Uno de los mayores errores al aprender álgebra lineal es pensar que trata de números, fórmulas y cálculos. Esa es solo la superficie. En realidad, lo que estás aprendiendo es algo mucho más poderoso: cómo interpretar y combinar información.
Para entenderlo, hay que hacer un pequeño cambio de perspectiva. Una ecuación no es una operación. Es una afirmación sobre la realidad. Es una sentencia, \( x+y=10 \), está diciendo: “hay dos cantidades cuya suma es 10”.
En base a esta afirmación, piensa en una ecuación como una oración que describe al mundo:
El perro es negro.
El gato es naranja.
Ambas son sentencias que aportan información y al combinarlas tienes un conjunto de afirmaciones que combinadas te permiten deducir información al igual que un sistema de acuaciones.
Cuando aparece el sistema: combinar información
Imagina que estás resolviendo un problema como si fuera un pequeño caso de investigación. Tienes varias pistas y cada una aporta información parcial. Una pista puede decirte algo genérico, otra puede acotar un poco más, y juntas empiezan a dibujar una imagen más precisa. Eso es exactamente lo que hace un sistema de ecuaciones: combinar piezas de información para reducir la incertidumbre.
Pero no todas las combinaciones de información funcionan igual. Y aquí es donde el álgebra deja de ser mecánica y empieza a ser lógica. Cuando juntas varias sentencias, solo pueden pasar tres cosas:
Que cada nueva ecuación aporte algo distinto y coherente con lo anterior. En ese caso, el sistema converge hacia una única solución. Este es el escenario ideal. En términos matemáticos, el sistema es consistente y determinado. En términos prácticos, tienes suficiente información bien estructurada.
Las sentencias no se contradicen, pero tampoco aportan nada nuevo. Es como si alguien repitiera la misma pista con otras palabras. En matemáticas esto se traduce en ecuaciones dependientes, y el resultado es que no hay una única solución, sino infinitas. Sabes que algo cumple ciertas condiciones, pero no puedes identificarlo de forma única.
Las sentencias se contradicen. Una dice una cosa y otra dice lo contrario. En ese momento, el sistema deja de tener sentido. Has construido una realidad imposible.
🔹 3. Los tres comportamientos posibles (y por qué importan)
Aquí es donde quiero que prestes atención, porque esto es el núcleo conceptual.
Cuando combinas sentencias, solo pueden pasar tres cosas. No cuatro. No cinco. Tres.
Primer caso: las sentencias se complementan
Cada ecuación aporta información nueva. No se repiten, no se contradicen. Se refuerzan.
En ese caso, el sistema converge hacia una única solución.
Esto significa que has descrito la realidad con suficiente precisión como para identificar un único resultado.
Geométricamente, si quieres visualizarlo, es el punto donde dos líneas se cruzan.
Pero no te quedes con la imagen. Quédate con la idea:
Información suficiente y coherente produce una respuesta única.
Segundo caso: las sentencias se repiten
Aquí ocurre algo más sutil. Las ecuaciones no están mal. No hay contradicción. Pero una no aporta nada nuevo respecto a la otra.
Es como si alguien te dijera dos veces lo mismo con palabras distintas.
En ese caso, el sistema no falla, pero tampoco se define completamente. Tienes infinitas soluciones.
No porque el sistema sea incorrecto, sino porque no tienes suficiente información independiente.
Y esto es una idea muy importante: no importa cuántas ecuaciones tengas, sino cuánta información diferente contienen.
Tercer caso: las sentencias se contradicen
Aquí el sistema se rompe.
Una ecuación afirma algo, la otra afirma lo contrario. No existe ningún valor que pueda satisfacer ambas simultáneamente.
Y esto no es un problema de cálculo. Es un problema lógico.
Has construido un sistema imposible.
🔹 4. Qué ocurre cuando pasamos a matrices
Ahora, muchos de vosotros habéis visto matrices como algo técnico: filas, columnas, operaciones…
Pero quiero que lo veáis de otra forma.
Una matriz no es más que una forma de organizar sentencias.
Cada fila → una ecuación → una afirmación
Cada columna → una variable → una dimensión del problema
Y cuando operas con matrices, lo que estás haciendo en realidad es manipular información estructurada.
🔹 5. El concepto de rango (explicado sin fórmulas)
Aquí aparece una palabra que suele intimidar: el rango de una matriz.
Olvida la definición formal por un momento.
Quiero que lo entiendas así:
El rango es el número de sentencias realmente útiles que tienes.
No las que escribiste. Las que aportan información nueva.
Puedes tener 10 ecuaciones, pero si 8 son combinaciones de las otras 2, en realidad solo tienes 2 piezas de información.
Eso es el rango.
Y esto es lo que determina si un sistema tiene solución única, infinitas o ninguna.
🔹 6. Por qué esto es crucial fuera del aula
Ahora viene la parte que normalmente no se explica en matemáticas, pero es donde todo cobra sentido.
Esto mismo ocurre en ciencia de datos.
Un dataset no es más que un conjunto de sentencias:
Cada fila → una observación
Cada columna → una característica
El modelo → una forma de combinar esa información
Si tus datos contienen información repetida, estás en el segundo caso: redundancia.
Si contienen contradicciones, estás en el tercero: inconsistencia.
Y si están bien construidos, estás en el primero: coherencia.
🔹 7. El error más común
Muchos estudiantes —y también muchos profesionales— creen que cuando algo falla, el problema está en el modelo.
No.
En muchísimos casos, el problema está en las sentencias.
Un modelo no puede arreglar un sistema de información mal construido.
Solo puede trabajar con lo que le das.
🔹 8. Cierre de la clase
Quiero que te quedes con esta idea, porque es la que marca la diferencia entre alguien que aplica fórmulas y alguien que entiende lo que hace:
Antes de resolver un sistema, pregúntate:
¿Estas ecuaciones aportan información nueva?
¿Se están repitiendo?
¿Se contradicen?
Si sabes responder eso, resolver el sistema es casi lo de menos.
Porque habrás entendido lo importante:
Las matemáticas no consisten en calcular resultados. Consisten en interpretar información.
En estadística y ciencia de datos, el valor esperado representa el promedio teórico de los resultados posibles de una variable aleatoria. Es una medida fundamental para evaluar decisiones bajo incertidumbre: juegos de azar, inversiones o modelos probabilísticos.
Para entenderlo de manera intuitiva, imagina dos juegos simples.
En el primero, lanzas un dado de seis caras y ganas la cantidad de dólares igual al número que salga.
En el segundo, lanzas una moneda: ganas $6 si sale cara, o $0 si sale cruz.
¿Cuál conviene jugar si quieres maximizar tus ganancias?
2. Representando los juegos como variables aleatorias
Denotemos por:
( D ): el valor aleatorio del dado (posibles valores 1, 2, 3, 4, 5, 6).
( C ): el valor aleatorio del lanzamiento de moneda (posibles valores 0 y 6).
El valor esperado de una variable aleatoria discreta ( X ) se calcula como:
[ E(X) = \sum_{i} x_i , P(x_i) ]
Es decir: multiplicamos cada resultado posible ( x_i ) por su probabilidad ( P(x_i) ), y sumamos todos esos productos.
3. Ejemplo 1: Dado justo
Cada cara tiene probabilidad ( \frac{1}{6} ), y los valores posibles son 1 a 6.
✅ Conclusión: el juego del dado tiene un valor esperado ligeramente mayor ($3.5 vs $3). Si jugamos muchas veces, el dado nos da, en promedio, más ganancia.
5. Ejemplo 3: Dado sesgado
Supongamos ahora que el dado está cargado:
Las probabilidades de sacar 1, 2, 3, 4 o 5 son 0.15 cada una.
Valor esperado dado justo: 3.5
Valor esperado moneda: 3.0
Valor esperado dado sesgado: 3.75
8. Conclusión
El valor esperado es una herramienta esencial para cuantificar el promedio a largo plazo de un proceso aleatorio. Aunque un solo resultado pueda variar, el valor esperado nos dice qué esperar “en promedio” si el experimento se repite muchas veces.
¿Quieres que a este artículo le agregue también una figura o gráfico en Python (por ejemplo, una comparación visual de las distribuciones del dado justo y el sesgado)?
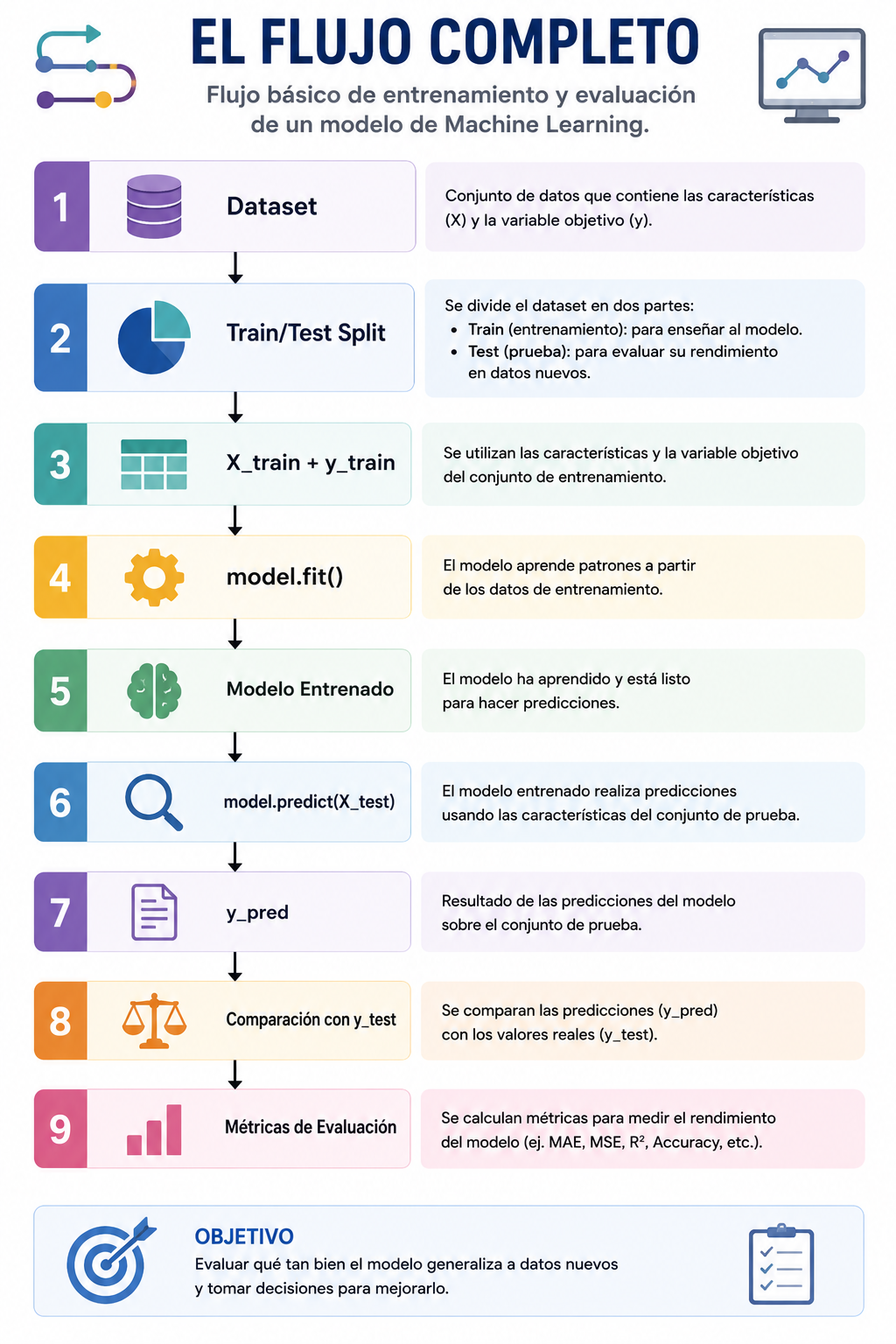
Uno de los objetivos fundamentales de cualquier proyecto de Machine Learning es construir modelos capaces de generalizar correctamente sobre datos que nunca han visto. Para conseguirlo utilizamos técnicas como el Train/Test Split, reservando una parte de los datos para evaluar el rendimiento real del modelo.
