La audiencia de un documento técnico es el lector o lectores previstos. Para los redactores técnicos, esta es la consideración clave al planificar, redactar y revisar. Se trata de adaptar la escritura a las necesidades, intereses y antecedentes del lector.
El principio es simple: habla para que te entiendan. No expliques cohetes a un niño de seis años. Parece obvio, pero la falta de análisis de audiencia es la raíz de la mayoría de los problemas en documentos técnicos, especialmente en instrucciones.
Herramientas Prácticas
Planificador de audiencias: Responde preguntas detalladas y envíatelo por email (opcional: a tu instructor).
Planificador de situaciones: Define el contexto en que tu audiencia usa el documento.
Tipos de Audiencias
Tipo
Descripción
Expertos
Conocen teoría y producto al detalle. Diseñan, prueban. Títulos avanzados. Desafío: comunicarse con técnicos y ejecutivos.
Técnicos
Construyen, operan, mantienen, reparan. Conocimiento práctico y técnico.
Ejecutivos
Toman decisiones comerciales, legales, políticas. Poco conocimiento técnico. Deciden si producir, implementar, financiar.
No especialistas
Mínimo conocimiento técnico. Interés práctico o curiosidad. Ej: votar en elecciones, aprender sin motivo específico.
Ejemplo: Guía de software en Windows → ¿incluyes basics de Windows?
No: Frustra al usuario.
Sí: Aumenta páginas y costo. → Equilibra según el tamaño del segmento que lo necesita.
Necesidades e intereses
¿Qué esperan del documento?
Ej: Manual de smartphone → pasos claros.
Informe de calentamiento global para inmobiliarios → ¿qué quieren (y no quieren) leer?
Diferentes culturas
Formatos de fecha, hora, moneda varían.
Evita humor local (“dar un jonrón”). → Recursos:
Capítulo 6: Escritura para lectores internacionales (Texas A&M).
Lista de guías de estilo en Wikipedia.
Otras características demográficas
Edad, género, residencia, preferencias políticas, etc.
Complicaciones Comunes
Audiencias mixtas: Técnicos + ejecutivos →
Opción 1: Todo comprensible para todos (difícil).
Opción 2: Secciones por audiencia + títulos claros para navegar.
Variabilidad amplia: En una misma categoría →
Escribir al mínimo común denominador → documento tedioso.
Solución:
Apuntar a la mayoría.
Info extra en apéndices o referencias cruzadas.
Ejemplo de Descripción de Audiencia (para curso)
Nota al instructor: Instrucciones para usuarios que optimizan cálculos en Excel con macros. Saben ingresar datos, usan Office Suite, están cómodos con Windows y aritmética básica para verificar errores.
Adaptación Práctica: 16 Controles para Conectar con tu Audiencia
(Enfocados en no especialistas, pero aplicables a todos)
Añade info clave → pasos, antecedentes, definiciones.
Omite lo innecesario → evita confusión.
Ajusta nivel técnico → no hables a expertos si tu lector es técnico.
Incluye ejemplos → analogías potentes.
Adapta ejemplos → caseros para no expertos, técnicos para especialistas.
En un análisis estadístico, normalmente se comienza considerando las características de la población sobre la cual se quieren hacer inferencias. De manera similar, cuando comienzas a escribir un informe sobre un análisis, generalmente comienzas considerando las características de la audiencia con la que deseas comunicarte.
Debes pensar en el quién, qué, por qué, dónde, cuándo y cómo de las personas clave que leerán tu informe.
¿Quién leerá tu informe?
La audiencia a menudo se define por el rol que desempeña el lector en relación con el informe:
Tomadores de decisiones: Usarán el informe para actuar.
Partes interesadas: Aprenderán nueva información.
Revisores: Lo criticarán en base a lo que ya saben.
Interesados generales: Buscan contexto o inspiración.
Algunos informes son leídos por una sola persona, pero la mayoría por muchas. Pueden existir niveles de participación: primarios, secundarios y terciarios.
Consejo clave:
No puedes complacer a todos. Concéntrate primero en las personas más importantes para recibir tu mensaje, y en segundo lugar en el grupo más amplio.
¿Qué saben tus lectores?
Una vez definido a quién te diriges, comprende sus características. La más importante para un redactor técnico es su nivel de comprensión del tema y de las técnicas estadísticas.
Puedes ajustar cómo presentas la información estadística. Aquí tienes un mapa de audiencias comunes:
Tipo de lector
Características
Recomendaciones
Matefobias
Temen a los números, pero escuchan conceptos
Evita jerga, fórmulas y porcentajes. Usa “aproximadamente la mitad” en lugar de “48.7%”.
Pasantes
Entienden poco y tienen bajo interés
No te preocupes: no leerán más allá del resumen. Hazlo conciso y resalta el hallazgo clave.
Turistas
Entienden algo y están interesados
Sé amable. Usa jerga solo si la defines. Prefiere gráficos simples (barras, circulares). Redondea valores.
Perros calientes
Creen saber más de lo que saben
Usa jerga y fórmulas, pero explícalas claramente. Guíalos para evitar conclusiones erróneas.
Asociados
Otros analistas con jerga básica
Todo vale si lo explicas bien.
Colegas
Expertos en el tema y técnicas
Todo vale. Sé técnico, preciso y directo.
Estas características te orientan sobre la extensión, tono y estilo del informe.
¿Por qué leerán tu informe?
Sé honesto:
¿Por qué alguien estaría interesado en leer tu informe?
Pregúntate:
¿Qué harán con tus hallazgos?
¿Se informarán? ¿Tomarán decisiones? ¿Actuarán?
¿Es algo crítico para ellos o solo un trámite?
El nivel de interés define cuánto esfuerzo debes invertir en hacerlo claro, atractivo y accionable.
¿Dónde se leerá tu informe?
Considera el alcance y contexto:
¿Es para un grupo interno (organización) o público general?
¿Va dirigido a la alta dirección (de arriba hacia abajo) o a equipos operativos (de abajo hacia arriba)?
¿Hay preocupaciones de seguridad o confidencialidad?
Esto afecta el lenguaje, el nivel de detalle y las medidas de protección (contraseñas, marcas de agua, etc.).
¿Cuándo lo necesitan?
El tiempo es un factor crítico:
¿Cuándo debe estar listo?
¿Quién lo revisará y cuánto tardará?
¿Los plazos son flexibles o inamovibles?
¿Tienes tiempo para:
Pensar el mensaje?
Hacer análisis adicionales?
Editar y pulir?
Regla de oro (que todos rompemos, pero no deberíamos):Nunca envíes un borrador para revisión que no sea tu obra maestra completa y editada.
¿Cómo debe presentarse el informe?
Finalmente, piensa en cómo maximizar el impacto para tu audiencia. Aquí van cinco consideraciones clave:
¿Entregarás datos, scripts, código o resultados adicionales?
¿Crearás una presentación?
¿Se usarán tus gráficos en tribunales o eventos públicos?
5. Accesibilidad
¿Debes cumplir con la Sección 508 (EE.UU.) para accesibilidad?
¿Tus gráficos son legibles para personas con daltonismo?
¿Usas títulos claros, tablas bien etiquetadas, alt text en imágenes?
Conclusión:
No necesitas responder todas estas preguntas en detalle. Muchas solo requieren unos segundos de reflexión. Pero si analizas estas dimensiones —quién, qué, por qué, dónde, cuándo y cómo— tendrás una idea mucho más clara de para quién escribes Y cómo debes escribirlo
El backsolving es un método para resolver sistemas de ecuaciones lineales una vez que ya hemos reducido el sistema a forma triangular superior mediante eliminación gaussiana (o cualquier otra técnica de factorización como LU).
Trabajamos el mismo problema del articulo anterior:
Queremos resolver los precios \( (p) \) de cada producto. En este caso utilizaremos eliminación gaussiana y luego sustitución hacia atrás — eso es, reducir el sistema a triangular superior y luego encontrar las incógnitas empezando por la última.
Eliminación gaussiana (reducción hacia triangular superior)
Escribimos el sistema en sus ecuaciones explícitas (producto fila por columna):
Sustituyendo el valor numérico de \(p_3\) (o directamente resolviendo con las fracciones) se obtiene \(p_2=3\).
Finalmente sustituimos \(p_2\) y \(p_3\) en la primera ecuación para obtener (p_1), que da (p_1=2).
Conclusión del método manual (eliminación + sustitución):
$$\mathbf p = \begin{pmatrix}2 \\ 3 \\ 5\end{pmatrix}$$
¿Qué significa calcular la inversa \(M^{-1}\) y cómo se obtiene con matriz aumentada?
Otra forma más “directa” (y que explica el porqué de la eliminación) es calcular la inversa de \(M\). Si \(M\) es invertible entonces
$$\mathbf p = M^{-1}\mathbf c$$
Para encontrar \(M^{-1}\) se construye la matriz aumentada \([,M \mid I,]\) y se aplican operaciones elementales por filas hasta transformar el lado izquierdo en la identidad; entonces el lado derecho habrá quedado como \(M^{-1}\).
Verificaciones numéricas y redondeo
En la práctica, cuando calculas \(M^{-1}M\) en ordenador verás que los elementos fuera de la diagonal no son exactamente cero sino números muy pequeños (por ejemplo \(-5\times 10^{-17})\). Eso es error numérico de punto flotante. Si redondeas (por ejemplo a 10 decimales) obtendrás la matriz identidad exacta en la presentación.
Resumen conceptual
Eliminación gaussiana: reduce el sistema a triangular superior (eliminación hacia adelante) y luego despeja las variables (sustitución hacia atrás).
Inversa por matriz aumentada: hacer operaciones elementales sobre \([M\mid I]\) hasta convertir \(M\) en \(I\); lo que quede a la derecha será \(M^{-1}\).
Comprobación: puedes verificar que \(M^{-1}\mathbf c = \mathbf p\) y \(M^{-1}M = I\) (hasta errores numéricos muy pequeños).
Código Python
import numpy as np# Definición de la matriz y vectores (el sistema del ejemplo)M = np.array([[3, 6, 2], [10, 3, 8], [1, 7, 5]], dtype=float)c = np.array([34, 69, 48], dtype=float)# 1) Resolver el sistema M p = cp = np.linalg.solve(M, c)print("Solución (np.linalg.solve):", p)# 2) Calcular la inversa de MM_inv = np.linalg.inv(M)print("\nInversa M^{-1}:\n", M_inv)# 3) Verificar que M^{-1} * c = pp_from_inv = M_inv @ cprint("\nM^{-1} @ c =", p_from_inv)# 4) Verificar que M_inv @ M ≈ I (mostramos la matriz y una versión redondeada)I_approx = M_inv @ Mprint("\nM^{-1} @ M (aprox):\n", I_approx)print("\nM^{-1} @ M (redondeado a 10 decimales):\n", np.round(I_approx, 10))
M_inv @ c debe coincidir con p (igual numéricamente, dentro de tolerancias de punto flotante).
M_inv @ M será numéricamente la identidad; si ves valores muy pequeños fuera de la diagonal, es normal: redondea para comprobar que esos valores son efectivamente cero dentro de la precisión de la máquina.
Resumen
La eliminación y la inversa son dos caras de la misma moneda: la primera resuelve un sistema concreto, la segunda construye la “función inversa” que, aplicada a cualquier vector de costes, devolvería los precios.
En aplicaciones (ciencia de datos, econometría, ingeniería), normalmente no calculamos la inversa si solo queremos resolver un sistema: usamos solve (algoritmos de factorización) por razones de estabilidad numérica y eficiencia. Sin embargo, obtener la inversa es útil para entender conceptualmente la transformada inversa y para comprobaciones.
Es el punto de partida que lleva directamente a la forma matricial de los sistemas lineales. El mismo sistema de ecuaciones de las frutas puede escribirse y resolverse en forma matricial. En la ciencia de datos los datasets son matrices, y resolver sistemas lineales ayuda a encontrar relaciones entre variables.
Partimos del sistema:
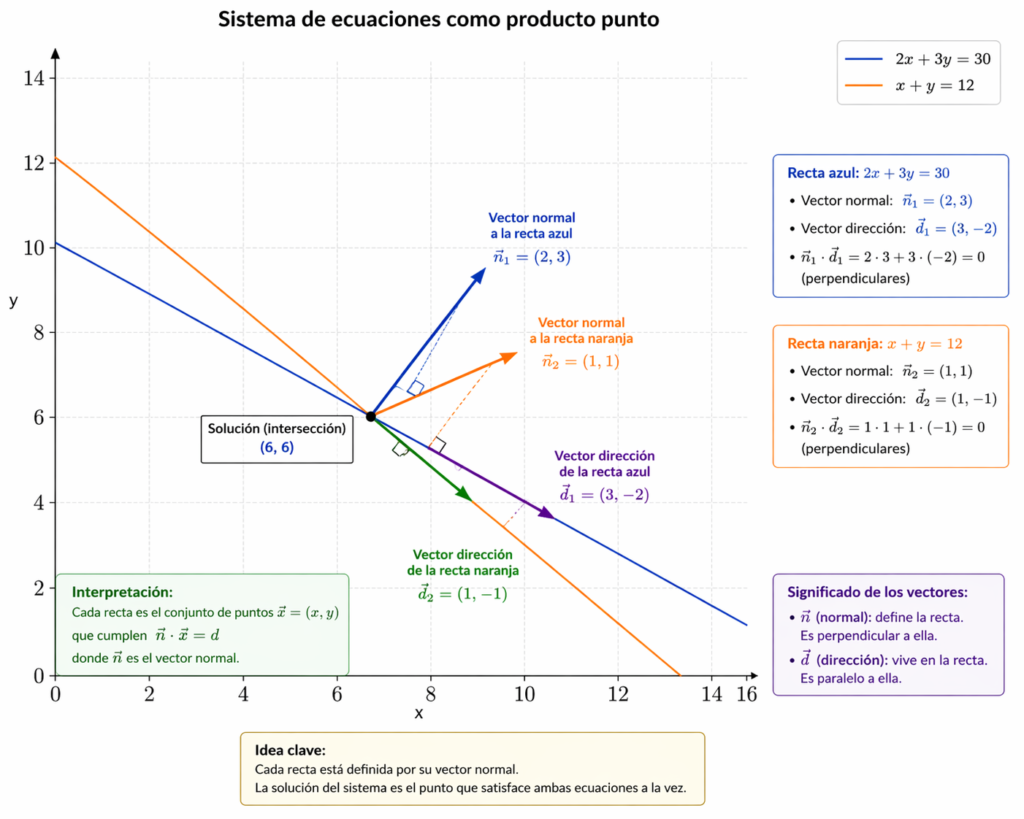
$$\begin{cases} 2x + 3y = 30 \\ x + y = 12 \end{cases}$$
En formato matricial:
$$\begin{bmatrix} 2 & 3 \\ 1 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 30 \\ 12 \end{bmatrix}$$
Significado de las partes:
Partes
Significado
$$\begin{bmatrix} 2 & 3 \\ 1 & 1 \end{bmatrix}$$
Matriz de coeficientes: contiene los números que multiplican a las variables (los precios de las frutas).
$$\begin{bmatrix} x \\ y \end{bmatrix}$$
Vector de incógnitas: las variables que queremos encontrar (número de manzanas y naranjas).
$$\begin{bmatrix} 30 \\ 12 \end{bmatrix}$$
Vector de resultados: los valores en el lado derecho (total de dinero y total de frutas).
