorítmicos que asumen una estructura matemática fija de aquellos que se adaptan libremente a la forma de los datos.
Distribuciones Estadísticas Comunes: Identificar los patrones y estructuras de datos más frecuentes en entornos reales.
Estadística Frecuentista frente a Bayesiana: Introducir las dos grandes filosofías e interpretaciones de la probabilidad.
Estimación frente a Inferencia Estadística
Es común confundir estos dos términos, pero representan alcances analíticos profundamente diferentes.
Estimación (Estimation)
La estimación consiste simplemente en calcular un parámetro específico (como la media o la varianza) utilizando exclusivamente los datos disponibles en nuestra muestra. Un estimador puntual nos da un único valor numérico.
Por ejemplo, la media muestral (\(\bar{x}\)) se calcula mediante la suma de todos los valores observados en una columna dividida por el número total de observaciones (\(n\)):
$$\bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i$$
La estimación se limita a describir y resumir numéricamente la muestra que tenemos sobre la mesa.
Inferencia Estadística (Inference)
La inferencia es un proceso mucho más amplio. Su objetivo no es solo calcular un número, sino comprender la distribución subyacente de la población completa a partir de una muestra pequeña, midiendo el grado de incertidumbre de dicha afirmación.
Para lograrlo, la inferencia evalúa otras propiedades estadísticas fundamentales como el error estándar (\(SE\)), el cual mide cuánto varía la media muestral respecto a la verdadera media poblacional.
3. Convergencia con el Machine Learning
El Machine Learning y la inferencia estadística están íntimamente entrelazados; de hecho, gran parte del ML moderno se construyó sobre los cimientos matemáticos de la estadística tradicional, mucho antes de que existiera la capacidad de cómputo actual.
En ambas disciplinas se utiliza una muestra de datos histórica para deducir las cualidades de un proceso generador de datos en el mundo real.
Proceso Generador de Datos (Mundo Real / Población) │ ▼ [Muestreo] Muestra de Datos │ ┌───────────────────────┴───────────────────────┐ ▼ ▼Inferencia Estadística Machine LearningEnfoque: Comprender parámetros Enfoque: Optimizar prediccionesy efectos individuales. y métricas de salida.
Los modelos de ML enfocados en la interpretabilidad (entender el impacto exacto de cada variable) dependen por completo de herramientas de inferencia estadística.
Los modelos de ML enfocados puramente en el rendimiento predictivo (cajas negras) minimizan la interpretación de los parámetros internos y se centran casi exclusivamente en la optimización del resultado final (estimaciones puntuales).
Caso de Negocio: Predicción de Abandono de Clientes (Customer Churn)
Para aterrizar estos conceptos en el ámbito empresarial, utilizaremos un caso de estudio clásico: la predicción del Churn (abandono de clientes). En este escenario, buscamos identificar qué usuarios tienen una alta probabilidad de cancelar sus contratos para actuar antes de que se marchen.
Variable Objetivo (\(y\)): Variable binaria que indica si el cliente abandonó la empresa (1) o permaneció en ella (0).
Variables Predictoras o Características (\(X\)): * Antigüedad del cliente (tiempo de permanencia).
Tipo y volumen financiero de las compras realizadas.
El modelo analiza estas variables y genera un score de riesgo para cada individuo, el cual representa la probabilidad matemática de abandono (donde 0.99 indica un abandono casi seguro y 0.01 indica fidelidad absoluta).
Aplicación Práctica: Estimación vs. Inferencia en Churn
¿Cómo se comportan la estimación y la inferencia al analizar la variable de antigüedad del cliente en este modelo?
El Enfoque de la Estimación
El modelo nos ofrece una estimación puntual del impacto de la característica:
“Por cada año adicional que un usuario permanece como cliente, la probabilidad de abandono disminuye en un 20%.”
El Enfoque de la Inferencia
La inferencia no se conforma con ese 20%. Expande el análisis calculando la significancia estadística y un intervalo de confianza (IC) del 95% para evaluar la certidumbre de ese número. Esto puede dar lugar a dos escenarios muy distintos:
Escenario A: Alta Certeza Estadísticas
Resultado del IC (95%): Entre 19% y 21%.
Interpretación: El intervalo es estrecho y rodea de cerca nuestra estimación del 20%. Podemos concluir con alta confianza que la antigüedad tiene un efecto protector real, sólido y predecible sobre la retención de clientes.