El Train/Test Split es el proceso mediante el cual dividimos nuestro conjunto de datos en dos partes:
Conjunto de entrenamiento (Training Set)
Conjunto de prueba (Test Set)
El conjunto de entrenamiento se utiliza para que el algoritmo aprenda los patrones presentes en los datos. El conjunto de prueba se reserva y permanece oculto durante el entrenamiento. Solo se utiliza al final para evaluar el rendimiento real del modelo.
La idea es simular una situación del mundo real. Entrenamos con datos históricos y evaluamos con datos que el modelo nunca ha visto.
El Objetivo Real del Machine Learning
Muchas personas creen que el objetivo del Machine Learning es obtener el mejor rendimiento posible sobre los datos disponibles. En realidad, el objetivo es diferente. El objetivo es construir modelos capaces de generalizar correctamente sobre datos que nunca han visto. Por eso la evaluación debe realizarse utilizando información que haya permanecido completamente separada durante el entrenamiento.
El flujo básico es el siguiente:
Datos originales: Disponemos de un conjunto de datos completo.
División de los datos: Separamos los datos en dos conjuntos: Train Set y Test Set
Paso 3: Entrenamiento: El modelo aprende exclusivamente utilizando el conjunto de entrenamiento: Train Set → Modelo
Paso 4: Evaluación: Una vez entrenado, el modelo realiza predicciones sobre el conjunto de prueba. Modelo → Predicciones → Test Set
El Papel del Conjunto de Entrenamiento
Tras realizar la división de datos obtenemos cuatro elementos principales:
X_train → Variables predictoras para entrenamientoX_test → Variables predictoras para evaluacióny_train → Variable objetivo para entrenamientoy_test → Variable objetivo para evaluación
Donde:
X representa las características o variables independientes.
y representa la variable objetivo que queremos predecir.
Durante el entrenamiento, el modelo utilizará las variables de X_train junto con los valores reales contenidos en y_train para aprender los patrones existentes en los datos.
El Método Fit()
En Scikit-Learn, el aprendizaje del modelo se realiza mediante el método fit().
model.fit(X_train, y_train)
Durante esta fase:
El algoritmo analiza los datos.
Aprende la relación entre las variables predictoras y la variable objetivo.
Calcula los parámetros internos necesarios para realizar futuras predicciones.
Por ejemplo, en una regresión lineal el algoritmo aprenderá los coeficientes de la ecuación. En un árbol de decisión aprenderá las reglas de partición. En una red neuronal ajustará miles o millones de pesos internos.
Proporciones Habituales de División
No existe una única división correcta. Las más utilizadas son:
Entrenamiento
Prueba
Cuándo usar
70%
30%
Cuando se dispone de una cantidad moderada de datos y se desea una evaluación más robusta del modelo. Muy utilizado en proyectos académicos y de aprendizaje.
80%
20%
Equilibrio ideal entre entrenamiento y evaluación. Es la división más utilizada en proyectos de Machine Learning y funciona especialmente bien con datasets medianos y grandes.
75%
25%
Alternativa intermedia cuando se quiere disponer de un conjunto de prueba ligeramente mayor sin sacrificar demasiados datos para el entrenamiento.
90%
10%
Recomendado para datasets pequeños, donde maximizar la cantidad de datos disponibles para el entrenamiento es más importante que disponer de un conjunto de prueba grande.
Regla general: cuanto más pequeño sea el dataset, mayor suele ser el porcentaje destinado al entrenamiento. Cuanto más grande sea el dataset, más sencillo resulta reservar una proporción mayor para pruebas sin afectar significativamente al aprendizaje del modelo.
¿Qué es la generalización?
La generalización es la capacidad de un modelo para funcionar correctamente sobre datos nuevos. Es probablemente el concepto más importante de todo Machine Learning. Un modelo que memoriza los datos de entrenamiento no es útil. Un modelo útil es aquel que:
Aprende patrones generales.
Mantiene un buen rendimiento fuera de la muestra.
El Test Set existe precisamente para medir esta capacidad. No debemos mezclar observaciones futuras con observaciones pasadas. La división correcta suele respetar el orden cronológico. De lo contrario, estaríamos introduciendo información futura durante el entrenamiento.
¿Qué significa que el modelo “aprende”?
Cuando hablamos de aprendizaje en Machine Learning nos referimos al proceso mediante el cual el algoritmo encuentra patrones en los datos históricos. El objetivo es identificar relaciones que puedan utilizarse posteriormente para realizar predicciones sobre nuevos datos. El resultado de este proceso es un modelo entrenado.
Generación de Predicciones
Una vez entrenado el modelo, podemos utilizarlo para realizar predicciones sobre observaciones que nunca ha visto. En Scikit-Learn esto se realiza mediante el método predict().
y_pred = model.predict(X_test)
El modelo recibe las variables del conjunto de prueba y genera una predicción para cada observación. Estas predicciones se almacenan en y_pred.
Comparando Predicciones con Valores Reales
La ventaja del conjunto de prueba es que conocemos los valores reales. Por tanto podemos comparar: y_test contra y_pred. Esta comparación permite medir el rendimiento real del modelo. Es precisamente aquí donde entran en juego las métricas de evaluación.
Cálculo del Error del Modelo
Dependiendo del tipo de problema utilizaremos métricas diferentes.
Problemas de Regresión
Cuando la variable objetivo es numérica:
MAE (Mean Absolute Error)
MSE (Mean Squared Error)
RMSE (Root Mean Squared Error)
R² (Coefficient of Determination)
Problemas de Clasificación
Cuando la variable objetivo es categórica:
Accuracy
Precision
Recall
F1 Score
ROC-AUC
Este proceso constituye la base de prácticamente todos los proyectos de Machine Learning modernos.
Data Leakage: El Error Silencioso que Puede Invalidar un Modelo de Machine Learning
Uno de los objetivos fundamentales de cualquier proyecto de Machine Learning es construir modelos capaces de generalizar correctamente sobre datos que nunca han visto. Para conseguirlo utilizamos técnicas como el Train/Test Split, reservando una parte de los datos para evaluar el rendimiento real del modelo.
Sin embargo, existe un problema que puede hacer que nuestras métricas parezcan excelentes mientras que el modelo fracasa cuando llega a producción. Este problema recibe el nombre de Data Leakage o fuga de información y es una de las causas más comunes de resultados excesivamente optimistas en Machine Learning.
Comprender qué es el Data Leakage, cómo se produce y cómo evitarlo es esencial para construir modelos fiables y obtener evaluaciones realistas.
¿Qué es el Data Leakage?
El Data Leakage ocurre cuando información que debería permanecer oculta durante el entrenamiento termina llegando al modelo de forma directa o indirecta. En otras palabras: El modelo recibe pistas sobre los datos de prueba antes de ser evaluado.
Como consecuencia:
El modelo aprende información que no debería conocer.
Las métricas de evaluación se inflan artificialmente.
El rendimiento real en producción suele ser mucho peor de lo esperado.
¿Por qué es un problema?
Supongamos que queremos predecir el precio de una vivienda. Disponemos de un conjunto de datos histórico y realizamos un Train/Test Split. La idea es que:
Train Set → AprendizajeTest Set → Evaluación
El Test Set debe representar información completamente nueva. Si el modelo tiene acceso, aunque sea parcialmente, a información procedente del conjunto de prueba, la evaluación deja de ser objetiva. Las métricas obtenidas ya no reflejan la capacidad real de generalización.
La Relación Entre Data Leakage y Train/Test Split
El propósito del Train/Test Split es simular una situación real. Entrenamos con datos históricos y posteriormente evaluamos el modelo sobre datos que nunca ha visto. Para que esta simulación sea válida, ambos conjuntos deben permanecer completamente independientes. Cuando esta independencia se rompe aparece el Data Leakage.
Un Ejemplo Sencillo
Imaginemos que queremos predecir la recaudación de películas. Disponemos de variables como:
Presupuesto.
Duración.
Género.
Popularidad de los actores.
Si entrenamos el modelo utilizando todo el dataset y después evaluamos sobre esos mismos registros, podríamos obtener resultados aparentemente perfectos. Sin embargo, el modelo no está aprendiendo patrones generales, está memorizando ejemplos concretos. Por tanto, las métricas no representan el rendimiento sobre datos nuevos.
El Caso Más Común: Transformaciones Antes del Split
Uno de los errores más frecuentes consiste en aplicar transformaciones sobre todo el dataset antes de dividir los datos. Por ejemplo:
Aunque parece correcto, existe un problema. El escalador ha calculado la media y la desviación estándar utilizando tanto el Train Set como el Test Set. Por tanto, durante el entrenamiento ya se ha utilizado información procedente del conjunto de prueba.
Existe una regla muy útil: Todo objeto que utilice el método .fit() debe aprender únicamente del conjunto de entrenamiento. Esto incluye:
Scalers.
Encoders.
Imputadores.
PCA.
Selectores de variables.
Modelos de Machine Learning.
Si un componente necesita ejecutar un .fit(), debe hacerlo exclusivamente utilizando el Train Set.
Cómo Detectar un Posible Data Leakage
Algunas señales de alerta son:
Accuracy extremadamente alta.
R² inusualmente elevado.
Error casi nulo.
Diferencias muy grandes entre entorno de pruebas y producción.
Cuando las métricas parecen demasiado buenas para ser ciertas, conviene revisar cuidadosamente posibles fugas de información.
Data Leakage en Series Temporales
En problemas temporales el riesgo es todavía mayor. Por ejemplo:
Predicción bursátil.
Forecasting de ventas.
Predicción meteorológica.
Un error habitual consiste en utilizar información futura durante el entrenamiento. Si mezclamos registros futuros con registros pasados, el modelo aprende patrones imposibles de conocer en una situación real. Por esta razón las series temporales requieren estrategias de validación específicas que respeten el orden cronológico.
Buenas Prácticas para Evitar Data Leakage
Dividir antes de transformar: Siempre: Split → Fit → Transform
Mantener independencia entre conjuntos: El Test Set debe permanecer aislado hasta la fase final de evaluación.