La forma vectorial compacta del sistema matricial se expresa como:
$$A\vec{x} = \vec{b}$$
Donde:
\(A\) –> es la matriz de coeficientes
\(\vec{x}\) –> es el vector de incógnitas
\(\vec{b}\) –> es el vector de términos independientes
En ciencia de datos y machine learning esta forma es fundamental porque:
Permite expresar relaciones entre miles de variables en una sola ecuación.
Es la base de la regresión lineal, la reducción de dimensionalidad, y el entrenamiento de modelos.
Toda la manipulación se hace con álgebra matricial, que es más eficiente computacionalmente.
Resolviendo problemas reales.
En artículos anteriores vimos operaciones sobre vectores y matrices desde la perspectiva matemática. Vamos a ver cómo esas mismas operaciones pueden resolver problemas reales, como descubrir cuánto cuesta cada producto de un supermercado.
Escenario
Volvemos a nuestro supermercado de frutas. Imaginemos que tenemos tres personas: Bob, Alice y Tim, que han ido al supermercado y compraron manzanas, naranjas y peras. Podemos representar sus compras en una matriz \(M\):
Matriz de coeficientes: contiene los números que multiplican a las variables (las cantidades de las frutas).
Vector de incógnitas: las variables que queremos encontrar (precio de las frutas).
Vector de resultados: los valores en el lado derecho (total de dinero gastado).
Cómo transformar el sistema para poder resolverlo
Hasta ahora has visto qué es un sistema de ecuaciones y cómo representarlo en forma matricial. Pero hay un problema práctico: tal como están escritas, las ecuaciones no siempre resultan fáciles de resolver.
En otros articulos hablamos de las caracteristicas del un sistema, como la singularidad. Aqui veremos como transformar el sistema sin cambiar su significado, haciendo mas simple su solucion.
Transformar sin perder información
Existe una serie de operaciones que podemos aplicar a las ecuaciones sin alterar sus soluciones:
Intercambiar ecuaciones
Multiplicar o dividir una ecuación por un número distinto de cero
Sumar o restar ecuaciones entre sí
Estas operaciones son la base del Algoritmo de eliminación de Gauss. Su objetivo es reorganizar el sistema en una forma mucho más sencilla de interpretar.
Ejemplo conceptual del proceso
Partimos de un sistema cualquiera y aplicamos operaciones de fila para:
Elegir un elemento clave (pivote)
Convertir en cero todo lo que hay debajo
Repetir el proceso en las siguientes filas
El resultado es una matriz en la que la estructura del sistema se vuelve transparente.
Es como resolver un sistema de ecuaciones común por eliminación, pero aplicado directamente a los números de una matriz (llamada matriz de coeficientes). El objetivo es limpiar la matriz para que las respuestas sean evidentes.
Forma escalonada por filas (row echelon form).
Se consigue eliminando la información redundante y aislando la información útil. Cada paso reduce el sistema a algo más simple, manteniendo exactamente las mismas soluciones.
Una matriz está en esta forma cuando:
Cada fila empieza más a la derecha que la anterior
Debajo de cada elemento clave (pivote) hay ceros
Las filas sin información (todos ceros) quedan al final
Es útil porque te deja el sistema listo para “sustitución hacia atrás”.
Forma escalonada reducida: la solución directa
Si continúas el proceso un paso más, llegas a la forma escalonada reducida (reduced row echelon form) Aquí ocurre algo muy potente, en su columna solo hay ceros (arriba y abajo)
Aquí la solución es directa, cada fila te dice el valor de cada variable.
¿Qué pasa si el sistema es “Singular”?
A veces, al hacer la eliminación gaussiana, una fila completa se convierte en ceros \( 0 = 0 \)). Esto significa que:
El sistema es singular (las ecuaciones eran dependientes o redundantes).
En la matriz, verás un 0 en la diagonal principal en lugar de un 1.
Esto indica que el sistema puede tener infinitas soluciones o ninguna.
Método de eliminación gaussiana
La eliminación gaussiana (o reducción de filas) es el proceso de manipular una matriz mediante operaciones matemáticas simples para simplificarla y resolver sistemas de ecuaciones.
Queremos eliminar las variables \( p_1 \) de las filas 2 y 3.
Buscamos eliminar las \(p_1\), lo primero es restar la fila 1 con la fila 2. Para esto hacemos una normalización de la fila dos, buscando que se elimine la variable. En notación de matrices se expone como:
$$ F_2 \leftarrow F_2 – 10F_1 $$
Lo que quiere decir es que la nueva fila \( F_2 \) será el resultado de la resta de la fila \( F_2 \) y la fila \( F_1 \) multiplicada por 10. Esto hace que se elimine \(p_1\) en la operación \(10p_1 – 10p_1\).
La segunda eliminación de la variable es creando una nueva fila 3 producto de la resta entre las filas \( F_3 \) y la \( F_1 \) multiplicando esta por 3.
Método de Gauss-Jordan: llevar el sistema hasta la matriz identidad
Una vez hemos aplicado la sustitución hacia atrás y ya conocemos los valores de las variables, puede surgir una pregunta lógica: ¿Y si en lugar de calcular las variables “a mano”, dejamos la matriz ya resuelta automáticamente? Aquí es donde entra el método de Gauss-Jordan.
¿Qué aporta Gauss-Jordan?
El método de Gauss (el que hemos usado) termina en una matriz escalonada, y a partir de ahí necesitamos hacer sustitución hacia atrás. El método de Gauss-Jordan va un paso más allá. Sigue aplicando operaciones hasta convertir la matriz en la matriz identidad
💡 En ese momento:
Ya no necesitas sustituir
Los valores de las variables aparecen directamente en la última columna
Para solucionar con python usamos numpy.linalg.solve, que aplica internamente eliminación de Gauss con pivotado, y es la forma más eficiente y segura de resolver sistemas lineales \(A \cdot x = b \) en Python.
import numpy as np# Matriz de coeficientesA = np.array([ [3, 6, 2], [10, 3, 8], [1, 7, 5]], dtype=float)# Vector de resultadosb = np.array([34, 69, 48], dtype=float)# Resolver el sistema A·x = bsol = np.linalg.solve(A, b)# Mostrar resultadosp1, p2, p3 = solprint(f"p1 = {p1:.2f}, p2 = {p2:.2f}, p3 = {p3:.2f}")
En el artículo anterior se trabajo los autovalores y autovectores, es común quedarse con la sensación de que son conceptos abstractos. Pero en realidad, están detrás de muchas de las herramientas más potentes del análisis de datos moderno.
Una de ellas es el Análisis de Componentes Principales (PCA), una técnica que permite comprimir información sin perder lo esencial.
En este artículo veremos cómo los eigenvectores sirven para reducir la dimensionalidad de los datos, y cómo este principio se aplica a algo tan visual como la compresión de imágenes de rostros humanos.
Cuando trabajamos con datos reales —imágenes, audio, sensores o registros de clientes— solemos tener miles de variables. Eso significa que el procesamiento se vuelve lento, costoso y muchas veces innecesario, porque buena parte de los datos son redundantes.
El PCA (Principal Component Analysis) se basa precisamente en encontrar las direcciones de mayor variabilidad dentro de los datos. Y esas direcciones no son otras que los autovectores de la matriz de covarianza del conjunto.
Visualizando el concepto con una imagen
Una imagen digital no es más que una matriz de números, donde cada valor representa la intensidad del color (por ejemplo, del blanco al negro si es en escala de grises).
Para este ejemplo usaremos el famoso dataset de rostros de celebridades incluido en scikit-learn.
from sklearn.datasets import fetch_lfw_peopleimport matplotlib.pyplot as plt# Cargamos el dataset de carasfaces = fetch_lfw_people(min_faces_per_person=60)image = faces.images[0]plt.imshow(image, cmap='bone')plt.title(f"Ejemplo de imagen: {faces.target_names[0]}")plt.axis('off')plt.show()
Cada imagen tiene 62 filas × 47 columnas, es decir, 2.914 píxeles o variables. PCA nos permitirá representar esta misma información con muchas menos variables.
Aplicando PCA paso a paso
PCA consiste básicamente en tres fases:
Calcular la matriz de covarianza del conjunto de datos.
Obtener sus autovectores y autovalores.
Proyectar los datos sobre las direcciones asociadas a los autovalores más grandes, que contienen la mayor parte de la varianza.
En código, podemos hacerlo así:
from sklearn.decomposition import PCAimport numpy as np# Aplanamos las imágenes 2D a vectores 1DX = faces.data# Aplicamos PCA para conservar solo 15 componentes principalespca = PCA(n_components=15)X_pca = pca.fit_transform(X)# Reconstruimos las imágenes desde los componentes principalesX_reconstructed = pca.inverse_transform(X_pca)# Mostramos la imagen original y la reconstruidafig, axes = plt.subplots(1, 2, figsize=(8, 4))axes[0].imshow(X[0].reshape(62, 47), cmap='bone')axes[0].set_title("Imagen original")axes[0].axis('off')axes[1].imshow(X_reconstructed[0].reshape(62, 47), cmap='bone')axes[1].set_title("Reconstruida (15 componentes)")axes[1].axis('off')plt.show()
¿Qué estamos haciendo en realidad?
Cada componente principal es un autovector de la matriz de covarianza. Cada uno representa una dirección en el espacio de datos donde la información cambia más. Los autovalores indican cuánta “varianza” explica cada componente.
En este caso, al reconstruir la imagen con solo 15 componentes, vemos una versión algo borrosa, pero perfectamente reconocible. Hemos pasado de 2.914 variables a solo 15, manteniendo casi toda la información útil.
Si reducimos a 5 componentes, la imagen pierde detalle; si aumentamos a 50, se ve casi igual que la original. Todo depende del equilibrio que queramos entre tamaño y fidelidad.
Las “eigenfaces”
Una de las formas más visuales de entender PCA en imágenes es observar los autovectores directamente. En este caso se les conoce como eigenfaces, o “caras propias”.
Cada eigenface representa un patrón característico: sombras de ojos, contorno del rostro, luz lateral, expresión, etc.
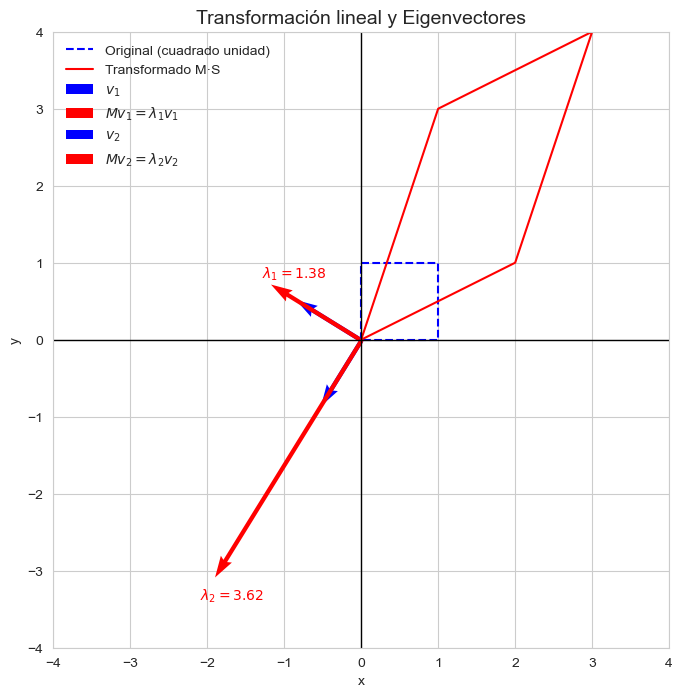
Verás que, aunque una transformación lineal cambia la dirección de la mayoría de los vectores, existen algunos vectores especiales que no rotan, solo se estiran o encogen. Esos vectores son los autovectores (eigenvector), y la cantidad por la que se estiran o encogen se llama autovalor (eigenvalues).
Intuición: vectores que no cambian de dirección
Imagina una matriz que representa una transformación lineal —por ejemplo, una matriz de “shear” (cizallamiento), que deforma un cuadrado en un paralelogramo. En la mayoría de los casos, todos los vectores cambian de dirección al aplicar la transformación… excepto algunos muy particulares. Esos vectores especiales mantienen su dirección (aunque pueden cambiar su longitud). Por eso decimos que son autovectores.
Un vector \( \vec{v} \) es un autovector de una matriz \( M \) si, al aplicar la matriz transformadora sobre él, el resultado es el mismo vector escalado por un número \( \lambda \):
$$M \vec{v} = \lambda \vec{v}$$
Donde:
\( M \) → es una matriz cuadrada \(n \times n\)
\( \vec{v} \) → es un autovector
\( \lambda \) → es el autovalor asociado
Este número \( \lambda \) indica cuánto se estira o encoge el vector cuando la matriz actúa sobre él.
Interpretación geométrica
Si \( \lambda > 1 \): el vector se alarga.
Si \( 0 < \lambda < 1 \): el vector se encoge.
Si \( \lambda < 0 \): el vector cambia de sentido (se invierte).
Si \( \lambda = 1 \): el vector queda igual.
Calculando los eigenvectors y eigenvalues
Continuamos con el ejemplo inicial:
import numpy as np# Calcular eigenvalores y eigenvectoresw, V = np.linalg.eig(M)print("\nEigenvalores:\n", w)print("\nEigenvectores (columnas):\n", V)
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))# Cuadrado original (azul) y transformado (rojo)ax.plot(square[0], square[1], 'b--', label='Original (cuadrado unidad)')ax.plot(transformed[0], transformed[1], 'r-', label='Transformado M·S')# Ejesax.axhline(0, color='black', linewidth=1)ax.axvline(0, color='black', linewidth=1)# Eigenvectoresfor i inrange(len(w)): v = V[:, i] # vector propio Mv = M @ v # su transformación λ = w[i]# Dibuja el eigenvector (azul) ax.quiver(0, 0, v[0], v[1], angles='xy', scale_units='xy', scale=1,color='blue', width=0.007, label=fr'$v_{i+1}$')# Dibuja el vector transformado (rojo) ax.quiver(0, 0, Mv[0], Mv[1], angles='xy', scale_units='xy', scale=1,color='red', width=0.007, label=fr'$M v_{i+1} = \lambda_{i+1} v_{i+1}$')# Muestra texto con el eigenvalor ax.text(Mv[0]*1.1, Mv[1]*1.1, fr'$\lambda_{i+1}={λ:.2f}$', color='red', fontsize=10)ax.set_xlim(-4, 4)ax.set_ylim(-4, 4)ax.set_aspect('equal', adjustable='box')ax.legend(loc='upper left', facecolor='none', edgecolor='none')ax.set_title("Transformación lineal y Eigenvectores", fontsize=14)ax.set_xlabel("x")ax.set_ylabel("y")plt.grid(True)plt.show()
Matrices simétricas
Cuando una matriz es simétrica (es decir, \( M = M^T \)), se cumple algo muy útil:
Todos sus autovectores son perpendiculares entre sí.
