La probabilidad condicional es uno de los conceptos más importantes en estadística y ciencia de datos. Nos permite responder preguntas como:
¿Cuál es la probabilidad de que ocurra un evento A sabiendo que ya ocurrió un evento B?
En la vida real, casi ningún fenómeno ocurre de forma completamente independiente. Las variables se relacionan, se influyen y cambian entre sí. La probabilidad condicional nos da una forma matemática de actualizar nuestras expectativas cuando obtenemos nueva información.
Cuando los eventos no son independientes
Si dos eventos A y B son independientes, conocer que uno ocurrió no cambia la probabilidad del otro. Por ejemplo, lanzar una moneda y luego lanzar un dado son sucesos independientes.
Pero, ¿qué pasa si los eventos no son independientes? Entonces el hecho de que ocurra A modifica la probabilidad de que ocurra B. Esto es exactamente lo que estudia la probabilidad condicional.
Dependiendo del resultado, lanzamos un dado distinto:
Si sale cara, lanzamos un dado de 6 caras.
Si sale cruz, lanzamos un dado de 20 caras.
En este experimento, el tipo de dado que usamos depende del resultado de la moneda. Por tanto, el resultado del dado no es independiente del lanzamiento previo.
Calculando una probabilidad condicional
Queremos saber, por ejemplo: ¿Cuál es la probabilidad de obtener un 5 en el dado?
Existen dos formas de obtener un 5:
Caso 1: La moneda sale cara y el dado de 6 caras muestra un 5.
$$P(5 \text{ y cara}) = P(C) \times P(5|C)$$
Dado que el dado de 6 caras es justo:
$$P(5|C) = \frac{1}{6}$$
Entonces:
$$P(5 \text{ y cara}) = P_c \times \frac{1}{6}$$
Caso 2: La moneda sale cruz y el dado de 20 caras muestra un 5.
$$P(5 \text{ y cruz}) = P(E) \times P(5|E)$$
En este caso:
$$P(5|T) = \frac{1}{20}$$
Entonces:
$$P(5 \text{ y cruz}) = p_E \times \frac{1}{20}$$
La probabilidad total de obtener un 5 es la suma de ambos casos:
Imagina el área total de posibles resultados del experimento como un rectángulo.
Una parte representa los casos en que la moneda da cara y se lanza el dado de 6.
La otra parte representa los casos con cruz y el dado de 20.
El área combinada de ambos representa la probabilidad total de obtener cualquier resultado posible. Dentro de cada zona, las franjas correspondientes al número “5” son pequeñas porciones de ese total, y su tamaño depende del tipo de dado y de la probabilidad de cada cara o cruz.
Definición formal
La probabilidad condicional de un evento A, dado que ocurrió B, se define como:
$$P(A|B) = \frac{P(A \cap B)}{P(B)}$$
Es decir:
La probabilidad de que ocurra A dado que ocurrió B, es igual a la probabilidad de que ambos ocurran, dividida entre la probabilidad de B.
Ejemplo generalizado
Volviendo a nuestro experimento, podemos preguntar:
¿Cuál es la probabilidad de que el dado muestre 5 dado que salió cara?
Lo que confirma que, al saber que salió cara, solo nos interesa el dado de 6 caras, y cada resultado tiene probabilidad 1/6.
La regla del producto
De la definición anterior se deriva una relación muy útil:
$$P(A \cap B) = P(A|B) \times P(B)$$
Esta regla permite descomponer probabilidades conjuntas en términos condicionales y viceversa. También sirve para construir árboles de probabilidad, donde cada rama representa la probabilidad condicional de avanzar hacia un resultado dado.
El principio de no duplicar probabilidades
Un error común al calcular probabilidades es sumar eventos que no son independientes sin ajustar por su intersección. Por ejemplo, si queremos la probabilidad de que ocurra A o B, debemos restar el solapamiento:
$$P(A \cup B) = P(A) + P(B) – P(A \cap B)$$
De lo contrario, estaríamos contando dos veces los casos en que A y B ocurren simultáneamente.
En Resumen
La probabilidad condicional nos enseña que la información cambia la probabilidad. Saber que algo ocurrió modifica lo que podemos esperar a continuación. Es la base de la estadística inferencial, la teoría bayesiana y gran parte del razonamiento probabilístico moderno.
Nos permite pasar de la incertidumbre total a una incertidumbre informada, paso esencial en cualquier proceso analítico.
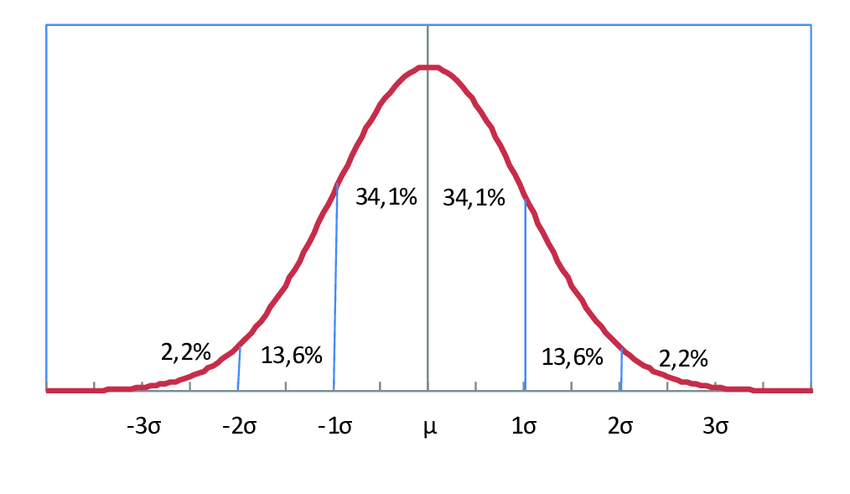
Cuando hablamos de probabilidad, a menudo pensamos en números entre 0 y 1, fracciones o porcentajes. Pero existe una forma geométrica e intuitiva de entender la probabilidad: la probabilidad es área.
¿Qué significa que la probabilidad sea área?
La probabilidad de que ocurra un evento puede representarse como la proporción del área total correspondiente a ese evento dentro del espacio de todos los posibles resultados.
Imagina un espacio de resultados como un rectángulo o un círculo que representa todos los resultados posibles de un experimento.
Cada punto dentro de este espacio es un resultado posible.
Un evento es una región dentro de ese espacio.
La probabilidad del evento es el área de esa región dividida entre el área total.
Ejemplo con un dado “geométrico”
Supongamos que lanzamos un dado y queremos visualizarlo en un diagrama rectangular:
Cada resultado (1, 2, 3, 4, 5, 6) ocupa el mismo “espacio” dentro del rectángulo.
El área de cada sección es igual, así que la probabilidad de cada resultado es:
$$P(\text{resultado}) = \frac{\text{área de la sección}}{\text{área total}} = \frac{1}{6}$$
Aquí, área = probabilidad. Este enfoque funciona incluso si el dado está sesgado: las áreas de cada sección cambian según la probabilidad, pero la suma de todas las áreas sigue siendo 1.
