En este articulo se explora la correlación entre diferentes factores y se estima hasta qué punto son confiables sus relaciones. Además, aborda sobre los diferentes tipos de análisis que podemos realizar para descubrir la relación entre los datos: análisis univariado, bivariado y multivariado.
Cualquier conjunto de datos que queramos analizar tendrá diferentes campos (columnas) con múltiples observaciones (filas). Estas variables suelen estar relacionadas entre sí, ya que se recopilan del mismo fenómeno. Un campo puede influir o no sobre otro; para entenderlo, necesitamos detectar las dependencias existentes entre variables.
La fuerza de la relación entre dos campos de un conjunto de datos se llama correlación, y se representa con un número entre -1 y 1.
En otras palabras, la correlación es una técnica estadística que mide y describe cómo se relacionan y varían juntas dos variables. Nos permite responder preguntas como:
- ¿Cómo cambia una variable con respecto a otra?
- Si cambia, ¿en qué grado o fuerza?
- ¿Podemos predecir una a partir de la otra?
Por ejemplo: la altura y el peso suelen estar relacionados. Las personas más altas tienden a pesar más que las más bajas. Si encontramos una persona más alta que el promedio, es razonable esperar que también pese más que el promedio.
Qué es el Coeficiente de Correlación
La correlación nos indica cómo cambian las variables juntas, ya sea en la misma dirección o en direcciones opuestas, y la fuerza de esa relación. El coeficiente de correlación de Pearson \(ρ\) o \(r\) mide esta relación y se calcula como:
$$r_{xy} = \frac{\text{cov}(x, y)}{\sigma_x , \sigma_y}$$
donde:
- \( \text{cov}(x, y)\) es la covarianza entre las variables,
- \( \sigma_x \) y \( \sigma_y \) son sus desviaciones estándar.
El valor de ( r ) varía entre -1 y +1:
| Valor de r | Tipo de correlación | Interpretación |
|---|---|---|
| +1 | Perfecta positiva | Ambas variables crecen juntas |
| 0 | Nula | No hay relación lineal |
| -1 | Perfecta negativa | Una crece mientras la otra disminuye |
Valores cercanos a |1| indican una relación fuerte, mientras que los cercanos a 0 indican una relación débil o inexistente.
Visualización: Diagramas de Dispersión
Los diagramas de dispersión son herramientas visuales clave para observar la correlación entre dos variables.
A continuación, veremos ejemplos con Python.
import matplotlib.pyplot as plt
import numpy as np
# Generar datos simulados
x = np.linspace(1, 10, 10)
y_pos = 2.5 * x + np.random.normal(0, 1, 10) # correlación positiva
y_neg = -2.5 * x + np.random.normal(0, 1, 10) # correlación negativa
y_none = np.random.normal(5, 5, 10) # sin correlación
# Crear figuras
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
axs[0].scatter(x, y_pos, color='green')
axs[0].set_title('Correlación Positiva')
axs[1].scatter(x, y_neg, color='red')
axs[1].set_title('Correlación Negativa')
axs[2].scatter(x, y_none, color='gray')
axs[2].set_title('Sin Correlación')
for ax in axs:
ax.set_xlabel('Variable X')
ax.set_ylabel('Variable Y')
ax.grid(True)
plt.tight_layout()
plt.show()
Cuanto más se acerquen los puntos a una línea recta, mayor será la correlación.
Si los puntos están dispersos sin formar ningún patrón, la correlación es baja o inexistente.
Correlación No Implica Causalidad
Una frase muy importante en estadística es:
“La correlación no implica causalidad.”
Esto significa que dos cosas pueden estar relacionadas sin que una cause la otra.
Por ejemplo:
- En invierno la gente compra más sopa caliente. Pero el frío no causa que la gente gaste más dinero; ambos fenómenos están relacionados por un tercer factor (la estación del año).
- Las ventas de helado y los homicidios aumentan simultáneamente durante el verano.
No significa que comer helado cause homicidios; ambos están correlacionados por la temperatura, que influye en ambos comportamientos.