Sus autovalores son reales.
Por ejemplo:
A = np.array([[4, 1], [1, 4]])autovalores, autovectores = np.linalg.eig(A)print("Autovalores:", autovalores)print("Autovectores:\n", autovectores)print("Producto punto entre los autovectores:", np.dot(autovectores[:,0], autovectores[:,1]))
La salida mostrará que el producto punto es 0, confirmando que los autovectores son ortogonales.
Autovalores: [5. 3.]Autovectores: [[ 0.70710678 -0.70710678] [ 0.70710678 0.70710678]]Producto punto entre los autovectores: 0.0
Aplicaciones en ciencia de datos
Los eigenvectores y eigenvalores son fundamentales en data science:
Análisis de Componentes Principales (PCA)
Qué hace: Reduce dimensiones de un dataset encontrando los eigenvectores de la matriz de covarianza.
Ejemplo: Dataset Iris (150×4) → eigenvectores indican las direcciones de mayor variación (ej: longitud vs ancho de pétalo).
Redes Neuronales
Eigenvectores optimizan transformaciones en capas de redes profundas.
Ejemplo: Ajustar pesos para maximizar patrones.
Procesamiento de Imágenes
Eigenvectores en eigenfaces identifican características faciales clave.
Ejemplo: Reconocimiento facial en apps de seguridad.
Sistemas Dinámicos
Modelan cómo cambian datos con el tiempo (ej: predicciones financieras).
Eigenvalores determinan la estabilidad de los sistemas.
Historia real: En 2024, Spotify usó eigenvectores en su sistema de recomendaciones para identificar patrones en gustos musicales, mejorando la precisión en un 10%.
Cómo encontrar los Eigenvalues y Eigenvectors
Para cualquier matriz \(M\):
Primero encontramos todos los eigenvalores λ.
Luego, usando esos eigenvalores, encontramos los eigenvectores correspondientes.
La ecuación base \(M \vec{v} = \lambda \cdot \vec{v}\) será la clave de todo.
Pero para trabajar con ella algebraicamente, vamos a transformarla un poco.
La matriz identidad
Necesitamos la matriz especial llamada la matriz identidad, que se denota por \(I\). La matriz identidad es una matriz cuadrada con unos en la diagonal principal (de arriba a la izquierda hasta abajo a la derecha) y ceros en todas las demás posiciones. Ya la vimos como ejemplo anteriormente en el articulo de las matrices.
Por ejemplo, la matriz identidad de tamaño 3×3 es:
Sacamos vvv como factor común (como si fuera un número):
$$(M \ – \lambda I) \cdot \vec{v} = 0 $$
Y esta ecuación es fundamental: se conoce como la ecuación característica.
La condición de existencia de eigenvectores
Esta ecuación tiene dos tipos de soluciones posibles:
La trivial, cuando \(v=0\). Pero ese vector no nos dice nada (no tiene dirección ni longitud), así que lo descartamos.
La no trivial, cuando \(v≠0\). Para que exista esta solución, debe cumplirse una condición especial.
Recuerda una propiedad del álgebra lineal:
Una ecuación de la forma \(A \cdot v=0\) solo tiene una solución no trivial \(v≠0\) si la matriz A es singular, es decir, su determinante es igual a cero.
Aplicando esto a nuestra ecuación \((M \ – \lambda I) \cdot \vec{v} = 0 \), la condición será: \(det(M \ – \lambda I) \cdot \vec{v} = 0 \)
Esta ecuación nos permitirá encontrar los valores de \( \lambda \), los eigenvalores.
Interpretación geométrica: el área que se hace cero
Detrás de todo esto hay una idea visual muy poderosa.
Imagina que tienes una matriz \(M\) que transforma puntos del plano \(XY\). Puedes representarla como una transformación del cuadrado unitario (un cuadrado de lado 1 anclado en el origen).
Cuando multiplicas \(M\) por las coordenadas de los vértices de ese cuadrado, obtienes un nuevo cuadrilátero. En general, este nuevo cuadrilátero es un paralelogramo.
Si \(M\) solo escala el cuadrado, obtienes un rectángulo.
Si además deforma el cuadrado (por ejemplo, en un cizallamiento), obtienes un paralelogramo inclinado.
El área de ese paralelogramo es una medida de cuánto “estira” o “encoge” la transformación de \(M\). Y el determinante de la matriz está directamente relacionado con esa área.
Cuando el determinante es cero, significa que la transformación ha colapsado el plano en una línea o un punto, es decir, ha perdido una dimensión. Eso ocurre exactamente cuando estamos en un eigenvalor, porque en ese caso el espacio queda “aplastado” en una dirección particular: la del eigenvector.
Ejemplo visual con una matriz 2×2
Imaginemos una matriz genérica \(M\) de 2×2:
$$M = \begin{bmatrix} a & b \\ c & d \end{bmatrix}$$
Y tomemos el cuadrado unitario cuyos vértices son (0,0), (1,0), (1,1) y (0,1).
Cuando aplicamos \(M\) sobre esos puntos, el cuadrado se transforma en un paralelogramo cuyos vértices vienen dados por los productos matriciales:
$$M \cdot S$$
donde \(S\) contiene las coordenadas de los vértices del cuadrado. El área de ese nuevo paralelogramo se puede calcular directamente como:
$$\text{Área} = ad – bc$$
que es precisamente el determinante de \(M\).
Así que cuando el determinante \(ad−bc=0\), el paralelogramo “se aplasta” y pierde área. Geométricamente, eso es lo que ocurre cuando hay un eigenvalor: la transformación ya no conserva el área y “colapsa” el espacio en una dirección.
Si los vectores son puntos en un mapa, las matrices son el mapa completo: una matriz es una cuadrícula de números organizada en filas y columnas. Puedes pensarla como un conjunto de vectores fila o vectores columna, dependiendo del caso.
Matemáticamente, se escribe como un conjunto rectangular o cuadrado de números. Cada número dentro de la matriz se llama elemento, y se identifica por su posición: \(a_{ij}\) es el elemento que está en la fila i y la columna j.
Para poder multiplicar dos matrices es necesario que el número de columnas de la primera matriz sea igual al número de filas de la segunda. Para realizar la multiplicación se multiplican los elementos de cada fila de A por cada elemento de las columnas de B y se suman los resultados.
Propiedad .shape: conocer las dimensiones de la matriz
print(A.shape)
(3, 4)
Indexación: acceder a elementos, fila y columnas
M = np.array([[1, 2, 3], [4, 5, 6] [7, 8, 9]])valor = M[4, 5] # valor en la fila 5, columna 6 (Python indexa desde 0)fila = M[1, :] # acceder a una fila completacolumna = M[:, 2] # acceder a una columna completaprint(valor)print(fila)print(columna)
6[4 5 6][3 6 9]
Suma y resta de matrices
C = A + BD = B - A
Multiplicación por escalar
E = 3 * A
Producto de matrices
C = A @ B# tambien se puede usar:np.dot(A, B)
Transpuesta de una matriz
print("A^T =\n", A.T)
Matriz identidad
I = np.eye(2)print("Matriz identidad:\n", I)print("A @ I =\n", A @ I)
Determinante y matriz inversa
det_A = np.linalg.det(A)inv_A = np.linalg.inv(A)
6. En resumen
Las matrices son la base del álgebra lineal y de los modelos de datos.
En Machine Learning, cada conjunto de entrenamiento es una gran matriz.
En visión por computador, las imágenes son matrices.
En análisis estadístico, las transformaciones de los datos se hacen con multiplicaciones matriciales.
Por eso, entender cómo funcionan es esencial: todo modelo, por complejo que parezca, se reduce a operaciones con vectores y matrices.
Imagina que los datos son como puntos en un mapa. Un vector es la flecha que describe dónde está ese punto y cómo llegar a él. En data science, los vectores son la forma más básica y poderosa de representar datos, desde características de un cliente hasta píxeles en una imagen.
El vector es el elemento fundamental y raíz de toda el algebra lineal.
Los vectores no son solo un concepto matemático para escribir ecuaciones de forma concisa. También son herramientas fundamentales para codificar información compleja, desde posiciones y velocidades hasta fuerzas y movimientos en varias dimensiones.
¿Qué es un vector?
Más allá de ser una lista ordenada de números, un vector puede pensarse como: cualquier cosa que tenga una dirección y una magnitud.
Es una lista ordenada de números que describe una posición o característica en un espacio. En data science, cada vector representa un punto de datos y cada fila de tu dataset es un vector.
Esta definición es la que usan los físicos. Por ejemplo:
Dirección: hacia dónde apunta el vector.
Magnitud: qué tan grande es, también llamada norma del vector.
Ejemplos
Supongamos que describes a una persona por su edad y salario:
Vector: \([25, 50000]\)
25: Edad (en años)
50000: Salario (en euros)
Visualmente:
Un vector es una flecha en un plano:
Origen: \((0,0)\)
Punta: \((25, 50000)\)
En 2D, se ve como una línea desde el origen al punto.
Dimensiones
2D: \([x, y]\) (ej: edad, salario)
3D: \([x, y, z]\) (ej: edad, salario, experiencia)
n-D: \([x₁, x₂, …, xₙ]\) (datasets con muchas columnas)
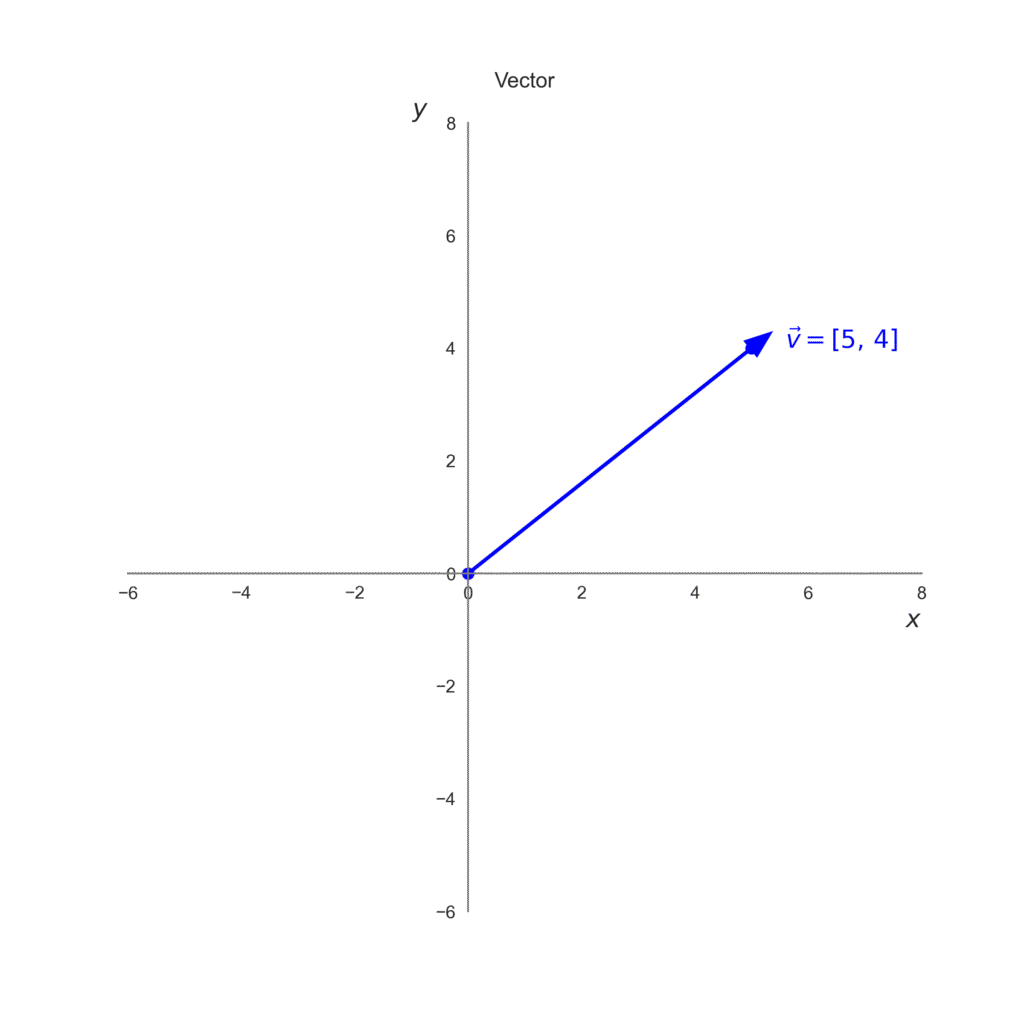
De la Ecuación al Movimiento
Imaginemos una pelota lanzada desde el origen que en términos de vectores seria la posición \((0,0)\) en un espacio bidimensional. La posición de la pelota en cada instante se puede codificar como un vector \( \mathbf{p} = (p_1, p_2) \), donde:
\(p_1 = 5\) representa la posición horizontal \(x\)
\(p_2 = 4\) representa la posición vertical \(y\).
Así, en lugar de seguir las coordenadas de los ejes por separado, podemos usar un solo vector para describir la posición de la pelota.
$$ \vec{p} = \begin{bmatrix}5\\4\end{bmatrix}$$
Si representamos \(\vec{p}\) en un plano cartesiano, se vería como una flecha que parte del origen (0,0) y termina en (5,4). La flecha tiene una dirección (hacia dónde apunta) y una longitud, que nos dice qué tan lejos está el punto final del origen. Para graficar podemos utilizar ax.arrow() en Matplotlib.
Código de la grafica
Código en Python Matplotlib
import matplotlib.pyplot as plt# Crear figura y ejesfig, ax = plt.subplots(figsize=(8, 8))# Dibujar el vector desde (0,0) hasta (5,4)ax.arrow(0, 0, 5, 4, head_width=0.3, head_length=0.4, fc='blue', ec='blue', linewidth=2)# Marcar el punto final del vectorax.plot(5, 4, 'o', markersize=6, color='blue')ax.plot(0, 0, 'o', markersize=6, color='blue')ax.text(5.6, 4, r"$\vec{v} = [5,\, 4]$", fontsize=14, color='blue')# Ejes centradosax.spines['left'].set_position('zero')ax.spines['bottom'].set_position('zero')# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Color y grosor de los ejesfor spine in ['left', 'bottom']: ax.spines[spine].set_color('gray') ax.spines[spine].set_linewidth(1)# Límites y cuadrículaax.set_xlim(-6, 8)ax.set_ylim(-6, 8)ax.grid(False)# Tamaño de los números de los ejesax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y títuloax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.set_title("Vector", pad=20)# Guardar y mostrarplt.savefig("vector.png", transparent=True, dpi=300)plt.show()
La norma (longitud del vector): cuánto ha viajado la pelota
Esa longitud, también llamada norma, nos dice qué tan grande es el vector. Se denota con dos barras verticales, así: \( ||\mathbf{p}|| \) Para saber qué tan lejos está la pelota desde el origen, usamos la norma del vector:
$$||\mathbf{p}|| = \sqrt{p_1^2 + p_2^2}$$
Esta ecuación se deriva directamente del teorema de Pitágoras: la hipotenusa de un triángulo rectángulo es la raíz cuadrada de la suma de los cuadrados de sus catetos. Por ejemplo, si \(p_1 = 5\) y \(p_2 = 4\), la norma es:
Esto hace que los vectores sean muy poderosos para manejar información compleja de manera compacta.