Distribuciones continuas
El concepto de probabilidad como área es fundamental en variables continuas, donde los resultados posibles no son discretos. Por ejemplo, si lanzamos un dado “perfectamente continuo” que puede dar cualquier valor entre 0 y 1, entonces:
No podemos hablar de un solo resultado: la probabilidad de un valor exacto es 0.
Pero podemos calcular la probabilidad de un intervalo, que es proporcional al área bajo la curva de densidad.
Esto es la base de la probabilidad continua y la función de densidad (PDF):
$$P(a \leq X \leq b) = \int_{a}^{b} f(x) dx$$
Aquí, la integral representa el área bajo la curva entre los puntos a y b, y esa área es la probabilidad de que X esté en ese intervalo.
Visualizando la probabilidad como área
Una forma muy clara de entenderlo es mediante un diagrama de rectángulos o gráficos de barras:
Cada barra representa un resultado posible.
La altura de la barra corresponde a la “densidad” o probabilidad.
El área de la barra es proporcional a la probabilidad del resultado.
En variables continuas, reemplazamos las barras por curvas suaves.
Por ejemplo, la distribución normal es una curva de campana:
La probabilidad de un intervalo es el área bajo la curva en ese intervalo.
Aplicaciones prácticas
Visualizar la probabilidad como área tiene ventajas:
Intuición inmediata: Nos ayuda a “ver” los eventos probables y menos probables.
Distribuciones continuas: Fundamental en estadística, machine learning y análisis de datos.
Comparación de eventos: Podemos comparar fácilmente qué evento es más probable observando qué área ocupa.
Simulaciones y Monte Carlo: Al generar puntos aleatorios dentro de un espacio, contar cuántos caen dentro de un evento es equivalente a calcular el área y, por lo tanto, la probabilidad.
En resumen
La probabilidad puede visualizarse como área dentro de un espacio de resultados.
En eventos discretos, el área es proporcional a la fracción de resultados posibles.
En variables continuas, la probabilidad es el área bajo la curva de densidad.
Este enfoque conecta geometría y estadística, haciendo que la probabilidad sea más intuitiva y visual.
La probabilidad es una herramienta matemática que nos permite cuantificar la incertidumbre asociada a fenómenos aleatorios. A través de ella, podemos estimar la posibilidad de que ocurran ciertos eventos y construir modelos que representen el comportamiento de sistemas inciertos: desde el lanzamiento de un dado hasta la predicción de enfermedades o el rendimiento de un modelo de Machine Learning.
El estudio de la probabilidad se basa en modelos formales, llamados modelos de probabilidad, que se sustentan en axiomas y reglas fundamentales. En esta sección exploraremos estos conceptos, desde las bases hasta aplicaciones prácticas como la Ley de Bayes o la construcción de un Clasificador de Bayes desde cero.
El Modelo de Probabilidad
Un modelo de probabilidad es un marco conceptual y matemático que permite analizar y predecir el comportamiento de fenómenos aleatorios.
Se apoya en dos componentes esenciales:
Espacio muestral (Ω): el conjunto de todos los resultados posibles de un experimento aleatorio.
Regla de probabilidad (P): una función que asigna valores entre 0 y 1 a cada subconjunto del espacio muestral.
El objetivo de este modelo es establecer una ley de probabilidad, una regla que asigne de manera coherente valores no negativos a los eventos, reflejando nuestro grado de confianza o creencia en que ocurran.
Asignación de Probabilidades
La asignación de probabilidades consiste en atribuir valores numéricos a los eventos del espacio muestral. Reflejando la confianza o la creencia en la ocurrencia de esos eventos.
La probabilidad de un evento \( A \), denotada como \(P(A) \), representa qué tan probable es que \( A \) ocurra cuando se realiza el experimento. Cumple siempre:
$$0 \leq P(A) \leq 1$$
Ley de Laplace
También conocida como la regla de la probabilidad clásica o equiprobable, establece que si un experimento aleatorio tiene resultados igualmente probables, entonces la probabilidad de un evento \(E\) es el número de resultados en \(|E|\) dividido por el número total de resultados posibles en el espacio muestral \(|S|\).
$$P(E) = \frac{|E|}{|S|}$$
Ejemplo práctico: Un bol contiene 3 bolas rojas y 2 azules.
$$P(\text{Roja}) = \frac{3}{5} = 0.6$$
Si no conocemos los colores, pero sabemos que hay 5 bolas idénticas, la probabilidad de sacar una cualquiera sería ( 1/5 ).
Axiomas de la Probabilidad
Formulados por Kolmogórov (1933), los axiomas definen la base formal de la probabilidad. Son las reglas fundamentales para definir las probabilidades de los eventos dentro del marco de la teoría de probabilidad.
No Negatividad:
El primer axioma establece que la probabilidad de cualquier evento es siempre un número no negativo.
$$ P(A) \geq 0 $$
Normalización:
La probabilidad del espacio muestral completo, representado como \(S\), es igual a 1. Esto significa que es seguro que ocurrirá algún resultado del experimento aleatorio. Se expresa como:
$$P(S)=1$$
Aditividad (Regla de la Suma para eventos disjuntos):
Para dos eventos \(A\) y \(B\) que no pueden ocurrir al mismo tiempo (es decir, son mutuamente excluyentes), la regla de la suma establece que la probabilidad de que ocurra \(A\) o \(B\) es simplemente la suma de sus probabilidades individuales:
$$P(A∪B)=P(A)+P(B)$$
Regla de la Suma para eventos no excluyentes
La regla de la suma es una derivación del axioma de aditivita en caso de que los eventos no sean mutuamente excluyentes. Esta permite calcular la probabilidad de que ocurra al menos uno de dos eventos.
$$P(A \cup B) = P(A) + P(B) – P(A \cap B)$$
Ejemplo (cartas): Probabilidad de sacar un as o un corazón:
$$P(A \cup B) = \frac{4}{52} + \frac{13}{52} – \frac{1}{52} $$
$$P(A \cup B) = \frac{16}{52} = \frac{4}{13}$$
Ejemplo (dados): Número impar o mayor que 4:
$$P(A \cup B) = \frac{3}{6} + \frac{2}{6} – \frac{1}{6} $$
$$P(A \cup B)= \frac{4}{6} = \frac{2}{3}$$
Regla de la Multiplicación general
Es un teorema derivado de los axiomas de probabilidad se define a partir del concepto de probabilidad condicional. Permite calcular la probabilidad de que ocurran dos o más eventos a la vez.