Por tanto, una correlación fuerte no garantiza una relación de causa-efecto. Antes de sacar conclusiones, es crucial analizar los factores subyacentes.
Análisis Bivariado
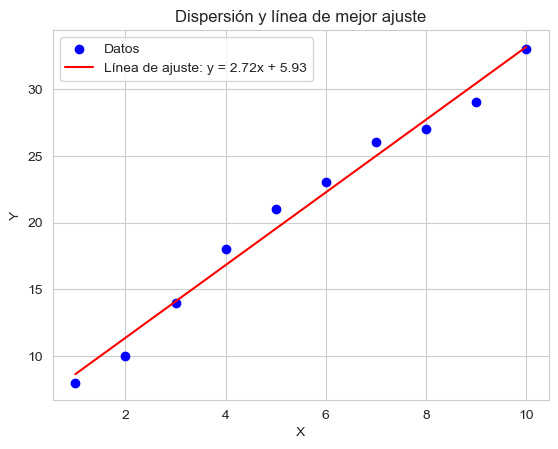
El análisis bivariado estudia la relación entre dos variables. Se usa para determinar si existe una relación y qué tipo de relación hay (positiva, negativa o nula). Por ejemplo, analicemos la relación entre el dinero invertido en publicidad y las ventas obtenidas:
Usando Numpy y Scipy:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# Datos ficticios
publicidad = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
ventas = np.array([10, 13, 19, 23, 26, 33, 38, 41, 47])
# Calcular coeficiente de correlación con Numpy
correlacion = np.corrcoef(publicidad, ventas)[0, 1]
print(f"Coeficiente de correlación de Pearson: {correlacion:.3f}")
# Calcular coeficiente de correlación con Scipy
corr = stats.pearsonr(publicidad, ventas)
print("Correlación:", corr[0])
# Graficar
plt.scatter(publicidad, ventas, color='blue', label='Datos')
m, b = np.polyfit(publicidad, ventas, 1)
plt.plot(publicidad, m*publicidad + b, color='red', label='Línea de mejor ajuste')
plt.xlabel("Dólares en publicidad")
plt.ylabel("Ventas")
plt.title("Análisis Bivariado: Publicidad vs Ventas")
plt.legend()
plt.grid(True)
plt.show()Salida:
Coeficiente de correlación de Pearson: 0.997
Correlación: 0.9973743231694302
Interpretación:
Si el coeficiente de correlación \( r \) es cercano a 1, existe una relación positiva fuerte, lo que sugiere que al aumentar la inversión publicitaria, las ventas también aumentan.
Análisis Multivariado
El análisis multivariado examina tres o más variables al mismo tiempo, buscando relaciones más complejas. Se utiliza cuando queremos entender cómo varias variables interactúan entre sí para predecir un resultado.
Ejemplo: predecir el precio de una casa según tamaño, ubicación y número de habitaciones.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import numpy as np
data = pd.DataFrame({
'tamaño_m2': [45, 55, 65, 75, 85, 95, 105, 115],
'habitaciones': [1, 2, 2, 3, 3, 3, 4, 4],
'ubicacion': [5, 4, 3, 2, 4, 3, 2, 1], # zonas más caras no siempre coinciden con mayor tamaño
'precio': [160000, 170000, 185000, 190000, 210000, 220000, 240000, 230000]
})
# Variables independientes y dependiente
X = data[['tamaño_m2', 'habitaciones', 'ubicacion']]
y = data['precio']
# Crear y entrenar el modelo
modelo = LinearRegression()
modelo.fit(X, y)
# Mostrar resultados
print("Coeficientes:", modelo.coef_)
print("Intercepto:", modelo.intercept_)
# --- Gráfico de correlaciones ---
plt.figure(figsize=(8, 6))
sns.heatmap(data.corr(), annot=True, cmap='coolwarm', fmt=".2f", linewidths=0.5)
plt.title("Mapa de calor de correlaciones", fontsize=14)
plt.show()Coeficientes: [ 1800. 22000. -9000.]