Aplicaciones de los vectores en física
Los vectores nos permiten representar de manera eficiente:
Posición: dónde se encuentra un objeto.
Velocidad: dirección y rapidez del movimiento.
Fuerza: hacia dónde actúa y cuán intensa es.
Además, con operaciones como suma, resta, multiplicación por escalar o producto punto, podemos combinar vectores y calcular efectos resultantes de manera simple.
Por ejemplo, en nuestra pelota de béisbol, un vector nos permite:
Conocer simultáneamente su posición en \(x\) y \( y\) ,
Medir su distancia desde el punto de lanzamiento con la norma,
Y si quisiéramos incluir velocidad o aceleración, usar vectores de mayor dimensión para mantener todo compacto y manejable.
Dos propiedades clave de un vector
Dirección: hacia dónde apunta.
Magnitud: cuán grande es, calculable con la norma.
En cualquier número de dimensiones, esta regla sigue siendo válida, lo que convierte a los vectores en herramientas universales para describir información física y multidimensional.
Operaciones con Vectores
Los vectores son poderosos porque puedes operarlos para descubrir patrones. Aquí las operaciones más importantes:
Esto es útil porque cuando sumamos vectores estamos combinando información de manera ordenada, igual que antes combinábamos cantidades de manzanas, naranjas y pan. La suma de vectores es la primera forma de “agrupar información” en un vector.
Multiplicación por escalar
Si tenemos un número \(k\) y un vector \(\vec{v}\), multiplicamos cada componente por ese número:
$$ k \cdot \vec{v}= k \cdot \begin{bmatrix}v_1\\v_2\\v_3\end{bmatrix} = \begin{bmatrix}kv_1\\kv_2\\kv_3\end{bmatrix}$$
Esto sirve para escalar vectores, como cuando queremos “duplicar” o “reducir” una cantidad.
Producto Escalar (Dot Product)
Dot Product: Mide la similitud entre dos vectores.
El producto escalar es una operación entre dos vectores que produce un número, a diferencia de la suma o resta de vectores, que produce otro vector.
Antes de hablar de matrices, hay una idea fundamental. Una ecuación lineal es un producto escalar.
ones
En resumen:
Una ecuación lineal = producto escalar
Un sistema = varios productos escalares
Una matriz = colección de vectores fila
Multiplicar matriz por vector = aplicar todos los productos escalares
Usos del producto escalar en data science
Similitud de vectores (cosine similarity): En NLP, sistemas de recomendación o embeddings de palabras. Cuanto mayor sea este valor, más similares son los vectores.
Regresión lineal / Neuronas : Calcula la combinación lineal de las variables
Similitud del coseno : Mide cuánto se parecen dos vectores
PCA / Proyecciones : Proyecta un vector sobre una dirección
Distancias : Base para métricas vectoriales
Álgebra de matrices : Operación elemental en multiplicación de matrices
Operaciones de vectores con Python
Los vectores en Python se manejan con Numpy y se representan como listas:
¿Por qué las ecuaciones lineales son clave en data science?
Las ecuaciones lineales y los sistemas lineales son como el esqueleto de la data science. Son la base de algoritmos como la regresión lineal, los sistemas de recomendación y el análisis de datos en general. Imagina que cada punto de datos es una pieza de un rompecabezas: las ecuaciones lineales te ayudan a juntar las piezas para descubrir patrones.
“Sin ecuaciones lineales, no habría machine learning moderno. Son el primer paso para transformar datos en decisiones.”
¿Qué es una ecuación lineal?
Una ecuación lineal es una ecuación donde las variables están elevadas a la potencia 1 y multiplicadas por un coeficiente (no hay cuadrados ni raíces) y se combinan con sumas o restas.
Ejemplo Simple
$$3x + 2y = 30$$
Como concepto está bien. ¿Pero cuál es el sentido de esto? ¿De dónde sale? La idea base de la ecuación lineal es una relación constante entre dos cosas. La ecuación lineal nace cuando dos magnitudes cambian de forma proporcional.
Por ejemplo:
Si vendes café a 2€ cada uno, el ingreso total depende linealmente del número de cafés vendidos.
$$Ingreso = 2 \times \text{Número de cafés}$$
Esto puede escribirse matemáticamente como
$$y = 2x$$
Donde:
x, y: Variables (Ingreso, Café).
2: Coeficientes (pesos de las variables)
Esa es una relación lineal: cada vez que \(x\) aumenta 1, \(y\) aumenta 2. La tasa de cambio es constante. Visualmente esta ecuación representa una línea recta en un plano. Cada solución \((x, y)\) es un punto en esa línea.
De ahí el nombre de lineal, porque describe una relación que se representa como una línea recta en un gráfico. Las ecuaciones lineales modelan situaciones donde:
El cambio es constante,
La relación entre variables es directa o proporcional.
Por eso son la base de la modelización matemática, antes de llegar a modelos más complejos, todo empieza por asumir una relación lineal.
Representar las ecuaciones
En la forma general o modelo pendiente e intersección, toda ecuación lineal puede escribirse así:
$$y=mx+b$$
Donde:
\(b\) –> es el valor inicial o intersección con el eje Y: el valor de \(y\) cuando \(x=0\).
\(y\) –> valor en el eje vertical (dependiente)
\(x\) –> valor en el eje horizontal (independiente)
\(m\) –> es la pendiente, cuánto cambia \(y\) cuando \(x\) aumenta una unidad.
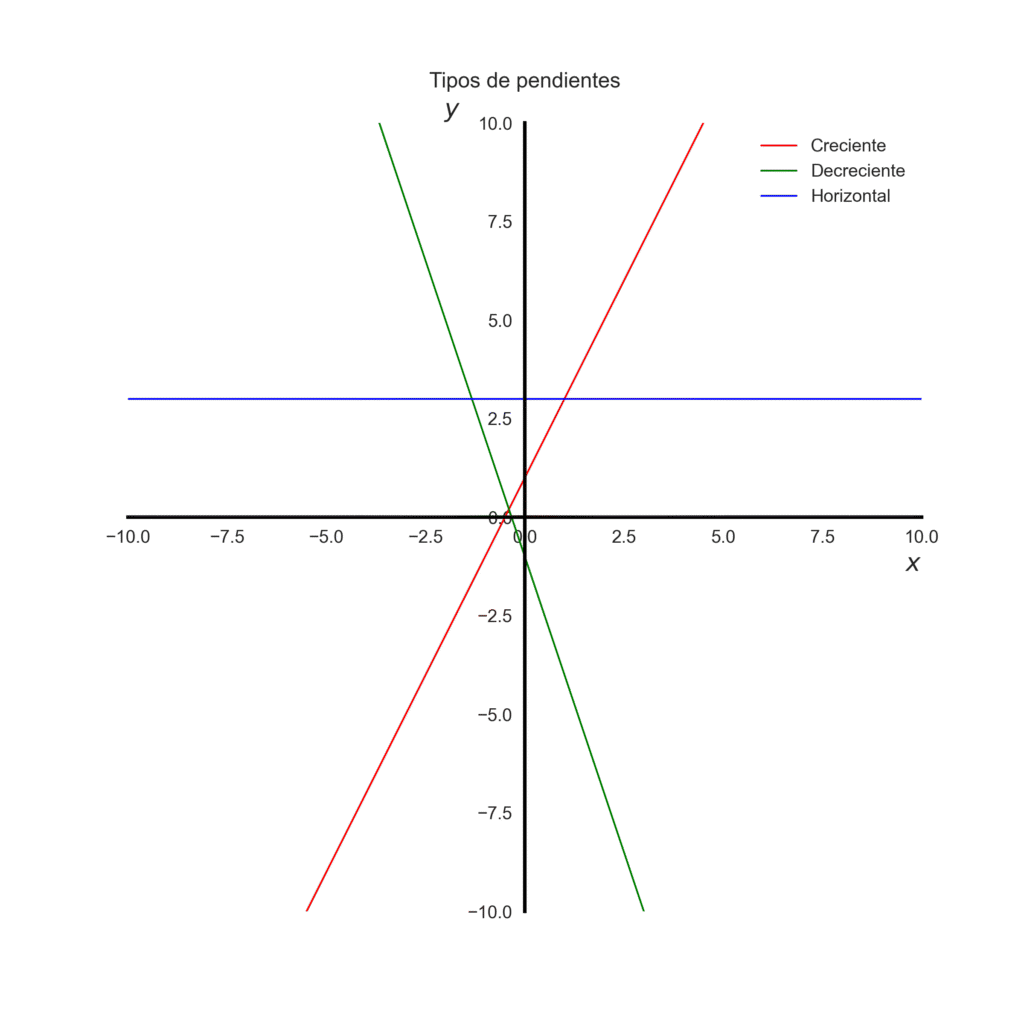
Si \(m > 0\) –> sube hacia la derecha (creciente)
Si \(m < 0\) –> baja hacia la derecha (decreciente)
Si \(m = 0\) –> la recta es horizontal
Código de la gráfica
Código Python con Matplotlib
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))ax.axline((0, 1), slope=2, color="red", linewidth=1, label="Creciente")ax.axline((0, -1), slope=-3, color="green", linewidth=1, label="Decreciente")ax.axline((0, 3), slope=0, color="blue",linewidth=1, label="Horizontal")# Ejes en el centroax.spines['left'].set_position('zero') # eje Y en x=0ax.spines['bottom'].set_position('zero') # eje X en y=0# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Cambiar color y grosor de los ejes (spines)for spine in ['left', 'bottom']: ax.spines[spine].set_color('black') ax.spines[spine].set_linewidth(2)# Límites y cuadrículaax.set_xlim(-10, 10)ax.set_ylim(-10, 10)# tamaño de los numerosax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y leyendaax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.legend()ax.set_title("Tipos de pendientes", pad=20)ax.legend(facecolor='none', edgecolor='none')ax.grid(False)plt.savefig("pendientes.png", transparent=True, dpi=300)plt.show()
¿Por qué las pendientes siempre avanzan a la derecha?
Esto tiene que ver con cómo definimos el sistema de coordenadas cartesianas y el concepto de pendiente. Vamos a desglosarlo paso a paso:
La pendiente mide cuánto cambia \(y\) cuando \(x\) cambia una unidad.
Cuando calculamos la pendiente avanzamos de izquierda a derecha en el eje \(x\).
Entonces la pendiente se interpreta como el cambio vertical que ocurre al movernos a la derecha.
Por eso, al dibujar la recta, decimos que “avanza a la derecha” y sube o baja según \(x\).
Si quisieras avanzar a la izquierda, sería simplemente \(x<0\) y la pendiente seguiría siendo la misma, solo que la “mirada” sería desde el otro extremo.
En otras palabras: no es que la recta no exista hacia la izquierda, sino que matemáticamente la pendiente se mide tomando \(Δx\) (variación de x) positivo, lo que corresponde a moverse hacia la derecha.
El sentido algebraico: equilibrio
Desde el punto de vista algebraico, una ecuación es una igualdad entre dos expresiones que mantiene un equilibrio. Una ecuación lineal representa un equilibrio simple, sin potencias ni productos entre variables:
$$2x+3y=30$$
Significa que existen valores de \(x\)y\(y\) para los cuales la expresión de la izquierda \(2x+3y\)) tiene el mismo valor que el número de la derecha (30).
Cada punto \((x,y)\) que cumple esa igualdad está en equilibrio: pertenece a la recta.
Ambos lados deben ser iguales para que la ecuación se cumpla.
Una ecuación representa una condición de equilibrio o una restricción sobre los valores posibles de las variables.
Desde el punto de vista algebraico, lo que hacemos con una ecuación es buscar los valores de las variables que la hacen verdadera. A eso lo llamamos resolver la ecuación. En este caso: \(2x+3y=30\) no tiene una única solución, sino infinitas combinaciones de \((x,y)\) que cumplen la igualdad (todas las que están sobre la recta).
Si representamos todos los puntos \((x,y)\) que cumplen esa ecuación, obtenemos una recta en el plano cartesiano. Así, una ecuación lineal de dos variables es la expresión algebraica de una recta.
Ejemplo: Ecuación lineal de las frutas
Un problema clásico seria resolver cuantas manzanas y naranjas podemos comprar con 30€, donde las manzanas tienen un precio de 2€ y las naranjas de 3€. (Supón que puedes fraccionar las frutas).
Este problema se resuelve con un ecuación lineal que se representa como sigue:
$$2x + 3y = 30$$
Donde:
2 y 3 –> son los coeficientes (precios de las frutas)
\(x\)–> variable que representa las manzanas
\(y\) –> variable que representa las naranjas
30 –> es el termino independiente (la constante)
Representamos la ecuación en la forma general \(y=mx+b\):
$$3y = -2x + 30$$
Pasamos el 3 dividiendo y calculamos:
$$y = \frac{2}{3}x – \frac{30}{3}$$
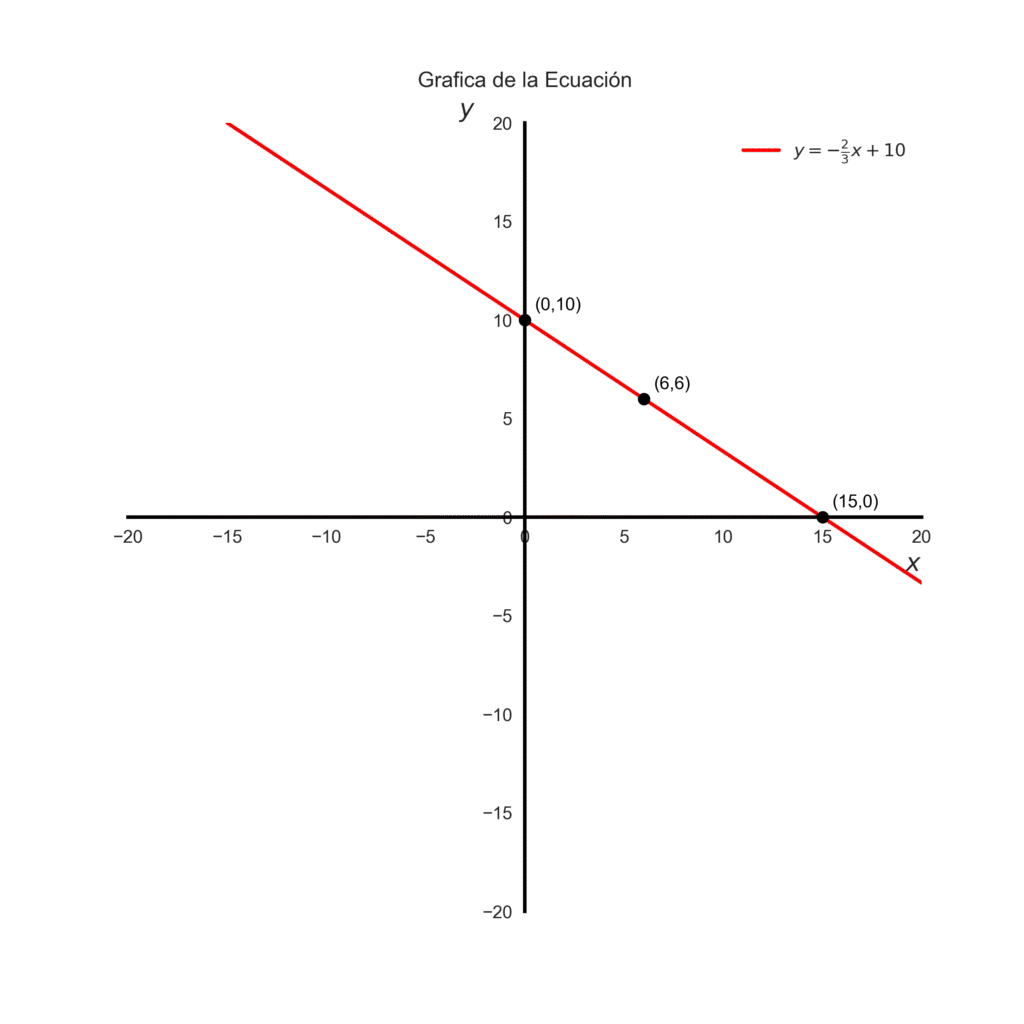
$$y = -\frac{2}{3}x + 10$$
Aquí tenemos:
\(m = – \frac{2}{3}\) –> pendiente de la recta.