Dado que A paso, ¿Cuál es la probabilidad de B?
$$P(A \cap B) = P(A) \times P(B|A)$$
Eventos independientes:
Si A y B son independientes (el resultado de uno no afecta al otro):
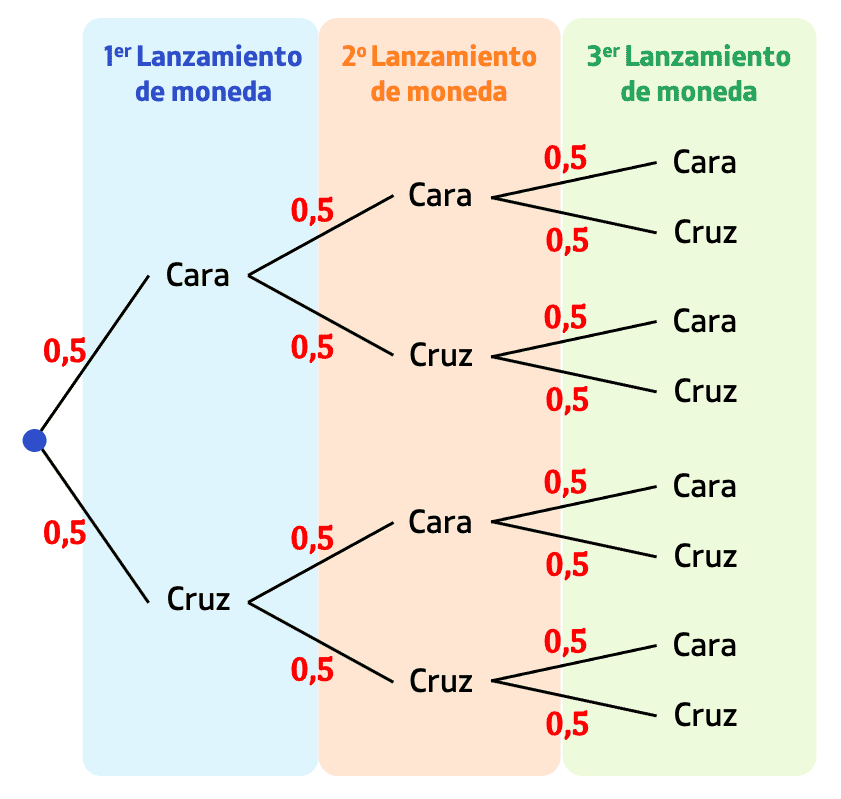
Un diagrama de árbol representa de forma visual las posibles secuencias de eventos y sus probabilidades. Cada rama muestra un resultado y la probabilidad asociada.
Ejemplo (dos monedas):
Cada camino representa un evento y su probabilidad se obtiene multiplicando las ramas.
Derivaciones de los Axiomas
A partir de estos axiomas, se pueden deducir varias reglas importantes que son esenciales para el trabajo práctico en probabilidad y estadística.:
Probabilidad del Complemento de un Evento:
Una de las derivaciones más directas es la probabilidad del complemento de un evento. Si A es un evento, entonces el complemento de A, denotado \( A^c\), representa la ocurrencia de \(no−A\). Utilizando los axiomas, se puede demostrar que:
$$P(A^c) = 1 – P(A)$$
Esto se deduce del hecho de que \( A\), y \( A^c\) son mutuamente excluyentes y su unión es el espacio muestral completo, cuya probabilidad es 1.
Probabilidad de Eventos Vacíos y Ciertos:
Directamente de los axiomas, se establece que la probabilidad del conjunto vacío \(∅\), que es un evento imposible, es 0:
$$P(\emptyset) = 0 $$
Asimismo, la probabilidad del espacio muestral completo \( Ω\) , que representa un evento seguro, es 1:
$$P(Ω)=1$$
Monotonicidad:
Si un evento A es un subconjunto de otro evento B, entonces la probabilidad de A es menor o igual a la probabilidad de B. Esto refleja la idea de que la ocurrencia de B incluye la ocurrencia de A junto con posiblemente otros resultados:
$$A \subseteq B \Rightarrow P(A) \leq P(B$$
Probabilidad de unión:
Para dos eventos A y B, la probabilidad de su unión puede ser expresada en términos de las probabilidades de A, B, y su intersección \(A∩B\). Esta regla se aplica incluso si A y B no son disjuntos y se deriva como sigue:
$$ P(A \cup B) = P(A) + P(B) – P(A \cap B)$$
Esto ajusta la aditividad para el caso de eventos que no son mutuamente excluyentes, evitando la sobre contabilización de la intersección de A y B.
Subaditividad:
La subaditividad se refiere a la propiedad de que la probabilidad de la unión de cualquier colección de eventos es menor o igual a la suma de sus probabilidades individuales. Para una secuencia de eventos \(A1,A2,….,An\):
Esta propiedad es particularmente útil para tratar con uniones de eventos que no son necesariamente disjuntos.
Límites de Probabilidad:
Cualquier probabilidad \(P(A)\) para un evento A siempre estará en el rango de 0 a 1, inclusive. Esto se deriva del hecho de que todas las probabilidades son no negativas y que la probabilidad del espacio muestral, el conjunto más grande posible, es 1.
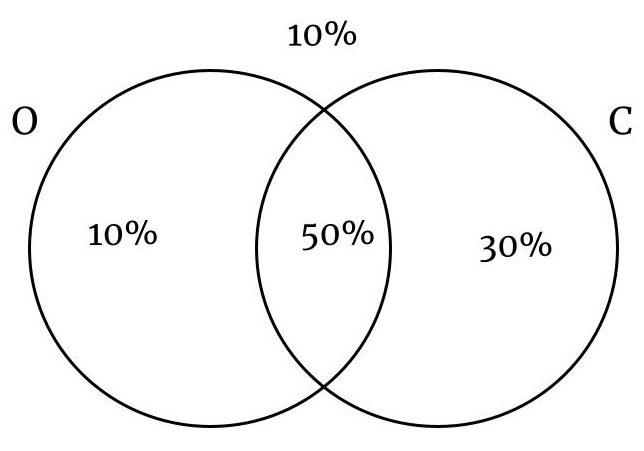
Tablas de Contingencia
Organizan y muestran las probabilidades de combinaciones de dos variables.+
Ejemplo:
En una ciudad el 60% de las personas tienen ojos negros, el 80% tienen cabello negro y el 50% tienen cabello negro y ojos negros. Si se selecciona una persona al azar, calcule la probabilidad que:
No tenga los ojos negros.
Tenga los ojos o cabello negro
O –> Ojos Negros
C –> Cabellos Negros
Variables
Ojos Negros
Ojos No Negros
Total
Cabello Negro
50%
30%
80%
Cabello No Negro
10%
10%
20%
Total
60%
40%
1.00
Las tablas permiten calcular probabilidades marginales, conjuntas y condicionales de manera sencilla.
Modelos de Probabilidad Discretos
Los modelos de probabilidad discretos se ocupan de experimentos donde el número de posibles resultados es finito o contable. Un ejemplo clásico es el lanzamiento de dados, donde los resultados posibles pueden listarse de manera explícita.
Ejemplo: dos dados de cuatro caras.
Supongamos que tenemos dos dados de cuatro caras, donde cada resultado tiene una probabilidad de 1/161/16, podemos construir una tabla que muestre todas las combinaciones posibles de los resultados de los dos dados. Cada dado puede mostrar uno de cuatro resultados posibles (1, 2, 3, o 4), lo que nos da un total de 4×4=164×4=16 combinaciones posibles para los dos dados.