Utilizar Pipelines: Los pipelines de Scikit-Learn ayudan a evitar errores de procesamiento. Permiten garantizar que cada transformación aprende únicamente a partir del conjunto de entrenamiento.
Desconfiar de resultados excesivamente buenos: Cuando las métricas parecen perfectas, conviene revisar cuidadosamente el flujo de datos.
Errores Comunes
Evaluar con datos de entrenamiento: produce resultados engañosamente buenos.
Realizar transformaciones antes de dividir: por ejemplo, escalado, normalización, imputación. Estas transformaciones deben aprenderse utilizando únicamente el Train Set. Está directamente relacionado con el problema de Data Leakage (fuga de información).
Utilizar el Test Set repetidamente: Cada vez que modificamos el modelo basándonos en el Test Set estamos filtrando información. Con el tiempo, el conjunto de prueba deja de ser independiente.
Ignorar el desbalanceo de clases: En clasificación puede ser necesario utilizar particiones estratificadas para mantener la proporción de clases.
Relación con la Validación Cruzada
El Train/Test Split suele ser el primer paso. Posteriormente pueden utilizarse técnicas más avanzadas como:
K-Fold Cross Validation.
Stratified K-Fold.
Time Series Split.
Estas técnicas proporcionan estimaciones más robustas del rendimiento del modelo. Sin embargo, incluso cuando utilizamos validación cruzada, suele mantenerse un conjunto de prueba final completamente independiente.
Conclusión
El Train/Test Split es una de las etapas más importantes de cualquier proyecto de Machine Learning. Su objetivo es garantizar que la evaluación del modelo se realiza sobre datos que no han participado en el entrenamiento, permitiendo medir de forma realista su capacidad de generalización. Esta práctica constituye la base sobre la que se apoyan todas las metodologías modernas de evaluación de modelos y resulta imprescindible tanto en problemas de regresión como de clasificación, Deep Learning o sistemas de recomendación. Comprender cómo dividir correctamente los datos y evitar fugas de información es uno de los primeros pasos para construir modelos fiables y útiles en entornos reales.
Cómo Medir la Capacidad Explicativa de un Modelo de Regresión
Cuando desarrollamos un modelo de regresión, una de las preguntas más importantes es: ¿qué tan bien explica el modelo los datos observados?. Aunque métricas como el Error Cuadrático Medio (MSE) o el Error Absoluto Medio (MAE) nos indican cuánto se equivoca un modelo en sus predicciones, no nos dicen qué proporción de la información presente en los datos ha sido realmente capturada.
Para responder a esta cuestión utilizamos el coeficiente de determinación, más conocido como R², una de las métricas más utilizadas en Machine Learning, estadística y ciencia de datos para evaluar modelos de regresión.
¿Qué es el coeficiente de determinación?
El coeficiente de determinación mide qué porcentaje de la variabilidad de la variable objetivo puede ser explicado por el modelo. Dicho de forma más sencilla: R² nos indica cuánto mejor es nuestro modelo que una predicción basada únicamente en la media de los datos. Si un modelo logra explicar gran parte de las variaciones observadas, tendrá un valor de R² elevado. Si apenas encuentra patrones útiles, el valor será bajo.
La Idea Intuitiva Detrás del R²
Imaginemos que queremos predecir el precio de viviendas. Supongamos que el precio medio de todas las viviendas del conjunto de datos es de 250.000 €. Una estrategia extremadamente simple sería ignorar todas las características de las viviendas y predecir siempre: 250.000€ para cualquier casa.
Obviamente, esta estrategia produciría errores importantes. Ahora entrenamos un modelo utilizando variables como: metros cuadrados, número de habitaciones, ubicación, antigüedad, etc. Si el modelo consigue reducir significativamente esos errores, significa que está explicando parte de la variabilidad presente en los precios. El R² cuantifica precisamente cuánto ha mejorado el modelo respecto a utilizar únicamente la media.
Variabilidad Total y Variabilidad Residual
Para entender cómo se calcula R² es necesario distinguir dos conceptos fundamentales.
Variabilidad Total
Representa toda la dispersión existente en la variable objetivo respecto a su media. Por ejemplo, si los precios de las viviendas varían entre 100.000 € y 800.000 €, existe una gran variabilidad que el modelo intentará explicar. La variabilidad total se calcula mediante la Suma Total de Cuadrados (SST):
$$SST=\sum_{i=1}^{n}(y_i-\bar{y})^2$$
Donde:
\(y_i\) es cada valor real.
\(\bar{y}\) es la media de todos los valores.
Variabilidad Residual
Una vez entrenado el modelo, siempre existirá cierta diferencia entre las predicciones y los valores reales. Esa parte que el modelo no consigue explicar se conoce como variabilidad residual; cuanto menor sea esta cantidad, mejor será el ajuste. Se calcula mediante la Suma de Cuadrados Residuales (SSE):
$$SSE=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2$$
Donde:
\(y_i\) es el valor real.
\(\hat{y}_i\) es la predicción del modelo.
Fórmula del Coeficiente de Determinación
El R² compara la variabilidad residual con la variabilidad total. Su fórmula es:
$$R^2=1-\frac{SSE}{SST}$$
Por tanto, mide la proporción de información que el modelo ha conseguido capturar.
Interpretación de los Valores de R²
R² = 0: El modelo no explica absolutamente nada. Tiene el mismo rendimiento que predecir siempre la media de los datos.
R² = 0.30: El modelo explica aproximadamente el 30% de la variabilidad observada. El 70% restante permanece sin explicar.
R² = 0.70: El modelo explica el 70% de la variación presente en los datos. Generalmente se considera un resultado bastante sólido en muchos problemas reales.
R² = 1: El modelo explica el 100% de la variabilidad. Todas las observaciones son predichas perfectamente. Aunque pueda parecer ideal, en algunos casos puede indicar sobreajuste (overfitting), especialmente cuando se evalúa sobre los mismos datos utilizados para entrenar.
Ventajas
Fácil de interpretar: Expresa directamente la proporción de información explicada por el modelo.
Permite comparar modelos: Es muy útil para evaluar diferentes algoritmos o configuraciones.
Independiente de las unidades: A diferencia del MSE o RMSE, el R² no depende de la escala de la variable objetivo. Puede utilizarse para comparar problemas distintos.
Limitaciones
Aunque es una métrica muy popular, también tiene limitaciones importantes.
No mide directamente el error: Dos modelos pueden tener valores de R² similares y errores muy diferentes. Por ello suele combinarse con métricas como:
MAE
MSE
RMSE
Puede aumentar al añadir variables irrelevantes: Una característica importante es que el R² nunca disminuye al incorporar nuevas variables al modelo. Incluso variables sin valor predictivo pueden provocar un ligero aumento. Por esta razón, utilizar únicamente R² puede conducir a conclusiones equivocadas.
No garantiza causalidad: Un valor elevado de R² no implica que exista una relación causal entre las variables. Simplemente indica que existe una relación estadística capaz de explicar parte de la variabilidad observada. Para solucionar el problema de añadir variables innecesarias, se utiliza el R² Ajustado (Adjusted R²).
Cálculo del Coeficiente de Determinación (R²) en Python
La biblioteca Scikit-Learn incorpora funciones que permiten calcular el coeficiente de determinación de forma sencilla. Una vez entrenado un modelo y generadas las predicciones, podemos evaluar su capacidad explicativa utilizando la función r2_score().
Supongamos que disponemos de los valores reales y las predicciones generadas por nuestro modelo:
Este enfoque permite comparar objetivamente distintos modelos y seleccionar aquel que mejor explica la variabilidad de los datos.
¿Qué se considera un buen R²?
No existe un valor universal. Depende del problema y del contexto de negocio. Por ejemplo:
R²
Interpretación
< 0.30
Capacidad explicativa baja
0.30 – 0.50
Moderada
0.50 – 0.70
Buena
0.70 – 0.90
Muy buena
> 0.90
Excelente (o posible sobreajuste)
Sin embargo, en problemas complejos como economía, comportamiento humano o mercados financieros, valores de R² relativamente modestos pueden seguir siendo extremadamente útiles.
R² Ajustado: Corrigiendo una de sus Limitaciones
Para solucionar el problema de añadir variables innecesarias, se utiliza el R² Ajustado (Adjusted R²). Esta métrica introduce una penalización cuando se agregan variables que no aportan información relevante. Por ello resulta especialmente útil en modelos con múltiples variables predictoras. Mientras que el R² tradicional tiende a aumentar al añadir variables, el R² ajustado puede disminuir si esas variables no mejoran realmente el modelo.
Aunque el coeficiente de determinación (R²) es una métrica muy útil para medir la capacidad explicativa de un modelo, presenta una limitación importante: nunca disminuye cuando añadimos nuevas variables predictoras. Incluso si una variable no aporta información relevante, el valor de R² puede mantenerse igual o aumentar ligeramente, dando la impresión de que el modelo ha mejorado.
Para corregir este problema se utiliza el R² Ajustado (Adjusted R²), una versión modificada del coeficiente de determinación que penaliza la incorporación de variables innecesarias.
¿Por qué necesitamos el R² Ajustado?
Supongamos que estamos construyendo un modelo para predecir el precio de una vivienda. Inicialmente utilizamos variables como:
Metros cuadrados.
Número de habitaciones.
Antigüedad de la vivienda.
Posteriormente añadimos una nueva variable:
Número de letras del nombre del propietario.
Esta última variable no tiene ninguna relación real con el precio de una vivienda. Sin embargo, el R² tradicional podría aumentar ligeramente simplemente por haber añadido una nueva característica al modelo. El problema es que el R² no distingue entre variables útiles y variables irrelevantes. El R² Ajustado sí lo hace.
¿Cómo Funciona?
El R² Ajustado incorpora una penalización basada en:
El número de observaciones disponibles.
El número de variables predictoras utilizadas.
Si una nueva variable aporta información relevante, el R² Ajustado aumentará. Si una nueva variable no mejora realmente la capacidad predictiva del modelo, el R² Ajustado disminuirá. Por esta razón, suele considerarse una métrica más fiable cuando se comparan modelos con distinto número de variables.
Fórmula del R² Ajustado
$$R^2_{adj}=1-(1-R^2)\frac{n-1}{n-p-1}$$
Donde:
R² = Coeficiente de determinación tradicional.
n = Número de observaciones.
p = Número de variables predictoras.
La fórmula introduce una penalización que aumenta a medida que incorporamos más variables al modelo.
Interpretación
La interpretación es similar a la del R² tradicional:
Valor
Interpretación
Cercano a 0
El modelo explica poca variabilidad
Cercano a 1
El modelo explica gran parte de la variabilidad
Disminuye al añadir variables
Las nuevas variables no aportan valor
¿Cuándo Utilizar R² Ajustado?
El R² Ajustado resulta especialmente útil cuando:
Trabajamos con regresión múltiple.
Comparamos modelos con diferente número de variables.
Realizamos procesos de selección de características (Feature Selection).
Queremos evitar modelos excesivamente complejos.