\(b = 10\) –> la ordenada en el origen, o sea el punto donde la recta corta el eje Y.
Cuando \(x=0\): \(y=10\) –> la recta pasa por el punto \((0, 10)\).
Cuando \(y=0\): \(x=15\) → la recta pasa por el punto (15, 0):
$$2x + 3y = 30$$
$$2x + 3(0) = 30$$
$$2x = 30$$
$$2x = \frac{30}{2}$$
$$x = 15$$
Entonces tenemos ya dos puntos \((0,10)\) y \((15,0)\). Con estos dos puntos podemos trazar una recta que representa la ecuación. Cada punto en la recta, es una combinación de manzanas(\(x\)) y naranjas (\(y\)) que equivalen a una compra de 30€.
Podemos calcular mas combinaciones de frutas posibles eligiendo los valores de \(x\) y calculando \(y\) en la ecuación de la forma pendiente – intersección.
Por ejemplo, si \(x = 6\):
$$y = – \frac{2}{3}x + 10$$
$$y = – \frac{2}{3}(6) + 10$$
$$y = – \frac{12}{3} + 10$$
$$y = – 4 + 10 = 6$$
Otra combinación de frutas y punto en la grafica seria \((6,6)\). Representemos gráficamente la ecuación.
Código de la gráfica
Código Python de Matplotlib
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))ax.axline((0, 10), slope=-2/3, color="red", linewidth=2, label=r"$y = -\frac{2}{3}x + 10$")# Puntos específicospuntos = [(15,0), (0,10), (6,6)]for x, y in puntos: ax.plot(x, y, 'ko', markersize=6) # dibujar punto ax.text(x + 0.5, y + 0.5, f"({x},{y})", fontsize=10, color='black')# Ejes en el centroax.spines['left'].set_position('zero') # eje Y en x=0ax.spines['bottom'].set_position('zero') # eje X en y=0# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Cambiar color y grosor de los ejes (spines)for spine in ['left', 'bottom']: ax.spines[spine].set_color('black') ax.spines[spine].set_linewidth(2)# Límites y cuadrículaax.set_xlim(-20, 20)ax.set_ylim(-20, 20)# tamaño de los numerosax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y leyendaax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.legend()ax.set_title("Grafica de la Ecuación", pad=20)ax.legend(facecolor='none', edgecolor='none')ax.grid(False)plt.savefig("ecuacion de las frutas.png", transparent=True, dpi=300)plt.show()
Este sencillo problema de manzanas y naranjas nos muestra cómo las ecuaciones lineales nos permiten modelar relaciones entre variables de manera clara y predecible. Cada punto en la recta representa una combinación posible que satisface la restricción del problema (gastar 30 €), y la pendiente nos indica cómo cambiaría una variable si ajustamos la otra.
En ciencia de datos y machine learning, este mismo concepto es fundamental: buscamos modelar relaciones entre variables para poder predecir, optimizar o tomar decisiones basadas en datos.
Sistemas Lineales
Un sistema lineal es un conjunto de ecuaciones lineales que resuelves juntas para encontrar valores que satisfagan todas.
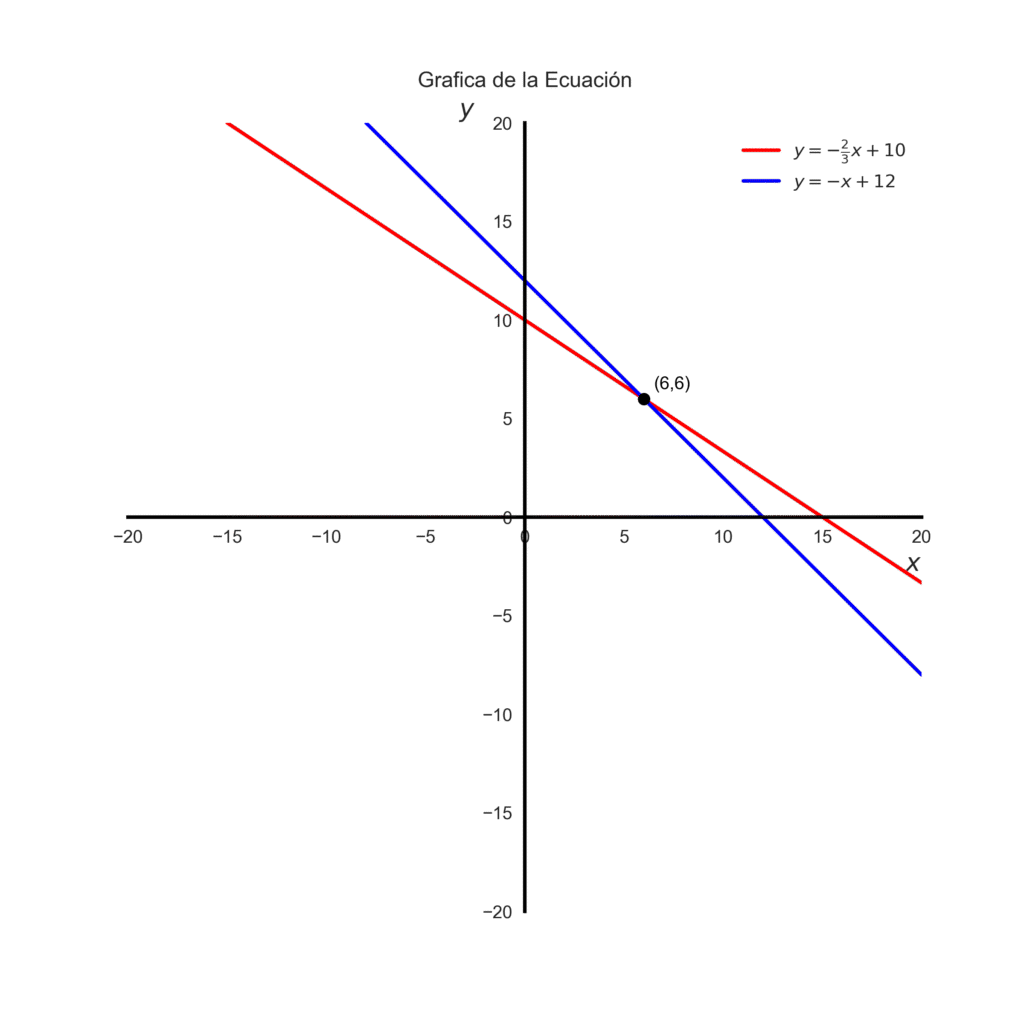
Supongamos que a nuestro problema anterior le añadimos una condición. Supón ahora que además de gastar 30 €, queremos comprar exactamente 12 frutas en total. Esa nueva condición se traduce en otra ecuación:
$$x + y = 12$$
Ahora tenemos dos ecuaciones y dos incógnitas \((x, y)\).
$$\begin{cases} 2x + 3y = 30 \\ x + y = 12 \end{cases}$$
Aquí, cada ecuación representa una recta en el plano cartesiano. El punto donde ambas rectas se cruzan es la combinación de frutas que cumple las dos condiciones al mismo tiempo: gastar 30 € y comprar exactamente 12 frutas. Existen varios métodos de resolver los sistemas de ecuaciones.
$$\begin{cases} 2x + 3y = 30 \\ x + y = 12 \end{cases}$$
Seleccionamos la variable \(x\) para normalizar la primera ecuación dividiendo la ecuación entre el coeficiente de \(x\) que es 2. La segunda ecuación no lo necesita, si fuera el caso, se dividiría la segunda ecuación por el coeficiente de su variable \(x\).
$$x + 1.5 y = 15$$
$$x + y = 12$$
Restamos la ecuación 1 a la 2.
$$x + y = 12$$
$$x + 1.5 y = 15$$
\( x -x = 0 \)
\( 1y – 1.5y = 0.5y \)
\(12 – 15 = -3 \)
resultado:
$$-0.5y = – 3$$
$$y = – \frac{3}{0.5}$$
$$y = 6$$
Ahora sustituimos \(y\) en la segunda:
$$x + y = 12$$
$$x + 6 = 12$$
$$x = 12 – 6 = 6$$
Resultado: \(x=6,y=6\).
Con Matplotlib podemos graficar la recta solo con la pendiente y la intersección. En este caso para la segunda ecuación \(m = -1\) y \(b = 12\) .
Código del gráfico
Código Python de Matplotlib
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(8,8))ax.axline((0, 10), slope=-2/3, color="red", linewidth=2, label=r"$y = -\frac{2}{3}x + 10$")ax.axline((0, 12), slope=-1, color="blue", linewidth=2, label=r"$y = -x + 12$")# Puntos específicosax.plot(6, 6, 'ko', markersize=6) # dibujar puntoax.text(x + 0.5, y + 0.5, f"({6},{6})", fontsize=10, color='black')# Ejes en el centroax.spines['left'].set_position('zero') # eje Y en x=0ax.spines['bottom'].set_position('zero') # eje X en y=0# Quitar bordes superior y derechoax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# Cambiar color y grosor de los ejes (spines)for spine in ['left', 'bottom']: ax.spines[spine].set_color('black') ax.spines[spine].set_linewidth(2)# Límites y cuadrículaax.set_xlim(-20, 20)ax.set_ylim(-20, 20)# tamaño de los numerosax.tick_params(axis='both', which='major', labelsize=10)# Etiquetas y leyendaax.set_xlabel(r"$x$", fontsize=14, loc="right")ax.set_ylabel(r"$y$", fontsize=14, loc="top", rotation=0)ax.legend()ax.set_title("Grafica de la Ecuación", pad=20)ax.legend(facecolor='none', edgecolor='none')ax.grid(False)plt.savefig("sistemas_de_ecuaciones.png", transparent=True, dpi=300)plt.show()
Método 2: Matriz inversa
Determinar si la matriz \(A\) tiene inversa.
Aislar el vector de incógnitas \(\vec{x}\).
La forma de hacerlo no es dividiendo, porque no existe la división entre matrices, sino multiplicando por su inversa, denotada \(A^{-1}\).
La ecuación de matriz inversa:
$$\vec{x} = A^{-1} \vec{b}$$
Resolviendo el sistema
Para una matriz de dos ecuaciones como la del ejemplo:
$$A = \begin{bmatrix} d & b \\ c & a \end{bmatrix}$$
Determinar su inversa es:
$$A^{-1} = \frac{1}{ad – bc} \begin{bmatrix} d & -b \\ -c & a \end{bmatrix}$$
Hay algunas operaciones básicas que usaremos constantemente:
Transposición (Aᵗ) → cambia filas por columnas.
Multiplicación de matrices (A·B) → combina vectores o sistemas.
Determinante (det(A)) → indica si el sistema tiene solución única.
Matriz inversa (A⁻¹) → nos permite resolver sistemas como \(x=A−1bx = A^{-1} bx=A−1b\).
Estas herramientas son la base de muchos algoritmos modernos de machine learning y análisis de datos.
Forma de la matriz aumentada
La matriz aumentada es otra forma de representar un sistema de ecuaciones lineales, pero con un propósito muy concreto: resolverlo más fácilmente mediante operaciones por filas (como en el método de Gauss o Gauss-Jordan). Contiene toda la información numérica del sistema. Trabajar con ella evita reescribir las variables en cada paso.
La matriz aumentada junta la matriz de coeficientes \(A\) y el vector de términos independientes \(\vec{b}\) en una sola matriz separada por una línea vertical:
Esa barra vertical no tiene significado algebraico en sí, simplemente marca la frontera entre los coeficientes del sistema y los resultados.
Método 3: Eliminación Gaussiana
El objetivo de la eliminación es transformar esa matriz con operaciones por filas hasta una forma en la que las variables se lean directamente. Las operaciones permitidas (elementales por filas) son:
Intercambiar dos filas.
Multiplicar una fila por un escalar distinto de 0.
Sumar a una fila un múltiplo de otra fila.
Estas operaciones no cambian el conjunto de soluciones del sistema: son equivalencias algebraicas.
En esta parte normalmente queremos que el primer elemento de la primera fila (posición (1,1)) sea un buen pivote (idealmente 1 y no 0). En nuestro caso la fila 2 ya tiene un 1 en la columna 1, así que intercambiamos las filas para facilitar cálculos:
Operacion \(R_1 \leftrightarrow R_2\) (Row1 y Row2)
Paso 2 — Eliminar la variable \(x\) de las filas inferiores
Qué se hace: queremos que en la columna del pivote (columna 1) todos los elementos excepto el pivote sean 0. Si el pivote fuese 0 habría que intercambiar filas para evitar dividir por 0.
Elegimos multiplicar por 2 porque ese número es precisamente lo necesario para que, al restarlo, el coeficiente 2 de la fila 2 quede anulado \((2 − 2 = 0)\).
La generalización del sistema lineal en una matriz aumentada es muy importante porque los modelos lineales en ciencia de datos funcionan exactamente igual:
$$\vec{y} = A\vec{w} + \vec{ε}$$
donde:
\(A\) es la matriz de datos (cada fila una observación, cada columna una variable)
\(\vec{w}\) son los pesos o coeficientes del modelo (lo que queremos estimar),,
\(\vec{y}\) son los valores observados o predichos.
\(\vec{ε}\) representa los errores o diferencias entre la predicción y los datos reales.
Esa es exactamente la forma que adoptan los modelos lineales en ciencia de datos y machine learning.