Probabilidades
1
2
3
4
1
1/16
1/16
1/16
1/16
2
1/16
1/16
1/16
1/16
3
1/16
1/16
1/16
1/16
4
1/16
1/16
1/16
1/16
Sumas
1
2
3
4
1
2
3
4
5
2
3
4
5
6
3
4
5
6
7
4
5
6
7
8
Probabilidad de suma par: 8 combinaciones → ( 8/16 = 1/2 ) Probabilidad de al menos un 4: 7 combinaciones → ( 7/16 )
Ejemplo Aplicado: Diagnóstico Médico
Un médico sabe que:
\( P(\text{Malaria}) = 0.6 \)
\( P(\text{Tifoidea}) = 0.7 \)
\( P(\text{Ambas}) = 0.4 \)
La probabilidad de que no tenga ninguna enfermedad:
$$P(\text{No M ni T}) = 1 – P(\text{M} \cup \text{T}) = 1 – [0.6 + 0.7 – 0.4] = 0.1$$
El 10% de los pacientes no tendra ninguna enfermedad.
En resumen
Las distribuciones de probabilidad son la base para el análisis estadístico, la simulación y la inferencia.
La probabilidad mide la incertidumbre.
Todo experimento tiene un conjunto de posibles resultados (espacio muestral).
Los eventos son subconjuntos de ese espacio.
Las probabilidades se pueden estimar mediante la frecuencia de los resultados en ensayos repetidos.
La suma de las probabilidades de todos los resultados posibles siempre es 1.
Se refiere a cualquier proceso o acción que se realiza bajo condiciones específicas y controladas, pero que, sin embargo, puede producir diferentes resultados en cada realización, sin que sea posible predecir con certeza cuál será el resultado específico en una instancia particular del experimento. La característica distintiva de un experimento aleatorio es esta incertidumbre inherente en el resultado.
Aunque las condiciones sean las mismas, el resultado puede variar en cada repetición. La característica clave es la incertidumbre del resultado.
Características de un Experimento Aleatorio
Múltiples resultados posibles: Puede producir más de un resultado distinto. Ejemplo: al lanzar un dado, los posibles resultados son ( {1, 2, 3, 4, 5, 6} ).
Resultado impredecible: No se puede saber con certeza cuál será el resultado antes de realizar el experimento.
Repetibilidad: El experimento puede repetirse bajo las mismas condiciones, manteniendo las mismas probabilidades para cada posible resultado.
Ejemplos Clásicos
Experimento
Espacio Muestral
Lanzar una moneda
{Cara, Cruz}
Lanzar un dado
{1, 2, 3, 4, 5, 6}
Extraer una carta de una baraja
52 posibles resultados
Medir el tiempo de vida de un componente
valores continuos en segundos o días
Resultado (Punto Muestral)
En el contexto de experimentos aleatorios en probabilidad y estadística. Un resultado es definido como el resultado observable de realizar un experimento, el cual, bajo las mismas condiciones, puede variar en cada realización. Esto ilustra la naturaleza aleatoria de tales experimentos, donde no es posible predecir con certeza el resultado específico antes de realizar el experimento.
El espacio muestral es el conjunto de todos los posibles resultados de un experimento aleatorio. simbolizado comúnmente como S o Ω. Cada resultado individual dentro del espacio muestral es un punto muestral.
Algunos espacios muestrales pueden ser infinitos, como lanzar una moneda hasta obtener “Cara”. Aunque sea infinito, sigue siendo contable, ya que podemos enumerar los posibles resultados.
Un evento o suceso se define como uno o cualquier conjunto de resultados posibles de un experimento. El espacio muestral S o Ω de un experimento es el conjunto de todos los posibles resultados individuales, y un evento es cualquier subconjunto de este espacio. Esto incluye desde el conjunto vacío, que representa un evento que nunca ocurre, hasta el espacio muestral completo, que es un evento que siempre ocurre.
Evento seguro: ocurre siempre → coincide con todo el espacio muestral.
Evento imposible: nunca ocurre → conjunto vacío \(\emptyset \).
S = [("Cara", "Cara"), ("Cara", "Cruz"), ("Cruz", "Cara"), ("Cruz", "Cruz")]A = [x for x in S if x[0] == "Cara"]print("Evento A:", A)
Salida:
Evento A: [('Cara', 'Cara'), ('Cara', 'Cruz')]
Eventos Mutuamente Excluyentes
Dos eventos son mutuamente excluyentes si no pueden ocurrir al mismo tiempo. En el lanzamiento de una moneda, los eventos “Cara” y “Cruz” son mutuamente excluyentes.
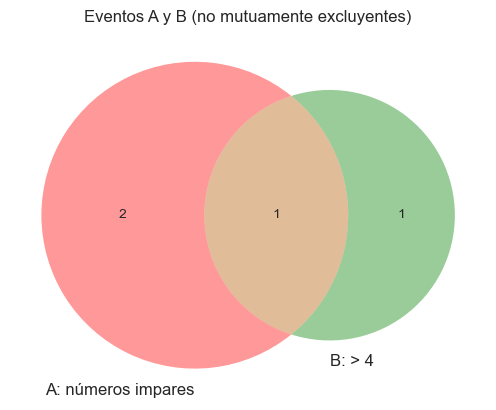
Ejemplo con Dado:
( A ): número impar → {1, 3, 5}
( B ): número mayor que 4 → {5, 6}
Intersección: {5} ⇒ No son mutuamente excluyentes.
Visualización con Diagramas de Venn
Podemos usar matplotlib-venn para visualizar intersecciones de eventos.
from matplotlib import pyplot as pltfrom matplotlib_venn import venn2A = set([1, 3, 5])B = set([5, 6])venn2([A, B], set_labels=('A: números impares', 'B: > 4'))plt.title("Eventos A y B (no mutuamente excluyentes)")plt.show()
Resumen Conceptual
Concepto
Descripción
Ejemplo
Experimento Aleatorio
Proceso con resultado incierto
Lanzar un dado
Resultado
Un resultado individual
“5”
Espacio Muestral (S)
Conjunto de todos los resultados
{1,2,3,4,5,6}
Evento
Subconjunto de S
“número par” = {2,4,6}
Eventos Mutuamente Excluyentes
No pueden ocurrir simultáneamente
“Cara” y “Cruz”
En la práctica estadística
En estadística aplicada y machine learning, estos conceptos son fundamentales porque:
Permiten modelar la incertidumbre (base de la probabilidad).
Sirven para definir variables aleatorias y distribuciones.
Son la base de los métodos inferenciales, como estimación o pruebas de hipótesis.
¿Quieres que el siguiente artículo de la serie sea sobre variables aleatorias (discretas y continuas) o sobre probabilidad condicional y regla de Bayes?