Buscamos reducir el riesgo de sobreajuste (Overfitting).
Si todos los modelos tienen exactamente las mismas variables, el R² tradicional suele ser suficiente. Sin embargo, cuando el número de características cambia entre modelos, el R² Ajustado proporciona una evaluación más justa.
Cálculo en Python
Scikit-Learn no incluye una función específica para calcular el R² Ajustado, pero puede obtenerse fácilmente a partir del R² tradicional.
from sklearn.metrics import r2_score# R² tradicionalr2 = r2_score(y_test, y_pred)# Número de observacionesn =len(y_test)# Número de variables predictorasp = X_test.shape[1]# R² Ajustadoadjusted_r2 =1- ((1- r2) * (n -1) / (n - p -1))print(f"R²: {r2:.4f}")print(f"Adjusted R²: {adjusted_r2:.4f}")
Conclusión
El coeficiente de determinación (R²) es una de las métricas fundamentales para evaluar modelos de regresión. Su principal objetivo es medir qué proporción de la variabilidad de la variable objetivo es explicada por el modelo. Gracias a su interpretación intuitiva, se ha convertido en una herramienta imprescindible para comparar modelos y evaluar su capacidad predictiva.
El R² Ajustado surge para corregir una de las principales limitaciones del coeficiente de determinación tradicional. Mientras que el R² tiende a favorecer modelos cada vez más complejos, el R² Ajustado introduce una penalización que obliga a que cada nueva variable aporte un valor real al modelo. Por este motivo, cuando se trabaja con regresión múltiple y se comparan modelos con diferente número de características, el R² Ajustado suele ser una métrica más fiable para evaluar la calidad y capacidad explicativa de un modelo.
No obstante, el R² no debe utilizarse de forma aislada. Una evaluación rigurosa requiere complementarlo con métricas de error como MAE, MSE o RMSE, así como validar el comportamiento del modelo sobre datos que no haya visto previamente. Comprender el significado de R² y sus limitaciones es un paso esencial para cualquier profesional que trabaje con Machine Learning y Ciencia de Datos.
Cuando construimos un modelo de regresión, el objetivo principal es realizar predicciones lo más cercanas posible a los valores reales. Sin embargo, ningún modelo es perfecto. Siempre existirá cierta diferencia entre lo que el modelo predice y lo que realmente ocurre. Para medir esa diferencia utilizamos métricas de evaluación, siendo una de las más importantes el Error Cuadrático Medio (Mean Squared Error o MSE).
El MSE es una de las métricas más utilizadas en Machine Learning y estadística porque proporciona una medida clara de cuánto se equivocan, en promedio, las predicciones de un modelo.
¿Qué es el error cuadrático medio?
El error cuadrático medio mide el promedio de los errores al cuadrado entre los valores reales y los valores predichos por un modelo.
En términos simples:
Calculamos la diferencia entre el valor real y la predicción.
(yᵢ − ŷᵢ)² = error cuadrado para cada observación.
¿Por qué se eleva el error al cuadrado?
Podríamos preguntarnos por qué no simplemente promediar los errores.
Supongamos estas diferencias:
Valor Real
Predicción
Error
100
90
10
50
60
-10
Si calculamos el promedio de los errores:
$$\frac{10 + (-10)}{2}=0$$
El resultado sería cero, sugiriendo incorrectamente que el modelo no se equivoca.
Al elevar cada error al cuadrado:
$$10^2 = 100$$ $$(-10)^2 = 100$$
Ambos errores contribuyen positivamente al resultado final, evitando cancelaciones. Además, el cuadrado penaliza más severamente los errores grandes, algo muy útil en muchos problemas de negocio.
Ejemplo de Cálculo Paso a Paso
Supongamos que tenemos un modelo que predice la recaudación de películas.
MSE pequeño → El modelo realiza buenas predicciones.
MSE grande → El modelo comete errores importantes.
Sin embargo, existe un detalle importante. Debido a que los errores se elevan al cuadrado, las unidades también quedan elevadas al cuadrado. Esto hace que la interpretación directa del valor sea menos intuitiva.
Sensibilidad a los Valores Atípicos
Una de las principales características del MSE es que penaliza fuertemente los errores grandes. Veamos un ejemplo.
Modelo A
Errores:
$$2,3,4$$
MSE:
$$\frac{4+9+16}{3}=9.67$$
Modelo B
Errores:
$$1,1,10$$
MSE:
$$\frac{1+1+100}{3}=34$$
Aunque la mayoría de los errores del segundo modelo son pequeños, un único error grande provoca que el MSE aumente considerablemente. Por este motivo, el MSE es especialmente útil cuando queremos detectar y penalizar predicciones muy alejadas de la realidad.
Ventajas del MSE
Fácil de calcular: La fórmula es sencilla y eficiente incluso para grandes volúmenes de datos.
Penaliza errores grandes: Los errores importantes tienen un peso mucho mayor que los errores pequeños. Esto resulta útil en aplicaciones donde los fallos graves tienen un alto coste económico o operativo.
Compatible con muchos algoritmos: Numerosos algoritmos de Machine Learning utilizan el MSE como función objetivo durante el entrenamiento. Por ejemplo:
Regresión Lineal.
Redes Neuronales.
Gradient Boosting.
XGBoost.
Random Forest Regressor.
Limitaciones del MSE
Sensibilidad a Outliers: Los valores atípicos pueden dominar completamente la métrica. Un único error extremo puede aumentar significativamente el MSE.
Interpretación menos intuitiva: Al estar expresado en unidades al cuadrado, resulta más difícil comprender su significado práctico. Por esta razón suele utilizarse junto con otras métricas.
Relación con el RMSE
Una métrica muy popular derivada del MSE es el Root Mean Squared Error (RMSE). Su fórmula es:
$$RMSE=\sqrt{MSE}$$
Por ejemplo:
Si:
$$MSE = 200$$
entonces:
$$RMSE = \sqrt{200}$$ $$RMSE \approx 14.14$$
La ventaja es que el RMSE vuelve a expresarse en las mismas unidades de la variable objetivo, facilitando la interpretación. Si estamos prediciendo ingresos en miles de euros, un RMSE de 14 indica que el modelo se equivoca aproximadamente en 14 mil euros por predicción.
MSE en Machine Learning
Durante el entrenamiento de muchos modelos de regresión, el algoritmo intenta minimizar el MSE. Esto significa que ajusta sus parámetros para que la suma de los errores cuadrados sea lo más pequeña posible. En una regresión lineal, por ejemplo, el proceso de aprendizaje consiste precisamente en encontrar los coeficientes de la recta que minimizan el Error Cuadrático Medio sobre los datos de entrenamiento. En otras palabras, el modelo aprende buscando la línea que produzca el menor MSE posible.
¿Cuándo utilizar el MSE?
El MSE es especialmente recomendable cuando:
Estamos trabajando con problemas de regresión.
Los errores grandes son especialmente costosos.
Queremos una métrica sensible a predicciones muy alejadas del valor real.
Necesitamos una función objetivo para optimizar modelos.
Por el contrario, si los datos contienen muchos valores atípicos o deseamos una métrica más robusta, puede ser conveniente complementar el análisis con métricas como el MAE (Mean Absolute Error).
MSE en Python
La biblioteca Scikit-Learn incluye la función mean_squared_error(), que permite calcular fácilmente el Error Cuadrático Medio de un modelo de regresión. Una vez generadas las predicciones, basta con comparar los valores reales con los valores estimados.
Supongamos que tenemos los siguientes valores reales y predicciones:
Este cálculo implementa directamente la fórmula matemática del Error Cuadrático Medio y produce exactamente el mismo resultado que mean_squared_error().
Conclusión
El Error Cuadrático Medio (MSE) es una de las métricas fundamentales para evaluar modelos de regresión. Su principal objetivo es medir cuánto se alejan las predicciones de los valores reales, penalizando especialmente los errores grandes. Esta característica lo convierte en una herramienta extremadamente útil tanto para evaluar modelos como para entrenarlos.
Aunque su interpretación puede resultar menos intuitiva debido a las unidades al cuadrado, su simplicidad matemática y su capacidad para detectar errores significativos explican por qué sigue siendo una de las métricas más utilizadas en Machine Learning, Estadística y Ciencia de Datos. Comprender cómo funciona el MSE es un paso esencial para analizar el rendimiento de cualquier modelo predictivo y tomar decisiones informadas durante el proceso de modelado.
En el universo del Aprendizaje Supervisado (Supervised Machine Learning), el objetivo fundamental es construir modelos matemáticos a partir de datos históricos para predecir resultados futuros. Sin embargo, no todos los problemas de negocio son iguales. Dependiendo de la naturaleza de lo que deseamos predecir, el aprendizaje supervisado se divide en dos grandes ramas: Regresión y Clasificación.
A continuación, analizaremos ambos enfoques de forma simétrica para comprender cómo funcionan, cómo se entrenan y qué necesitan para tener éxito.
Regresión: Predicción de Valores Continuos
La Regresión se ocupa de predecir un resultado cuantitativo y continuo. Esto significa que la variable objetivo (lo que queremos averiguar) es un número real dentro de un rango infinito de posibilidades medibles.
Ejemplos de Problemas de Regresión
Mercado Inmobiliario: Predice el precio final de venta de una vivienda basándose en sus metros cuadrados y ubicación.
Industria del Cine: Estimar la recaudación exacta en taquilla (Box Office Revenue) de un largometraje según su inversión publicitaria.
Planificación de Operaciones: Calcular el número de asistentes a un evento corporativo para optimizar recursos.
El Proceso de Entrenamiento del Modelo (Paso a Paso)
El flujo mecánico para que un algoritmo aprenda a realizar regresiones sigue cuatro etapas estructuradas:
Paso 1: Datos históricos continuos: Se recopila un conjunto de entrenamiento donde ya se conocen las características de entrada (X) y el valor numérico real de salida (Y).
Paso 2: Selección del modelo: Se elige el algoritmo matemático base adecuado para trazar la tendencia (por ejemplo, una Regresión Lineal).
Paso 3: Ajuste de parámetros (Fitting): El algoritmo analiza los datos y calcula los coeficientes óptimos (pesos) necesarios para minimizar el error entre sus estimaciones y los valores reales.
Paso 4: Predicción sobre nuevos datos: El modelo, ya entrenado, recibe un registro completamente nuevo y calcula de forma automática el valor numérico estimado.
Requisitos Técnicos de un Modelo de Regresión
Para desplegar un modelo de regresión con garantías, el ingeniero de datos debe asegurar:
Variable objetivo numérica: El fenómeno a predecir debe ser obligatoriamente un número continuo y escalable.
Métricas de evaluación adecuadas: Se requiere medir la proximidad entre la realidad y la predicción utilizando indicadores cuantitativos de error, como el Error Cuadrático Medio (MSE).
Control del Sobreajuste (Overfitting): Es crítico vigilar que el modelo no memorice los datos de entrenamiento a la perfección, ya que si lo hace, perderá la capacidad de generalizar y fallará al enfrentarse a datos nuevos en el mundo real.