Intercepto: 11000.0Interpretación:
- Coeficiente de
tamaño_m2: 1800
➜ Por cada metro cuadrado adicional, el precio sube 1,800 €, manteniendo las demás variables constantes. - Coeficiente de
habitaciones: 22000
➜ Añadir una habitación aumenta el precio promedio en 22,000 €, suponiendo mismo tamaño y ubicación. - Coeficiente de
ubicacion: -9000
➜ En este ejemplo, los valores de ubicación están codificados de forma que un número menor representa una zona mejor.
Por eso el coeficiente es negativo: al bajar el número (mejor ubicación), aumenta el precio. - Intercepto: 11,000
➜ Es el valor base del modelo cuando todas las variables valen 0 (solo tiene sentido teórico, no real).

El análisis multivariado permite estimar el efecto combinado de múltiples variables y mejorar la precisión de las predicciones.
Limitaciones de la Correlación
La correlación solo mide relaciones lineales. Puede ser engañosa cuando la relación es curvilínea o no lineal. Por ejemplo, los siguientes diagramas de dispersión muestran pares de variables con correlaciones cercanas a cero:
- En uno de ellos, la relación es perfectamente horizontal (pendiente = 0).
- En los demás, las relaciones son no lineales (curvas, cuadráticas, circulares, etc.).
En estos casos, la correlación no detecta la relación real, porque una línea recta no puede describir la forma del patrón.

Explorando la covarianza
Más allá de visualizar relaciones, también podemos utilizar estadísticas resumidas para cuantificar la fuerza de ciertas asociaciones. La covarianza es una estadística resumida que describe la fuerza de una relación lineal.
La covarianza puede variar desde infinito negativo hasta infinito positivo. Una covarianza positiva indica que un valor mayor de una variable está asociado con un valor mayor de la otra. Una covarianza negativa indica que un valor mayor de una variable está asociado con un valor menor de la otra. Una covarianza de 0 indica que no hay relación lineal. Aquí hay unos ejemplos:

Para calcular la covarianza, podemos usar la función cov() de NumPy, que produce una matriz de covarianza para dos o más variables . Una matriz de covarianza para dos variables se parece a esto:
| Variable 1 | Variable 2 | |
|---|---|---|
| Variable 1 | varianza (Variable 1) | covarianza |
| Variable 2 | covarianza | varianza (Variable 2) |
En Python, podemos calcular esta matriz de la siguiente manera:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Datos simulados de viviendas
data = pd.DataFrame({
'tamaño_m2': [45, 55, 65, 75, 85, 95, 105, 115],
'habitaciones': [1, 2, 2, 3, 3, 3, 4, 4],
'ubicacion': [5, 4, 3, 2, 4, 3, 2, 1], # zonas más caras no siempre coinciden con mayor tamaño
'precio': [160000, 170000, 185000, 190000, 210000, 220000, 240000, 230000]
})
# --- 1️⃣ Cálculo manual y con NumPy ---
cov_matrix = np.cov(data['tamaño_m2'], data['precio'])
cov_tamaño_precio = cov_matrix[0, 1]
print("Matriz de Covarianza:\n", cov_matrix)
print("\nCovarianza entre tamaño_m2 y precio:", round(cov_tamaño_precio, 2))Salida:
Matriz de Covarianza:
[[ 616.07142857 5687.5 ]
[5687.5 53839285.71428572]]
Covarianza entre tamaño_m2 y precio: 5687.5Interpretación
- El valor 5 687.5 es positivo, lo que significa que cuando el tamaño aumenta, el precio también tiende a aumentar.
- Si fuera negativo, indicaría que los valores mayores de una variable se asocian con valores menores de la otra.
- Si fuera cercano a 0, implicaría que no hay una relación lineal clara entre tamaño y precio.
La magnitud (qué tan grande es el número) depende de las unidades de medida. Por eso, la covarianza no es directamente comparable entre conjuntos de datos distintos. Para una medida normalizada e interpretable, se usa la correlación de Pearson, que va de -1 a +1.



{kind=link}
{kind=link}