Los conjuntos son uno de los conceptos más básicos y a la vez más importantes en estadística y probabilidad. Toda la teoría de la probabilidad —y, por extensión, gran parte del análisis estadístico— se construye sobre la teoría de conjuntos, que nos permite describir y razonar sobre eventos, muestras y resultados posibles.
¿Qué es un Conjunto?
Un conjunto es una colección bien definida de elementos, que pueden ser números, personas, objetos o resultados de un experimento.
En estadística, usamos conjuntos para describir:
El espacio muestral (todos los resultados posibles de un experimento).
Los eventos (subconjuntos del espacio muestral).
Las relaciones entre distintos eventos.
Por ejemplo:
Si lanzamos un dado, el espacio muestral es
$$S = {1, 2, 3, 4, 5, 6}$$
Un evento puede ser “obtener un número par”:
$$A = {2, 4, 6}$$
Operaciones entre Conjuntos
Las operaciones entre conjuntos reflejan relaciones entre eventos en probabilidad.
Operación
Descripción
Símbolo
Ejemplo (en el dado)
Unión
Ocurre A o B (o ambos)
\(A \cup B\)
“Número par o mayor que 4”
Intersección
Ocurre A y B a la vez
\(A \cap B\)
“Número par y mayor que 4”
Complemento
No ocurre A
\(A’\) o \(A^c\)
“Número impar”
Diferencia
Elementos en A que no están en B
\(A – B\)
“Números pares que no son mayores que 4”
Estas operaciones son la base del cálculo de probabilidades, porque cada evento se asocia con un conjunto de resultados, y las reglas de probabilidad siguen las mismas leyes que los conjuntos (como las Leyes de De Morgan).
Ejemplo Práctico en Python
Podemos representar los conjuntos y operaciones anteriores fácilmente con set:
# Espacio muestral del lanzamiento de un dadoS = {1, 2, 3, 4, 5, 6}# EventosA = {2, 4, 6} # número parB = {4, 5, 6} # número mayor que 3# Operaciones entre conjuntosunion = A | Binterseccion = A & Bcomplemento = S - Adiferencia = A - Bprint("A ∪ B =", union)print("A ∩ B =", interseccion)print("A' =", complemento)print("A - B =", diferencia)
Salida:
A ∪ B = {2, 4, 5, 6}A ∩ B = {4, 6}A' = {1, 3, 5}A - B = {2}
Conjuntos y Probabilidad
En la teoría de la probabilidad, los conjuntos se usan para definir y combinar eventos. La probabilidad de un evento \( A \) se define como la proporción de casos favorables respecto al total de casos posibles:
Las Leyes de De Morgan conectan los conceptos de unión, intersección y complemento, tanto en conjuntos como en eventos probabilísticos:
$$(A \cup B)’ = A’ \cap B’$$
$$(A \cap B)’ = A’ \cup B’$$
Estas leyes permiten simplificar cálculos y entender mejor la relación entre eventos.
Verificación en Python: assert no devuelve ningún valor. Es una instrucción de verificación:
Si la condición es verdadera, no hace nada.
Si la condición es falsa, lanza un AssertionError.
U = {1, 2, 3, 4, 5, 6}A = {1, 2, 3}B = {3, 4, 5}# Leyes de De Morgan:# (A ∪ B)' = A' ∩ B'# (A ∩ B)' = A' ∪ B'assert U - (A | B) == (U - A) & (U - B)assert U - (A & B) == (U - A) | (U - B)print("Ambas leyes de De Morgan se verifican correctamente.")
Representación Visual: Diagramas de Venn
En estadística, los diagramas de Venn son una herramienta visual para representar eventos y sus intersecciones.
En Python podemos generarlos fácilmente:
from matplotlib import pyplot as pltfrom matplotlib_venn import venn2A = {1, 2, 3, 4, 5}B = {4, 5, 6, 7, 8}union = A | Binterseccion = A & Bdiferencia = A - Bprint("A ∪ B:", union)print("A ∩ B:", interseccion)print("A - B:", diferencia)venn2([A, B], set_labels=('A', 'B'))plt.title("Operaciones entre conjuntos")plt.show()
Union - A ∪ B: {1, 2, 3, 4, 5, 6, 7, 8}Interseccion - A ∩ B: {4, 5}Diferencia - A - B: {1, 2, 3}
Estos gráficos son muy útiles al enseñar reglas de probabilidad, interdependencia de eventos y espacios muestrales.
Cuando trabajamos con datos, es muy común escuchar los términos probabilidad y estadística. A menudo se usan de manera indistinta, pero en realidad representan dos enfoques complementarios dentro del análisis cuantitativo: uno mira hacia el futuro y el otro hacia el pasado.
¿Qué es la probabilidad?
La probabilidad es la rama de la matemática que estudia la incertidumbre de los eventos futuros. Su objetivo es predecir la posibilidad de que algo ocurra, basándose en un modelo o conjunto de reglas conocidas.
En términos simples:
Si la probabilidad de un evento es 0, significa que no puede ocurrir.
Si es 1, significa que ocurrirá con certeza.
Y si es, por ejemplo, 0.73, interpretamos que hay un 73% de confianza en que el evento sucederá.
Por ejemplo, si lanzamos una moneda justa, la probabilidad de obtener “cara” es de 0.5. No sabemos qué ocurrirá en un lanzamiento particular, pero sí podemos modelar el comportamiento esperado a largo plazo.
La probabilidad como teoría se enfoca en desarrollar leyes, reglas y fórmulas matemáticas que permiten cuantificar la incertidumbre. No necesita datos históricos; parte de supuestos o modelos ideales (por ejemplo, monedas justas, dados equilibrados, distribuciones normales, etc.).
¿Qué es la Estadística?
La estadística, en cambio, mira hacia el pasado. Su tarea es aprender de los datos existentes: descubrir patrones, estimar parámetros y generar modelos que expliquen la realidad observada.
Mientras la probabilidad se basa en reglas teóricas para predecir el futuro, la estadística extrae esas reglas a partir de datos reales.
Por ejemplo, si observamos el resultado de 1000 lanzamientos de una moneda y obtenemos 520 caras y 480 cruces, podemos usar estadística para inferir si la moneda es justa o no.
En ciencia de datos, la estadística incluye:
Descriptiva → resumir y visualizar datos (media, desviación estándar, histogramas, etc.)
Inferencial → estimar y hacer inferencias sobre una población usando una muestra (intervalos de confianza, tests de hipótesis, regresión, etc.)
Ejemplo práctico
Supongamos que tenemos datos históricos de lluvia de los últimos 10 años en una ciudad.
Un estadístico analizará los datos pasados para estimar la frecuencia de días lluviosos, promedios, variaciones y tendencias. → “En promedio, llueve el 30% de los días del año.”
Un probabilista utilizará esos patrones para predecir la probabilidad de que mañana llueva. → “Según el modelo, la probabilidad de lluvia mañana es del 35%.”