Clasificación: Predicción de Categorías
La Clasificación entra en juego cuando el resultado que buscamos no es un número, sino una etiqueta, clase o categoría discreta. El objetivo del algoritmo aquí es determinar a qué grupo específico pertenece un registro.
Ejemplos de Problemas de Clasificación
Retención de Clientes (Customer Churn): Clasificar si un usuario activo cancelará su suscripción (Sí) o permanecerá en la empresa (No).
Finanzas: Evaluar si un solicitante de crédito tiene un perfil de riesgo propenso al impago (Default).
Seguridad Informática: Identificar si una transacción con tarjeta de crédito es legítima o un intento de fraude.
Ejemplo Destacado: Filtro de Correos Electrónicos
El caso de uso más cotidiano es el filtro anti-spam de tu bandeja de entrada. El sistema analiza el texto de cada correo entrante y calcula la probabilidad de que pertenezca a la categoría de “Spam” o “Correo Deseado”, redirigiéndolo automáticamente según la etiqueta asignada.
El Proceso de Entrenamiento del Modelo (Paso a Paso)
Al igual que en la regresión, la clasificación sigue el mismo ciclo de vida universal:
Paso 1: Datos etiquetados: Se parte de un dataset histórico donde los humanos ya han clasificado previamente los registros con sus respuestas correctas (ej. correos marcados como spam).
Paso 2: Selección del modelo: Se escoge la arquitectura de clasificación (como un Árbol de Decisión o Regresión Logística).
Paso 3: Ajuste de parámetros (Fitting): El modelo ajusta sus funciones internas para aprender qué patrones o combinaciones de variables separan con mayor precisión a una categoría de otra.
Paso 4: Predicción sobre nuevos datos: Ante un dato nuevo sin etiquetar, el modelo calcula las probabilidades y le asigna la categoría correspondiente.
Requisitos Técnicos de un Modelo de Clasificación
Para estructurar con éxito un entorno de clasificación, el framework exige tres pilares fundamentales:
Variables cuantificables: Dado que los algoritmos solo procesan números, las características cualitativas (como las palabras de un email) deben pasar por una ingeniería de codificación (encoding) para transformarse en vectores numéricos.
Datos etiquetados de origen: Se necesita obligatoriamente un histórico donde la variable objetivo ya esté resuelta (etiquetada), lo que a menudo requiere un esfuerzo humano inicial de supervisión.
Medidas de similitud: El sistema debe contar con una métrica matemática matemática para evaluar qué tan parecido es el nuevo registro con respecto a los patrones de las clases que asimiló durante el entrenamiento.
Aplicaciones Empresariales del Aprendizaje Supervisado
El verdadero valor del aprendizaje supervisado reside en su capacidad para automatizar decisiones estratégicas a gran escala en el tejido corporativo. Las empresas combinan de forma sinérgica ambas herramientas para optimizar sus operaciones:
Mientras que el departamento de Finanzas utiliza modelos de Clasificación para mitigar riesgos bloqueando transacciones sospechosas de fraude en tiempo real, el equipo de Logística y Ventas se apoya en modelos de Regresión para predecir la demanda exacta de inventario para el próximo trimestre, evitando sobrecostes de almacenamiento. En el ecosistema empresarial maduro, entender si tu problema se resuelve identificando un grupo o calculando una cifra es el primer paso hacia el éxito de cualquier proyecto de IA.
El aprendizaje supervisado se encuentra presente en prácticamente todos los sectores económicos.
Marketing: Predicción de abandono de clientes, segmentación avanzada, predicción de conversiones.
Finanzas: Detección de fraude, evaluación de riesgo crediticio, predicción de impagos.
Salud: Diagnóstico asistido por IA, predicción de enfermedades, análisis de imágenes médicas.
Retail: Predicción de demanda, optimización de inventarios, recomendación de productos.
Turismo y Hostelería: Predicción de ocupación hotelera, forecasting de reservas, estimación de ingresos futuros.
En los articulos anteriores establecimos el framework operativo del aprendizaje supervisado y diferenciamos las variables continuas de las categóricas. Ahora, abriremos el capó matemático para analizar el algoritmo predictivo más fundamental, transparente y utilizado en la historia de la ciencia de datos: la Regresión Lineal.
La Anatomía de la Ecuación Lineal
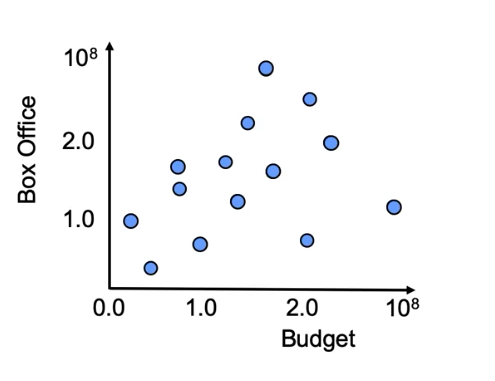
Para entender su funcionamiento, utilizaremos un caso de estudio clásico: predecir la recaudación en taquilla de una película (Box Office Revenue) basándonos única y exclusivamente en su presupuesto de marketing (Marketing Budget).
Cuando disponemos de un histórico de datos (nuestro training set) con el presupuesto invertido y la recaudación real de múltiples películas, podemos plasmar esa información en un gráfico de dispersión (scatter plot). Veremos una nube de puntos dispersos donde el eje X representa la variable predictora (marketing) y el eje Y representa la variable objetivo (recaudación).
El objetivo de la regresión lineal es trazar una línea recta que atraviese esa nube de puntos de la forma más óptima posible. Matemáticamente, la ecuación de esta recta se define de la siguiente manera:
$$Y_\beta(X) = \beta_0 + \beta_1X$$
Desglose analítico de sus componentes esenciales para la ingeniería de modelos:
\(Y_\beta(X) \): (Variable objetivo o prediccion / Target), en este caso se corresponde a Box Office Revenue (Recaudación en taquilla)
\(X \) (Variable independiente o Caracteristica / Feature): Es la información que utilizamos para realizar la predicción, en este caso, el presupuesto de marketing.
\(\beta_0\) (El Intercepto / Bias): Es el coeficiente que determina dónde corta la recta al eje \(Y\). Físicamente representa el escenario donde la variable \(X\) vale exactamente cero. En nuestro ejemplo, nos indica cuál sería la recaudación base de una película si no se invirtiera absolutamente nada en marketing.
\(\beta_1\) (La Pendiente / Slope): Es el coeficiente que mide la inclinación de la recta. Indica el impacto directo de la característica sobre el objetivo: por cada euro extra invertido en marketing, ¿cuántos euros aumentará la recaudación en taquilla?
El modelo intentará aprender la relación entre:
Presupuesto de la película (\(X\))
Recaudación en taquilla (\(Y\))
para poder estimar la recaudación de futuras películas.
Supongamos que alimentamos nuestro algoritmo con el dataset histórico y, tras el proceso de optimización, el sistema calcula los siguientes coeficientes óptimos:
\(\beta_0 = 80\text{ millones}\)
\(\beta_1 = 0.6\)
Nuestra ecuación predictiva final queda estructurada así:
Recaudación Base (\(\beta_0\)): Si lanzamos una película con cero presupuesto de marketing (\(X = 0\)), el modelo estima que aun así recaudará 80 millones de euros gracias a factores orgánicos (como la sinopsis o los actores).
Retorno de Inversión (\(\beta_1\)): El coeficiente \(0.6\) nos dice que por cada dólar o euro adicional que la productora inyecte en marketing, la taquilla responderá incrementándose en \(0.6\) dólares o de manera proporcional.
Generando Predicciones:
Si una nueva producción planea invertir un presupuesto de marketing de 160 millones, sustituimos el valor en nuestra función matemática entrenada:
El modelo predice con alta transparencia que la recaudación estimada se situará en torno a los 176 millones.
¿Cómo encuentra el algoritmo la recta perfecta?
Si tomamos una regla, podríamos trazar infinitas líneas rectas diferentes cruzando el gráfico de dispersión. El Machine Learning descarta la aleatoriedad utilizando una función de pérdida o costo (\(J\)) para medir matemáticamente la calidad de cada recta posible.
Para cualquier línea propuesta, existirá una diferencia (un error) entre los puntos reales observados en el mundo real (\(Y_{\text{obs}}\)) y las predicciones teóricas situadas exactamente sobre la recta (\(Y_{\beta}\)).
La distancia vertical que separa a cada punto de la recta representa la magnitud del error de esa observación específica. La fórmula base del error individual es:
La Función de Costo Estándar: Error Cuadrático Medio (MSE)
No podemos simplemente sumar los errores individuales de todas las películas para evaluar el modelo, porque los errores de los puntos que están por encima de la recta (positivos) se cancelarían matemáticamente con los errores de los puntos que están por debajo (negativos).
Para solucionar esto e ignorar el signo enfocándonos solo en la magnitud, la ciencia de datos utiliza la distancia euclidiana al cuadrado (conocida como la norma L2), dando origen a la función de costo por excelencia en regresión: el Error Cuadrático Medio (Mean Squared Error o MSE).
Matemáticamente, el MSE calcula el promedio de los errores elevados al cuadrado para todas las observaciones del set de entrenamiento:
(Nota técnica de producción: En los manuales de cálculo avanzado y optimización, es común ver la función escrita multiplicando el denominador por dos, es decir, \(\frac{1}{2m}\). Esto se hace únicamente para facilitar las operaciones de derivación mediante cálculo infinitesimal al buscar mínimos, pero el resultado de optimización matemática para hallar los coeficientes es exactamente equivalente a usar \(\frac{1}{m}\) ).
El trabajo del algoritmo de regresión lineal consiste en encontrar la combinación exacta de valores para \(\beta_0\) y \(\beta_1\) que logre minimizar el MSE a su valor más bajo posible. La recta que logre reducir al mínimo esta distancia cuadrática promedio será, por definición, la recta óptima.
Buenas Prácticas de Modelado y Despliegue en Python
Una vez comprendida la estructura de la Regresión Lineal y cómo la función de costo del Error Cuadrático Medio (MSE) permite encontrar la recta óptima, es crucial abordar cómo gestionamos los modelos en la práctica profesional. Para construir soluciones de Machine Learning robustas, los científicos de datos siguen un protocolo estricto de ingeniería, evalúan la varianza explicada mediante estadística avanzada y traducen las ecuaciones matemáticas en scripts de código funcionales.