Escenario B: Alta Incertidumbre (Baja Significancia)
Resultado del IC (95%): Entre -10% (el riesgo sube) y 50% (el riesgo baja drásticamente).
Interpretación: Aunque la estimación puntual inicial fue del 20%, el intervalo nos revela que no hay datos suficientes para sostenerla. El efecto real podría ser negativo o extremadamente alto; la variabilidad es tan grande que la estimación carece de validez estadística para la toma de decisiones estratégicas.
Caso de Estudio Práctico: Datos de Churn en Telecomunicaciones
Para profundizar en el análisis exploratorio de datos (EDA) orientado a la inferencia, trabajaremos con el dataset ficticio Telco Customer Churn de IBM Cognos Analytics. Este conjunto de datos registra las características operacionales y demográficas de los clientes de una compañía de telecomunicaciones.
Variables Principales del Dataset
El set de datos se encuentra estructurado dentro de un DataFrame de Pandas bajo la variable df_phone y contiene las siguientes características (features):
Características de Cuenta: Tipo de contrato y método de pago elegido.
Métricas de Ingreso: Facturación mensual y el Valor del Tiempo de Vida del Cliente (CLTV), que calcula la suma total de ingresos que el usuario representa durante toda su relación comercial con la empresa.
Métricas de Satisfacción: Puntuación de satisfacción otorgada por el usuario.
Uso de Datos: Gigabytes mensuales consumidos.
Variable Objetivo (churn_value): Binaria. Indica si el cliente abandonó la compañía (1) o permaneció activo (0).
Categorías de Abandono: Clasificación del tipo de baja (por ejemplo, cancelación activa frente a la no renovación de una suscripción).
Análisis Exploratorio de Datos (EDA) para Inferencia
A través de la visualización de datos, buscaremos inferir de manera preliminar qué factores influyen en la retención de los usuarios.
Impacto del Método de Pago en el Abandono
Utilizando gráficos de barras, analizamos la tasa de abandono en función del método de pago.
Al examinar la gráfica, surge un patrón claro: los clientes que pagan con tarjeta de crédito presentan una probabilidad de abandono significativamente menor en comparación con aquellos que utilizan transferencias bancarias automatizadas o cheques por correo. El método de pago sirve como un indicador inicial del nivel de vinculación del cliente.
Segmentación de la Antigüedad con pd.cut
Para evaluar cómo influye el tiempo de permanencia en el abandono mediante un gráfico de barras, es necesario transformar la variable continua de meses en rangos discretos o categorías. La función pd.cut() de Pandas divide la columna de meses en 5 contenedores (bins) de igual longitud:
import pandas as pdimport seaborn as sns# Segmentar la variable continua de meses en 5 rangos categóricosdf_phone['rango_meses'] = pd.cut(df_phone['months_as_customer'], bins=5)# Graficar el porcentaje de abandono por cada rango de antigüedadsns.barplot(x='rango_meses', y='churn_value', data=df_phone)
La visualización de estos bloques revela una relación inversamente proporcional: los usuarios que se encuentran en el primer bloque (menor antigüedad, entre $0$ y $15$ meses) muestran la tasa de abandono más alta. A medida que el cliente supera los umbrales de tiempo y avanza hacia los bloques de mayor permanencia, la probabilidad de churn cae drásticamente.
Visualización de Relaciones Multivariables
Gráfico de Pares (Pair Plot)
El gráfico de pares (sns.pairplot) permite evaluar las distribuciones individuales y los cruces cruzados de múltiples variables numéricas simultáneamente. En este análisis seleccionamos: la antigüedad en meses, los gigabytes consumidos, el ingreso total, el CLTV y la variable objetivo.
Para segmentar la información, aplicamos el parámetro hue='churn_value', el cual divide y colorea los datos según su estado de permanencia:
Azul (0): Clientes retenidos (Permanecen en la empresa).
Verde (1): Clientes perdidos (Churn).
Al observar las esquinas de la matriz de gráficos (especialmente el cruce de antigüedad), se aprecia visualmente cómo la masa de puntos verdes (bajas) se concentra fuertemente en los valores de tenencia más bajos, confirmando de manera gráfica la consistencia del comportamiento de abandono temprano.
Densidad con Gráficos Hexagonales (Hexbin Joint Plot)
Cuando manejamos miles de registros, los gráficos de dispersión tradicionales sufren de saturación de puntos (overplotting), impidiendo ver dónde se concentra la mayor densidad de la población. Para resolverlo, el gráfico de compartimentos hexagonales (hexbin) agrupa los puntos en celdas hexagonales y asigna una intensidad de color proporcional a la cantidad de registros en esa zona.