En Ciencia de Datos
En los proyectos de ciencia de datos, ambas disciplinas trabajan juntas:
Etapa del proceso
Enfoque
Objetivo
Exploración y limpieza
Estadística descriptiva
Entender y preparar los datos
Modelado y ajuste
Estadística inferencial
Estimar parámetros del modelo
Predicción
Probabilidad aplicada
Calcular probabilidades de eventos futuros
Evaluación del modelo
Estadística y probabilidad
Validar y cuantificar incertidumbre
Por ejemplo, cuando entrenamos un modelo de clasificación, usamos estadística para estimar los parámetros del modelo y probabilidad para predecir la pertenencia de un nuevo dato a una clase determinada.
Las expresiones regulares son una herramienta esencial en Python para buscar, validar y transformar texto. Se implementan a través del módulo estándar re, que proporciona funciones como search(), match(), findall(), split() o sub().
Puedes experimentar tus expresiones directamente en regex101.com seleccionando el motor Python.
Clases de Caracteres
Expresión
Descripción
[ABC]
Coincide con cualquiera de los caracteres dentro de los corchetes.
[^ABC]
Coincide con cualquier carácter que no esté en el conjunto.
[A-Z]
Coincide con un carácter dentro del rango especificado (inclusive).
.
Coincide con cualquier carácter, excepto el salto de línea (\n). Puede incluirlo si se usa la bandera re.S.
\w
Coincide con un carácter de palabra (letra, número o guion bajo). Equivalente a [A-Za-z0-9_].
\W
Coincide con cualquier carácter que no sea de palabra.
\d
Coincide con un dígito (0–9).
\D
Coincide con cualquier carácter que no sea un dígito.
\s
Coincide con un carácter de espacio en blanco (espacio, tab, salto de línea, retorno de carro, etc.).
\S
Coincide con cualquier carácter que no sea espacio en blanco.
\n, \r, \t, \f, \v
Coinciden con salto de línea, retorno de carro, tabulación, salto de página y tabulación vertical, respectivamente.
\xFF
Coincide con el carácter cuyo valor hexadecimal es FF.
\uFFFF
Coincide con el carácter Unicode especificado (por ejemplo \u00F1 → ñ).
Anclas
Expresión
Descripción
^
Coincide con el inicio de la cadena o de una línea (si se usa re.M).
$
Coincide con el final de la cadena o de una línea (si se usa re.M).
\b
Coincide con un límite de palabra (entre un carácter de palabra y uno que no lo es).
\B
Coincide con una posición que no sea límite de palabra.
\A
Coincide solo al inicio de toda la cadena (no afectado por re.M).
\Z
Coincide solo al final de toda la cadena (no afectado por re.M).
Grupos de Captura
Expresión
Descripción
(ABC)
Agrupa tokens y crea un grupo de captura.
(?P<nombre>ABC)
Grupo de captura con nombre, referenciable como (?P=nombre) o \g<nombre> en reemplazos.
\1, \2, \3
Referencias a grupos de captura por número.
(?:ABC)
Grupo no capturante: agrupa sin guardar coincidencias.
Lookaround (búsquedas anticipadas y retrospectivas)
Expresión
Descripción
(?=ABC)
Lookahead positivo: coincide si después del patrón actual está ABC.
(?!ABC)
Lookahead negativo: coincide si no hay ABC después.
(?<=ABC)
Lookbehind positivo: coincide si antes del patrón está ABC.
(?<!ABC)
Lookbehind negativo: coincide si no hay ABC antes.
Cuantificadores y Alternancia
Expresión
Descripción
+
1 o más repeticiones del token anterior.
*
0 o más repeticiones del token anterior.
?
0 o 1 del token anterior (opcional).
{n}
Exactamente n repeticiones.
{n,}
n o más repeticiones.
{n,m}
Entre n y m repeticiones.
+?, *?, ??, {n,m}?
Cuantificadores no codiciosos (buscan la menor coincidencia posible).
`
`
Sustitución (Reemplazo en re.sub())
Expresión
Descripción
\1, \2, …
Inserta el texto del grupo de captura correspondiente.
\g<nombre>
Inserta el texto del grupo con nombre.
\\
Inserta un carácter \ literal.
\n, \r, \t
Caracteres de escape comunes.
Banderas en Python (re)
Bandera
Descripción
re.I o re.IGNORECASE
Ignora mayúsculas y minúsculas.
re.M o re.MULTILINE
^ y $ coinciden al inicio y final de cada línea.
re.S o re.DOTALL
Hace que . coincida también con saltos de línea.
re.U o re.UNICODE
Interpreta \w, \W, \b y \B según Unicode (activado por defecto en Python 3).
re.X o re.VERBOSE
Permite escribir expresiones legibles con espacios y comentarios.
re.A o re.ASCII
Hace que \w, \b, \d y \s solo reconozcan caracteres ASCII.
En ciencia de datos y estadística, las decisiones que tomamos dependen directamente de cómo analizamos la información. A menudo confiamos en medidas estadísticas como medias, proporciones o correlaciones para sacar conclusiones. Sin embargo, a veces las tendencias cambian drásticamente cuando separamos los datos en grupos o los combinamos.
A este fenómeno se le conoce como Paradoja de Simpson. En pocas palabras, ocurre cuando una tendencia observada en varios grupos individuales desaparece o incluso se invierte al combinar los datos de todos esos grupos.
Ejemplo clásico: recomendaciones de consolas de videojuegos
Imaginemos una encuesta sobre qué consola recomiendan más los usuarios, PS4 o Xbox One, separando las respuestas por género:
Grupos
PS4
Xbox One
Masculino
50/150 = 33%
180/360 = 50%
Femenino
200/250 = 80%
36/40 = 90%
Combinado
250/400 = 62.5%
216/400 = 54%
A primera vista, tanto hombres como mujeres prefieren Xbox One dentro de sus respectivos grupos. Pero al combinar los datos, PS4 parece ser la consola más recomendada.
Esto parece contradictorio —y lo es. La paradoja surge porque las proporciones se interpretan sin tener en cuenta el tamaño de cada grupo.
En este caso:
Xbox One tiene muchas más respuestas de hombres (360) que de mujeres (40).
PS4 tiene el patrón opuesto: muchas más respuestas femeninas (250) que masculinas (150).
Cuando agregamos los datos, los tamaños de muestra desiguales alteran la tendencia global. Este es el corazón de la Paradoja de Simpson: una conclusión opuesta al combinar los datos frente a cuando se analizan por separado.
Cómo reproducir la paradoja en Python
Podemos ilustrar el efecto con un pequeño ejemplo:
import pandas as pd# Datos de ejemplodata = pd.DataFrame({'consola': ['PS4']*400 + ['Xbox One']*400,'genero': ['Hombre']*150 + ['Mujer']*250 + ['Hombre']*360 + ['Mujer']*40,'recomienda': ( [1]*50 + [0]*100 + # PS4 hombres [1]*200 + [0]*50 + # PS4 mujeres [1]*180 + [0]*180 + # Xbox hombres [1]*36 + [0]*4# Xbox mujeres )})# Tasas por grupoprint(data.groupby(['consola','genero'])['recomienda'].mean().unstack())# Tasa global combinadaprint('\nTasas globales:')print(data.groupby('consola')['recomienda'].mean())
Salida:
genero Hombre Mujerconsola PS4 0.33 0.80Xbox One 0.50 0.90Tasas globales:consolaPS4 0.625Xbox One 0.540
La paradoja aparece claramente: las preferencias se invierten al combinar los grupos.