Buenas Prácticas Universales en el Modelado Predictivo
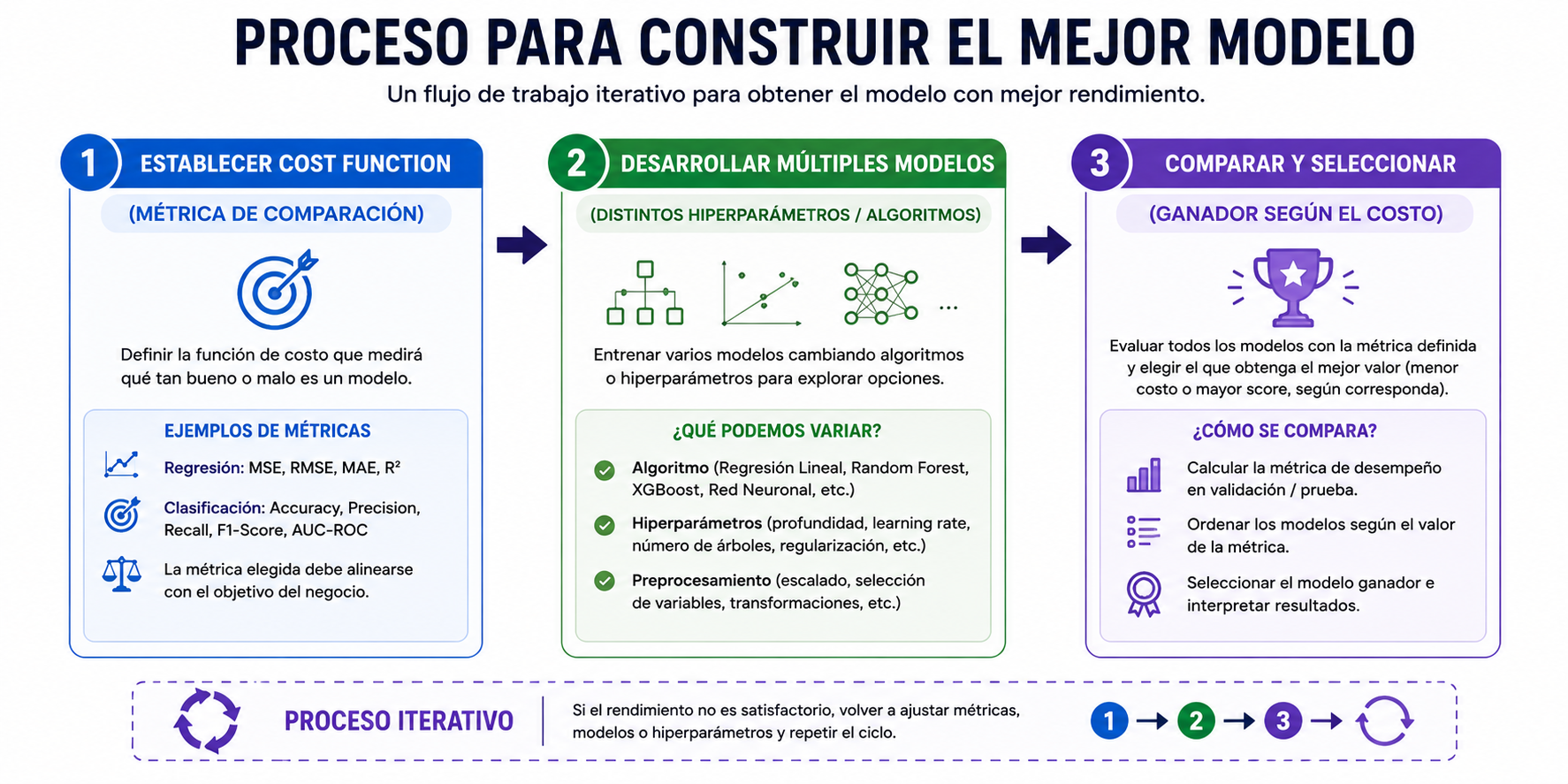
Cuando nos enfrentamos a un problema de regresión en producción, el flujo de trabajo no consiste en lanzar un algoritmo a ciegas. La metodología de ingeniería de datos dicta tres pasos esenciales:
Establecer la Función de Costo: Antes de entrenar, definimos qué función matemática queremos minimizar (por ejemplo, el MSE). Esto nos proporciona una métrica objetiva y estandarizada para comparar la fuerza de un modelo frente a otro.
Desarrollar Múltiples Modelos: Creamos arquitecturas variadas, experimentando con diferentes hiperparámetros o algoritmos alternativos para evaluar cuál se adapta mejor a la complejidad de los datos.
Comparar y Seleccionar: Contrastamos cuantitativamente las puntuaciones (scores) de todos los experimentos bajo la misma función de costo y seleccionamos el modelo con el rendimiento óptimo.
Descifrando el Coeficiente de Determinación: R-cuadrado
Aunque el MSE mide la magnitud del error, su valor depende de la escala de la variable objetivo. Para obtener una métrica de rendimiento estandarizada e independiente de la escala, recurrimos al Coeficiente de Determinación o \(R^2\).
El \(R^2\) es una métrica que mide la proporción de la variación total de los datos que es explicada con éxito por el modelo. Para entender su matemática, debemos desglosar sus dos componentes principales:
Representa la variación total de los datos. Físicamente, equivale al error que cometeríamos si no usáramos Machine Learning y nos limitáramos a trazar una línea horizontal estática basada en el promedio.
Para llevar este ecosistema matemático a la práctica, la comunidad de Data Science utiliza la librería estándar Scikit-Learn (sklearn). El flujo de codificación sigue una estructura limpia de programación orientada a objetos dividida en tres pasos clave:
Paso 1: Importar e Instanciar
En primer lugar, importamos la clase especializada desde el módulo correspondiente e instanciamos el objeto de nuestro modelo. En esta etapa, el algoritmo existe como una estructura matemática vacía, ya que aún no ha visto ningún dato histórico.
from sklearn.linear_model import LinearRegression# Creamos el objeto del modelo (aún sin ajustar)lr = LinearRegression()
Paso 2: El Proceso de Ajuste (fit)
Pasamos los conjuntos de datos históricos de entrenamiento (x_train y y_train) al método .fit(). En este punto, el motor de Scikit-Learn ejecuta las optimizaciones numéricas necesarias para minimizar la función de costo y calcular los coeficientes (\(\beta_0, \beta_1\)) óptimos.
# El modelo analiza los datos y optimiza sus parámetros internoslr.fit(x_train, y_train)
Paso 3: Generación de Predicciones (predict)
Una vez que el modelo cuenta con sus parámetros fijos y entrenados, el método .predict() queda completamente habilitado. Ahora podemos pasarle una matriz de características de prueba (x_test) que el sistema nunca haya visto para calcular de forma automática las estimaciones numéricas correspondientes.
# Predecimos valores continuos para un conjunto de prueba sin etiquetaspredictions = lr.predict(x_test)
Cuando nos adentramos en el universo del Aprendizaje Supervisado (Supervised Machine Learning), tendemos a pensar que el objetivo único y absoluto de cualquier algoritmo es lograr el 100% de precisión en sus estimaciones. Sin embargo, en el mundo real de la ciencia de datos y los negocios, las decisiones arquitectónicas no son tan simples.
Existe una tensión constante, una balanza de ingeniería conocida como el trade-off entre interpretación y predicción. Dependiendo estrictamente de cuáles sean tus objetivos estratégicos, tu enfoque y la elección de tus modelos diferirán radicalmente.
Enfoque 1: Interpretación (Entender el Mecanismo)
Cuando el objetivo principal de un proyecto es la interpretación, el foco no se centra en adivinar el futuro con precisión milimétrica, sino en encontrar insights de alto valor sobre los datos actuales. Aquí, el científico de datos entrena al modelo para inspeccionar sus parámetros internos y deducir matemáticamente cómo funciona el sistema.
Flujo de Trabajo y Características:
El Foco en los Parámetros: Recolectamos datos de entrada (X) y etiquetas de salida (Y). Minimizamos la función de pérdida para ajustar el modelo, pero nuestra atención se centra en analizar qué coeficientes o variables aportan más peso al resultado.
Simplicidad sobre Complejidad: Para que un modelo sea altamente interpretable, sacrificamos intencionadamente su capacidad matemática de predicción y optamos por algoritmos menos complejos (como una Regresión Lineal o un Árbol de Decisión simple). El objetivo es evitar cajas negras.
Casos de Uso Reales:
Segmentación y Demografía: Analizar qué características demográficas de los clientes detonan la lealtad a una marca, en lugar de predecir la cifra exacta de ventas futuras.
Ingeniería de Seguridad: Identificar con precisión qué sistemas o componentes de seguridad previenen accidentes automovilísticos para poder modificarlos en fábrica, en lugar de predecir cuántos choques sufrirá un conductor.
Efectividad Publicitaria: Medir el impacto directo del presupuesto de marketing en los ingresos de taquilla de una película para optimizar la inversión, en lugar de adivinar la recaudación exacta del estreno.
Enfoque 2: Predicción (Optimizar el Resultado)
En el extremo opuesto de la balanza se encuentra la predicción pura. Aquí, los motivos ocultos o los mecanismos internos del algoritmo pasan a un segundo plano. Lo único que le importa al negocio es qué tan cerca está la predicción del valor real observado.
Flujo de Trabajo y Características:
Métricas de Rendimiento: El éxito se evalúa mediante indicadores cuantitativos puros de cercanía matemática (como el MSE, RMSE o Accuracy).
Modelos de Caja Negra (Black Box): Al buscar la máxima potencia predictiva, es común delegar el problema a arquitecturas masivas y sumamente complejas como el Deep Learning (Redes Neuronales Profundas). El modelo arrojará resultados espectaculares, pero es probable que nadie en el equipo entienda con exactitud la correlación interna de sus variables.
Casos de Uso Reales:
Fuga de Clientes (Customer Churn): Estimar con la mayor probabilidad posible qué usuario está a punto de cancelar una suscripción para lanzar una campaña de retención automática; las razones sociológicas profundas importan menos que evitar la pérdida.
Riesgo de Impago (Credit Default): Para una entidad bancaria, predecir con exactitud milimétrica si un cliente pagará o no un préstamo financiero es vital para la supervivencia del negocio, por encima de desglosar la interpretación subyacente de sus hábitos.
Pronóstico de Compras: Anticipar las adquisiciones futuras de inventario basándose en el historial transaccional masivo de la plataforma.
El Dilema de la Elección del Modelo
El panorama ideal dictaría que todos los modelos del mercado tuvieran simultáneamente una interpretabilidad perfecta y una predicción infalible; sin embargo, en la práctica computacional esto casi nunca ocurre.
Al enfrentarte a un problema de machine learning en tu empresa o startup, debes sentarte con las partes interesadas para definir el objetivo de negocio. Esa métrica comercial será el único faro que determine si construyes un mapa transparente y explicable o un motor predictivo opaco de alta precisión.
Resumen del Concepto
Métrica / Dimensión
Enfoque de Interpretación
Enfoque de Predicción
Meta Principal
Comprender las dinámicas del sistema.
Baja o moderada (regresiones, árboles).
Complejidad del Modelo
Baja o Moderada (Regresiones, Árboles).
Alta o Extrema (Deep Learning, Ensembles).
Transparencia
Total (Caja Blanca / Parámetros expuestos).
Baja (Caja Negra / Patrones no lineales complejos).
Mecanismo de Control
Análisis de Coeficientes y Variables.
Métricas de Rendimiento Cuantitativo (Score).
Casos Prácticos y Sinergias en el Balance de Modelos
Para entender cómo se traduce la teoría del balance entre interpretación y predicción en la práctica de la ingeniería de datos, es necesario analizar cómo responden los algoritmos ante dos naturalezas distintas de problemas: la regresión (predicción de valores numéricos continuos) y la clasificación (predicción de categorías discretas).