Resolver el sistema equivale a encontrar los valores de \(\vec{w}\) que mejor explican o ajustan los datos. Por eso, las ecuaciones lineales y su resolución matricial son la base matemática de muchos algoritmos de Machine Learning.
Ecuaciones Lineales con Python
Python hace que resolver sistemas lineales sea fácil y rápido con NumPy. Vamos a hacerlo de forma didáctica, con el mismo ejemplo de las frutas (dos ecuaciones, dos incógnitas), y luego generalizamos a más variables.
Ve los artículos relacionados con las matrices en Python:
import numpy as np# Definimos la matriz de coeficientes y el vector de resultadosA = np.array([[2, 3], [1, 1]])b = np.array([30, 12])# Resolver el sistema A x = bx = np.linalg.solve(A, b)print("Solución (x, y):", x)
Solución (x, y): [6. 6.]
Comprobar el resultado:
# Verificamos A @ x = bprint("Comprobación:", A @ x)
Comprobación: [30. 12.]
Usando la inversa de la matriz (método alternativo)
Este método no se recomienda en práctica cuando hay muchas variables, porque calcular la inversa directamente es más costoso y menos estable numéricamente.
A_inv = np.linalg.inv(A)x_alt = A_inv @ bprint("Solución con A^-1:", x_alt)
El sector inmobiliario global está experimentando una transformación estructural impulsada por el fenómeno PropTech (Property Technology), donde la analítica de datos avanzada y el Big Data sustituyen a los métodos tradicionales de tasación y análisis de mercado. Hoy en día, plataformas líderes como Idealista o Zillow operan como masivos agregadores de información en tiempo real, abriendo una ventana de oportunidad única para la toma de decisiones basada en datos (Data-Driven Decisions). En este contexto, la capacidad de procesar, limpiar y modelar datos extraídos directamente de la web no es solo una ventaja competitiva, sino el estándar operativo para inversores institucionales, desarrolladores urbanos y analistas financieros en mercados altamente dinámicos.
Data Science Pipeline
Ingesta de datos tabulares: Ejecutar el pipeline de lectura de fuentes de datos estructuradas en texto plano (raw data) para su inicialización en memoria.
Curación y limpieza de datos (Data Wrangling / Preprocessing): Aplicar transformaciones en el DataFrame (imputación de valores nulos, parsing de tipos de datos, manejo de outliers y deduplicación) para optimizar la calidad de los datos (data quality) y mitigar sesgos en el modelado.
Geocodificación y Enriquecimiento de Features: Implementar el proceso de geocoding mediante la API de Geopy para transmutar variables de texto (direcciones físicas) en vectores geoespaciales (latitud y longitud), permitiendo la representación cartográfica en un mapa interactivo.
Análisis Exploratorio de Datos (EDA): examinar el conjunto de datos para entender sus características, detectar anomalías y descubrir patrones mediante resúmenes estadísticos y gráficos.
Visualización de Analíticas Geoespaciales: Desplegar mapas de calor (heatmaps) o mapas coropléticos para mapear la distribución espacial e identificar sesgos geográficos o gradientes de precio entre regiones.
Ingeniería de Características y Análisis de Correlación: Evaluar la covarianza y el impacto estadístico (feature importance) de las variables independientes del inmueble sobre la variable objetivo (target), que es el precio.
Clustering para Segmentación de Mercado: Implementar algoritmos de aprendizaje no supervisado (como K-Means o DBSCAN) para agrupar patrones ocultos, reduciendo la dimensionalidad para perfilar clústeres del sector inmobiliario.
Inferencia Estadística y Pruebas A/B (A/B Testing): Ejecutar tests estadísticos (como ANOVA, T-Test o pruebas no paramétricas) para validar la significancia estadística de las diferencias de precio e aislar el efecto de features específicas.
Despliegue de un Dashboard de BI en Tableau: Desarrollar un cuadro de mando interactivo para habilitar el drill-down de métricas clave y permitir la exploración dinámica del dataset por parte de los stakeholders.
Data Storytelling y Data-Driven Insights: Comunicar los hallazgos críticos del pipeline analítico mediante narrativas de datos, transformando métricas técnicas en recomendaciones estratégicas e insights accionables para el negocio.
1. Introducción y Contexto del Negocio (Business Understanding)
Proyecto Capstone del Curso Data Science: Analytics Specialist, de Codecademy. En este se desarrolla un Pipeline de Ciencia de Datos de extremo a extremo aplicado al sector PropTech (tecnología inmobiliaria). Para este análisis se ha seleccionado el Spanish Housing Dataset, un conjunto de datos reales de código abierto alojado en Kaggle. Los datos fueron recolectados originalmente mediante técnicas de web scraping automatizado sobre la plataforma Idealista S.A.U., el portal inmobiliario líder en España.
La investigación se enfoca estratégicamente en el segmento de apartamentos (apartments/condos) dentro del territorio español. Este subsector representa una categoría crítica en los núcleos urbanos y suburbanos de alta densidad, donde la demanda de soluciones habitacionales eficientes, accesibles y con alta liquidez es elevada.
El propósito central de este análisis es desentrañar las dinámicas subyacentes del mercado inmobiliario español, aislando las características clave (features) que impactan directamente en la tasación y la elasticidad del precio. A través de un riguroso Análisis Exploratorio de Datos (EDA), estadística descriptiva e inferencial, se identifican patrones ocultos, asimetrías de precios y agrupaciones geoespaciales (clusters). Los resultados proveen insights de alto valor estratégico para tomadores de decisiones, inversores institucionales (REITs) y compradores privados internacionales.
Nota metodológica: Con el fin de garantizar la escalabilidad del proyecto, la fase de curación y preprocesamiento de datos (Data Wrangling) se ejecuta de manera agnóstica sobre el volumen total del dataset. Esto permite estructurar una base de datos limpia, robusta y optimizada para futuros análisis predictivos o modelos de Machine Learning aplicados a otros tipos de activos (como viviendas unifamiliares o locales comerciales).
2. Objetivos Estratégicos
El objetivo principal de este proyecto es modelar y analizar el comportamiento estadístico de los apartamentos y viviendas unifamiliares en venta a lo largo de diversas provincias españolas durante el ejercicio fiscal 2019.
Los objetivos específicos del pipeline analítico incluyen:
Ingesta y Curación de Datos: Diseñar un flujo de preprocesamiento robusto en Pandas para mitigar el ruido estadístico (outliers, nulos y duplicados).
Enriquecimiento Geoespacial: Implementar algoritmos de geocoding mediante la API de Geopy para transmutar direcciones textuales en vectores tridimensionales (latitud, longitud y altitud) que permitan una cartografía interactiva precisa.
Segmentación Avanzada: Aplicar modelos de aprendizaje no supervisado (Clustering) para clasificar el mercado e identificar micronichos de inversión.
Business Intelligence (BI): Construir e implementar un dashboard interactivo en Tableau enfocado en la exploración dinámica y el desglose (drill-down) de métricas macroeconómicas locales.
Localización Internacional: Adaptar la terminología técnica, métricas superficiales (de metros cuadrados a square feet) y formatos financieros al contexto normativo y cultural de los inversores privados de Estados Unidos (EE. UU.), facilitando la transferencia de conocimiento (Data Storytelling).
3. Fuente, Arquitectura y Estructura de los Datos
La fuente de datos de partida consiste en un dataset crudo de texto plano estructurado que consta de 100,000 registros (instancias) y 41 variables (características). La granularidad de la información abarca atributos multidimensionales de los listados inmobiliarios activos en el portal, agrupados de la siguiente forma:
Métricas Financieras y de Dimensión: Variable objetivo (target) precio, coste por unidad de superficie, tamaño del inmueble, entre otros.
Atributos Estructurales y de Calidad: Estado de conservación (renovado, a reformar), año de construcción, planta/piso.
Variables de Confort (Features Binarias): Presencia de sistemas de climatización (A/C), zonas verdes (jardín), terrazas, plazas de garaje y piscinas comunitarias o privadas.
Datos de Localización: Direcciones normalizadas, municipios, códigos postales y provincias.
El conjunto de datos presenta una naturaleza híbrida compuesta por variables cuantitativas (discretas y continuas) y cualitativas (nominales y ordinales), ofreciendo un entorno óptimo para la inferencia estadística robusta y la ingeniería de características.
4. Inspección Inicial del Dataset (Raw Data Snapshot)
Para validar la integridad estructural e iniciar el proceso de auditoría de datos (Data Profiling), se presenta a continuación una muestra del primer registro indexado en memoria dentro de nuestro DataFrame original:
print(raw_data.head(1).T)
0ad_description Precio chalet individual en la localidad de Ab...ad_last_update Anuncio actualizado el 27 de marzoair_conditioner 0balcony 0bath_num 2built_in_wardrobe 0chimney 0condition segunda mano/buen estadoconstruct_date NaNenergetic_certif NaNfloor 2 plantasgarage plaza de garaje incluida en el preciogarden 1ground_size NaNheating NaNhouse_id 81717634house_type Casa o chalet independientekitchen NaNlift NaNloc_city Urcabustaizloc_district La iglesialoc_full La iglesia , Urcabustaiz , Zuya, Álava loc_neigh NaNloc_street NaNloc_zone Zuya, Álavam2_real 1000m2_useful 172.0obtention_date 2019-03-29orientation norte, sur, este, oesteprice 310000reduced_mobility 0room_num 4storage_room 0swimming_pool 0terrace 1unfurnished NaNnumber_of_companies_prov 19147population_prov 328868companies_prov_vs_national_% 0.57population_prov_vs_national_% 0.70renta_media_prov 19889.00
5. Pipeline de Procesamiento y Curación de Datos (Data Wrangling)
El proceso de preparación y adecuación del dataset se estructuró en un pipeline secuencial dividido en tres fases fundamentales, garantizando así la calidad de los datos (Data Quality), la consistencia interna y la reproducibilidad del análisis.
Fase 1: Preprocesamiento y Depuración Estructural (Initial Transformation)
El objetivo de esta primera fase fue mitigar el ruido estadístico inicial, descartar redundancias en el flujo de datos y homogeneizar los formatos vectoriales necesarios para las posteriores tareas de enriquecimiento geoespacial. Las operaciones críticas ejecutadas incluyeron:
Filtrado de Características (Feature Dropping / Data Filtering): Se realizó un análisis de relevancia para identificar y remover 16 variables que no aportaban valor predictivo ni descriptivo al núcleo del negocio (como identificadores internos del portal web o metadatos de los anuncios). Esta reducción de dimensionalidad optimizó drásticamente el consumo de memoria en el entorno de ejecución.
Deduplicación de Instancias (Data Deduplication): Se auditó el DataFrame en busca de registros idénticos que pudieran sesgar las distribuciones de precios (causados habitualmente por la republicación de anuncios). Se identificaron e indexaron 6,071 registros duplicados, los cuales fueron eliminados por completo para asegurar la unicidad de las observaciones.
Tratamiento de Valores Omisos (Handling Missing Data): Se evaluó la matriz de densidad de nulos para determinar el mecanismo de pérdida de información (MCAR, MAR o MNAR). Dependiendo de la variable, se aplicaron estrategias diferenciadas:
Filtrado por umbral (Drop) en variables críticas de localización imposibles de inferir.
Imputación estadística (empleando la mediana del vecindario/provincia) para variables numéricas continuas como la superficie o el precio.
Categorización explícita (como “No especificado”) para atributos cualitativos binarios o nominales, evitando así la pérdida de registros valiosos.
Imputación por Ausencia Estructural (Structural Missingness): Se identificó que los valores faltantes en ciertas variables cualitativas binarias (como la disponibilidad de garaje o ascensor) no respondían a una pérdida aleatoria de información, sino a una omisión estructural. En el sector PropTech, la ausencia de registro equivale a la inexistencia del atributo. Por lo tanto, se ejecutó una imputación determinista reemplazando estos nulos por el valor binario 0 (Falso).
Filtrado por Umbral de Densidad (Sparsity Filtering): Se auditó la tasa de completitud de todas las características. Nueve variables que exhibían un índice de valores ausentes superior al 60% fueron descartadas de forma definitiva, mitigando el riesgo de introducir sesgos artificiales mediante técnicas de imputación masiva sobre matrices dispersas.
Fase 2: Armonización de Variables y Derivación de Características (Feature Engineering)
Con el fin de estandarizar el dataset e iniciar el proceso de auditoría y perfilado de variables (Data Profiling), se implementaron las siguientes operaciones a nivel de registro:
Estandarización de Categorías y Localización de Dominio: Para adaptar el proyecto al mercado objetivo de inversores de EE. UU., se transformó la taxonomía y codificación original hacia la jerga inmobiliaria americana (e.g., convirtiendo tipos de propiedad a Apartment/Condo, Single-Family Home, etc.). Asimismo, se corrigieron inconsistencias sintácticas y tipográficas presentes en el texto libre.
Casteo de Tipos de Datos (Type Casting): Se reasignaron los tipos de datos en memoria para optimizar el rendimiento del sistema, forzando variables numéricas mal indexadas a flotantes o enteros (float64/int64), y convirtiendo variables de texto repetitivas en el tipo eficiente category de Pandas.
Normalización de Texto para Geocodificación: Se aplicaron expresiones regulares (Regex) para limpiar la variable de dirección física, eliminando ruidos de texto y prefijos redundantes (como “Calle”, “Avenida”, “Av.”) que disminuyen la precisión de los motores de búsqueda geográfica.
Derivación de Características de Respaldo (Feature Derivation): Se diseñó una variable sintética denominada city_prov mediante la concatenación de los campos loc_city y loc_zone. Esta variable actúa como una directiva de ubicación secundaria (fallback location) en el pipeline, asegurando que si la dirección específica falla al geocodificarse, el sistema pueda aproximar el registro a nivel municipal.
Persistencia Intermedia: El DataFrame limpio y armonizado se exportó a un nuevo archivo serializado, garantizando un punto de restauración óptimo antes de iniciar la fase de cómputo intensivo.
6. Enriquecimiento Geoespacial y Procesamiento por Lotes (Batch Geocoding)
Para transformar las direcciones físicas en vectores de coordenadas espaciales (Latitud y Longitud), se integró la librería Geopy utilizando el servicio de geocodificación Nominatim, un motor de código abierto basado en el ecosistema de mapas vectoriales OpenStreetMap.
Arquitectura del Pipeline de Geocodificación por Bloques (Chunking)
Debido al volumen masivo del dataset (100,000 registros), realizar peticiones síncronas a una API externa en un solo bloque comprometería la memoria del sistema y provocaría el bloqueo por tiempo de espera (timeout). Para solucionar esta limitación de infraestructura, se diseñó una arquitectura de procesamiento por lotes (batch processing) dividiendo el DataFrame en bloques (chunks) de 10,000 registros.