Un ejemplo del mundo real: tratamientos de salud mental
La paradoja de Simpson no es solo una curiosidad estadística. En el mundo real se ha observado en áreas críticas como la medicina, educación, o economía.
Considera un estudio sobre la efectividad de dos terapias para la depresión:
Tipo de depresión
Terapia A
Terapia B
Ligera
81/87 = 93%
234/270 = 87%
Severa
192/263 = 73%
55/80 = 69%
Combinado
273/350 = 78%
289/350 = 83%
Aquí, la Terapia A funciona mejor tanto para casos leves como severos. Sin embargo, al combinar los datos, parece que la Terapia B es más efectiva.
¿Por qué? Porque el número de pacientes tratados con cada terapia y tipo de depresión no es el mismo. En los casos leves (que tienen tasas altas de éxito), la mayoría recibió la Terapia A, mientras que los casos severos (con tasas más bajas) se concentraron más en la Terapia B.
La gravedad de la depresión es una variable de confusión, es decir, un factor no considerado que afecta el resultado global.
Lecciones de la Paradoja de Simpson
El contexto importa. Los datos sin contexto pueden llevar a conclusiones erróneas. Siempre debemos preguntarnos qué factores ocultos pueden estar influyendo en las relaciones observadas.
Analiza por subgrupos antes de agregar. Las tendencias globales pueden esconder comportamientos opuestos en segmentos individuales.
El tamaño de muestra importa. No todos los grupos tienen el mismo peso; las proporciones deben interpretarse considerando cuántos datos hay en cada grupo.
Correlación no implica causalidad. Que dos variables se muevan juntas no significa que una cause a la otra. La paradoja de Simpson es una excelente demostración de esto.
En Resumen
La Paradoja de Simpson nos recuerda que los datos nunca cuentan toda la historia por sí solos.
Antes de tomar decisiones basadas en estadísticas agregadas, debemos explorar los subgrupos y buscar posibles variables de confusión que puedan estar distorsionando la interpretación.
En análisis de datos, la clave no es solo calcular, sino entender. Porque a veces, los promedios engañan más de lo que explican.
En este articulo veremos cómo estudiar la asociación entre dos variables categóricas.
Ejemplo: Inventario de Personalidad Narcisista (NPI-40)
El Inventario de Personalidad Narcisista (NPI-40) es un cuestionario que evalúa rasgos narcisistas a través de 40 ítems con opciones A o B. Las respuestas se puntúan para determinar el nivel de narcisismo, que puede variar de bajo a muy alto. Se aclara que este inventario no es un diagnóstico clínico, sino una herramienta para medir características de personalidad. Cada pregunta tiene dos posibles respuestas: “sí” o “no”.
Algunas de las preguntas incluidas en este ejemplo son:
influence:
yes → “Tengo un talento natural para influir en las personas.”
no → “No soy bueno para influir en las personas.”
blend_in:
yes → “Prefiero mezclarme con la multitud.”
no → “Me gusta ser el centro de atención.”
special:
yes → “Creo que soy una persona especial.”
no → “No soy mejor ni peor que la mayoría.”
leader:
yes → “Me veo como un buen líder.”
no → “No estoy seguro de ser un buen líder.”
authority:
yes → “Me gusta tener autoridad sobre otras personas.”
no → “No me importa seguir órdenes.”
Como puedes imaginar, las respuestas a algunas de estas preguntas están asociadas entre sí. Por ejemplo, alguien que se considera líder también podría tender a disfrutar de tener autoridad.
Tablas de Contingencia de Frecuencias
Una forma práctica de resumir la relación entre dos variables categóricas es mediante una tabla de contingencia (también conocida como tabla cruzada o de doble entrada). Podemos construirla fácilmente en pandas con crosstab().
Supongamos que queremos analizar la relación entre influence (creerse bueno para influir en los demás) y leader (verse como líder):
import pandas as pdinfluence_leader_freq = pd.crosstab(npi.influence, npi.leader)print(influence_leader_freq)
Resultado:
leader no yesinfluenceno 3015 1293yes 2360 4429
Esta tabla muestra cuántas personas dieron cada combinación de respuestas. Por ejemplo:
3015 personas respondieron “no” a ambas preguntas.
4429 personas respondieron “sí” tanto a influence como a leader.
Observación: si alguien se ve como líder, es más probable que también piense que tiene talento para influir en los demás. Esto ya sugiere una posible asociación entre ambas variables.
Tablas de Contingencia de Proporciones
Para comparar mejor, es útil expresar las frecuencias como proporciones del total. Podemos hacerlo dividiendo entre el número total de observaciones:
leader no yesinfluenceno 0.272 0.117yes 0.213 0.399
Estas proporciones nos muestran que las categorías “sí/sí” (0.399) y “no/no” (0.272) son las más frecuentes. En otras palabras, casi el 40% de los participantes se ven como líderes y dicen tener talento para influir.
Proporciones Marginales
Ahora bien, incluso si no existiera relación entre las variables, las proporciones no se distribuirían equitativamente (no serían todas 0.25). Por ejemplo, puede que más de la mitad de las personas se consideren influyentes, lo cual afectará las proporciones. Las proporciones marginales resumen la fracción total de personas en cada categoría individual (por filas y columnas).
leader_marginals = influence_leader_prop.sum(axis=0)influence_marginals = influence_leader_prop.sum(axis=1)print("Marginal por líder:\n", leader_marginals)print("\nMarginal por influencia:\n", influence_marginals)
Resultado:
Marginal por líder:no 0.484yes 0.516Marginal por influencia:no 0.388yes 0.612
Esto nos dice que:
El 51.6% de las personas se consideran líderes.
El 61.2% piensa que tiene talento para influir.
Tablas de Contingencia Esperadas
Si las variables no estuvieran asociadas, podríamos predecir las proporciones esperadas multiplicando las proporciones marginales de cada categoría:
Líder = no
Líder = sí
Influencia = no
0.484 × 0.388 = 0.188
0.516 × 0.388 = 0.200
Influencia = sí
0.484 × 0.612 = 0.296
0.516 × 0.612 = 0.315
Si el total de observaciones es 11 097, podemos calcular las frecuencias esperadas:
Líder = no
Líder = sí
Influencia = no
0.188 × 11097 = 2087
0.200 × 11097 = 2221
Influencia = sí
0.296 × 11097 = 3288
0.315 × 11097 = 3501
Podemos obtener esta tabla automáticamente con SciPy:
from scipy.stats import chi2_contingencyimport numpy as npchi2, pval, dof, expected = chi2_contingency(influence_leader_freq)print(np.round(expected))
Salida:
[[2087. 2221.] [3288. 3501.]]