Evaluamos el cruce entre la antigüedad en meses ($x$) y el cargo mensual ($y$) mediante un sns.jointplot:
Python
# Crear un gráfico de densidad hexagonal con distribuciones marginalessns.jointplot(x='months_as_customer', y='monthly_charge', data=df_phone, kind='hex')
El gráfico muestra las distribuciones de cada variable en los márgenes superior y derecho, revelando una estructura con dos grandes focos de alta densidad (colores más oscuros):
Zona Superior Derecha: Representa un grupo denso de clientes consolidados, caracterizados por una alta antigüedad y cargos mensuales elevados.
Zona Inferior Izquierda / Media: Revela un volumen importante de clientes nuevos (poca antigüedad) que ingresan directamente con tarifas mensuales superiores al promedio.
Zona Intermedia: Presenta una densidad notablemente baja, lo que indica que hay pocos clientes en situaciones intermedias de precio y permanencia.
Este análisis exploratorio nos proporciona una perspectiva clara sobre las dinámicas de la cartera de clientes. En la siguiente sección, profundizaremos en los fundamentos teóricos que diferencian a los modelos bajo los enfoques de Estadística Paramétrica y No Paramétrica.
Modelos Paramétricos vs. No Paramétricos
Dentro del campo de la inferencia estadística y el aprendizaje automático, los modelos se dividen en dos grandes filosofías dependiendo de las suposiciones que hagamos sobre el proceso generador de datos.
A. Modelos Paramétricos
Un modelo paramétrico asume que los datos siguen una estructura matemática predefinida y conocida.
Características principales: Sus parámetros son finitos y fijos (no cambian de número según el tamaño de la muestra). Además, dependen de supuestos estrictos sobre la distribución de origen.
Ejemplos: * Regresión Lineal por Mínimos Cuadrados Ordinarios (OLS): Antes de entrenar, fijamos el número de coeficientes (\(\beta\)) según el número de características. El modelo asume rígidamente una relación lineal y que los residuos se distribuyen normalmente.
Distribución Normal: Se define por una ecuación matemática exacta que depende únicamente de dos parámetros: la media (\(\mu\)) y la desviación estándar (\(\sigma\)).
Ventaja: Al tener restricciones fuertes, son matemáticamente más sencillos y rápidos de resolver con pocos datos.
Desventaja: Si los datos reales no cumplen las suposiciones teóricas (por ejemplo, si la relación no es lineal), el modelo arrojará resultados sesgados y erróneos.
Modelos No Paramétricos
Los modelos no paramétricos no limitan los datos a una forma geométrica o matemática rígida. Se conocen también como modelos de inferencia libre de distribución (distribution-free inference).
Características principales: El número de parámetros puede crecer a medida que recopilamos más datos. No asumen curvas preestablecidas (como una campana de Gauss o una línea recta), sino que construyen la forma basándose directamente en la muestra disponible.
Ejemplo visual: La creación de un histograma para aproximar la Función de Distribución Acumulada (CDF). No forzamos a los datos a ser normales; dejamos que las barras del histograma tracen la verdadera silueta del fenómeno.
Ventaja: Alta flexibilidad para modelar relaciones extremadamente complejas en el mundo real.
Desventaja: Requieren volúmenes de datos mucho mayores para alcanzar conclusiones sólidas y estables.
Aplicación al Caso de Negocio: Valor del Tiempo de Vida del Cliente (CLTV)
El Customer Lifetime Value (CLTV) estima el valor financiero neto que un usuario aportará a la empresa a lo largo de toda su relación comercial. Calcularlo requiere predecir dos factores de alta incertidumbre: cuánto tiempo se mantendrá activo el cliente y cuánto gastará en ese periodo.
Enfoque Paramétrico: Podríamos asumir que el gasto del cliente decae de forma estrictamente lineal o exponencial con el tiempo. Ajustamos los datos a esa fórmula fija y proyectamos el CLTV. Es útil si tenemos pocos datos históricos.
Enfoque No Paramétrico: No asumimos ninguna curva de decaimiento. Dejamos que algoritmos avanzados analicen los patrones masivos de comportamiento de los usuarios históricos para trazar libremente las tendencias de gasto, sin importar qué tan irregulares sean. Reclama bases de datos muy robustas.