Caso de Estudio 1: Regresión en el Mercado Inmobiliario
Imagina que trabajamos con el célebre dataset de ventas de casas de Ames, Iowa. Nuestro objetivo matemático o target (Y) es el precio final de la vivienda, mientras que nuestra matriz de características (X) incluye variables como la ubicación, la calidad de los acabados, el año de construcción y el número de pisos.
Alineando este problema con nuestros dos enfoques, obtenemos dos herramientas de diagnóstico completamente diferentes:
A. Si priorizamos la Interpretación: Feature Importance
Al ajustar un modelo altamente interpretable (como una Regresión Lineal Múltiple), el algoritmo calcula estimaciones para cada uno de sus parámetros (los coeficientes de cada variable). Estos coeficientes nos permiten extraer un atributo crucial en Python: la Importancia de las Características (Feature Importance).
Lectura del impacto: La importancia de una característica no siempre es positiva. Por ejemplo, una variable como “calidad general” o “superficie habitable” tendrá un impacto positivo fuerte en el precio. Por el contrario, una tasa de criminalidad alta en la zona tendrá un impacto negativo severo.
Toma de decisiones: Para evaluar qué variables mueven más el mercado, el científico de datos analiza el valor absoluto de estos coeficientes. Esto nos dice qué factores afectan más al precio, sin importar si lo suben o lo bajan.
B. Si priorizamos la Predicción: La Gráfica de Dispersión Diagonal
Si nuestro único fin es generar el valor de predicción más exacto posible (\(\)\hat{y}\(\)), dejamos de mirar los coeficientes individuales y pasamos a evaluar un gráfico de dispersión de Valores Predichos frente a Valores Reales.
Evaluación geométrica: En este gráfico, se traza una línea diagonal perfecta que representa el escenario ideal donde la predicción coincide exactamente con la realidad.
Interpretación del error: Cuanto más cerca se agrupen los puntos dispersos alrededor de esa diagonal, más preciso y potente es nuestro modelo predictivo. Los puntos que se disparan lejos de la línea delatan los casos donde el algoritmo ha fallado significativamente.
Caso de Estudio 2: Clasificación y Retención de Clientes (Customer Churn)
Saltemos ahora de un output numérico a un problema de clasificación binaria: predecir si un usuario abandonará o no nuestra plataforma de servicios corporativos (Churn). Aquí, las características (X) son el costo de la suscripción, la antigüedad del cliente y su frecuencia de uso.
En un ecosistema empresarial maduro, este problema exige obligatoriamente un enfoque híbrido que busque el balance:
Desde la perspectiva predictiva: El negocio necesita estimar con precisión matemática la probabilidad de fuga de los usuarios vigentes para anticipar el valor del ciclo de vida del cliente y dimensionar el equipo de soporte necesario.
Desde la perspectiva interpretativa: De nada sirve saber que un cliente se va a ir si no entendemos los factores subyacentes que provocan su descontento. Identificar que el “costo de suscripción” es la variable con mayor peso explicivo permite a la dirección ajustar las tarifas estratégicamente antes de que ocurra la fuga.
La Sinergia Oculta: Cómo se ayudan mutuamente
La gran conclusión de este módulo es que la interpretación y la predicción no son enemigas acérrimas; de hecho, en la mayoría de los proyectos reales de Machine Learning, coexistir y retroalimentarse es el camino óptimo.
La interpretación mejora la predicción: Al inspeccionar los coeficientes e importancias de un modelo inicial, podemos descubrir qué variables son puro ruido estadístico para eliminarlas, o cuáles pueden combinarse entre sí para simplificar el entorno, guiando al algoritmo hacia un score predictivo mucho más alto.
La predicción valida la interpretación: Si construyes un modelo muy explicable pero sus métricas predictivas son pésimas (baja cercanía a la diagonal), no puedes confiar en las conclusiones de sus parámetros. Un nivel robusto de precisión predictiva te otorga la confianza científica de que los factores identificados como “importantes” realmente controlan el fenómeno en el mundo real.
Conclusión del Marco de Trabajo (Framework)
El Aprendizaje Supervisado es una rama de la IA cuyo núcleo es el desarrollo de modelos matemáticos basados en la experiencia pasada para predecir o explicar experiencias futuras.
La estructura matemática general siempre obedece a la misma función fundamental:
$$\hat{y} = f(W, X)$$
Donde nuestra predicción (\(\)\hat{y}\(\)) se construye a partir de una función que combina las características de entrada (X) con los parámetros o pesos (W) que el algoritmo ha aprendido del histórico de datos. Tu rol como Data Scientist será siempre determinar, basándote en los objetivos comerciales de la organización, qué tanto necesitas abrir esa función f para explicarla, o qué tanto puedes cerrarla en una potente “caja negra” en pos del rendimiento absoluto.
Flujo general del aprendizaje supervisado
El proceso suele seguir las siguientes etapas:
Disponemos de un conjunto de datos etiquetado.
Seleccionamos un algoritmo de Machine Learning.
Entrenamos el modelo con los datos históricos.
El algoritmo ajusta sus parámetros internos para aprender la relación entre las variables.
Una vez entrenado, utilizamos el modelo para realizar predicciones sobre datos nuevos.
Este enfoque permite automatizar la toma de decisiones y generar estimaciones basadas en patrones previamente observados.
Desarrollo de un Motor de Recomendación para Plataformas MOOC mediante Machine Learning
Este proyecto corresponde al Capstone Project del programa profesional IBM Machine Learning Professional Certificate, finalizado en 2025. Como trabajo final de la certificación, integra de forma práctica los conocimientos adquiridos a lo largo de todo el itinerario formativo, incluyendo análisis exploratorio de datos, ingeniería de características, aprendizaje supervisado y no supervisado, reducción de dimensionalidad, procesamiento de datos textuales y sistemas de recomendación.
El objetivo del proyecto es resolver un problema empresarial real mediante la aplicación de técnicas de Machine Learning, siguiendo una metodología similar a la empleada en entornos profesionales de ciencia de datos e inteligencia artificial.
Reestructuración del Proyecto y Gestión de Datos
Durante el análisis inicial de este proyecto se identificó que los notebooks originales funcionan de forma relativamente independiente y utilizan distintos conjuntos de datos previamente preparados. Lo que constituye una de las debilidades de muchos proyectos educativos: el pipeline real está oculto o simplificado para centrarse en la técnica que se quiere enseñar. Esto dificulta la comprensión del flujo completo de datos y la trazabilidad de las transformaciones realizadas a lo largo del proyecto.
Con el objetivo de construir una solución más cercana a un entorno profesional de Ciencia de Datos y Machine Learning, se ha decidido reorganizar el proyecto siguiendo una arquitectura basada en etapas claramente definidas. Para ello, se identificarán los conjuntos de datos originales proporcionados por IBM y se establecerá un flujo de procesamiento donde cada notebook consumirá los resultados generados por la fase anterior.
El proyecto partirá de tres fuentes de datos principales:
course_genre.csv, que contiene la información categórica de los cursos.
course_processed.csv, que contiene la información textual de los cursos utilizada para las tareas de procesamiento de lenguaje natural.
ratings.csv, que almacena las interacciones entre usuarios y cursos.
La arquitectura final seguirá un enfoque tipo pipeline, donde los datos evolucionan progresivamente desde su estado original hasta convertirse en las características y estructuras necesarias para los diferentes sistemas de recomendación implementados. Este enfoque aporta varias ventajas:
De esta manera, el proyecto mantiene el mismo problema de negocio planteado en el Capstone de IBM, pero adopta una estructura de datos más sólida, transparente y alineada con las buenas prácticas de desarrollo de proyectos de Machine Learning en entornos reales.
Introducción
Los sistemas de recomendación se han convertido en una pieza fundamental dentro de las plataformas digitales modernas. Empresas como Netflix, Spotify, Amazon, YouTube o Coursera utilizan algoritmos de recomendación para personalizar la experiencia de sus usuarios, facilitar el descubrimiento de contenido relevante y aumentar los niveles de interacción dentro de sus ecosistemas.
En este proyecto se aborda el diseño y desarrollo de un sistema de recomendación aplicado al sector de la formación online. El escenario se sitúa en una plataforma MOOC (Massive Open Online Course) denominada AI Training Room, una empresa dedicada a la distribución de cursos relacionados con inteligencia artificial, machine learning, ciencia de datos, computación en la nube y desarrollo de software.
Debido al rápido crecimiento de la plataforma y al incremento constante del catálogo de cursos disponibles, surge la necesidad de ayudar a los estudiantes a identificar contenidos de interés de forma eficiente. Un sistema de recomendación permite resolver este problema mediante el análisis de los cursos existentes y del comportamiento de los usuarios, generando sugerencias personalizadas que facilitan la construcción de itinerarios formativos adaptados a cada alumno.
Desde una perspectiva empresarial, una recomendación más precisa no solo mejora la experiencia de aprendizaje, sino que también puede incrementar indicadores clave como la retención de usuarios, el número de inscripciones por estudiante y los ingresos de la organización.
El objetivo principal de este proyecto consiste en explorar, implementar y comparar diferentes enfoques de recomendación utilizando técnicas de aprendizaje automático tanto supervisadas como no supervisadas. Para ello se trabajará con información relativa a cursos, contenidos y registros de inscripción de estudiantes.
A lo largo del proyecto se desarrollará un flujo de trabajo completo de Machine Learning que incluye:
Comprensión y exploración de los datos disponibles.
Análisis exploratorio de datos (EDA).
Extracción de características textuales mediante técnicas de Bag of Words (BoW).
Construcción de sistemas de recomendación basados en contenido.
Aplicación de algoritmos de aprendizaje no supervisado como métricas de similitud, K-Means y Análisis de Componentes Principales (PCA).
Desarrollo de modelos de filtrado colaborativo utilizando algoritmos como K-Nearest Neighbors (KNN), Non-negative Matrix Factorization (NMF), Redes Neuronales Artificiales y modelos clásicos de Machine Learning.
Comparación del rendimiento de los distintos enfoques mediante evaluaciones offline.
El proyecto no busca únicamente obtener un modelo funcional, sino analizar las ventajas, limitaciones y casos de uso de cada técnica de recomendación. De esta forma, se reproduce un escenario real de investigación y desarrollo dentro de una empresa tecnológica, donde la selección del modelo adecuado requiere equilibrar precisión, escalabilidad e interpretabilidad.
Finalmente, este trabajo constituye una demostración práctica de competencias en análisis de datos, procesamiento de lenguaje natural, aprendizaje supervisado, aprendizaje no supervisado y sistemas de recomendación, áreas que representan una parte esencial de las aplicaciones modernas de Inteligencia Artificial.
1. Exploratory Data Analysis (EDA)
Antes de desarrollar los modelos de recomendación, fue necesario comprender la estructura y las características de los datos disponibles. Esta fase de análisis exploratorio tuvo como objetivo identificar los principales temas presentes en el catálogo de cursos, analizar la distribución de las categorías y detectar patrones relevantes en las inscripciones de los estudiantes.