Estas son las frecuencias esperadas si no hubiera asociación entre las variables.
Comparación Observada vs Esperada
Tabla observada:
leader no yesinfluenceno 3015 1293yes 2360 4429
Tabla esperada (sin asociación):
leader no yesinfluenceno 2087 2221yes 3288 3501
Vemos diferencias notables: por ejemplo, hay 3015 observaciones reales en la celda (no/no), cuando esperaríamos 2087. Esto sugiere que las variables están efectivamente asociadas.
La Estadística Chi-Cuadrado (χ²)
Para cuantificar la diferencia entre ambas tablas, utilizamos la prueba Chi-Cuadrado de independencia. La fórmula general es:
Cómo evaluar la asociación entre una variable cuantitativa (por ejemplo, una puntuación o precio) y una variable categórica (por ejemplo, tipo de escuela, zona, o profesión).
Ejemplo: Datos de Estudiantes
Supongamos que tenemos un conjunto de datos de estudiantes de dos escuelas portuguesas. Contiene la siguiente información:
school: escuela del alumno → Gabriel Pereira ('GP') o Mousinho da Silveira ('MS')
address: zona de residencia → 'U' urbana o 'R' rural
absences: número de ausencias durante el curso
Mjob: profesión de la madre
Fjob: profesión del padre
G3: puntuación final del alumno en matemáticas (0 a 20)
Queremos responder:
¿Las puntuaciones de matemáticas (G3) están asociadas con la escuela a la que asisten los estudiantes?
Si es así, conocer la escuela podría ayudarnos a predecir el rendimiento académico.
Diferencias de Medias y Medianas
Una forma inicial de explorar esta relación es comparar las medias y medianas de las puntuaciones en cada grupo.
import numpy as np# Dividir los puntajes según la escuelascores_GP = students.G3[students.school == 'GP']scores_MS = students.G3[students.school == 'MS']# Calcular mediasmean_GP = np.mean(scores_GP)mean_MS = np.mean(scores_MS)mean_diff = mean_GP - mean_MSprint(f"Media GP: {mean_GP:.2f}")print(f"Media MS: {mean_MS:.2f}")print(f"Diferencia de medias: {mean_diff:.2f}")
Resultado:
Media GP: 10.49 Media MS: 9.85 Diferencia de medias: 0.64
También podríamos usar la mediana en lugar de la media para reducir el efecto de valores extremos.
Median_GP: 12.00Median_MS: 11.00Diferencia de medianas: 1.00
Estas diferencias nos dan una idea inicial, pero no nos dicen si la diferencia es relevante o significativa. Para eso, es útil visualizar la dispersión de los datos.
Diagramas de Caja Comparativos
Los diagramas de caja (boxplots) permiten visualizar simultáneamente la distribución, mediana y variabilidad de una variable cuantitativa entre grupos. Esto puede ayudarnos a determinar si las diferencias de medias o medianas son “grandes” o “pequeñas”. Echemos un vistazo a los diagramas de caja de los puntajes de matemáticas en cada escuela:
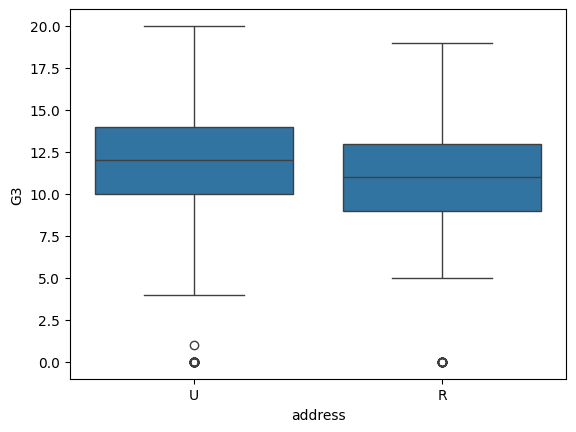
import seaborn as snssns.boxplot(data = students, x = 'address', y = 'G3')plt.show()
Estos gráficos nos permiten ver si una escuela o zona tiene valores consistentemente más altos, o si las distribuciones se superponen mucho.
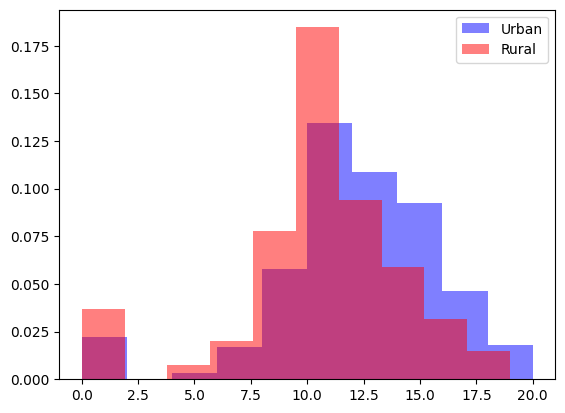
Histogramas Superpuestos
Otra opción es comparar las distribuciones con histogramas superpuestos. Aquí usamos alpha=0.5 para hacerlos semitransparentes, y density=True para que representen proporciones, no frecuencias absolutas (lo cual es importante si los grupos tienen tamaños distintos).
Si las curvas están muy superpuestas → la asociación es débil.
Si una está claramente desplazada a la derecha → hay una diferencia consistente entre grupos.
Las colas o picos distintos pueden revelar variabilidad o subgrupos (por ejemplo, alumnos destacados).
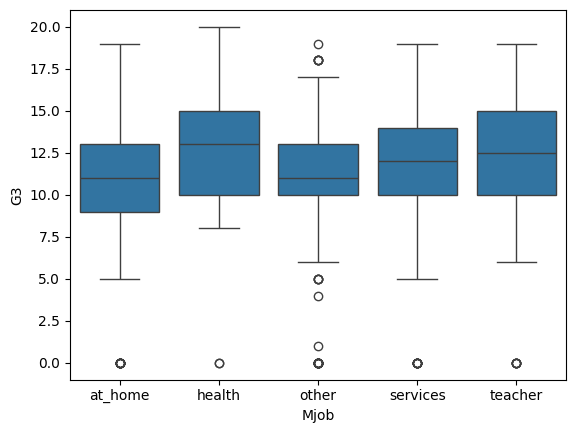
Variables Categóricas No Binarias
Hasta ahora, hemos trabajado con variables categóricas binarias (dos grupos). Pero ¿Qué ocurre si la categoría tiene más de dos valores?
Por ejemplo, la profesión de la madre (Mjob) puede tener cinco categorías:
at_home
health
services
teacher
other
Podemos visualizar la relación con un boxplot múltiple:
sns.boxplot(data = students, x = 'Mjob', y = 'G3')plt.show()
Aquí evaluamos todas las comparaciones por pares. Si al menos un grupo tiene una distribución diferente (por ejemplo, “health” con valores más altos), podemos decir que existe asociación entre las variables.