Estimación por Máxima Verosimilitud (MLE)
En los modelos paramétricos, el método estándar para calcular los parámetros óptimos es la Estimación por Máxima Verosimilitud (Maximum Likelihood Estimation o MLE).
La función de verosimilitud invierte la lógica tradicional de la probabilidad: toma los datos observados en nuestra muestra como un hecho fijo y se pregunta: “¿Cuáles tendrían que ser los parámetros reales (\(\mu\) y \(\sigma\)) de la población para que esta muestra específica sea lo más probable de ocurrir?”
El algoritmo calcula y selecciona los valores exactos de los parámetros que maximizan esa probabilidad estructural.
Distribuciones Estadísticas Comunes en el Mundo Real
A continuación, analizaremos las formas y comportamientos de las distribuciones más utilizadas para describir fenómenos reales:
Distribución Uniforme
Todos los resultados posibles dentro de un rango definido tienen exactamente la misma probabilidad de ocurrir.
Ejemplo clásico: Lanzar un dado de 6 caras. Obtener un 1 tiene la misma probabilidad (\(\frac{1}{6}\)) que obtener un 3, un 4 o un 6. La gráfica de densidad es completamente plana.
Distribución Normal (o Gaussiana)
Es la célebre curva en forma de campana. Los valores más probables se concentran fuertemente alrededor de la media ($\mu$). Conforme nos alejamos de ella hacia los extremos izquierdo o derecho, la probabilidad disminuye de manera simétrica.
Parámetros: La media determina la ubicación del centro en el eje gráfico; la desviación estándar determina la dispersión. Una desviación pequeña genera una curva alta y estilizada; una desviación grande produce una campana achatada y extendida.
Teorema del Límite Central: Es la razón de su popularidad. Establece que si extraemos múltiples muestras aleatorias de cualquier población (incluso de una con una distribución no normal) y calculamos sus medias, la distribución de esas medias muestrales convergerá hacia una distribución normal a medida que el tamaño de la muestra aumente.
Ejemplo real: La estatura de la población humana. La mayoría se sitúa cerca del promedio, siendo extremadamente raro encontrar personas de 2.20 metros o de 1.10 metros.
Distribución Log-Normal
Ocurre cuando la variable original presenta un fuerte sesgo positivo (una cola larga hacia la derecha), pero al aplicar una transformación logarítmica sobre ella, los valores resultantes adoptan una distribución normal perfecta.
Relación con la dispersión: Si la desviación estándar es muy pequeña, la curva se comprime y se asemeja bastante a una normal; si es grande, la cola derecha se extiende notablemente.
Ejemplo real: La distribución de los ingresos económicos de un país. La mediana se sitúa en rangos de clase media o trabajadora (parte alta de la curva a la izquierda), pero existe una cola larga hacia la derecha provocada por los ingresos extraordinarios de los multimillonarios.
Distribución Exponencial
Describe variables continuas donde los valores más altos se agrupan en el extremo izquierdo y decaen de forma constante a lo largo del eje. Se utiliza principalmente para medir el tiempo transcurrido entre eventos sucesivos.
Ejemplo real: El tiempo de espera entre las reproducciones de este video. Es muy común que un usuario entre un minuto después del anterior; sin embargo, es poco probable (cola larga) que transcurran intervalos de 15 o 20 minutos sin registros antes de que llegue el siguiente espectador.
E. Distribución de Poisson
A diferencia de la exponencial, la distribución de Poisson es discreta y mide el número de veces que ocurre un evento dentro de un intervalo constante de tiempo o espacio.
Parámetro Lambda (\(\lambda\)): Representa simultáneamente la media y la varianza de los datos.
Ejemplo real: ¿Cuántos usuarios reproducirán este video en los próximos 10 minutos? Si \(\lambda = 1\), la densidad se concentrará de forma estrecha indicando que lo habitual es recibir un solo usuario en ese lapso. Si \(\lambda = 10\), la desviación estándar se ensancha, abriendo la posibilidad de registrar de forma habitual entre 5 y 15 usuarios por intervalo.
Estadística Frecuentista vs. Estadística Bayesiana
La distinción entre la estadística frecuentista y la bayesiana radica en cómo interpretan el concepto de probabilidad. Mientras que una se enfoca en la repetición infinita de experimentos, la otra modela la probabilidad como un grado de creencia que se actualiza con la evidencia.