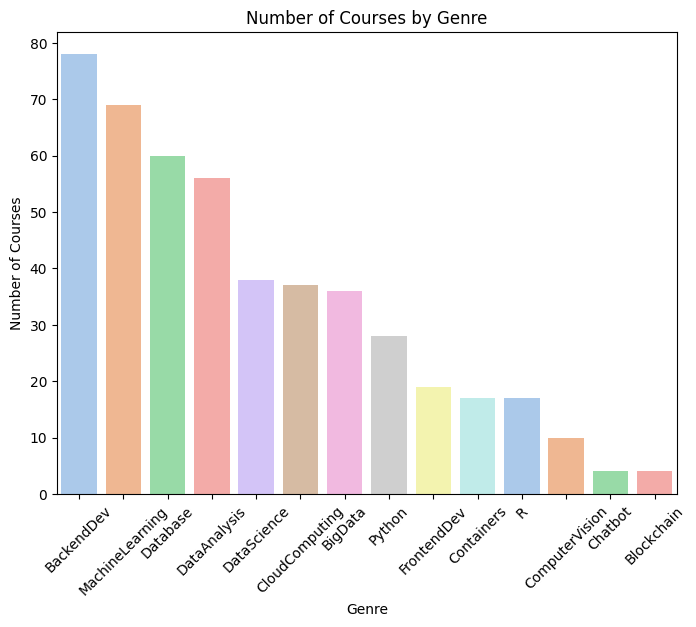
El conjunto de datos de cursos contiene 307 cursos online clasificados en 14 categorías tecnológicas diferentes, incluyendo Machine Learning, Data Science, Cloud Computing, Python, Big Data y Desarrollo Web. La ausencia de valores nulos y la representación binaria de las categorías proporcionan una base sólida para la construcción de sistemas de recomendación basados en contenido.
Para obtener una visión general del catálogo, se generó una nube de palabras a partir de los títulos de los cursos. El análisis reveló una fuerte presencia de tecnologías ampliamente demandadas en la industria, como Python, Machine Learning, Artificial Intelligence, Data Science, TensorFlow y Cloud Computing. Estos resultados confirman que la plataforma está orientada hacia competencias técnicas de alta relevancia en el mercado laboral actual.
Posteriormente, se analizó la distribución de las categorías para identificar las áreas temáticas más representadas. Este análisis permitió comprender el equilibrio del catálogo y detectar los dominios con mayor oferta formativa. Asimismo, se exploraron combinaciones de categorías, identificando cursos que integran áreas complementarias como Machine Learning y Big Data, una combinación especialmente relevante para el desarrollo de soluciones escalables basadas en datos.
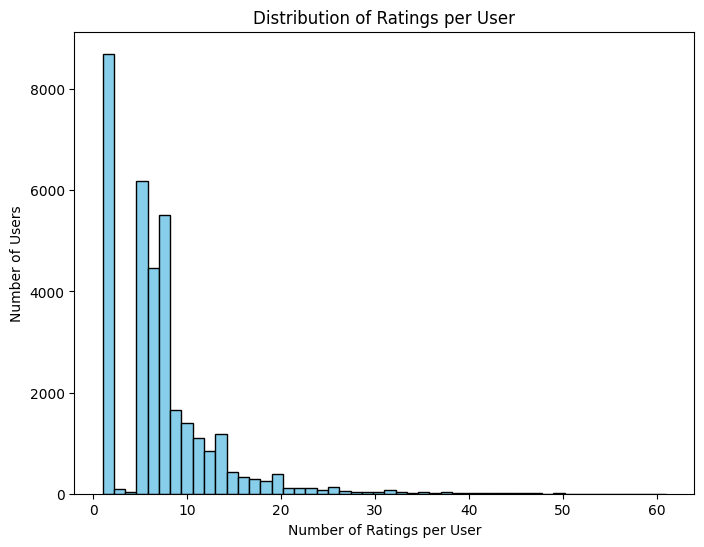
Finalmente, se examinó el conjunto de datos de inscripciones con el objetivo de identificar los cursos más populares y los patrones generales de participación de los estudiantes. Estos hallazgos proporcionaron información valiosa tanto para comprender el comportamiento de los usuarios como para fundamentar el diseño posterior de los modelos de recomendación.
Los 20 cursos con más estudiantes enrolados:
TITLE Enrolls0 python for data science 149361 introduction to data science 144772 big data 101 132913 hadoop 101 105994 data analysis with python 83035 data science methodology 77196 machine learning with python 76447 spark fundamentals i 75518 data science hands on with open source tools 71999 blockchain essentials 671910 data visualization with python 670911 deep learning 101 632312 build your own chatbot 551213 r for data science 523714 statistics 101 501515 introduction to cloud 498316 docker essentials a developer introduction 448017 sql and relational databases 101 369718 mapreduce and yarn 367019 data privacy fundamentals 3624
En conjunto, esta fase permitió obtener una comprensión profunda de los datos disponibles y sentó las bases para las etapas posteriores del proyecto, donde se aplicaron técnicas de recomendación basadas en similitud, clustering y filtrado colaborativo.
2. Ingeniería de Características: Representación Bag of Words (BoW)
Uno de los principales desafíos en la construcción de un sistema de recomendación basado en contenido es que los algoritmos de machine learning no pueden procesar directamente información textual. Aunque los títulos y descripciones de los cursos contienen información valiosa sobre las tecnologías, habilidades y temáticas abordadas, es necesario transformar ese contenido en una representación numérica antes de poder utilizarlo en modelos analíticos y algoritmos de recomendación.
Para resolver este problema, se implementó una estrategia de Bag of Words (BoW), una de las técnicas fundamentales del Procesamiento del Lenguaje Natural (NLP). El proceso comenzó con la preparación y limpieza del texto de los cursos mediante técnicas de tokenización, eliminación de palabras vacías (stopwords) y normalización del contenido textual. Este paso permitió reducir el ruido de los datos y conservar únicamente los términos más representativos de cada curso.
Una vez procesado el texto, se construyó un vocabulario global a partir de todos los términos presentes en el catálogo de cursos. Posteriormente, cada curso fue transformado en un vector numérico donde cada dimensión representa una palabra del vocabulario y su valor indica la frecuencia de aparición de dicho término en el curso correspondiente. De esta manera, el contenido textual quedó convertido en una estructura matemática apta para ser utilizada por algoritmos de machine learning.
El resultado de este proceso fue una matriz Bag of Words que captura la composición temática de cada curso y permite cuantificar el nivel de similitud entre ellos. Los cursos que comparten conceptos, tecnologías o áreas de conocimiento generan vectores similares, facilitando la identificación automática de contenidos relacionados incluso en ausencia de información histórica de los usuarios.
Esta fase constituye uno de los pilares del sistema de recomendación, ya que transforma datos no estructurados en características cuantificables sobre las que posteriormente se aplicarán métricas de similitud, algoritmos de clustering y modelos de recomendación basados en contenido.
Objetivos de la fase
Transformar información textual en variables numéricas procesables por algoritmos de machine learning.
Aplicar técnicas básicas de Procesamiento del Lenguaje Natural (NLP) para limpiar y estructurar el contenido de los cursos.
Construir un vocabulario representativo de las tecnologías y habilidades presentes en el catálogo.
Generar una matriz Bag of Words que describa matemáticamente cada curso.
Preparar la base de características que servirá como entrada para los modelos de recomendación desarrollados en las siguientes etapas del proyecto.
Tecnologías utilizadas
Python
Pandas
NLTK
Bag of Words (BoW)
Procesamiento del Lenguaje Natural (NLP)
Ingeniería de Características (Feature Engineering)
Resultado obtenido
Se generó una representación vectorial de los cursos basada en su contenido textual, permitiendo convertir descripciones y títulos en información cuantificable. Esta transformación constituye la base sobre la que se calcularán similitudes entre cursos y se construirán los modelos de recomendación personalizados del proyecto.
Imagen recomendada para esta sección: diagrama del pipeline Texto → Tokenización → Limpieza → Vocabulario → Matriz Bag of Words → Vector de Características.
Explicabilidad (“porque compraste X y tiene buenas reviews en Y”)
Dashboard de métricas (NDCG, Recall@K)
Despliegue: VPS (Docker) + Hugging Face Space (demo ligera)
Por qué impresiona: Es uno de los problemas más demandados en industria.
2. Predictive Maintenance + Análisis de Fallos (Industria 4.0)
Dataset: NASA Turbofan Engine Degradation o Predictive Maintenance Dataset (Kaggle)
Qué incluye:
Predicción de Remaining Useful Life (RUL)
Detección de anomalías (Isolation Forest + LSTM/Transformer)
Dashboard con evolución temporal y alertas
Stack:
Procesamiento de series temporales
FastAPI backend
Streamlit frontend con gráficos interactivos (Plotly)
Optuna + MLflow para tracking
Valor añadido: Simulación de “alarma temprana” y costo ahorrado.
Despliegue: VPS principal + HF Space para demo.
3. Plataforma de Análisis de Sentimiento + Voice of Customer (para Empresas)
Dataset: Amazon Reviews 2023 + opcional Twitter/X data
Funcionalidades:
Análisis de sentimiento aspect-based (qué les gusta y qué no)
Topic Modeling (BERTopic)
Detección de crisis (picos negativos)
Generación automática de reportes con LLM (Llama-3 o similar)
Frontend potente: Streamlit con filtros por producto/categoría/tiempo + visualizaciones bonitas
Por qué es fuerte: Combina NLP + Business Intelligence + LLMs.
4. Sistema de Optimización de Precios Dinámicos (Pricing Intelligence)
Dataset: Rossmann Store Sales, Walmart, o scraped de e-commerce
Modelos:
Forecasting (Prophet + XGBoost/LightGBM)
Elasticidad de demanda
Optimización (usando PuLP o OR-Tools)
App features:
Simulador “¿qué pasa si subo el precio 10%?”
Predicción de ventas + recomendación de precio óptimo
Dashboard ejecutivo
Nivel: Muy valorado en e-commerce y retail.
5. RAG + Agente Inteligente para Documentos Empresariales (LLM Application)
Datos: Puedes usar PDFs de reportes financieros, manuales técnicos, o dataset de papers (arXiv).
Tecnologías modernas:
Embeddings (sentence-transformers o voyage-ai)
Vector Database (Chroma, Pinecone o Qdrant)
RAG pipeline + LangChain / LlamaIndex
Agente que pueda razonar y usar herramientas
Frontend: Streamlit o Gradio con chat interactivo + fuentes citadas
Por qué es top en 2026: Las empresas buscan gente que sepa llevar LLMs a producción de forma útil.
Proyectos end-to-end potentes (más avanzados) que combinan Machine Learning clásico + IA Agentica (agentes autónomos con razonamiento, tools, memoria y planificación).
Estos están pensados para un portafolio Fullstack Data Science fuerte en 2026.
6. Agente Analista de Datos Autónomo (Data Analyst Agent)
Descripción: Un agente que recibe una pregunta en lenguaje natural (“¿Cuáles son los drivers de churn este trimestre?”) y automáticamente hace EDA, corre modelos, genera visualizaciones y reportes.