El flujo algorítmico se estructuró a través del siguiente pipeline de funciones:
create_chunks: Segmenta el DataFrame maestro en particiones homogéneas de 10,000 filas y persiste temporalmente cada bloque en disco para minimizar la huella de memoria RAM.
geolocate: Invoca el motor de Nominatim fila por fila dentro del bloque para capturar las coordenadas y retornar una cadena de texto con la dirección normalizada completa encontrada por el servidor.
split_address: Realiza un proceso de parsing (análisis sintáctico) sobre la dirección completa devuelta por el servidor para extraer y estructurar vectorialmente variables críticas: código postal (ZIP code), municipio y región.
process_chunk: Actúa como la función orquestadora del lote. Ejecuta secuencialmente geolocate y split_address, integra las nuevas características geoespaciales en el bloque actual, escribe el resultado parcial en almacenamiento físico y ejecuta el recolector de basura de Python para liberar la memoria antes de procesar el siguiente lote.
Finalmente, un script de consolidación unificó todos los bloques procesados en un único dataset maestro enriquecido.
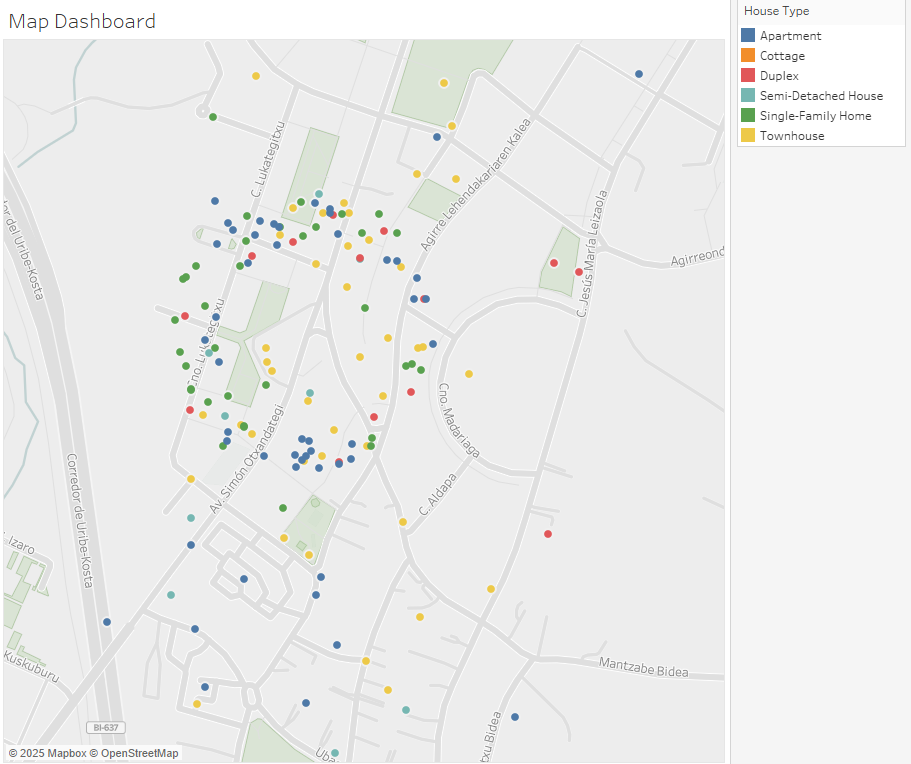
Optimización Visual mediante Dispersión de Coordenadas (Spatial Jittering)
Durante la fase de control de calidad y representación cartográfica preliminar, se detectó una alta colisión de registros en coordenadas idénticas. Este fenómeno de superposición espacial responde a tres dinámicas del mercado real:
Unidades Multifamiliares: Propiedades verticales (apartamentos) que coexisten dentro del mismo edificio físico.
Geocodificación por Fallback: Registros cuya dirección original presentaba fallos sintácticos graves, forzando al pipeline a utilizar la variable de respaldo city_prov, ubicando la propiedad en el centroide geográfico de la ciudad.
Anuncios Ciego (Blind Listings): Una práctica comercial extendida en el sector Real Estate donde las agencias omiten deliberadamente la dirección exacta para proteger la privacidad del vendedor, evitar la desintermediación y prevenir que competidores contacten directamente al propietario. Estos anuncios comparten coordenadas genéricas centralizadas.
Implementación del Algoritmo de Jittering
Para resolver la superposición visual en los mapas interactivos y permitir un análisis de densidad correcto, se aplicó la técnica estadística de Jittering Spatial, la cual introduce ruido estocástico aleatorio de baja magnitud a las coordenadas duplicadas.
El sub-pipeline matemático opera mediante dos funciones clave:
move_coordinates: Desplaza de forma vectorial las coordenadas originales calculando un nuevo punto a partir de un ángulo de azimut y una distancia radial aleatoria. Estos valores métricos se transmutan a grados de arco geográfico (ajustando la deformación por latitud) y se adicionan a los vectores originales. (Nota de limitación del modelo: Al aplicar ruido aleatorio en zonas costeras, existe un margen de error donde algunos registros pueden sufrir un desplazamiento infinitesimal que los posicione visualmente sobre la superficie marina).
disperse_coordinates: Actúa como la función de agrupación. Identifica mediante una operación de agregación todas las coordenadas duplicadas en el dataset y aplica de manera aislada la función move_coordinates a cada registro repetido, distribuyendo las propiedades de forma concéntrica en un radio controlado por parámetros de distancia mínima y máxima predefinidos.
Muestra Visual del Impacto del Algoritmo (Spatial Jittering Demo)
A continuación, se ilustra el comportamiento del algoritmo donde múltiples instancias colapsadas en un único centroide se transforman en una distribución dispersa y legible para el analista o el usuario final:
Curación de Datos Avanzada y Acotación del Espacio Muestral (Data Cleaning for Analytics)
Una vez integrado el algoritmo de jittering, el dataset se exportó como un punto de control intermedio. En esta etapa, el DataFrame maestro consolidó un volumen de 89,948 registros y 19 columnas (incluyendo las 6 nuevas variables vectoriales derivadas de la fase de geocodificación).
A partir de esta estructura, se diseñó un pipeline de depuración quirúrgica para asegurar la validez estadística, eliminando sesgos geográficos y comerciales antes de la fase de modelado analítico:
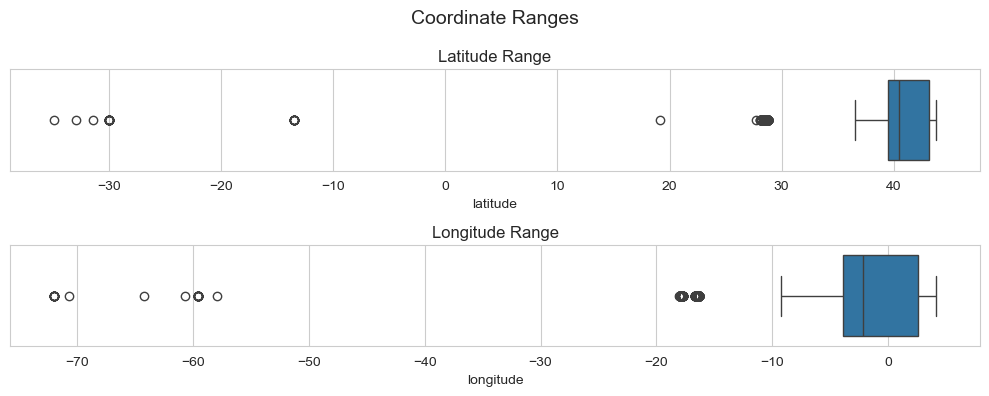
Validación de Límites Geoespaciales (Bounding Box Filtering): Para evitar errores de proyección en la cartografía, se realizó una auditoría de coordenadas aplicando máscaras booleanas basadas en el bounding box oficial del territorio español:
Latitud: 27.6ºN, 43.8ºN (Desde el archipiélago canario hasta el litoral cantábrico).
Longitud: -18.2ºW, 4.3ºE (Desde la isla de El Hierro hasta la costa oriental de Baleares).
Esta validación identificó 37 anomalías espaciales (outliers geográficos), las cuales fueron removidas del flujo principal para evitar distorsiones en los mapas interactivos.
Filtrado por Representatividad Muestral: Con el objetivo de estabilizar la varianza del modelo, se ejecutó una poda estadística en variables categóricas de baja frecuencia:
Se removieron regiones administrativas con un volumen de registros estadísticamente insignificante (low-density regions).
Se descartaron tipologías de vivienda con nula representatividad en el mercado masivo urbano (tales como castillos, palacios, ranchos, mansiones, casas torres y casas rurales), concentrando el espectro analítico puramente en el segmento residencial estándar.
Ingeniería de Características (Feature Binning & Binning Stratification): Se transformaron variables continuas en estructuras categóricas ordinales para facilitar la segmentación de mercado en Tableau:
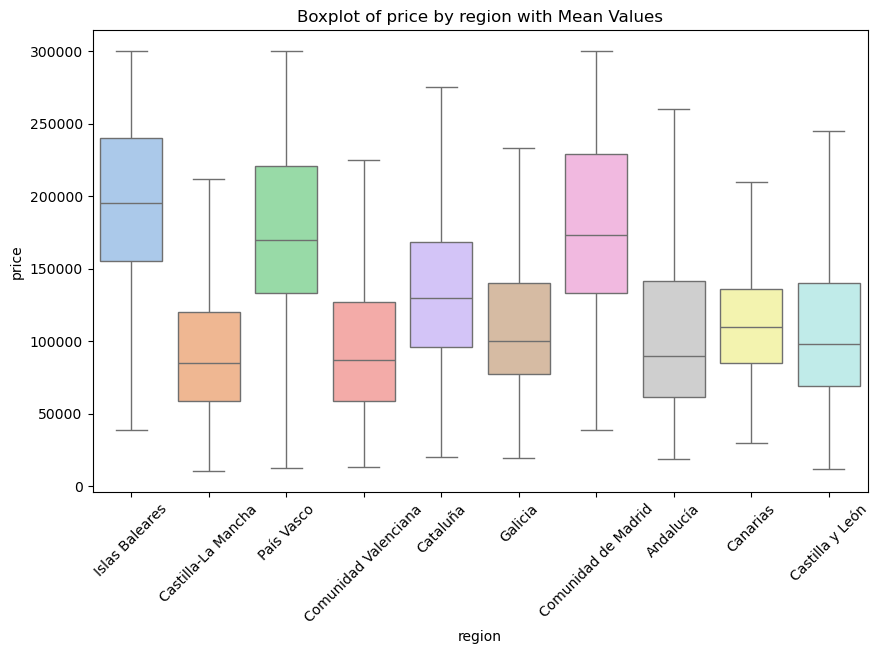
price_segment: Clasificación del inventario según su valor financiero:
Affordable:
Mid-Range:
Luxury:
size_category: Clasificación por densidad de superficie construida (mapeada bajo estándares internacionales de la industria):
Small: ()
Medium:
Large: ()
Tratamiento de Inconsistencias Lógicas: Se ejecutó un filtro de integridad física eliminando registros con valores imposibles o nulos en variables clave de habitabilidad, tales como propiedades con cero baños o cero habitaciones.
Truncamiento del Espectro Inmobiliario (Capping Extremes): Al evaluar la función de densidad de probabilidad (PDF) de la variable objetivo price, se observó una cola pesada hacia la derecha (right-skewed distribution). Para mitigar el efecto de datos atípicos o errores de digitación en el portal inmobiliario, se parametrizó un umbral de corte estricto, aislando el análisis entre un mínimo de €10,000 y un máximo de €2,000,000. Cualquier registro fuera de este intervalo operativo fue removido.
Algoritmo de Remoción de Outliers Segmentado (Stratified Outlier Treatment)
Eliminar valores atípicos de forma global sobre un mercado tan heterogéneo como el inmobiliario introduce un sesgo metodológico crítico: un precio “atípico alto” para un apartamento pequeño en una región rural podría ser un precio “atípico bajo” para un inmueble en una zona de lujo urbana.
Para resolver esto, se desarrolló e implementó un enfoque de remoción adaptativa y estratificada mediante dos funciones customizadas en Python:
remove_outliers: Función atómica que calcula el Rango Intercuartílico () sobre una serie numérica. Define las barreras de aceptación estadística mediante los límites inferior y superior tradicionales: Cualquier observación que se posicione fuera de estas fronteras analíticas es clasificada como un outlier estadístico y removida.
clean_outliers_by_segment: Función orquestadora que aplica una estrategia de descomposición jerárquica mediante agrupamientos sucesivos (nested group-by). El algoritmo aísla el cálculo del IQR de forma justa y comparable, subdividiendo el conjunto de datos bajo el siguiente flujo:
Esta normalización multicapa garantiza que los valores considerados atípicos se evalúen respetando el comportamiento de sus pares directos de mercado, preservando la microestructura económica del conjunto de datos.
Consolidación del Dataset Final para Análisis
Tras la ejecución completa de este pipeline de ingeniería y curación de datos, la dimensión final del DataFrame maestro se estabilizó en 77,677 registros y 21 columnas. Este volumen de datos limpio, curado, enriquecido y libre de ruido estadístico conforma la base de datos de alta fidelidad (Analytics-Ready Dataset) utilizada para las posteriores fases de analítica inferencial y visualización.
Para verificar la disposición física de la estructura de datos en memoria lista para su ingesta en Tableau, se presenta un perfil transpuesto del primer registro procesado:
print(spain_housing.head(1).T)
air_conditioner 0bath_num 2chimney 0condition Resalegarage Not Includedgarden 1house_type Single-Family Homem2_real 275price 242000.00room_num 3storage_room 1swimming_pool 1terrace 1latitude 38.59longitude -0.14address Urbanizatzación Convent de les Monges / Urbani...p_code 3530region Comunidad Valencianamunicipality Alicanteprice_segment Affordablesize_category Large
Análisis Exploratorio de Datos (EDA) y Modularización Analítica
Con el conjunto de datos limpio y validado estadísticamente, se procedió a la fase de Análisis Exploratorio de Datos (EDA). En este punto, la investigación se estructuró de manera estratificada por cada price_segment, aislando el comportamiento de las variables continuas y categóricas para identificar dinámicas específicas de oferta y demanda.
Arquitectura de Software: Modularización mediante functions.py
Para garantizar la mantenibilidad, escalabilidad y legibilidad del código (siguiendo las mejores prácticas de ingeniería de software para Ciencia de Datos), se evitó saturar el cuaderno principal (Jupyter Notebook) con bloques de código redundantes de generación de gráficos. En su lugar, se encapsuló toda la lógica visual en un script modular independiente denominado functions.py.
Este fichero actúa como una librería interna que es importada en el entorno de ejecución, permitiendo invocar funciones dinámicas y parametrizables de manera limpia:
Catálogo de Funciones de Abstracción Analítica
Las funciones integradas en el pipeline modular se dividen según su propósito específico dentro de la auditoría analítica:
1. Motores de Transformación e Interrogación de Datos
filterdf(df, col1, val1, col2, val2): Retorna un sub-DataFrame ejecutando una máscara booleana bidimensional basada en dos características y sus respectivos umbrales operativos.