Para entender la diferencia operativa en el entorno empresarial, utilizaremos como analogía la Teoría de Colas (Queuing Theory).
¿Qué es la Teoría de Colas?
Es el estudio matemático de las líneas de espera. Permite a las empresas calcular cuántos recursos o “servidores” necesitan para procesar una demanda y evitar cuellos de botella.
Ejemplos: Determinar cuántos cajeros abrir en un supermercado, cuántos servidores web desplegar para responder peticiones sin caídas, o cuántos agentes de soporte asignar a un centro de llamadas.
Tanto bajo el enfoque frecuentista como el bayesiano, el flujo de llegada de clientes en un tiempo fijo se modela mediante una Distribución de Poisson. Sin embargo, la estimación del parámetro $\lambda$ (la tasa promedio de llegadas) se aborda de formas completamente distintas.
El Enfoque Frecuentista
Para un frecuentista, la probabilidad está ligada a la frecuencia relativa a largo plazo de un evento mediante la repetición matemática infinita de un experimento.
Supuesto Inicial: Se inicia el análisis sin ninguna idea previa (prior) sobre la probabilidad o el parámetro que se desea estimar.
El Parámetro es Fijo: En la población real, el parámetro verdadero (por ejemplo, el promedio exacto de clientes que llegan por minuto) es un valor único, fijo e inmutable.
Dependencia de la Muestra: La estimación se deriva directamente de los datos observados, sin influencias externas. La incertidumbre no recae en el parámetro, sino en la muestra: nos preguntamos qué tan probable es que nuestro muestreo haya “capturado” el parámetro real de la población.
En la Teoría de Colas: No asumimos saber cuántos clientes visitan la tienda. Registramos meticulosamente los tiempos de espera durante semanas. Si la muestra es lo suficientemente grande, los datos revelarán por sí solos la tasa de llegada real, permitiendo calibrar la cantidad de servidores.
El Enfoque Bayesiano
Para un bayesiano, la probabilidad no es una frecuencia de eventos repetidos, sino una medida del grado de certeza o creencia que se tiene sobre un fenómeno.
Los Parámetros son Variables Aleatorias: El parámetro real no se considera un número fijo, sino una variable que posee su propia distribución de probabilidad.
Incorporación de Conocimiento Previo (Prior): Permite al analista integrar sus creencias o conocimientos empíricos previos antes de observar los datos actuales.
Actualización Dinámica: A medida que ingresa nueva información, la certeza sobre el parámetro se refina, concentrando la distribución de probabilidad en un rango más estrecho.
El proceso bayesiano sigue un flujo de actualización estructurado:
Distribución Previa (Prior): Nuestra hipótesis u observación empírica inicial (por ejemplo, el gerente estima, por experiencia, que llegan unos 10 clientes por hora).
Evidencia: Los datos duros que se recolectan en tiempo real en el negocio.
Distribución Posterior (Posterior): El resultado de actualizar el Prior con los Datos. Representa la nueva estimación optimizada del parámetro.
En la Teoría de Colas: Permite iniciar operaciones el primer día basándose en una estimación intuitiva o en datos de sucursales similares (Prior). Conforme pasan las horas y el sistema registra las llegadas reales (Datos), el modelo automatiza la actualización hacia una curva de recursos óptima (Posterior).
Resumen del Módulo de Inferencia Estadística
Hemos concluido la base teórica del análisis estadístico inferencial aplicado a la ciencia de datos. A lo largo de estas secciones hemos cubierto:
Inferencia vs. Estimación: Cómo el Machine Learning se enfoca con frecuencia en la precisión de la estimación (predicción), mientras que la inferencia busca desentrañar el proceso biológico o comercial generador de los datos.
Modelos Paramétricos vs. No Paramétricos: El balance entre modelos de parámetros finitos con supuestos rígidos (como la regresión lineal y la estimación por máxima verosimilitud) y la flexibilidad de los modelos libres de distribución.
Distribuciones en el Mundo Real: La identificación y uso práctico de las estructuras Uniforme, Normal, Log-Normal, Exponencial y de Poisson dentro del entorno de negocios (como el cálculo del CLTV).
Frecuentista vs. Bayesiano: Las dos grandes interpretaciones de la probabilidad que dictan cómo estimar la incertidumbre de nuestros parámetros.
En el próximo módulo, aplicaremos estas dos estructuras de pensamiento para profundizar en el desarrollo de Pruebas de Hipótesis (Hypothesis Testing).