2. Motores de Análisis Univariado y Distribución
boxplot_view(dataframe, column): Despliega diagramas de caja para diagnosticar la asimetría y el rango intercuartílico de variables continuas.
boxplot_view_wo(dataframe, column): Muestra la misma distribución de cajas, pero truncando los extremos (whiskers) para aislar visualmente los datos atípicos y mejorar el detalle de los cuartiles centrales.
distribution_views(dataframe): Inicializa una cuadrícula de gráficos de densidad para contrastar la dispersión en los campos críticos m2_real y price.
plot_histogram(df, column, bins=20, kde=True, xlim=None): Genera histogramas avanzados con la estimación de densidad de kernel (KDE) integrada para evaluar la normalidad de la variable.
3. Motores de Análisis Categórico y Frecuencias
binary_categorical_view(dataframe): Evalúa simultáneamente el volumen y tasa de penetración de características booleanas ligadas al confort habitacional (air_conditioner, chimney, garden, storage_room, swimming_pool, terrace).
categorical_features_view(dataframe): Desglosa las variables categóricas ordinales y cardinales del inventario como room_num, bath_num y el estado general (condition).
plot_rooms_bathrooms_distribution(df): Muestra la densidad de la distribución cruzada de dormitorios y cuartos de baño específicos para un nicho analítico.
plot_category_histograms(df, numeric_col, category_col): Superpone histogramas de variables cuantitativas segregados por etiquetas de una dimensión cualitativa.
4. Motores de Análisis Bivariado, Multivariado y Correlación
bivariate_distribution(dataframe, group_col, target_col, show_outliers): Acopla diagramas de caja cruzados junto a una matriz de salida de estadística descriptiva (media, mediana, desviación estándar) para analizar la variabilidad de una métrica frente a factores grupales.
plot_binary_categorical_relationships(dataframe, target_variable): Ejecuta un análisis de contraste que mapea el impacto de cada atributo binario sobre una variable continua (como el precio), inyectando una tabla resumen con los deltas de variación.
correlation_heatmap_by_size_category(df): Calcula y grafica matrices de correlación de Pearson o Spearman segregadas de forma independiente para cada nivel de size_category.
plot_distribution_by_price_segment(df): Ejecuta un cruce multidimensional agrupando por segmento financiero y tipología de activo para proyectar la densidad de la oferta mediante un mapa de calor bidimensional.
Muestra de implementación: functions.py (Script Snippet)
A continuación se expone, a modo de ejemplo de ingeniería de código, la arquitectura interna de una de las funciones clave del módulo. Esta estructura destaca por su manejo integrado de visualizaciones con Seaborn/Matplotlib y la inyección automática de resúmenes de datos numéricos en la consola:
defbivariate_distribution(dataframe, group_col, target_col, show_outliers=True, figsize=(10, 6)):""" Displays a boxplot and a summary table of a variable grouped by another variable's values. """ df_copy = dataframe.copy()# Boxplot plt.figure(figsize=figsize) ax = sns.boxplot(data=df_copy, x=group_col, y=target_col, showfliers=show_outliers, palette="pastel") plt.title(f'Boxplot of {target_col} by {group_col} with Mean Values') plt.xlabel(group_col) plt.ylabel(target_col) plt.xticks(rotation=45) plt.show()# Summary Statistics table summary_stats = df_copy.groupby(group_col)[target_col].agg( mean=lambda x: round(x.mean(), 2), Q1=lambda x: x.quantile(0.25), Q3=lambda x: x.quantile(0.75), std_dev=lambda x: round(x.std(), 2) ).reset_index() summary_stats = summary_stats.sort_values(by='mean', ascending=False).reset_index(drop=True)print(f"Summary Table of {target_col} by {group_col} sorted by Mean:")print(summary_stats)
Summary Table of price by region sorted by Mean: region mean Q1 Q3 std_dev0 Islas Baleares 197767.25 155000.00 240000.00 56301.501 Comunidad de Madrid 180755.40 133350.00 229000.00 59592.772 País Vasco 176976.07 133000.00 220794.00 60137.553 Cataluña 133926.13 96000.00 168000.00 50869.324 Galicia 116780.80 77000.00 140000.00 55973.885 Canarias 114996.06 85000.00 136000.00 41459.246 Castilla y León 108825.89 69000.00 140000.00 53845.327 Andalucía 104710.97 61650.00 141650.00 54689.418 Comunidad Valenciana 100787.91 59000.00 126800.00 58180.429 Castilla-La Mancha 94720.85 58555.00 120000.00 50163.13
Hallazgos Analíticos y Evidencia Empírica (Exploratory Insights)
A lo largo de cada sección del análisis de datos se documentaron detalladamente las métricas clave descubiertas y las distribuciones de frecuencia de las variables del entorno PropTech. El reporte analítico exhaustivo, junto con los gráficos de dispersión y mapas de calor interactivos generados en esta etapa, se encuentra completamente documentado y disponible para su consulta en el repositorio oficial del proyecto en GitHub.
Inferencia Estadística y Modelado Predictivo (Advanced Analytics)
En esta fase del pipeline, se transicionó de la analítica descriptiva a la analítica diagnóstica y predictiva. Se aplicaron metodologías de estadística inferencial y modelos lineales avanzados para validar con rigor matemático las correlaciones y patrones observados durante el EDA, buscando dar respuesta a la pregunta de negocio central: ¿Cuáles son los inductores de valor (value drivers) estadísticamente significativos en la tasación del mercado de apartamentos en España?
Este bloque de analítica avanzada se articuló bajo dos verticales metodológicas:
Inferencia Estadística (Pruebas de Hipótesis): Diseñada para mitigar el riesgo de sesgo por aleatoriedad y confirmar la significancia de las relaciones.
Modelado Predictivo Supervizado: Orientado a cuantificar el poder explicativo y la elasticidad de los vectores geográficos sobre la variable objetivo (target).
Validaciones Estadísticas e Inferencia
1. Análisis de Varianza (ANOVA) para Segmentos de Superficie (size_category)
Se ejecutó un test ANOVA de una vía (One-Way ANOVA) para contrastar si las discrepancias de precio observadas entre los grupos de tamaño (Small, Medium, Large) eran producto del azar o respondían a dinámicas estructurales de mercado:
Hipótesis Nula (): (No existen diferencias significativas entre los precios medios de las tres categorías).
Hipótesis Alternativa (): Al menos un par de medias poblacionales difiere significativamente entre sí.
Resultado: El rechazo de la hipótesis nula () confirmó que la escala métrica de la vivienda fragmenta el mercado en estratos de valoración completamente independientes.
2. Evaluación del Impacto del Estado de Conservación (condition) en el Precio
Para determinar si el ciclo de depreciación física o la prima por estreno impactan la valoración de forma homogénea, se estructuró un segundo diseño ANOVA comparando los precios según el estado de preservación indexado en el portal:
Grupos de Contraste: New construction (Nueva), Good condition (Reventa) y To renovate (Necesita reforma).
Resultado: La prueba arrojó significancia estadística crítica, validando empíricamente que el coste de oportunidad de la reforma y el valor premium del suelo a estrenar son factores determinantes en la dispersión de precios.
3. Análisis de Correlación de Pearson para Atributos de Habitabilidad (bath_num)
Se evaluó la intensidad del vínculo lineal existente entre la densidad de cuartos de baño y el precio final de los apartamentos:
Hipótesis Nula (): (No existe correlación lineal estadísticamente significativa entre el número de baños y el precio del inmueble).
Hipótesis Alternativa (): (Existe una correlación lineal significativa entre ambas variables).
Resultado: Se evidenció una correlación lineal positiva y robusta, confirmando que la infraestructura interna de fontanería actúa como un proxy de lujo y confort habitacional fuertemente valorado por el mercado.
Modelado Lineal Predictivo: El Vector Geográfico como Inductor de Valor
Más allá de la validación de hipótesis aisladas, se construyó y entrenó un modelo de Regresión Lineal Múltiple. El objetivo de este algoritmo supervisado fue aislar el impacto puramente geoespacial, evaluando en qué medida los vectores tridimensionales combinados (latitud, longitud) y las variables categóricas regionales explican estadísticamente la varianza de la variable dependiente price.
Este modelo base (baseline model) cuantifica el impacto marginal de la ubicación geográfica exacta, sentando los cimientos matemáticos para algoritmos más complejos de tasación automatizada (AVM – Automated Valuation Models).
Impacto del Proyecto y Aplicación de Negocio (Business Value)
Al integrar la exploración visual, la inferencia estadística y el modelado predictivo, el proyecto transita con éxito desde la descripción analítica hacia la anticipación del comportamiento del mercado. Este marco de trabajo robusto se traduce en una toma de decisiones informada por datos (Data-Driven Decisions) con aplicaciones críticas para diversos stakeholders de la industria:
Agentes y Brókers Inmobiliarios: Optimiza las estrategias de fijación de precios de salida (listing price) basándose en el comportamiento real de las features del entorno.
Inversores Corporativos y Compradores Privados: Permite identificar anomalías del mercado, micronichos de inversión de alto rendimiento (yield) y activos infravalorados respecto a su entorno geoespacial.
Desarrolladores, Constructores y Arquitectos: Provee métricas claras sobre la configuración óptima de la vivienda (relación de tamaño, habitaciones y baños) más demandada y valorada en cada región.
Planificadores Urbanos y Oficinas de Desarrollo Económico: Aporta datos empíricos sobre la densidad de la oferta y la distribución del valor del suelo, esenciales para el diseño de políticas de vivienda y zonificación urbana.
Visualización Interactiva y Business Intelligence (Tableau Dashboard)
Para democratizar el acceso a los insights y permitir que los stakeholders no técnicos exploren los resultados de manera autónoma, los datos curados fueron exportados e integrados en un cuadro de mando interactivo desarrollado en Tableau.
El diseño del dashboard se estructuró bajo los siguientes pilares de Experiencia de Usuario (UX) y Analítica Visual:
Exploración Dinámica mediante Filtros en Cascada: Permite al usuario aislar el mercado de forma interactiva seleccionando el price_segment, la región geográfica o la tipología específica de la vivienda.
Mapeo de Densidad Geoespacial: Utiliza las capas vectoriales enriquecidas en la fase de geocodificación para proyectar mapas de calor y clústeres visuales, permitiendo identificar zonas calientes (hotspots) de precios en tiempo real.
Métricas Macroeconómicas Locales: Cuadros de mando (KPI Cards) que calculan automáticamente el precio medio por metro cuadrado (y su equivalencia a square feet para el mercado de EE. UU.), la mediana de habitaciones y los ratios de disponibilidad por provincia.
Conclusiones y Recomendaciones del Pipeline Analítico (Data-Driven Insights)
Tras completar el pipeline analítico, validar las pruebas inferenciales y ajustar el modelo de regresión sobre el segmento de apartamentos en España, se sintetizan las siguientes conclusiones fundamentales para el negocio (p. 1):
1. Validación de los Inductores de Valor Físicos (Property Features)
El impacto crítico de la infraestructura interna: Las pruebas estadísticas rechazaron formalmente la hipótesis nula respecto a la distribución de baños (p-value = 0.0), demostrando una correlación positiva moderada (p=0.49) con el precio de venta. Esto confirma que la densidad de cuartos de baño es un proxy de confort habitacional que pondera más en el precio final que el número de habitaciones independientes, especialmente en los segmentos Medium y Large (p. 1).
Preeminencia del área construida: La matriz de correlaciones determinó que la superficie real (m2_real) mantiene el vínculo más fuerte con la variable objetivo precio (p=0.60). Asimismo, se validó mediante el test ANOVA (F-stat = 7878.25, p-value = 0.0) que la segmentación por tamaño (Small, Medium, Large) divide el mercado en estratos de valoración completamente independientes y significativos.
2. Dinámicas de Conservación y Segmentación del Mercado
El paradigma de la Obra Nueva vs. Reventa: El test ANOVA enfocado en el estado de conservación (condition) ratificó la existencia de diferencias significativas en los precios medios. (F-stat = 17.64, p-value < 0.05) Sin embargo, el análisis descriptivo profundo reveló un comportamiento asimétrico según el poder adquisitivo: mientras que en el segmento Affordable la obra nueva lidera el precio premium, en el segmento Luxury las propiedades de reventa (resale) mantienen promedios superiores a €1M, sugiriendo que la ubicación prime de los activos consolidados supera el valor de depreciación física.
Asimetría Geográfica de la Oferta: El inventario inmobiliario de apartamentos está masivamente dominado por el segmento Affordable (79% del total de registros) y propiedades Small de hasta 93 (57%). Territorios como el País Vasco lideran el volumen absoluto de este mercado base, mientras que la oferta de los segmentos Mid-Range (16%) y Luxury (4%) está estrictamente polarizada y concentrada en tres núcleos: Islas Baleares, Comunidad de Madrid y País Vasco (p. 1).
3. Diagnóstico del Modelo Predictivo Geoespacial (Spatial Regression)
Poder Explicativo de la Ubicación: El modelo de regresión lineal múltiple (OLS) parametrizado con variables puramente geográficas arrojó un R^2 ajustado de 0.192. Esto demuestra matemáticamente que la localización (coordenadas vectoriales y región) es capaz de explicar de forma aislada el 19.2% de la variabilidad total de los precios de los apartamentos en España.
Gradiente de Precios y Sesgo Regional: La regresión confirmó la influencia del eje Norte-Sur del país a través de la variable latitude, la cual posee un coeficiente positivo y altamente significativo. Asimismo, se identificó que la región de Canarias inyecta el mayor impacto positivo marginal en la tasación promedio , contrastando con penalizaciones significativas en la valoración media de regiones como Galicia o Cataluña tras ajustar por el resto de factores espaciales .
Limitaciones del Modelo Baseline: El elevado número de condiciones del modelo alerta sobre la existencia de multicolinealidad entre los predictores espaciales. Además, la falta de normalidad en la distribución de los residuos (confirmada por el test de Jarque-Bera) evidencia la necesidad de transicionar en futuras iteraciones hacia arquitecturas no lineales (como Random Forest Regressor o XGBoost) e incorporar las variables estructurales desestimadas (m2_real y bath_num) para elevar la robustez del ajuste predictivo.
Recomendaciones Estratégicas para Stakeholders
Para Inversores Internacionales (EE. UU.): Las regiones de Castilla-La Mancha y Comunidad Valenciana presentan las oportunidades de arbitraje más eficientes en coste por unidad de superficie, ofreciendo apartamentos sustancialmente más amplios a tasas de cotización bajas. Por el contrario, Madrid y Cataluña representan mercados altamente competitivos y compactos con ratios elevados de precio por pie cuadrado.
Para Desarrolladores Urbanos: Dada la fuerte correlación de la variable bath_num con el precio de mercado, los proyectos de optimización de activos (house flipping o remodelaciones residenciales) deben priorizar la adición o mejora de un segundo o tercer cuarto de baño por encima de la subdivisión de dormitorios, maximizando el retorno de la inversión (ROI) por metro cuadrado.
Stack Tecnológico y Entorno de Ejecución (Tech Stack)
Para garantizar la reproducibilidad de este entorno de análisis, se detallan las tecnologías y librerías de Python utilizadas en el pipeline:
Manipulación y Core Analítico: Python 3.x, Pandas, NumPy.